 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Meta-RangeSeg: LiDAR Sequence Semantic Segmentation Using Multiple Feature Aggregation
Mar 03, 2022
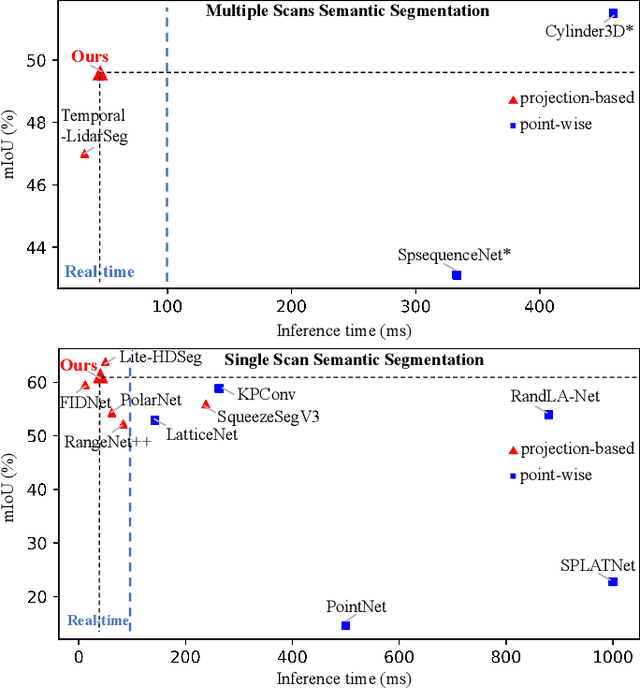
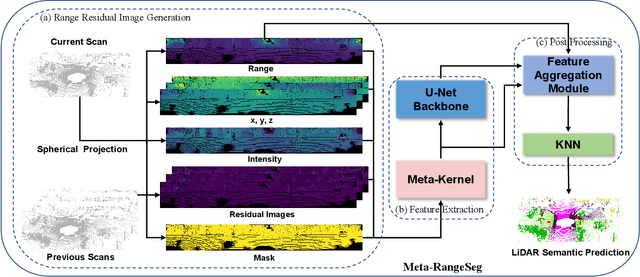
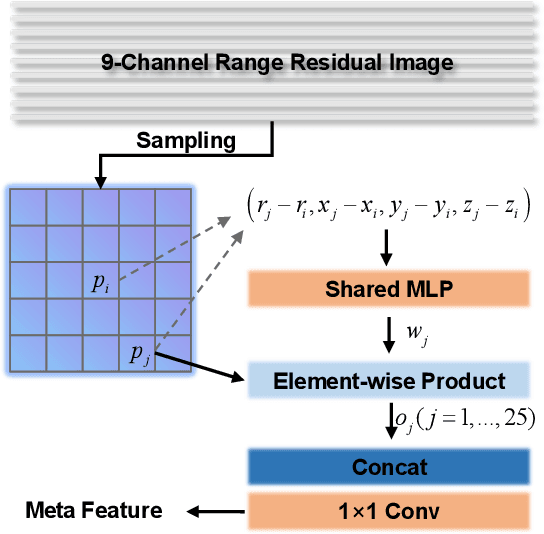
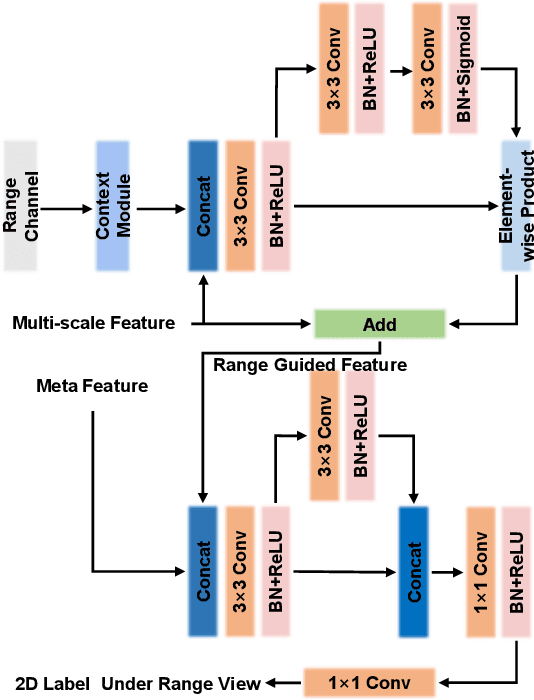
LiDAR sensor is essential to the perception system in autonomous vehicles and intelligent robots. To fulfill the real-time requirements in real-world applications, it is necessary to efficiently segment the LiDAR scans. Most of previous approaches directly project 3D point cloud onto the 2D spherical range image so that they can make use of the efficient 2D convolutional operations for image segmentation. Although having achieved the encouraging results, the neighborhood information is not well-preserved in the spherical projection. Moreover, the temporal information is not taken into consideration in the single scan segmentation task. To tackle these problems, we propose a novel approach to semantic segmentation for LiDAR sequences named Meta-RangeSeg, where a novel range residual image representation is introduced to capture the spatial-temporal information. Specifically, Meta-Kernel is employed to extract the meta features, which reduces the inconsistency between the 2D range image coordinates input and Cartesian coordinates output. An efficient U-Net backbone is used to obtain the multi-scale features. Furthermore, Feature Aggregation Module (FAM) aggregates the meta features and multi-scale features, which tends to strengthen the role of range channel. We have conducted extensive experiments for performance evaluation on SemanticKITTI, which is the de-facto dataset for LiDAR semantic segmentation. The promising results show that our proposed Meta-RangeSeg method is more efficient and effective than the existing approaches. Our full implementation is publicly available at https://github.com/songw-zju/Meta-RangeSeg .
Deep Unsupervised Hashing with Latent Semantic Components
Mar 17, 2022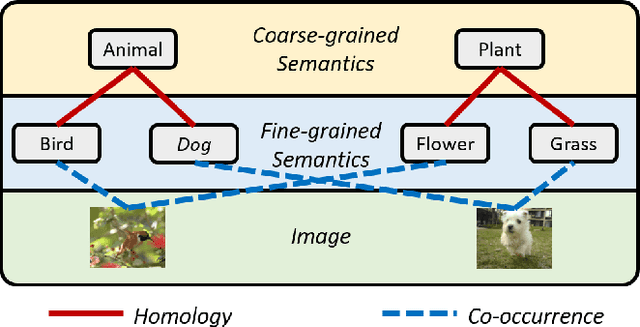
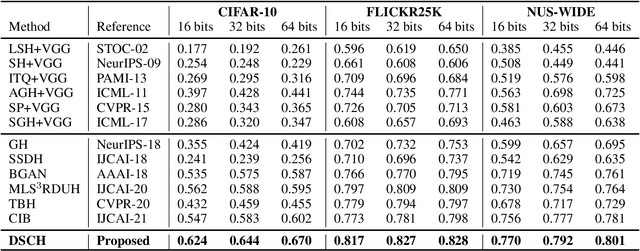
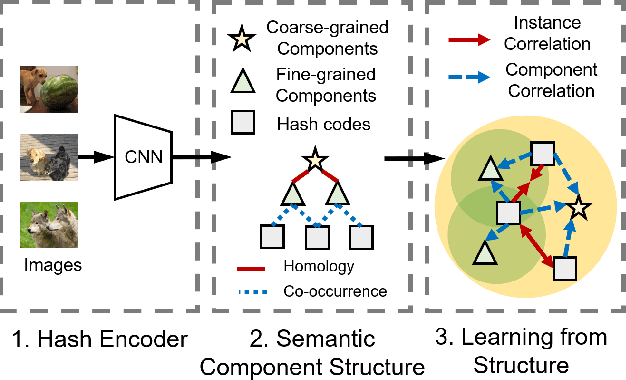
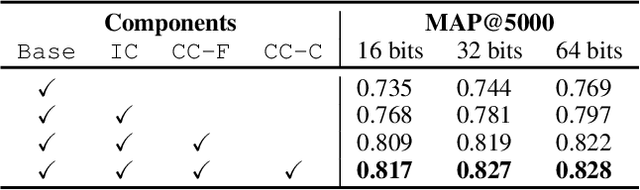
Deep unsupervised hashing has been appreciated in the regime of image retrieval. However, most prior arts failed to detect the semantic components and their relationships behind the images, which makes them lack discriminative power. To make up the defect, we propose a novel Deep Semantic Components Hashing (DSCH), which involves a common sense that an image normally contains a bunch of semantic components with homology and co-occurrence relationships. Based on this prior, DSCH regards the semantic components as latent variables under the Expectation-Maximization framework and designs a two-step iterative algorithm with the objective of maximum likelihood of training data. Firstly, DSCH constructs a semantic component structure by uncovering the fine-grained semantics components of images with a Gaussian Mixture Modal~(GMM), where an image is represented as a mixture of multiple components, and the semantics co-occurrence are exploited. Besides, coarse-grained semantics components, are discovered by considering the homology relationships between fine-grained components, and the hierarchy organization is then constructed. Secondly, DSCH makes the images close to their semantic component centers at both fine-grained and coarse-grained levels, and also makes the images share similar semantic components close to each other. Extensive experiments on three benchmark datasets demonstrate that the proposed hierarchical semantic components indeed facilitate the hashing model to achieve superior performance.
Light Robust Monocular Depth Estimation For Outdoor Environment Via Monochrome And Color Camera Fusion
Feb 24, 2022
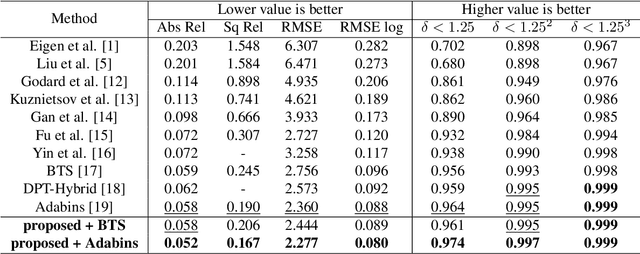
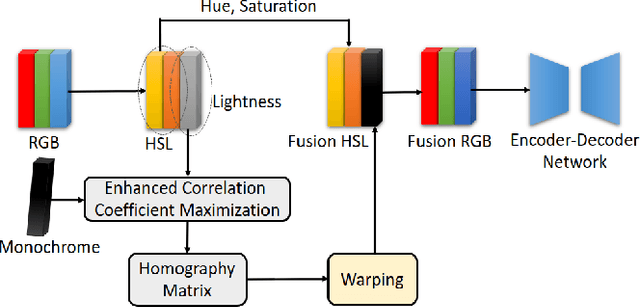
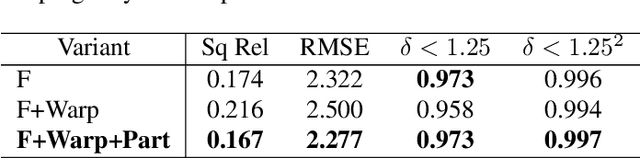
Depth estimation plays a important role in SLAM, odometry, and autonomous driving. Especially, monocular depth estimation is profitable technology because of its low cost, memory, and computation. However, it is not a sufficiently predicting depth map due to a camera often failing to get a clean image because of light conditions. To solve this problem, various sensor fusion method has been proposed. Even though it is a powerful method, sensor fusion requires expensive sensors, additional memory, and high computational performance. In this paper, we present color image and monochrome image pixel-level fusion and stereo matching with partially enhanced correlation coefficient maximization. Our methods not only outperform the state-of-the-art works across all metrics but also efficient in terms of cost, memory, and computation. We also validate the effectiveness of our design with an ablation study.
Parametrization of High-Rank Line-of-Sight MIMO Channels with Reflected Paths
May 11, 2022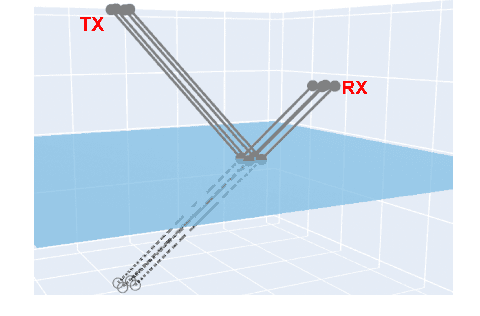
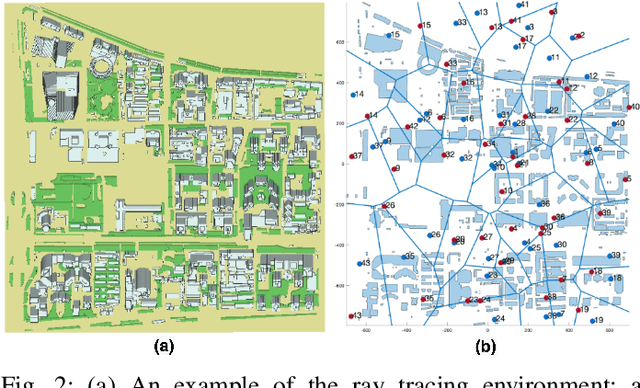
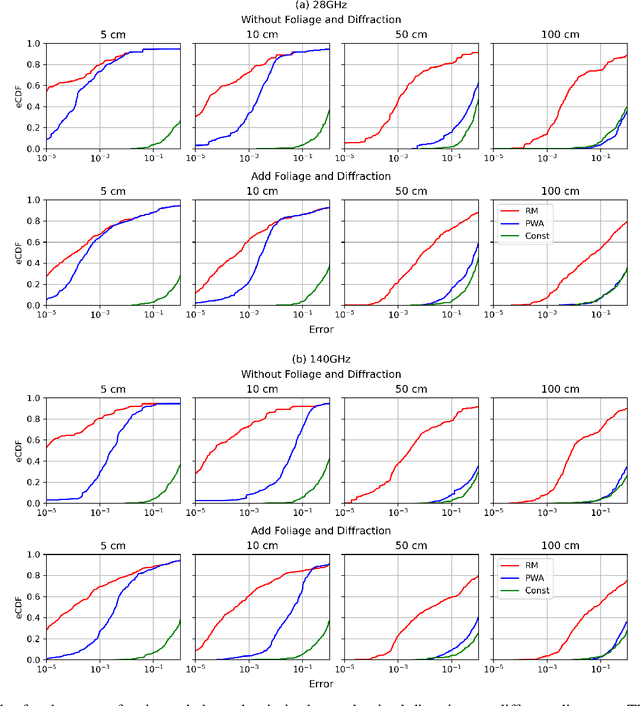
High-rank line-of-sight (LOS) MIMO systems have attracted considerable attention for millimeter wave and THz communications. The small wavelengths in these frequencies enable spatial multiplexing with massive data rates at long distances. Such systems are also being considered for multi-path non-LOS (NLOS) environments. In these scenarios, standard channels models based on plane waves cannot capture the curvature of each wave front necessary to model spatial multiplexing. This work presents a novel and simple multi-path wireless channel parametrization where each path is replaced by a LOS path with a reflected image source. The model fully captures the spherical nature of each wave front and uses only two additional parameters relative to the standard plane wave model. Moreover, the parameters can be easily captured in standard ray tracing. The accuracy of the approach is demonstrated on detailed ray tracing simulations at 28GHz and 140GHz in a dense urban area.
Comparative evaluation of CNN architectures for Image Caption Generation
Feb 23, 2021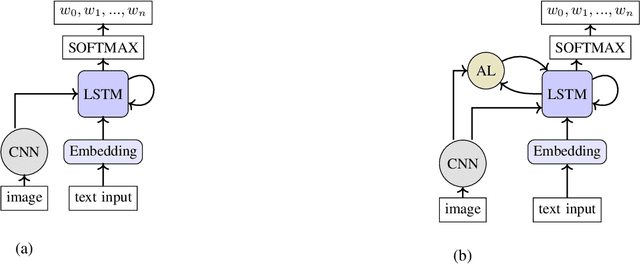
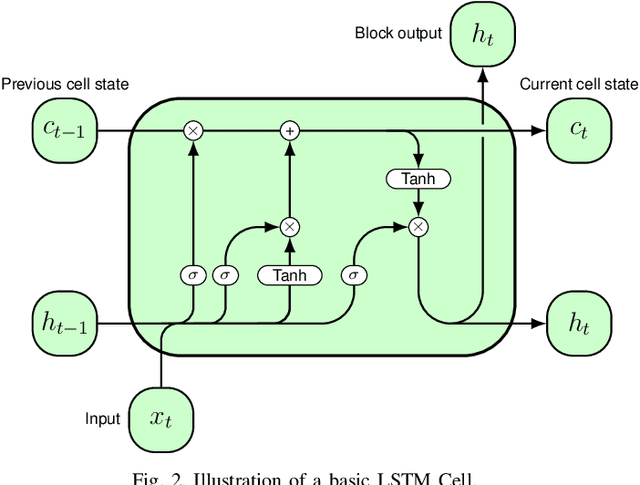
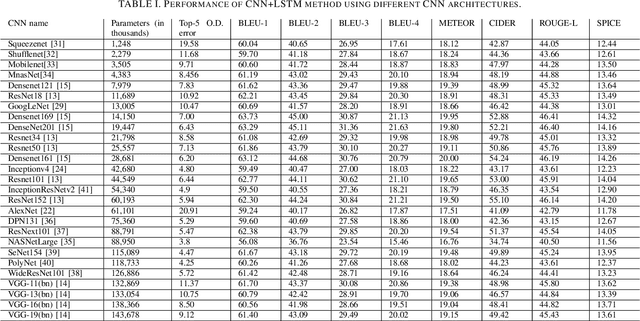
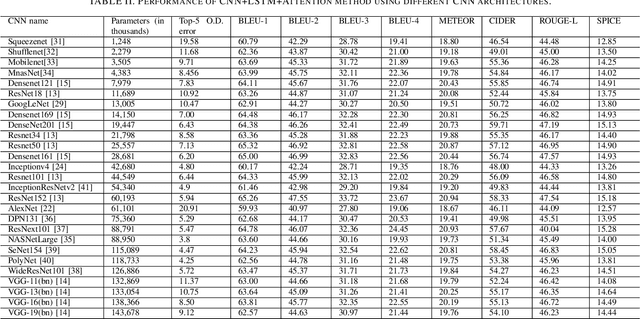
Aided by recent advances in Deep Learning, Image Caption Generation has seen tremendous progress over the last few years. Most methods use transfer learning to extract visual information, in the form of image features, with the help of pre-trained Convolutional Neural Network models followed by transformation of the visual information using a Caption Generator module to generate the output sentences. Different methods have used different Convolutional Neural Network Architectures and, to the best of our knowledge, there is no systematic study which compares the relative efficacy of different Convolutional Neural Network architectures for extracting the visual information. In this work, we have evaluated 17 different Convolutional Neural Networks on two popular Image Caption Generation frameworks: the first based on Neural Image Caption (NIC) generation model and the second based on Soft-Attention framework. We observe that model complexity of Convolutional Neural Network, as measured by number of parameters, and the accuracy of the model on Object Recognition task does not necessarily co-relate with its efficacy on feature extraction for Image Caption Generation task.
* Article Published in International Journal of Advanced Computer Science and Applications(IJACSA), Volume 11 Issue 12, 2020
ART-SS: An Adaptive Rejection Technique for Semi-Supervised restoration for adverse weather-affected images
Mar 17, 2022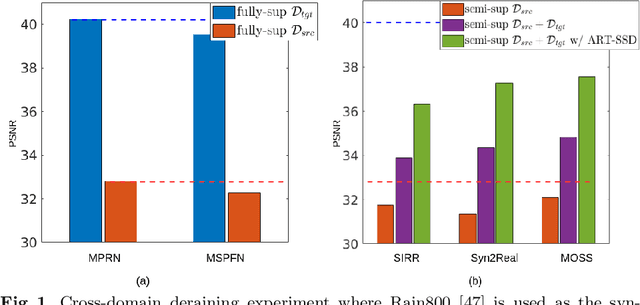
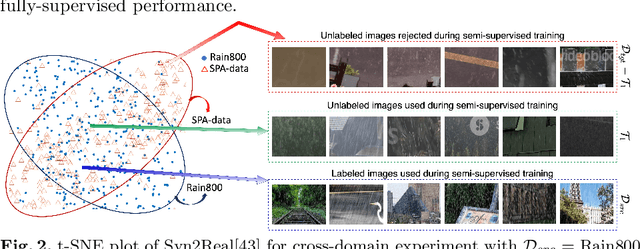

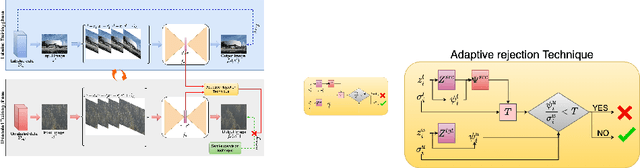
In recent years, convolutional neural network-based single image adverse weather removal methods have achieved significant performance improvements on many benchmark datasets. However, these methods require large amounts of clean-weather degraded image pairs for training, which is often difficult to obtain in practice. Although various weather degradation synthesis methods exist in the literature, the use of synthetically generated weather degraded images often results in sub-optimal performance on the real weather degraded images due to the domain gap between synthetic and real-world images. To deal with this problem, various semi-supervised restoration (SSR) methods have been proposed for deraining or dehazing which learn to restore the clean image using synthetically generated datasets while generalizing better using unlabeled real-world images. The performance of a semi-supervised method is essentially based on the quality of the unlabeled data. In particular, if the unlabeled data characteristics are very different from that of the labeled data, then the performance of a semi-supervised method degrades significantly. We theoretically study the effect of unlabeled data on the performance of an SSR method and develop a technique that rejects the unlabeled images that degrade the performance. Extensive experiments and ablation study show that the proposed sample rejection method increases the performance of existing SSR deraining and dehazing methods significantly. Code is available at :https://github.com/rajeevyasarla/ART-SS
Re-ordering of Hadamard matrix using Fourier transform and gray-level co-occurrence matrix for compressive single-pixel imaging
Mar 09, 2022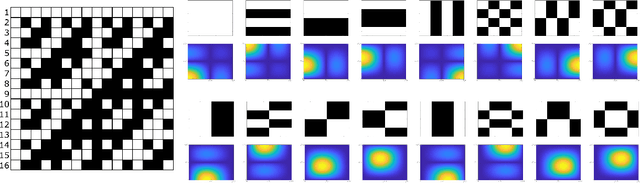
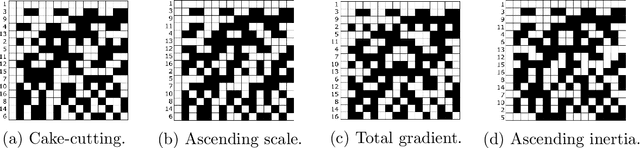


One of the most active research fields in single-pixel imaging is the influence of the sampling basis and its order in the quality of the reconstructed images. This paper presents two new orders, ascending scale (AS) and ascending inertia (AI), of the Hadamard basis and test their performance, using simulation and experimental methods, for low sampling ratios (0.5 to 0.01). These orders were compared with two state-of-the-art orders, cake-cutting (CC) and total gradient (TG), using TVAL3 as the reconstruction algorithm and three noise levels. These newly proposed orders have better reconstructed image quality on the simulation data set (110 images) and achieved structure similarity index values higher than CC order. The experimental data set (2 images) showed that the AS and AI orders performed better with a sampling ratio of 0.5, while for lower sampling ratio the performance of AS, AI and CC was similar. The TG order performed worst in the majority of the cases. Finally, the simulation results present clear evidence that peak signal-to-noise ratio (PSNR) is not a reliable image quality assessment (IQA) metric to assess image reconstruction quality in the context of single pixel imaging.
Few Shot Generative Model Adaption via Relaxed Spatial Structural Alignment
Mar 31, 2022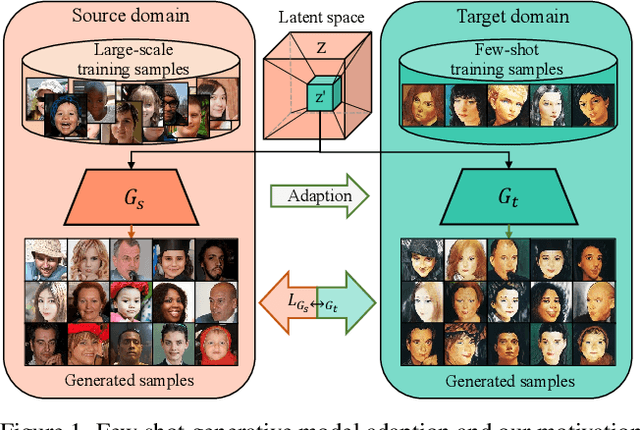
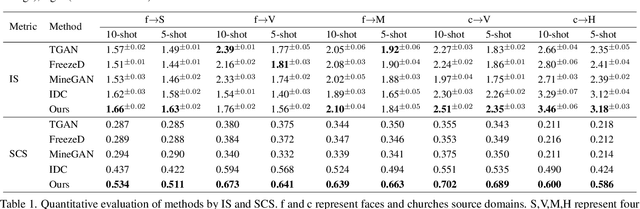
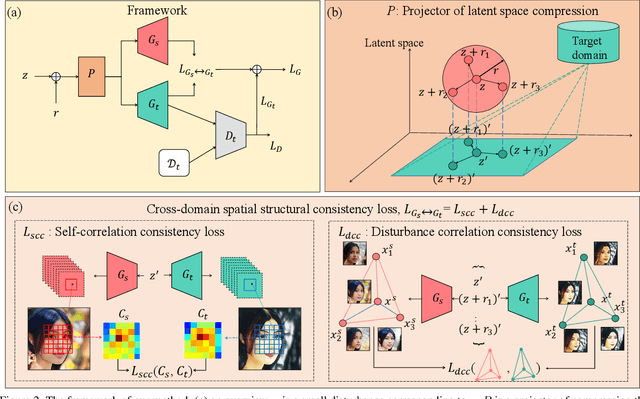

Training a generative adversarial network (GAN) with limited data has been a challenging task. A feasible solution is to start with a GAN well-trained on a large scale source domain and adapt it to the target domain with a few samples, termed as few shot generative model adaption. However, existing methods are prone to model overfitting and collapse in extremely few shot setting (less than 10). To solve this problem, we propose a relaxed spatial structural alignment method to calibrate the target generative models during the adaption. We design a cross-domain spatial structural consistency loss comprising the self-correlation and disturbance correlation consistency loss. It helps align the spatial structural information between the synthesis image pairs of the source and target domains. To relax the cross-domain alignment, we compress the original latent space of generative models to a subspace. Image pairs generated from the subspace are pulled closer. Qualitative and quantitative experiments show that our method consistently surpasses the state-of-the-art methods in few shot setting.
Enhanced Modality Transition for Image Captioning
Feb 23, 2021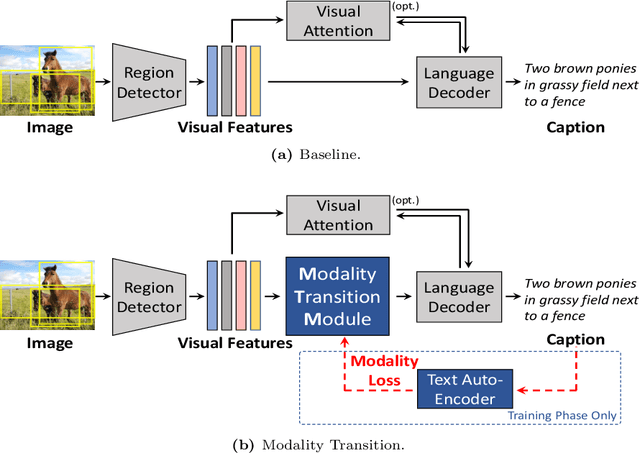
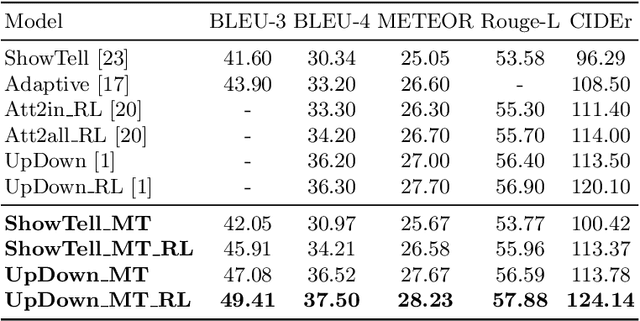
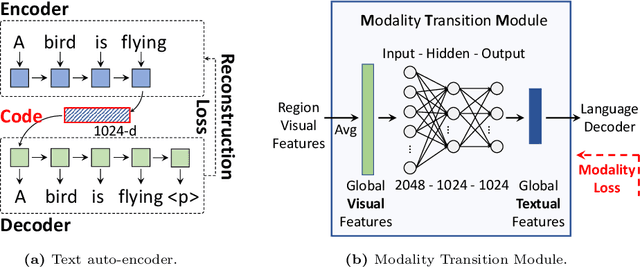
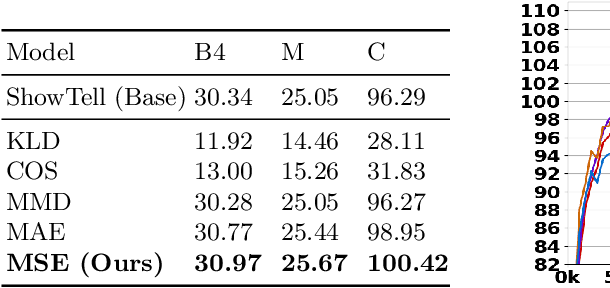
Image captioning model is a cross-modality knowledge discovery task, which targets at automatically describing an image with an informative and coherent sentence. To generate the captions, the previous encoder-decoder frameworks directly forward the visual vectors to the recurrent language model, forcing the recurrent units to generate a sentence based on the visual features. Although these sentences are generally readable, they still suffer from the lack of details and highlights, due to the fact that the substantial gap between the image and text modalities is not sufficiently addressed. In this work, we explicitly build a Modality Transition Module (MTM) to transfer visual features into semantic representations before forwarding them to the language model. During the training phase, the modality transition network is optimised by the proposed modality loss, which compares the generated preliminary textual encodings with the target sentence vectors from a pre-trained text auto-encoder. In this way, the visual vectors are transited into the textual subspace for more contextual and precise language generation. The novel MTM can be incorporated into most of the existing methods. Extensive experiments have been conducted on the MS-COCO dataset demonstrating the effectiveness of the proposed framework, improving the performance by 3.4% comparing to the state-of-the-arts.
Boosting Facial Expression Recognition by A Semi-Supervised Progressive Teacher
May 28, 2022
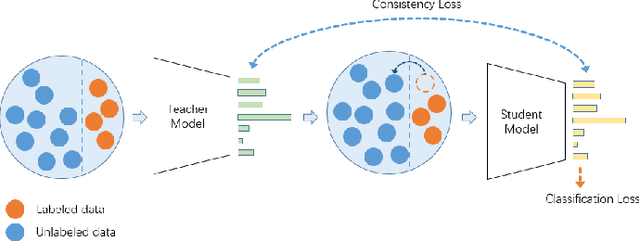

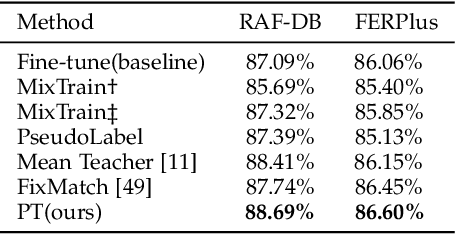
In this paper, we aim to improve the performance of in-the-wild Facial Expression Recognition (FER) by exploiting semi-supervised learning. Large-scale labeled data and deep learning methods have greatly improved the performance of image recognition. However, the performance of FER is still not ideal due to the lack of training data and incorrect annotations (e.g., label noises). Among existing in-the-wild FER datasets, reliable ones contain insufficient data to train robust deep models while large-scale ones are annotated in lower quality. To address this problem, we propose a semi-supervised learning algorithm named Progressive Teacher (PT) to utilize reliable FER datasets as well as large-scale unlabeled expression images for effective training. On the one hand, PT introduces semi-supervised learning method to relieve the shortage of data in FER. On the other hand, it selects useful labeled training samples automatically and progressively to alleviate label noise. PT uses selected clean labeled data for computing the supervised classification loss and unlabeled data for unsupervised consistency loss. Experiments on widely-used databases RAF-DB and FERPlus validate the effectiveness of our method, which achieves state-of-the-art performance with accuracy of 89.57% on RAF-DB. Additionally, when the synthetic noise rate reaches even 30%, the performance of our PT algorithm only degrades by 4.37%.