 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Median Pixel Difference Convolutional Network for Robust Face Recognition
May 30, 2022

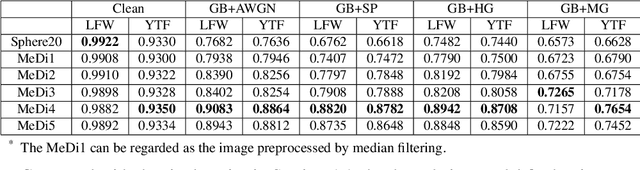
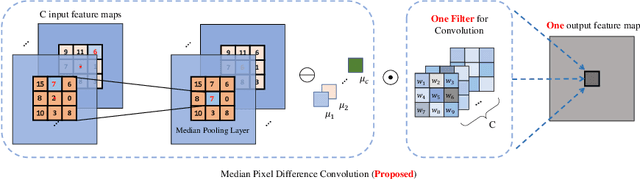
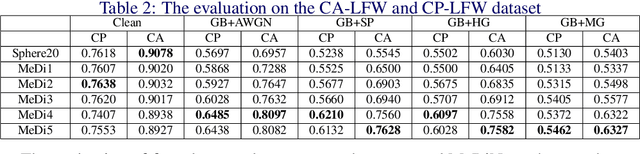
Face recognition is one of the most active tasks in computer vision and has been widely used in the real world. With great advances made in convolutional neural networks (CNN), lots of face recognition algorithms have achieved high accuracy on various face datasets. However, existing face recognition algorithms based on CNNs are vulnerable to noise. Noise corrupted image patterns could lead to false activations, significantly decreasing face recognition accuracy in noisy situations. To equip CNNs with built-in robustness to noise of different levels, we proposed a Median Pixel Difference Convolutional Network (MeDiNet) by replacing some traditional convolutional layers with the proposed novel Median Pixel Difference Convolutional Layer (MeDiConv) layer. The proposed MeDiNet integrates the idea of traditional multiscale median filtering with deep CNNs. The MeDiNet is tested on the four face datasets (LFW, CA-LFW, CP-LFW, and YTF) with versatile settings on blur kernels, noise intensities, scales, and JPEG quality factors. Extensive experiments show that our MeDiNet can effectively remove noisy pixels in the feature map and suppress the negative impact of noise, leading to achieving limited accuracy loss under these practical noises compared with the standard CNN under clean conditions.
A Deep Local and Global Scene-Graph Matching for Image-Text Retrieval
Jun 04, 2021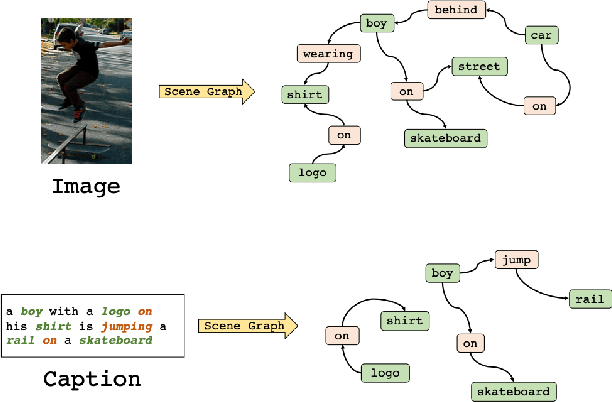
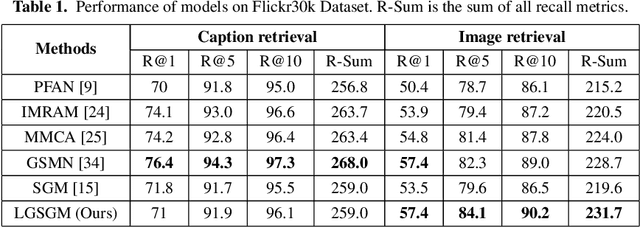
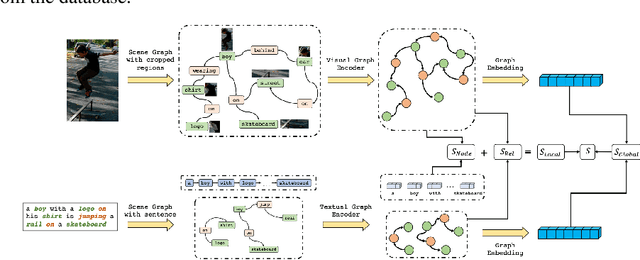
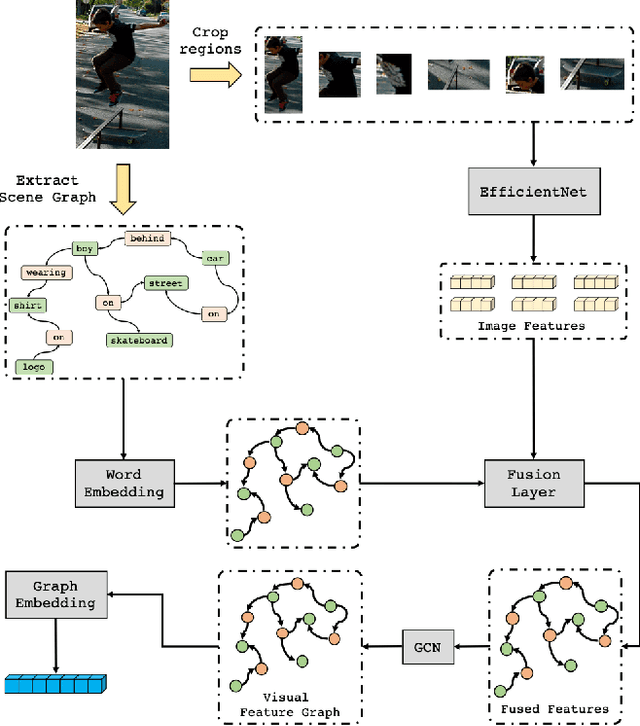
Conventional approaches to image-text retrieval mainly focus on indexing visual objects appearing in pictures but ignore the interactions between these objects. Such objects occurrences and interactions are equivalently useful and important in this field as they are usually mentioned in the text. Scene graph presentation is a suitable method for the image-text matching challenge and obtained good results due to its ability to capture the inter-relationship information. Both images and text are represented in scene graph levels and formulate the retrieval challenge as a scene graph matching challenge. In this paper, we introduce the Local and Global Scene Graph Matching (LGSGM) model that enhances the state-of-the-art method by integrating an extra graph convolution network to capture the general information of a graph. Specifically, for a pair of scene graphs of an image and its caption, two separate models are used to learn the features of each graph's nodes and edges. Then a Siamese-structure graph convolution model is employed to embed graphs into vector forms. We finally combine the graph-level and the vector-level to calculate the similarity of this image-text pair. The empirical experiments show that our enhancement with the combination of levels can improve the performance of the baseline method by increasing the recall by more than 10% on the Flickr30k dataset.
An Object Detection based Solver for Google's Image reCAPTCHA v2
Apr 07, 2021
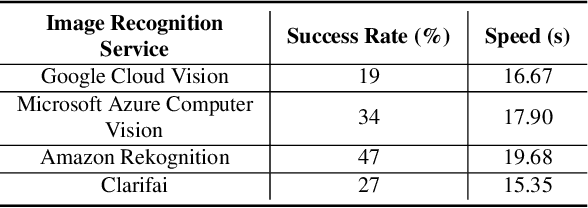
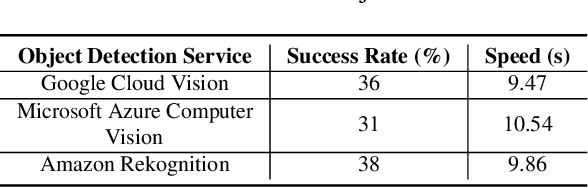
Previous work showed that reCAPTCHA v2's image challenges could be solved by automated programs armed with Deep Neural Network (DNN) image classifiers and vision APIs provided by off-the-shelf image recognition services. In response to emerging threats, Google has made significant updates to its image reCAPTCHA v2 challenges that can render the prior approaches ineffective to a great extent. In this paper, we investigate the robustness of the latest version of reCAPTCHA v2 against advanced object detection based solvers. We propose a fully automated object detection based system that breaks the most advanced challenges of reCAPTCHA v2 with an online success rate of 83.25%, the highest success rate to date, and it takes only 19.93 seconds (including network delays) on average to crack a challenge. We also study the updated security features of reCAPTCHA v2, such as anti-recognition mechanisms, improved anti-bot detection techniques, and adjustable security preferences. Our extensive experiments show that while these security features can provide some resistance against automated attacks, adversaries can still bypass most of them. Our experimental findings indicate that the recent advances in object detection technologies pose a severe threat to the security of image captcha designs relying on simple object detection as their underlying AI problem.
Pyramid Fusion Dark Channel Prior for Single Image Dehazing
May 21, 2021

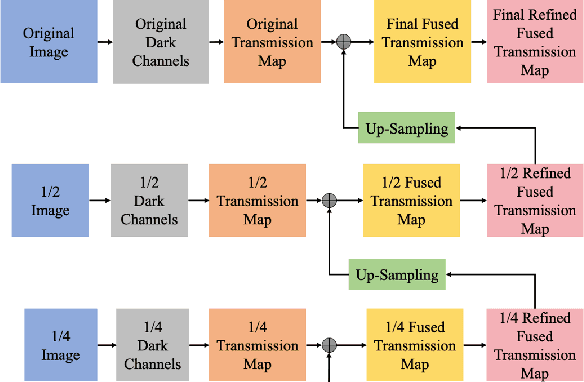
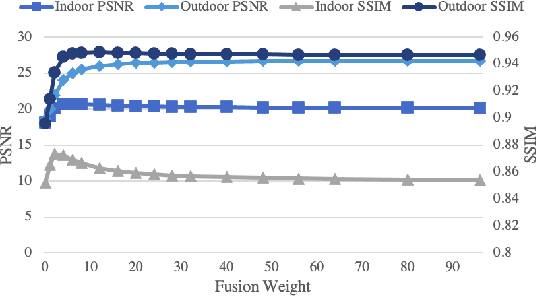
In this paper, we propose the pyramid fusion dark channel prior (PF-DCP) for single image dehazing. Based on the well-known Dark Channel Prior (DCP), we introduce an easy yet effective approach PF-DCP by employing the DCP algorithm at a pyramid of multi-scale images to alleviate the problem of patch size selection. In this case, we obtain the final transmission map by fusing transmission maps at each level to recover a high-quality haze-free image. Experiments on RESIDE SOTS show that PF-DCP not only outperforms the traditional prior-based methods with a large margin but also achieves comparable or even better results of state-of-art deep learning approaches. Furthermore, the visual quality is also greatly improved with much fewer color distortions and halo artifacts.
Region-Adaptive Deformable Network for Image Quality Assessment
Apr 23, 2021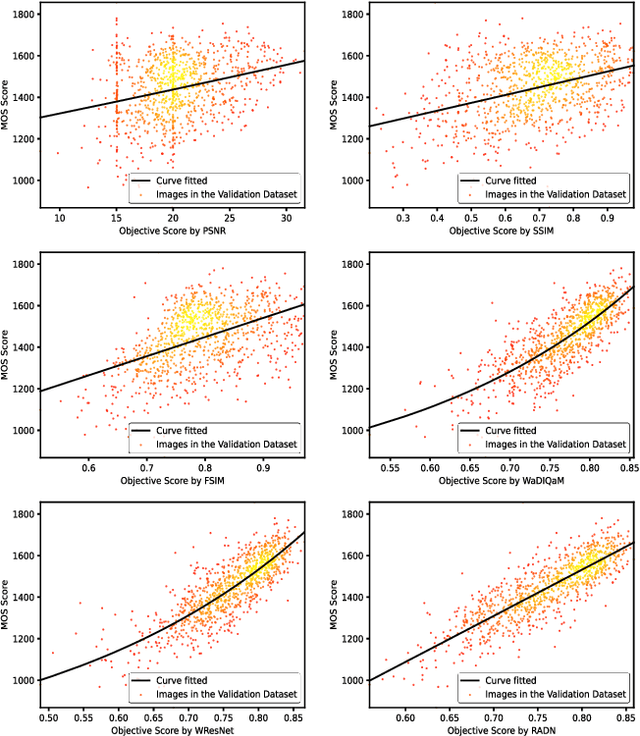
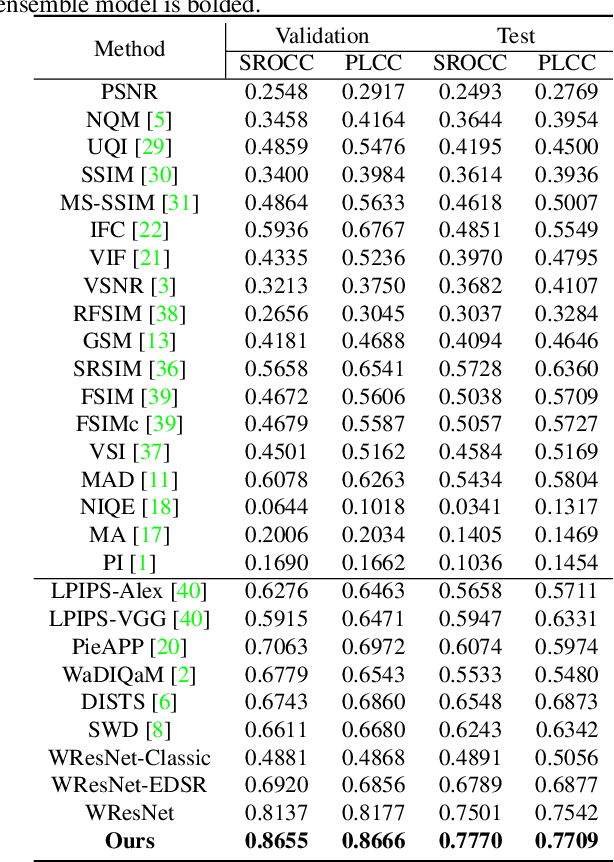
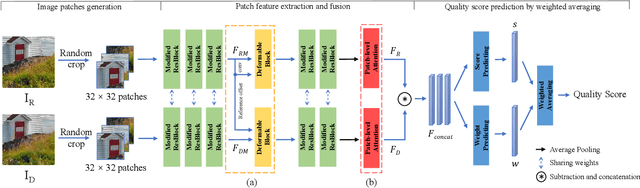
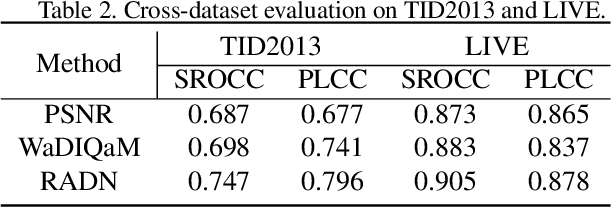
Image quality assessment (IQA) aims to assess the perceptual quality of images. The outputs of the IQA algorithms are expected to be consistent with human subjective perception. In image restoration and enhancement tasks, images generated by generative adversarial networks (GAN) can achieve better visual performance than traditional CNN-generated images, although they have spatial shift and texture noise. Unfortunately, the existing IQA methods have unsatisfactory performance on the GAN-based distortion partially because of their low tolerance to spatial misalignment. To this end, we propose the reference-oriented deformable convolution, which can improve the performance of an IQA network on GAN-based distortion by adaptively considering this misalignment. We further propose a patch-level attention module to enhance the interaction among different patch regions, which are processed independently in previous patch-based methods. The modified residual block is also proposed by applying modifications to the classic residual block to construct a patch-region-based baseline called WResNet. Equipping this baseline with the two proposed modules, we further propose Region-Adaptive Deformable Network (RADN). The experiment results on the NTIRE 2021 Perceptual Image Quality Assessment Challenge dataset show the superior performance of RADN, and the ensemble approach won fourth place in the final testing phase of the challenge. Code is available at https://github.com/IIGROUP/RADN.
What's in your hands? 3D Reconstruction of Generic Objects in Hands
Apr 14, 2022
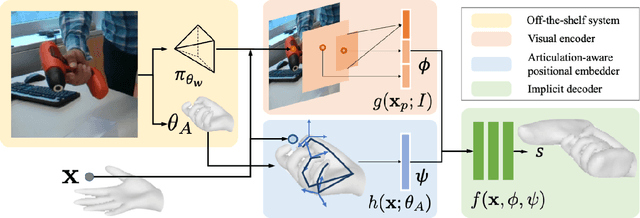

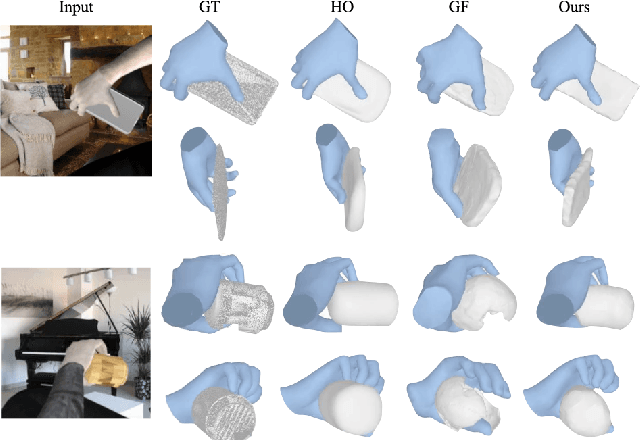
Our work aims to reconstruct hand-held objects given a single RGB image. In contrast to prior works that typically assume known 3D templates and reduce the problem to 3D pose estimation, our work reconstructs generic hand-held object without knowing their 3D templates. Our key insight is that hand articulation is highly predictive of the object shape, and we propose an approach that conditionally reconstructs the object based on the articulation and the visual input. Given an image depicting a hand-held object, we first use off-the-shelf systems to estimate the underlying hand pose and then infer the object shape in a normalized hand-centric coordinate frame. We parameterized the object by signed distance which are inferred by an implicit network which leverages the information from both visual feature and articulation-aware coordinates to process a query point. We perform experiments across three datasets and show that our method consistently outperforms baselines and is able to reconstruct a diverse set of objects. We analyze the benefits and robustness of explicit articulation conditioning and also show that this allows the hand pose estimation to further improve in test-time optimization.
RPLHR-CT Dataset and Transformer Baseline for Volumetric Super-Resolution from CT Scans
Jun 13, 2022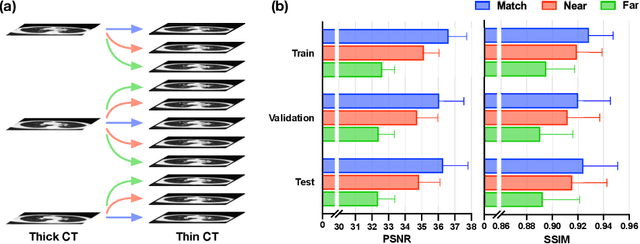
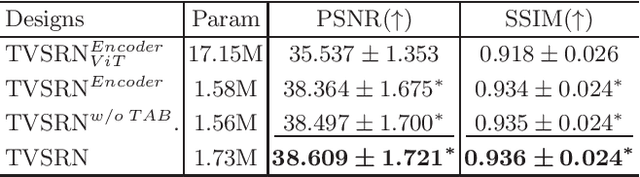
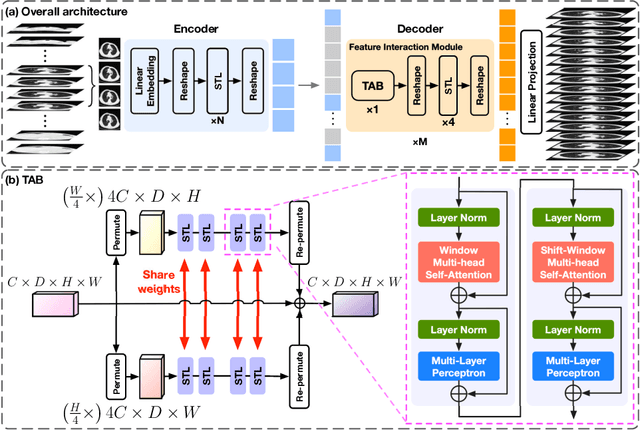
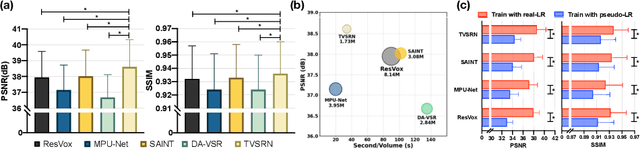
In clinical practice, anisotropic volumetric medical images with low through-plane resolution are commonly used due to short acquisition time and lower storage cost. Nevertheless, the coarse resolution may lead to difficulties in medical diagnosis by either physicians or computer-aided diagnosis algorithms. Deep learning-based volumetric super-resolution (SR) methods are feasible ways to improve resolution, with convolutional neural networks (CNN) at their core. Despite recent progress, these methods are limited by inherent properties of convolution operators, which ignore content relevance and cannot effectively model long-range dependencies. In addition, most of the existing methods use pseudo-paired volumes for training and evaluation, where pseudo low-resolution (LR) volumes are generated by a simple degradation of their high-resolution (HR) counterparts. However, the domain gap between pseudo- and real-LR volumes leads to the poor performance of these methods in practice. In this paper, we build the first public real-paired dataset RPLHR-CT as a benchmark for volumetric SR, and provide baseline results by re-implementing four state-of-the-art CNN-based methods. Considering the inherent shortcoming of CNN, we also propose a transformer volumetric super-resolution network (TVSRN) based on attention mechanisms, dispensing with convolutions entirely. This is the first research to use a pure transformer for CT volumetric SR. The experimental results show that TVSRN significantly outperforms all baselines on both PSNR and SSIM. Moreover, the TVSRN method achieves a better trade-off between the image quality, the number of parameters, and the running time. Data and code are available at https://github.com/smilenaxx/RPLHR-CT.
VizInspect Pro -- Automated Optical Inspection (AOI) solution
May 26, 2022Traditional vision based Automated Optical Inspection (referred to as AOI in paper) systems present multiple challenges in factory settings including inability to scale across multiple product lines, requirement of vendor programming expertise, little tolerance to variations and lack of cloud connectivity for aggregated insights. The lack of flexibility in these systems presents a unique opportunity for a deep learning based AOI system specifically for factory automation. The proposed solution, VizInspect pro is a generic computer vision based AOI solution built on top of Leo - An edge AI platform. Innovative features that overcome challenges of traditional vision systems include deep learning based image analysis which combines the power of self-learning with high speed and accuracy, an intuitive user interface to configure inspection profiles in minutes without ML or vision expertise and the ability to solve complex inspection challenges while being tolerant to deviations and unpredictable defects. This solution has been validated by multiple external enterprise customers with confirmed value propositions. In this paper we show you how this solution and platform solved problems around model development, deployment, scaling multiple inferences and visualizations.
TarGAN: Target-Aware Generative Adversarial Networks for Multi-modality Medical Image Translation
May 19, 2021
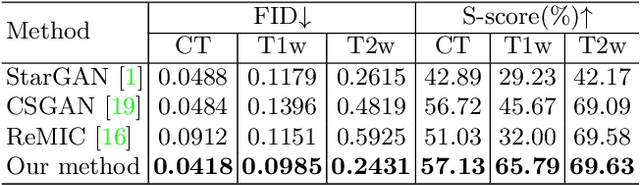
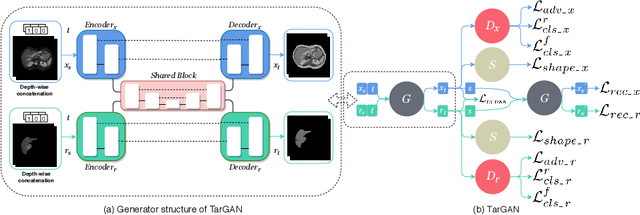
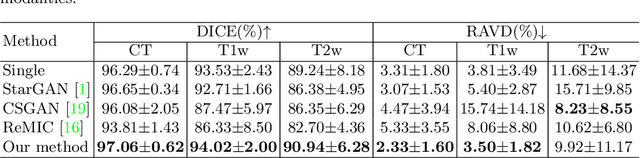
Paired multi-modality medical images, can provide complementary information to help physicians make more reasonable decisions than single modality medical images. But they are difficult to generate due to multiple factors in practice (e.g., time, cost, radiation dose). To address these problems, multi-modality medical image translation has aroused increasing research interest recently. However, the existing works mainly focus on translation effect of a whole image instead of a critical target area or Region of Interest (ROI), e.g., organ and so on. This leads to poor-quality translation of the localized target area which becomes blurry, deformed or even with extra unreasonable textures. In this paper, we propose a novel target-aware generative adversarial network called TarGAN, which is a generic multi-modality medical image translation model capable of (1) learning multi-modality medical image translation without relying on paired data, (2) enhancing quality of target area generation with the help of target area labels. The generator of TarGAN jointly learns mapping at two levels simultaneously - whole image translation mapping and target area translation mapping. These two mappings are interrelated through a proposed crossing loss. The experiments on both quantitative measures and qualitative evaluations demonstrate that TarGAN outperforms the state-of-the-art methods in all cases. Subsequent segmentation task is conducted to demonstrate effectiveness of synthetic images generated by TarGAN in a real-world application. Our code is available at https://github.com/2165998/TarGAN.
MetaLR: Layer-wise Learning Rate based on Meta-Learning for Adaptively Fine-tuning Medical Pre-trained Models
Jun 03, 2022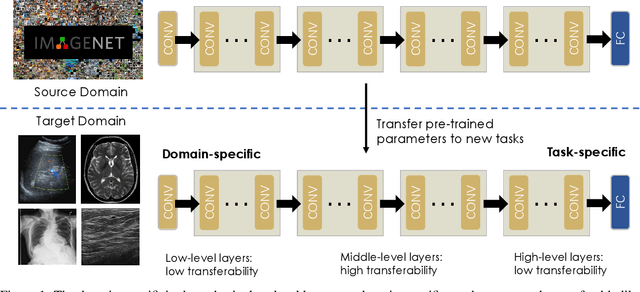

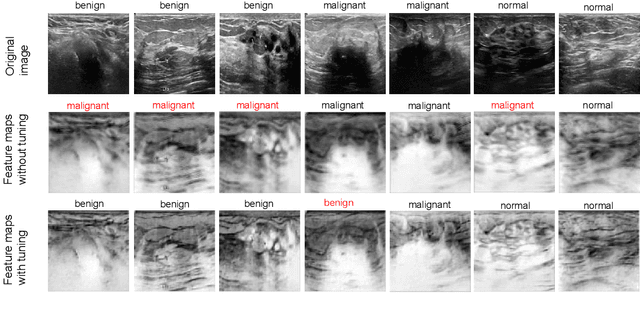
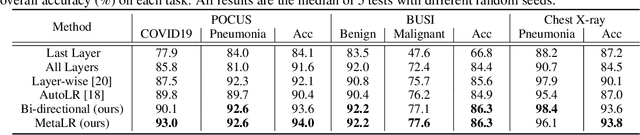
When applying transfer learning for medical image analysis, downstream tasks often have significant gaps with the pre-training tasks. Previous methods mainly focus on improving the transferabilities of the pre-trained models to bridge the gaps. In fact, model fine-tuning can also play a very important role in tackling this problem. A conventional fine-tuning method is updating all deep neural networks (DNNs) layers by a single learning rate (LR), which ignores the unique transferabilities of different layers. In this work, we explore the behaviors of different layers in the fine-tuning stage. More precisely, we first hypothesize that lower-level layers are more domain-specific while higher-level layers are more task-specific, which is verified by a simple bi-directional fine-tuning scheme. It is harder for the pre-trained specific layers to transfer to new tasks than general layers. On this basis, to make different layers better co-adapt to the downstream tasks according to their transferabilities, a meta-learning-based LR learner, namely MetaLR, is proposed to assign LRs for each layer automatically. Extensive experiments on various medical applications (i.e., POCUS, BUSI, Chest X-ray, and LiTS) well confirm our hypothesis and show the superior performance of the proposed methods to previous state-of-the-art fine-tuning methods.