 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Effective Message Hiding with Order-Preserving Mechanisms
Feb 29, 2024
Message hiding, a technique that conceals secret message bits within a cover image, aims to achieve an optimal balance among message capacity, recovery accuracy, and imperceptibility. While convolutional neural networks have notably improved message capacity and imperceptibility, achieving high recovery accuracy remains challenging. This challenge arises because convolutional operations struggle to preserve the sequential order of message bits and effectively address the discrepancy between these two modalities. To address this, we propose StegaFormer, an innovative MLP-based framework designed to preserve bit order and enable global fusion between modalities. Specifically, StegaFormer incorporates three crucial components: Order-Preserving Message Encoder (OPME), Decoder (OPMD) and Global Message-Image Fusion (GMIF). OPME and OPMD aim to preserve the order of message bits by segmenting the entire sequence into equal-length segments and incorporating sequential information during encoding and decoding. Meanwhile, GMIF employs a cross-modality fusion mechanism to effectively fuse the features from the two uncorrelated modalities. Experimental results on the COCO and DIV2K datasets demonstrate that StegaFormer surpasses existing state-of-the-art methods in terms of recovery accuracy, message capacity, and imperceptibility. We will make our code publicly available.
DiffuseKronA: A Parameter Efficient Fine-tuning Method for Personalized Diffusion Models
Feb 28, 2024In the realm of subject-driven text-to-image (T2I) generative models, recent developments like DreamBooth and BLIP-Diffusion have led to impressive results yet encounter limitations due to their intensive fine-tuning demands and substantial parameter requirements. While the low-rank adaptation (LoRA) module within DreamBooth offers a reduction in trainable parameters, it introduces a pronounced sensitivity to hyperparameters, leading to a compromise between parameter efficiency and the quality of T2I personalized image synthesis. Addressing these constraints, we introduce \textbf{\textit{DiffuseKronA}}, a novel Kronecker product-based adaptation module that not only significantly reduces the parameter count by 35\% and 99.947\% compared to LoRA-DreamBooth and the original DreamBooth, respectively, but also enhances the quality of image synthesis. Crucially, \textit{DiffuseKronA} mitigates the issue of hyperparameter sensitivity, delivering consistent high-quality generations across a wide range of hyperparameters, thereby diminishing the necessity for extensive fine-tuning. Furthermore, a more controllable decomposition makes \textit{DiffuseKronA} more interpretable and even can achieve up to a 50\% reduction with results comparable to LoRA-Dreambooth. Evaluated against diverse and complex input images and text prompts, \textit{DiffuseKronA} consistently outperforms existing models, producing diverse images of higher quality with improved fidelity and a more accurate color distribution of objects, all the while upholding exceptional parameter efficiency, thus presenting a substantial advancement in the field of T2I generative modeling. Our project page, consisting of links to the code, and pre-trained checkpoints, is available at https://diffusekrona.github.io/.
Saliency-aware End-to-end Learned Variable-Bitrate 360-degree Image Compression
Feb 14, 2024Effective compression of 360$^\circ$ images, also referred to as omnidirectional images (ODIs), is of high interest for various virtual reality (VR) and related applications. 2D image compression methods ignore the equator-biased nature of ODIs and fail to address oversampling near the poles, leading to inefficient compression when applied to ODI. We present a new learned saliency-aware 360$^\circ$ image compression architecture that prioritizes bit allocation to more significant regions, considering the unique properties of ODIs. By assigning fewer bits to less important regions, significant data size reduction can be achieved while maintaining high visual quality in the significant regions. To the best of our knowledge, this is the first study that proposes an end-to-end variable-rate model to compress 360$^\circ$ images leveraging saliency information. The results show significant bit-rate savings over the state-of-the-art learned and traditional ODI compression methods at similar perceptual visual quality.
Self-Supervised Learning in Electron Microscopy: Towards a Foundation Model for Advanced Image Analysis
Feb 28, 2024In this work, we explore the potential of self-supervised learning from unlabeled electron microscopy datasets, taking a step toward building a foundation model in this field. We show how self-supervised pretraining facilitates efficient fine-tuning for a spectrum of downstream tasks, including semantic segmentation, denoising, noise & background removal, and super-resolution. Experimentation with varying model complexities and receptive field sizes reveals the remarkable phenomenon that fine-tuned models of lower complexity consistently outperform more complex models with random weight initialization. We demonstrate the versatility of self-supervised pretraining across various downstream tasks in the context of electron microscopy, allowing faster convergence and better performance. We conclude that self-supervised pretraining serves as a powerful catalyst, being especially advantageous when limited annotated data are available and efficient scaling of computational cost are important.
Image captioning for Brazilian Portuguese using GRIT model
Feb 07, 2024This work presents the early development of a model of image captioning for the Brazilian Portuguese language. We used the GRIT (Grid - and Region-based Image captioning Transformer) model to accomplish this work. GRIT is a Transformer-only neural architecture that effectively utilizes two visual features to generate better captions. The GRIT method emerged as a proposal to be a more efficient way to generate image captioning. In this work, we adapt the GRIT model to be trained in a Brazilian Portuguese dataset to have an image captioning method for the Brazilian Portuguese Language.
Captions Are Worth a Thousand Words: Enhancing Product Retrieval with Pretrained Image-to-Text Models
Feb 13, 2024This paper explores the usage of multimodal image-to-text models to enhance text-based item retrieval. We propose utilizing pre-trained image captioning and tagging models, such as instructBLIP and CLIP, to generate text-based product descriptions which are combined with existing text descriptions. Our work is particularly impactful for smaller eCommerce businesses who are unable to maintain the high-quality text descriptions necessary to effectively perform item retrieval for search and recommendation use cases. We evaluate the searchability of ground-truth text, image-generated text, and combinations of both texts on several subsets of Amazon's publicly available ESCI dataset. The results demonstrate the dual capability of our proposed models to enhance the retrieval of existing text and generate highly-searchable standalone descriptions.
Can a Confident Prior Replace a Cold Posterior?
Mar 02, 2024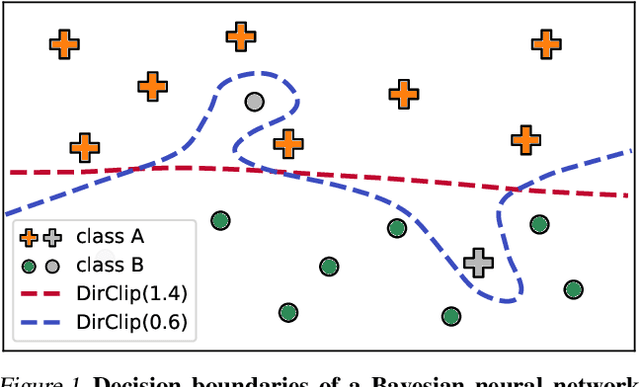
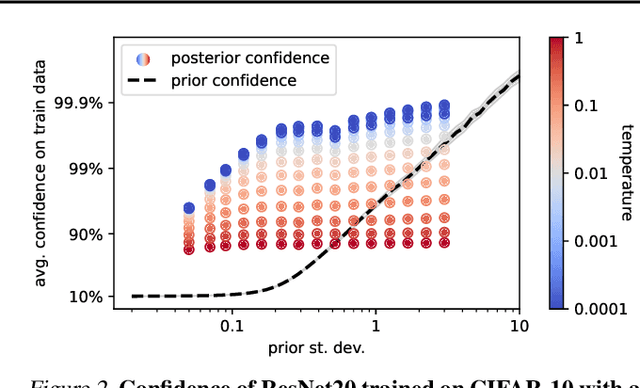
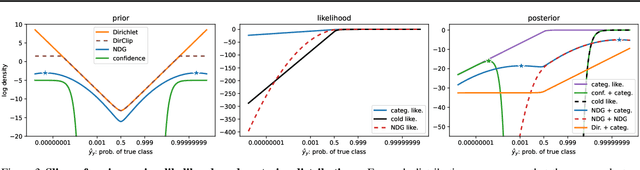
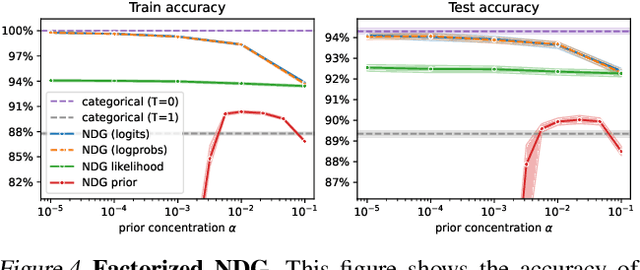
Benchmark datasets used for image classification tend to have very low levels of label noise. When Bayesian neural networks are trained on these datasets, they often underfit, misrepresenting the aleatoric uncertainty of the data. A common solution is to cool the posterior, which improves fit to the training data but is challenging to interpret from a Bayesian perspective. We explore whether posterior tempering can be replaced by a confidence-inducing prior distribution. First, we introduce a "DirClip" prior that is practical to sample and nearly matches the performance of a cold posterior. Second, we introduce a "confidence prior" that directly approximates a cold likelihood in the limit of decreasing temperature but cannot be easily sampled. Lastly, we provide several general insights into confidence-inducing priors, such as when they might diverge and how fine-tuning can mitigate numerical instability.
Minecraft-ify: Minecraft Style Image Generation with Text-guided Image Editing for In-Game Application
Feb 08, 2024In this paper, we first present the character texture generation system \textit{Minecraft-ify}, specified to Minecraft video game toward in-game application. Ours can generate face-focused image for texture mapping tailored to 3D virtual character having cube manifold. While existing projects or works only generate texture, proposed system can inverse the user-provided real image, or generate average/random appearance from learned distribution. Moreover, it can be manipulated with text-guidance using StyleGAN and StyleCLIP. These features provide a more extended user experience with enlarged freedom as a user-friendly AI-tool. Project page can be found at https://gh-bumsookim.github.io/Minecraft-ify/
Machine Unlearning for Image-to-Image Generative Models
Feb 02, 2024Machine unlearning has emerged as a new paradigm to deliberately forget data samples from a given model in order to adhere to stringent regulations. However, existing machine unlearning methods have been primarily focused on classification models, leaving the landscape of unlearning for generative models relatively unexplored. This paper serves as a bridge, addressing the gap by providing a unifying framework of machine unlearning for image-to-image generative models. Within this framework, we propose a computationally-efficient algorithm, underpinned by rigorous theoretical analysis, that demonstrates negligible performance degradation on the retain samples, while effectively removing the information from the forget samples. Empirical studies on two large-scale datasets, ImageNet-1K and Places-365, further show that our algorithm does not rely on the availability of the retain samples, which further complies with data retention policy. To our best knowledge, this work is the first that represents systemic, theoretical, empirical explorations of machine unlearning specifically tailored for image-to-image generative models. Our code is available at https://github.com/jpmorganchase/l2l-generator-unlearning.
Vision Language Model-based Caption Evaluation Method Leveraging Visual Context Extraction
Feb 28, 2024Given the accelerating progress of vision and language modeling, accurate evaluation of machine-generated image captions remains critical. In order to evaluate captions more closely to human preferences, metrics need to discriminate between captions of varying quality and content. However, conventional metrics fail short of comparing beyond superficial matches of words or embedding similarities; thus, they still need improvement. This paper presents VisCE$^2$, a vision language model-based caption evaluation method. Our method focuses on visual context, which refers to the detailed content of images, including objects, attributes, and relationships. By extracting and organizing them into a structured format, we replace the human-written references with visual contexts and help VLMs better understand the image, enhancing evaluation performance. Through meta-evaluation on multiple datasets, we validated that VisCE$^2$ outperforms the conventional pre-trained metrics in capturing caption quality and demonstrates superior consistency with human judgment.