 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VNT-Net: Rotational Invariant Vector Neuron Transformers
May 25, 2022

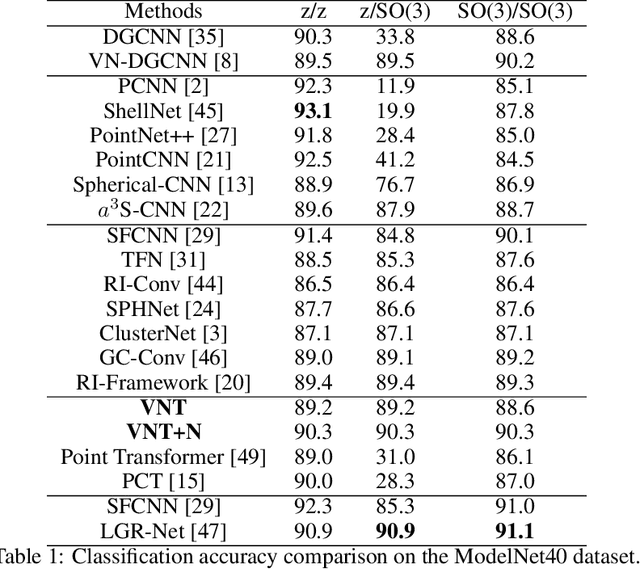
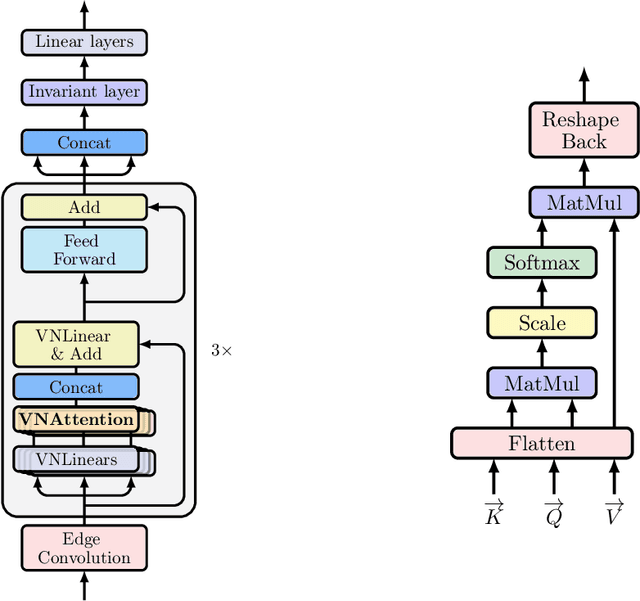
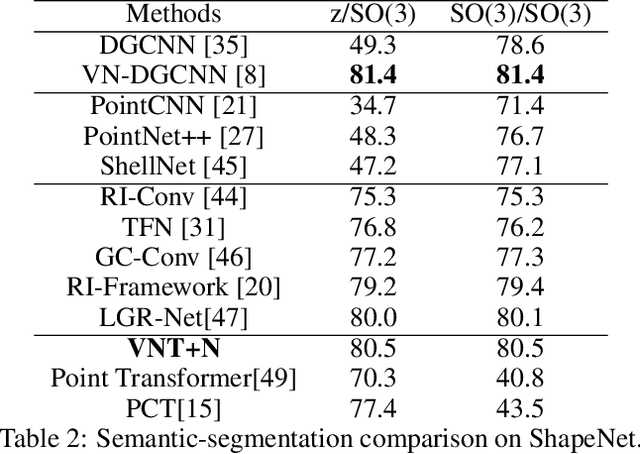
Learning 3D point sets with rotational invariance is an important and challenging problem in machine learning. Through rotational invariant architectures, 3D point cloud neural networks are relieved from requiring a canonical global pose and from exhaustive data augmentation with all possible rotations. In this work, we introduce a rotational invariant neural network by combining recently introduced vector neurons with self-attention layers to build a point cloud vector neuron transformer network (VNT-Net). Vector neurons are known for their simplicity and versatility in representing SO(3) actions and are thereby incorporated in common neural operations. Similarly, Transformer architectures have gained popularity and recently were shown successful for images by applying directly on sequences of image patches and achieving superior performance and convergence. In order to benefit from both worlds, we combine the two structures by mainly showing how to adapt the multi-headed attention layers to comply with vector neurons operations. Through this adaptation attention layers become SO(3) and the overall network becomes rotational invariant. Experiments demonstrate that our network efficiently handles 3D point cloud objects in arbitrary poses. We also show that our network achieves higher accuracy when compared to related state-of-the-art methods and requires less training due to a smaller number of hyperparameters in common classification and segmentation tasks.
Global Contrast Masked Autoencoders Are Powerful Pathological Representation Learners
May 21, 2022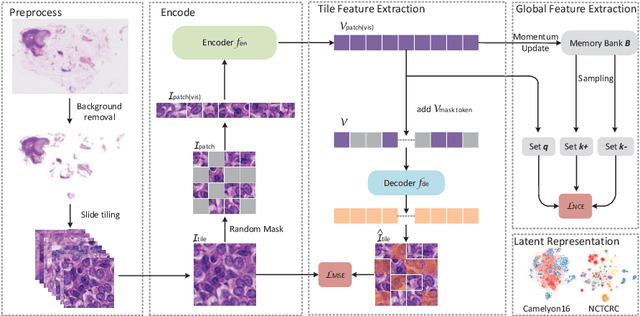
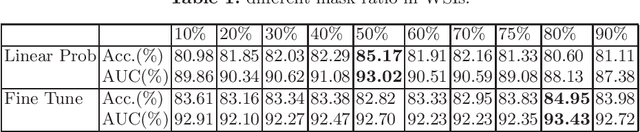

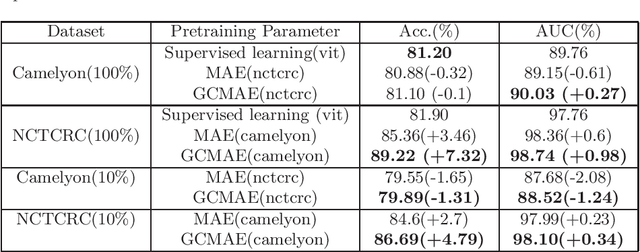
Based on digital whole slide scanning technique, artificial intelligence algorithms represented by deep learning have achieved remarkable results in the field of computational pathology. Compared with other medical images such as Computed Tomography (CT) or Magnetic Resonance Imaging (MRI), pathological images are more difficult to annotate, thus there is an extreme lack of data sets that can be used for supervised learning. In this study, a self-supervised learning (SSL) model, Global Contrast Masked Autoencoders (GCMAE), is proposed, which has the ability to represent both global and local domain-specific features of whole slide image (WSI), as well as excellent cross-data transfer ability. The Camelyon16 and NCTCRC datasets are used to evaluate the performance of our model. When dealing with transfer learning tasks with different data sets, the experimental results show that GCMAE has better linear classification accuracy than MAE, which can reach 81.10% and 89.22% respectively. Our method outperforms the previous state-of-the-art algorithm and even surpass supervised learning (improved by 3.86% on NCTCRC data sets). The source code of this paper is publicly available at https://github.com/StarUniversus/gcmae
Multimodal Dual Emotion with Fusion of Visual Sentiment for Rumor Detection
Apr 25, 2022
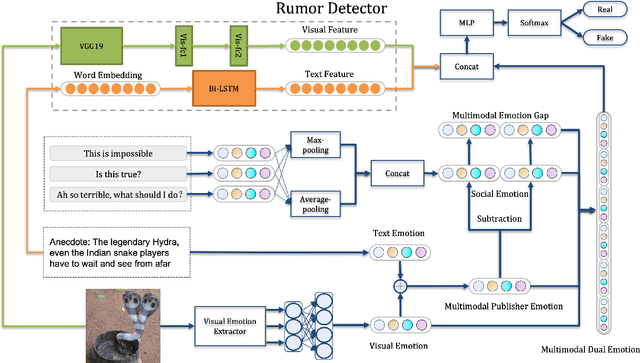
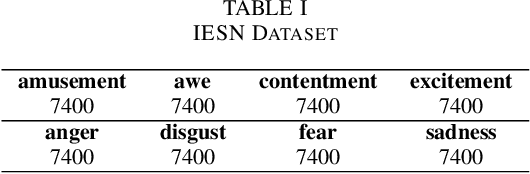
In recent years, rumors have had a devastating impact on society, making rumor detection a significant challenge. However, the studies on rumor detection ignore the intense emotions of images in the rumor content. This paper verifies that the image emotion improves the rumor detection efficiency. A Multimodal Dual Emotion feature in rumor detection, which consists of visual and textual emotions, is proposed. To the best of our knowledge, this is the first study which uses visual emotion in rumor detection. The experiments on real datasets verify that the proposed features outperform the state-of-the-art sentiment features, and can be extended in rumor detectors while improving their performance.
User-Guided Personalized Image Aesthetic Assessment based on Deep Reinforcement Learning
Jun 14, 2021
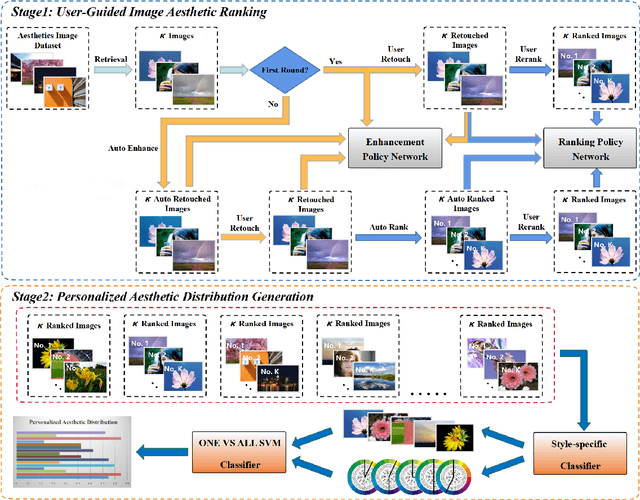
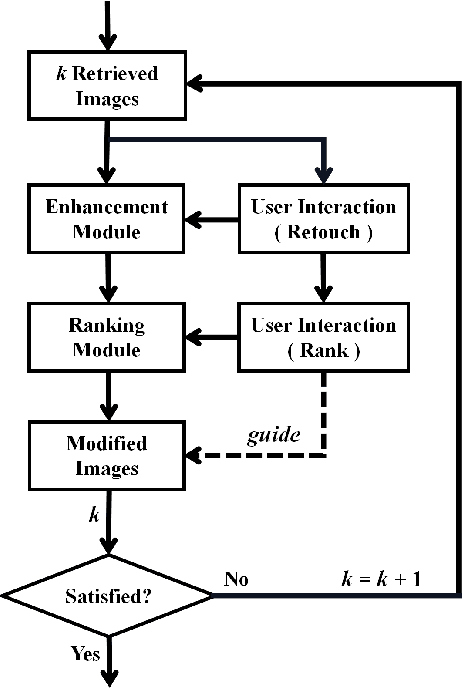
Personalized image aesthetic assessment (PIAA) has recently become a hot topic due to its usefulness in a wide variety of applications such as photography, film and television, e-commerce, fashion design and so on. This task is more seriously affected by subjective factors and samples provided by users. In order to acquire precise personalized aesthetic distribution by small amount of samples, we propose a novel user-guided personalized image aesthetic assessment framework. This framework leverages user interactions to retouch and rank images for aesthetic assessment based on deep reinforcement learning (DRL), and generates personalized aesthetic distribution that is more in line with the aesthetic preferences of different users. It mainly consists of two stages. In the first stage, personalized aesthetic ranking is generated by interactive image enhancement and manual ranking, meanwhile two policy networks will be trained. The images will be pushed to the user for manual retouching and simultaneously to the enhancement policy network. The enhancement network utilizes the manual retouching results as the optimization goals of DRL. After that, the ranking process performs the similar operations like the retouching mentioned before. These two networks will be trained iteratively and alternatively to help to complete the final personalized aesthetic assessment automatically. In the second stage, these modified images are labeled with aesthetic attributes by one style-specific classifier, and then the personalized aesthetic distribution is generated based on the multiple aesthetic attributes of these images, which conforms to the aesthetic preference of users better.
muNet: Evolving Pretrained Deep Neural Networks into Scalable Auto-tuning Multitask Systems
May 25, 2022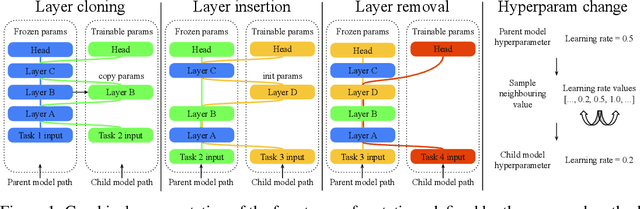
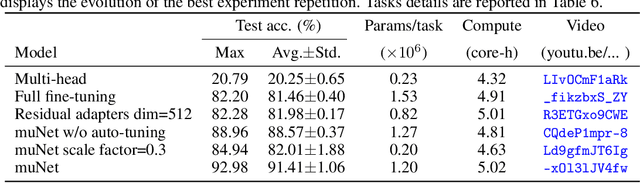
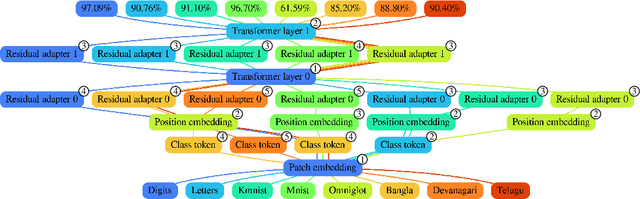
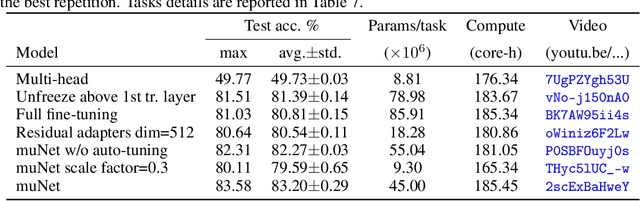
Most uses of machine learning today involve training a model from scratch for a particular task, or sometimes starting with a model pretrained on a related task and then fine-tuning on a downstream task. Both approaches offer limited knowledge transfer between different tasks, time-consuming human-driven customization to individual tasks and high computational costs especially when starting from randomly initialized models. We propose a method that uses the layers of a pretrained deep neural network as building blocks to construct an ML system that can jointly solve an arbitrary number of tasks. The resulting system can leverage cross tasks knowledge transfer, while being immune from common drawbacks of multitask approaches such as catastrophic forgetting, gradients interference and negative transfer. We define an evolutionary approach designed to jointly select the prior knowledge relevant for each task, choose the subset of the model parameters to train and dynamically auto-tune its hyperparameters. Furthermore, a novel scale control method is employed to achieve quality/size trade-offs that outperform common fine-tuning techniques. Compared with standard fine-tuning on a benchmark of 10 diverse image classification tasks, the proposed model improves the average accuracy by 2.39% while using 47% less parameters per task.
A Linear Comb Filter for Event Flicker Removal
May 17, 2022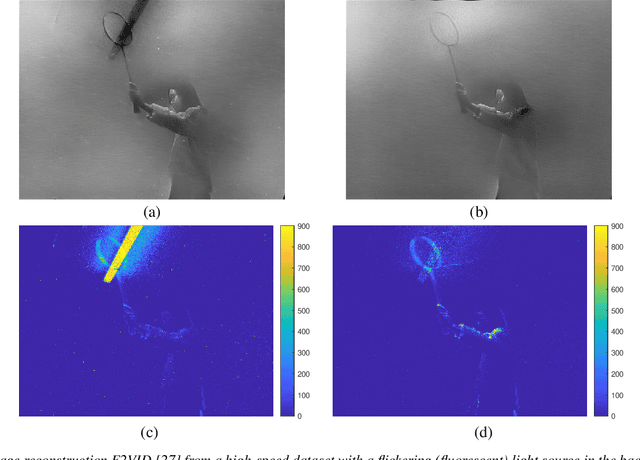
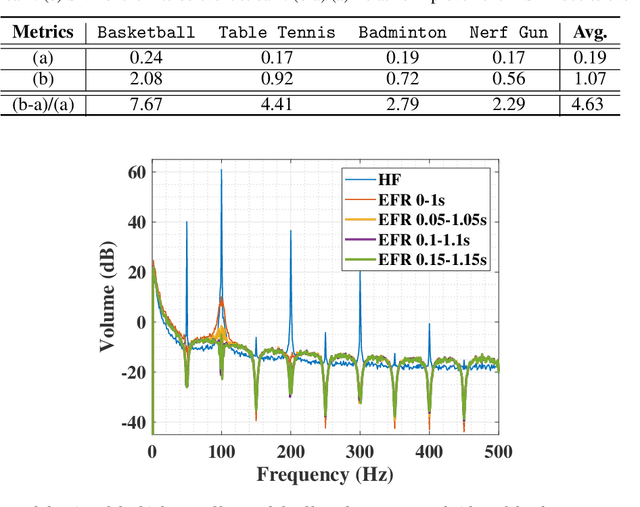
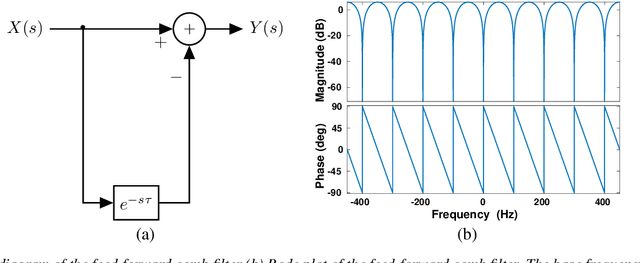
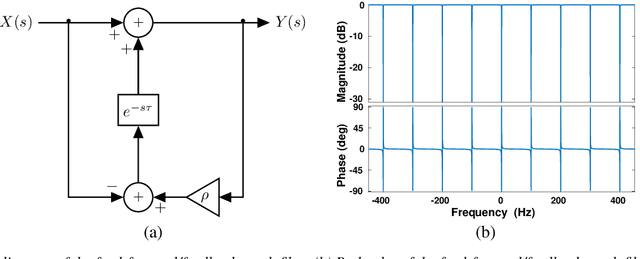
Event cameras are bio-inspired sensors that capture per-pixel asynchronous intensity change rather than the synchronous absolute intensity frames captured by a classical camera sensor. Such cameras are ideal for robotics applications since they have high temporal resolution, high dynamic range and low latency. However, due to their high temporal resolution, event cameras are particularly sensitive to flicker such as from fluorescent or LED lights. During every cycle from bright to dark, pixels that image a flickering light source generate many events that provide little or no useful information for a robot, swamping the useful data in the scene. In this paper, we propose a novel linear filter to preprocess event data to remove unwanted flicker events from an event stream. The proposed algorithm achieves over 4.6 times relative improvement in the signal-to-noise ratio when compared to the raw event stream due to the effective removal of flicker from fluorescent lighting. Thus, it is ideally suited to robotics applications that operate in indoor settings or scenes illuminated by flickering light sources.
An Embedded System for Image-based Crack Detection by using Fine-Tuning model of Adaptive Structural Learning of Deep Belief Network
Oct 25, 2021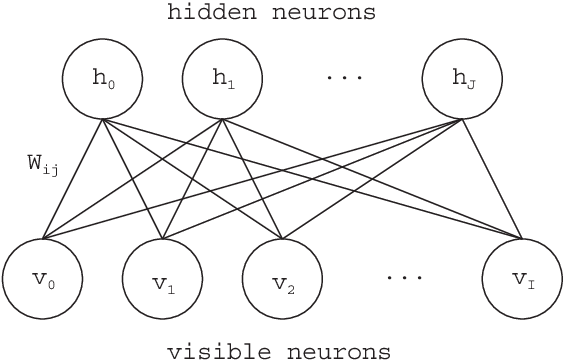
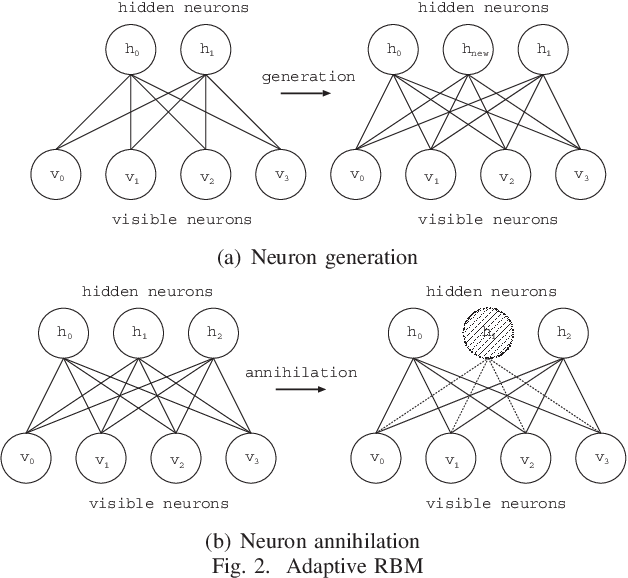
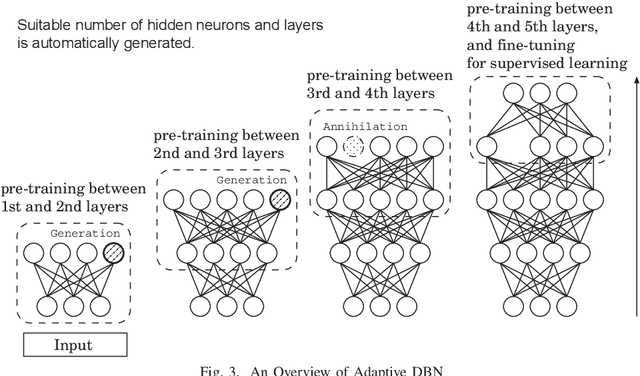

Deep learning has been a successful model which can effectively represent several features of input space and remarkably improve image recognition performance on the deep architectures. In our research, an adaptive structural learning method of Restricted Boltzmann Machine (Adaptive RBM) and Deep Belief Network (Adaptive DBN) have been developed as a deep learning model. The models have a self-organize function which can discover an optimal number of hidden neurons for given input data in a RBM by neuron generation-annihilation algorithm, and can obtain an appropriate number of RBM as hidden layers in the trained DBN. The proposed method was applied to a concrete image benchmark data set SDNET 2018 for crack detection. The dataset contains about 56,000 crack images for three types of concrete structures: bridge decks, walls, and paved roads. The fine-tuning method of the Adaptive DBN can show 99.7%, 99.7%, and 99.4% classification accuracy for test dataset of three types of structures. In this paper, our developed Adaptive DBN was embedded to a tiny PC with GPU for real-time inference on a drone. For fast inference, the fine tuning algorithm also removed some inactivated hidden neurons to make a small model and then the model was able to improve not only classification accuracy but also inference speed simultaneously. The inference speed and running time of portable battery charger were evaluated on three kinds of Nvidia embedded systems; Jetson Nano, AGX Xavier, and Xavier NX.
Empirical Analysis of Image Caption Generation using Deep Learning
May 14, 2021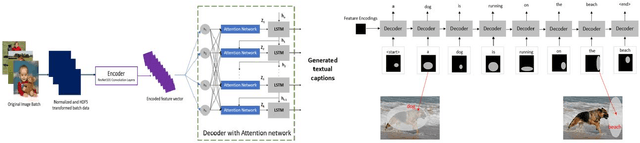
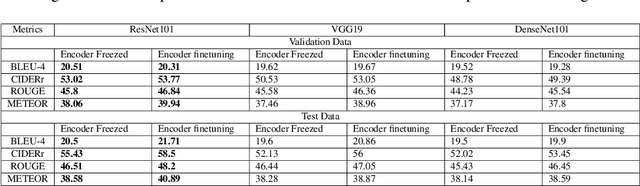

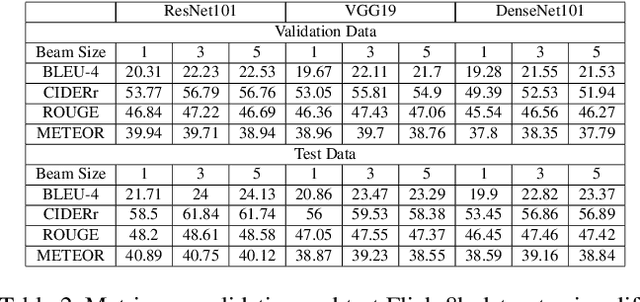
Automated image captioning is one of the applications of Deep Learning which involves fusion of work done in computer vision and natural language processing, and it is typically performed using Encoder-Decoder architectures. In this project, we have implemented and experimented with various flavors of multi-modal image captioning networks where ResNet101, DenseNet121 and VGG19 based CNN Encoders and Attention based LSTM Decoders were explored. We have studied the effect of beam size and the use of pretrained word embeddings and compared them to baseline CNN encoder and RNN decoder architecture. The goal is to analyze the performance of each approach using various evaluation metrics including BLEU, CIDEr, ROUGE and METEOR. We have also explored model explainability using Visual Attention Maps (VAM) to highlight parts of the images which has maximum contribution for predicting each word of the generated caption.
Self-Supervised Representation Learning as Multimodal Variational Inference
Mar 22, 2022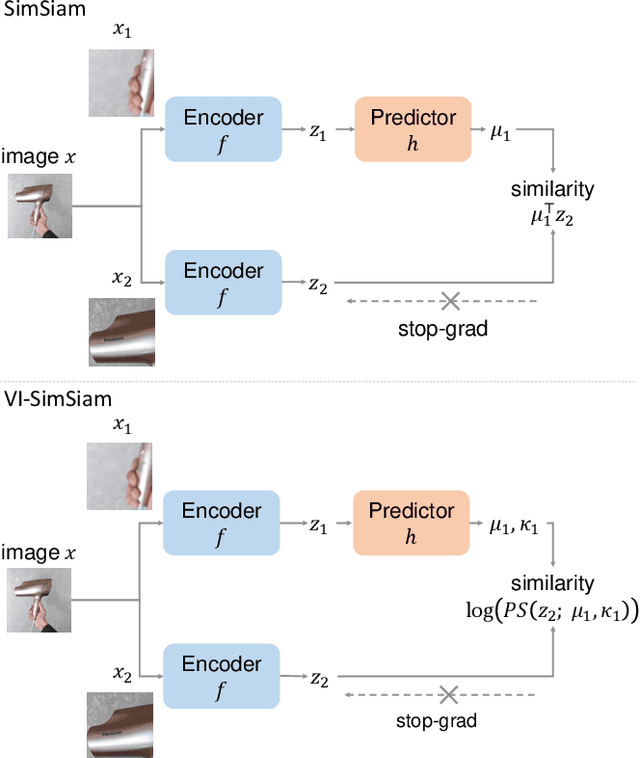

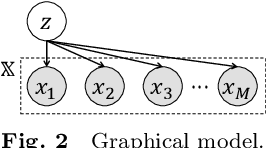
This paper proposes a probabilistic extension of SimSiam, a recent self-supervised learning (SSL) method. SimSiam trains a model by maximizing the similarity between image representations of different augmented views of the same image. Although uncertainty-aware machine learning has been getting general like deep variational inference, SimSiam and other SSL are insufficiently uncertainty-aware, which could lead to limitations on its potential. The proposed extension is to make SimSiam uncertainty-aware based on variational inference. Our main contributions are twofold: Firstly, we clarify the theoretical relationship between non-contrastive SSL and multimodal variational inference. Secondly, we introduce a novel SSL called variational inference SimSiam (VI-SimSiam), which incorporates the uncertainty by involving spherical posterior distributions. Our experiment shows that VI-SimSiam outperforms SimSiam in classification tasks in ImageNette and ImageWoof by successfully estimating the representation uncertainty.
Trash or Treasure? An Interactive Dual-Stream Strategy for Single Image Reflection Separation
Oct 20, 2021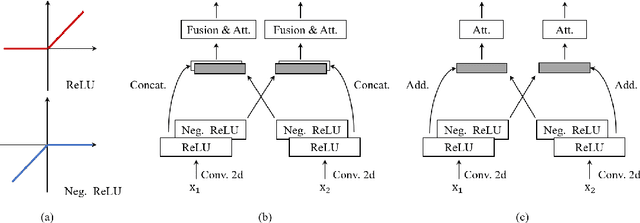
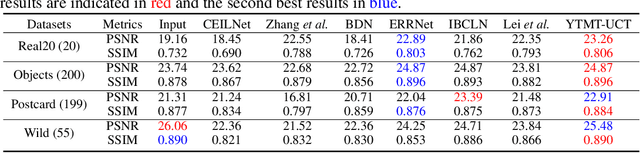
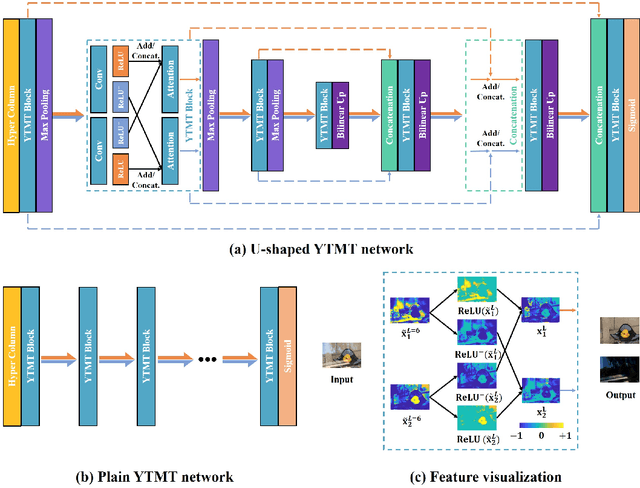
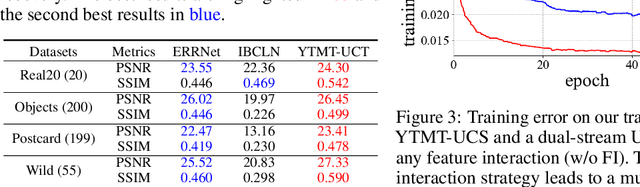
Single image reflection separation (SIRS), as a representative blind source separation task, aims to recover two layers, $\textit{i.e.}$, transmission and reflection, from one mixed observation, which is challenging due to the highly ill-posed nature. Existing deep learning based solutions typically restore the target layers individually, or with some concerns at the end of the output, barely taking into account the interaction across the two streams/branches. In order to utilize information more efficiently, this work presents a general yet simple interactive strategy, namely $\textit{your trash is my treasure}$ (YTMT), for constructing dual-stream decomposition networks. To be specific, we explicitly enforce the two streams to communicate with each other block-wisely. Inspired by the additive property between the two components, the interactive path can be easily built via transferring, instead of discarding, deactivated information by the ReLU rectifier from one stream to the other. Both ablation studies and experimental results on widely-used SIRS datasets are conducted to demonstrate the efficacy of YTMT, and reveal its superiority over other state-of-the-art alternatives. The implementation is quite simple and our code is publicly available at $\href{https://github.com/mingcv/YTMT-Strategy}{\textit{https://github.com/mingcv/YTMT-Strategy}}$.