 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Psychologically-Inspired, Unsupervised Inference of Perceptual Groups of GUI Widgets from GUI Images
Jun 15, 2022
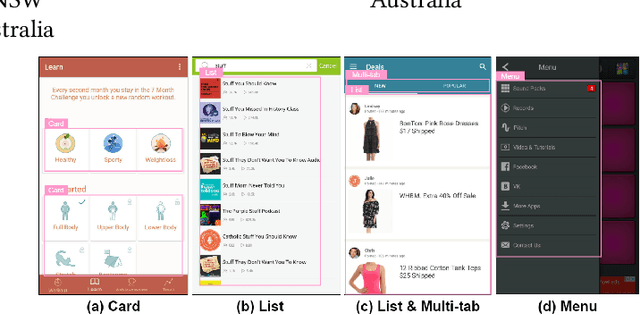
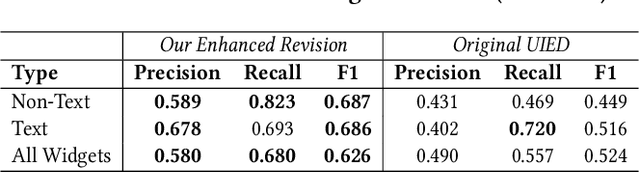
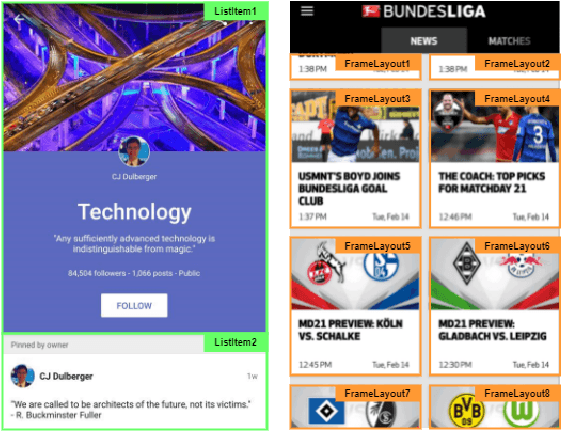
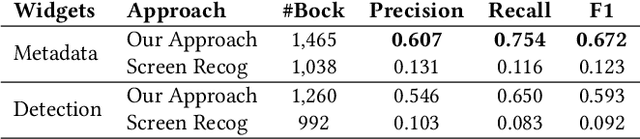
Graphical User Interface (GUI) is not merely a collection of individual and unrelated widgets, but rather partitions discrete widgets into groups by various visual cues, thus forming higher-order perceptual units such as tab, menu, card or list. The ability to automatically segment a GUI into perceptual groups of widgets constitutes a fundamental component of visual intelligence to automate GUI design, implementation and automation tasks. Although humans can partition a GUI into meaningful perceptual groups of widgets in a highly reliable way, perceptual grouping is still an open challenge for computational approaches. Existing methods rely on ad-hoc heuristics or supervised machine learning that is dependent on specific GUI implementations and runtime information. Research in psychology and biological vision has formulated a set of principles (i.e., Gestalt theory of perception) that describe how humans group elements in visual scenes based on visual cues like connectivity, similarity, proximity and continuity. These principles are domain-independent and have been widely adopted by practitioners to structure content on GUIs to improve aesthetic pleasant and usability. Inspired by these principles, we present a novel unsupervised image-based method for inferring perceptual groups of GUI widgets. Our method requires only GUI pixel images, is independent of GUI implementation, and does not require any training data. The evaluation on a dataset of 1,091 GUIs collected from 772 mobile apps and 20 UI design mockups shows that our method significantly outperforms the state-of-the-art ad-hoc heuristics-based baseline. Our perceptual grouping method creates the opportunities for improving UI-related software engineering tasks.
Towards Lightweight Transformer via Group-wise Transformation for Vision-and-Language Tasks
Apr 16, 2022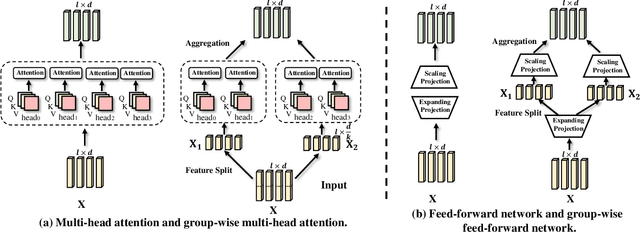


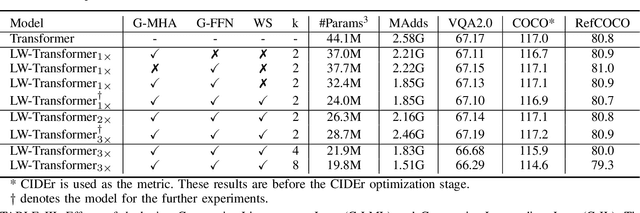
Despite the exciting performance, Transformer is criticized for its excessive parameters and computation cost. However, compressing Transformer remains as an open problem due to its internal complexity of the layer designs, i.e., Multi-Head Attention (MHA) and Feed-Forward Network (FFN). To address this issue, we introduce Group-wise Transformation towards a universal yet lightweight Transformer for vision-and-language tasks, termed as LW-Transformer. LW-Transformer applies Group-wise Transformation to reduce both the parameters and computations of Transformer, while also preserving its two main properties, i.e., the efficient attention modeling on diverse subspaces of MHA, and the expanding-scaling feature transformation of FFN. We apply LW-Transformer to a set of Transformer-based networks, and quantitatively measure them on three vision-and-language tasks and six benchmark datasets. Experimental results show that while saving a large number of parameters and computations, LW-Transformer achieves very competitive performance against the original Transformer networks for vision-and-language tasks. To examine the generalization ability, we also apply our optimization strategy to a recently proposed image Transformer called Swin-Transformer for image classification, where the effectiveness can be also confirmed
Holistic Approach to Measure Sample-level Adversarial Vulnerability and its Utility in Building Trustworthy Systems
May 05, 2022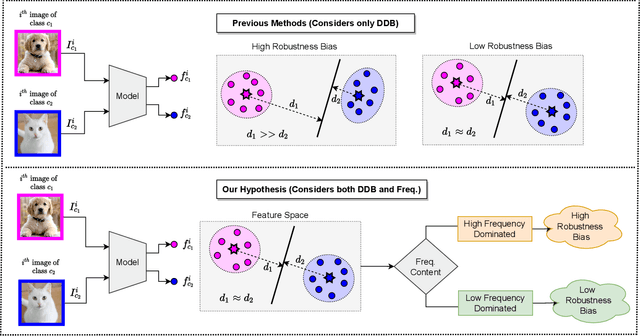
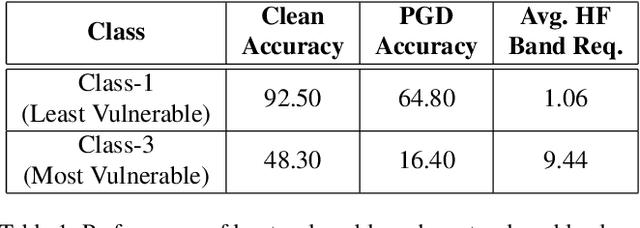
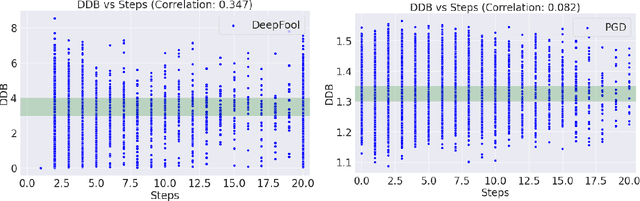

Adversarial attack perturbs an image with an imperceptible noise, leading to incorrect model prediction. Recently, a few works showed inherent bias associated with such attack (robustness bias), where certain subgroups in a dataset (e.g. based on class, gender, etc.) are less robust than others. This bias not only persists even after adversarial training, but often results in severe performance discrepancies across these subgroups. Existing works characterize the subgroup's robustness bias by only checking individual sample's proximity to the decision boundary. In this work, we argue that this measure alone is not sufficient and validate our argument via extensive experimental analysis. It has been observed that adversarial attacks often corrupt the high-frequency components of the input image. We, therefore, propose a holistic approach for quantifying adversarial vulnerability of a sample by combining these different perspectives, i.e., degree of model's reliance on high-frequency features and the (conventional) sample-distance to the decision boundary. We demonstrate that by reliably estimating adversarial vulnerability at the sample level using the proposed holistic metric, it is possible to develop a trustworthy system where humans can be alerted about the incoming samples that are highly likely to be misclassified at test time. This is achieved with better precision when our holistic metric is used over individual measures. To further corroborate the utility of the proposed holistic approach, we perform knowledge distillation in a limited-sample setting. We observe that the student network trained with the subset of samples selected using our combined metric performs better than both the competing baselines, viz., where samples are selected randomly or based on their distances to the decision boundary.
A Novel Viewport-Adaptive Motion Compensation Technique for Fisheye Video
Feb 28, 2022
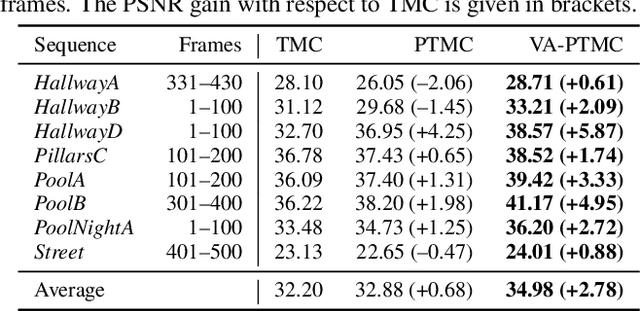

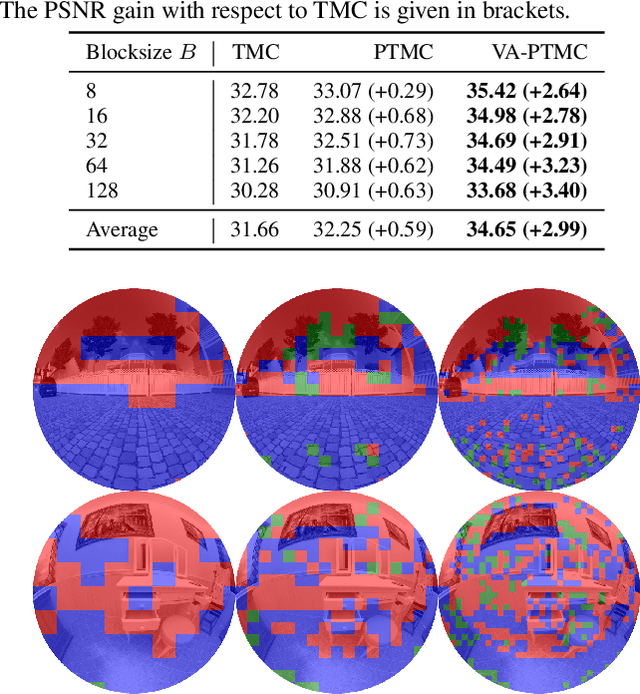
Although fisheye cameras are in high demand in many application areas due to their large field of view, many image and video signal processing tasks such as motion compensation suffer from the introduced strong radial distortions. A recently proposed projection-based approach takes the fisheye projection into account to improve fisheye motion compensation. However, the approach does not consider the large field of view of fisheye lenses that requires the consideration of different motion planes in 3D space. We propose a novel viewport-adaptive motion compensation technique that applies the motion vectors in different perspective viewports in order to realize these motion planes. Thereby, some pixels are mapped to so-called virtual image planes and require special treatment to obtain reliable mappings between the perspective viewports and the original fisheye image. While the state-of-the-art ultra wide-angle compensation is sufficiently accurate, we propose a virtual image plane compensation that leads to perfect mappings. All in all, we achieve average gains of +2.40 dB in terms of PSNR compared to the state of the art in fisheye motion compensation.
* 5 pages, 5 figures, 2 tables
Applying convolutional neural networks to extremely sparse image datasets using an image subdivision approach
Oct 25, 2020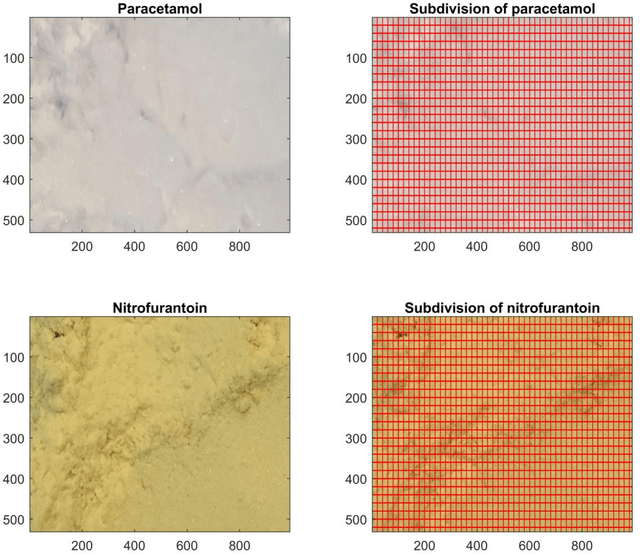
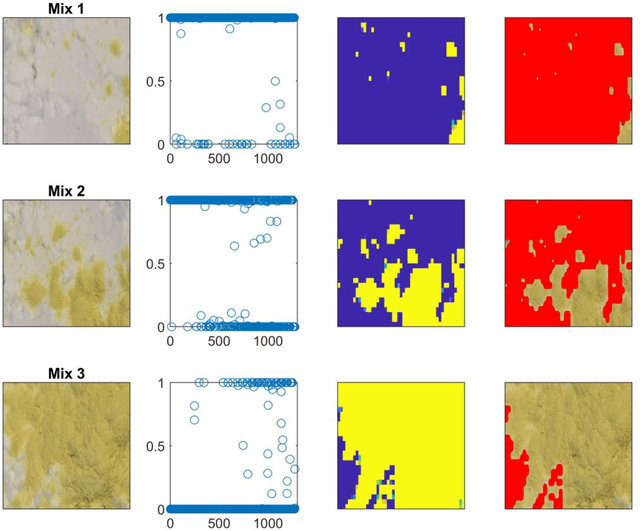

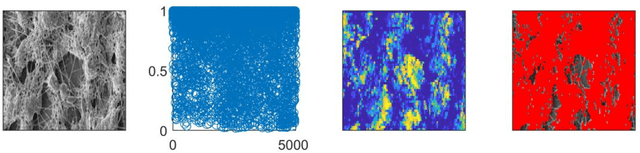
Purpose: The aim of this work is to demonstrate that convolutional neural networks (CNN) can be applied to extremely sparse image libraries by subdivision of the original image datasets. Methods: Image datasets from a conventional digital camera was created and scanning electron microscopy (SEM) measurements were obtained from the literature. The image datasets were subdivided and CNN models were trained on parts of the subdivided datasets. Results: The CNN models were capable of analyzing extremely sparse image datasets by utilizing the proposed method of image subdivision. It was furthermore possible to provide a direct assessment of the various regions where a given API or appearance was predominant.
Precision-medicine-toolbox: An open-source python package for facilitation of quantitative medical imaging and radiomics analysis
Feb 28, 2022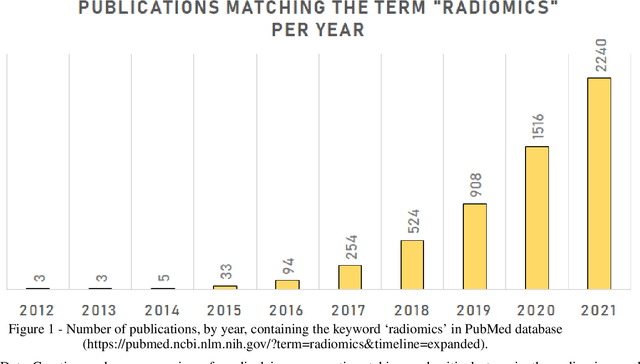
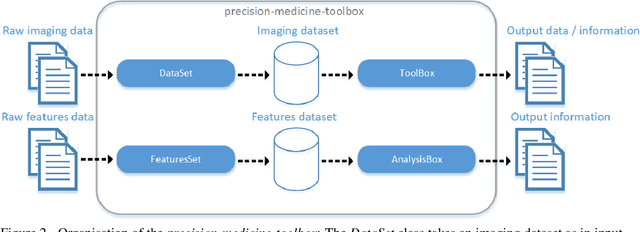
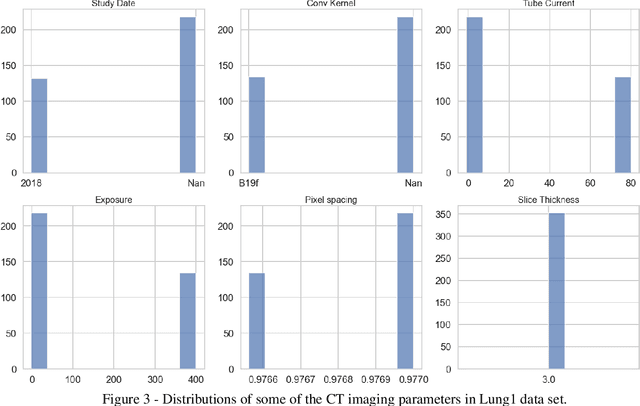
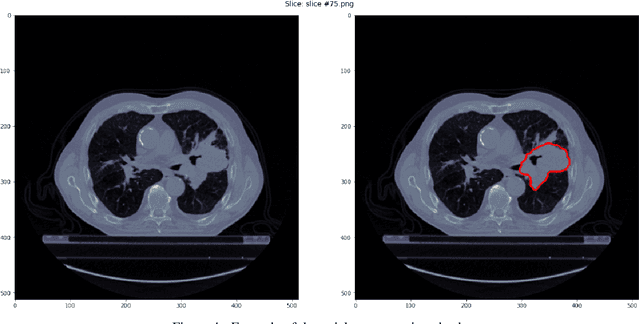
Medical image analysis plays a key role in precision medicine as it allows the clinicians to identify anatomical abnormalities and it is routinely used in clinical assessment. Data curation and pre-processing of medical images are critical steps in the quantitative medical image analysis that can have a significant impact on the resulting model performance. In this paper, we introduce a precision-medicine-toolbox that allows researchers to perform data curation, image pre-processing and handcrafted radiomics extraction (via Pyradiomics) and feature exploration tasks with Python. With this open-source solution, we aim to address the data preparation and exploration problem, bridge the gap between the currently existing packages, and improve the reproducibility of quantitative medical imaging research.
Wavelet-Packet Powered Deepfake Image Detection
Jun 17, 2021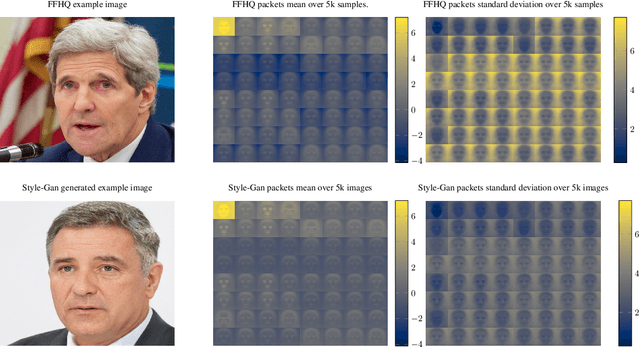
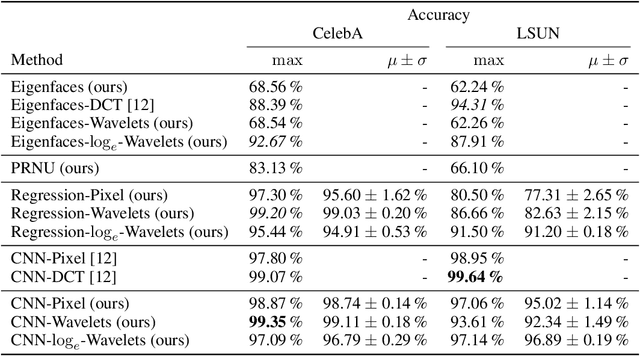
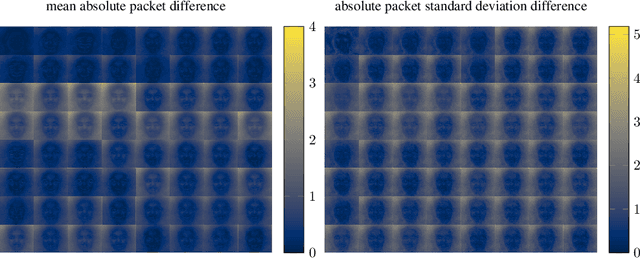
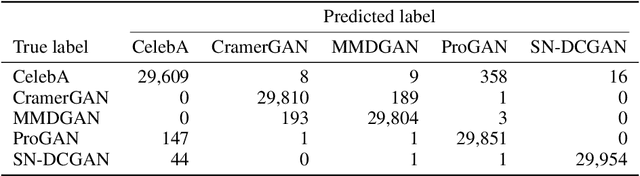
As neural networks become more able to generate realistic artificial images, they have the potential to improve movies, music, video games and make the internet an even more creative and inspiring place. Yet, at the same time, the latest technology potentially enables new digital ways to lie. In response, the need for a diverse and reliable toolbox arises to identify artificial images and other content. Previous work primarily relies on pixel-space CNN or the Fourier transform. To the best of our knowledge, wavelet-based gan analysis and detection methods have been absent thus far. This paper aims to fill this gap and describes a wavelet-based approach to gan-generated image analysis and detection. We evaluate our method on FFHQ, CelebA, and LSUN source identification problems and find improved or competitive performance.
VALHALLA: Visual Hallucination for Machine Translation
May 31, 2022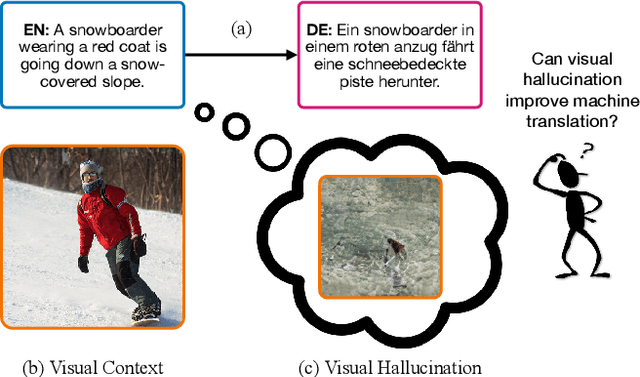
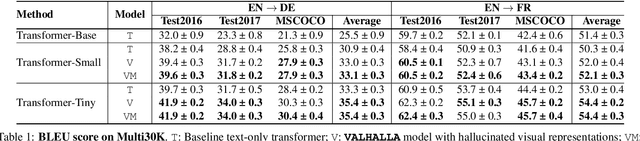
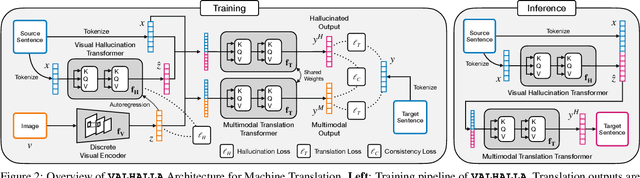
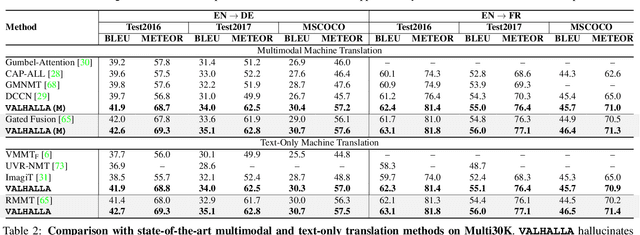
Designing better machine translation systems by considering auxiliary inputs such as images has attracted much attention in recent years. While existing methods show promising performance over the conventional text-only translation systems, they typically require paired text and image as input during inference, which limits their applicability to real-world scenarios. In this paper, we introduce a visual hallucination framework, called VALHALLA, which requires only source sentences at inference time and instead uses hallucinated visual representations for multimodal machine translation. In particular, given a source sentence an autoregressive hallucination transformer is used to predict a discrete visual representation from the input text, and the combined text and hallucinated representations are utilized to obtain the target translation. We train the hallucination transformer jointly with the translation transformer using standard backpropagation with cross-entropy losses while being guided by an additional loss that encourages consistency between predictions using either ground-truth or hallucinated visual representations. Extensive experiments on three standard translation datasets with a diverse set of language pairs demonstrate the effectiveness of our approach over both text-only baselines and state-of-the-art methods. Project page: http://www.svcl.ucsd.edu/projects/valhalla.
Rethinking the Truly Unsupervised Image-to-Image Translation
Jun 11, 2020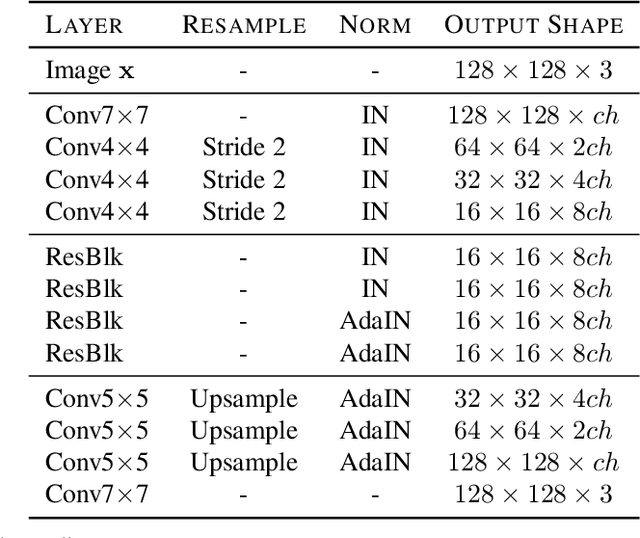

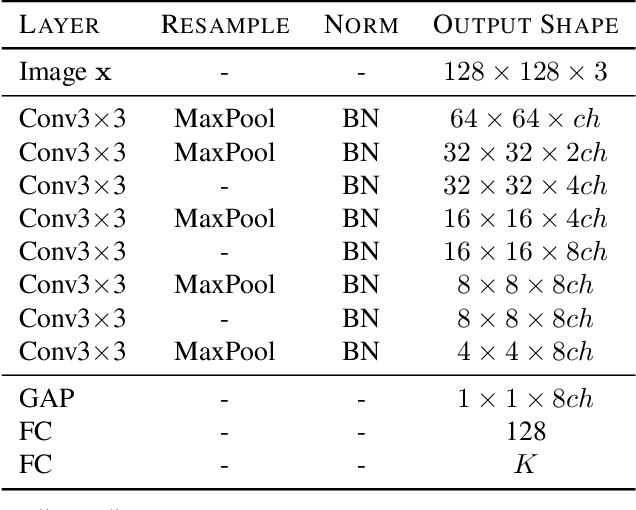
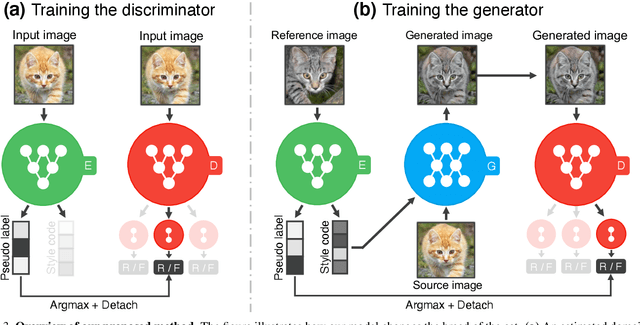
Every recent image-to-image translation model uses either image-level (i.e. input-output pairs) or set-level (i.e. domain labels) supervision at minimum. However, even the set-level supervision can be a serious bottleneck for data collection in practice. In this paper, we tackle image-to-image translation in a fully unsupervised setting, i.e., neither paired images nor domain labels. To this end, we propose the truly unsupervised image-to-image translation method (TUNIT) that simultaneously learns to separate image domains via an information-theoretic approach and generate corresponding images using the estimated domain labels. Experimental results on various datasets show that the proposed method successfully separates domains and translates images across those domains. In addition, our model outperforms existing set-level supervised methods under a semi-supervised setting, where a subset of domain labels is provided. The source code is available at https://github.com/clovaai/tunit
3DILG: Irregular Latent Grids for 3D Generative Modeling
May 27, 2022

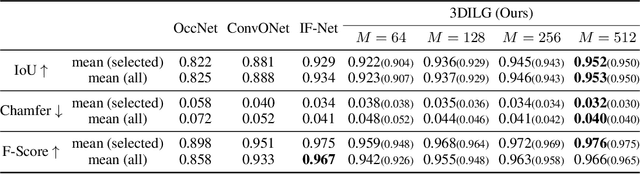
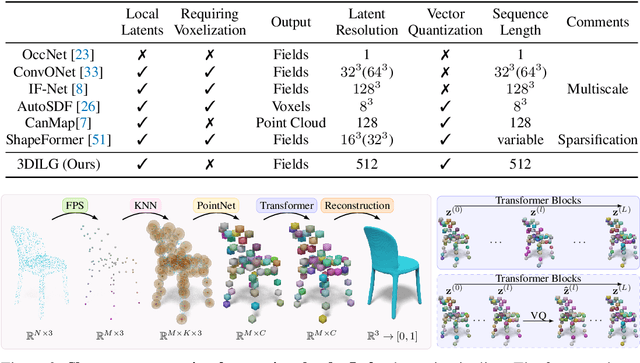
We propose a new representation for encoding 3D shapes as neural fields. The representation is designed to be compatible with the transformer architecture and to benefit both shape reconstruction and shape generation. Existing works on neural fields are grid-based representations with latents defined on a regular grid. In contrast, we define latents on irregular grids, enabling our representation to be sparse and adaptive. In the context of shape reconstruction from point clouds, our shape representation built on irregular grids improves upon grid-based methods in terms of reconstruction accuracy. For shape generation, our representation promotes high-quality shape generation using auto-regressive probabilistic models. We show different applications that improve over the current state of the art. First, we show results for probabilistic shape reconstruction from a single higher resolution image. Second, we train a probabilistic model conditioned on very low resolution images. Third, we apply our model to category-conditioned generation. All probabilistic experiments confirm that we are able to generate detailed and high quality shapes to yield the new state of the art in generative 3D shape modeling.