 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hyperparameter Sensitivity in Deep Outlier Detection: Analysis and a Scalable Hyper-Ensemble Solution
Jun 15, 2022
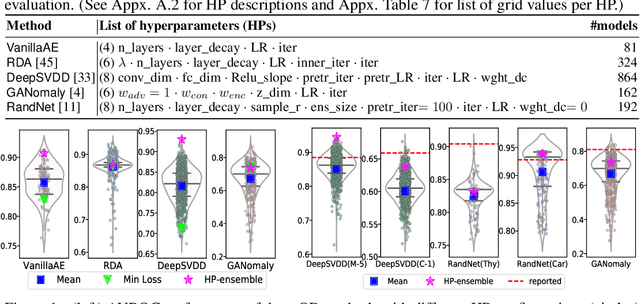

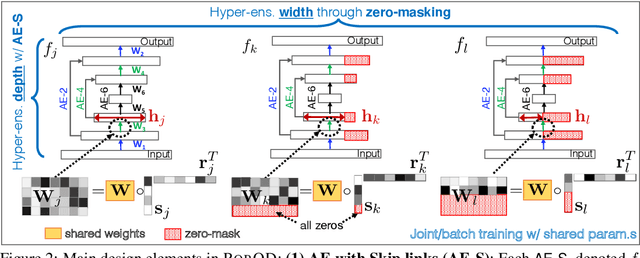
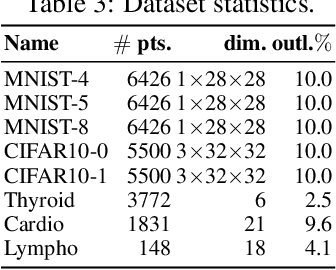
Outlier detection (OD) literature exhibits numerous algorithms as it applies to diverse domains. However, given a new detection task, it is unclear how to choose an algorithm to use, nor how to set its hyperparameter(s) (HPs) in unsupervised settings. HP tuning is an ever-growing problem with the arrival of many new detectors based on deep learning. While they have appealing properties such as task- driven representation learning and end-to-end optimization, deep models come with a long list of HPs. Surprisingly, the issue of model selection in the outlier mining literature has been "the elephant in the room"; a significant factor in unlocking the utmost potential of deep methods, yet little said or done to systematically tackle the issue. In the first part of this paper, we conduct the first large-scale analysis on the HP sensitivity of deep OD methods, and through more than 35,000 trained models, quantitatively demonstrate that model selection is inevitable. Next, we design a HP-robust and scalable deep hyper-ensemble model called ROBOD that assembles models with varying HP configurations, bypassing the choice paralysis. Importantly, we introduce novel strategies to speed up ensemble training, such as parameter sharing, batch/simultaneous training, and data subsampling, that allow us to train fewer models with fewer parameters. Extensive experiments on both image and tabular datasets show that ROBOD achieves and retains robust, state-of-the-art detection performance as compared to its modern counterparts, while taking only 2-10% of the time by the naive hyper-ensemble with independent training.
Pre-train, Self-train, Distill: A simple recipe for Supersizing 3D Reconstruction
Apr 07, 2022

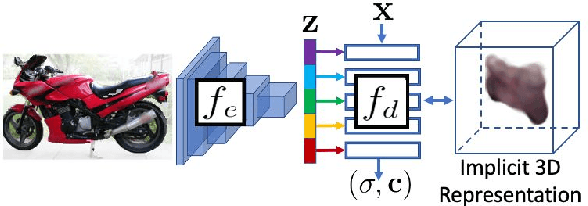
Our work learns a unified model for single-view 3D reconstruction of objects from hundreds of semantic categories. As a scalable alternative to direct 3D supervision, our work relies on segmented image collections for learning 3D of generic categories. Unlike prior works that use similar supervision but learn independent category-specific models from scratch, our approach of learning a unified model simplifies the training process while also allowing the model to benefit from the common structure across categories. Using image collections from standard recognition datasets, we show that our approach allows learning 3D inference for over 150 object categories. We evaluate using two datasets and qualitatively and quantitatively show that our unified reconstruction approach improves over prior category-specific reconstruction baselines. Our final 3D reconstruction model is also capable of zero-shot inference on images from unseen object categories and we empirically show that increasing the number of training categories improves the reconstruction quality.
Font Style that Fits an Image -- Font Generation Based on Image Context
May 19, 2021
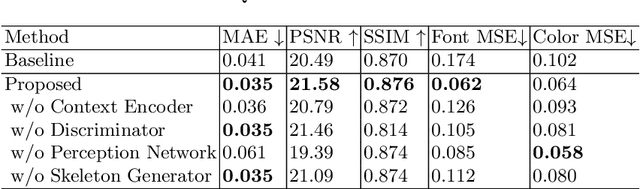
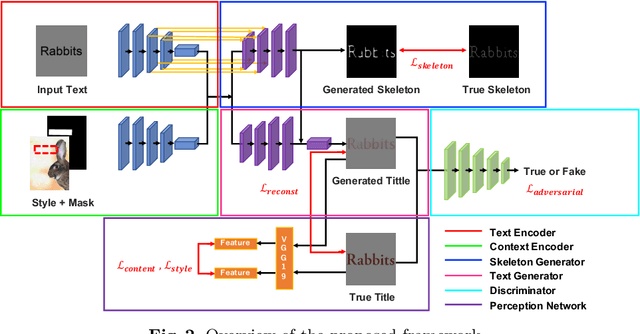

When fonts are used on documents, they are intentionally selected by designers. For example, when designing a book cover, the typography of the text is an important factor in the overall feel of the book. In addition, it needs to be an appropriate font for the rest of the book cover. Thus, we propose a method of generating a book title image based on its context within a book cover. We propose an end-to-end neural network that inputs the book cover, a target location mask, and a desired book title and outputs stylized text suitable for the cover. The proposed network uses a combination of a multi-input encoder-decoder, a text skeleton prediction network, a perception network, and an adversarial discriminator. We demonstrate that the proposed method can effectively produce desirable and appropriate book cover text through quantitative and qualitative results.
BiX-NAS: Searching Efficient Bi-directional Architecture for Medical Image Segmentation
Jun 30, 2021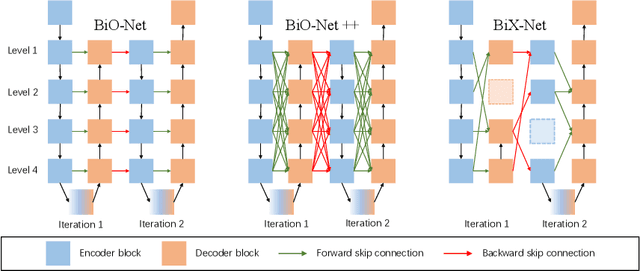
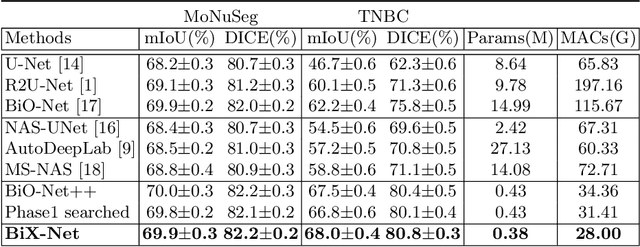
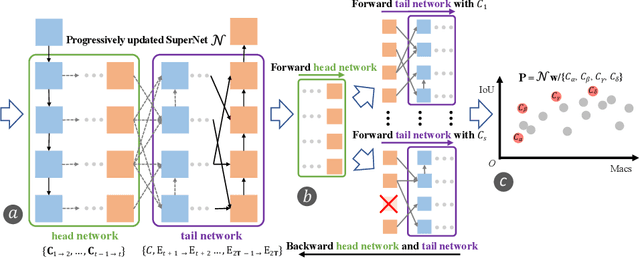
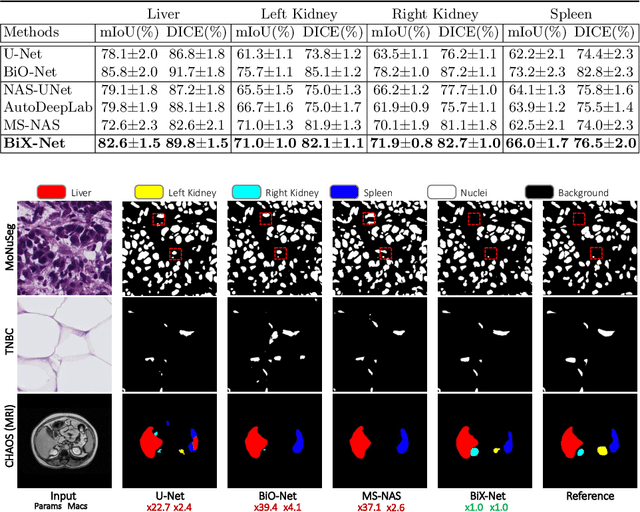
The recurrent mechanism has recently been introduced into U-Net in various medical image segmentation tasks. Existing studies have focused on promoting network recursion via reusing building blocks. Although network parameters could be greatly saved, computational costs still increase inevitably in accordance with the pre-set iteration time. In this work, we study a multi-scale upgrade of a bi-directional skip connected network and then automatically discover an efficient architecture by a novel two-phase Neural Architecture Search (NAS) algorithm, namely BiX-NAS. Our proposed method reduces the network computational cost by sifting out ineffective multi-scale features at different levels and iterations. We evaluate BiX-NAS on two segmentation tasks using three different medical image datasets, and the experimental results show that our BiX-NAS searched architecture achieves the state-of-the-art performance with significantly lower computational cost.
A Generalized Supervised Contrastive Learning Framework
Jun 01, 2022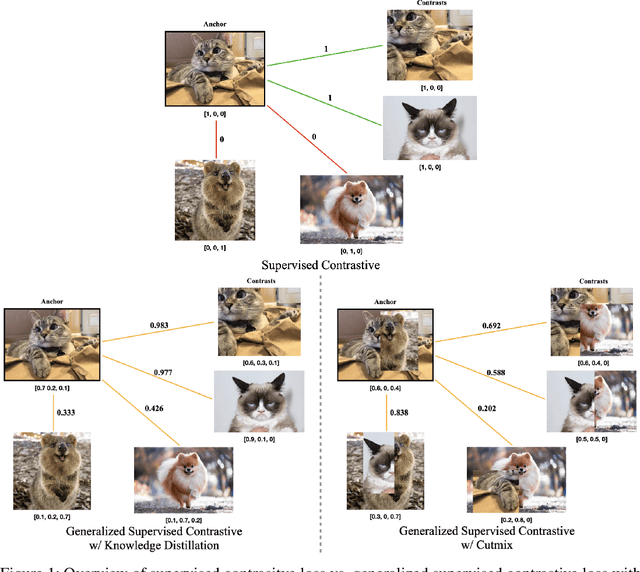

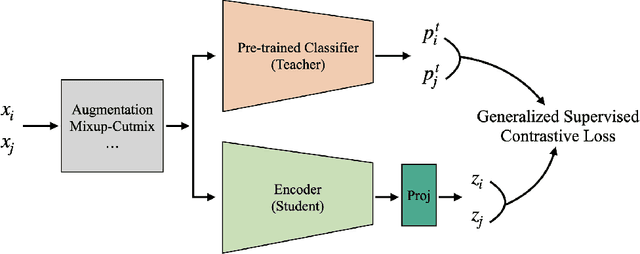

Based on recent remarkable achievements of contrastive learning in self-supervised representation learning, supervised contrastive learning (SupCon) has successfully extended the batch contrastive approaches to the supervised context and outperformed cross-entropy on various datasets on ResNet. In this work, we present GenSCL: a generalized supervised contrastive learning framework that seamlessly adapts modern image-based regularizations (such as Mixup-Cutmix) and knowledge distillation (KD) to SupCon by our generalized supervised contrastive loss. Generalized supervised contrastive loss is a further extension of supervised contrastive loss measuring cross-entropy between the similarity of labels and that of latent features. Then a model can learn to what extent contrastives should be pulled closer to an anchor in the latent space. By explicitly and fully leveraging label information, GenSCL breaks the boundary between conventional positives and negatives, and any kind of pre-trained teacher classifier can be utilized. ResNet-50 trained in GenSCL with Mixup-Cutmix and KD achieves state-of-the-art accuracies of 97.6% and 84.7% on CIFAR10 and CIFAR100 without external data, which significantly improves the results reported in the original SupCon (1.6% and 8.2%, respectively). Pytorch implementation is available at https://t.ly/yuUO.
Online Hybrid Lightweight Representations Learning: Its Application to Visual Tracking
May 23, 2022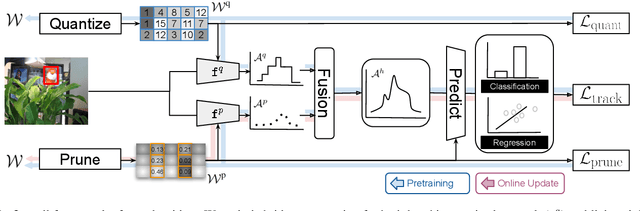
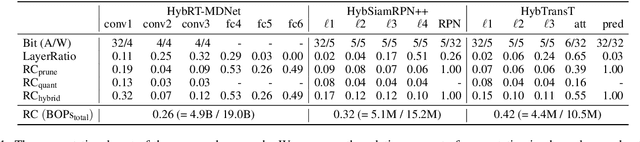
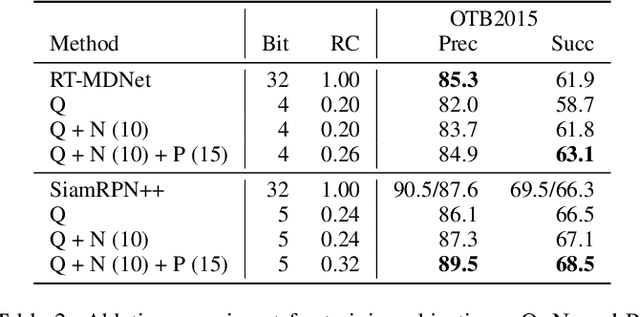
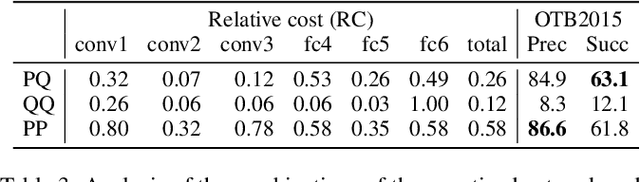
This paper presents a novel hybrid representation learning framework for streaming data, where an image frame in a video is modeled by an ensemble of two distinct deep neural networks; one is a low-bit quantized network and the other is a lightweight full-precision network. The former learns coarse primary information with low cost while the latter conveys residual information for high fidelity to original representations. The proposed parallel architecture is effective to maintain complementary information since fixed-point arithmetic can be utilized in the quantized network and the lightweight model provides precise representations given by a compact channel-pruned network. We incorporate the hybrid representation technique into an online visual tracking task, where deep neural networks need to handle temporal variations of target appearances in real-time. Compared to the state-of-the-art real-time trackers based on conventional deep neural networks, our tracking algorithm demonstrates competitive accuracy on the standard benchmarks with a small fraction of computational cost and memory footprint.
Meta-Learning Regrasping Strategies for Physical-Agnostic Objects
May 23, 2022
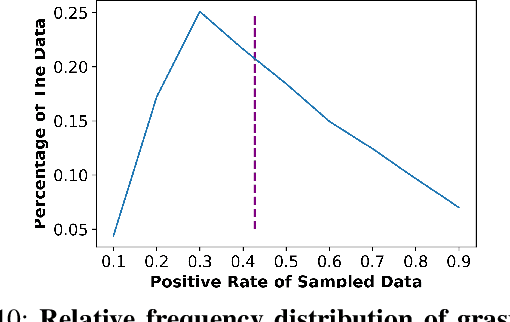
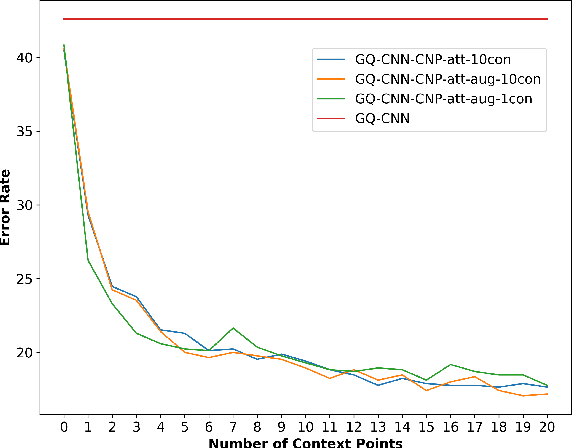
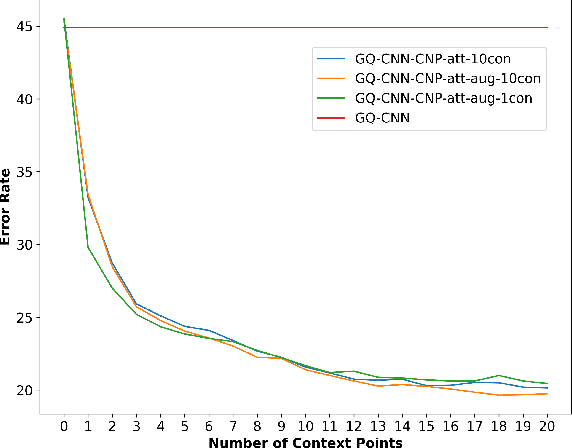
Grasping inhomogeneous objects, practical use in real-world applications, remains a challenging task due to the unknown physical properties such as mass distribution and coefficient of friction. In this study, we propose a vision-based meta-learning algorithm to learn physical properties in an agnostic way. In particular, we employ Conditional Neural Processes (CNPs) on top of DexNet-2.0. CNPs learn physical embeddings rapidly from a few observations where each observation is composed of i) the cropped depth image, ii) the grasping height between the gripper and estimated grasping point, and iii) the binary grasping result. Our modified conditional DexNet-2.0 (DexNet-CNP) updates the predicted grasping quality iteratively from new observations, which can be executed in an online fashion. We evaluate our method in the Pybullet simulator using various shape primitive objects with different physical parameters. The results show that our model outperforms the original DexNet-2.0 and is able to generalize on unseen objects with different shapes.
Practical Learned Lossless JPEG Recompression with Multi-Level Cross-Channel Entropy Model in the DCT Domain
Mar 30, 2022JPEG is a popular image compression method widely used by individuals, data center, cloud storage and network filesystems. However, most recent progress on image compression mainly focuses on uncompressed images while ignoring trillions of already-existing JPEG images. To compress these JPEG images adequately and restore them back to JPEG format losslessly when needed, we propose a deep learning based JPEG recompression method that operates on DCT domain and propose a Multi-Level Cross-Channel Entropy Model to compress the most informative Y component. Experiments show that our method achieves state-of-the-art performance compared with traditional JPEG recompression methods including Lepton, JPEG XL and CMIX. To the best of our knowledge, this is the first learned compression method that losslessly transcodes JPEG images to more storage-saving bitstreams.
High-fidelity GAN Inversion with Padding Space
Mar 21, 2022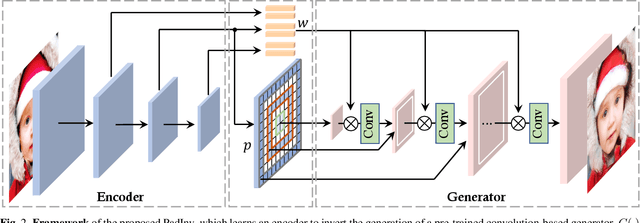



Inverting a Generative Adversarial Network (GAN) facilitates a wide range of image editing tasks using pre-trained generators. Existing methods typically employ the latent space of GANs as the inversion space yet observe the insufficient recovery of spatial details. In this work, we propose to involve the padding space of the generator to complement the latent space with spatial information. Concretely, we replace the constant padding (e.g., usually zeros) used in convolution layers with some instance-aware coefficients. In this way, the inductive bias assumed in the pre-trained model can be appropriately adapted to fit each individual image. Through learning a carefully designed encoder, we manage to improve the inversion quality both qualitatively and quantitatively, outperforming existing alternatives. We then demonstrate that such a space extension barely affects the native GAN manifold, hence we can still reuse the prior knowledge learned by GANs for various downstream applications. Beyond the editing tasks explored in prior arts, our approach allows a more flexible image manipulation, such as the separate control of face contour and facial details, and enables a novel editing manner where users can customize their own manipulations highly efficiently.
Multi-organ Segmentation Network with Adversarial Performance Validator
Apr 16, 2022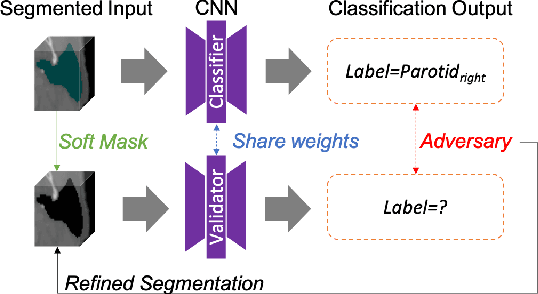
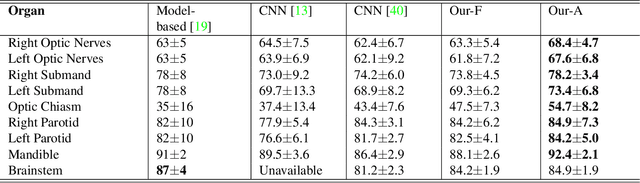
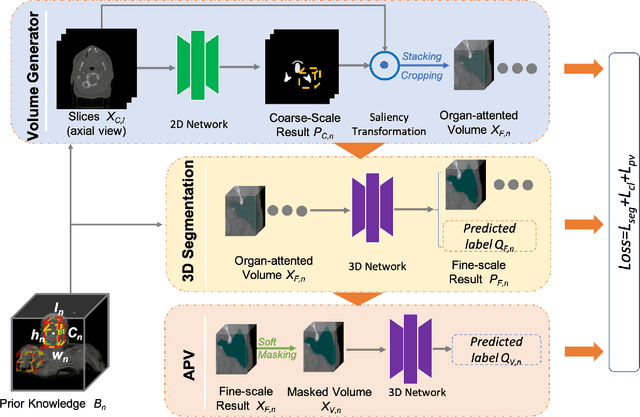
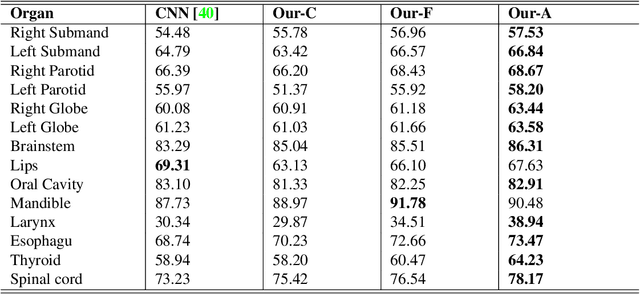
CT organ segmentation on computed tomography (CT) images becomes a significant brick for modern medical image analysis, supporting clinic workflows in multiple domains. Previous segmentation methods include 2D convolution neural networks (CNN) based approaches, fed by CT image slices that lack the structural knowledge in axial view, and 3D CNN-based methods with the expensive computation cost in multi-organ segmentation applications. This paper introduces an adversarial performance validation network into a 2D-to-3D segmentation framework. The classifier and performance validator competition contribute to accurate segmentation results via back-propagation. The proposed network organically converts the 2D-coarse result to 3D high-quality segmentation masks in a coarse-to-fine manner, allowing joint optimization to improve segmentation accuracy. Besides, the structural information of one specific organ is depicted by a statistics-meaningful prior bounding box, which is transformed into a global feature leveraging the learning process in 3D fine segmentation. The experiments on the NIH pancreas segmentation dataset demonstrate the proposed network achieves state-of-the-art accuracy on small organ segmentation and outperforms the previous best. High accuracy is also reported on multi-organ segmentation in a dataset collected by ourselves.