 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Monocular Human Digitization via Implicit Re-projection Networks
May 16, 2022
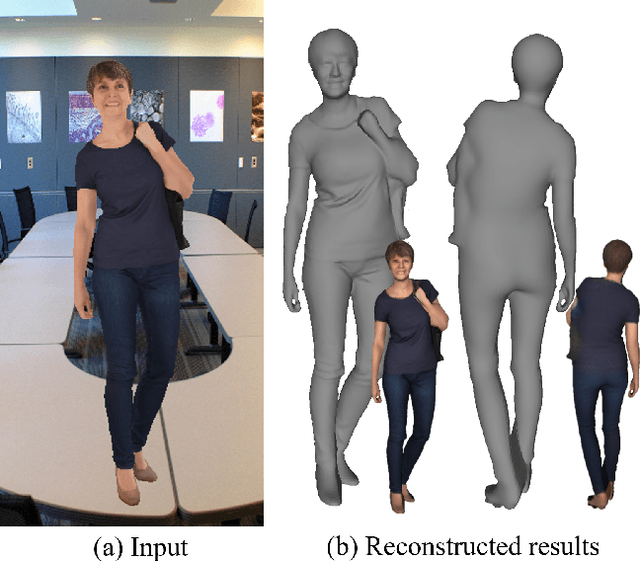
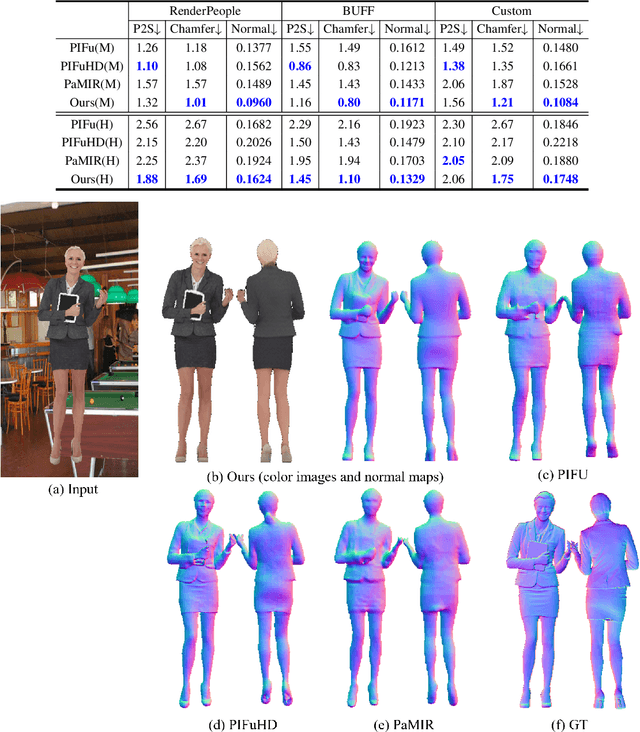
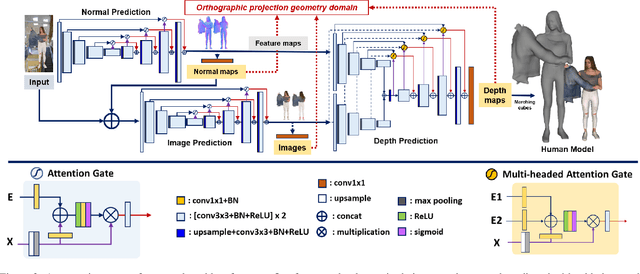
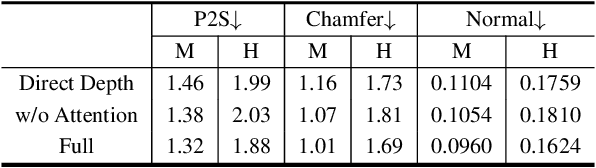
We present an approach to generating 3D human models from images. The key to our framework is that we predict double-sided orthographic depth maps and color images from a single perspective projected image. Our framework consists of three networks. The first network predicts normal maps to recover geometric details such as wrinkles in the clothes and facial regions. The second network predicts shade-removed images for the front and back views by utilizing the predicted normal maps. The last multi-headed network takes both normal maps and shade-free images and predicts depth maps while selectively fusing photometric and geometric information through multi-headed attention gates. Experimental results demonstrate that our method shows visually plausible results and competitive performance in terms of various evaluation metrics over state-of-the-art methods.
BiX-NAS: Searching Efficient Bi-directional Architecture for Medical Image Segmentation
Jul 01, 2021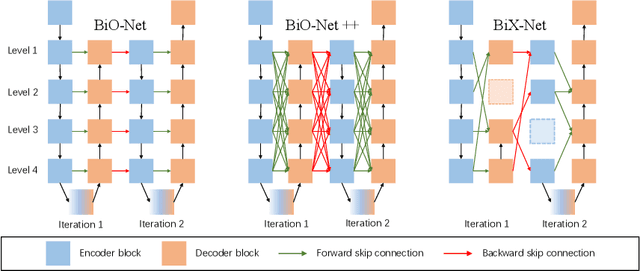
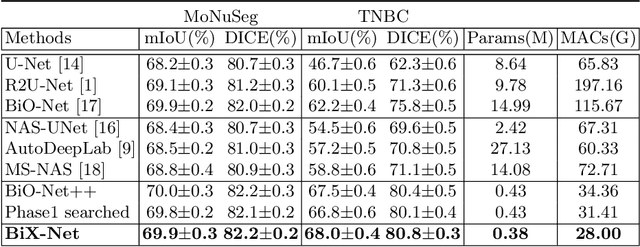
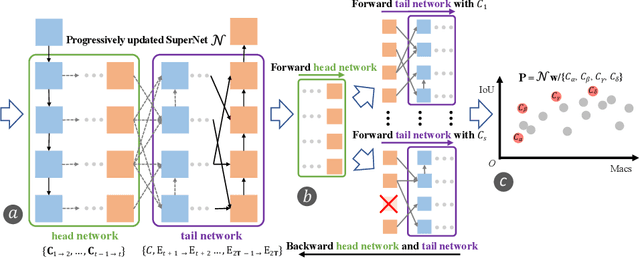
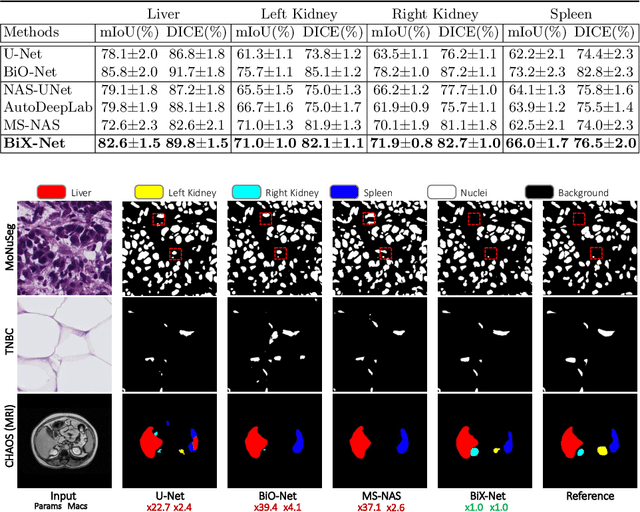
The recurrent mechanism has recently been introduced into U-Net in various medical image segmentation tasks. Existing studies have focused on promoting network recursion via reusing building blocks. Although network parameters could be greatly saved, computational costs still increase inevitably in accordance with the pre-set iteration time. In this work, we study a multi-scale upgrade of a bi-directional skip connected network and then automatically discover an efficient architecture by a novel two-phase Neural Architecture Search (NAS) algorithm, namely BiX-NAS. Our proposed method reduces the network computational cost by sifting out ineffective multi-scale features at different levels and iterations. We evaluate BiX-NAS on two segmentation tasks using three different medical image datasets, and the experimental results show that our BiX-NAS searched architecture achieves the state-of-the-art performance with significantly lower computational cost.
Physics to the Rescue: Deep Non-line-of-sight Reconstruction for High-speed Imaging
May 03, 2022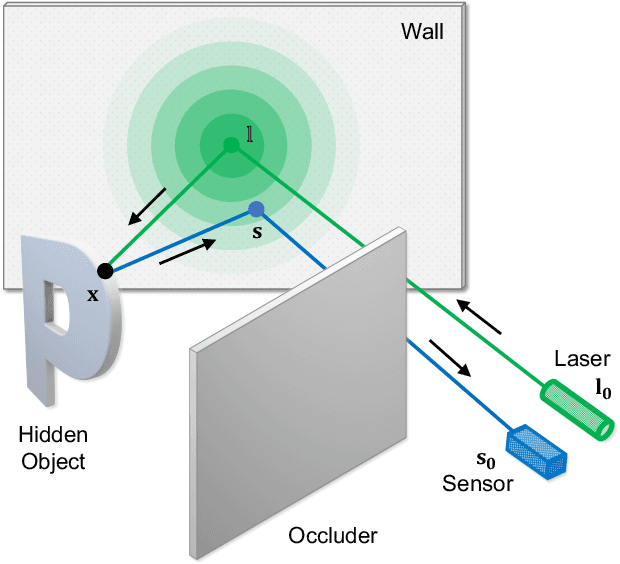
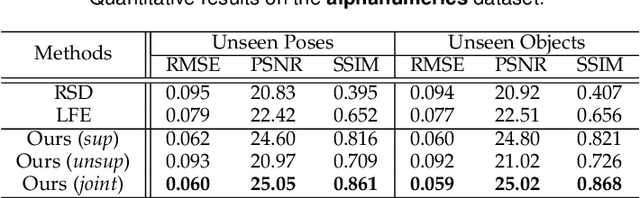
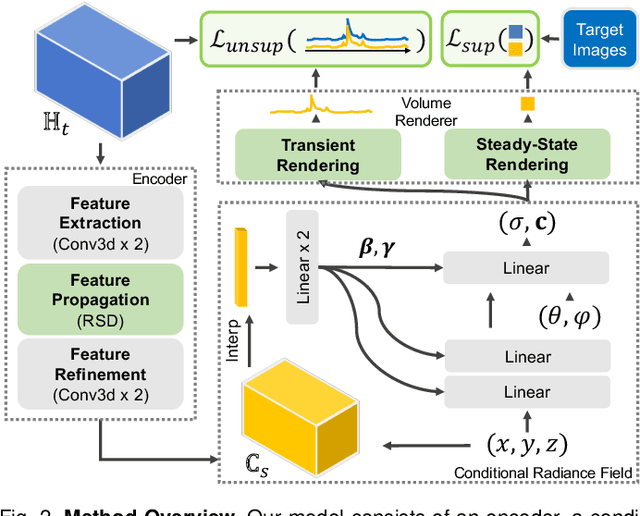
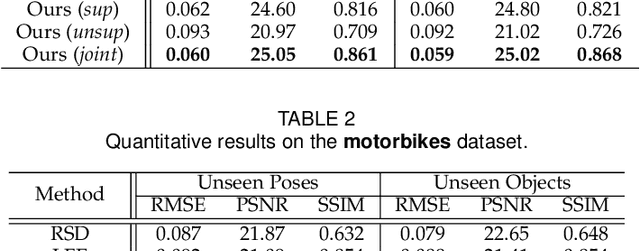
Computational approach to imaging around the corner, or non-line-of-sight (NLOS) imaging, is becoming a reality thanks to major advances in imaging hardware and reconstruction algorithms. A recent development towards practical NLOS imaging, Nam et al. demonstrated a high-speed non-confocal imaging system that operates at 5Hz, 100x faster than the prior art. This enormous gain in acquisition rate, however, necessitates numerous approximations in light transport, breaking many existing NLOS reconstruction methods that assume an idealized image formation model. To bridge the gap, we present a novel deep model that incorporates the complementary physics priors of wave propagation and volume rendering into a neural network for high-quality and robust NLOS reconstruction. This orchestrated design regularizes the solution space by relaxing the image formation model, resulting in a deep model that generalizes well on real captures despite being exclusively trained on synthetic data. Further, we devise a unified learning framework that enables our model to be flexibly trained using diverse supervision signals, including target intensity images or even raw NLOS transient measurements. Once trained, our model renders both intensity and depth images at inference time in a single forward pass, capable of processing more than 5 captures per second on a high-end GPU. Through extensive qualitative and quantitative experiments, we show that our method outperforms prior physics and learning based approaches on both synthetic and real measurements. We anticipate that our method along with the fast capturing system will accelerate future development of NLOS imaging for real world applications that require high-speed imaging.
Share With Thy Neighbors: Single-View Reconstruction by Cross-Instance Consistency
Apr 21, 2022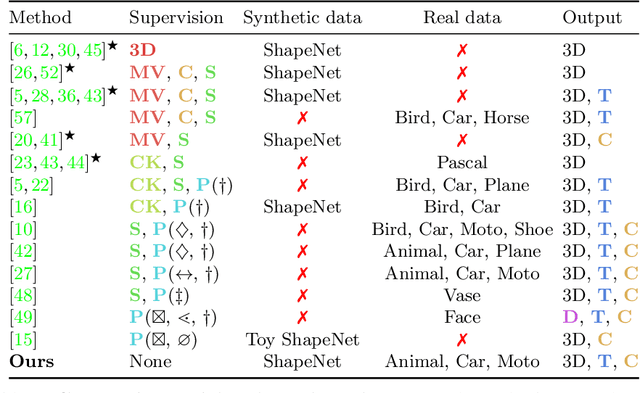
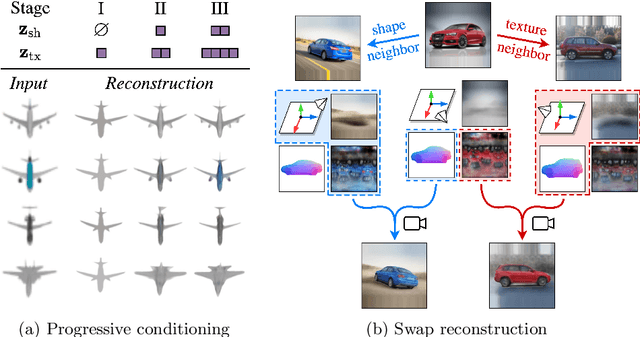
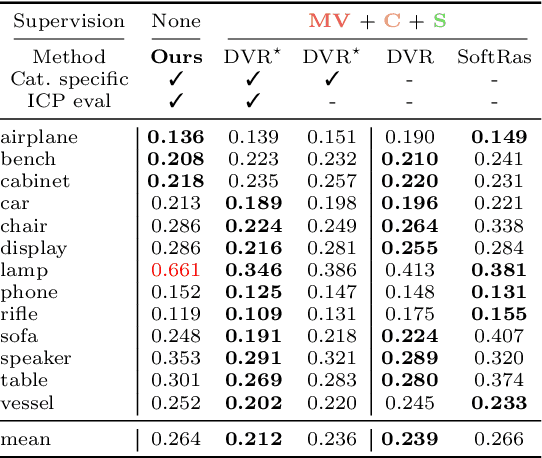
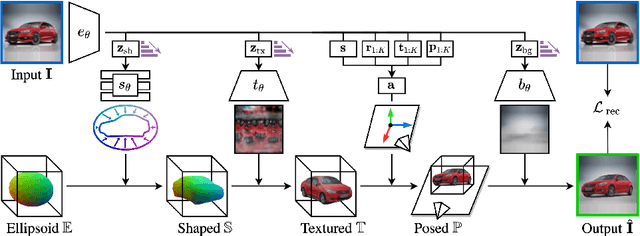
Approaches to single-view reconstruction typically rely on viewpoint annotations, silhouettes, the absence of background, multiple views of the same instance, a template shape, or symmetry. We avoid all of these supervisions and hypotheses by leveraging explicitly the consistency between images of different object instances. As a result, our method can learn from large collections of unlabelled images depicting the same object category. Our main contributions are two approaches to leverage cross-instance consistency: (i) progressive conditioning, a training strategy to gradually specialize the model from category to instances in a curriculum learning fashion; (ii) swap reconstruction, a loss enforcing consistency between instances having similar shape or texture. Critical to the success of our method are also: our structured autoencoding architecture decomposing an image into explicit shape, texture, pose, and background; an adapted formulation of differential rendering, and; a new optimization scheme alternating between 3D and pose learning. We compare our approach, UNICORN, both on the diverse synthetic ShapeNet dataset - the classical benchmark for methods requiring multiple views as supervision - and on standard real-image benchmarks (Pascal3D+ Car, CUB-200) for which most methods require known templates and silhouette annotations. We also showcase applicability to more challenging real-world collections (CompCars, LSUN), where silhouettes are not available and images are not cropped around the object.
A Closer Look at Self-supervised Lightweight Vision Transformers
May 28, 2022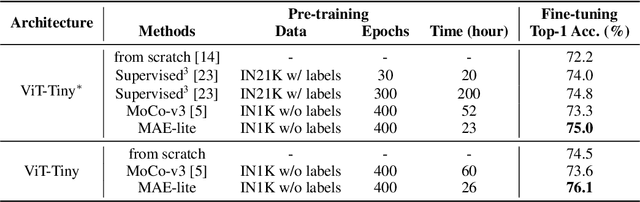
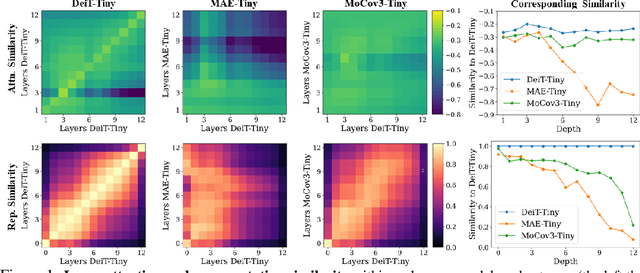
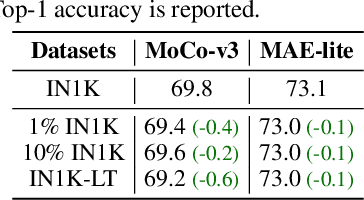
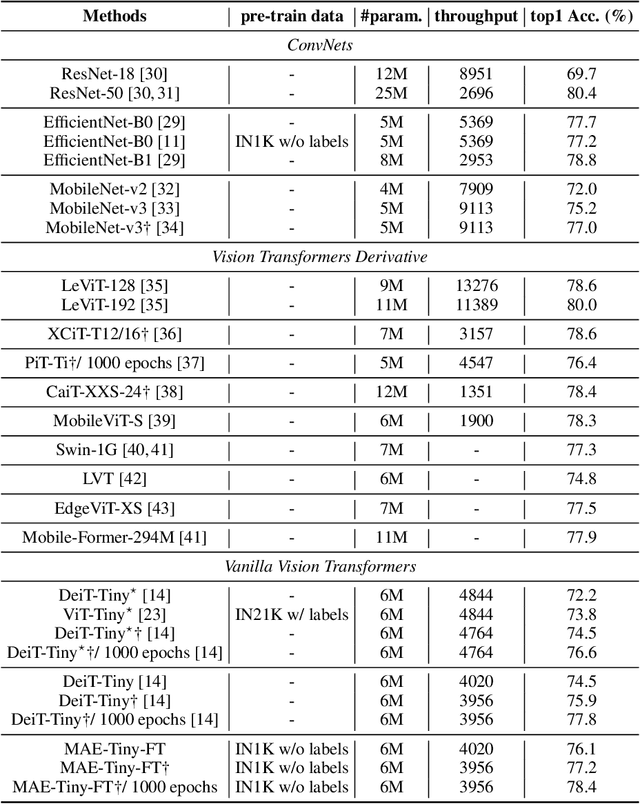
Self-supervised learning on large-scale Vision Transformers (ViTs) as pre-training methods has achieved promising downstream performance. Yet, how such pre-training paradigms promote lightweight ViTs' performance is considerably less studied. In this work, we mainly produce recipes for pre-training high-performance lightweight ViTs using masked-image-modeling-based MAE, namely MAE-lite, which achieves 78.4% top-1 accuracy on ImageNet with ViT-Tiny (5.7M). Furthermore, we develop and benchmark other fully-supervised and self-supervised pre-training counterparts, e.g., contrastive-learning-based MoCo-v3, on both ImageNet and other classification tasks. We analyze and clearly show the effect of such pre-training, and reveal that properly-learned lower layers of the pre-trained models matter more than higher ones in data-sufficient downstream tasks. Finally, by further comparing with the pre-trained representations of the up-scaled models, a distillation strategy during pre-training is developed to improve the pre-trained representations as well, leading to further downstream performance improvement. The code and models will be made publicly available.
TransforMatcher: Match-to-Match Attention for Semantic Correspondence
May 23, 2022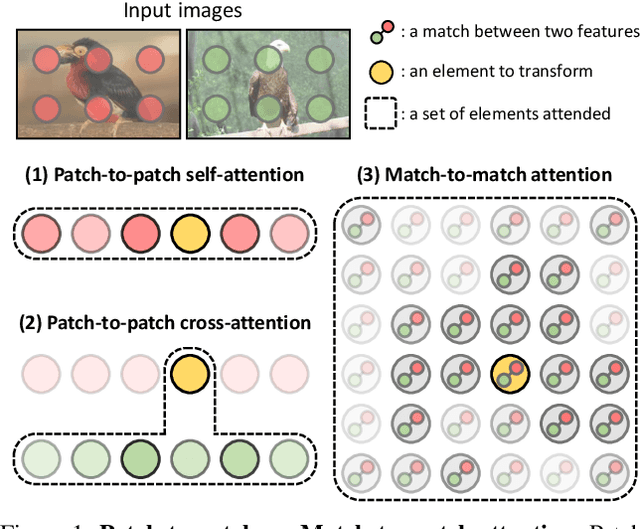
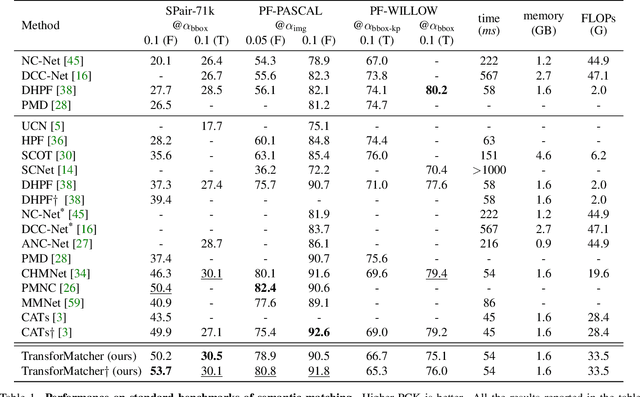
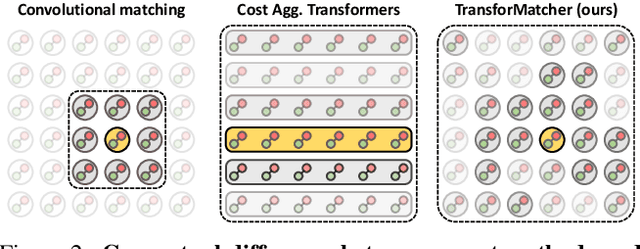
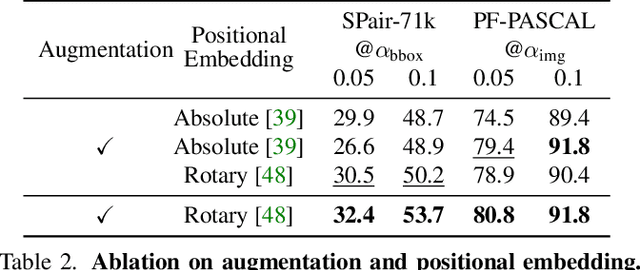
Establishing correspondences between images remains a challenging task, especially under large appearance changes due to different viewpoints or intra-class variations. In this work, we introduce a strong semantic image matching learner, dubbed TransforMatcher, which builds on the success of transformer networks in vision domains. Unlike existing convolution- or attention-based schemes for correspondence, TransforMatcher performs global match-to-match attention for precise match localization and dynamic refinement. To handle a large number of matches in a dense correlation map, we develop a light-weight attention architecture to consider the global match-to-match interactions. We also propose to utilize a multi-channel correlation map for refinement, treating the multi-level scores as features instead of a single score to fully exploit the richer layer-wise semantics. In experiments, TransforMatcher sets a new state of the art on SPair-71k while performing on par with existing SOTA methods on the PF-PASCAL dataset.
Leveraging Equivariant Features for Absolute Pose Regression
Apr 05, 2022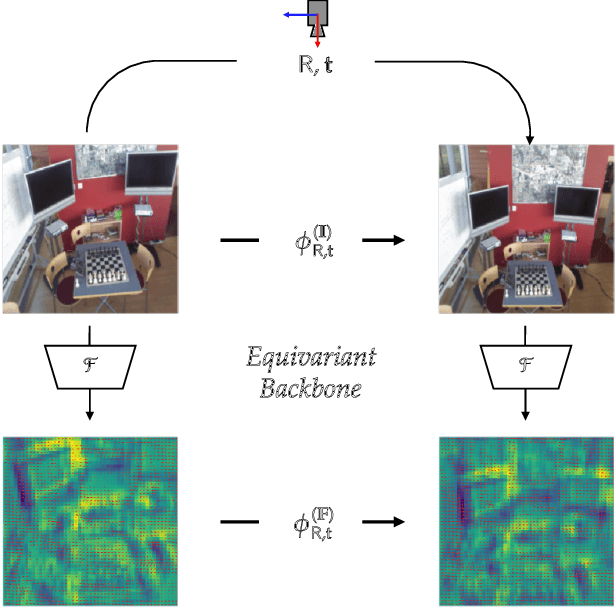
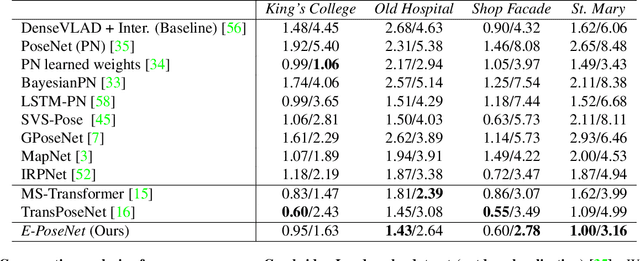
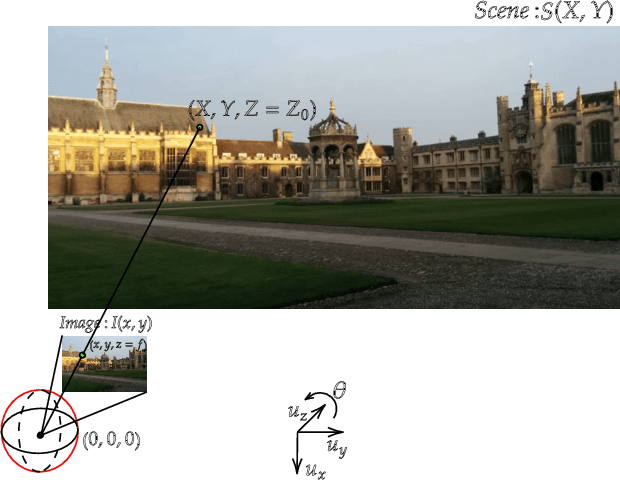
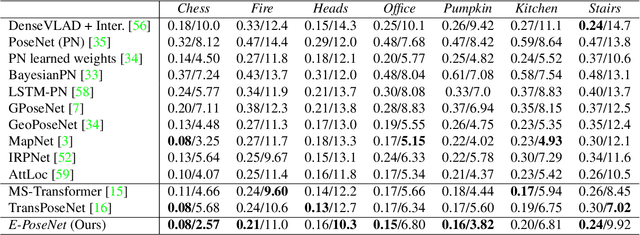
While end-to-end approaches have achieved state-of-the-art performance in many perception tasks, they are not yet able to compete with 3D geometry-based methods in pose estimation. Moreover, absolute pose regression has been shown to be more related to image retrieval. As a result, we hypothesize that the statistical features learned by classical Convolutional Neural Networks do not carry enough geometric information to reliably solve this inherently geometric task. In this paper, we demonstrate how a translation and rotation equivariant Convolutional Neural Network directly induces representations of camera motions into the feature space. We then show that this geometric property allows for implicitly augmenting the training data under a whole group of image plane-preserving transformations. Therefore, we argue that directly learning equivariant features is preferable than learning data-intensive intermediate representations. Comprehensive experimental validation demonstrates that our lightweight model outperforms existing ones on standard datasets.
3SD: Self-Supervised Saliency Detection With No Labels
Mar 09, 2022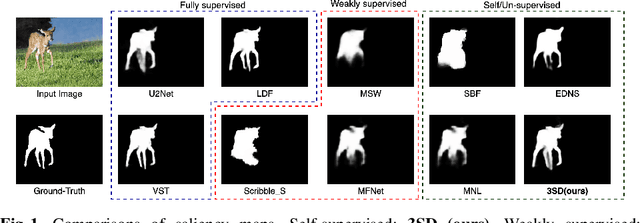
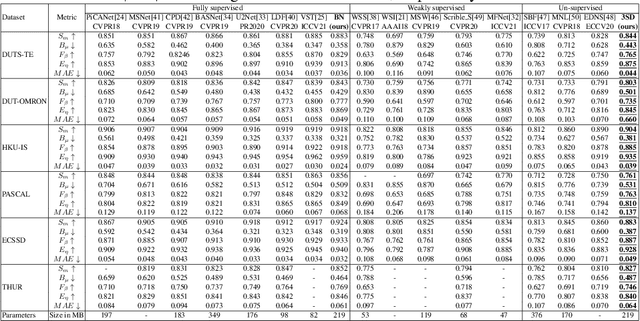

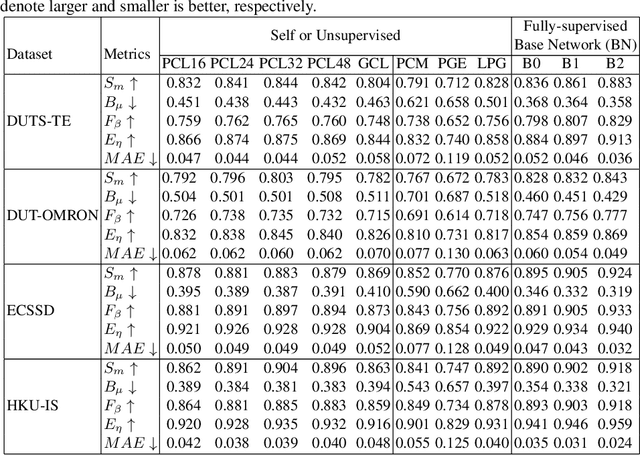
We present a conceptually simple self-supervised method for saliency detection. Our method generates and uses pseudo-ground truth labels for training. The generated pseudo-GT labels don't require any kind of human annotations (e.g., pixel-wise labels or weak labels like scribbles). Recent works show that features extracted from classification tasks provide important saliency cues like structure and semantic information of salient objects in the image. Our method, called 3SD, exploits this idea by adding a branch for a self-supervised classification task in parallel with salient object detection, to obtain class activation maps (CAM maps). These CAM maps along with the edges of the input image are used to generate the pseudo-GT saliency maps to train our 3SD network. Specifically, we propose a contrastive learning-based training on multiple image patches for the classification task. We show the multi-patch classification with contrastive loss improves the quality of the CAM maps compared to naive classification on the entire image. Experiments on six benchmark datasets demonstrate that without any labels, our 3SD method outperforms all existing weakly supervised and unsupervised methods, and its performance is on par with the fully-supervised methods. Code is available at :https://github.com/rajeevyasarla/3SD
MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Resolution
Jun 04, 2021
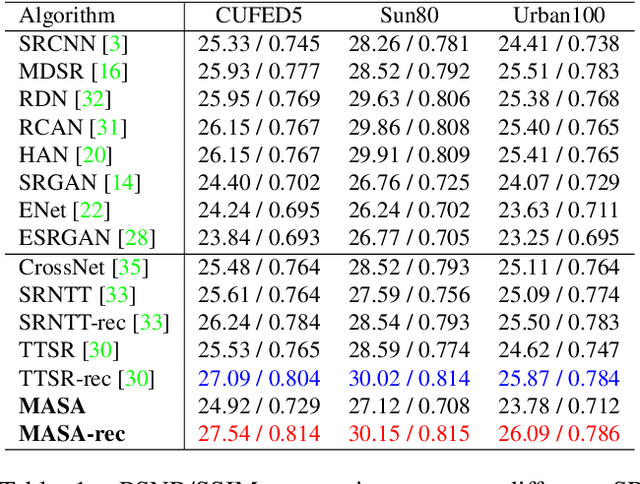
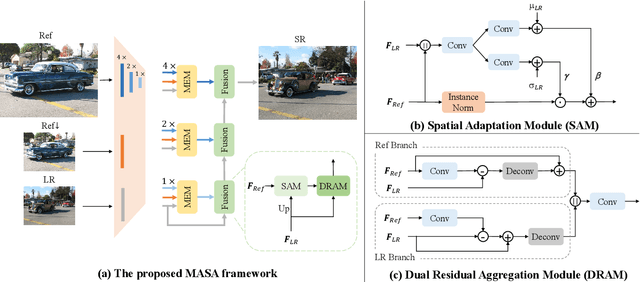

Reference-based image super-resolution (RefSR) has shown promising success in recovering high-frequency details by utilizing an external reference image (Ref). In this task, texture details are transferred from the Ref image to the low-resolution (LR) image according to their point- or patch-wise correspondence. Therefore, high-quality correspondence matching is critical. It is also desired to be computationally efficient. Besides, existing RefSR methods tend to ignore the potential large disparity in distributions between the LR and Ref images, which hurts the effectiveness of the information utilization. In this paper, we propose the MASA network for RefSR, where two novel modules are designed to address these problems. The proposed Match & Extraction Module significantly reduces the computational cost by a coarse-to-fine correspondence matching scheme. The Spatial Adaptation Module learns the difference of distribution between the LR and Ref images, and remaps the distribution of Ref features to that of LR features in a spatially adaptive way. This scheme makes the network robust to handle different reference images. Extensive quantitative and qualitative experiments validate the effectiveness of our proposed model.
VPAIR -- Aerial Visual Place Recognition and Localization in Large-scale Outdoor Environments
May 23, 2022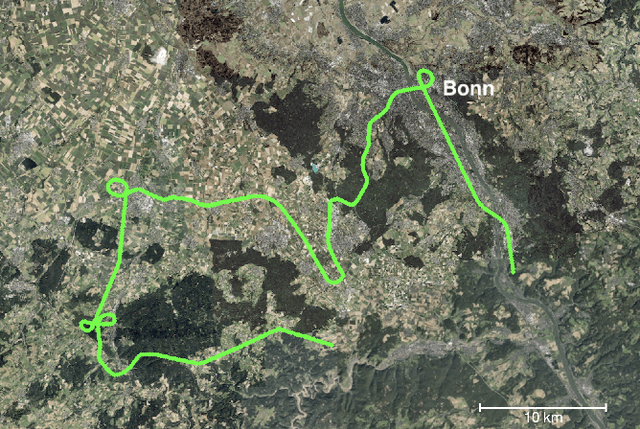
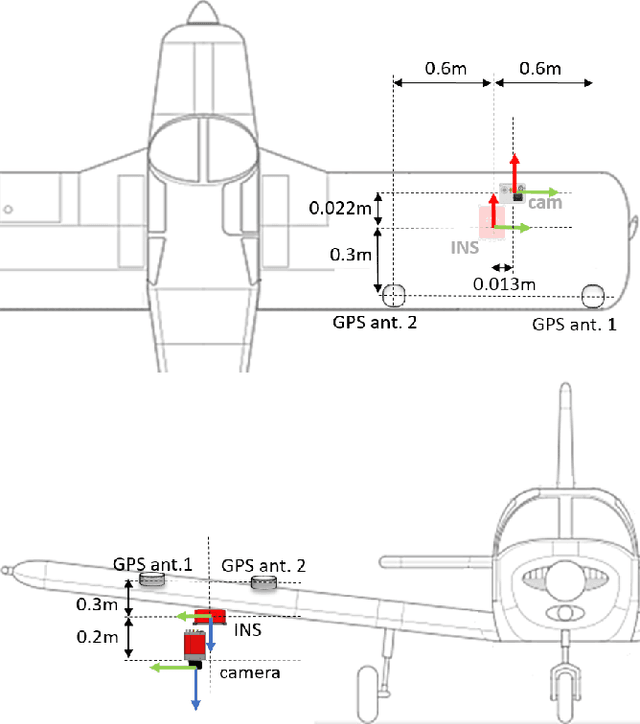

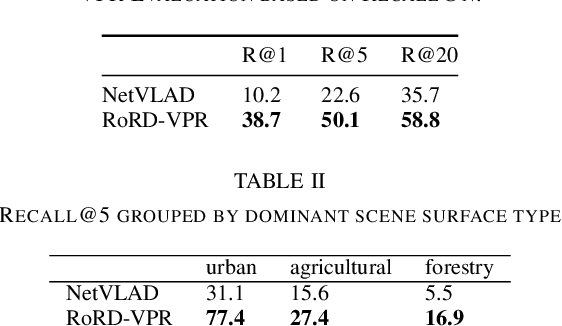
Visual Place Recognition and Visual Localization are essential components in navigation and mapping for autonomous vehicles especially in GNSS-denied navigation scenarios. Recent work has focused on ground or close to ground applications such as self-driving cars or indoor-scenarios and low-altitude drone flights. However, applications such as Urban Air Mobility require operations in large-scale outdoor environments at medium to high altitudes. We present a new dataset named VPAIR. The dataset was recorded on board a light aircraft flying at an altitude of more than 300 meters above ground capturing images with a downwardfacing camera. Each image is paired with a high resolution reference render including dense depth information and 6-DoF reference poses. The dataset covers a more than one hundred kilometers long trajectory over various types of challenging landscapes, e.g. urban, farmland and forests. Experiments on this dataset illustrate the challenges introduced by the change in perspective to a bird's eye view such as in-plane rotations.