 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Trajectory Consistency Distillation
Feb 29, 2024
Latent Consistency Model (LCM) extends the Consistency Model to the latent space and leverages the guided consistency distillation technique to achieve impressive performance in accelerating text-to-image synthesis. However, we observed that LCM struggles to generate images with both clarity and detailed intricacy. To address this limitation, we initially delve into and elucidate the underlying causes. Our investigation identifies that the primary issue stems from errors in three distinct areas. Consequently, we introduce Trajectory Consistency Distillation (TCD), which encompasses trajectory consistency function and strategic stochastic sampling. The trajectory consistency function diminishes the distillation errors by broadening the scope of the self-consistency boundary condition and endowing the TCD with the ability to accurately trace the entire trajectory of the Probability Flow ODE. Additionally, strategic stochastic sampling is specifically designed to circumvent the accumulated errors inherent in multi-step consistency sampling, which is meticulously tailored to complement the TCD model. Experiments demonstrate that TCD not only significantly enhances image quality at low NFEs but also yields more detailed results compared to the teacher model at high NFEs.
ProtoP-OD: Explainable Object Detection with Prototypical Parts
Feb 29, 2024Interpretation and visualization of the behavior of detection transformers tends to highlight the locations in the image that the model attends to, but it provides limited insight into the \emph{semantics} that the model is focusing on. This paper introduces an extension to detection transformers that constructs prototypical local features and uses them in object detection. These custom features, which we call prototypical parts, are designed to be mutually exclusive and align with the classifications of the model. The proposed extension consists of a bottleneck module, the prototype neck, that computes a discretized representation of prototype activations and a new loss term that matches prototypes to object classes. This setup leads to interpretable representations in the prototype neck, allowing visual inspection of the image content perceived by the model and a better understanding of the model's reliability. We show experimentally that our method incurs only a limited performance penalty, and we provide examples that demonstrate the quality of the explanations provided by our method, which we argue outweighs the performance penalty.
OpenMEDLab: An Open-source Platform for Multi-modality Foundation Models in Medicine
Mar 04, 2024The emerging trend of advancing generalist artificial intelligence, such as GPTv4 and Gemini, has reshaped the landscape of research (academia and industry) in machine learning and many other research areas. However, domain-specific applications of such foundation models (e.g., in medicine) remain untouched or often at their very early stages. It will require an individual set of transfer learning and model adaptation techniques by further expanding and injecting these models with domain knowledge and data. The development of such technologies could be largely accelerated if the bundle of data, algorithms, and pre-trained foundation models were gathered together and open-sourced in an organized manner. In this work, we present OpenMEDLab, an open-source platform for multi-modality foundation models. It encapsulates not only solutions of pioneering attempts in prompting and fine-tuning large language and vision models for frontline clinical and bioinformatic applications but also building domain-specific foundation models with large-scale multi-modal medical data. Importantly, it opens access to a group of pre-trained foundation models for various medical image modalities, clinical text, protein engineering, etc. Inspiring and competitive results are also demonstrated for each collected approach and model in a variety of benchmarks for downstream tasks. We welcome researchers in the field of medical artificial intelligence to continuously contribute cutting-edge methods and models to OpenMEDLab, which can be accessed via https://github.com/openmedlab.
Theoretical Insights for Diffusion Guidance: A Case Study for Gaussian Mixture Models
Mar 03, 2024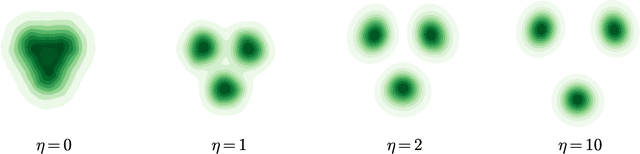
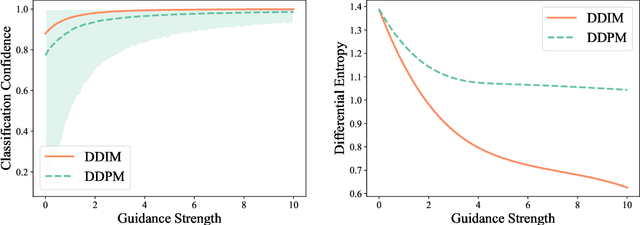
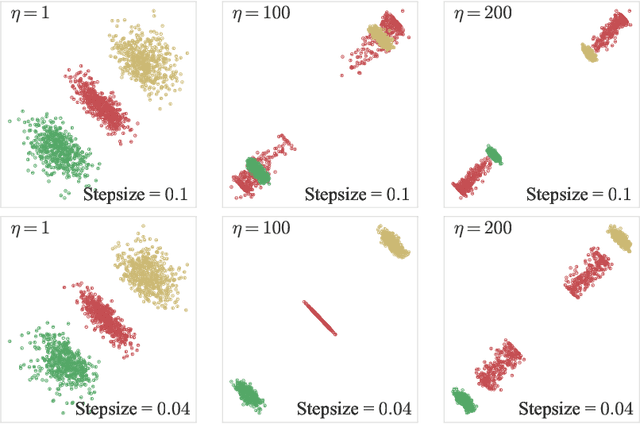
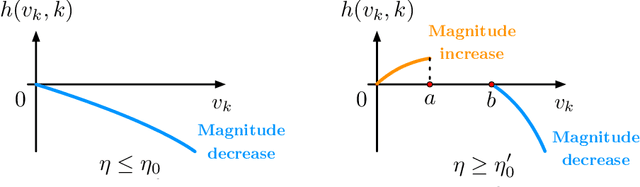
Diffusion models benefit from instillation of task-specific information into the score function to steer the sample generation towards desired properties. Such information is coined as guidance. For example, in text-to-image synthesis, text input is encoded as guidance to generate semantically aligned images. Proper guidance inputs are closely tied to the performance of diffusion models. A common observation is that strong guidance promotes a tight alignment to the task-specific information, while reducing the diversity of the generated samples. In this paper, we provide the first theoretical study towards understanding the influence of guidance on diffusion models in the context of Gaussian mixture models. Under mild conditions, we prove that incorporating diffusion guidance not only boosts classification confidence but also diminishes distribution diversity, leading to a reduction in the differential entropy of the output distribution. Our analysis covers the widely adopted sampling schemes including DDPM and DDIM, and leverages comparison inequalities for differential equations as well as the Fokker-Planck equation that characterizes the evolution of probability density function, which may be of independent theoretical interest.
Depth Estimation Algorithm Based on Transformer-Encoder and Feature Fusion
Mar 03, 2024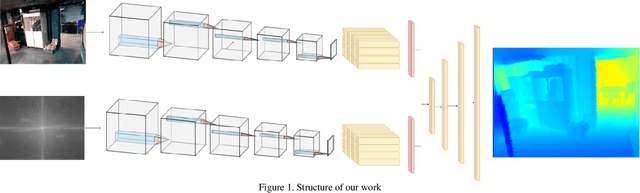
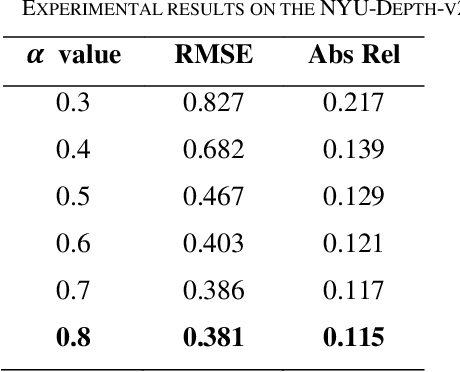
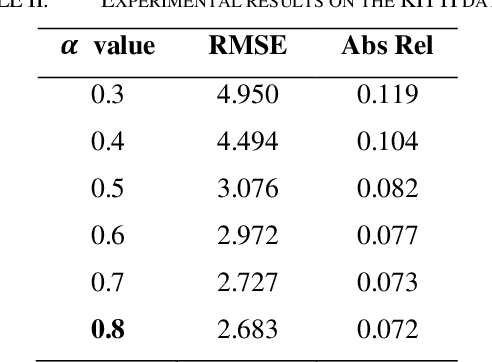

This research presents a novel depth estimation algorithm based on a Transformer-encoder architecture, tailored for the NYU and KITTI Depth Dataset. This research adopts a transformer model, initially renowned for its success in natural language processing, to capture intricate spatial relationships in visual data for depth estimation tasks. A significant innovation of the research is the integration of a composite loss function that combines Structural Similarity Index Measure (SSIM) with Mean Squared Error (MSE). This combined loss function is designed to ensure the structural integrity of the predicted depth maps relative to the original images (via SSIM) while minimizing pixel-wise estimation errors (via MSE). This research approach addresses the challenges of over-smoothing often seen in MSE-based losses and enhances the model's ability to predict depth maps that are not only accurate but also maintain structural coherence with the input images. Through rigorous training and evaluation using the NYU Depth Dataset, the model demonstrates superior performance, marking a significant advancement in single-image depth estimation, particularly in complex indoor and traffic environments.
Demonstrating and Reducing Shortcuts in Vision-Language Representation Learning
Feb 27, 2024Vision-language models (VLMs) mainly rely on contrastive training to learn general-purpose representations of images and captions. We focus on the situation when one image is associated with several captions, each caption containing both information shared among all captions and unique information per caption about the scene depicted in the image. In such cases, it is unclear whether contrastive losses are sufficient for learning task-optimal representations that contain all the information provided by the captions or whether the contrastive learning setup encourages the learning of a simple shortcut that minimizes contrastive loss. We introduce synthetic shortcuts for vision-language: a training and evaluation framework where we inject synthetic shortcuts into image-text data. We show that contrastive VLMs trained from scratch or fine-tuned with data containing these synthetic shortcuts mainly learn features that represent the shortcut. Hence, contrastive losses are not sufficient to learn task-optimal representations, i.e., representations that contain all task-relevant information shared between the image and associated captions. We examine two methods to reduce shortcut learning in our training and evaluation framework: (i) latent target decoding and (ii) implicit feature modification. We show empirically that both methods improve performance on the evaluation task, but only partly reduce shortcut learning when training and evaluating with our shortcut learning framework. Hence, we show the difficulty and challenge of our shortcut learning framework for contrastive vision-language representation learning.
LLMBind: A Unified Modality-Task Integration Framework
Feb 26, 2024While recent progress in multimodal large language models tackles various modality tasks, they posses limited integration capabilities for complex multi-modality tasks, consequently constraining the development of the field. In this work, we take the initiative to explore and propose the LLMBind, a unified framework for modality task integration, which binds Large Language Models and corresponding pre-trained task models with task-specific tokens. Consequently, LLMBind can interpret inputs and produce outputs in versatile combinations of image, text, video, and audio. Specifically, we introduce a Mixture-of-Experts technique to enable effective learning for different multimodal tasks through collaboration among diverse experts. Furthermore, we create a multi-task dataset comprising 400k instruction data, which unlocks the ability for interactive visual generation and editing tasks. Extensive experiments show the effectiveness of our framework across various tasks, including image, video, audio generation, image segmentation, and image editing. More encouragingly, our framework can be easily extended to other modality tasks, showcasing the promising potential of creating a unified AI agent for modeling universal modalities.
Referee Can Play: An Alternative Approach to Conditional Generation via Model Inversion
Feb 26, 2024As a dominant force in text-to-image generation tasks, Diffusion Probabilistic Models (DPMs) face a critical challenge in controllability, struggling to adhere strictly to complex, multi-faceted instructions. In this work, we aim to address this alignment challenge for conditional generation tasks. First, we provide an alternative view of state-of-the-art DPMs as a way of inverting advanced Vision-Language Models (VLMs). With this formulation, we naturally propose a training-free approach that bypasses the conventional sampling process associated with DPMs. By directly optimizing images with the supervision of discriminative VLMs, the proposed method can potentially achieve a better text-image alignment. As proof of concept, we demonstrate the pipeline with the pre-trained BLIP-2 model and identify several key designs for improved image generation. To further enhance the image fidelity, a Score Distillation Sampling module of Stable Diffusion is incorporated. By carefully balancing the two components during optimization, our method can produce high-quality images with near state-of-the-art performance on T2I-Compbench.
KnowPhish: Large Language Models Meet Multimodal Knowledge Graphs for Enhancing Reference-Based Phishing Detection
Mar 04, 2024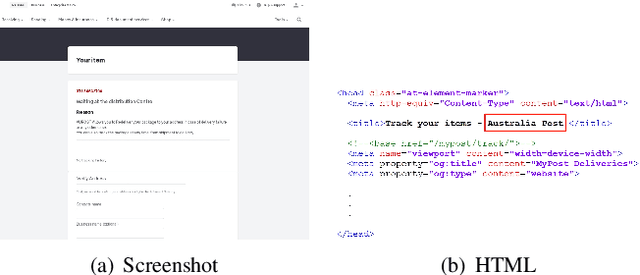

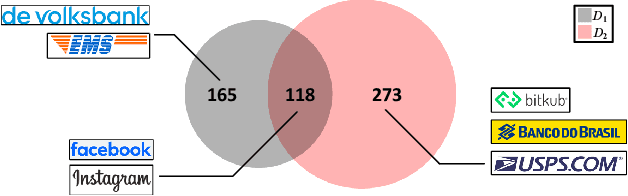

Phishing attacks have inflicted substantial losses on individuals and businesses alike, necessitating the development of robust and efficient automated phishing detection approaches. Reference-based phishing detectors (RBPDs), which compare the logos on a target webpage to a known set of logos, have emerged as the state-of-the-art approach. However, a major limitation of existing RBPDs is that they rely on a manually constructed brand knowledge base, making it infeasible to scale to a large number of brands, which results in false negative errors due to the insufficient brand coverage of the knowledge base. To address this issue, we propose an automated knowledge collection pipeline, using which we collect and release a large-scale multimodal brand knowledge base, KnowPhish, containing 20k brands with rich information about each brand. KnowPhish can be used to boost the performance of existing RBPDs in a plug-and-play manner. A second limitation of existing RBPDs is that they solely rely on the image modality, ignoring useful textual information present in the webpage HTML. To utilize this textual information, we propose a Large Language Model (LLM)-based approach to extract brand information of webpages from text. Our resulting multimodal phishing detection approach, KnowPhish Detector (KPD), can detect phishing webpages with or without logos. We evaluate KnowPhish and KPD on a manually validated dataset, and on a field study under Singapore's local context, showing substantial improvements in effectiveness and efficiency compared to state-of-the-art baselines.
Map-aided annotation for pole base detection
Mar 04, 2024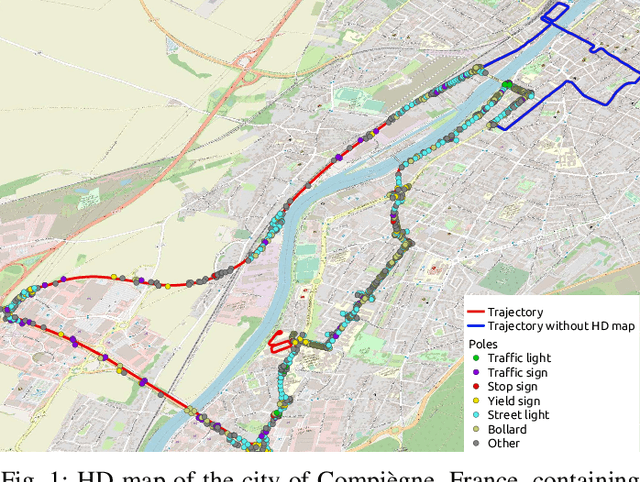



For autonomous navigation, high definition maps are a widely used source of information. Pole-like features encoded in HD maps such as traffic signs, traffic lights or street lights can be used as landmarks for localization. For this purpose, they first need to be detected by the vehicle using its embedded sensors. While geometric models can be used to process 3D point clouds retrieved by lidar sensors, modern image-based approaches rely on deep neural network and therefore heavily depend on annotated training data. In this paper, a 2D HD map is used to automatically annotate pole-like features in images. In the absence of height information, the map features are represented as pole bases at the ground level. We show how an additional lidar sensor can be used to filter out occluded features and refine the ground projection. We also demonstrate how an object detector can be trained to detect a pole base. To evaluate our methodology, it is first validated with data manually annotated from semantic segmentation and then compared to our own automatically generated annotated data recorded in the city of Compi{\`e}gne, France. Erratum: In the original version [1], an error occurred in the accuracy evaluation of the different models studied and the evaluation method applied on the detection results was not clearly defined. In this revision, we offer a rectification to this segment, presenting updated results, especially in terms of Mean Absolute Errors (MAE).