 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Incremental Learning with Differentiable Architecture and Forgetting Search
May 19, 2022
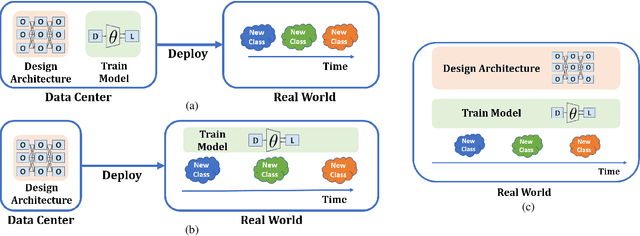
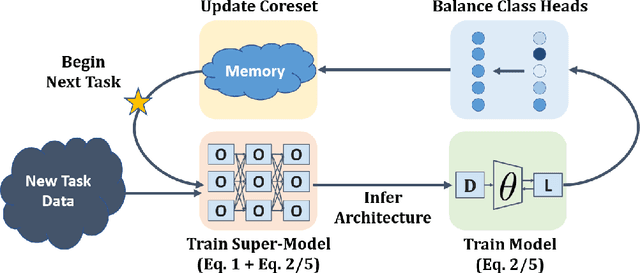
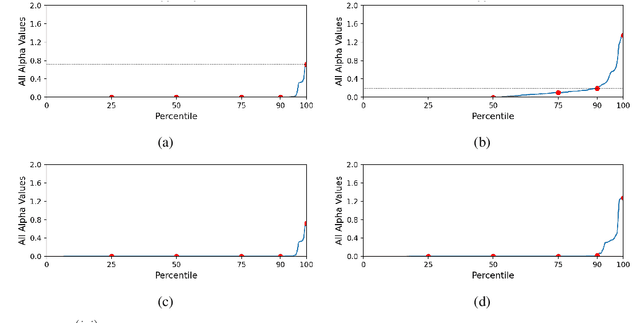
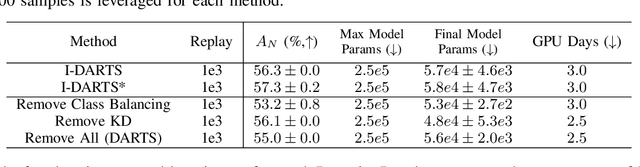
As progress is made on training machine learning models on incrementally expanding classification tasks (i.e., incremental learning), a next step is to translate this progress to industry expectations. One technique missing from incremental learning is automatic architecture design via Neural Architecture Search (NAS). In this paper, we show that leveraging NAS for incremental learning results in strong performance gains for classification tasks. Specifically, we contribute the following: first, we create a strong baseline approach for incremental learning based on Differentiable Architecture Search (DARTS) and state-of-the-art incremental learning strategies, outperforming many existing strategies trained with similar-sized popular architectures; second, we extend the idea of architecture search to regularize architecture forgetting, boosting performance past our proposed baseline. We evaluate our method on both RF signal and image classification tasks, and demonstrate we can achieve up to a 10% performance increase over state-of-the-art methods. Most importantly, our contribution enables learning from continuous distributions on real-world application data for which the complexity of the data distribution is unknown, or the modality less explored (such as RF signal classification).
Human Gender Prediction Based on Deep Transfer Learning from Panoramic Radiograph Images
May 19, 2022
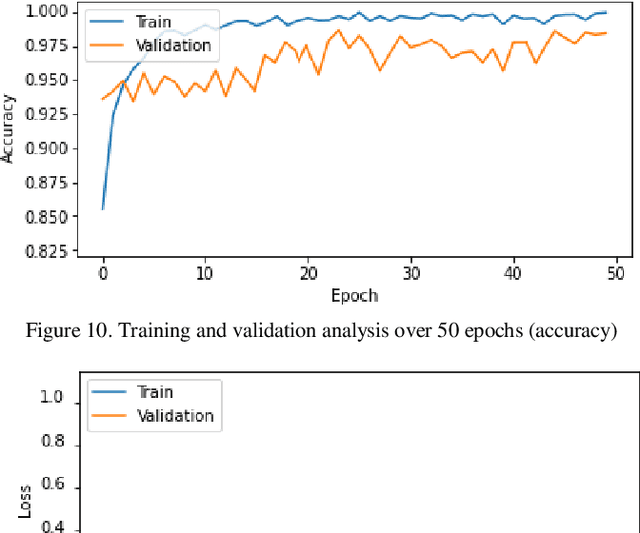
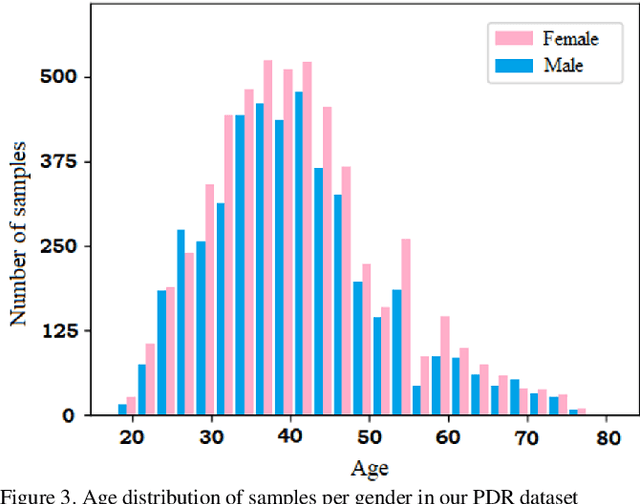
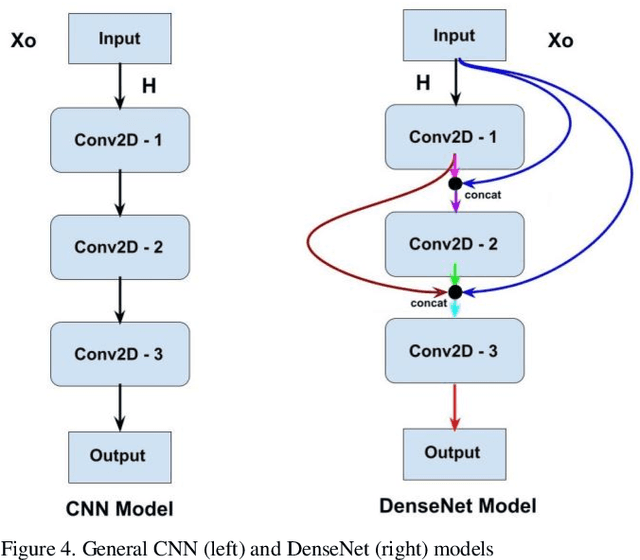
Panoramic Dental Radiography (PDR) image processing is one of the most extensively used manual methods for gender determination in forensic medicine. Manual approaches require a wide range of mandibular parameter measurements in metric units. Besides being time-consuming, these methods also necessitate the employment of experienced professionals. In this context, deep learning models are widely utilized in the auto-analysis of radiological images nowadays, owing to their high processing speed, accuracy, and stability. In our study, a data set consisting of 24,000 dental panoramic images was prepared for binary classification, and the transfer learning method was used to accelerate the training and increase the performance of our proposed DenseNet121 deep learning model. With the transfer learning method, instead of starting the learning process from scratch, the existing patterns learned beforehand were used. Extensive comparisons were made using deep transfer learning (DTL) models VGG16, ResNet50, and EfficientNetB6 to assess the classification performance of the proposed model in PDR images. According to the findings of the comparative analysis, the proposed model outperformed the other approaches by achieving a success rate of 97.25% in gender classification.
Cross-view and Cross-domain Underwater Localization based on Optical Aerial and Acoustic Underwater Images
Feb 16, 2022
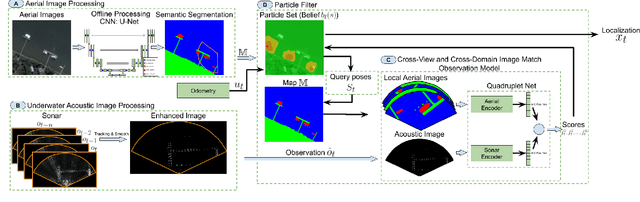

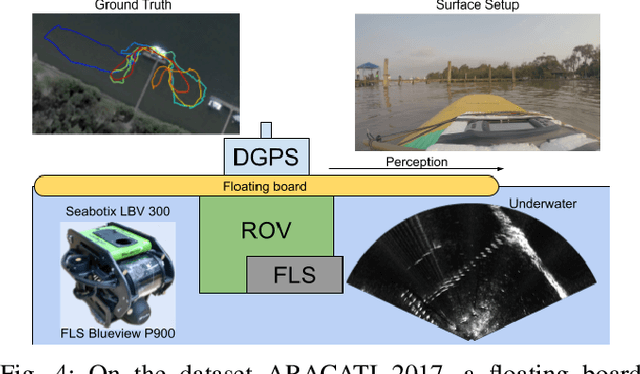
Cross-view image matches have been widely explored on terrestrial image localization using aerial images from drones or satellites. This study expands the cross-view image match idea and proposes a cross-domain and cross-view localization framework. The method identifies the correlation between color aerial images and underwater acoustic images to improve the localization of underwater vehicles that travel in partially structured environments such as harbors and marinas. The approach is validated on a real dataset acquired by an underwater vehicle in a marina. The results show an improvement in the localization when compared to the dead reckoning of the vehicle.
Fake It Till You Make It: Near-Distribution Novelty Detection by Score-Based Generative Models
May 28, 2022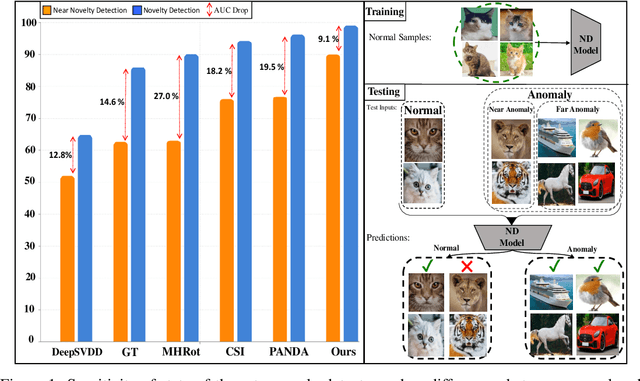
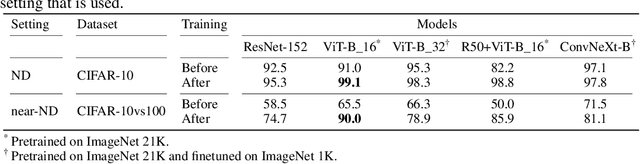
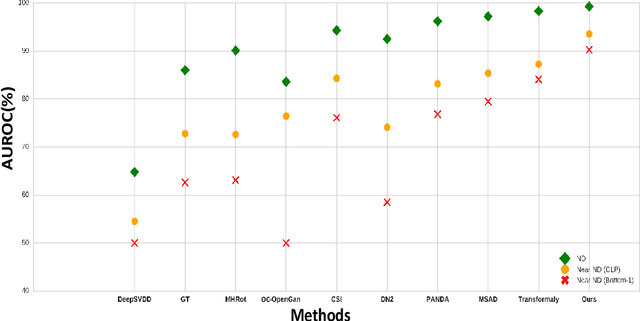
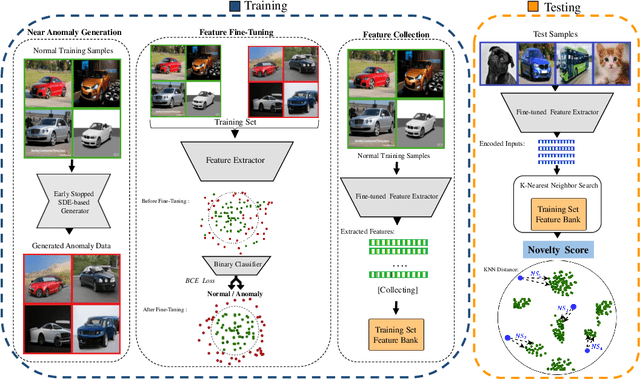
We aim for image-based novelty detection. Despite considerable progress, existing models either fail or face a dramatic drop under the so-called ``near-distribution" setting, where the differences between normal and anomalous samples are subtle. We first demonstrate existing methods experience up to 20\% decrease in performance in the near-distribution setting. Next, we propose to exploit a score-based generative model to produce synthetic near-distribution anomalous data. Our model is then fine-tuned to distinguish such data from the normal samples. We provide a quantitative as well as qualitative evaluation of this strategy, and compare the results with a variety of GAN-based models. Effectiveness of our method for both the near-distribution and standard novelty detection is assessed through extensive experiments on datasets in diverse applications such as medical images, object classification, and quality control. This reveals that our method considerably improves over existing models, and consistently decreases the gap between the near-distribution and standard novelty detection performance. Overall, our method improves the near-distribution novelty detection by 6% and passes the state-of-the-art by 1% to 5% across nine novelty detection benchmarks. The code repository is available at https://github.com/rohban-lab/FITYMI
ObjectAug: Object-level Data Augmentation for Semantic Image Segmentation
Jan 30, 2021
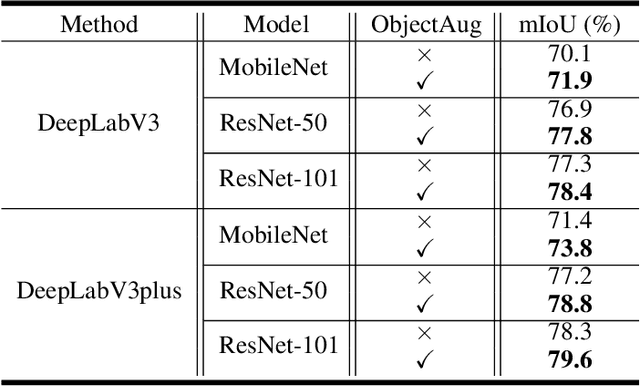

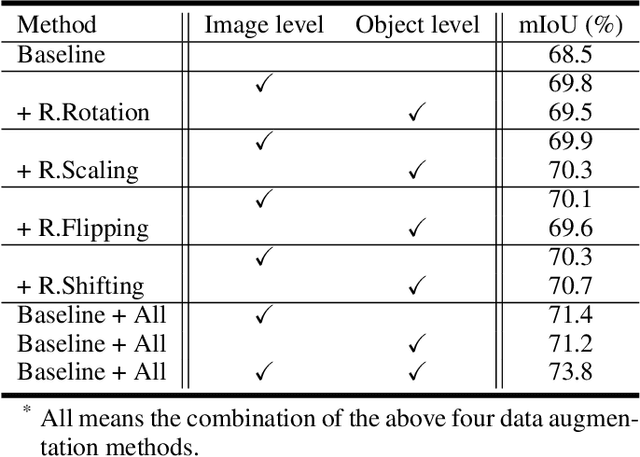
Semantic image segmentation aims to obtain object labels with precise boundaries, which usually suffers from overfitting. Recently, various data augmentation strategies like regional dropout and mix strategies have been proposed to address the problem. These strategies have proved to be effective for guiding the model to attend on less discriminative parts. However, current strategies operate at the image level, and objects and the background are coupled. Thus, the boundaries are not well augmented due to the fixed semantic scenario. In this paper, we propose ObjectAug to perform object-level augmentation for semantic image segmentation. ObjectAug first decouples the image into individual objects and the background using the semantic labels. Next, each object is augmented individually with commonly used augmentation methods (e.g., scaling, shifting, and rotation). Then, the black area brought by object augmentation is further restored using image inpainting. Finally, the augmented objects and background are assembled as an augmented image. In this way, the boundaries can be fully explored in the various semantic scenarios. In addition, ObjectAug can support category-aware augmentation that gives various possibilities to objects in each category, and can be easily combined with existing image-level augmentation methods to further boost performance. Comprehensive experiments are conducted on both natural image and medical image datasets. Experiment results demonstrate that our ObjectAug can evidently improve segmentation performance.
SIGAN: A Novel Image Generation Method for Solar Cell Defect Segmentation and Augmentation
Apr 11, 2021
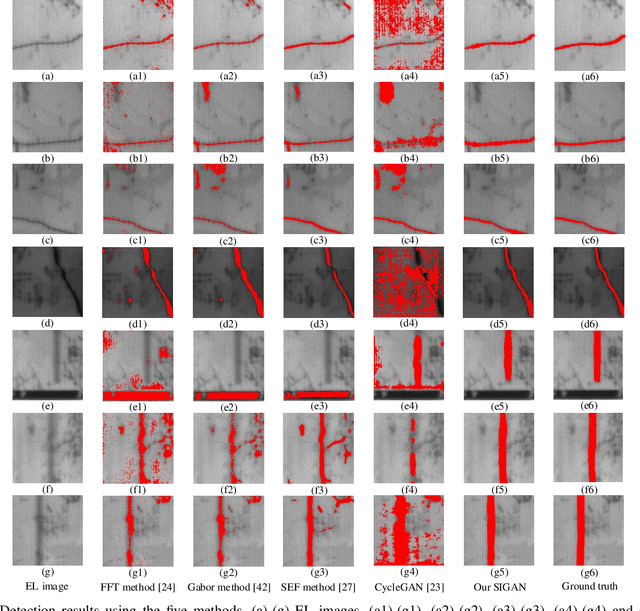
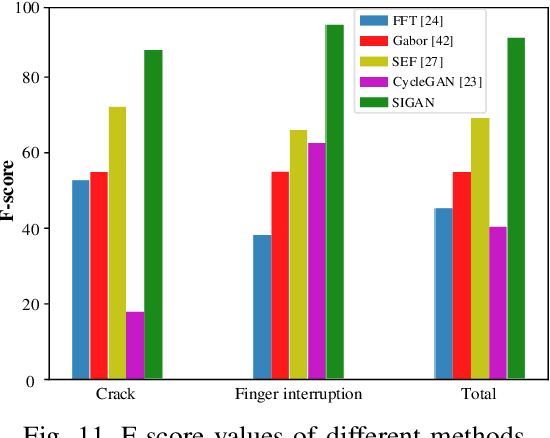
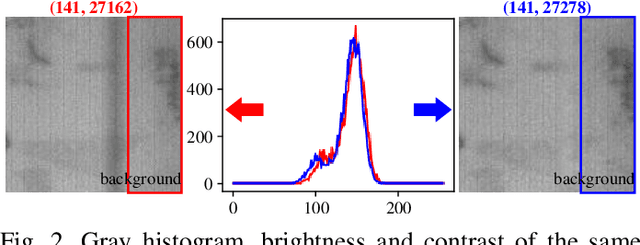
Solar cell electroluminescence (EL) defect segmentation is an interesting and challenging topic. Many methods have been proposed for EL defect detection, but these methods are still unsatisfactory due to the diversity of the defect and background. In this paper, we provide a new idea of using generative adversarial network (GAN) for defect segmentation. Firstly, the GAN-based method removes the defect region in the input defective image to get a defect-free image, while keeping the background almost unchanged. Then, the subtracted image is obtained by making difference between the defective input image with the generated defect-free image. Finally, the defect region can be segmented through thresholding the subtracted image. To keep the background unchanged before and after image generation, we propose a novel strong identity GAN (SIGAN), which adopts a novel strong identity loss to constraint the background consistency. The SIGAN can be used not only for defect segmentation, but also small-samples defective dataset augmentation. Moreover, we release a new solar cell EL image dataset named as EL-2019, which includes three types of images: crack, finger interruption and defect-free. Experiments on EL-2019 dataset show that the proposed method achieves 90.34% F-score, which outperforms many state-of-the-art methods in terms of solar cell defects segmentation results.
Decision boundaries and convex hulls in the feature space that deep learning functions learn from images
Feb 17, 2022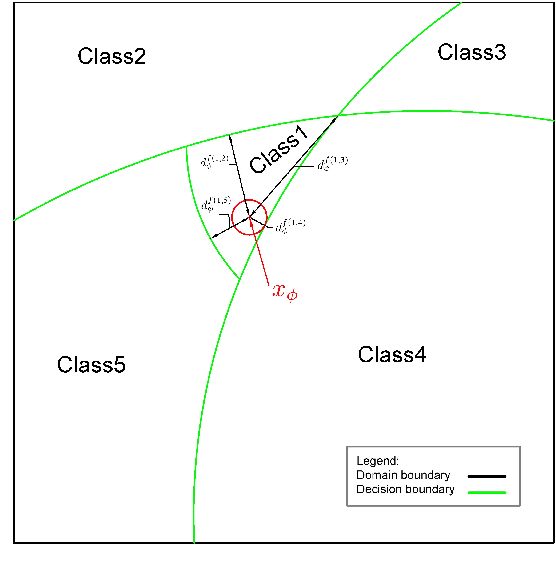
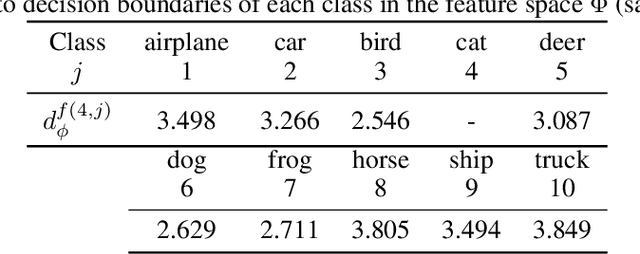
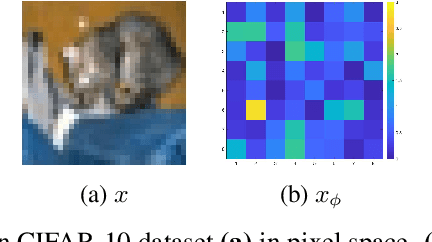
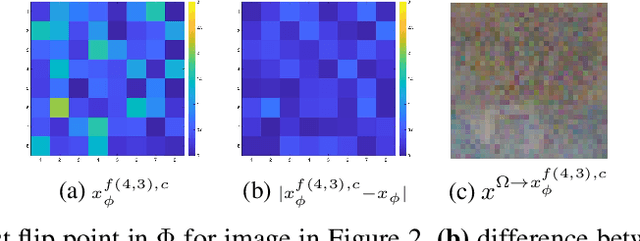
The success of deep neural networks in image classification and learning can be partly attributed to the features they extract from images. It is often speculated about the properties of a low-dimensional manifold that models extract and learn from images. However, there is not sufficient understanding about this low-dimensional space based on theory or empirical evidence. For image classification models, their last hidden layer is the one where images of each class is separated from other classes and it also has the least number of features. Here, we develop methods and formulations to study that feature space for any model. We study the partitioning of the domain in feature space, identify regions guaranteed to have certain classifications, and investigate its implications for the pixel space. We observe that geometric arrangements of decision boundaries in feature space is significantly different compared to pixel space, providing insights about adversarial vulnerabilities, image morphing, extrapolation, ambiguity in classification, and the mathematical understanding of image classification models.
Towards Accurate Text-based Image Captioning with Content Diversity Exploration
Apr 23, 2021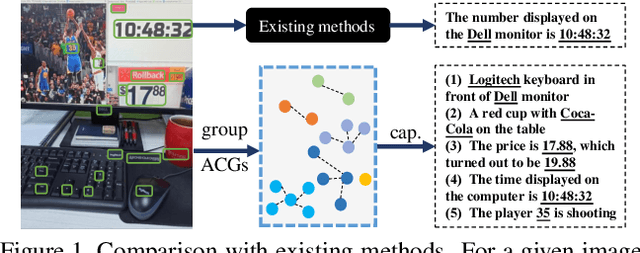
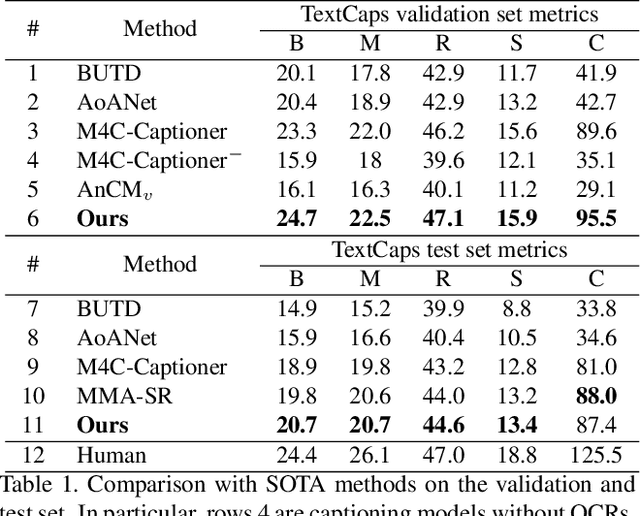
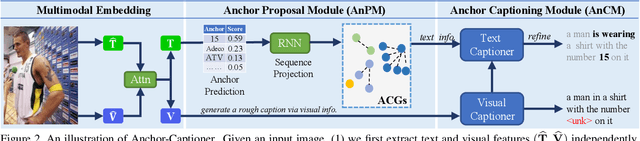
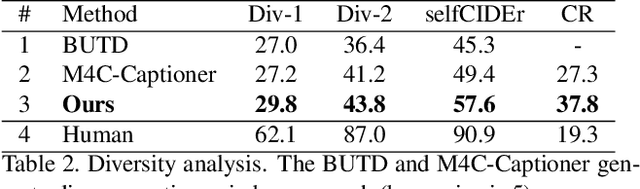
Text-based image captioning (TextCap) which aims to read and reason images with texts is crucial for a machine to understand a detailed and complex scene environment, considering that texts are omnipresent in daily life. This task, however, is very challenging because an image often contains complex texts and visual information that is hard to be described comprehensively. Existing methods attempt to extend the traditional image captioning methods to solve this task, which focus on describing the overall scene of images by one global caption. This is infeasible because the complex text and visual information cannot be described well within one caption. To resolve this difficulty, we seek to generate multiple captions that accurately describe different parts of an image in detail. To achieve this purpose, there are three key challenges: 1) it is hard to decide which parts of the texts of images to copy or paraphrase; 2) it is non-trivial to capture the complex relationship between diverse texts in an image; 3) how to generate multiple captions with diverse content is still an open problem. To conquer these, we propose a novel Anchor-Captioner method. Specifically, we first find the important tokens which are supposed to be paid more attention to and consider them as anchors. Then, for each chosen anchor, we group its relevant texts to construct the corresponding anchor-centred graph (ACG). Last, based on different ACGs, we conduct multi-view caption generation to improve the content diversity of generated captions. Experimental results show that our method not only achieves SOTA performance but also generates diverse captions to describe images.
Distributionally Robust Multiclass Classification and Applications in Deep CNN Image Classifiers
Sep 27, 2021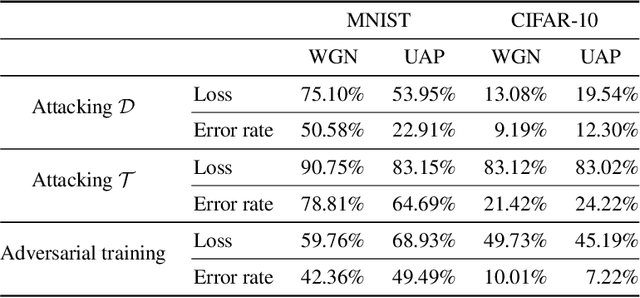
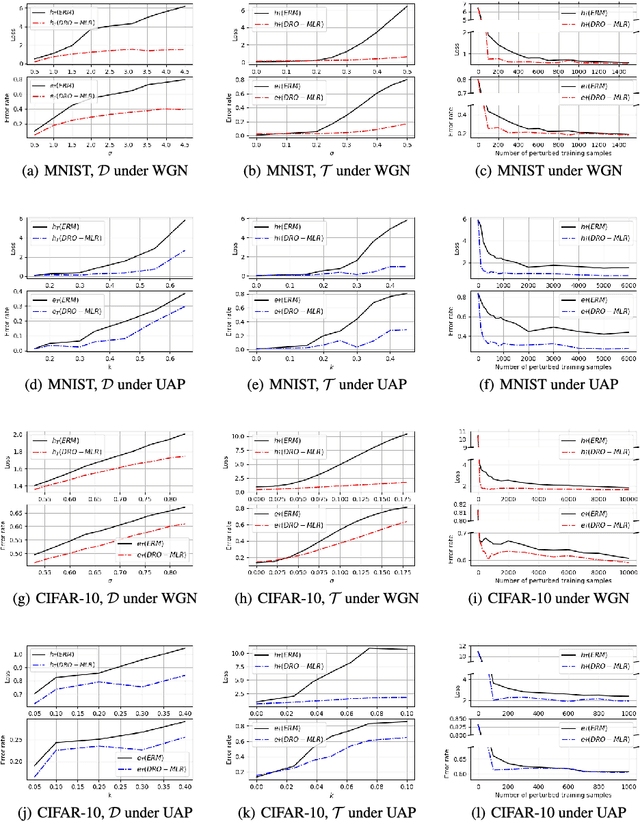
We develop a Distributionally Robust Optimization (DRO) formulation for Multiclass Logistic Regression (MLR), which could tolerate data contaminated by outliers. The DRO framework uses a probabilistic ambiguity set defined as a ball of distributions that are close to the empirical distribution of the training set in the sense of the Wasserstein metric. We relax the DRO formulation into a regularized learning problem whose regularizer is a norm of the coefficient matrix. We establish out-of-sample performance guarantees for the solutions to our model, offering insights on the role of the regularizer in controlling the prediction error. We apply the proposed method in rendering deep CNN-based image classifiers robust to random and adversarial attacks. Specifically, using the MNIST and CIFAR-10 datasets, we demonstrate reductions in test error rate by up to 78.8% and loss by up to 90.8%. We also show that with a limited number of perturbed images in the training set, our method can improve the error rate by up to 49.49% and the loss by up to 68.93% compared to Empirical Risk Minimization (ERM), converging faster to an ideal loss/error rate as the number of perturbed images increases.
TransClaw U-Net: Claw U-Net with Transformers for Medical Image Segmentation
Jul 12, 2021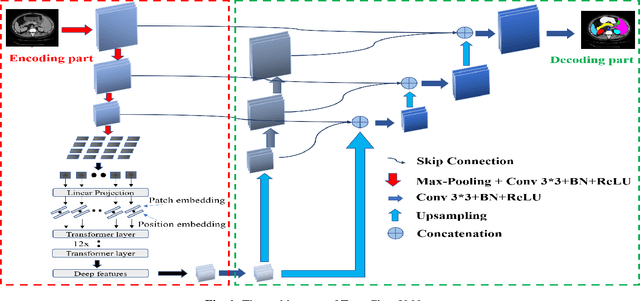
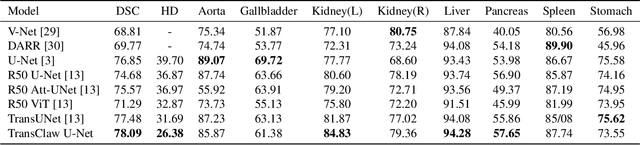
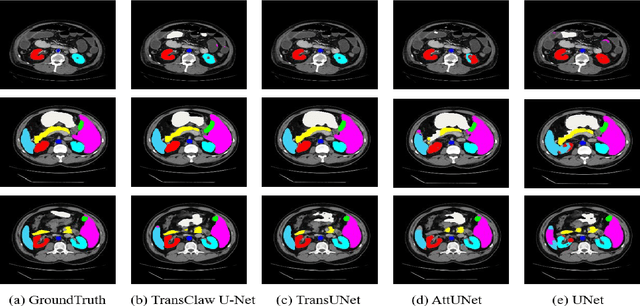

In recent years, computer-aided diagnosis has become an increasingly popular topic. Methods based on convolutional neural networks have achieved good performance in medical image segmentation and classification. Due to the limitations of the convolution operation, the long-term spatial features are often not accurately obtained. Hence, we propose a TransClaw U-Net network structure, which combines the convolution operation with the transformer operation in the encoding part. The convolution part is applied for extracting the shallow spatial features to facilitate the recovery of the image resolution after upsampling. The transformer part is used to encode the patches, and the self-attention mechanism is used to obtain global information between sequences. The decoding part retains the bottom upsampling structure for better detail segmentation performance. The experimental results on Synapse Multi-organ Segmentation Datasets show that the performance of TransClaw U-Net is better than other network structures. The ablation experiments also prove the generalization performance of TransClaw U-Net.