 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Computer-Aided Extraction of Select MRI Markers of Cerebral Small Vessel Disease: A Systematic Review
Apr 04, 2022
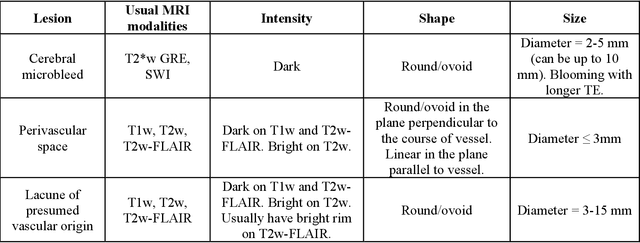
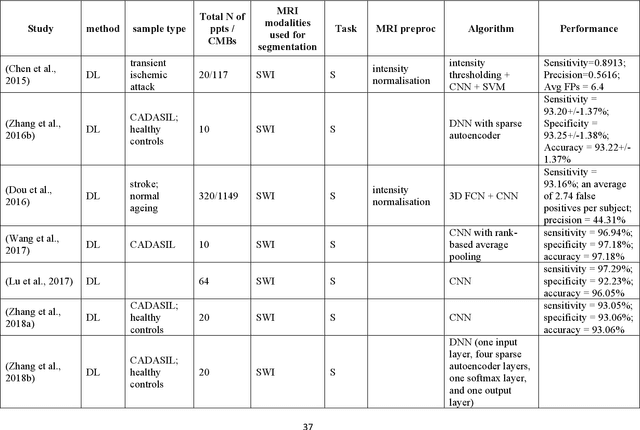
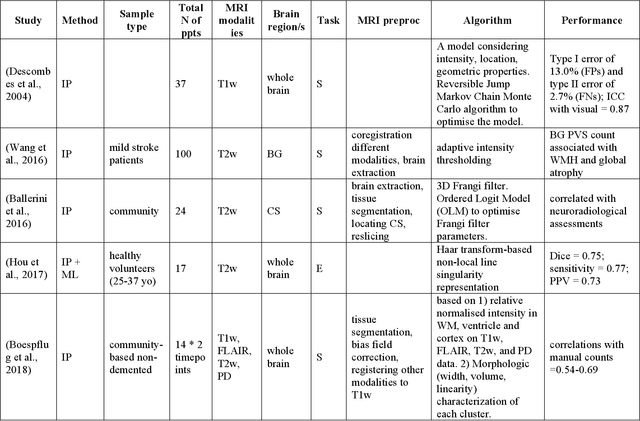
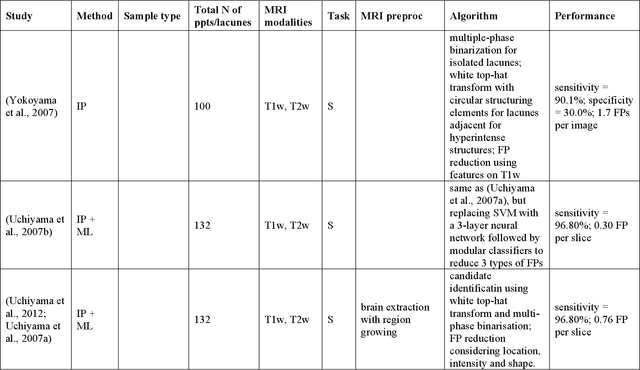
Cerebral small vessel disease (CSVD) is a major vascular contributor to cognitive impairment in ageing, including dementias. Imaging remains the most promising method for in vivo studies of CSVD. To replace the subjective and laborious visual rating approaches, emerging studies have applied state-of-the-art artificial intelligence to extract imaging biomarkers of CSVD from MRI scans. We aimed to summarise published computer-aided methods to examine three imaging biomarkers of CSVD, namely cerebral microbleeds (CMB), dilated perivascular spaces (PVS), and lacunes of presumed vascular origin. Seventy-one classical image processing, classical machine learning, and deep learning studies were identified. CMB and PVS have been better studied, compared to lacunes. While good performance metrics have been achieved in local test datasets, there have not been generalisable pipelines validated in different research or clinical cohorts. Transfer learning and weak supervision techniques have been applied to accommodate the limitations in training data. Future studies could consider pooling data from multiple sources to increase diversity, and validating the performance of the methods using both image processing metrics and associations with clinical measures.
Absolute Triangulation Algorithms for Space Exploration
May 24, 2022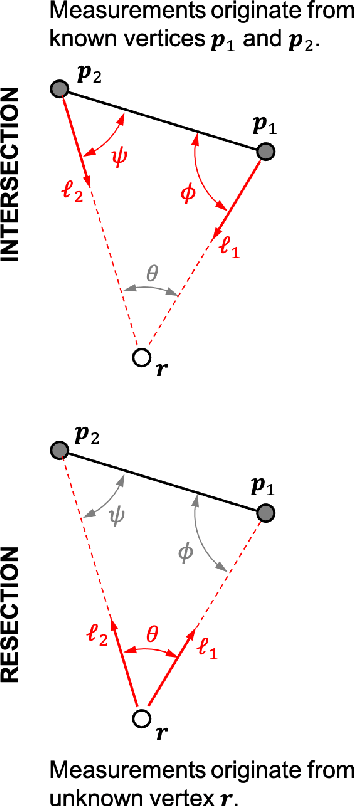
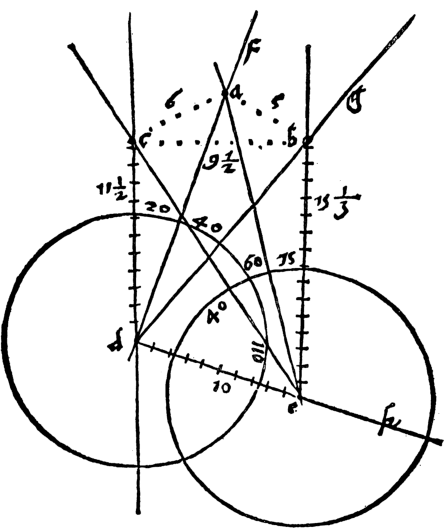

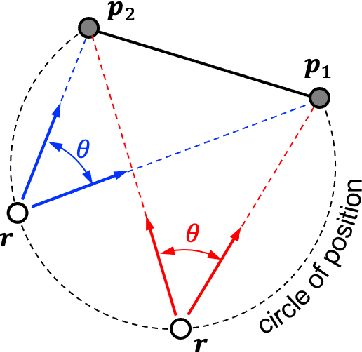
Images are an important source of information for spacecraft navigation and for three-dimensional reconstruction of observed space objects. Both of these applications take the form of a triangulation problem when the camera has a known attitude and the measurements extracted from the image are line of sight (LOS) directions. This work provides a comprehensive review of the history and theoretical foundations of triangulation. A variety of classical triangulation algorithms are reviewed, including a number of suboptimal linear methods (many LOS measurements) and the optimal method of Hartley and Sturm (only two LOS measurements). Two new optimal non-iterative triangulation algorithms are introduced that provide the same solution as Hartley and Sturm. The optimal two-measurement case can be solved as a quadratic equation in many common situations. The optimal many-measurement case may be solved without iteration as a linear system using the new Linear Optimal Sine Triangulation (LOST) method. The various triangulation algorithms are assessed with a few numerical examples, including planetary terrain relative navigation, angles-only optical navigation at Uranus, 3-D reconstruction of Notre-Dame de Paris, and angles-only relative navigation.
Rethinking Evaluation Practices in Visual Question Answering: A Case Study on Out-of-Distribution Generalization
May 24, 2022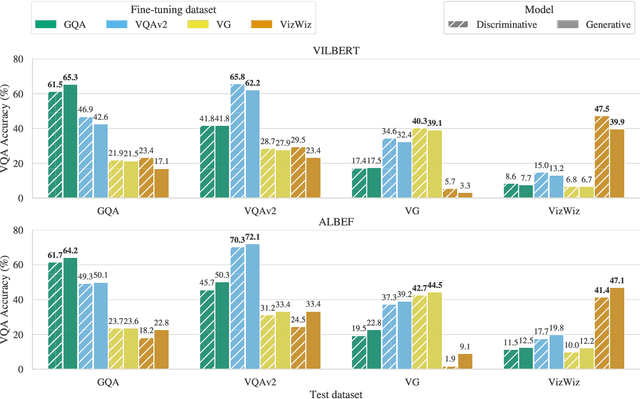
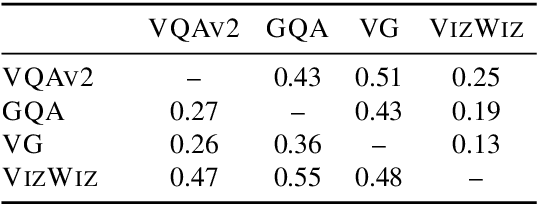
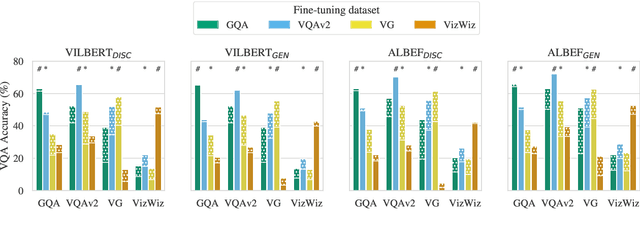
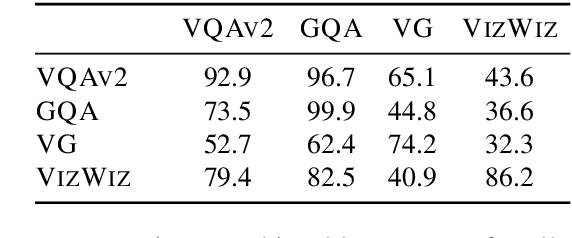
Vision-and-language (V&L) models pretrained on large-scale multimodal data have demonstrated strong performance on various tasks such as image captioning and visual question answering (VQA). The quality of such models is commonly assessed by measuring their performance on unseen data that typically comes from the same distribution as the training data. However, we observe that these models exhibit poor out-of-distribution (OOD) generalization on the task of VQA. To better understand the underlying causes of poor generalization, we comprehensively investigate performance of two pretrained V&L models under different settings (i.e. classification and open-ended text generation) by conducting cross-dataset evaluations. We find that these models tend to learn to solve the benchmark, rather than learning the high-level skills required by the VQA task. We also argue that in most cases generative models are less susceptible to shifts in data distribution, while frequently performing better on our tested benchmarks. Moreover, we find that multimodal pretraining improves OOD performance in most settings. Finally, we revisit assumptions underlying the use of automatic VQA evaluation metrics, and empirically show that their stringent nature repeatedly penalizes models for correct responses.
Learning to Prompt for Open-Vocabulary Object Detection with Vision-Language Model
Mar 28, 2022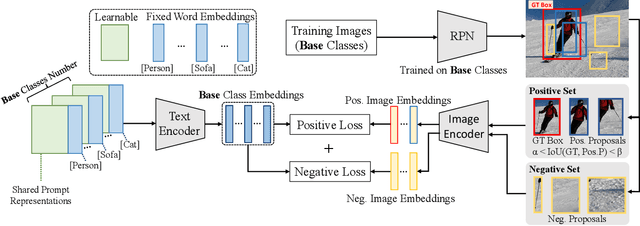
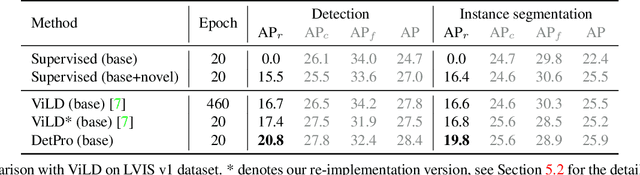
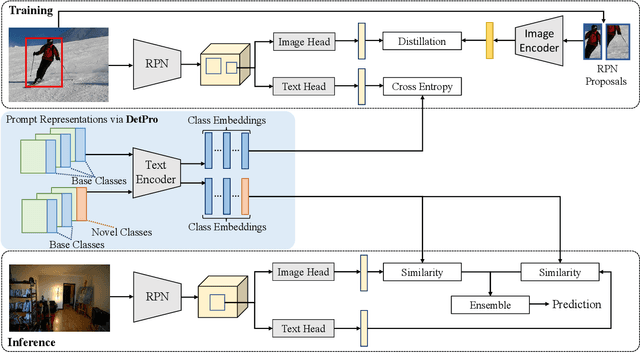

Recently, vision-language pre-training shows great potential in open-vocabulary object detection, where detectors trained on base classes are devised for detecting new classes. The class text embedding is firstly generated by feeding prompts to the text encoder of a pre-trained vision-language model. It is then used as the region classifier to supervise the training of a detector. The key element that leads to the success of this model is the proper prompt, which requires careful words tuning and ingenious design. To avoid laborious prompt engineering, there are some prompt representation learning methods being proposed for the image classification task, which however can only be sub-optimal solutions when applied to the detection task. In this paper, we introduce a novel method, detection prompt (DetPro), to learn continuous prompt representations for open-vocabulary object detection based on the pre-trained vision-language model. Different from the previous classification-oriented methods, DetPro has two highlights: 1) a background interpretation scheme to include the proposals in image background into the prompt training; 2) a context grading scheme to separate proposals in image foreground for tailored prompt training. We assemble DetPro with ViLD, a recent state-of-the-art open-world object detector, and conduct experiments on the LVIS as well as transfer learning on the Pascal VOC, COCO, Objects365 datasets. Experimental results show that our DetPro outperforms the baseline ViLD in all settings, e.g., +3.4 APbox and +3.0 APmask improvements on the novel classes of LVIS. Code and models are available at https://github.com/dyabel/detpro.
A Deep Learning Generative Model Approach for Image Synthesis of Plant Leaves
Nov 05, 2021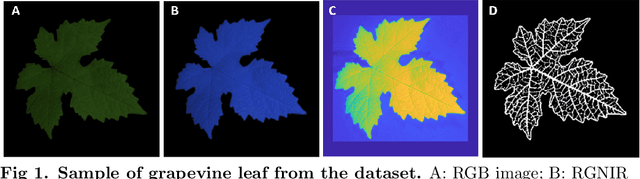
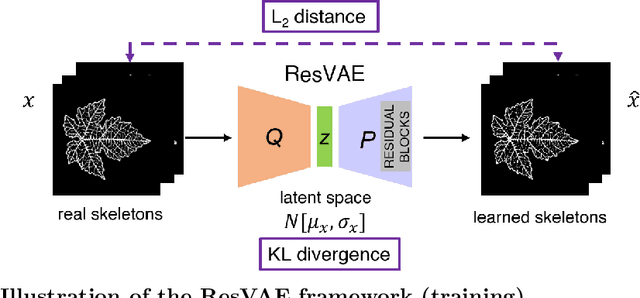
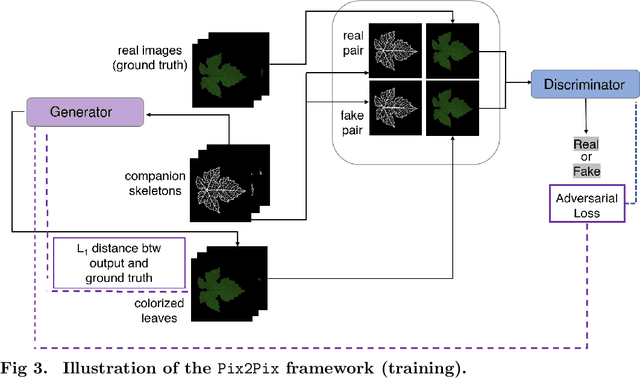
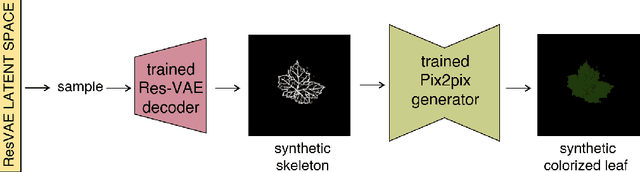
Objectives. We generate via advanced Deep Learning (DL) techniques artificial leaf images in an automatized way. We aim to dispose of a source of training samples for AI applications for modern crop management. Such applications require large amounts of data and, while leaf images are not truly scarce, image collection and annotation remains a very time--consuming process. Data scarcity can be addressed by augmentation techniques consisting in simple transformations of samples belonging to a small dataset, but the richness of the augmented data is limited: this motivates the search for alternative approaches. Methods. Pursuing an approach based on DL generative models, we propose a Leaf-to-Leaf Translation (L2L) procedure structured in two steps: first, a residual variational autoencoder architecture generates synthetic leaf skeletons (leaf profile and veins) starting from companions binarized skeletons of real images. In a second step, we perform translation via a Pix2pix framework, which uses conditional generator adversarial networks to reproduce the colorization of leaf blades, preserving the shape and the venation pattern. Results. The L2L procedure generates synthetic images of leaves with a realistic appearance. We address the performance measurement both in a qualitative and a quantitative way; for this latter evaluation, we employ a DL anomaly detection strategy which quantifies the degree of anomaly of synthetic leaves with respect to real samples. Conclusions. Generative DL approaches have the potential to be a new paradigm to provide low-cost meaningful synthetic samples for computer-aided applications. The present L2L approach represents a step towards this goal, being able to generate synthetic samples with a relevant qualitative and quantitative resemblance to real leaves.
Decision boundaries and convex hulls in the feature space that deep learning functions learn from images
Feb 17, 2022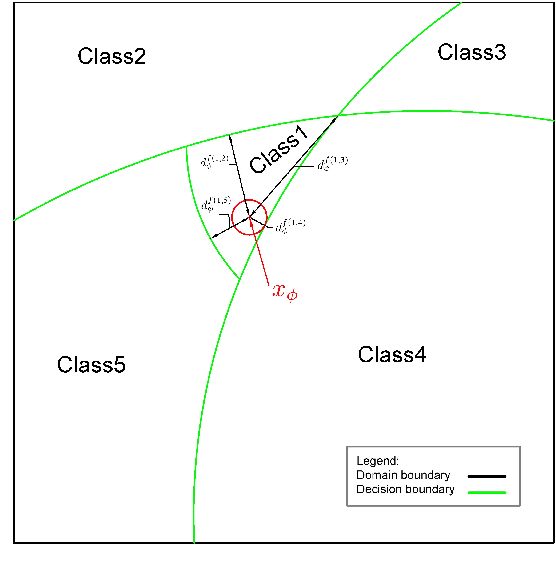
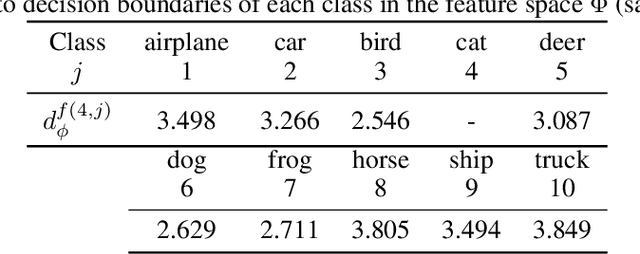
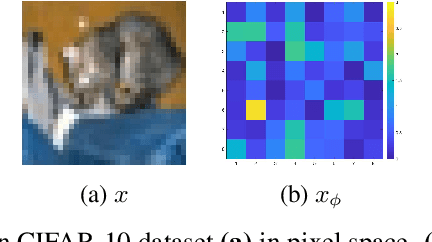
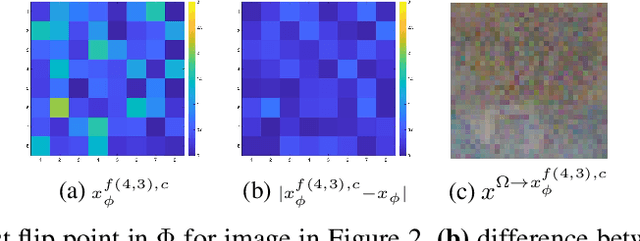
The success of deep neural networks in image classification and learning can be partly attributed to the features they extract from images. It is often speculated about the properties of a low-dimensional manifold that models extract and learn from images. However, there is not sufficient understanding about this low-dimensional space based on theory or empirical evidence. For image classification models, their last hidden layer is the one where images of each class is separated from other classes and it also has the least number of features. Here, we develop methods and formulations to study that feature space for any model. We study the partitioning of the domain in feature space, identify regions guaranteed to have certain classifications, and investigate its implications for the pixel space. We observe that geometric arrangements of decision boundaries in feature space is significantly different compared to pixel space, providing insights about adversarial vulnerabilities, image morphing, extrapolation, ambiguity in classification, and the mathematical understanding of image classification models.
CLCNet: Rethinking of Ensemble Modeling with Classification Confidence Network
May 20, 2022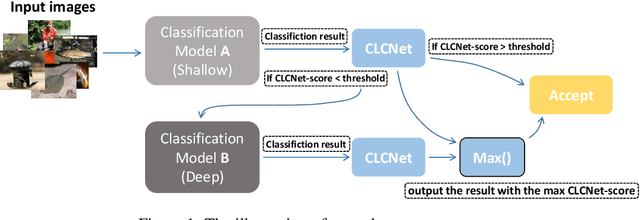
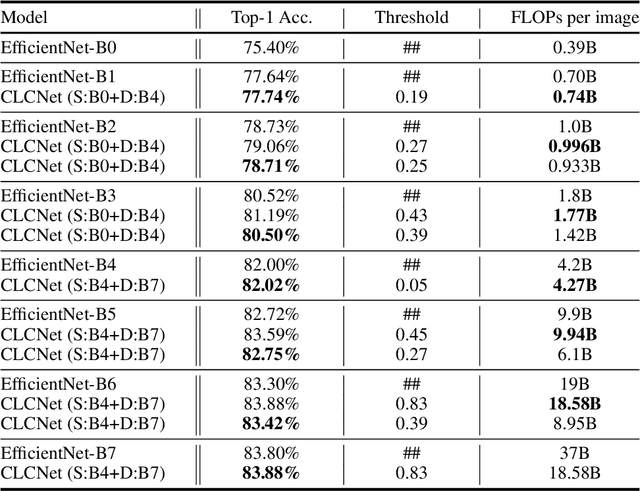
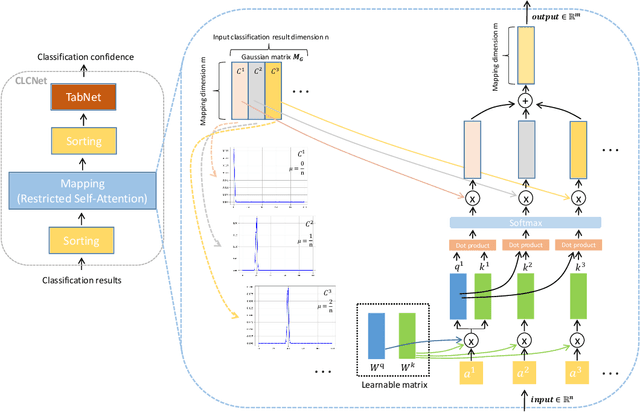
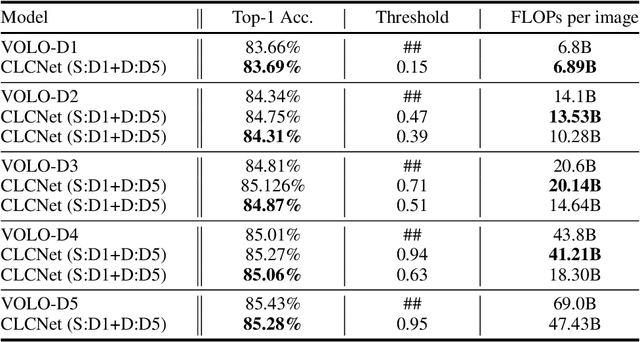
In this paper, we propose a Classification Confidence Network (CLCNet) that can determine whether the classification model classifies input samples correctly. It can take a classification result in the form of vector in any dimension, and return a confidence score as output, which represents the probability of an instance being classified correctly. We can utilize CLCNet in a simple cascade structure system consisting of several SOTA (state-of-the-art) classification models, and our experiments show that the system can achieve the following advantages: 1. The system can customize the average computation requirement (FLOPs) per image while inference. 2. Under the same computation requirement, the performance of the system can exceed any model that has identical structure with the model in the system, but different in size. In fact, this is a new type of ensemble modeling. Like general ensemble modeling, it can achieve higher performance than single classification model, yet our system requires much less computation than general ensemble modeling. We have uploaded our code to a github repository: https://github.com/yaoching0/CLCNet-Rethinking-of-Ensemble-Modeling.
AmsterTime: A Visual Place Recognition Benchmark Dataset for Severe Domain Shift
Mar 30, 2022
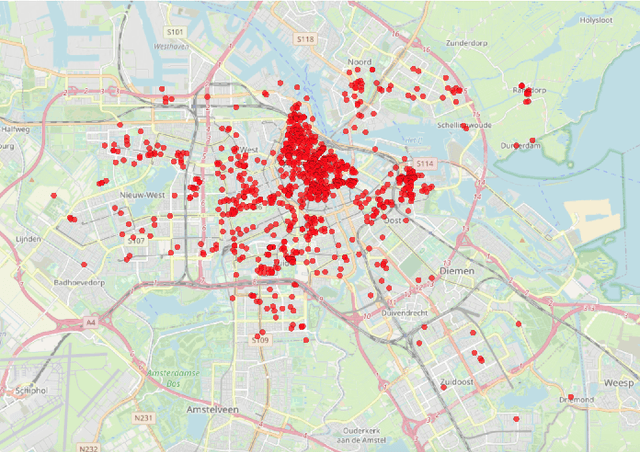

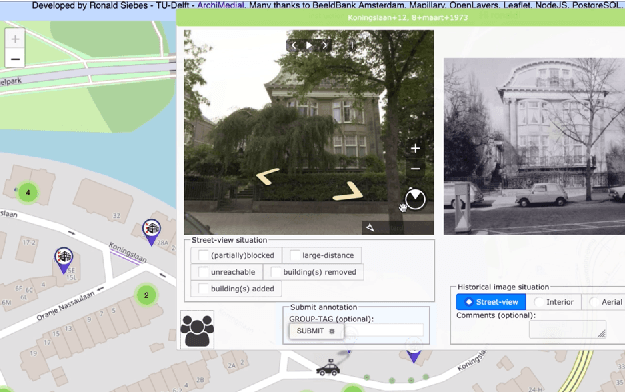
We introduce AmsterTime: a challenging dataset to benchmark visual place recognition (VPR) in presence of a severe domain shift. AmsterTime offers a collection of 2,500 well-curated images matching the same scene from a street view matched to historical archival image data from Amsterdam city. The image pairs capture the same place with different cameras, viewpoints, and appearances. Unlike existing benchmark datasets, AmsterTime is directly crowdsourced in a GIS navigation platform (Mapillary). We evaluate various baselines, including non-learning, supervised and self-supervised methods, pre-trained on different relevant datasets, for both verification and retrieval tasks. Our result credits the best accuracy to the ResNet-101 model pre-trained on the Landmarks dataset for both verification and retrieval tasks by 84% and 24%, respectively. Additionally, a subset of Amsterdam landmarks is collected for feature evaluation in a classification task. Classification labels are further used to extract the visual explanations using Grad-CAM for inspection of the learned similar visuals in a deep metric learning models.
Towards Accurate Text-based Image Captioning with Content Diversity Exploration
Apr 23, 2021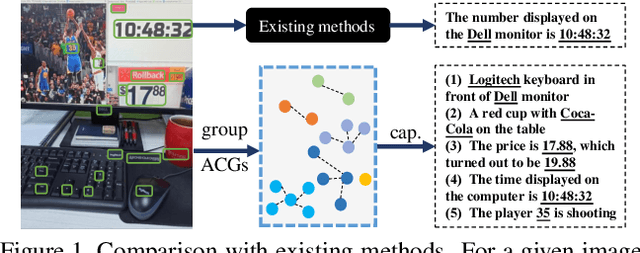
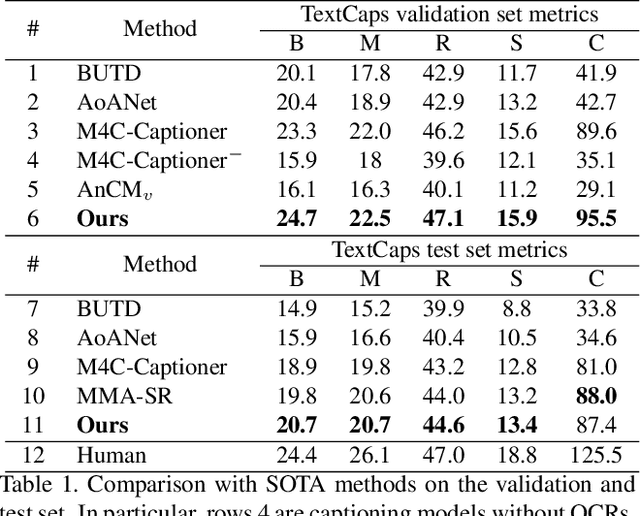
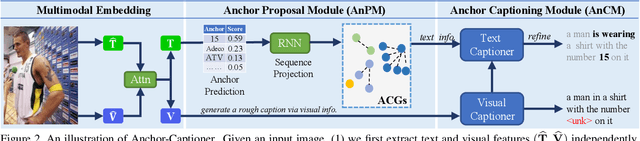
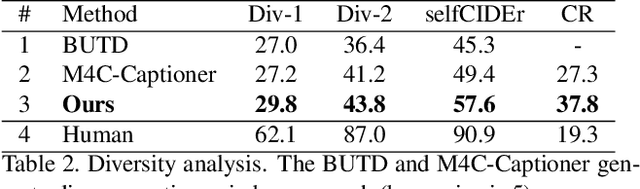
Text-based image captioning (TextCap) which aims to read and reason images with texts is crucial for a machine to understand a detailed and complex scene environment, considering that texts are omnipresent in daily life. This task, however, is very challenging because an image often contains complex texts and visual information that is hard to be described comprehensively. Existing methods attempt to extend the traditional image captioning methods to solve this task, which focus on describing the overall scene of images by one global caption. This is infeasible because the complex text and visual information cannot be described well within one caption. To resolve this difficulty, we seek to generate multiple captions that accurately describe different parts of an image in detail. To achieve this purpose, there are three key challenges: 1) it is hard to decide which parts of the texts of images to copy or paraphrase; 2) it is non-trivial to capture the complex relationship between diverse texts in an image; 3) how to generate multiple captions with diverse content is still an open problem. To conquer these, we propose a novel Anchor-Captioner method. Specifically, we first find the important tokens which are supposed to be paid more attention to and consider them as anchors. Then, for each chosen anchor, we group its relevant texts to construct the corresponding anchor-centred graph (ACG). Last, based on different ACGs, we conduct multi-view caption generation to improve the content diversity of generated captions. Experimental results show that our method not only achieves SOTA performance but also generates diverse captions to describe images.
On Improving Cross-dataset Generalization of Deepfake Detectors
Apr 08, 2022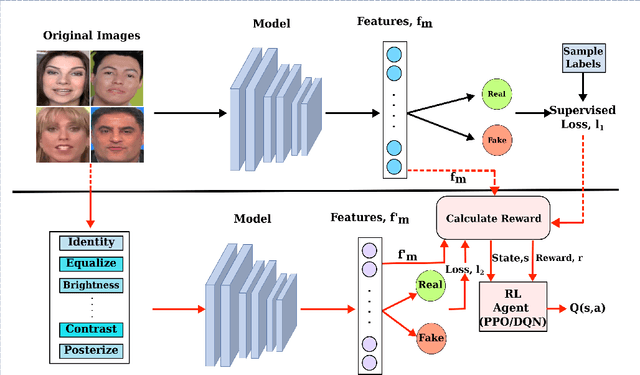
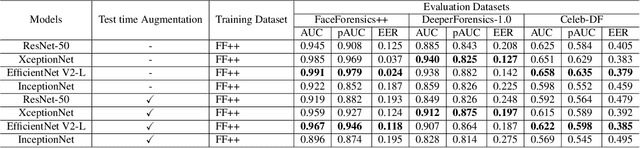
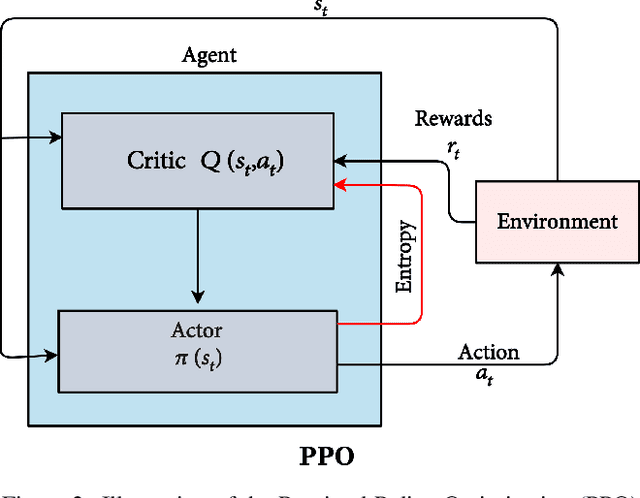
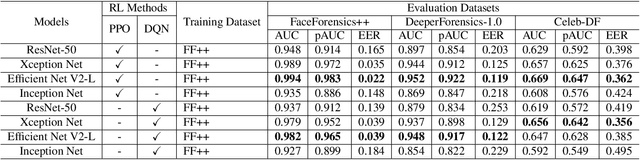
Facial manipulation by deep fake has caused major security risks and raised severe societal concerns. As a countermeasure, a number of deep fake detection methods have been proposed recently. Most of them model deep fake detection as a binary classification problem using a backbone convolutional neural network (CNN) architecture pretrained for the task. These CNN-based methods have demonstrated very high efficacy in deep fake detection with the Area under the Curve (AUC) as high as 0.99. However, the performance of these methods degrades significantly when evaluated across datasets. In this paper, we formulate deep fake detection as a hybrid combination of supervised and reinforcement learning (RL) to improve its cross-dataset generalization performance. The proposed method chooses the top-k augmentations for each test sample by an RL agent in an image-specific manner. The classification scores, obtained using CNN, of all the augmentations of each test image are averaged together for final real or fake classification. Through extensive experimental validation, we demonstrate the superiority of our method over existing published research in cross-dataset generalization of deep fake detectors, thus obtaining state-of-the-art performance.