 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Preliminary experiments on thermal emissivity adjustment for face images
Mar 30, 2022
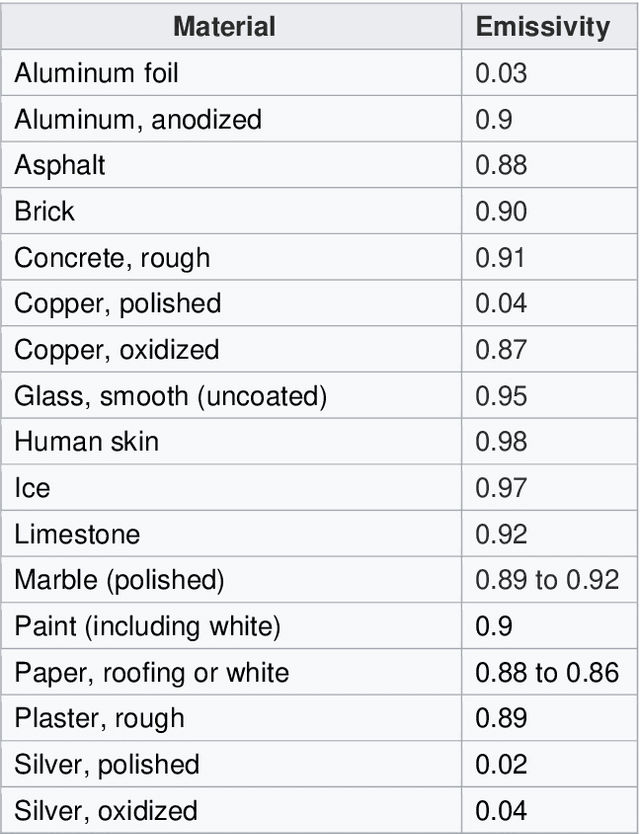
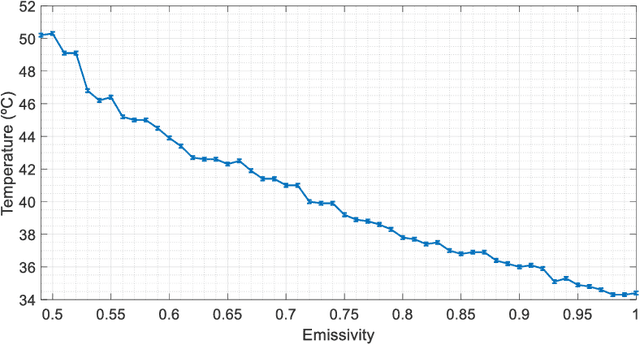
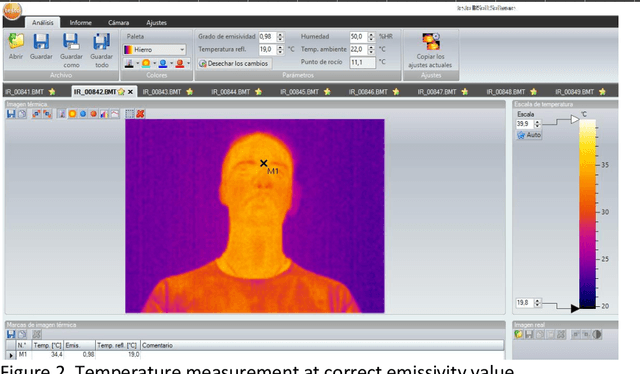
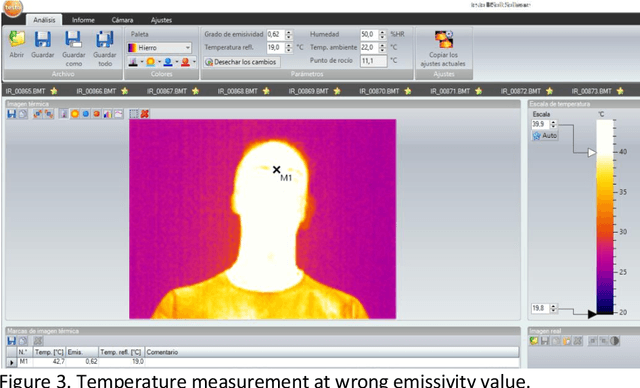
In this paper we summarize several applications based on thermal imaging. We emphasize the importance of emissivity adjustment for a proper temperature measurement. A new set of face images acquired at different emissivity values with steps of 0.01 is also presented and will be distributed for free for research purposes. Among the utilities, we can mention: a) the possibility to apply corrections once an image is acquired with a wrong emissivity value and it is not possible to acquire a new one; b) privacy protection in thermal images, which can be obtained with a low emissivity factor, which is still suitable for several applications, but hides the identity of a user; c) image processing for improving temperature detection in scenes containing objects of different emissivity.
* 8 pages, published in: Esposito, A., Faundez-Zanuy, M., Morabito, F., Pasero, E. (eds) Progresses in Artificial Intelligence and Neural Systems. Smart Innovation, Systems and Technologies, vol 184. Springer, Singapore
Graph Convolutional Networks for Multi-modality Medical Imaging: Methods, Architectures, and Clinical Applications
Feb 17, 2022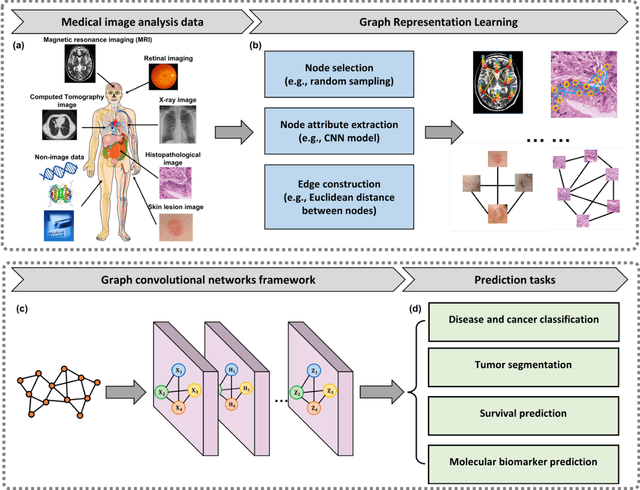

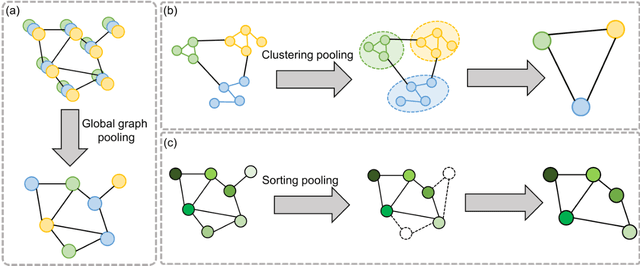
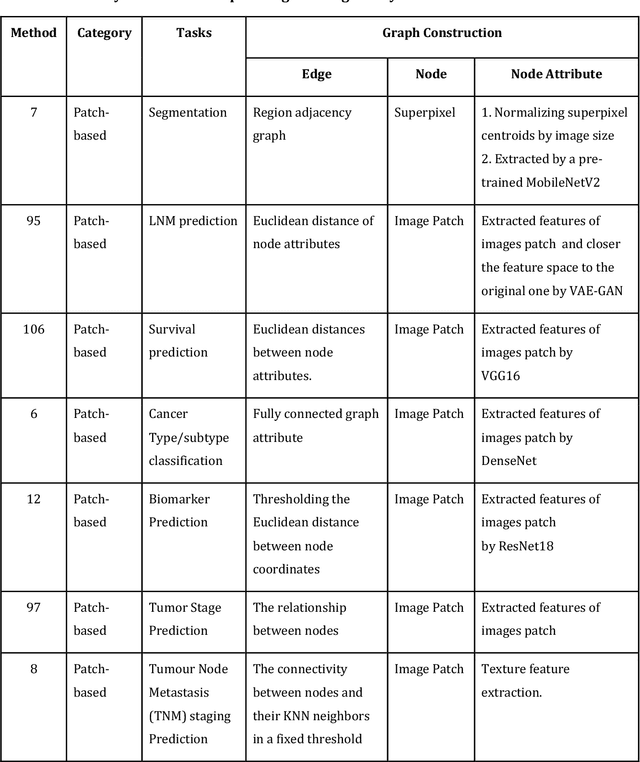
Image-based characterization and disease understanding involve integrative analysis of morphological, spatial, and topological information across biological scales. The development of graph convolutional networks (GCNs) has created the opportunity to address this information complexity via graph-driven architectures, since GCNs can perform feature aggregation, interaction, and reasoning with remarkable flexibility and efficiency. These GCNs capabilities have spawned a new wave of research in medical imaging analysis with the overarching goal of improving quantitative disease understanding, monitoring, and diagnosis. Yet daunting challenges remain for designing the important image-to-graph transformation for multi-modality medical imaging and gaining insights into model interpretation and enhanced clinical decision support. In this review, we present recent GCNs developments in the context of medical image analysis including imaging data from radiology and histopathology. We discuss the fast-growing use of graph network architectures in medical image analysis to improve disease diagnosis and patient outcomes in clinical practice. To foster cross-disciplinary research, we present GCNs technical advancements, emerging medical applications, identify common challenges in the use of image-based GCNs and their extensions in model interpretation, large-scale benchmarks that promise to transform the scope of medical image studies and related graph-driven medical research.
Reducing the Gibbs effect in multimodal medical imaging by the Fake Nodes Approach
Feb 21, 2022
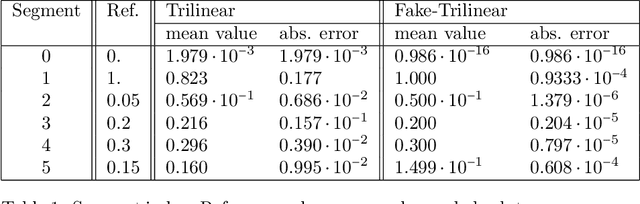

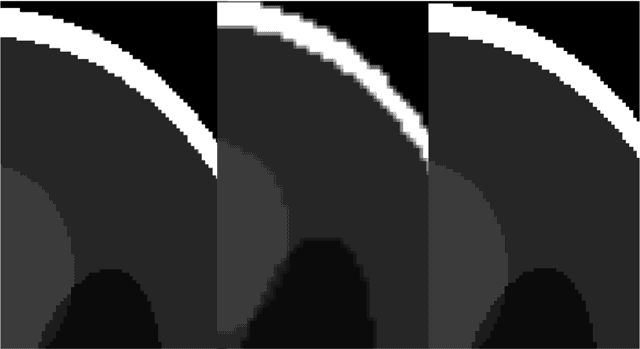
It is a common practice in multimodal medical imaging to undersample the anatomically-derived segmentation images to measure the mean activity of a co-acquired functional image. This practice avoids the resampling-related Gibbs effect that would occur in oversampling the functional image. As sides effect, waste of time and efforts are produced since the anatomical segmentation at full resolution is performed in many hours of computations or manual work. In this work we explain the commonly-used resampling methods and give errors bound in the cases of continuous and discontinuous signals. Then we propose a Fake Nodes scheme for image resampling designed to reduce the Gibbs effect when oversampling the functional image. This new approach is compared to the traditional counterpart in two significant experiments, both showing that Fake Nodes resampling gives smaller errors.
3D Common Corruptions and Data Augmentation
Apr 04, 2022
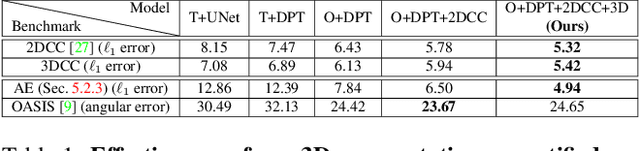

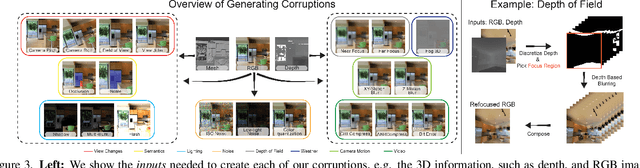
We introduce a set of image transformations that can be used as corruptions to evaluate the robustness of models as well as data augmentation mechanisms for training neural networks. The primary distinction of the proposed transformations is that, unlike existing approaches such as Common Corruptions, the geometry of the scene is incorporated in the transformations -- thus leading to corruptions that are more likely to occur in the real world. We also introduce a set of semantic corruptions (e.g. natural object occlusions). We show these transformations are `efficient' (can be computed on-the-fly), `extendable' (can be applied on most image datasets), expose vulnerability of existing models, and can effectively make models more robust when employed as `3D data augmentation' mechanisms. The evaluations on several tasks and datasets suggest incorporating 3D information into benchmarking and training opens up a promising direction for robustness research.
Towards Fine-grained Image Classification with Generative Adversarial Networks and Facial Landmark Detection
Aug 28, 2021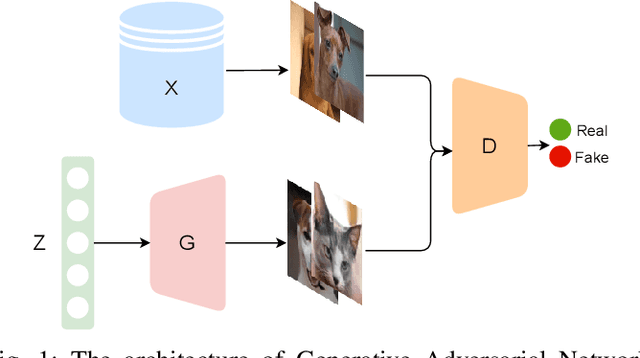
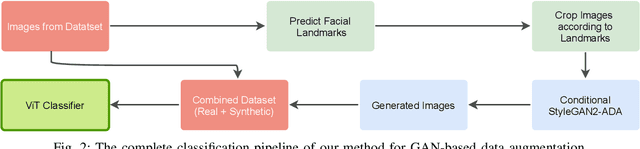


Fine-grained classification remains a challenging task because distinguishing categories needs learning complex and local differences. Diversity in the pose, scale, and position of objects in an image makes the problem even more difficult. Although the recent Vision Transformer models achieve high performance, they need an extensive volume of input data. To encounter this problem, we made the best use of GAN-based data augmentation to generate extra dataset instances. Oxford-IIIT Pets was our dataset of choice for this experiment. It consists of 37 breeds of cats and dogs with variations in scale, poses, and lighting, which intensifies the difficulty of the classification task. Furthermore, we enhanced the performance of the recent Generative Adversarial Network (GAN), StyleGAN2-ADA model to generate more realistic images while preventing overfitting to the training set. We did this by training a customized version of MobileNetV2 to predict animal facial landmarks; then, we cropped images accordingly. Lastly, we combined the synthetic images with the original dataset and compared our proposed method with standard GANs augmentation and no augmentation with different subsets of training data. We validated our work by evaluating the accuracy of fine-grained image classification on the recent Vision Transformer (ViT) Model.
Unsupervised Image-to-Image Translation via Pre-trained StyleGAN2 Network
Oct 12, 2020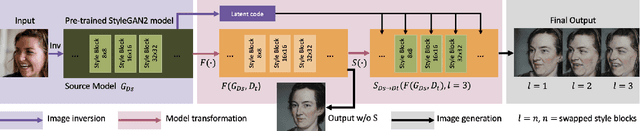



Image-to-Image (I2I) translation is a heated topic in academia, and it also has been applied in real-world industry for tasks like image synthesis, super-resolution, and colorization. However, traditional I2I translation methods train data in two or more domains together. This requires lots of computation resources. Moreover, the results are of lower quality, and they contain many more artifacts. The training process could be unstable when the data in different domains are not balanced, and modal collapse is more likely to happen. We proposed a new I2I translation method that generates a new model in the target domain via a series of model transformations on a pre-trained StyleGAN2 model in the source domain. After that, we proposed an inversion method to achieve the conversion between an image and its latent vector. By feeding the latent vector into the generated model, we can perform I2I translation between the source domain and target domain. Both qualitative and quantitative evaluations were conducted to prove that the proposed method can achieve outstanding performance in terms of image quality, diversity and semantic similarity to the input and reference images compared to state-of-the-art works.
Conditional Injective Flows for Bayesian Imaging
Apr 19, 2022
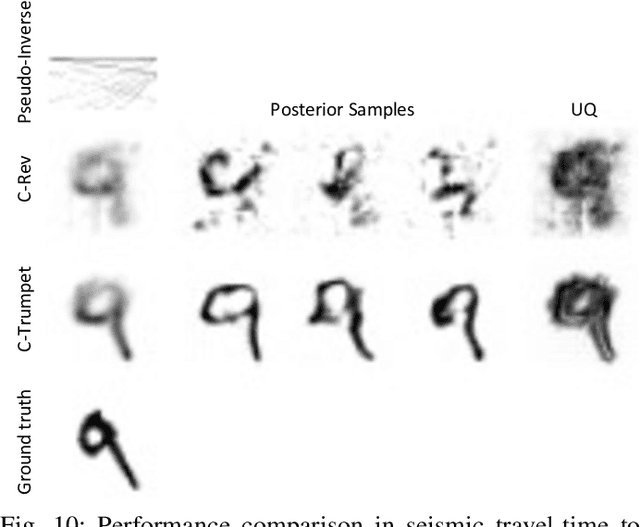

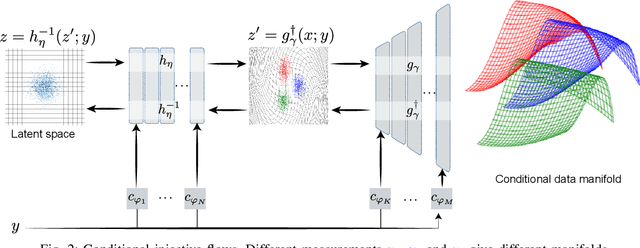
Most deep learning models for computational imaging regress a single reconstructed image. In practice, however, ill-posedness, nonlinearity, model mismatch, and noise often conspire to make such point estimates misleading or insufficient. The Bayesian approach models images and (noisy) measurements as jointly distributed random vectors and aims to approximate the posterior distribution of unknowns. Recent variational inference methods based on conditional normalizing flows are a promising alternative to traditional MCMC methods, but they come with drawbacks: excessive memory and compute demands for moderate to high resolution images and underwhelming performance on hard nonlinear problems. In this work, we propose C-Trumpets -- conditional injective flows specifically designed for imaging problems, which greatly diminish these challenges. Injectivity reduces memory footprint and training time while low-dimensional latent space together with architectural innovations like fixed-volume-change layers and skip-connection revnet layers, C-Trumpets outperform regular conditional flow models on a variety of imaging and image restoration tasks, including limited-view CT and nonlinear inverse scattering, with a lower compute and memory budget. C-Trumpets enable fast approximation of point estimates like MMSE or MAP as well as physically-meaningful uncertainty quantification.
Optimal Correction Cost for Object Detection Evaluation
Mar 28, 2022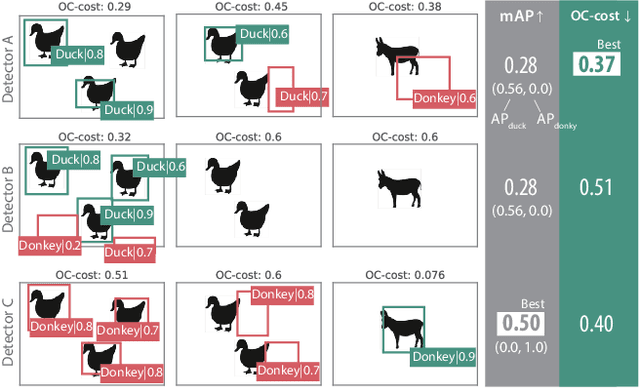
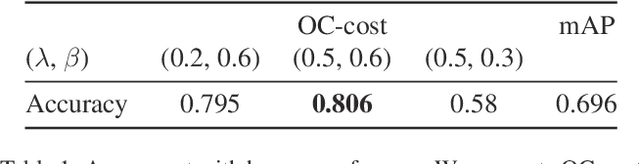
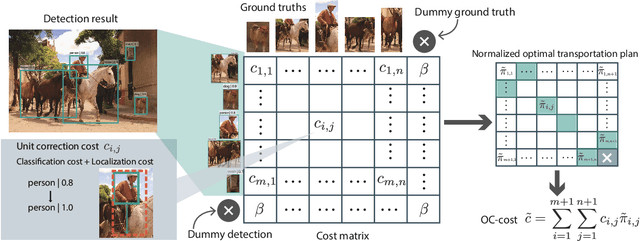

Mean Average Precision (mAP) is the primary evaluation measure for object detection. Although object detection has a broad range of applications, mAP evaluates detectors in terms of the performance of ranked instance retrieval. Such the assumption for the evaluation task does not suit some downstream tasks. To alleviate the gap between downstream tasks and the evaluation scenario, we propose Optimal Correction Cost (OC-cost), which assesses detection accuracy at image level. OC-cost computes the cost of correcting detections to ground truths as a measure of accuracy. The cost is obtained by solving an optimal transportation problem between the detections and the ground truths. Unlike mAP, OC-cost is designed to penalize false positive and false negative detections properly, and every image in a dataset is treated equally. Our experimental result validates that OC-cost has better agreement with human preference than a ranking-based measure, i.e., mAP for a single image. We also show that detectors' rankings by OC-cost are more consistent on different data splits than mAP. Our goal is not to replace mAP with OC-cost but provide an additional tool to evaluate detectors from another aspect. To help future researchers and developers choose a target measure, we provide a series of experiments to clarify how mAP and OC-cost differ.
Fractional Vegetation Cover Estimation using Hough Lines and Linear Iterative Clustering
Apr 30, 2022
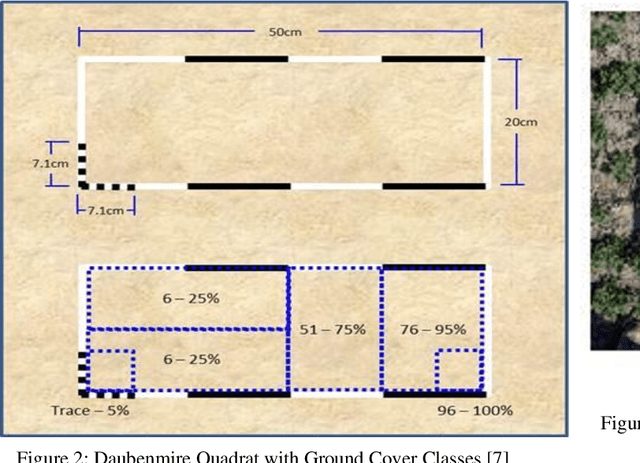
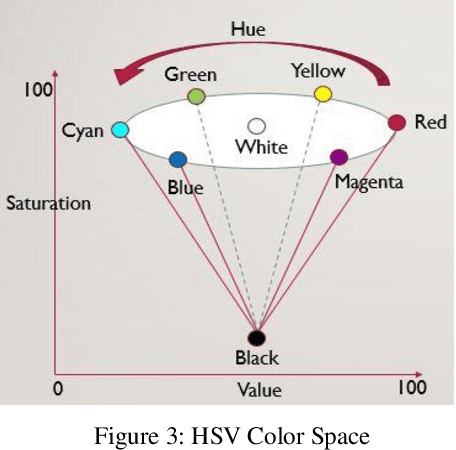

A common requirement of plant breeding programs across the country is companion planting -- growing different species of plants in close proximity so they can mutually benefit each other. However, the determination of companion plants requires meticulous monitoring of plant growth. The technique of ocular monitoring is often laborious and error prone. The availability of image processing techniques can be used to address the challenge of plant growth monitoring and provide robust solutions that assist plant scientists to identify companion plants. This paper presents a new image processing algorithm to determine the amount of vegetation cover present in a given area, called fractional vegetation cover. The proposed technique draws inspiration from the trusted Daubenmire method for vegetation cover estimation and expands upon it. Briefly, the idea is to estimate vegetation cover from images containing multiple rows of plant species growing in close proximity separated by a multi-segment PVC frame of known size. The proposed algorithm applies a Hough Transform and Simple Linear Iterative Clustering (SLIC) to estimate the amount of vegetation cover within each segment of the PVC frame. The analysis when repeated over images captured at regular intervals of time provides crucial insights into plant growth. As a means of comparison, the proposed algorithm is compared with SamplePoint and Canopeo, two trusted applications used for vegetation cover estimation. The comparison shows a 99% similarity with both SamplePoint and Canopeo demonstrating the accuracy and feasibility of the algorithm for fractional vegetation cover estimation.
R2RNet: Low-light Image Enhancement via Real-low to Real-normal Network
Jun 28, 2021

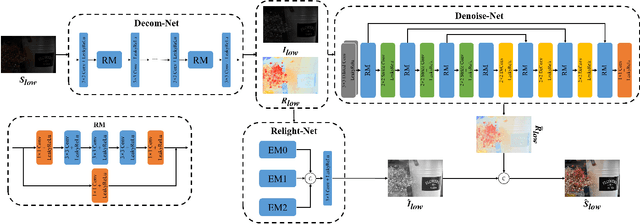

Images captured in weak illumination conditions will seriously degrade the image quality. Solving a series of degradation of low-light images can effectively improve the visual quality of the image and the performance of high-level visual tasks. In this paper, we propose a novel Real-low to Real-normal Network for low-light image enhancement, dubbed R2RNet, based on the Retinex theory, which includes three subnets: a Decom-Net, a Denoise-Net, and a Relight-Net. These three subnets are used for decomposing, denoising, and contrast enhancement, respectively. Unlike most previous methods trained on synthetic images, we collect the first Large-Scale Real-World paired low/normal-light images dataset (LSRW dataset) for training. Our method can properly improve the contrast and suppress noise simultaneously. Extensive experiments on publicly available datasets demonstrate that our method outperforms the existing state-of-the-art methods by a large margin both quantitatively and visually. And we also show that the performance of the high-level visual task (\emph{i.e.} face detection) can be effectively improved by using the enhanced results obtained by our method in low-light conditions. Our codes and the LSRW dataset are available at: https://github.com/abcdef2000/R2RNet.