 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Composition Assessment with Saliency-augmented Multi-pattern Pooling
Apr 07, 2021
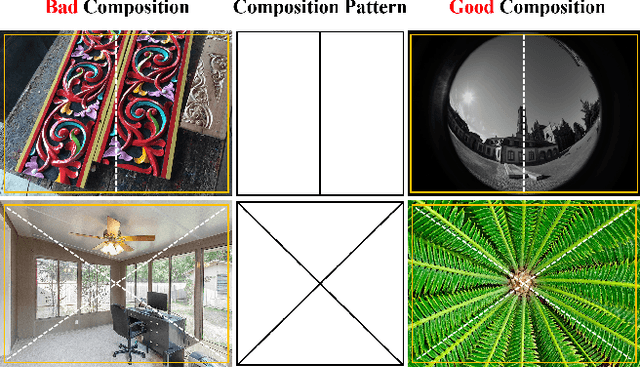
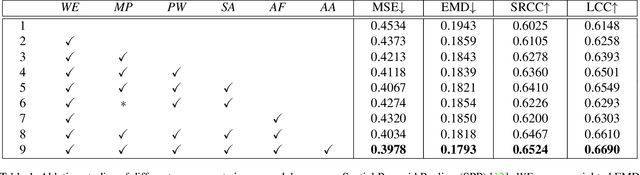
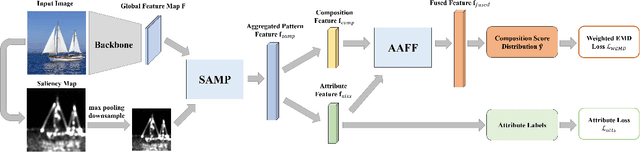
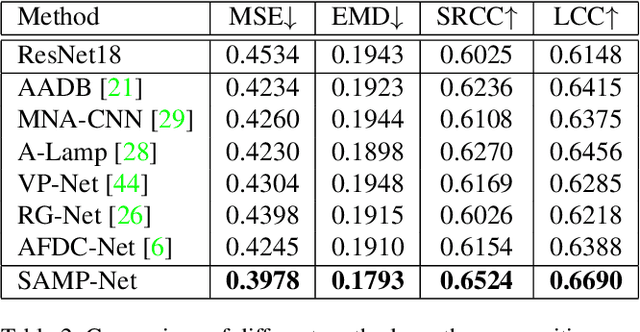
Image composition assessment is crucial in aesthetic assessment, which aims to assess the overall composition quality of a given image. However, to the best of our knowledge, there is neither dataset nor method specifically proposed for this task. In this paper, we contribute the first composition assessment dataset CADB with composition scores for each image provided by multiple professional raters. Besides, we propose a composition assessment network SAMP-Net with a novel Saliency-Augmented Multi-pattern Pooling (SAMP) module, which analyses visual layout from the perspectives of multiple composition patterns. We also leverage composition-relevant attributes to further boost the performance, and extend Earth Mover's Distance (EMD) loss to weighted EMD loss to eliminate the content bias. The experimental results show that our SAMP-Net can perform more favorably than previous aesthetic assessment approaches and offer constructive composition suggestions.
What do we learn? Debunking the Myth of Unsupervised Outlier Detection
Jun 08, 2022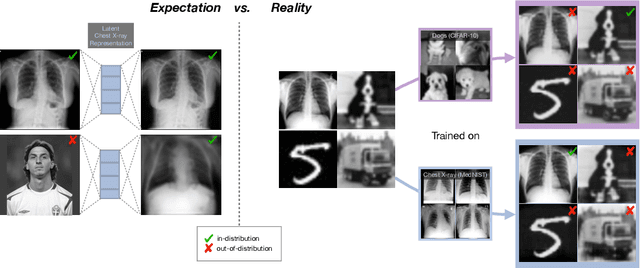
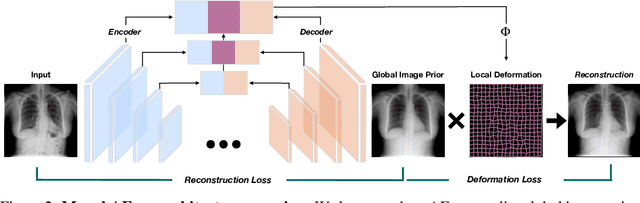
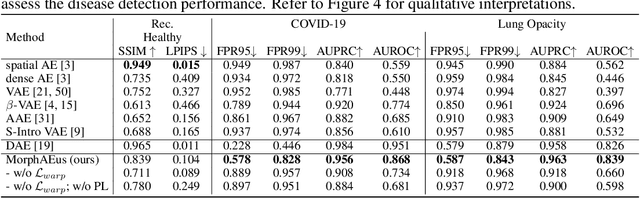
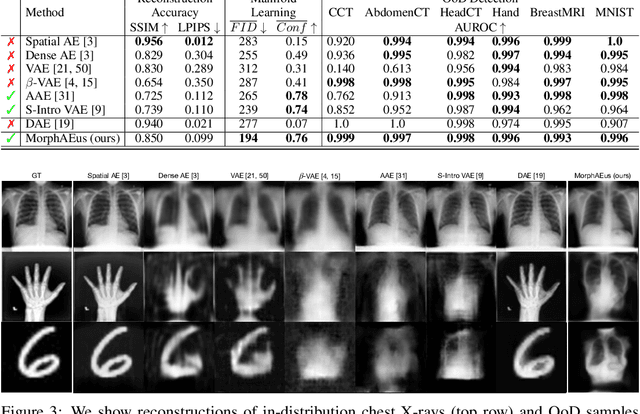
Even though auto-encoders (AEs) have the desirable property of learning compact representations without labels and have been widely applied to out-of-distribution (OoD) detection, they are generally still poorly understood and are used incorrectly in detecting outliers where the normal and abnormal distributions are strongly overlapping. In general, the learned manifold is assumed to contain key information that is only important for describing samples within the training distribution, and that the reconstruction of outliers leads to high residual errors. However, recent work suggests that AEs are likely to be even better at reconstructing some types of OoD samples. In this work, we challenge this assumption and investigate what auto-encoders actually learn when they are posed to solve two different tasks. First, we propose two metrics based on the Fr\'echet inception distance (FID) and confidence scores of a trained classifier to assess whether AEs can learn the training distribution and reliably recognize samples from other domains. Second, we investigate whether AEs are able to synthesize normal images from samples with abnormal regions, on a more challenging lung pathology detection task. We have found that state-of-the-art (SOTA) AEs are either unable to constrain the latent manifold and allow reconstruction of abnormal patterns, or they are failing to accurately restore the inputs from their latent distribution, resulting in blurred or misaligned reconstructions. We propose novel deformable auto-encoders (MorphAEus) to learn perceptually aware global image priors and locally adapt their morphometry based on estimated dense deformation fields. We demonstrate superior performance over unsupervised methods in detecting OoD and pathology.
BTranspose: Bottleneck Transformers for Human Pose Estimation with Self-Supervised Pre-Training
Apr 21, 2022
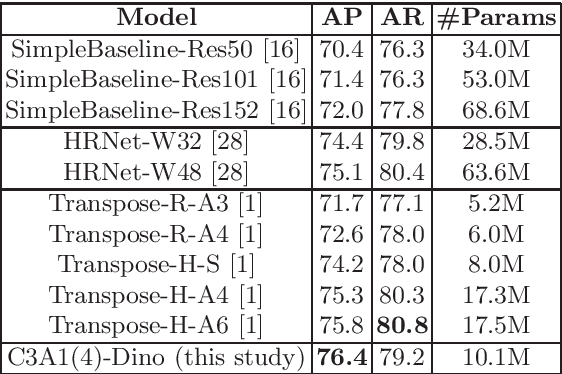
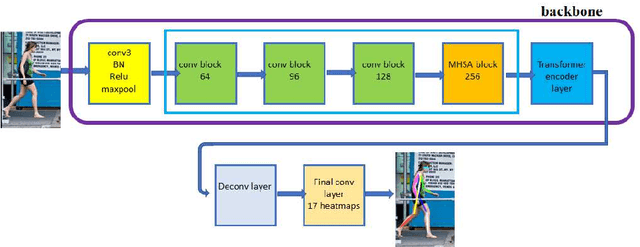
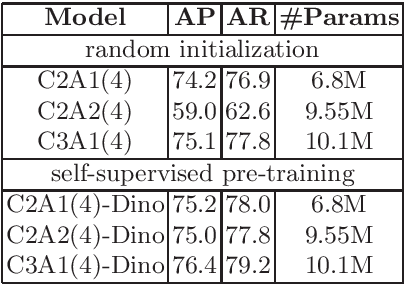
The task of 2D human pose estimation is challenging as the number of keypoints is typically large (~ 17) and this necessitates the use of robust neural network architectures and training pipelines that can capture the relevant features from the input image. These features are then aggregated to make accurate heatmap predictions from which the final keypoints of human body parts can be inferred. Many papers in literature use CNN-based architectures for the backbone, and/or combine it with a transformer, after which the features are aggregated to make the final keypoint predictions [1]. In this paper, we consider the recently proposed Bottleneck Transformers [2], which combine CNN and multi-head self attention (MHSA) layers effectively, and we integrate it with a Transformer encoder and apply it to the task of 2D human pose estimation. We consider different backbone architectures and pre-train them using the DINO self-supervised learning method [3], this pre-training is found to improve the overall prediction accuracy. We call our model BTranspose, and experiments show that on the COCO validation set, our model achieves an AP of 76.4, which is competitive with other methods such as [1] and has fewer network parameters. Furthermore, we also present the dependencies of the final predicted keypoints on both the MHSA block and the Transformer encoder layers, providing clues on the image sub-regions the network attends to at the mid and high levels.
An End-to-End Food Image Analysis System
Feb 01, 2021
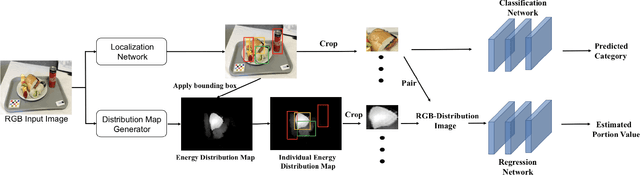
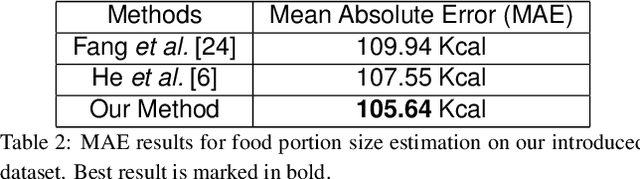

Modern deep learning techniques have enabled advances in image-based dietary assessment such as food recognition and food portion size estimation. Valuable information on the types of foods and the amount consumed are crucial for prevention of many chronic diseases. However, existing methods for automated image-based food analysis are neither end-to-end nor are capable of processing multiple tasks (e.g., recognition and portion estimation) together, making it difficult to apply to real life applications. In this paper, we propose an image-based food analysis framework that integrates food localization, classification and portion size estimation. Our proposed framework is end-to-end, i.e., the input can be an arbitrary food image containing multiple food items and our system can localize each single food item with its corresponding predicted food type and portion size. We also improve the single food portion estimation by consolidating localization results with a food energy distribution map obtained by conditional GAN to generate a four-channel RGB-Distribution image. Our end-to-end framework is evaluated on a real life food image dataset collected from a nutrition feeding study.
The Missing Invariance Principle Found -- the Reciprocal Twin of Invariant Risk Minimization
May 29, 2022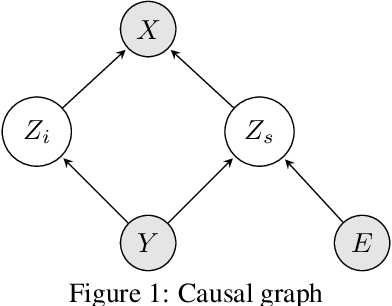
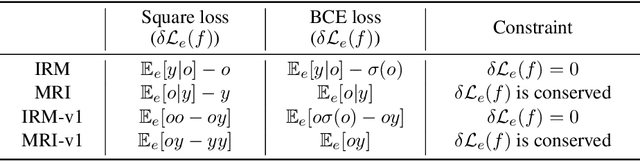
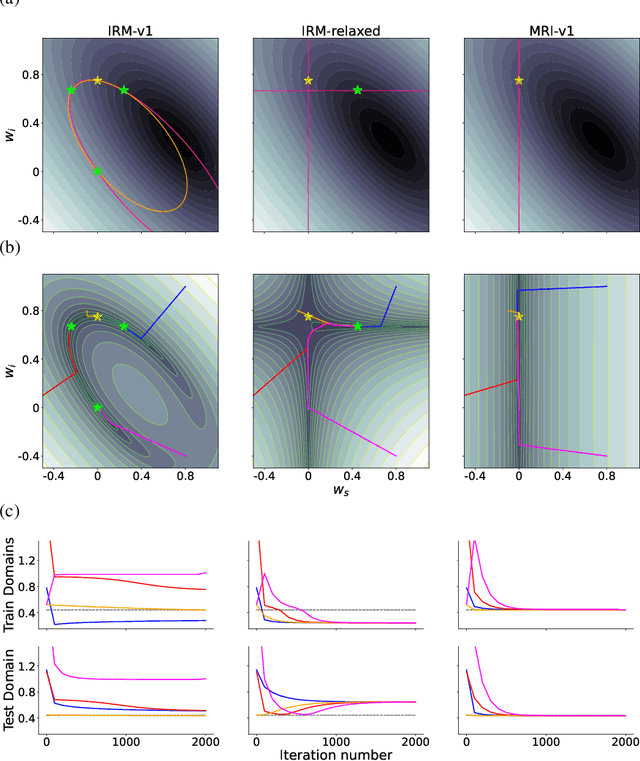

Machine learning models often generalize poorly to out-of-distribution (OOD) data as a result of relying on features that are spuriously correlated with the label during training. Recently, the technique of Invariant Risk Minimization (IRM) was proposed to learn predictors that only use invariant features by conserving the feature-conditioned class expectation $\mathbb{E}_e[y|f(x)]$ across environments. However, more recent studies have demonstrated that IRM can fail in various task settings. Here, we identify a fundamental flaw of IRM formulation that causes the failure. We then introduce a complementary notion of invariance, MRI, that is based on conserving the class-conditioned feature expectation $\mathbb{E}_e[f(x)|y]$ across environments, that corrects for the flaw in IRM. Further, we introduce a simplified, practical version of the MRI formulation called as MRI-v1. We note that this constraint is convex which confers it with an advantage over the practical version of IRM, IRM-v1, which imposes non-convex constraints. We prove that in a general linear problem setting, MRI-v1 can guarantee invariant predictors given sufficient environments. We also empirically demonstrate that MRI strongly out-performs IRM and consistently achieves near-optimal OOD generalization in image-based nonlinear problems.
TVConv: Efficient Translation Variant Convolution for Layout-aware Visual Processing
Mar 22, 2022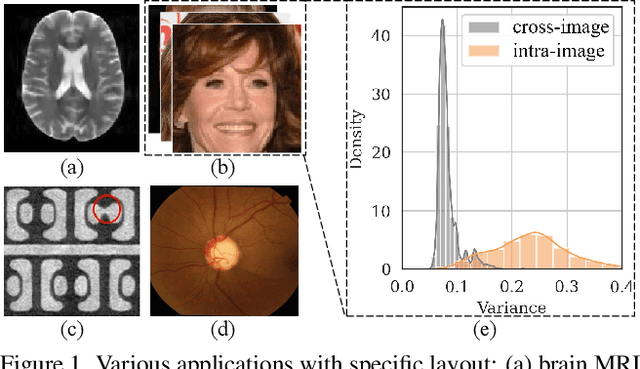
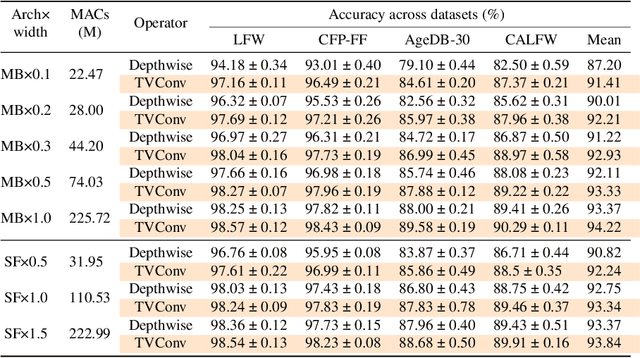
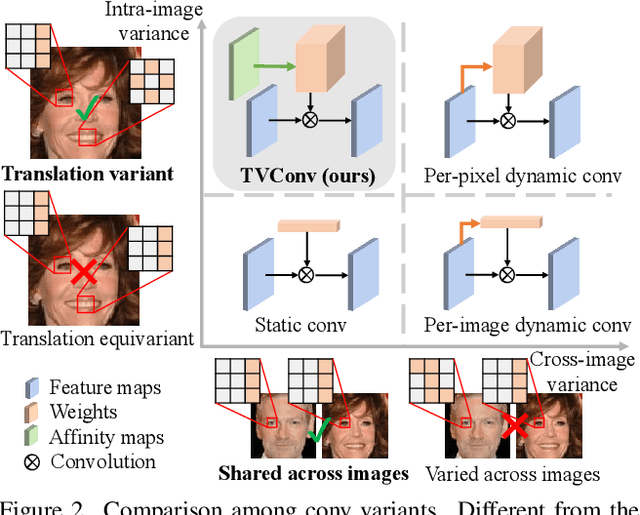
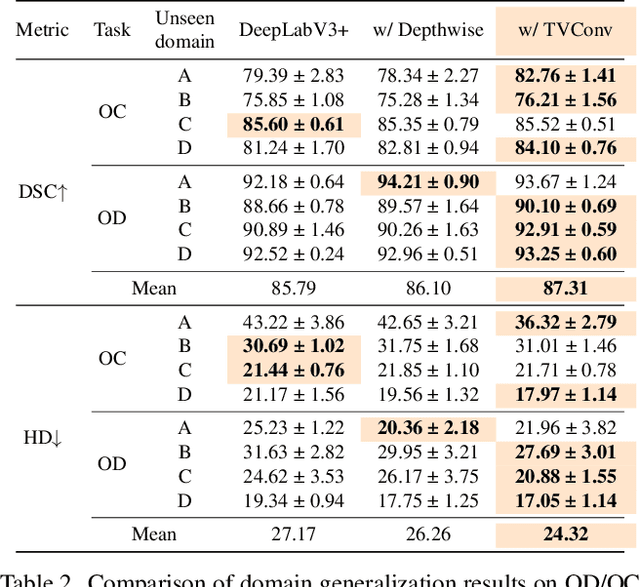
As convolution has empowered many smart applications, dynamic convolution further equips it with the ability to adapt to diverse inputs. However, the static and dynamic convolutions are either layout-agnostic or computation-heavy, making it inappropriate for layout-specific applications, e.g., face recognition and medical image segmentation. We observe that these applications naturally exhibit the characteristics of large intra-image (spatial) variance and small cross-image variance. This observation motivates our efficient translation variant convolution (TVConv) for layout-aware visual processing. Technically, TVConv is composed of affinity maps and a weight-generating block. While affinity maps depict pixel-paired relationships gracefully, the weight-generating block can be explicitly overparameterized for better training while maintaining efficient inference. Although conceptually simple, TVConv significantly improves the efficiency of the convolution and can be readily plugged into various network architectures. Extensive experiments on face recognition show that TVConv reduces the computational cost by up to 3.1x and improves the corresponding throughput by 2.3x while maintaining a high accuracy compared to the depthwise convolution. Moreover, for the same computation cost, we boost the mean accuracy by up to 4.21%. We also conduct experiments on the optic disc/cup segmentation task and obtain better generalization performance, which helps mitigate the critical data scarcity issue. Code is available at https://github.com/JierunChen/TVConv.
A Deep Learning Generative Model Approach for Image Synthesis of Plant Leaves
Nov 05, 2021
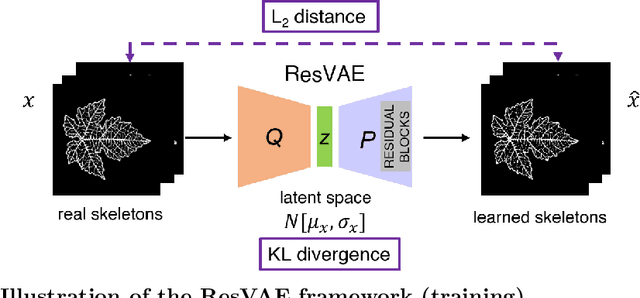
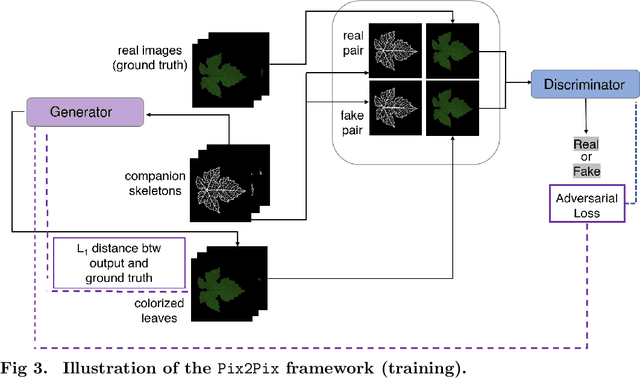
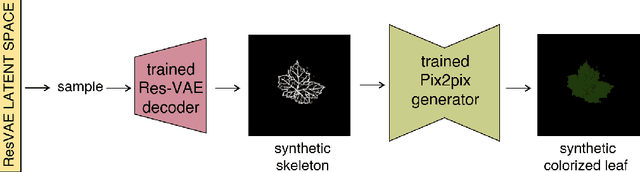
Objectives. We generate via advanced Deep Learning (DL) techniques artificial leaf images in an automatized way. We aim to dispose of a source of training samples for AI applications for modern crop management. Such applications require large amounts of data and, while leaf images are not truly scarce, image collection and annotation remains a very time--consuming process. Data scarcity can be addressed by augmentation techniques consisting in simple transformations of samples belonging to a small dataset, but the richness of the augmented data is limited: this motivates the search for alternative approaches. Methods. Pursuing an approach based on DL generative models, we propose a Leaf-to-Leaf Translation (L2L) procedure structured in two steps: first, a residual variational autoencoder architecture generates synthetic leaf skeletons (leaf profile and veins) starting from companions binarized skeletons of real images. In a second step, we perform translation via a Pix2pix framework, which uses conditional generator adversarial networks to reproduce the colorization of leaf blades, preserving the shape and the venation pattern. Results. The L2L procedure generates synthetic images of leaves with a realistic appearance. We address the performance measurement both in a qualitative and a quantitative way; for this latter evaluation, we employ a DL anomaly detection strategy which quantifies the degree of anomaly of synthetic leaves with respect to real samples. Conclusions. Generative DL approaches have the potential to be a new paradigm to provide low-cost meaningful synthetic samples for computer-aided applications. The present L2L approach represents a step towards this goal, being able to generate synthetic samples with a relevant qualitative and quantitative resemblance to real leaves.
Illumination-Invariant Active Camera Relocalization for Fine-Grained Change Detection in the Wild
Apr 13, 2022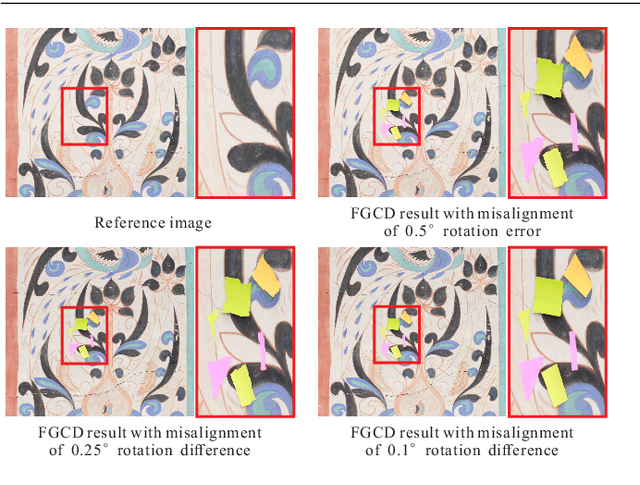
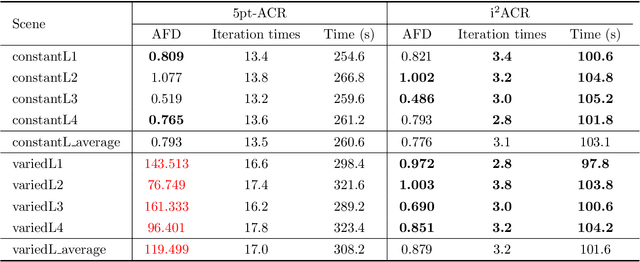
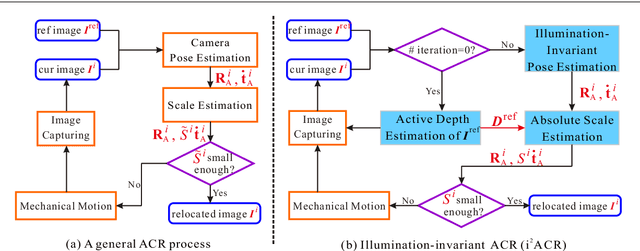
Active camera relocalization (ACR) is a new problem in computer vision that significantly reduces the false alarm caused by image distortions due to camera pose misalignment in fine-grained change detection (FGCD). Despite the fruitful achievements that ACR can support, it still remains a challenging problem caused by the unstable results of relative pose estimation, especially for outdoor scenes, where the lighting condition is out of control, i.e., the twice observations may have highly varied illuminations. This paper studies an illumination-invariant active camera relocalization method, it improves both in relative pose estimation and scale estimation. We use plane segments as an intermediate representation to facilitate feature matching, thus further boosting pose estimation robustness and reliability under lighting variances. Moreover, we construct a linear system to obtain the absolute scale in each ACR iteration by minimizing the image warping error, thus, significantly reduce the time consume of ACR process, it is nearly $1.6$ times faster than the state-of-the-art ACR strategy. Our work greatly expands the feasibility of real-world fine-grained change monitoring tasks for cultural heritages. Extensive experiments tests and real-world applications verify the effectiveness and robustness of the proposed pose estimation method using for ACR tasks.
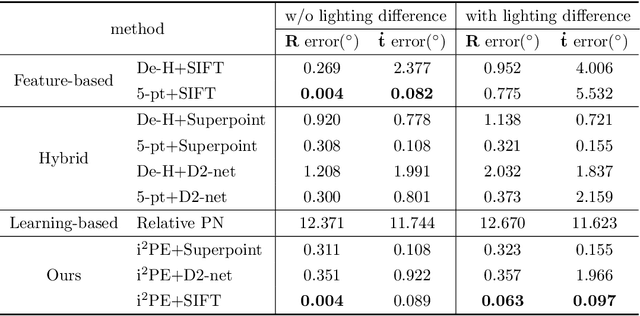
Reflection and Rotation Symmetry Detection via Equivariant Learning
Mar 31, 2022
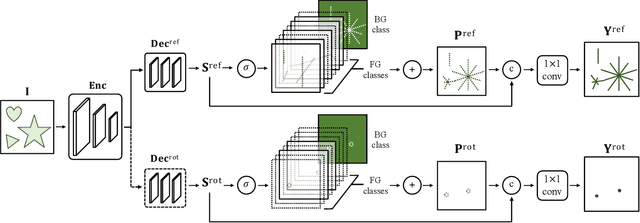
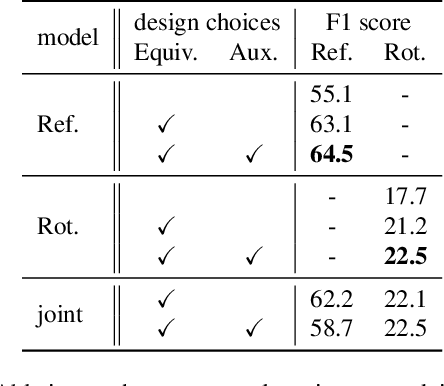
The inherent challenge of detecting symmetries stems from arbitrary orientations of symmetry patterns; a reflection symmetry mirrors itself against an axis with a specific orientation while a rotation symmetry matches its rotated copy with a specific orientation. Discovering such symmetry patterns from an image thus benefits from an equivariant feature representation, which varies consistently with reflection and rotation of the image. In this work, we introduce a group-equivariant convolutional network for symmetry detection, dubbed EquiSym, which leverages equivariant feature maps with respect to a dihedral group of reflection and rotation. The proposed network is built end-to-end with dihedrally-equivariant layers and trained to output a spatial map for reflection axes or rotation centers. We also present a new dataset, DENse and DIverse symmetry (DENDI), which mitigates limitations of existing benchmarks for reflection and rotation symmetry detection. Experiments show that our method achieves the state of the arts in symmetry detection on LDRS and DENDI datasets.
Learning to Count Anything: Reference-less Class-agnostic Counting with Weak Supervision
May 20, 2022
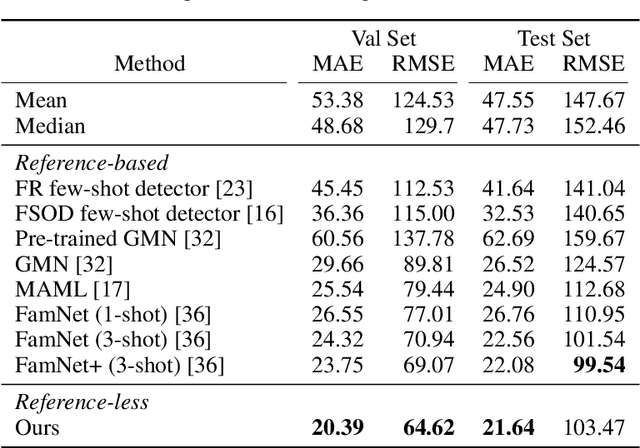
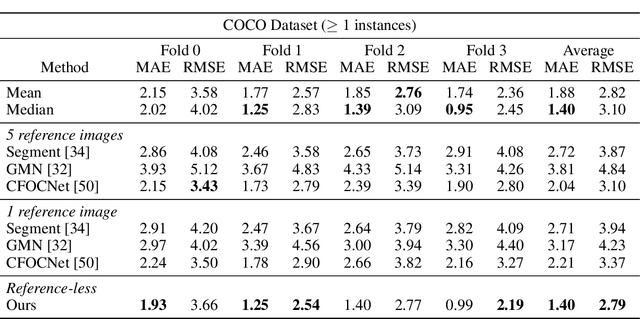

Object counting is a seemingly simple task with diverse real-world applications. Most counting methods focus on counting instances of specific, known classes. While there are class-agnostic counting methods that can generalise to unseen classes, these methods require reference images to define the type of object to be counted, as well as instance annotations during training. We identify that counting is, at its core, a repetition-recognition task and show that a general feature space, with global context, is sufficient to enumerate instances in an image without a prior on the object type present. Specifically, we demonstrate that self-supervised vision transformer features combined with a lightweight count regression head achieve competitive results when compared to other class-agnostic counting tasks without the need for point-level supervision or reference images. Our method thus facilitates counting on a constantly changing set composition. To the best of our knowledge, we are both the first reference-less class-agnostic counting method as well as the first weakly-supervised class-agnostic counting method.