 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Few-Shot Diffusion Models
May 30, 2022


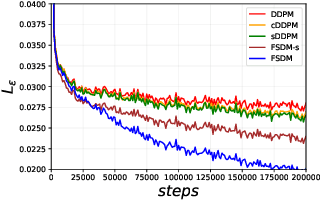
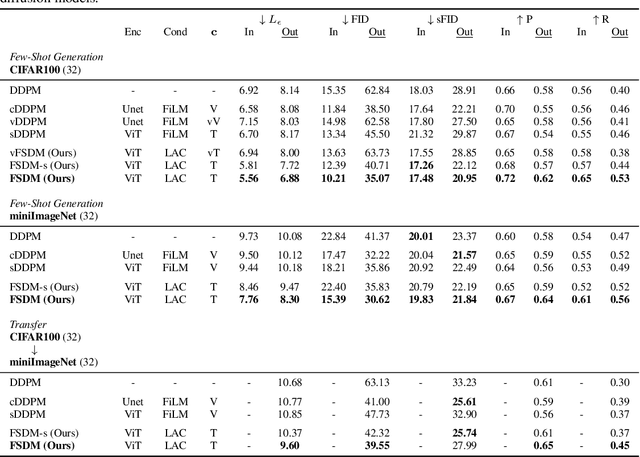
Denoising diffusion probabilistic models (DDPM) are powerful hierarchical latent variable models with remarkable sample generation quality and training stability. These properties can be attributed to parameter sharing in the generative hierarchy, as well as a parameter-free diffusion-based inference procedure. In this paper, we present Few-Shot Diffusion Models (FSDM), a framework for few-shot generation leveraging conditional DDPMs. FSDMs are trained to adapt the generative process conditioned on a small set of images from a given class by aggregating image patch information using a set-based Vision Transformer (ViT). At test time, the model is able to generate samples from previously unseen classes conditioned on as few as 5 samples from that class. We empirically show that FSDM can perform few-shot generation and transfer to new datasets. We benchmark variants of our method on complex vision datasets for few-shot learning and compare to unconditional and conditional DDPM baselines. Additionally, we show how conditioning the model on patch-based input set information improves training convergence.
OmniFusion: 360 Monocular Depth Estimation via Geometry-Aware Fusion
Mar 29, 2022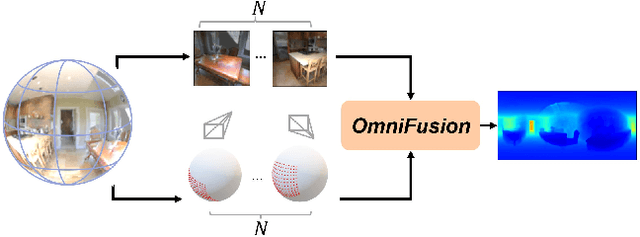
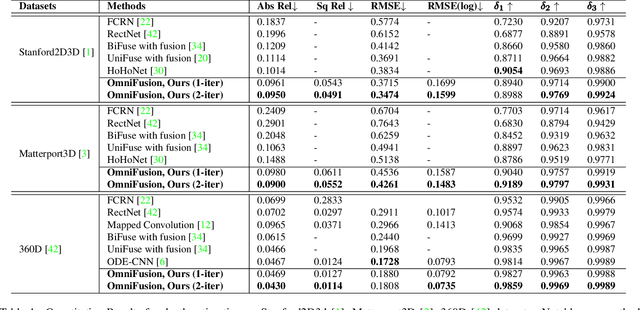
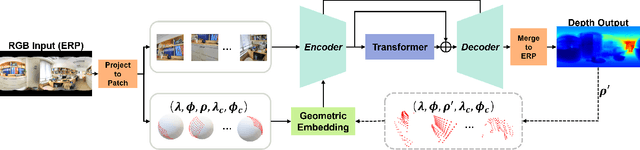

A well-known challenge in applying deep-learning methods to omnidirectional images is spherical distortion. In dense regression tasks such as depth estimation, where structural details are required, using a vanilla CNN layer on the distorted 360 image results in undesired information loss. In this paper, we propose a 360 monocular depth estimation pipeline, OmniFusion, to tackle the spherical distortion issue. Our pipeline transforms a 360 image into less-distorted perspective patches (i.e. tangent images) to obtain patch-wise predictions via CNN, and then merge the patch-wise results for final output. To handle the discrepancy between patch-wise predictions which is a major issue affecting the merging quality, we propose a new framework with the following key components. First, we propose a geometry-aware feature fusion mechanism that combines 3D geometric features with 2D image features to compensate for the patch-wise discrepancy. Second, we employ the self-attention-based transformer architecture to conduct a global aggregation of patch-wise information, which further improves the consistency. Last, we introduce an iterative depth refinement mechanism, to further refine the estimated depth based on the more accurate geometric features. Experiments show that our method greatly mitigates the distortion issue, and achieves state-of-the-art performances on several 360 monocular depth estimation benchmark datasets.
Vision-Language Pre-Training with Triple Contrastive Learning
Feb 21, 2022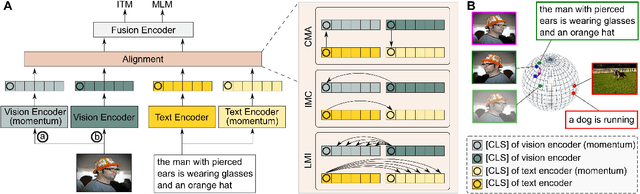

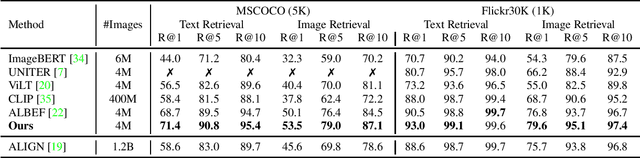
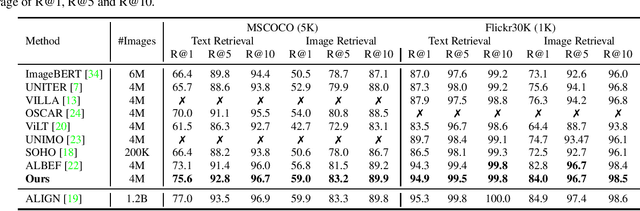
Vision-language representation learning largely benefits from image-text alignment through contrastive losses (e.g., InfoNCE loss). The success of this alignment strategy is attributed to its capability in maximizing the mutual information (MI) between an image and its matched text. However, simply performing cross-modal alignment (CMA) ignores data potential within each modality, which may result in degraded representations. For instance, although CMA-based models are able to map image-text pairs close together in the embedding space, they fail to ensure that similar inputs from the same modality stay close by. This problem can get even worse when the pre-training data is noisy. In this paper, we propose triple contrastive learning (TCL) for vision-language pre-training by leveraging both cross-modal and intra-modal self-supervision. Besides CMA, TCL introduces an intra-modal contrastive objective to provide complementary benefits in representation learning. To take advantage of localized and structural information from image and text input, TCL further maximizes the average MI between local regions of image/text and their global summary. To the best of our knowledge, ours is the first work that takes into account local structure information for multi-modality representation learning. Experimental evaluations show that our approach is competitive and achieve the new state of the art on various common down-stream vision-language tasks such as image-text retrieval and visual question answering.
Discovering Multiple and Diverse Directions for Cognitive Image Properties
Feb 23, 2022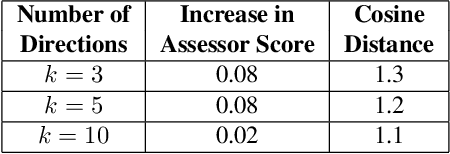
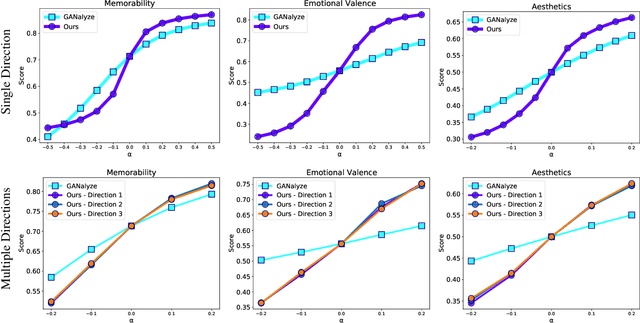


Recent research has shown that it is possible to find interpretable directions in the latent spaces of pre-trained GANs. These directions enable controllable generation and support a variety of semantic editing operations. While previous work has focused on discovering a single direction that performs a desired editing operation such as zoom-in, limited work has been done on the discovery of multiple and diverse directions that can achieve the desired edit. In this work, we propose a novel framework that discovers multiple and diverse directions for a given property of interest. In particular, we focus on the manipulation of cognitive properties such as Memorability, Emotional Valence and Aesthetics. We show with extensive experiments that our method successfully manipulates these properties while producing diverse outputs. Our project page and source code can be found at http://catlab-team.github.io/latentcognitive.
Image Compression with Encoder-Decoder Matched Semantic Segmentation
Jan 24, 2021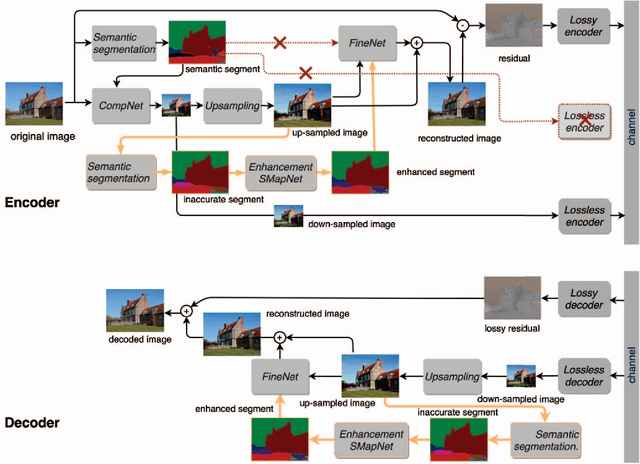

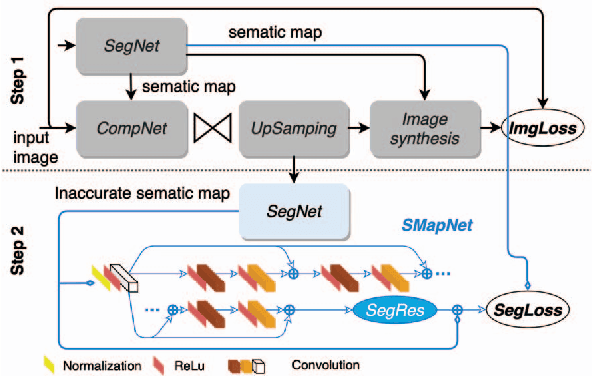
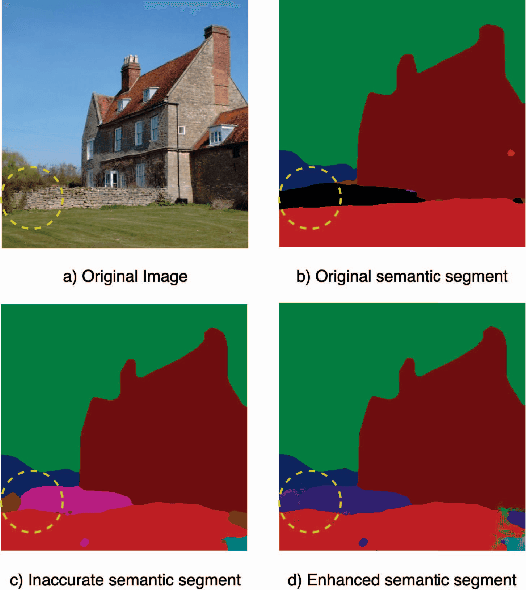
In recent years, layered image compression is demonstrated to be a promising direction, which encodes a compact representation of the input image and apply an up-sampling network to reconstruct the image. To further improve the quality of the reconstructed image, some works transmit the semantic segment together with the compressed image data. Consequently, the compression ratio is also decreased because extra bits are required for transmitting the semantic segment. To solve this problem, we propose a new layered image compression framework with encoder-decoder matched semantic segmentation (EDMS). And then, followed by the semantic segmentation, a special convolution neural network is used to enhance the inaccurate semantic segment. As a result, the accurate semantic segment can be obtained in the decoder without requiring extra bits. The experimental results show that the proposed EDMS framework can get up to 35.31% BD-rate reduction over the HEVC-based (BPG) codec, 5% bitrate, and 24% encoding time saving compare to the state-of-the-art semantic-based image codec.
Pyramidal Dense Attention Networks for Lightweight Image Super-Resolution
Jun 13, 2021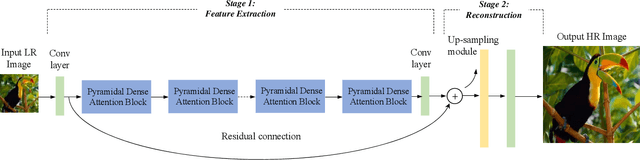
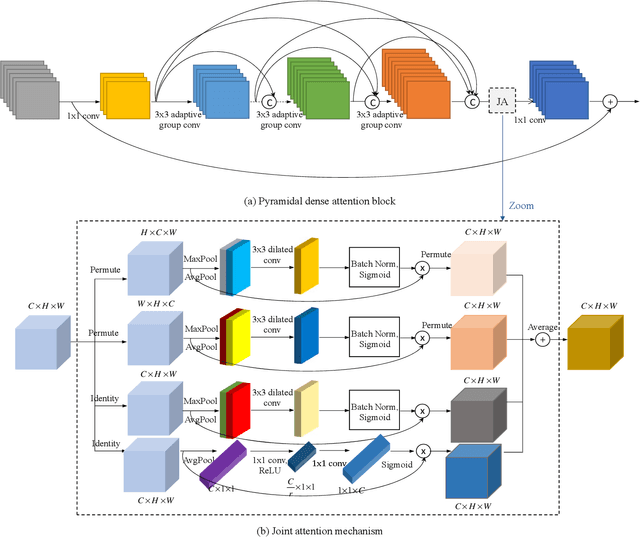

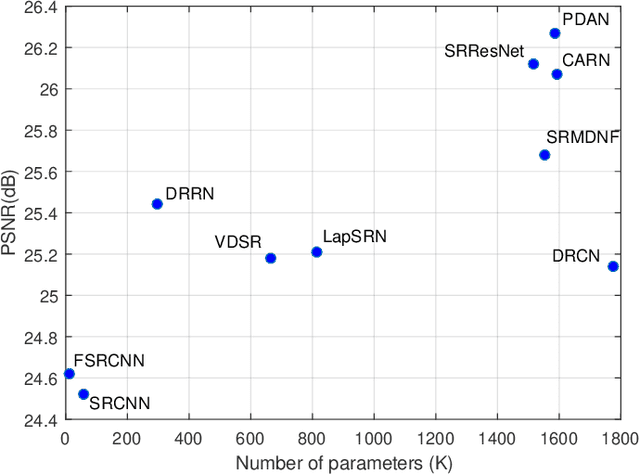
Recently, deep convolutional neural network methods have achieved an excellent performance in image superresolution (SR), but they can not be easily applied to embedded devices due to large memory cost. To solve this problem, we propose a pyramidal dense attention network (PDAN) for lightweight image super-resolution in this paper. In our method, the proposed pyramidal dense learning can gradually increase the width of the densely connected layer inside a pyramidal dense block to extract deep features efficiently. Meanwhile, the adaptive group convolution that the number of groups grows linearly with dense convolutional layers is introduced to relieve the parameter explosion. Besides, we also present a novel joint attention to capture cross-dimension interaction between the spatial dimensions and channel dimension in an efficient way for providing rich discriminative feature representations. Extensive experimental results show that our method achieves superior performance in comparison with the state-of-the-art lightweight SR methods.
OUR-GAN: One-shot Ultra-high-Resolution Generative Adversarial Networks
Feb 28, 2022

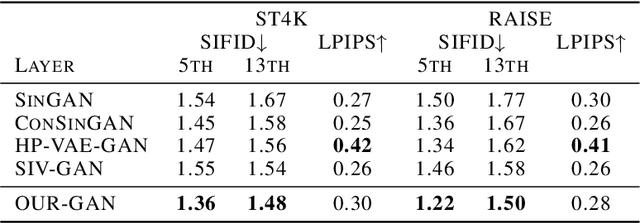
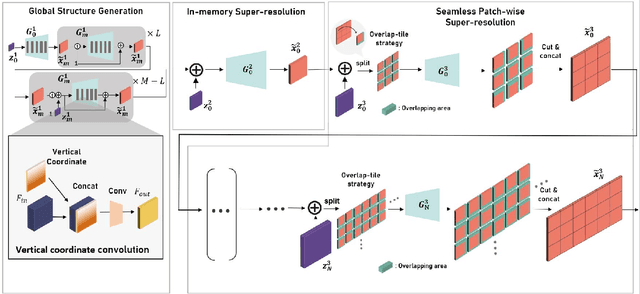
We propose OUR-GAN, the first one-shot ultra-high-resolution (UHR) image synthesis framework that generates non-repetitive images with 4K or higher resolution from a single training image. OUR-GAN generates a visually coherent image at low resolution and then gradually increases the resolution by super-resolution. Since OUR-GAN learns from a real UHR image, it can synthesize large-scale shapes with fine details while maintaining long-range coherence, which is difficult with conventional generative models that generate large images based on the patch distribution learned from relatively small images. OUR-GAN applies seamless subregion-wise super-resolution that synthesizes 4k or higher UHR images with limited memory, preventing discontinuity at the boundary. Additionally, OUR-GAN improves visual coherence maintaining diversity by adding vertical positional embeddings to the feature maps. In experiments on the ST4K and RAISE datasets, OUR-GAN exhibited improved fidelity, visual coherency, and diversity compared with existing methods. The synthesized images are presented at https://anonymous-62348.github.io.
Learning to segment with limited annotations: Self-supervised pretraining with regression and contrastive loss in MRI
May 26, 2022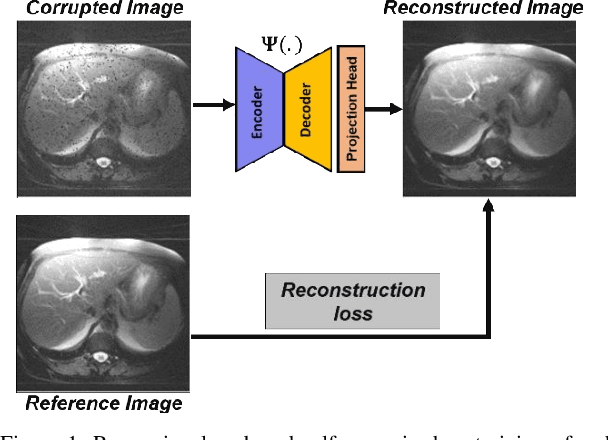
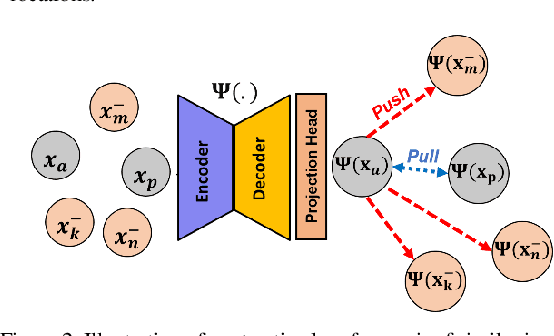
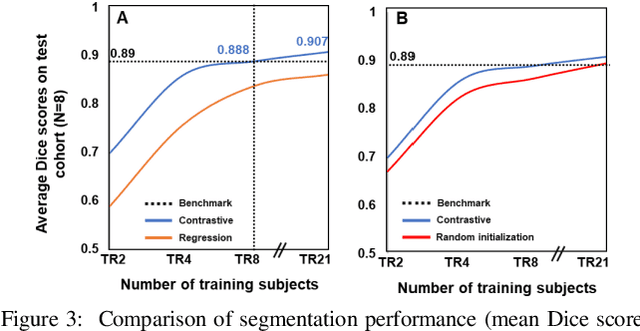
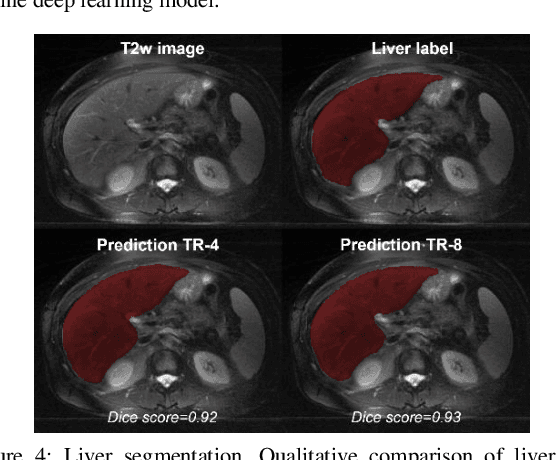
Obtaining manual annotations for large datasets for supervised training of deep learning (DL) models is challenging. The availability of large unlabeled datasets compared to labeled ones motivate the use of self-supervised pretraining to initialize DL models for subsequent segmentation tasks. In this work, we consider two pre-training approaches for driving a DL model to learn different representations using: a) regression loss that exploits spatial dependencies within an image and b) contrastive loss that exploits semantic similarity between pairs of images. The effect of pretraining techniques is evaluated in two downstream segmentation applications using Magnetic Resonance (MR) images: a) liver segmentation in abdominal T2-weighted MR images and b) prostate segmentation in T2-weighted MR images of the prostate. We observed that DL models pretrained using self-supervision can be finetuned for comparable performance with fewer labeled datasets. Additionally, we also observed that initializing the DL model using contrastive loss based pretraining performed better than the regression loss.
Image Classification on Small Datasets via Masked Feature Mixing
Feb 23, 2022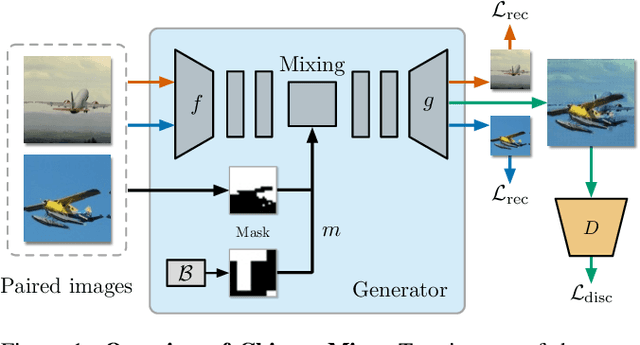
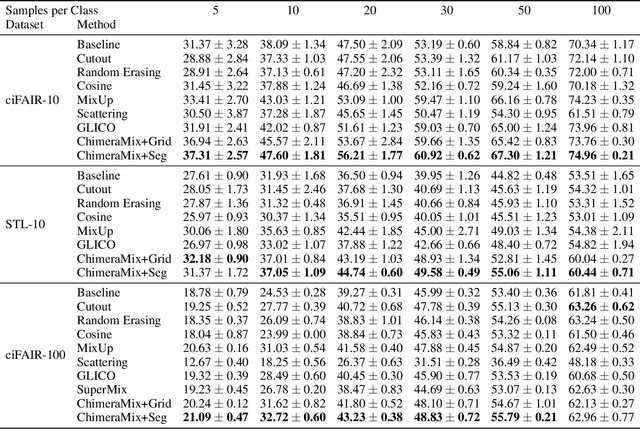

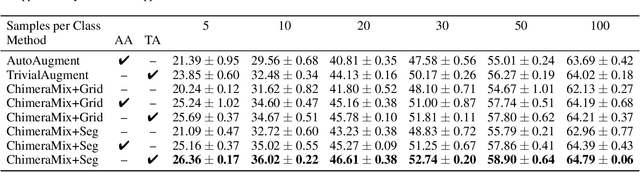
Deep convolutional neural networks require large amounts of labeled data samples. For many real-world applications, this is a major limitation which is commonly treated by augmentation methods. In this work, we address the problem of learning deep neural networks on small datasets. Our proposed architecture called ChimeraMix learns a data augmentation by generating compositions of instances. The generative model encodes images in pairs, combines the features guided by a mask, and creates new samples. For evaluation, all methods are trained from scratch without any additional data. Several experiments on benchmark datasets, e.g. ciFAIR-10, STL-10, and ciFAIR-100, demonstrate the superior performance of ChimeraMix compared to current state-of-the-art methods for classification on small datasets.
Pooling Revisited: Your Receptive Field is Suboptimal
May 30, 2022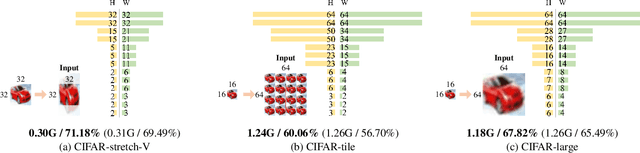
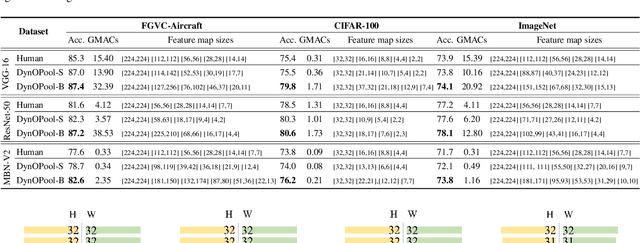
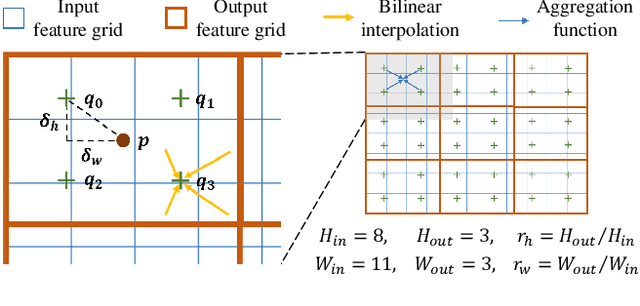
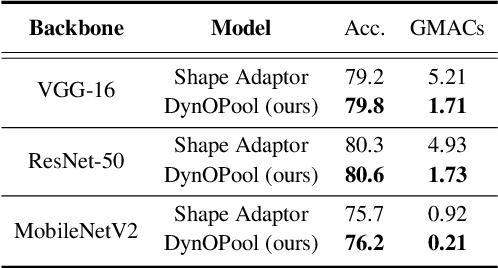
The size and shape of the receptive field determine how the network aggregates local information and affect the overall performance of a model considerably. Many components in a neural network, such as kernel sizes and strides for convolution and pooling operations, influence the configuration of a receptive field. However, they still rely on hyperparameters, and the receptive fields of existing models result in suboptimal shapes and sizes. Hence, we propose a simple yet effective Dynamically Optimized Pooling operation, referred to as DynOPool, which optimizes the scale factors of feature maps end-to-end by learning the desirable size and shape of its receptive field in each layer. Any kind of resizing modules in a deep neural network can be replaced by the operations with DynOPool at a minimal cost. Also, DynOPool controls the complexity of a model by introducing an additional loss term that constrains computational cost. Our experiments show that the models equipped with the proposed learnable resizing module outperform the baseline networks on multiple datasets in image classification and semantic segmentation.