 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Basis Models for Interpretability
Jun 08, 2022
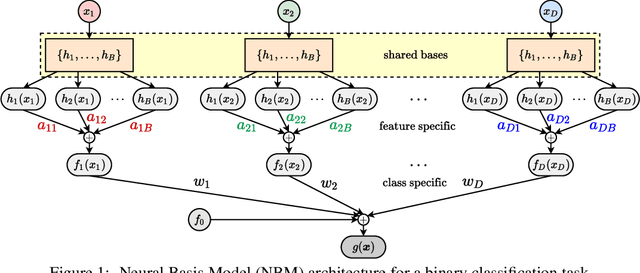
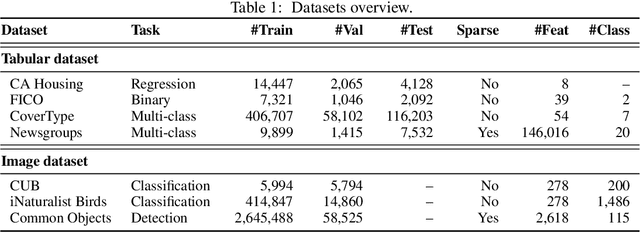
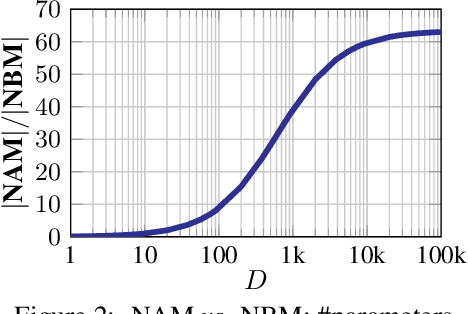
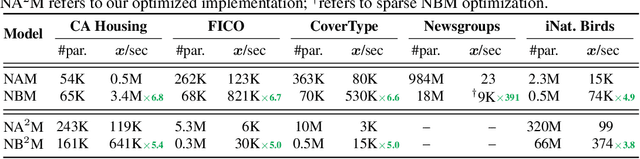
Due to the widespread use of complex machine learning models in real-world applications, it is becoming critical to explain model predictions. However, these models are typically black-box deep neural networks, explained post-hoc via methods with known faithfulness limitations. Generalized Additive Models (GAMs) are an inherently interpretable class of models that address this limitation by learning a non-linear shape function for each feature separately, followed by a linear model on top. However, these models are typically difficult to train, require numerous parameters, and are difficult to scale. We propose an entirely new subfamily of GAMs that utilizes basis decomposition of shape functions. A small number of basis functions are shared among all features, and are learned jointly for a given task, thus making our model scale much better to large-scale data with high-dimensional features, especially when features are sparse. We propose an architecture denoted as the Neural Basis Model (NBM) which uses a single neural network to learn these bases. On a variety of tabular and image datasets, we demonstrate that for interpretable machine learning, NBMs are the state-of-the-art in accuracy, model size, and, throughput and can easily model all higher-order feature interactions. Source code is available at https://github.com/facebookresearch/nbm-spam.
Correspondence Learning for Controllable Person Image Generation
Dec 23, 2020
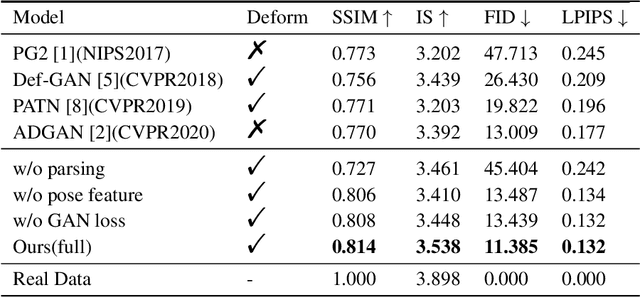
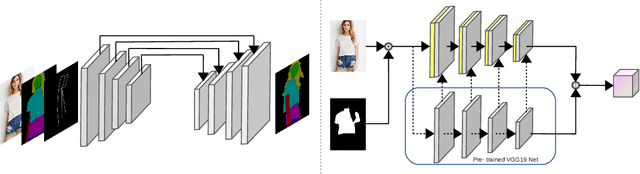
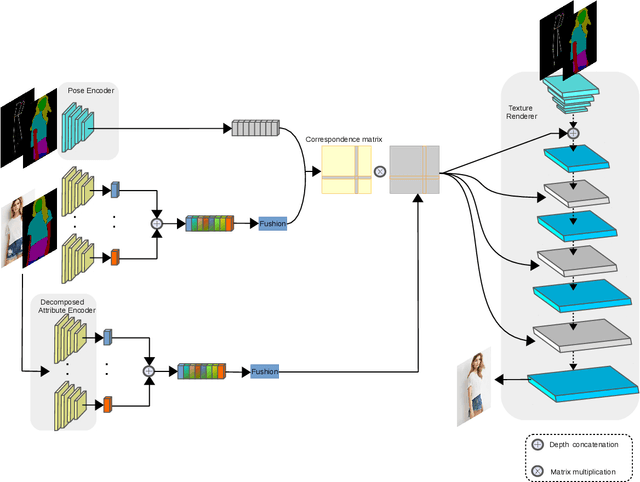
We present a generative model for controllable person image synthesis,as shown in Figure , which can be applied to pose-guided person image synthesis, $i.e.$, converting the pose of a source person image to the target pose while preserving the texture of that source person image, and clothing-guided person image synthesis, $i.e.$, changing the clothing texture of a source person image to the desired clothing texture. By explicitly establishing the dense correspondence between the target pose and the source image, we can effectively address the misalignment introduced by pose tranfer and generate high-quality images. Specifically, we first generate the target semantic map under the guidence of the target pose, which can provide more accurate pose representation and structural constraints during the generation process. Then, decomposed attribute encoder is used to extract the component features, which not only helps to establish a more accurate dense correspondence, but also realizes the clothing-guided person generation. After that, we will establish a dense correspondence between the target pose and the source image within the sharded domain. The source image feature is warped according to the dense correspondence to flexibly account for deformations. Finally, the network renders image based on the warped source image feature and the target pose. Experimental results show that our method is superior to state-of-the-art methods in pose-guided person generation and its effectiveness in clothing-guided person generation.
A Novel Graph-Theoretic Deep Representation Learning Method for Multi-Label Remote Sensing Image Retrieval
Jun 01, 2021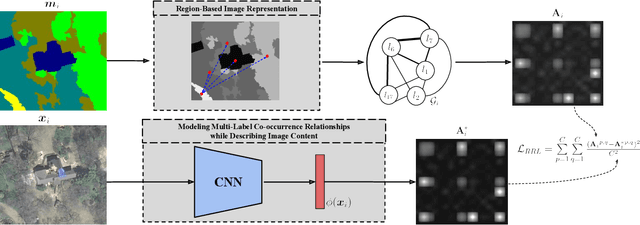
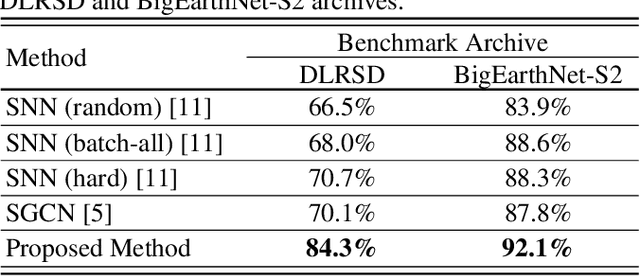
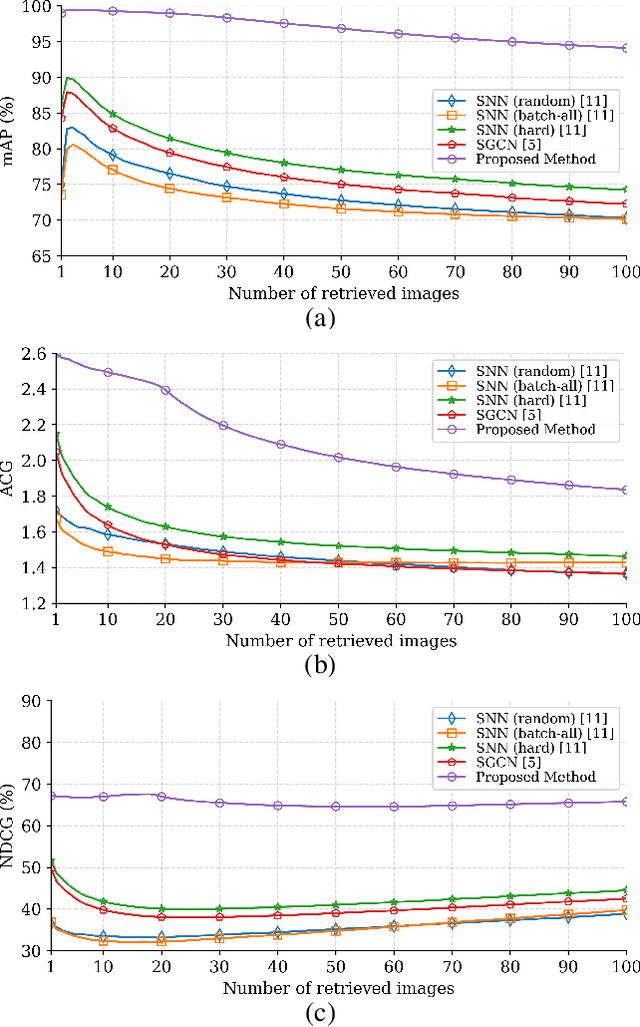
This paper presents a novel graph-theoretic deep representation learning method in the framework of multi-label remote sensing (RS) image retrieval problems. The proposed method aims to extract and exploit multi-label co-occurrence relationships associated to each RS image in the archive. To this end, each training image is initially represented with a graph structure that provides region-based image representation combining both local information and the related spatial organization. Unlike the other graph-based methods, the proposed method contains a novel learning strategy to train a deep neural network for automatically predicting a graph structure of each RS image in the archive. This strategy employs a region representation learning loss function to characterize the image content based on its multi-label co-occurrence relationship. Experimental results show the effectiveness of the proposed method for retrieval problems in RS compared to state-of-the-art deep representation learning methods. The code of the proposed method is publicly available at https://git.tu-berlin.de/rsim/GT-DRL-CBIR .
Few-Shot Diffusion Models
May 30, 2022

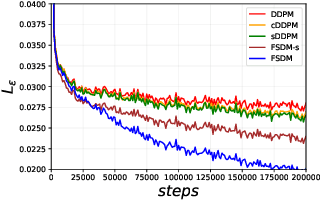
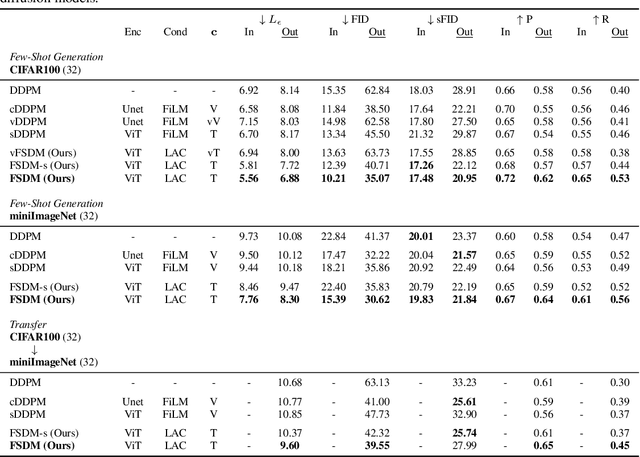
Denoising diffusion probabilistic models (DDPM) are powerful hierarchical latent variable models with remarkable sample generation quality and training stability. These properties can be attributed to parameter sharing in the generative hierarchy, as well as a parameter-free diffusion-based inference procedure. In this paper, we present Few-Shot Diffusion Models (FSDM), a framework for few-shot generation leveraging conditional DDPMs. FSDMs are trained to adapt the generative process conditioned on a small set of images from a given class by aggregating image patch information using a set-based Vision Transformer (ViT). At test time, the model is able to generate samples from previously unseen classes conditioned on as few as 5 samples from that class. We empirically show that FSDM can perform few-shot generation and transfer to new datasets. We benchmark variants of our method on complex vision datasets for few-shot learning and compare to unconditional and conditional DDPM baselines. Additionally, we show how conditioning the model on patch-based input set information improves training convergence.
Image Animation with Perturbed Masks
Nov 13, 2020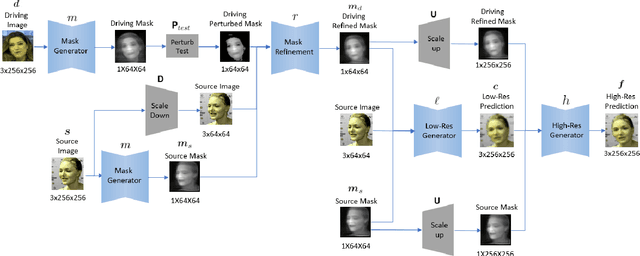
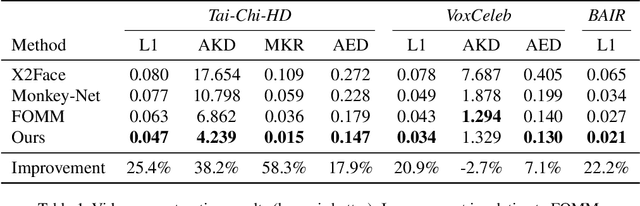
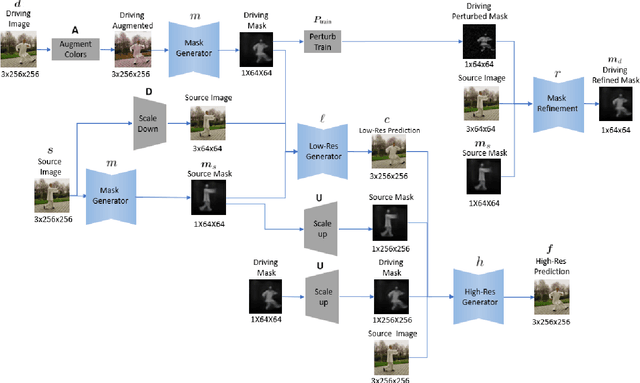
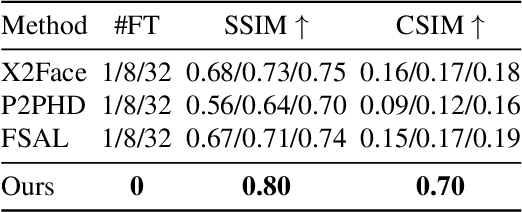
We present a novel approach for image-animation of a source image by a driving video, both depicting the same type of object. We do not assume the existence of pose models and our method is able to animate arbitrary objects without knowledge of the object's structure. Furthermore, both the driving video and the course image are only seen during test-time. Our method is based on a shared mask generator, which separates the foreground object from its background, and captures the object's general pose and shape. A mask-refinement module then replaces, in the mask extracted from the driver image, the identity of the driver with the identity of the source. Conditioned on the source image, the transformed mask is then decoded by a multi-scale generator that renders a realistic image, in which the content of the source frame is animated by the pose in the driving video. Due to lack of fully supervised data, we train on the task of reconstructing frames from the same video the source image is taken from. In order to control source of the identity of the output frame, we employ during training perturbations that remove the unwanted identity information. Our method is shown to greatly outperform the state of the art methods on multiple benchmarks. Our code and samples are available at https://github.com/itsyoavshalev/Image-Animation-with-Perturbed-Masks.
Learning a Model-Driven Variational Network for Deformable Image Registration
May 25, 2021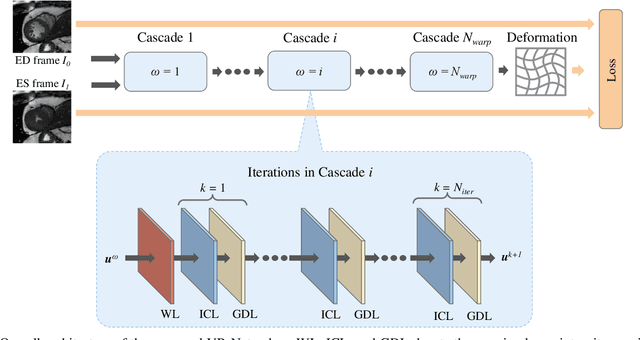
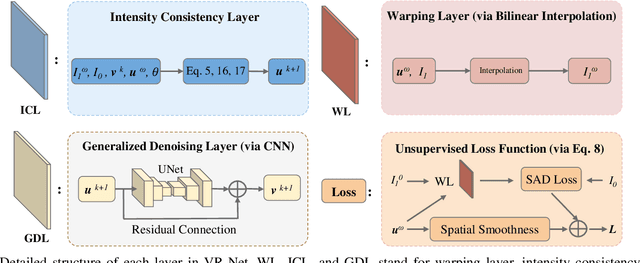
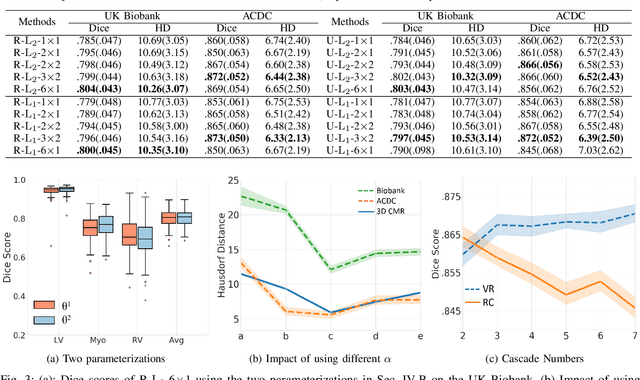
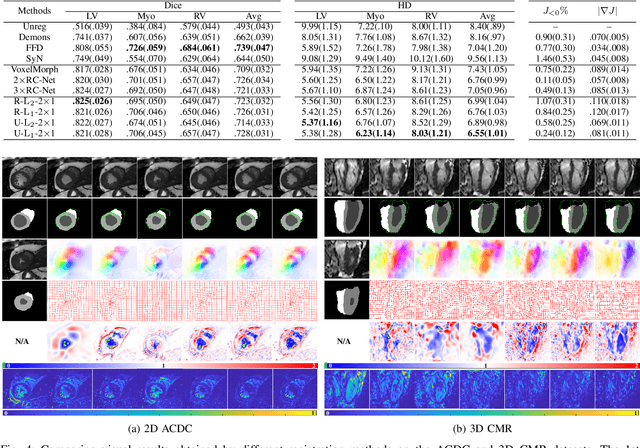
Data-driven deep learning approaches to image registration can be less accurate than conventional iterative approaches, especially when training data is limited. To address this whilst retaining the fast inference speed of deep learning, we propose VR-Net, a novel cascaded variational network for unsupervised deformable image registration. Using the variable splitting optimization scheme, we first convert the image registration problem, established in a generic variational framework, into two sub-problems, one with a point-wise, closed-form solution while the other one is a denoising problem. We then propose two neural layers (i.e. warping layer and intensity consistency layer) to model the analytical solution and a residual U-Net to formulate the denoising problem (i.e. generalized denoising layer). Finally, we cascade the warping layer, intensity consistency layer, and generalized denoising layer to form the VR-Net. Extensive experiments on three (two 2D and one 3D) cardiac magnetic resonance imaging datasets show that VR-Net outperforms state-of-the-art deep learning methods on registration accuracy, while maintains the fast inference speed of deep learning and the data-efficiency of variational model.
Training Vision Transformers for Image Retrieval
Feb 10, 2021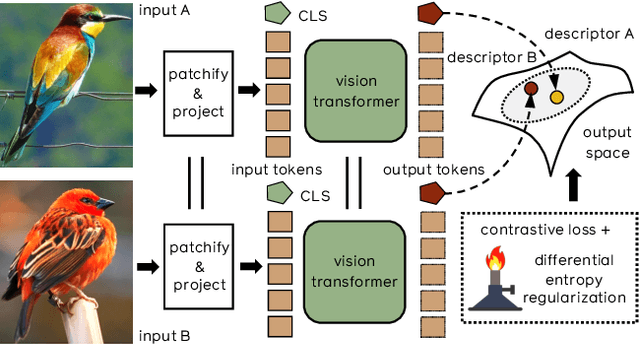
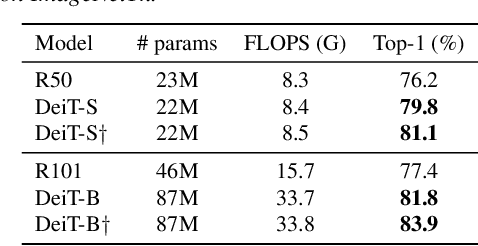
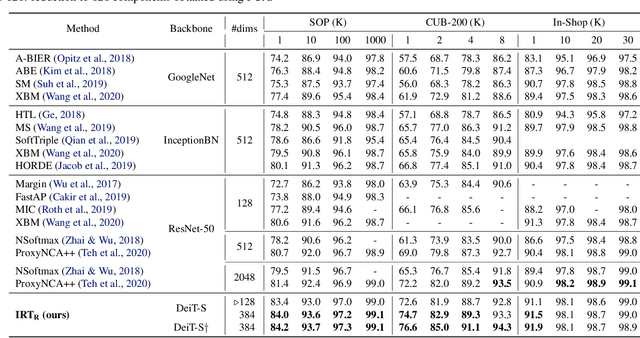
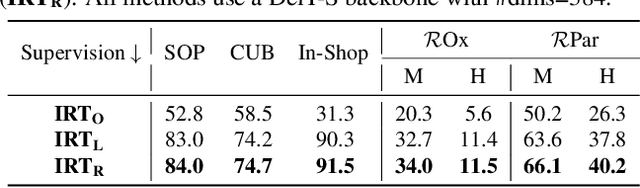
Transformers have shown outstanding results for natural language understanding and, more recently, for image classification. We here extend this work and propose a transformer-based approach for image retrieval: we adopt vision transformers for generating image descriptors and train the resulting model with a metric learning objective, which combines a contrastive loss with a differential entropy regularizer. Our results show consistent and significant improvements of transformers over convolution-based approaches. In particular, our method outperforms the state of the art on several public benchmarks for category-level retrieval, namely Stanford Online Product, In-Shop and CUB-200. Furthermore, our experiments on ROxford and RParis also show that, in comparable settings, transformers are competitive for particular object retrieval, especially in the regime of short vector representations and low-resolution images.
Layer Ensembles: A Single-Pass Uncertainty Estimation in Deep Learning for Segmentation
Mar 16, 2022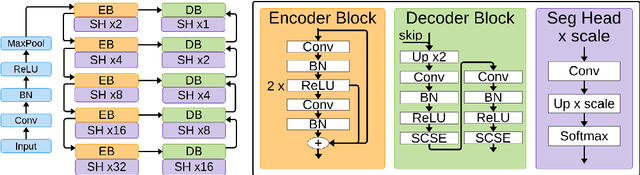

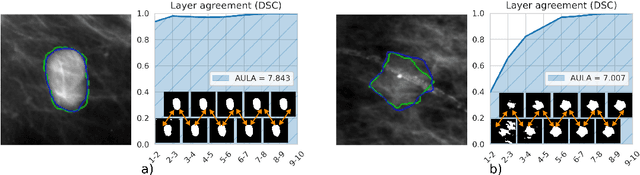
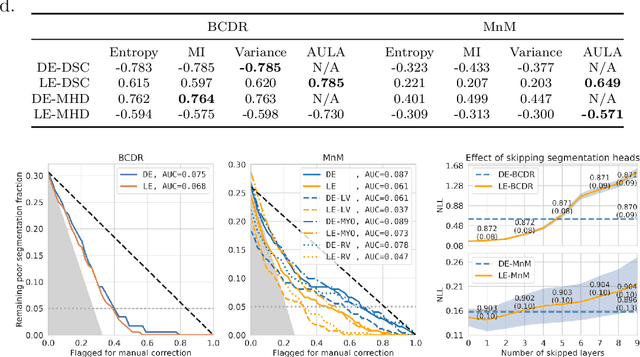
Uncertainty estimation in deep learning has become a leading research field in medical image analysis due to the need for safe utilisation of AI algorithms in clinical practice. Most approaches for uncertainty estimation require sampling the network weights multiple times during testing or training multiple networks. This leads to higher training and testing costs in terms of time and computational resources. In this paper, we propose Layer Ensembles, a novel uncertainty estimation method that uses a single network and requires only a single pass to estimate predictive uncertainty of a network. Moreover, we introduce an image-level uncertainty metric, which is more beneficial for segmentation tasks compared to the commonly used pixel-wise metrics such as entropy and variance. We evaluate our approach on 2D and 3D, binary and multi-class medical image segmentation tasks. Our method shows competitive results with state-of-the-art Deep Ensembles, requiring only a single network and a single pass.
Effect of Parameter Optimization on Classical and Learning-based Image Matching Methods
Aug 18, 2021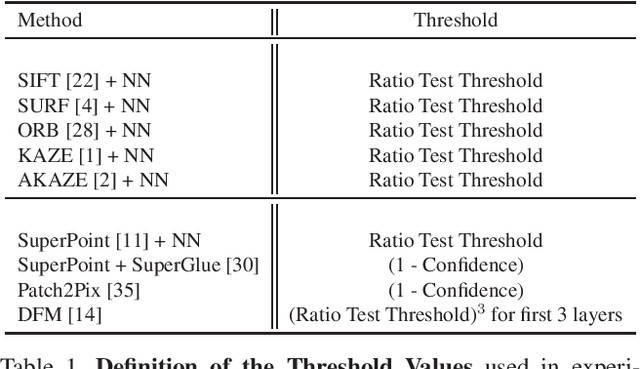
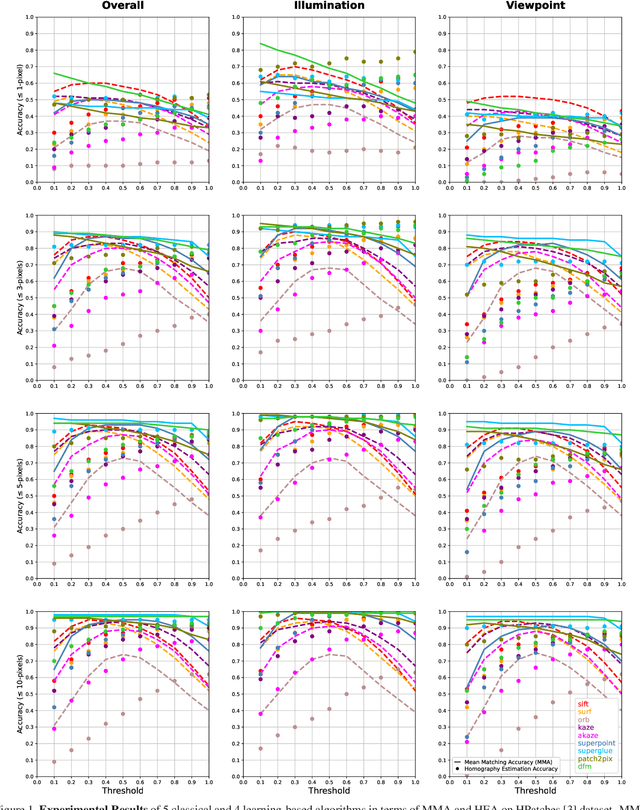
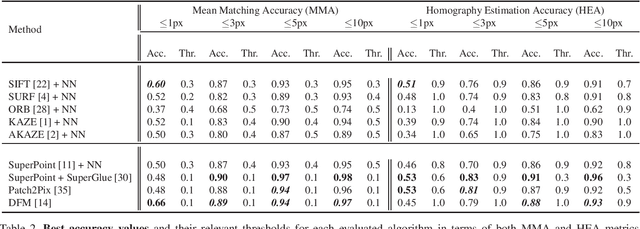
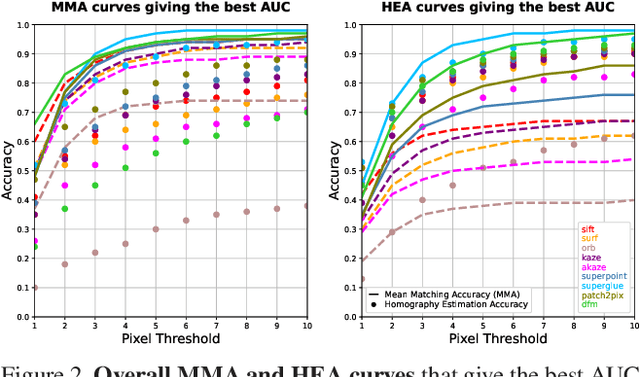
Deep learning-based image matching methods are improved significantly during the recent years. Although these methods are reported to outperform the classical techniques, the performance of the classical methods is not examined in detail. In this study, we compare classical and learning-based methods by employing mutual nearest neighbor search with ratio test and optimizing the ratio test threshold to achieve the best performance on two different performance metrics. After a fair comparison, the experimental results on HPatches dataset reveal that the performance gap between classical and learning-based methods is not that significant. Throughout the experiments, we demonstrated that SuperGlue is the state-of-the-art technique for the image matching problem on HPatches dataset. However, if a single parameter, namely ratio test threshold, is carefully optimized, a well-known traditional method SIFT performs quite close to SuperGlue and even outperforms in terms of mean matching accuracy (MMA) under 1 and 2 pixel thresholds. Moreover, a recent approach, DFM, which only uses pre-trained VGG features as descriptors and ratio test, is shown to outperform most of the well-trained learning-based methods. Therefore, we conclude that the parameters of any classical method should be analyzed carefully before comparing against a learning-based technique.
OmniFusion: 360 Monocular Depth Estimation via Geometry-Aware Fusion
Mar 29, 2022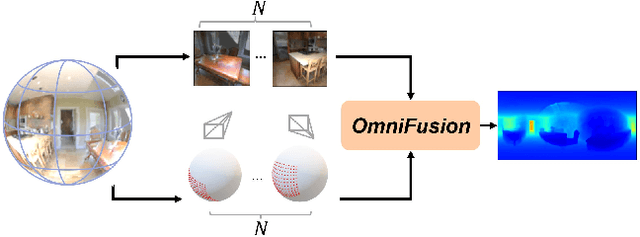
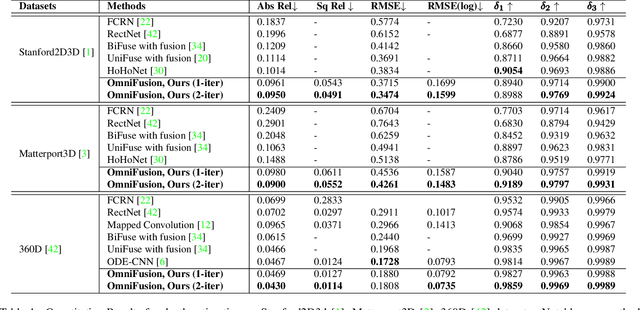
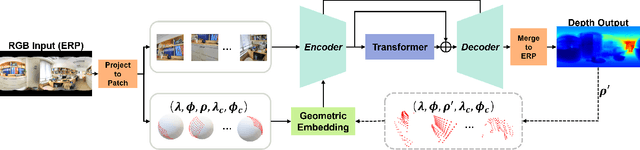

A well-known challenge in applying deep-learning methods to omnidirectional images is spherical distortion. In dense regression tasks such as depth estimation, where structural details are required, using a vanilla CNN layer on the distorted 360 image results in undesired information loss. In this paper, we propose a 360 monocular depth estimation pipeline, OmniFusion, to tackle the spherical distortion issue. Our pipeline transforms a 360 image into less-distorted perspective patches (i.e. tangent images) to obtain patch-wise predictions via CNN, and then merge the patch-wise results for final output. To handle the discrepancy between patch-wise predictions which is a major issue affecting the merging quality, we propose a new framework with the following key components. First, we propose a geometry-aware feature fusion mechanism that combines 3D geometric features with 2D image features to compensate for the patch-wise discrepancy. Second, we employ the self-attention-based transformer architecture to conduct a global aggregation of patch-wise information, which further improves the consistency. Last, we introduce an iterative depth refinement mechanism, to further refine the estimated depth based on the more accurate geometric features. Experiments show that our method greatly mitigates the distortion issue, and achieves state-of-the-art performances on several 360 monocular depth estimation benchmark datasets.