 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From a few Accurate 2D Correspondences to 3D Point Clouds
Jun 13, 2022




Key points, correspondences, projection matrices, point clouds and dense clouds are the skeletons in image-based 3D reconstruction, of which point clouds have the important role in generating a realistic and natural model for a 3D reconstructed object. To achieve a good 3D reconstruction, the point clouds must be almost everywhere in the surface of the object. In this article, with a main purpose to build the point clouds covering the entire surface of the object, we propose a new feature named a geodesic feature or geo-feature. Based on the new geo-feature, if there are several (given) initial world points on the object's surface along with all accurately estimated projection matrices, some new world points on the geodesics connecting any two of these given world points will be reconstructed. Then the regions on the surface bordering by these initial world points will be covered by the point clouds. Thus, if the initial world points are around the surface, the point clouds will cover the entire surface. This article proposes a new method to estimate the world points and projection matrices from their correspondences. This method derives the closed-form and iterative solutions for the world points and projection matrices and proves that when the number of world points is less than seven and the number of images is at least five, the proposed solutions are global optimal. We propose an algorithm named World points from their Correspondences (WPfC) to estimate the world points and projection matrices from their correspondences, and another algorithm named Creating Point Clouds (CrPC) to create the point clouds from the world points and projection matrices given by the first algorithm.
SIGAN: A Novel Image Generation Method for Solar Cell Defect Segmentation and Augmentation
Apr 11, 2021
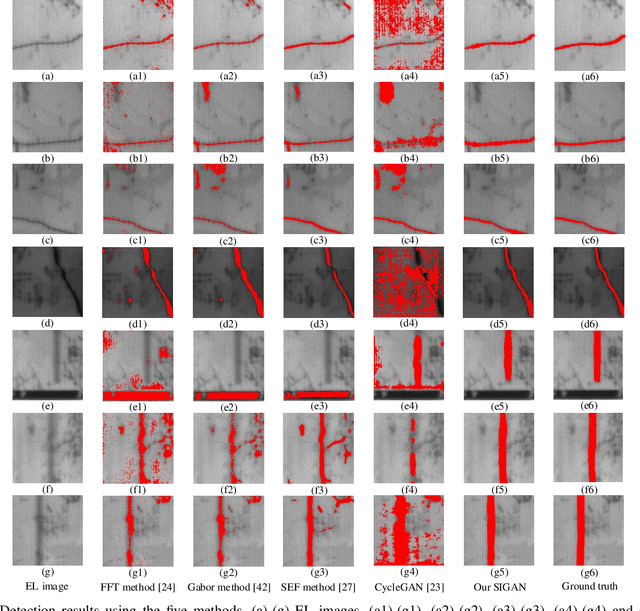
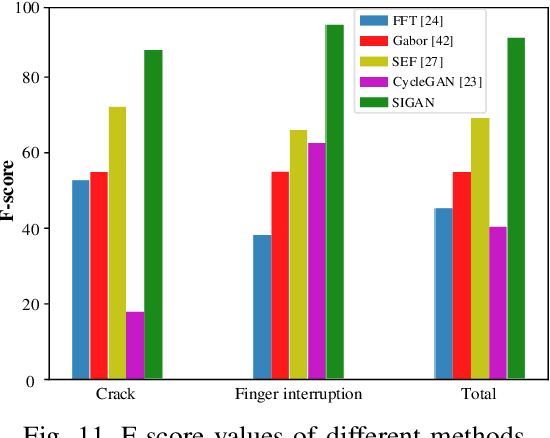
Solar cell electroluminescence (EL) defect segmentation is an interesting and challenging topic. Many methods have been proposed for EL defect detection, but these methods are still unsatisfactory due to the diversity of the defect and background. In this paper, we provide a new idea of using generative adversarial network (GAN) for defect segmentation. Firstly, the GAN-based method removes the defect region in the input defective image to get a defect-free image, while keeping the background almost unchanged. Then, the subtracted image is obtained by making difference between the defective input image with the generated defect-free image. Finally, the defect region can be segmented through thresholding the subtracted image. To keep the background unchanged before and after image generation, we propose a novel strong identity GAN (SIGAN), which adopts a novel strong identity loss to constraint the background consistency. The SIGAN can be used not only for defect segmentation, but also small-samples defective dataset augmentation. Moreover, we release a new solar cell EL image dataset named as EL-2019, which includes three types of images: crack, finger interruption and defect-free. Experiments on EL-2019 dataset show that the proposed method achieves 90.34% F-score, which outperforms many state-of-the-art methods in terms of solar cell defects segmentation results.
Grasping the Arrow of Time from the Singularity: Decoding Micromotion in Low-dimensional Latent Spaces from StyleGAN
Apr 27, 2022
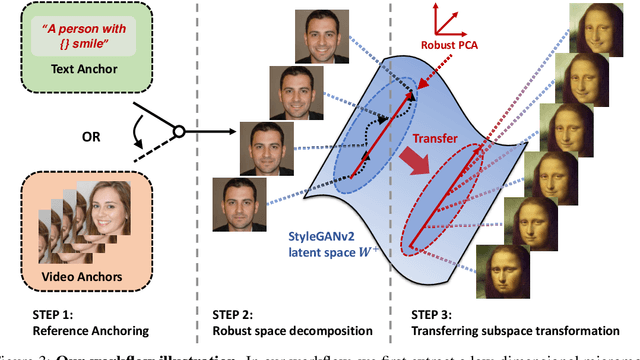


The disentanglement of StyleGAN latent space has paved the way for realistic and controllable image editing, but does StyleGAN know anything about temporal motion, as it was only trained on static images? To study the motion features in the latent space of StyleGAN, in this paper, we hypothesize and demonstrate that a series of meaningful, natural, and versatile small, local movements (referred to as "micromotion", such as expression, head movement, and aging effect) can be represented in low-rank spaces extracted from the latent space of a conventionally pre-trained StyleGAN-v2 model for face generation, with the guidance of proper "anchors" in the form of either short text or video clips. Starting from one target face image, with the editing direction decoded from the low-rank space, its micromotion features can be represented as simple as an affine transformation over its latent feature. Perhaps more surprisingly, such micromotion subspace, even learned from just single target face, can be painlessly transferred to other unseen face images, even those from vastly different domains (such as oil painting, cartoon, and sculpture faces). It demonstrates that the local feature geometry corresponding to one type of micromotion is aligned across different face subjects, and hence that StyleGAN-v2 is indeed "secretly" aware of the subject-disentangled feature variations caused by that micromotion. We present various successful examples of applying our low-dimensional micromotion subspace technique to directly and effortlessly manipulate faces, showing high robustness, low computational overhead, and impressive domain transferability. Our codes are available at https://github.com/wuqiuche/micromotion-StyleGAN.
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
May 27, 2022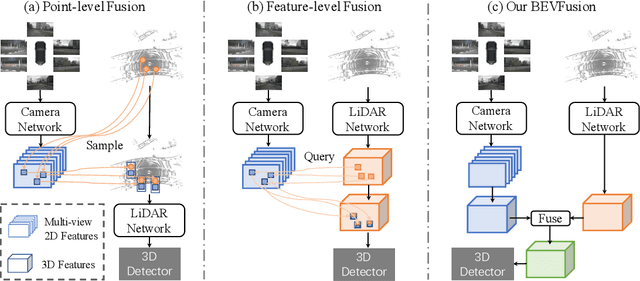

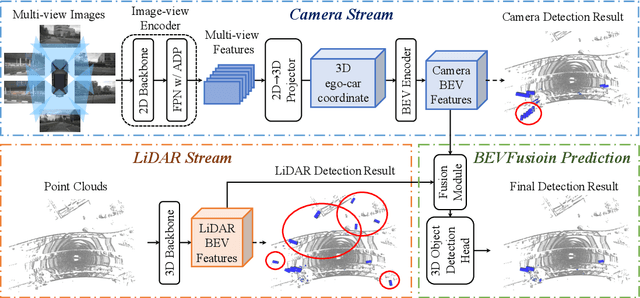
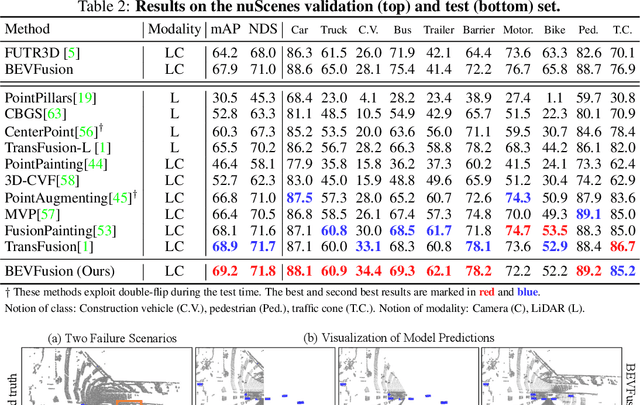
Fusing the camera and LiDAR information has become a de-facto standard for 3D object detection tasks. Current methods rely on point clouds from the LiDAR sensor as queries to leverage the feature from the image space. However, people discover that this underlying assumption makes the current fusion framework infeasible to produce any prediction when there is a LiDAR malfunction, regardless of minor or major. This fundamentally limits the deployment capability to realistic autonomous driving scenarios. In contrast, we propose a surprisingly simple yet novel fusion framework, dubbed BEVFusion, whose camera stream does not depend on the input of LiDAR data, thus addressing the downside of previous methods. We empirically show that our framework surpasses the state-of-the-art methods under the normal training settings. Under the robustness training settings that simulate various LiDAR malfunctions, our framework significantly surpasses the state-of-the-art methods by 15.7% to 28.9% mAP. To the best of our knowledge, we are the first to handle realistic LiDAR malfunction and can be deployed to realistic scenarios without any post-processing procedure. The code is available at https://github.com/ADLab-AutoDrive/BEVFusion.
Vision Xformers: Efficient Attention for Image Classification
Jul 05, 2021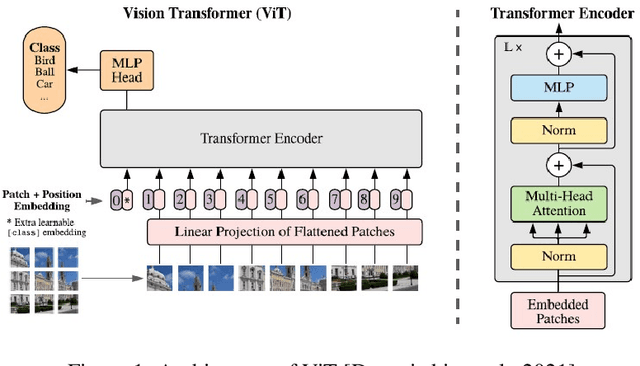

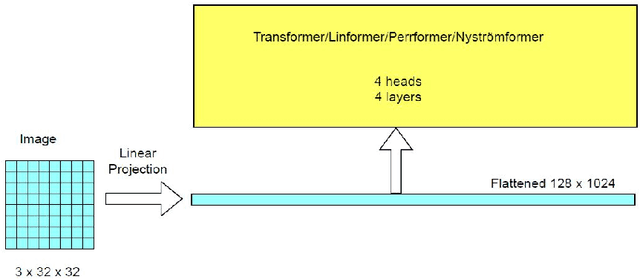

Linear attention mechanisms provide hope for overcoming the bottleneck of quadratic complexity which restricts application of transformer models in vision tasks. We modify the ViT architecture to work on longer sequence data by replacing the quadratic attention with efficient transformers like Performer, Linformer and Nystr\"omformer of linear complexity creating Vision X-formers (ViX). We show that ViX performs better than ViT in image classification consuming lesser computing resources. We further show that replacing the embedding linear layer by convolutional layers in ViX further increases their performance. Our test on recent visions transformer models like LeViT and Compact Convolutional Transformer (CCT) show that replacing the attention with Nystr\"omformer or Performer saves GPU usage and memory without deteriorating performance. Incorporating these changes can democratize transformers by making them accessible to those with limited data and computing resources.
Variational Image Restoration Network
Aug 25, 2020
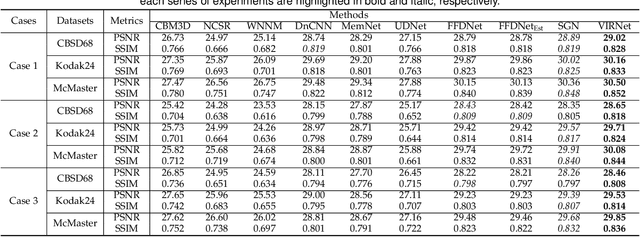
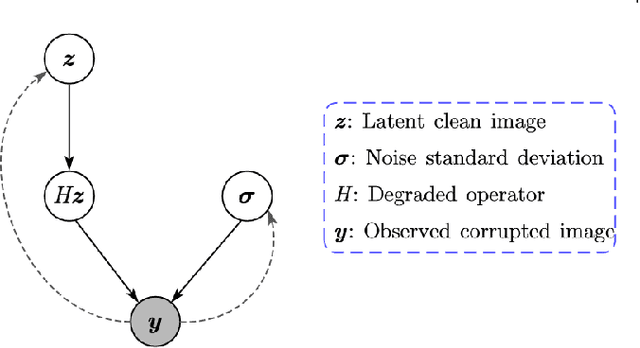
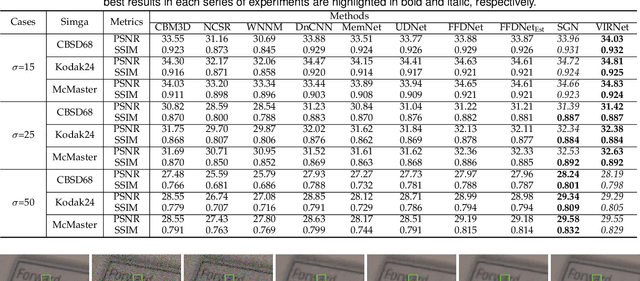
Deep neural networks (DNNs) have achieved significant success in image restoration tasks by directly learning a powerful non-linear mapping from corrupted images to their latent clean ones. However, there still exist two major limitations for these deep learning (DL)-based methods. Firstly, the noises contained in real corrupted images are very complex, usually neglected and largely under-estimated in most current methods. Secondly, existing DL methods are mostly trained on one pre-assumed degradation process for all of the training image pairs, such as the widely used bicubic downsampling assumption in the image super-resolution task, inevitably leading to poor generalization performance when the true degradation does not match with such assumed one. To address these issues, we propose a unified generative model for the image restoration, which elaborately configures the degradation process from the latent clean image to the observed corrupted one. Specifically, different from most of current methods, the pixel-wisely non-i.i.d. Gaussian distribution, being with more flexibility, is adopted in our method to fit the complex real noises. Furthermore, the method is built on the general image degradation process, making it capable of adapting diverse degradations under one single model. Besides, we design a variational inference algorithm to learn all parameters involved in the proposed model with explicit form of objective loss. Specifically, beyond traditional variational methodology, two DNNs are employed to parameterize the posteriori distributions, one to infer the distribution of the latent clean image, and another to infer the distribution of the image noise. Extensive experiments demonstrate the superiority of the proposed method on three classical image restoration tasks, including image denoising, image super-resolution and JPEG image deblocking.
Real-time FPGA Design for OMP Targeting 8K Image Reconstruction
Oct 10, 2021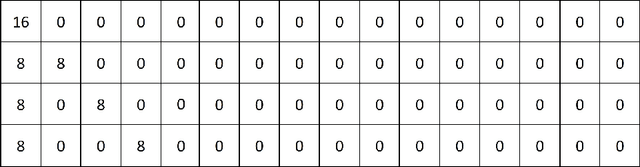
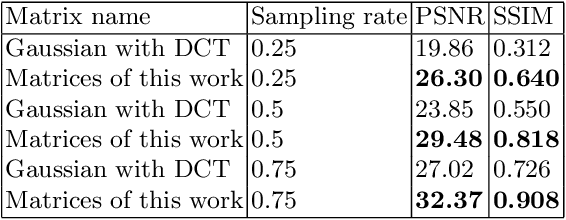

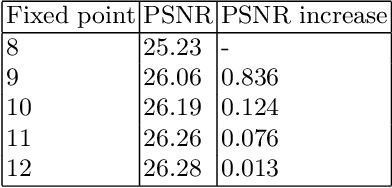
During the past decade, implementing reconstruction algorithms on hardware has been at the center of much attention in the field of real-time reconstruction in Compressed Sensing (CS). Orthogonal Matching Pursuit (OMP) is the most widely used reconstruction algorithm on hardware implementation because OMP obtains good quality reconstruction results under a proper time cost. OMP includes Dot Product (DP) and Least Square Problem (LSP). These two parts have numerous division calculations and considerable vector-based multiplications, which limit the implementation of real-time reconstruction on hardware. In the theory of CS, besides the reconstruction algorithm, the choice of sensing matrix affects the quality of reconstruction. It also influences the reconstruction efficiency by affecting the hardware architecture. Thus, designing a real-time hardware architecture of OMP needs to take three factors into consideration. The choice of sensing matrix, the implementation of DP and LSP. In this paper, a sensing matrix, which is sparsity and contains zero vectors mainly, is adopted to optimize the OMP reconstruction to break the bottleneck of reconstruction efficiency. Based on the features of the chosen matrix, the DP and LSP are implemented by simple shift, add and comparing procedures. This work is implemented on the Xilinx Virtex UltraScale+ FPGA device. To reconstruct a digital signal with 1024 length under 0.25 sampling rate, the proposal method costs 0.818us while the state-of-the-art costs 238$us. Thus, this work speedups the state-of-the-art method 290 times. This work costs 0.026s to reconstruct an 8K gray image, which achieves 30FPS real-time reconstruction.
Pseudo-Data based Self-Supervised Federated Learning for Classification of Histopathological Images
May 31, 2022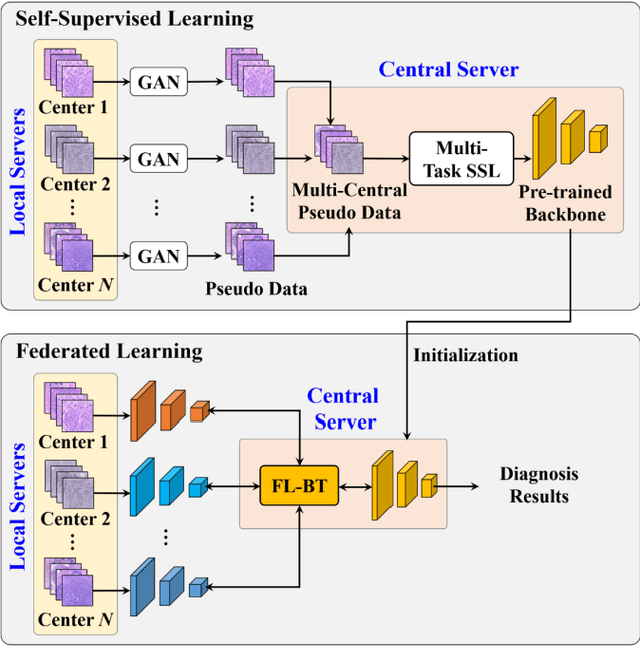
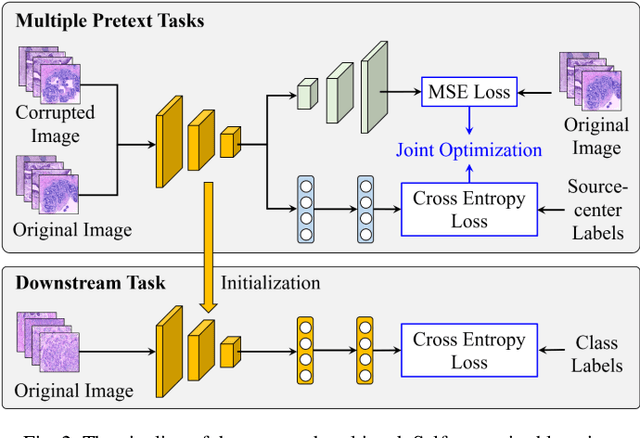
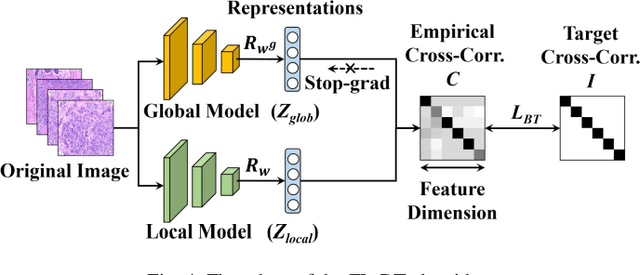
Computer-aided diagnosis (CAD) can help pathologists improve diagnostic accuracy together with consistency and repeatability for cancers. However, the CAD models trained with the histopathological images only from a single center (hospital) generally suffer from the generalization problem due to the straining inconsistencies among different centers. In this work, we propose a pseudo-data based self-supervised federated learning (FL) framework, named SSL-FT-BT, to improve both the diagnostic accuracy and generalization of CAD models. Specifically, the pseudo histopathological images are generated from each center, which contains inherent and specific properties corresponding to the real images in this center, but does not include the privacy information. These pseudo images are then shared in the central server for self-supervised learning (SSL). A multi-task SSL is then designed to fully learn both the center-specific information and common inherent representation according to the data characteristics. Moreover, a novel Barlow Twins based FL (FL-BT) algorithm is proposed to improve the local training for the CAD model in each center by conducting contrastive learning, which benefits the optimization of the global model in the FL procedure. The experimental results on three public histopathological image datasets indicate the effectiveness of the proposed SSL-FL-BT on both diagnostic accuracy and generalization.
CIGMO: Categorical invariant representations in a deep generative framework
May 27, 2022
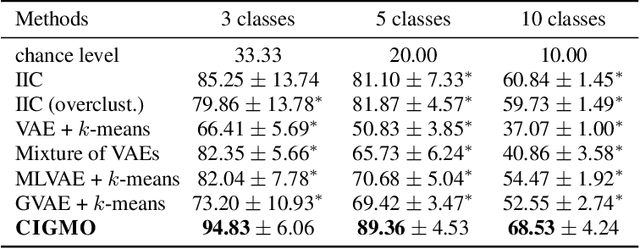

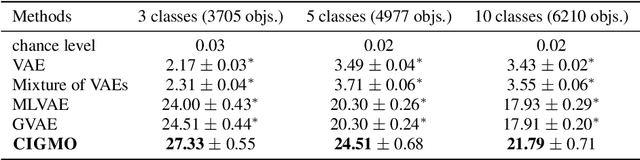
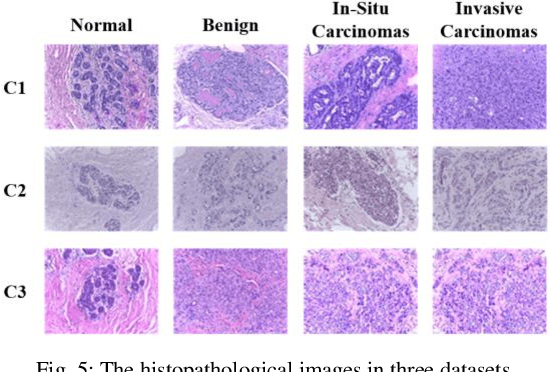
Data of general object images have two most common structures: (1) each object of a given shape can be rendered in multiple different views, and (2) shapes of objects can be categorized in such a way that the diversity of shapes is much larger across categories than within a category. Existing deep generative models can typically capture either structure, but not both. In this work, we introduce a novel deep generative model, called CIGMO, that can learn to represent category, shape, and view factors from image data. The model is comprised of multiple modules of shape representations that are each specialized to a particular category and disentangled from view representation, and can be learned using a group-based weakly supervised learning method. By empirical investigation, we show that our model can effectively discover categories of object shapes despite large view variation and quantitatively supersede various previous methods including the state-of-the-art invariant clustering algorithm. Further, we show that our approach using category-specialization can enhance the learned shape representation to better perform down-stream tasks such as one-shot object identification as well as shape-view disentanglement.
Gastrointestinal Polyps and Tumors Detection Based on Multi-scale Feature-fusion with WCE Sequences
Apr 03, 2022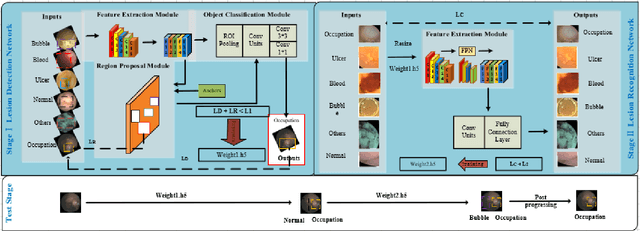

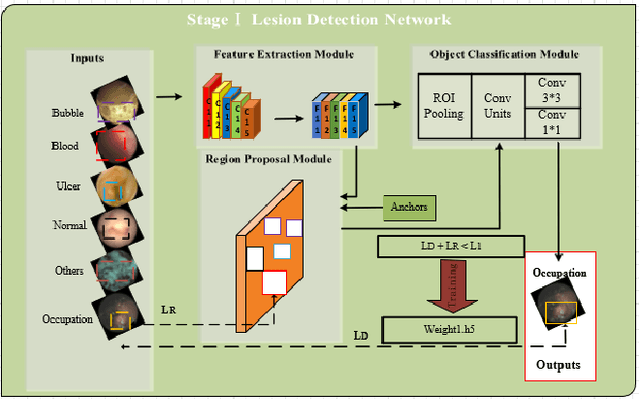
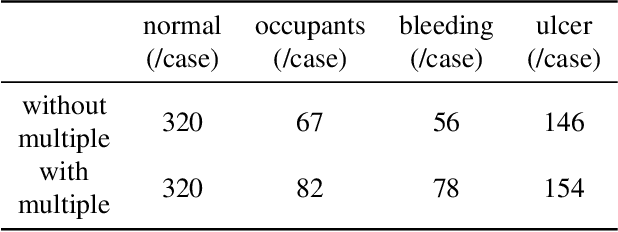
Wireless Capsule Endoscopy(WCE) has been widely used for the screening of gastrointestinal(GI) diseases, especially the small intestine, due to its advantages of non-invasive and painless imaging of the entire digestive tract.However, the huge amount of image data captured by WCE makes manual reading a process that requires a huge amount of tasks and can easily lead to missed detection and false detection of lesions.Therefore, In this paper, we propose a \textbf{T}wo-stage \textbf{M}ulti-scale \textbf{F}eature-fusion learning network(\textbf{TMFNet}) to automatically detect small intestinal polyps and tumors in WCE image sequences. Specifically, TMFNet consists of lesion detection network and lesion identification network. Among them, the former improves the feature extraction module and detection module based on the traditional Faster R-CNN network, and readjusts the parameters of the anchor in the region proposal network(RPN) module;the latter combines residual structure and feature pyramid structure are used to build a small intestinal lesion recognition network based on feature fusion, for reducing the false positive rate of the former and improve the overall accuracy.We used 22,335 WCE images in the experiment, with a total of 123,092 lesion regions used to train the detection framework of this paper. In the experiment, the detection framework is trained and tested on the real WCE image dataset provided by the hospital gastroenterology department. The sensitivity, false positive and accuracy of the final model on the RPM are 98.81$\%$, 7.43$\%$ and 92.57$\%$, respectively.Meanwhile,the corresponding results on the lesion images were 98.75$\%$, 5.62$\%$ and 94.39$\%$. The algorithm model proposed in this paper is obviously superior to other detection algorithms in detection effect and performance