 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Controllable Confidence-Based Image Denoising
Jun 17, 2021
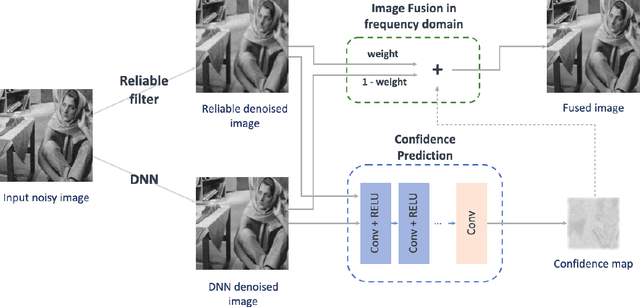
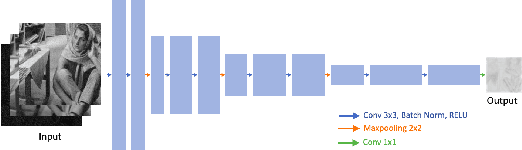
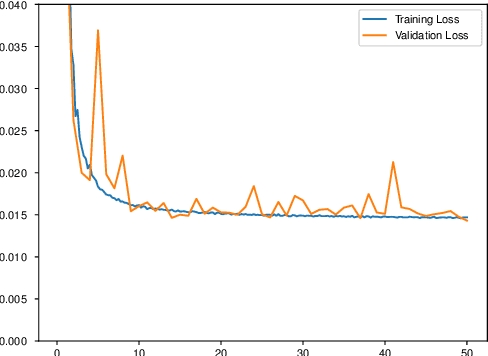
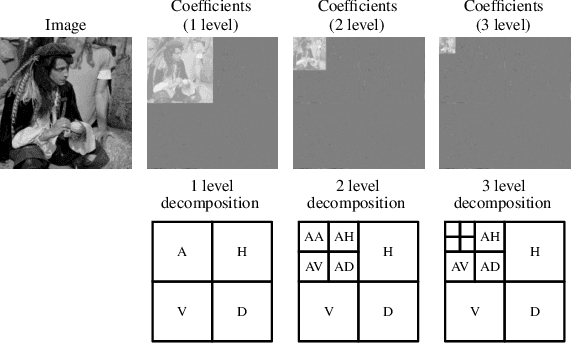
Image denoising is a classic restoration problem. Yet, current deep learning methods are subject to the problems of generalization and interpretability. To mitigate these problems, in this project, we present a framework that is capable of controllable, confidence-based noise removal. The framework is based on the fusion between two different denoised images, both derived from the same noisy input. One of the two is denoised using generic algorithms (e.g. Gaussian), which make few assumptions on the input images, therefore, generalize in all scenarios. The other is denoised using deep learning, performing well on seen datasets. We introduce a set of techniques to fuse the two components smoothly in the frequency domain. Beyond that, we estimate the confidence of a deep learning denoiser to allow users to interpret the output, and provide a fusion strategy that safeguards them against out-of-distribution inputs. Through experiments, we demonstrate the effectiveness of the proposed framework in different use cases.
Impact of deep learning-based image super-resolution on binary signal detection
Jul 06, 2021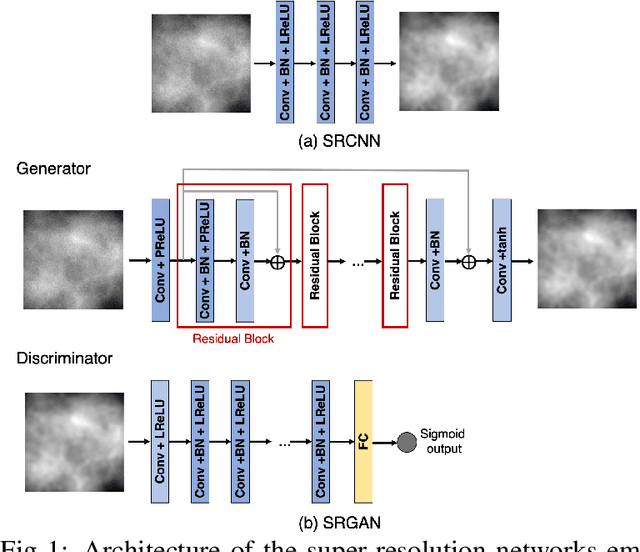


Deep learning-based image super-resolution (DL-SR) has shown great promise in medical imaging applications. To date, most of the proposed methods for DL-SR have only been assessed by use of traditional measures of image quality (IQ) that are commonly employed in the field of computer vision. However, the impact of these methods on objective measures of image quality that are relevant to medical imaging tasks remains largely unexplored. In this study, we investigate the impact of DL-SR methods on binary signal detection performance. Two popular DL-SR methods, the super-resolution convolutional neural network (SRCNN) and the super-resolution generative adversarial network (SRGAN), were trained by use of simulated medical image data. Binary signal-known-exactly with background-known-statistically (SKE/BKS) and signal-known-statistically with background-known-statistically (SKS/BKS) detection tasks were formulated. Numerical observers, which included a neural network-approximated ideal observer and common linear numerical observers, were employed to assess the impact of DL-SR on task performance. The impact of the complexity of the DL-SR network architectures on task-performance was quantified. In addition, the utility of DL-SR for improving the task-performance of sub-optimal observers was investigated. Our numerical experiments confirmed that, as expected, DL-SR could improve traditional measures of IQ. However, for many of the study designs considered, the DL-SR methods provided little or no improvement in task performance and could even degrade it. It was observed that DL-SR could improve the task-performance of sub-optimal observers under certain conditions. The presented study highlights the urgent need for the objective assessment of DL-SR methods and suggests avenues for improving their efficacy in medical imaging applications.
SimCVD: Simple Contrastive Voxel-Wise Representation Distillation for Semi-Supervised Medical Image Segmentation
Aug 16, 2021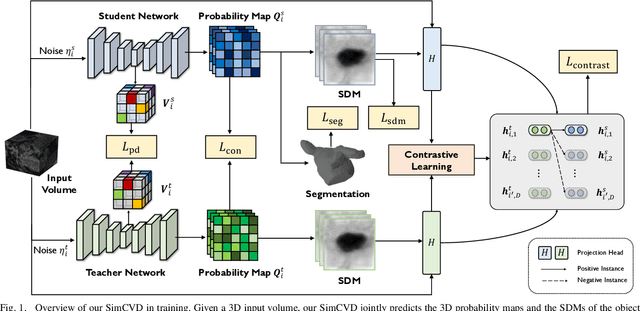
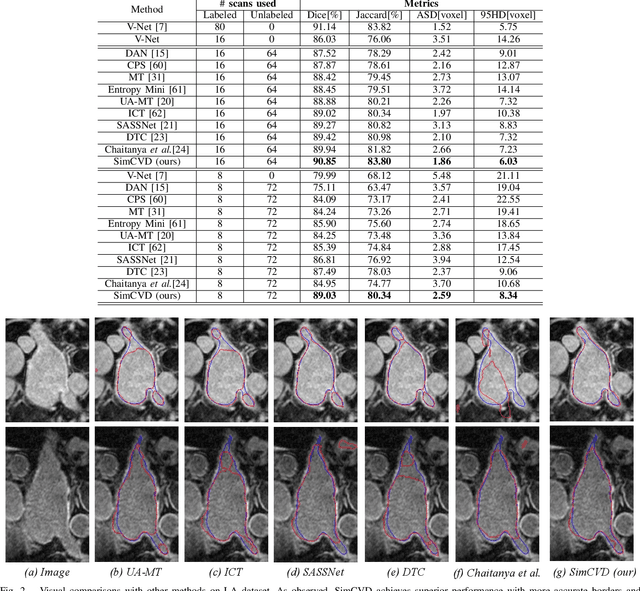
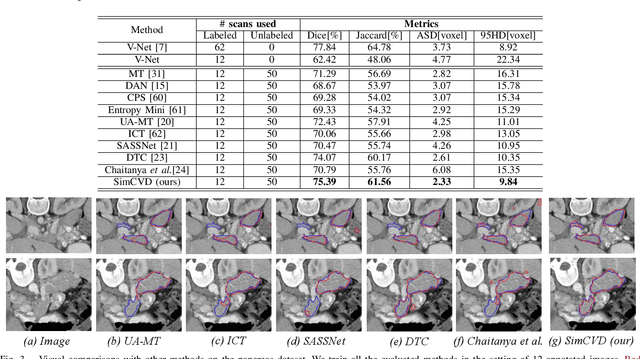
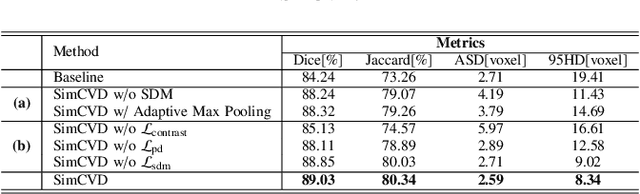
Automated segmentation in medical image analysis is a challenging task that requires a large amount of manually labeled data. However, most existing learning-based approaches usually suffer from limited manually annotated medical data, which poses a major practical problem for accurate and robust medical image segmentation. In addition, most existing semi-supervised approaches are usually not robust compared with the supervised counterparts, and also lack explicit modeling of geometric structure and semantic information, both of which limit the segmentation accuracy. In this work, we present SimCVD, a simple contrastive distillation framework that significantly advances state-of-the-art voxel-wise representation learning. We first describe an unsupervised training strategy, which takes two views of an input volume and predicts their signed distance maps of object boundaries in a contrastive objective, with only two independent dropout as mask. This simple approach works surprisingly well, performing on the same level as previous fully supervised methods with much less labeled data. We hypothesize that dropout can be viewed as a minimal form of data augmentation and makes the network robust to representation collapse. Then, we propose to perform structural distillation by distilling pair-wise similarities. We evaluate SimCVD on two popular datasets: the Left Atrial Segmentation Challenge (LA) and the NIH pancreas CT dataset. The results on the LA dataset demonstrate that, in two types of labeled ratios (i.e., 20% and 10%), SimCVD achieves an average Dice score of 90.85% and 89.03% respectively, a 0.91% and 2.22% improvement compared to previous best results. Our method can be trained in an end-to-end fashion, showing the promise of utilizing SimCVD as a general framework for downstream tasks, such as medical image synthesis and registration.
Condensing Graphs via One-Step Gradient Matching
Jun 15, 2022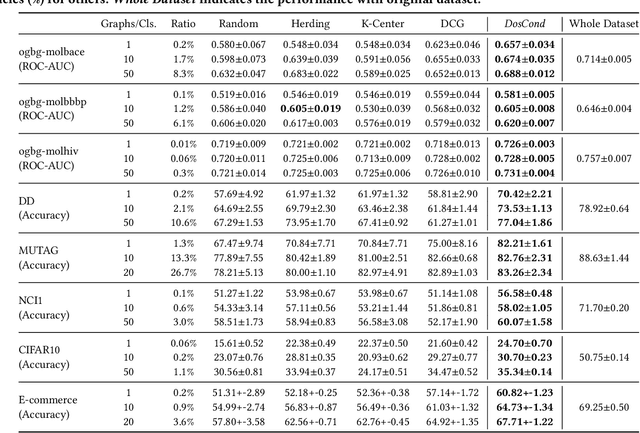
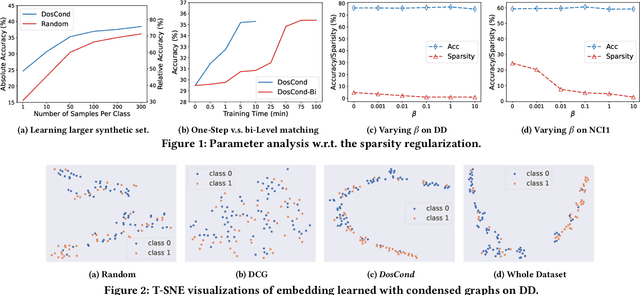
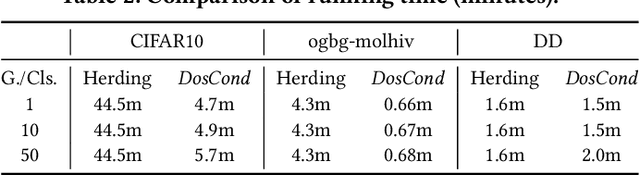
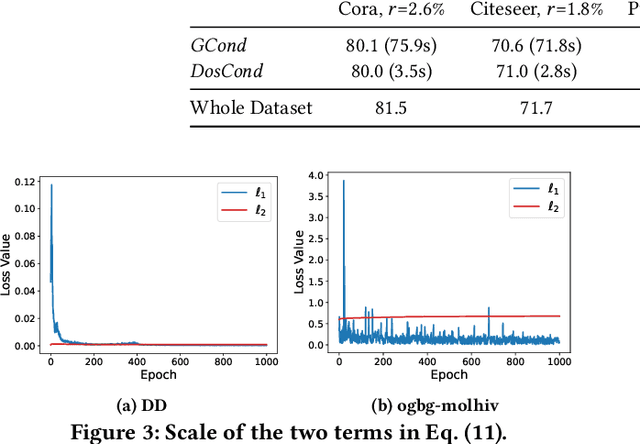
As training deep learning models on large dataset takes a lot of time and resources, it is desired to construct a small synthetic dataset with which we can train deep learning models sufficiently. There are recent works that have explored solutions on condensing image datasets through complex bi-level optimization. For instance, dataset condensation (DC) matches network gradients w.r.t. large-real data and small-synthetic data, where the network weights are optimized for multiple steps at each outer iteration. However, existing approaches have their inherent limitations: (1) they are not directly applicable to graphs where the data is discrete; and (2) the condensation process is computationally expensive due to the involved nested optimization. To bridge the gap, we investigate efficient dataset condensation tailored for graph datasets where we model the discrete graph structure as a probabilistic model. We further propose a one-step gradient matching scheme, which performs gradient matching for only one single step without training the network weights. Our theoretical analysis shows this strategy can generate synthetic graphs that lead to lower classification loss on real graphs. Extensive experiments on various graph datasets demonstrate the effectiveness and efficiency of the proposed method. In particular, we are able to reduce the dataset size by 90% while approximating up to 98% of the original performance and our method is significantly faster than multi-step gradient matching (e.g. 15x in CIFAR10 for synthesizing 500 graphs).
Variational Deep Image Denoising
Apr 02, 2021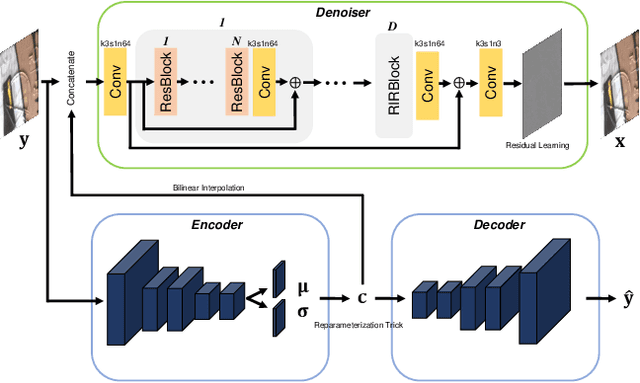
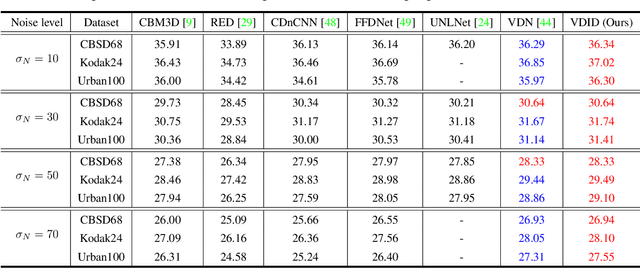
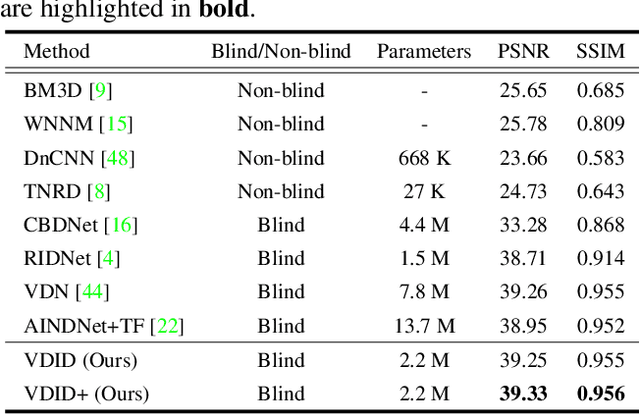

Convolutional neural networks (CNNs) have shown outstanding performance on image denoising with the help of large-scale datasets. Earlier methods naively trained a single CNN with many pairs of clean-noisy images. However, the conditional distribution of the clean image given a noisy one is too complicated and diverse, so that a single CNN cannot well learn such distributions. Therefore, there have also been some methods that exploit additional noise level parameters or train a separate CNN for a specific noise level parameter. These methods separate the original problem into easier sub-problems and thus have shown improved performance than the naively trained CNN. In this step, we raise two questions. The first one is whether it is an optimal approach to relate the conditional distribution only to noise level parameters. The second is what if we do not have noise level information, such as in a real-world scenario. To answer the questions and provide a better solution, we propose a novel Bayesian framework based on the variational approximation of objective functions. This enables us to separate the complicated target distribution into simpler sub-distributions. Eventually, the denoising CNN can conquer noise from each sub-distribution, which is generally an easier problem than the original. Experiments show that the proposed method provides remarkable performance on additive white Gaussian noise (AWGN) and real-noise denoising while requiring fewer parameters than recent state-of-the-art denoisers.
Interactiveness Field in Human-Object Interactions
Apr 16, 2022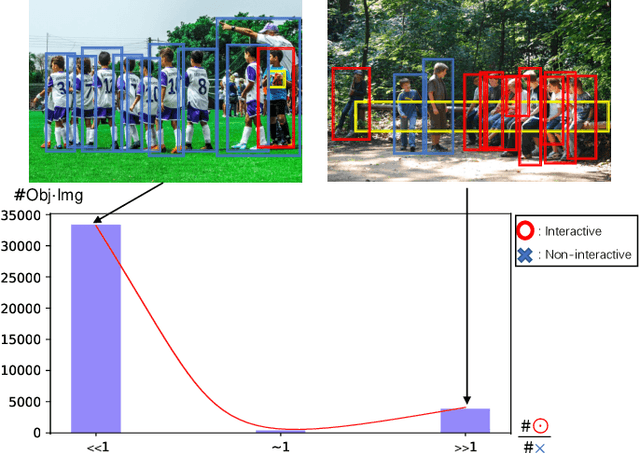
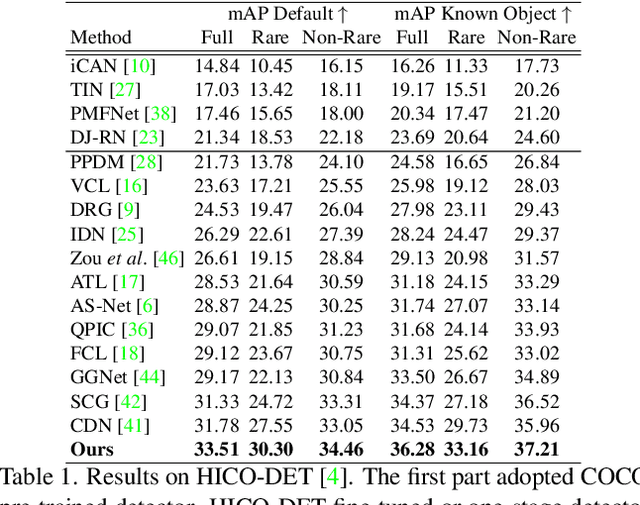
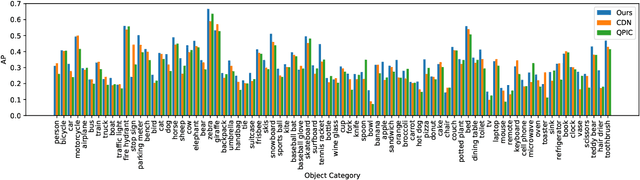
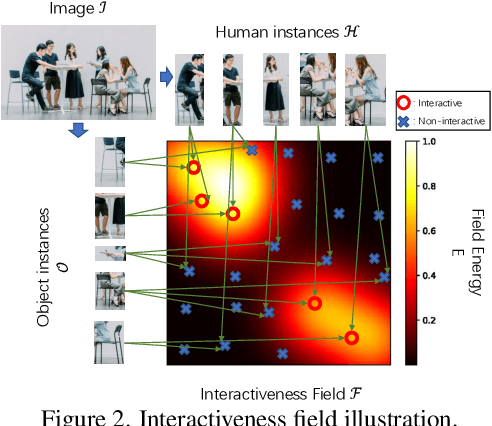
Human-Object Interaction (HOI) detection plays a core role in activity understanding. Though recent two/one-stage methods have achieved impressive results, as an essential step, discovering interactive human-object pairs remains challenging. Both one/two-stage methods fail to effectively extract interactive pairs instead of generating redundant negative pairs. In this work, we introduce a previously overlooked interactiveness bimodal prior: given an object in an image, after pairing it with the humans, the generated pairs are either mostly non-interactive, or mostly interactive, with the former more frequent than the latter. Based on this interactiveness bimodal prior we propose the "interactiveness field". To make the learned field compatible with real HOI image considerations, we propose new energy constraints based on the cardinality and difference in the inherent "interactiveness field" underlying interactive versus non-interactive pairs. Consequently, our method can detect more precise pairs and thus significantly boost HOI detection performance, which is validated on widely-used benchmarks where we achieve decent improvements over state-of-the-arts. Our code is available at https://github.com/Foruck/Interactiveness-Field.
DRaCoN -- Differentiable Rasterization Conditioned Neural Radiance Fields for Articulated Avatars
Mar 29, 2022
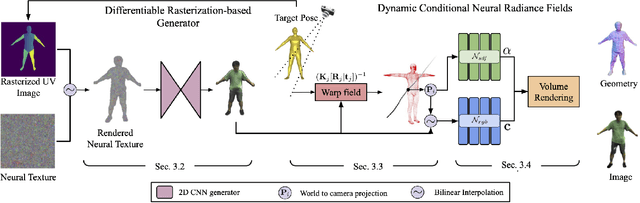
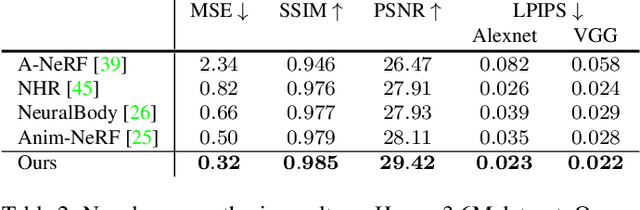
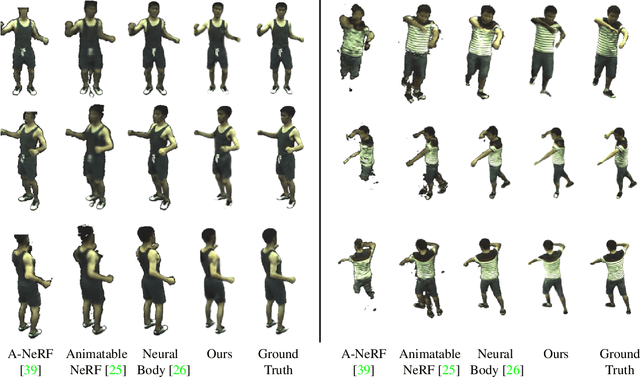
Acquisition and creation of digital human avatars is an important problem with applications to virtual telepresence, gaming, and human modeling. Most contemporary approaches for avatar generation can be viewed either as 3D-based methods, which use multi-view data to learn a 3D representation with appearance (such as a mesh, implicit surface, or volume), or 2D-based methods which learn photo-realistic renderings of avatars but lack accurate 3D representations. In this work, we present, DRaCoN, a framework for learning full-body volumetric avatars which exploits the advantages of both the 2D and 3D neural rendering techniques. It consists of a Differentiable Rasterization module, DiffRas, that synthesizes a low-resolution version of the target image along with additional latent features guided by a parametric body model. The output of DiffRas is then used as conditioning to our conditional neural 3D representation module (c-NeRF) which generates the final high-res image along with body geometry using volumetric rendering. While DiffRas helps in obtaining photo-realistic image quality, c-NeRF, which employs signed distance fields (SDF) for 3D representations, helps to obtain fine 3D geometric details. Experiments on the challenging ZJU-MoCap and Human3.6M datasets indicate that DRaCoN outperforms state-of-the-art methods both in terms of error metrics and visual quality.
Correspondence Learning for Controllable Person Image Generation
Dec 23, 2020
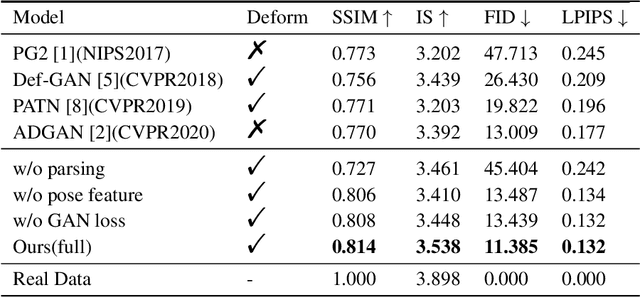
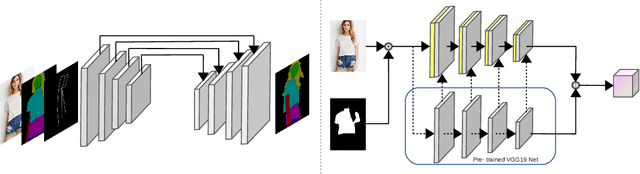
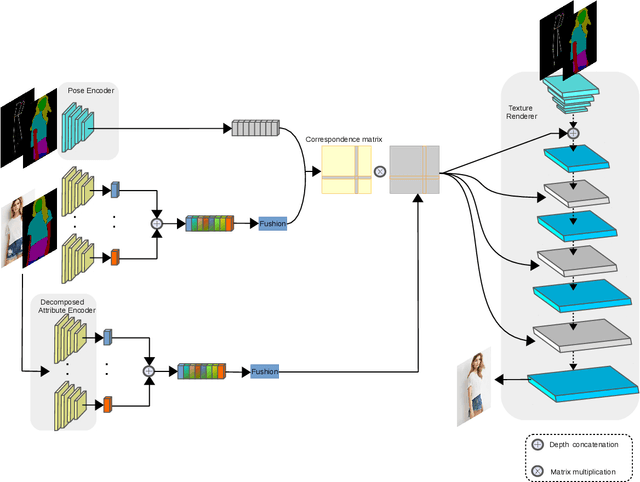
We present a generative model for controllable person image synthesis,as shown in Figure , which can be applied to pose-guided person image synthesis, $i.e.$, converting the pose of a source person image to the target pose while preserving the texture of that source person image, and clothing-guided person image synthesis, $i.e.$, changing the clothing texture of a source person image to the desired clothing texture. By explicitly establishing the dense correspondence between the target pose and the source image, we can effectively address the misalignment introduced by pose tranfer and generate high-quality images. Specifically, we first generate the target semantic map under the guidence of the target pose, which can provide more accurate pose representation and structural constraints during the generation process. Then, decomposed attribute encoder is used to extract the component features, which not only helps to establish a more accurate dense correspondence, but also realizes the clothing-guided person generation. After that, we will establish a dense correspondence between the target pose and the source image within the sharded domain. The source image feature is warped according to the dense correspondence to flexibly account for deformations. Finally, the network renders image based on the warped source image feature and the target pose. Experimental results show that our method is superior to state-of-the-art methods in pose-guided person generation and its effectiveness in clothing-guided person generation.
ViT-BEVSeg: A Hierarchical Transformer Network for Monocular Birds-Eye-View Segmentation
May 31, 2022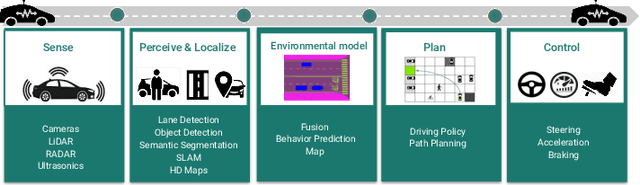
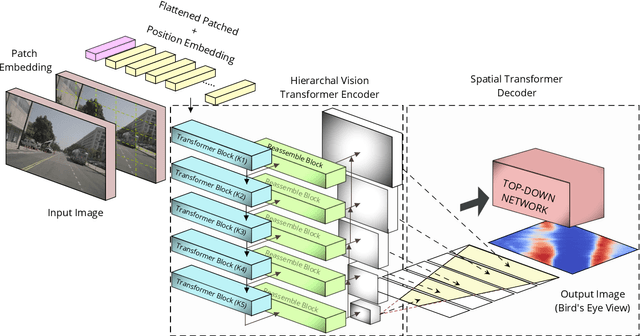

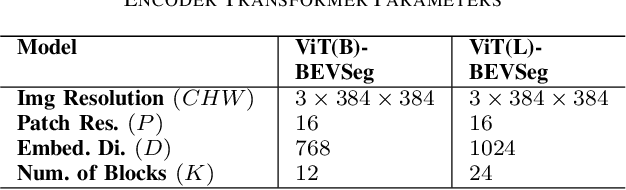
Generating a detailed near-field perceptual model of the environment is an important and challenging problem in both self-driving vehicles and autonomous mobile robotics. A Bird Eye View (BEV) map, providing a panoptic representation, is a commonly used approach that provides a simplified 2D representation of the vehicle surroundings with accurate semantic level segmentation for many downstream tasks. Current state-of-the art approaches to generate BEV-maps employ a Convolutional Neural Network (CNN) backbone to create feature-maps which are passed through a spatial transformer to project the derived features onto the BEV coordinate frame. In this paper, we evaluate the use of vision transformers (ViT) as a backbone architecture to generate BEV maps. Our network architecture, ViT-BEVSeg, employs standard vision transformers to generate a multi-scale representation of the input image. The resulting representation is then provided as an input to a spatial transformer decoder module which outputs segmentation maps in the BEV grid. We evaluate our approach on the nuScenes dataset demonstrating a considerable improvement in the performance relative to state-of-the-art approaches.
Cervical Optical Coherence Tomography Image Classification Based on Contrastive Self-Supervised Texture Learning
Aug 11, 2021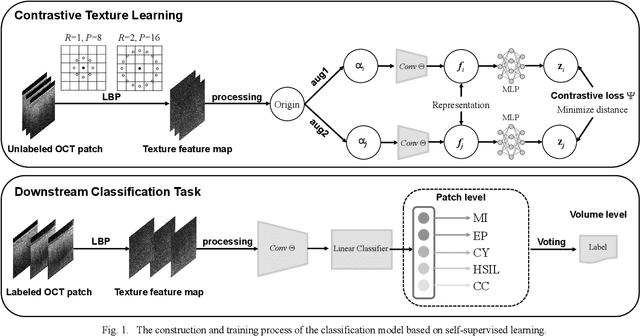
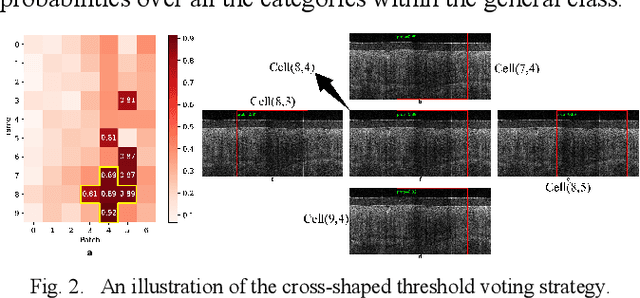
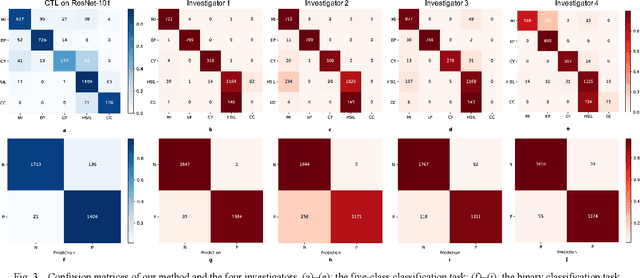
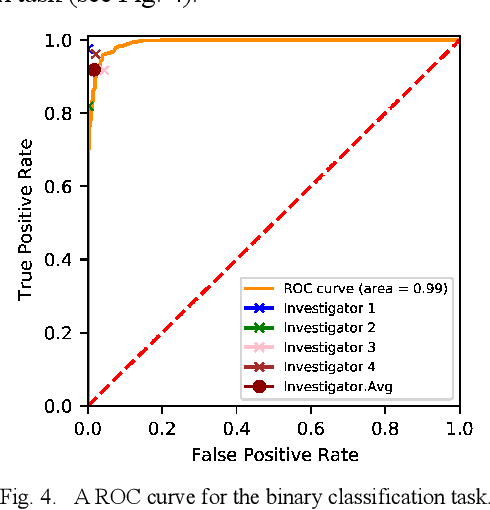
Background: Cervical cancer seriously affects the health of the female reproductive system. Optical coherence tomography (OCT) emerges as a non-invasive, high-resolution imaging technology for cervical disease detection. However, OCT image annotation is knowledge-intensive and time-consuming, which impedes the training process of deep-learning-based classification models. Objective: This study aims to develop a computer-aided diagnosis (CADx) approach to classifying in-vivo cervical OCT images based on self-supervised learning. Methods: Besides high-level semantic features extracted by a convolutional neural network (CNN), the proposed CADx approach leverages unlabeled cervical OCT images' texture features learned by contrastive texture learning. We conducted ten-fold cross-validation on the OCT image dataset from a multi-center clinical study on 733 patients from China. Results: In a binary classification task for detecting high-risk diseases, including high-grade squamous intraepithelial lesion (HSIL) and cervical cancer, our method achieved an area-under-the-curve (AUC) value of 0.9798 Plus or Minus 0.0157 with a sensitivity of 91.17 Plus or Minus 4.99% and a specificity of 93.96 Plus or Minus 4.72% for OCT image patches; also, it outperformed two out of four medical experts on the test set. Furthermore, our method achieved a 91.53% sensitivity and 97.37% specificity on an external validation dataset containing 287 3D OCT volumes from 118 Chinese patients in a new hospital using a cross-shaped threshold voting strategy. Conclusion: The proposed contrastive-learning-based CADx method outperformed the end-to-end CNN models and provided better interpretability based on texture features, which holds great potential to be used in the clinical protocol of "see-and-treat."