 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Empirical Analysis of Image Caption Generation using Deep Learning
May 22, 2021
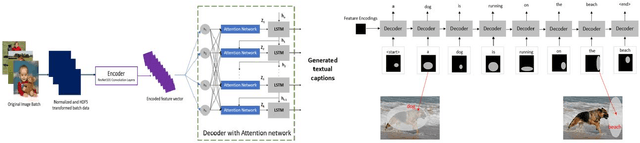
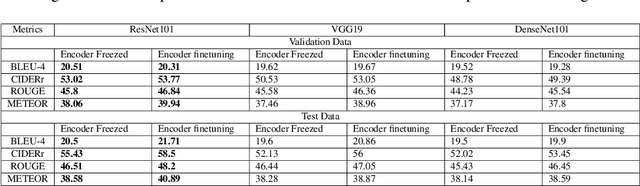

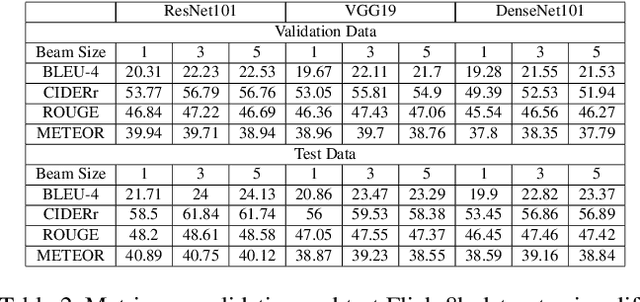
Automated image captioning is one of the applications of Deep Learning which involves fusion of work done in computer vision and natural language processing, and it is typically performed using Encoder-Decoder architectures. In this project, we have implemented and experimented with various flavors of multi-modal image captioning networks where ResNet101, DenseNet121 and VGG19 based CNN Encoders and Attention based LSTM Decoders were explored. We have studied the effect of beam size and the use of pretrained word embeddings and compared them to baseline CNN encoder and RNN decoder architecture. The goal is to analyze the performance of each approach using various evaluation metrics including BLEU, CIDEr, ROUGE and METEOR. We have also explored model explainability using Visual Attention Maps (VAM) to highlight parts of the images which has maximum contribution for predicting each word of the generated caption.
An End-to-End Food Image Analysis System
Feb 01, 2021
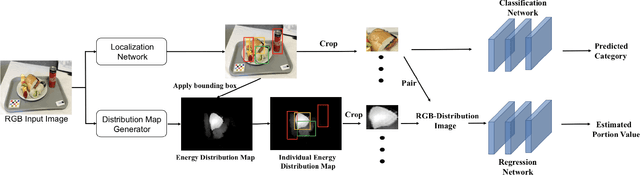
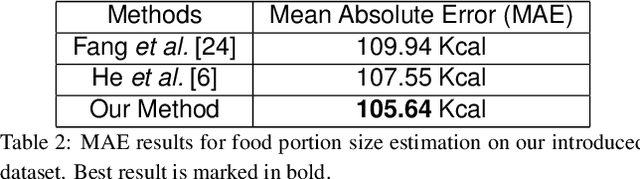

Modern deep learning techniques have enabled advances in image-based dietary assessment such as food recognition and food portion size estimation. Valuable information on the types of foods and the amount consumed are crucial for prevention of many chronic diseases. However, existing methods for automated image-based food analysis are neither end-to-end nor are capable of processing multiple tasks (e.g., recognition and portion estimation) together, making it difficult to apply to real life applications. In this paper, we propose an image-based food analysis framework that integrates food localization, classification and portion size estimation. Our proposed framework is end-to-end, i.e., the input can be an arbitrary food image containing multiple food items and our system can localize each single food item with its corresponding predicted food type and portion size. We also improve the single food portion estimation by consolidating localization results with a food energy distribution map obtained by conditional GAN to generate a four-channel RGB-Distribution image. Our end-to-end framework is evaluated on a real life food image dataset collected from a nutrition feeding study.
Semi-supervised Semantics-guided Adversarial Training for Trajectory Prediction
May 27, 2022

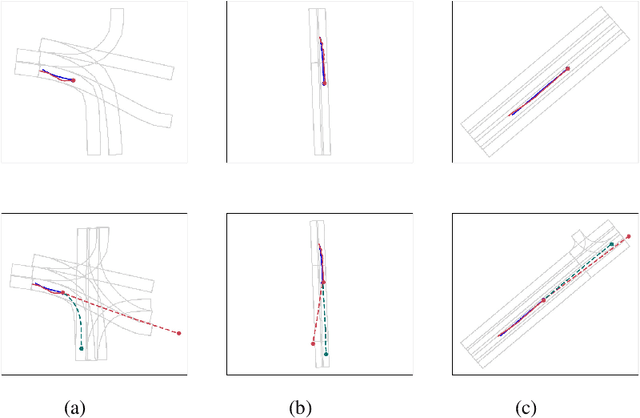
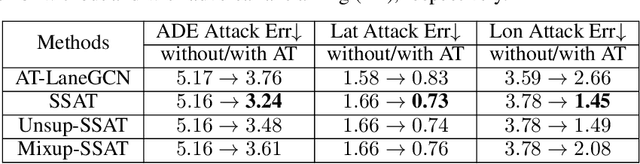
Predicting the trajectories of surrounding objects is a critical task in self-driving and many other autonomous systems. Recent works demonstrate that adversarial attacks on trajectory prediction, where small crafted perturbations are introduced to history trajectories, may significantly mislead the prediction of future trajectories and ultimately induce unsafe planning. However, few works have addressed enhancing the robustness of this important safety-critical task. In this paper, we present the first adversarial training method for trajectory prediction. Compared with typical adversarial training on image tasks, our work is challenged by more random inputs with rich context, and a lack of class labels. To address these challenges, we propose a method based on a semi-supervised adversarial autoencoder that models disentangled semantic features with domain knowledge and provides additional latent labels for the adversarial training. Extensive experiments with different types of attacks demonstrate that our semi-supervised semantics-guided adversarial training method can effectively mitigate the impact of adversarial attacks and generally improve the system's adversarial robustness to a variety of attacks, including unseen ones. We believe that such semantics-guided architecture and advancement in robust generalization is an important step for developing robust prediction models and enabling safe decision making.
MonoDETR: Depth-aware Transformer for Monocular 3D Object Detection
Mar 28, 2022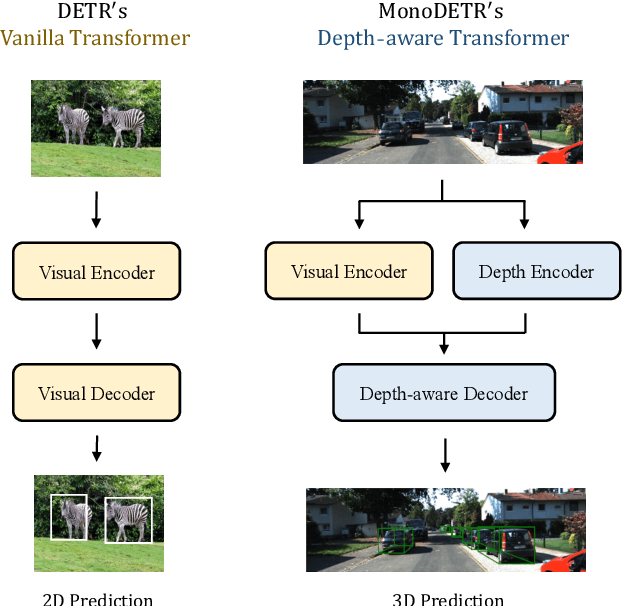
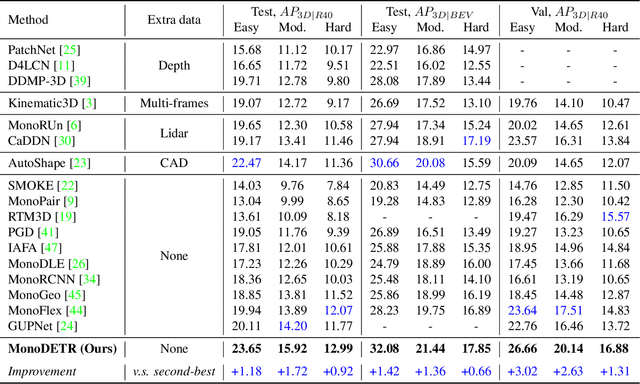

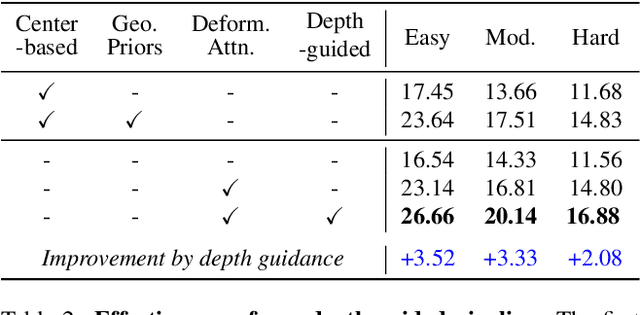
Monocular 3D object detection has long been a challenging task in autonomous driving, which requires to decode 3D predictions solely from a single 2D image. Most existing methods follow conventional 2D object detectors to first localize objects by their centers, and then predict 3D attributes using center-neighboring local features. However, such center-based pipeline views 3D prediction as a subordinate task and lacks inter-object depth interactions with global spatial clues. In this paper, we introduce a simple framework for Monocular DEtection with depth-aware TRansformer, named MonoDETR. We enable the vanilla transformer to be depth-aware and enforce the whole detection process guided by depth. Specifically, we represent 3D object candidates as a set of queries and produce non-local depth embeddings of the input image by a lightweight depth predictor and an attention-based depth encoder. Then, we propose a depth-aware decoder to conduct both inter-query and query-scene depth feature communication. In this way, each object estimates its 3D attributes adaptively from the depth-informative regions on the image, not limited by center-around features. With minimal handcrafted designs, MonoDETR is an end-to-end framework without additional data, anchors or NMS and achieves competitive performance on KITTI benchmark among state-of-the-art center-based networks. Extensive ablation studies demonstrate the effectiveness of our approach and its potential to serve as a transformer baseline for future monocular research. Code is available at https://github.com/ZrrSkywalker/MonoDETR.git.
Instance-aware Remote Sensing Image Captioning with Cross-hierarchy Attention
May 11, 2021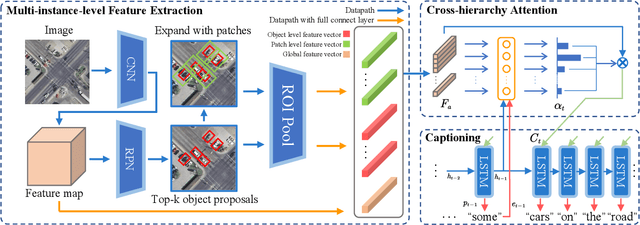


The spatial attention is a straightforward approach to enhance the performance for remote sensing image captioning. However, conventional spatial attention approaches consider only the attention distribution on one fixed coarse grid, resulting in the semantics of tiny objects can be easily ignored or disturbed during the visual feature extraction. Worse still, the fixed semantic level of conventional spatial attention limits the image understanding in different levels and perspectives, which is critical for tackling the huge diversity in remote sensing images. To address these issues, we propose a remote sensing image caption generator with instance-awareness and cross-hierarchy attention. 1) The instances awareness is achieved by introducing a multi-level feature architecture that contains the visual information of multi-level instance-possible regions and their surroundings. 2) Moreover, based on this multi-level feature extraction, a cross-hierarchy attention mechanism is proposed to prompt the decoder to dynamically focus on different semantic hierarchies and instances at each time step. The experimental results on public datasets demonstrate the superiority of proposed approach over existing methods.
A Comparative Study of Meter Detection Methods for Automated Infrastructure Inspection
Apr 24, 2022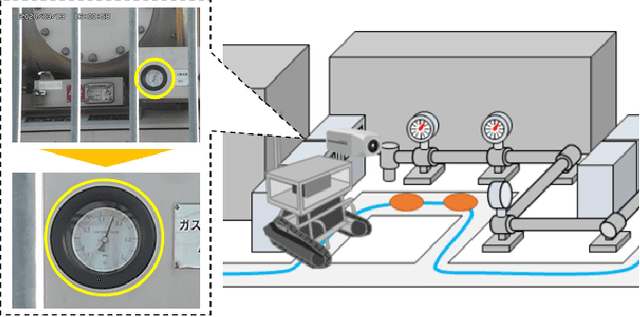

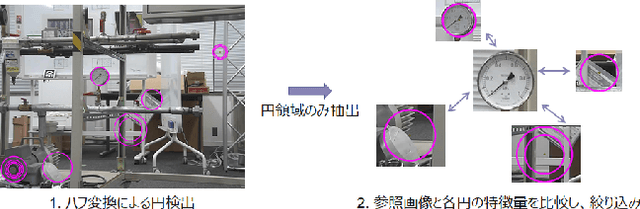
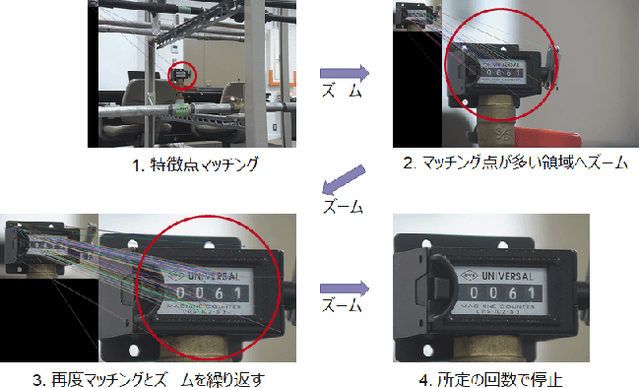
In order to read meter values from a camera on an autonomous inspection robot with positional errors, it is necessary to detect meter regions from the image. In this study, we developed shape-based, texture-based, and background information-based methods as meter area detection techniques and compared their effectiveness for meters of different shapes and sizes. As a result, we confirmed that the background information-based method can detect the farthest meters regardless of the shape and number of meters, and can stably detect meters with a diameter of 40px.
A Benchmark for Compositional Visual Reasoning
Jun 11, 2022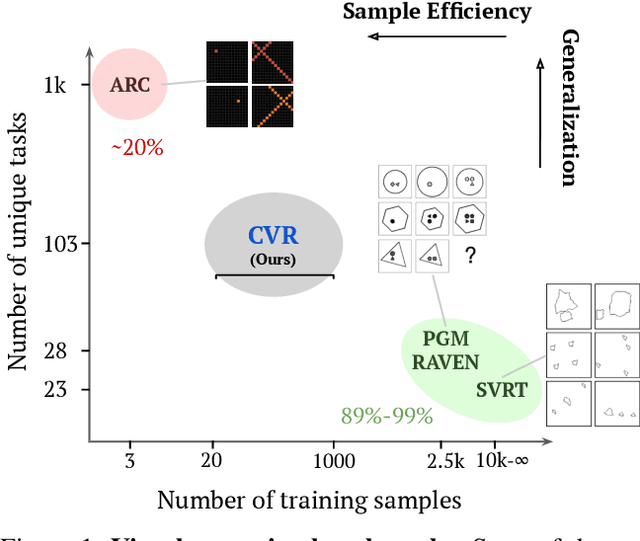
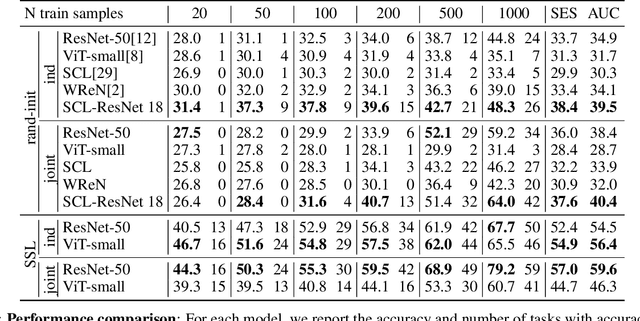
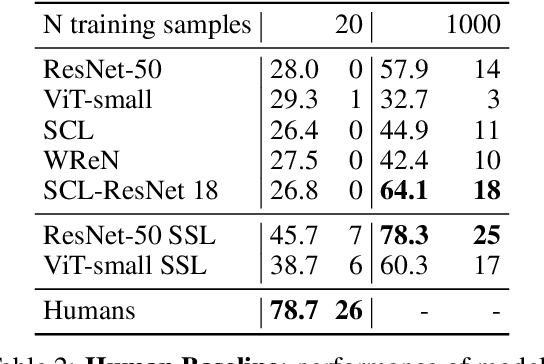
A fundamental component of human vision is our ability to parse complex visual scenes and judge the relations between their constituent objects. AI benchmarks for visual reasoning have driven rapid progress in recent years with state-of-the-art systems now reaching human accuracy on some of these benchmarks. Yet, a major gap remains in terms of the sample efficiency with which humans and AI systems learn new visual reasoning tasks. Humans' remarkable efficiency at learning has been at least partially attributed to their ability to harness compositionality -- such that they can efficiently take advantage of previously gained knowledge when learning new tasks. Here, we introduce a novel visual reasoning benchmark, Compositional Visual Relations (CVR), to drive progress towards the development of more data-efficient learning algorithms. We take inspiration from fluidic intelligence and non-verbal reasoning tests and describe a novel method for creating compositions of abstract rules and associated image datasets at scale. Our proposed benchmark includes measures of sample efficiency, generalization and transfer across task rules, as well as the ability to leverage compositionality. We systematically evaluate modern neural architectures and find that, surprisingly, convolutional architectures surpass transformer-based architectures across all performance measures in most data regimes. However, all computational models are a lot less data efficient compared to humans even after learning informative visual representations using self-supervision. Overall, we hope that our challenge will spur interest in the development of neural architectures that can learn to harness compositionality toward more efficient learning.
Contrastive Identification of Covariate Shift in Image Data
Aug 19, 2021



Identifying covariate shift is crucial for making machine learning systems robust in the real world and for detecting training data biases that are not reflected in test data. However, detecting covariate shift is challenging, especially when the data consists of high-dimensional images, and when multiple types of localized covariate shift affect different subspaces of the data. Although automated techniques can be used to detect the existence of covariate shift, our goal is to help human users characterize the extent of covariate shift in large image datasets with interfaces that seamlessly integrate information obtained from the detection algorithms. In this paper, we design and evaluate a new visual interface that facilitates the comparison of the local distributions of training and test data. We conduct a quantitative user study on multi-attribute facial data to compare two different learned low-dimensional latent representations (pretrained ImageNet CNN vs. density ratio) and two user analytic workflows (nearest-neighbor vs. cluster-to-cluster). Our results indicate that the latent representation of our density ratio model, combined with a nearest-neighbor comparison, is the most effective at helping humans identify covariate shift.
Simple Unsupervised Object-Centric Learning for Complex and Naturalistic Videos
May 27, 2022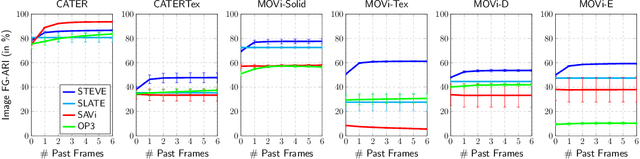
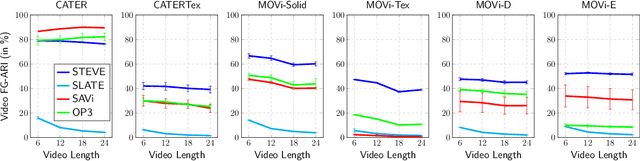
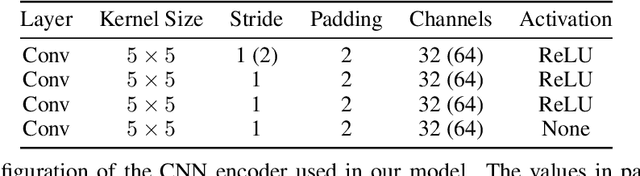
Unsupervised object-centric learning aims to represent the modular, compositional, and causal structure of a scene as a set of object representations and thereby promises to resolve many critical limitations of traditional single-vector representations such as poor systematic generalization. Although there have been many remarkable advances in recent years, one of the most critical problems in this direction has been that previous methods work only with simple and synthetic scenes but not with complex and naturalistic images or videos. In this paper, we propose STEVE, an unsupervised model for object-centric learning in videos. Our proposed model makes a significant advancement by demonstrating its effectiveness on various complex and naturalistic videos unprecedented in this line of research. Interestingly, this is achieved by neither adding complexity to the model architecture nor introducing a new objective or weak supervision. Rather, it is achieved by a surprisingly simple architecture that uses a transformer-based image decoder conditioned on slots and the learning objective is simply to reconstruct the observation. Our experiment results on various complex and naturalistic videos show significant improvements compared to the previous state-of-the-art.
Image Composition Assessment with Saliency-augmented Multi-pattern Pooling
Apr 07, 2021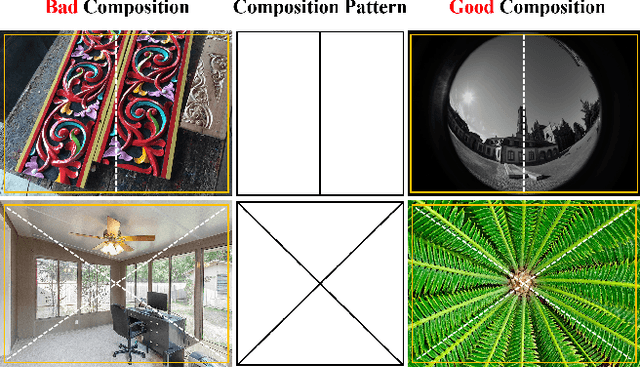
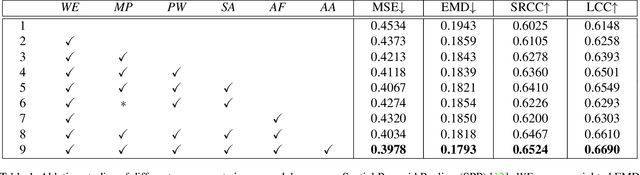
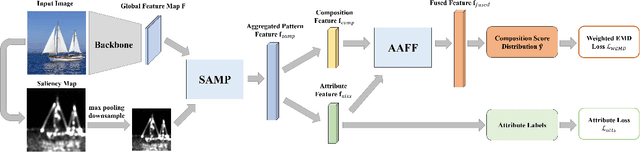
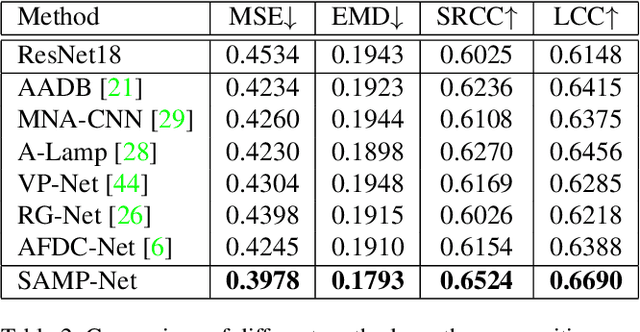
Image composition assessment is crucial in aesthetic assessment, which aims to assess the overall composition quality of a given image. However, to the best of our knowledge, there is neither dataset nor method specifically proposed for this task. In this paper, we contribute the first composition assessment dataset CADB with composition scores for each image provided by multiple professional raters. Besides, we propose a composition assessment network SAMP-Net with a novel Saliency-Augmented Multi-pattern Pooling (SAMP) module, which analyses visual layout from the perspectives of multiple composition patterns. We also leverage composition-relevant attributes to further boost the performance, and extend Earth Mover's Distance (EMD) loss to weighted EMD loss to eliminate the content bias. The experimental results show that our SAMP-Net can perform more favorably than previous aesthetic assessment approaches and offer constructive composition suggestions.