 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PCNet: A Structure Similarity Enhancement Method for Multispectral and Multimodal Image Registration
Jun 09, 2021
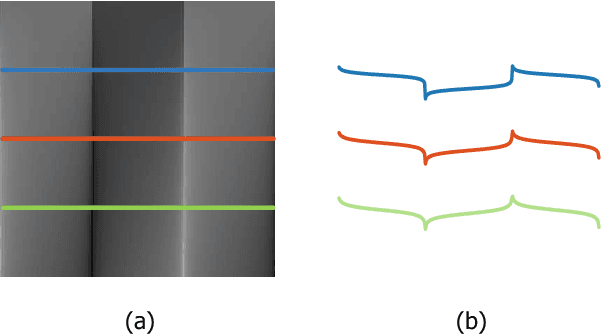
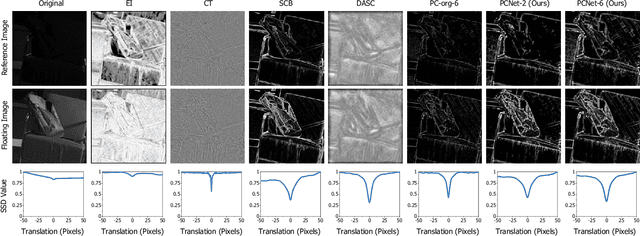


Multispectral and multimodal image processing is important in the community of computer vision and computational photography. As the acquired multispectral and multimodal data are generally misaligned due to the alternation or movement of the image device, the image registration procedure is necessary. The registration of multispectral or multimodal image is challenging due to the non-linear intensity and gradient variation. To cope with this challenge, we propose the phase congruency network (PCNet), which is able to enhance the structure similarity and alleviate the non-linear intensity and gradient variation. The images can then be aligned using the similarity enhanced features produced by the network. PCNet is constructed under the guidance of the phase congruency prior. The network contains three trainable layers accompany with the modified learnable Gabor kernels according to the phase congruency theory. Thanks to the prior knowledge, PCNet is extremely light-weight and can be trained on quite a small amount of multispectral data. PCNet can be viewed to be fully convolutional and hence can take input of arbitrary sizes. Once trained, PCNet is applicable on a variety of multispectral and multimodal data such as RGB/NIR and flash/no-flash images without additional further tuning. Experimental results validate that PCNet outperforms current state-of-the-art registration algorithms, including the deep-learning based ones that have the number of parameters hundreds times compared to PCNet. Thanks to the similarity enhancement training, PCNet outperforms the original phase congruency algorithm with two-thirds less feature channels.
A Mixed Quantization Network for Computationally Efficient Mobile Inverse Tone Mapping
Mar 12, 2022
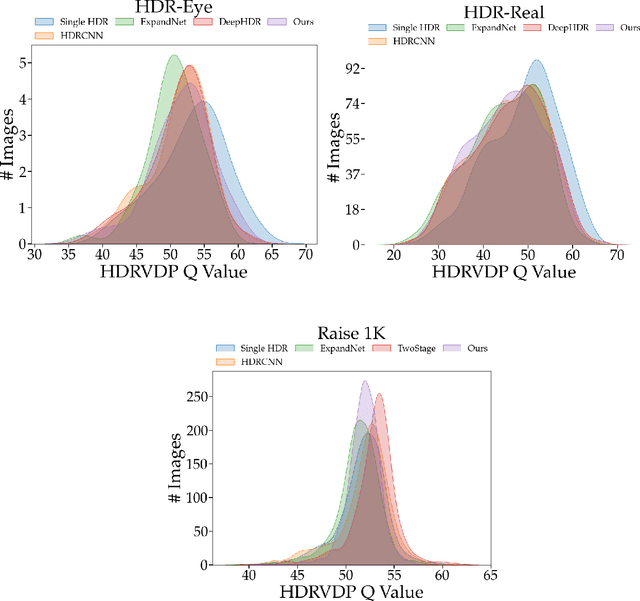
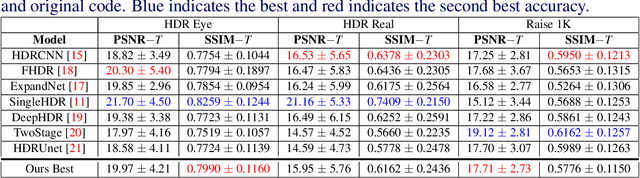
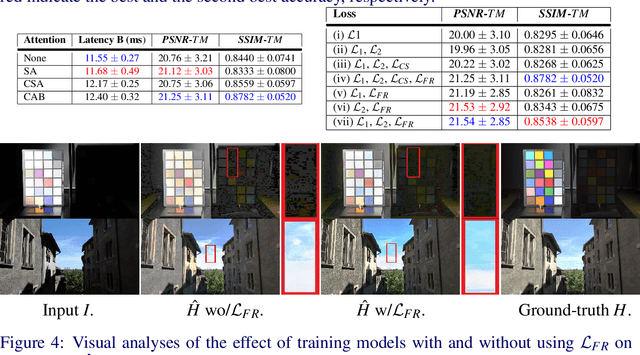
Recovering a high dynamic range (HDR) image from a single low dynamic range (LDR) image, namely inverse tone mapping (ITM), is challenging due to the lack of information in over- and under-exposed regions. Current methods focus exclusively on training high-performing but computationally inefficient ITM models, which in turn hinder deployment of the ITM models in resource-constrained environments with limited computing power such as edge and mobile device applications. To this end, we propose combining efficient operations of deep neural networks with a novel mixed quantization scheme to construct a well-performing but computationally efficient mixed quantization network (MQN) which can perform single image ITM on mobile platforms. In the ablation studies, we explore the effect of using different attention mechanisms, quantization schemes, and loss functions on the performance of MQN in ITM tasks. In the comparative analyses, ITM models trained using MQN perform on par with the state-of-the-art methods on benchmark datasets. MQN models provide up to 10 times improvement on latency and 25 times improvement on memory consumption.
All You Need is Color: Image based Spatial Gene Expression Prediction using Neural Stain Learning
Aug 26, 2021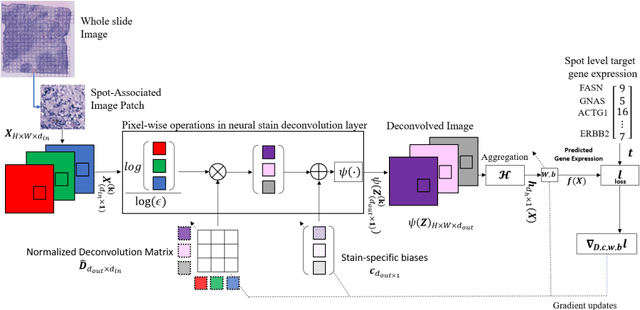
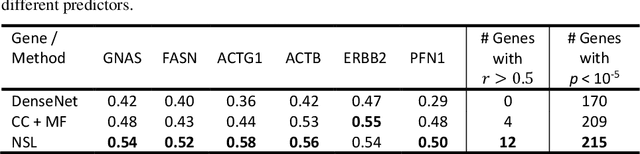
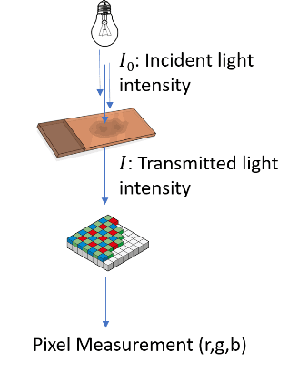
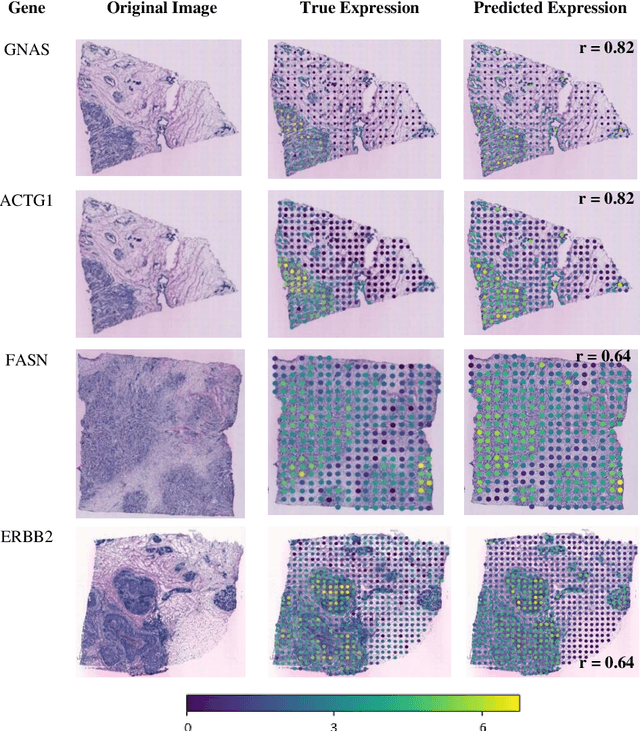
"Is it possible to predict expression levels of different genes at a given spatial location in the routine histology image of a tumor section by modeling its stain absorption characteristics?" In this work, we propose a "stain-aware" machine learning approach for prediction of spatial transcriptomic gene expression profiles using digital pathology image of a routine Hematoxylin & Eosin (H&E) histology section. Unlike recent deep learning methods which are used for gene expression prediction, our proposed approach termed Neural Stain Learning (NSL) explicitly models the association of stain absorption characteristics of the tissue with gene expression patterns in spatial transcriptomics by learning a problem-specific stain deconvolution matrix in an end-to-end manner. The proposed method with only 11 trainable weight parameters outperforms both classical regression models with cellular composition and morphological features as well as deep learning methods. We have found that the gene expression predictions from the proposed approach show higher correlations with true expression values obtained through sequencing for a larger set of genes in comparison to other approaches.
Region-Adaptive Deformable Network for Image Quality Assessment
Apr 23, 2021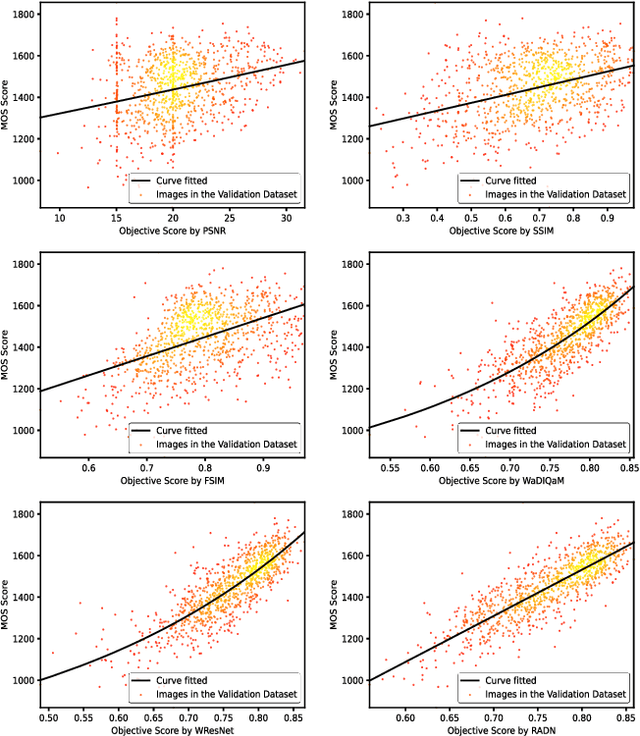
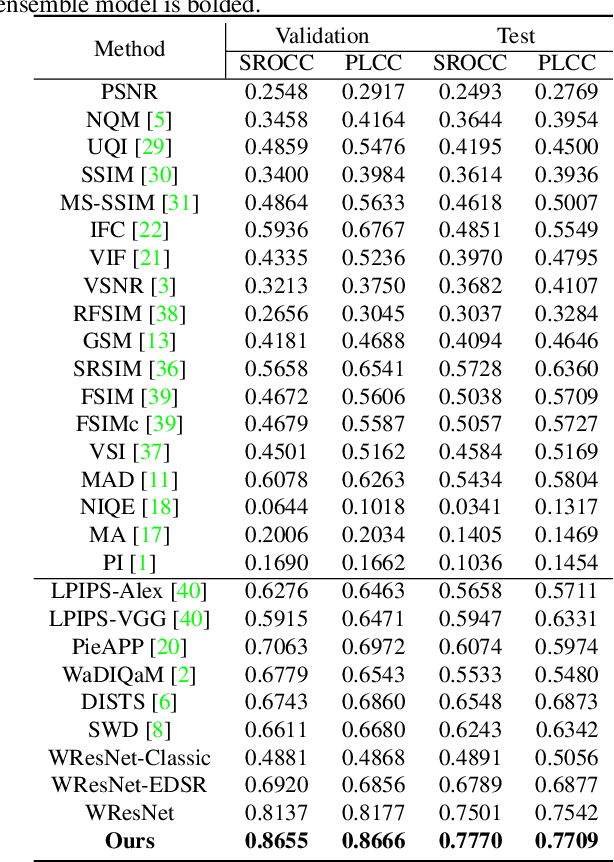
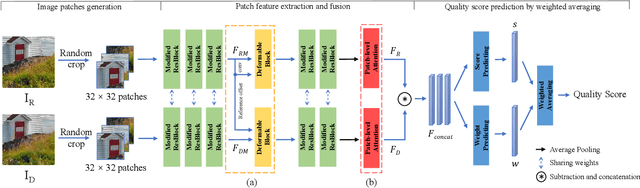
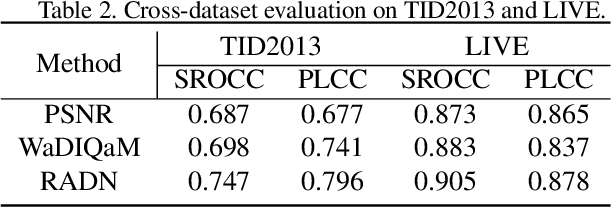
Image quality assessment (IQA) aims to assess the perceptual quality of images. The outputs of the IQA algorithms are expected to be consistent with human subjective perception. In image restoration and enhancement tasks, images generated by generative adversarial networks (GAN) can achieve better visual performance than traditional CNN-generated images, although they have spatial shift and texture noise. Unfortunately, the existing IQA methods have unsatisfactory performance on the GAN-based distortion partially because of their low tolerance to spatial misalignment. To this end, we propose the reference-oriented deformable convolution, which can improve the performance of an IQA network on GAN-based distortion by adaptively considering this misalignment. We further propose a patch-level attention module to enhance the interaction among different patch regions, which are processed independently in previous patch-based methods. The modified residual block is also proposed by applying modifications to the classic residual block to construct a patch-region-based baseline called WResNet. Equipping this baseline with the two proposed modules, we further propose Region-Adaptive Deformable Network (RADN). The experiment results on the NTIRE 2021 Perceptual Image Quality Assessment Challenge dataset show the superior performance of RADN, and the ensemble approach won fourth place in the final testing phase of the challenge. Code is available at https://github.com/IIGROUP/RADN.
Grasping the Arrow of Time from the Singularity: Decoding Micromotion in Low-dimensional Latent Spaces from StyleGAN
Apr 27, 2022
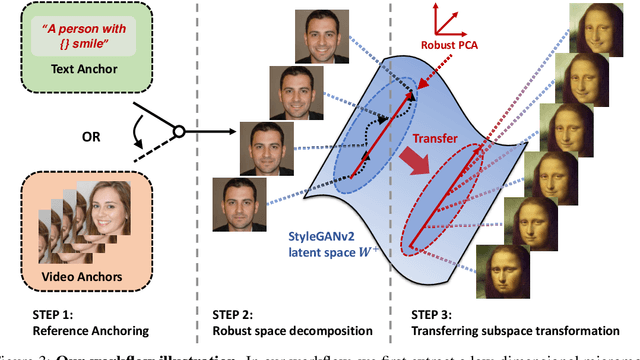


The disentanglement of StyleGAN latent space has paved the way for realistic and controllable image editing, but does StyleGAN know anything about temporal motion, as it was only trained on static images? To study the motion features in the latent space of StyleGAN, in this paper, we hypothesize and demonstrate that a series of meaningful, natural, and versatile small, local movements (referred to as "micromotion", such as expression, head movement, and aging effect) can be represented in low-rank spaces extracted from the latent space of a conventionally pre-trained StyleGAN-v2 model for face generation, with the guidance of proper "anchors" in the form of either short text or video clips. Starting from one target face image, with the editing direction decoded from the low-rank space, its micromotion features can be represented as simple as an affine transformation over its latent feature. Perhaps more surprisingly, such micromotion subspace, even learned from just single target face, can be painlessly transferred to other unseen face images, even those from vastly different domains (such as oil painting, cartoon, and sculpture faces). It demonstrates that the local feature geometry corresponding to one type of micromotion is aligned across different face subjects, and hence that StyleGAN-v2 is indeed "secretly" aware of the subject-disentangled feature variations caused by that micromotion. We present various successful examples of applying our low-dimensional micromotion subspace technique to directly and effortlessly manipulate faces, showing high robustness, low computational overhead, and impressive domain transferability. Our codes are available at https://github.com/wuqiuche/micromotion-StyleGAN.
L2G: A Simple Local-to-Global Knowledge Transfer Framework for Weakly Supervised Semantic Segmentation
Apr 07, 2022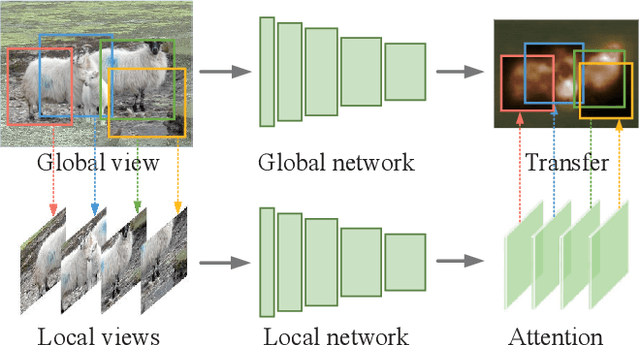


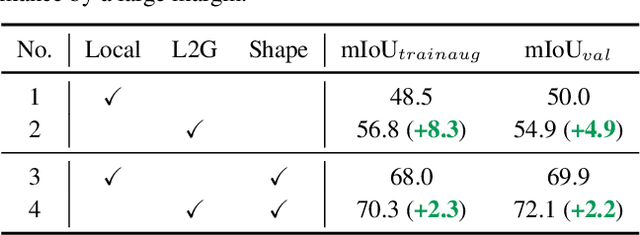
Mining precise class-aware attention maps, a.k.a, class activation maps, is essential for weakly supervised semantic segmentation. In this paper, we present L2G, a simple online local-to-global knowledge transfer framework for high-quality object attention mining. We observe that classification models can discover object regions with more details when replacing the input image with its local patches. Taking this into account, we first leverage a local classification network to extract attentions from multiple local patches randomly cropped from the input image. Then, we utilize a global network to learn complementary attention knowledge across multiple local attention maps online. Our framework conducts the global network to learn the captured rich object detail knowledge from a global view and thereby produces high-quality attention maps that can be directly used as pseudo annotations for semantic segmentation networks. Experiments show that our method attains 72.1% and 44.2% mIoU scores on the validation set of PASCAL VOC 2012 and MS COCO 2014, respectively, setting new state-of-the-art records. Code is available at https://github.com/PengtaoJiang/L2G.
A Lightweight Dual-Domain Attention Framework for Sparse-View CT Reconstruction
Feb 19, 2022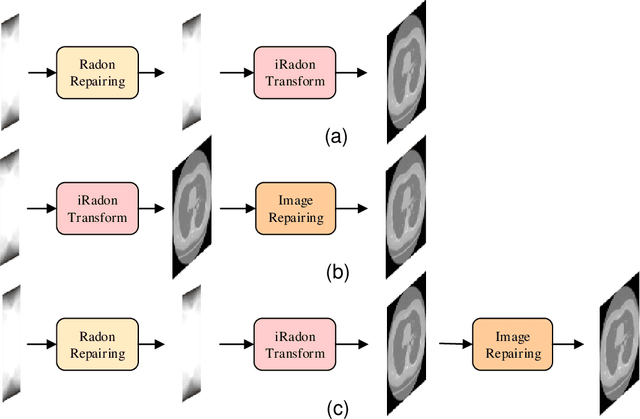

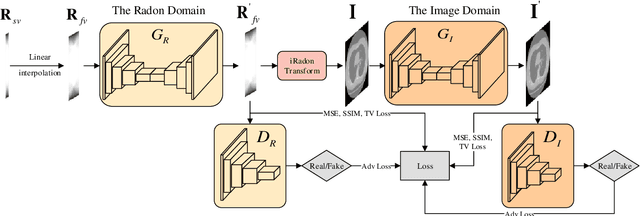

Computed Tomography (CT) plays an essential role in clinical diagnosis. Due to the adverse effects of radiation on patients, the radiation dose is expected to be reduced as low as possible. Sparse sampling is an effective way, but it will lead to severe artifacts on the reconstructed CT image, thus sparse-view CT image reconstruction has been a prevailing and challenging research area. With the popularity of mobile devices, the requirements for lightweight and real-time networks are increasing rapidly. In this paper, we design a novel lightweight network called CAGAN, and propose a dual-domain reconstruction pipeline for parallel beam sparse-view CT. CAGAN is an adversarial auto-encoder, combining the Coordinate Attention unit, which preserves the spatial information of features. Also, the application of Shuffle Blocks reduces the parameters by a quarter without sacrificing its performance. In the Radon domain, the CAGAN learns the mapping between the interpolated data and fringe-free projection data. After the restored Radon data is reconstructed to an image, the image is sent into the second CAGAN trained for recovering the details, so that a high-quality image is obtained. Experiments indicate that the CAGAN strikes an excellent balance between model complexity and performance, and our pipeline outperforms the DD-Net and the DuDoNet.
TarGAN: Target-Aware Generative Adversarial Networks for Multi-modality Medical Image Translation
May 19, 2021
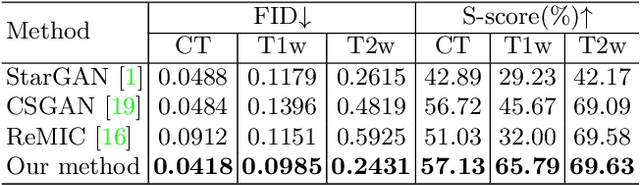
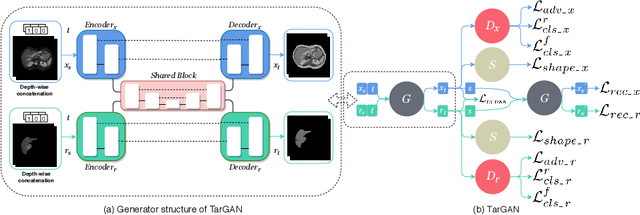
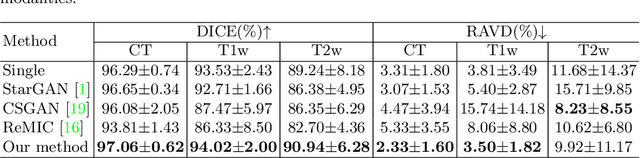
Paired multi-modality medical images, can provide complementary information to help physicians make more reasonable decisions than single modality medical images. But they are difficult to generate due to multiple factors in practice (e.g., time, cost, radiation dose). To address these problems, multi-modality medical image translation has aroused increasing research interest recently. However, the existing works mainly focus on translation effect of a whole image instead of a critical target area or Region of Interest (ROI), e.g., organ and so on. This leads to poor-quality translation of the localized target area which becomes blurry, deformed or even with extra unreasonable textures. In this paper, we propose a novel target-aware generative adversarial network called TarGAN, which is a generic multi-modality medical image translation model capable of (1) learning multi-modality medical image translation without relying on paired data, (2) enhancing quality of target area generation with the help of target area labels. The generator of TarGAN jointly learns mapping at two levels simultaneously - whole image translation mapping and target area translation mapping. These two mappings are interrelated through a proposed crossing loss. The experiments on both quantitative measures and qualitative evaluations demonstrate that TarGAN outperforms the state-of-the-art methods in all cases. Subsequent segmentation task is conducted to demonstrate effectiveness of synthetic images generated by TarGAN in a real-world application. Our code is available at https://github.com/2165998/TarGAN.
An Object Detection based Solver for Google's Image reCAPTCHA v2
Apr 07, 2021
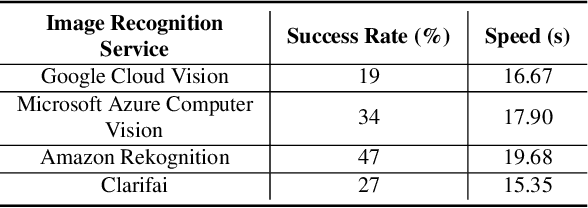
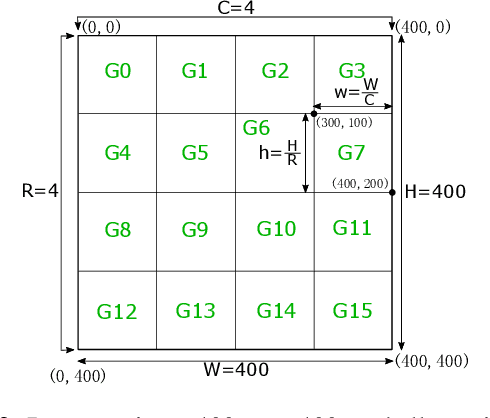
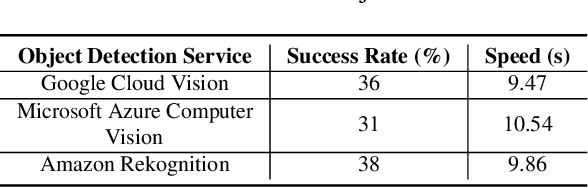
Previous work showed that reCAPTCHA v2's image challenges could be solved by automated programs armed with Deep Neural Network (DNN) image classifiers and vision APIs provided by off-the-shelf image recognition services. In response to emerging threats, Google has made significant updates to its image reCAPTCHA v2 challenges that can render the prior approaches ineffective to a great extent. In this paper, we investigate the robustness of the latest version of reCAPTCHA v2 against advanced object detection based solvers. We propose a fully automated object detection based system that breaks the most advanced challenges of reCAPTCHA v2 with an online success rate of 83.25%, the highest success rate to date, and it takes only 19.93 seconds (including network delays) on average to crack a challenge. We also study the updated security features of reCAPTCHA v2, such as anti-recognition mechanisms, improved anti-bot detection techniques, and adjustable security preferences. Our extensive experiments show that while these security features can provide some resistance against automated attacks, adversaries can still bypass most of them. Our experimental findings indicate that the recent advances in object detection technologies pose a severe threat to the security of image captcha designs relying on simple object detection as their underlying AI problem.
Rethinking the Truly Unsupervised Image-to-Image Translation
Jun 11, 2020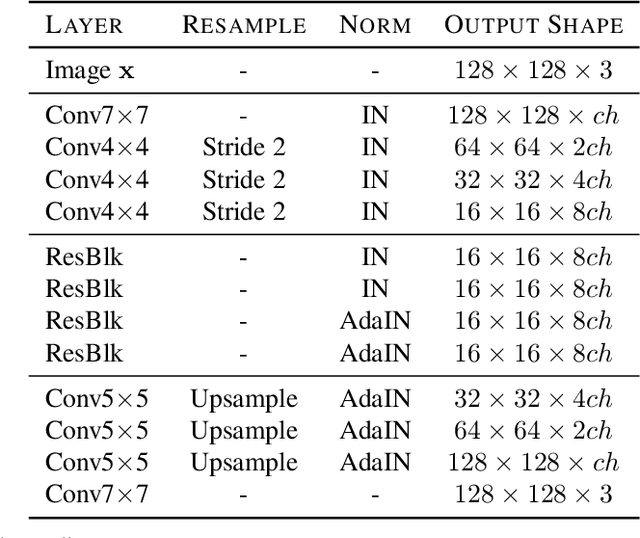

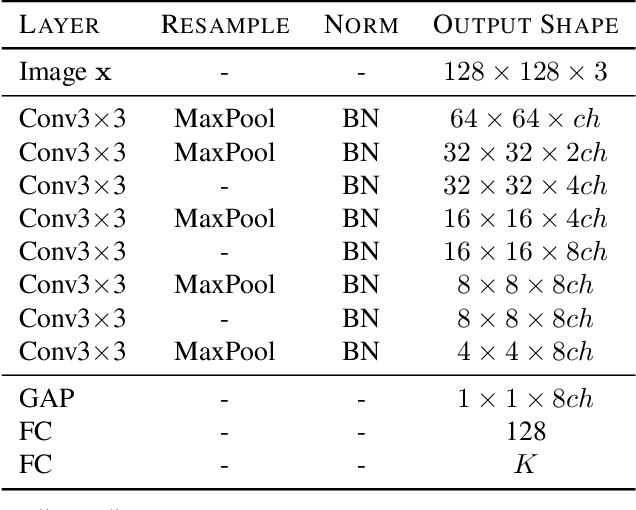
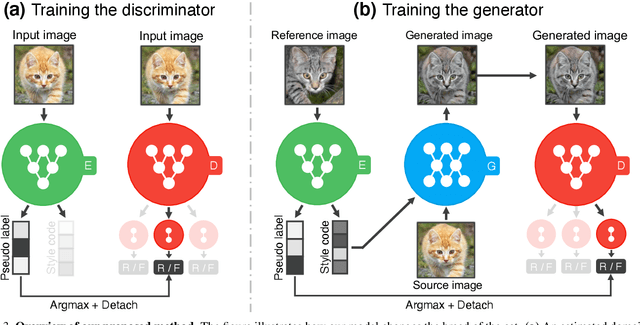
Every recent image-to-image translation model uses either image-level (i.e. input-output pairs) or set-level (i.e. domain labels) supervision at minimum. However, even the set-level supervision can be a serious bottleneck for data collection in practice. In this paper, we tackle image-to-image translation in a fully unsupervised setting, i.e., neither paired images nor domain labels. To this end, we propose the truly unsupervised image-to-image translation method (TUNIT) that simultaneously learns to separate image domains via an information-theoretic approach and generate corresponding images using the estimated domain labels. Experimental results on various datasets show that the proposed method successfully separates domains and translates images across those domains. In addition, our model outperforms existing set-level supervised methods under a semi-supervised setting, where a subset of domain labels is provided. The source code is available at https://github.com/clovaai/tunit