 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Lightweight Dual-Domain Attention Framework for Sparse-View CT Reconstruction
Feb 19, 2022
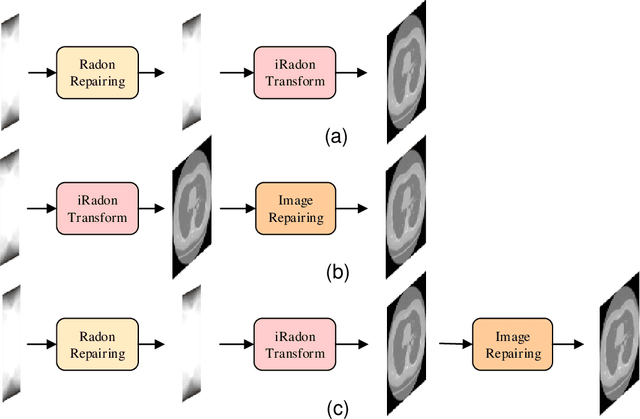

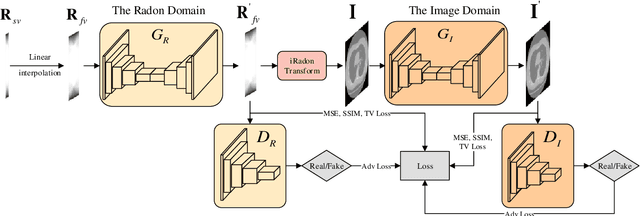

Computed Tomography (CT) plays an essential role in clinical diagnosis. Due to the adverse effects of radiation on patients, the radiation dose is expected to be reduced as low as possible. Sparse sampling is an effective way, but it will lead to severe artifacts on the reconstructed CT image, thus sparse-view CT image reconstruction has been a prevailing and challenging research area. With the popularity of mobile devices, the requirements for lightweight and real-time networks are increasing rapidly. In this paper, we design a novel lightweight network called CAGAN, and propose a dual-domain reconstruction pipeline for parallel beam sparse-view CT. CAGAN is an adversarial auto-encoder, combining the Coordinate Attention unit, which preserves the spatial information of features. Also, the application of Shuffle Blocks reduces the parameters by a quarter without sacrificing its performance. In the Radon domain, the CAGAN learns the mapping between the interpolated data and fringe-free projection data. After the restored Radon data is reconstructed to an image, the image is sent into the second CAGAN trained for recovering the details, so that a high-quality image is obtained. Experiments indicate that the CAGAN strikes an excellent balance between model complexity and performance, and our pipeline outperforms the DD-Net and the DuDoNet.
A Mixed Quantization Network for Computationally Efficient Mobile Inverse Tone Mapping
Mar 12, 2022
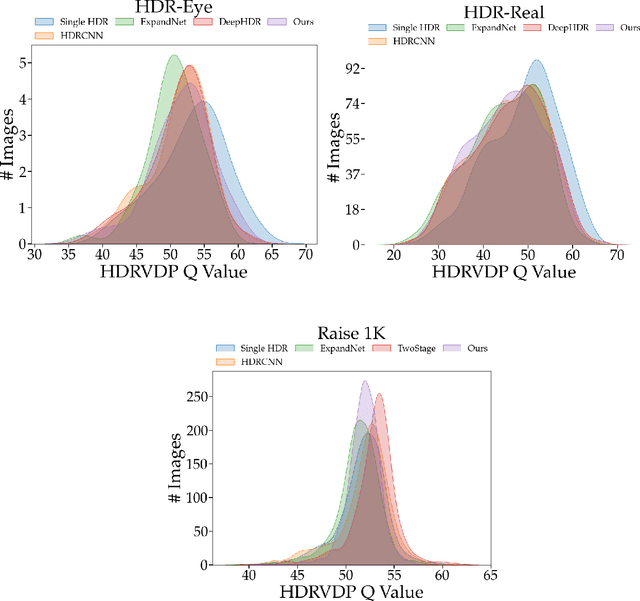
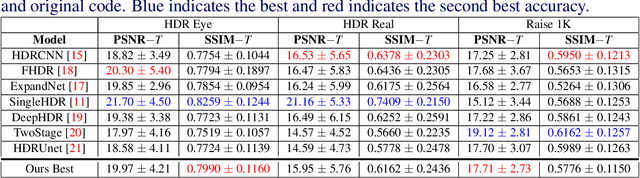
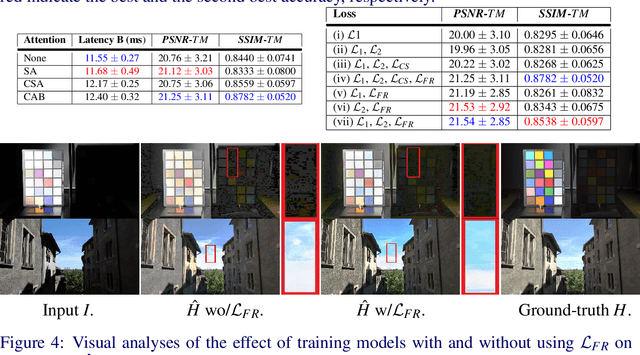
Recovering a high dynamic range (HDR) image from a single low dynamic range (LDR) image, namely inverse tone mapping (ITM), is challenging due to the lack of information in over- and under-exposed regions. Current methods focus exclusively on training high-performing but computationally inefficient ITM models, which in turn hinder deployment of the ITM models in resource-constrained environments with limited computing power such as edge and mobile device applications. To this end, we propose combining efficient operations of deep neural networks with a novel mixed quantization scheme to construct a well-performing but computationally efficient mixed quantization network (MQN) which can perform single image ITM on mobile platforms. In the ablation studies, we explore the effect of using different attention mechanisms, quantization schemes, and loss functions on the performance of MQN in ITM tasks. In the comparative analyses, ITM models trained using MQN perform on par with the state-of-the-art methods on benchmark datasets. MQN models provide up to 10 times improvement on latency and 25 times improvement on memory consumption.
CAMERAS: Enhanced Resolution And Sanity preserving Class Activation Mapping for image saliency
Jun 20, 2021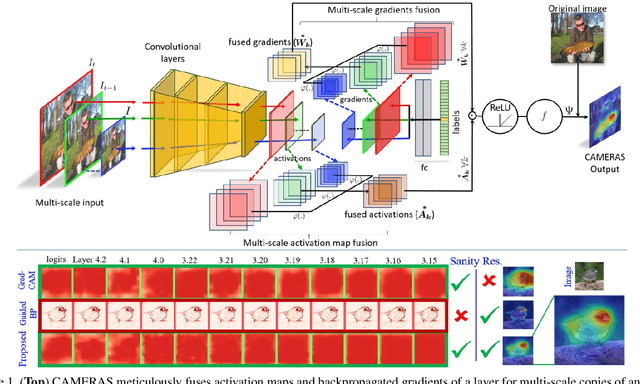
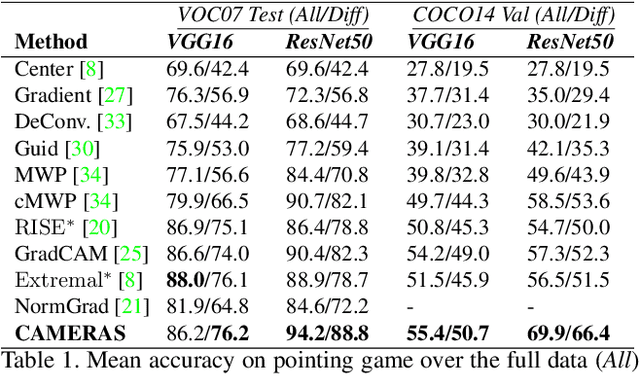
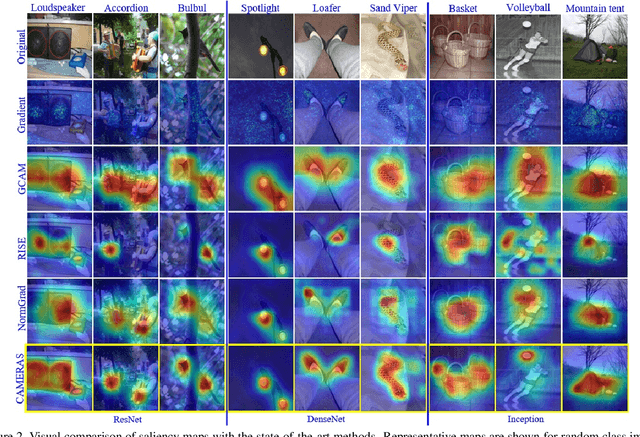
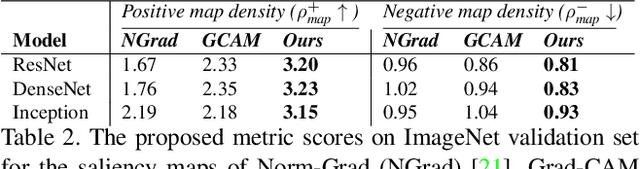
Backpropagation image saliency aims at explaining model predictions by estimating model-centric importance of individual pixels in the input. However, class-insensitivity of the earlier layers in a network only allows saliency computation with low resolution activation maps of the deeper layers, resulting in compromised image saliency. Remedifying this can lead to sanity failures. We propose CAMERAS, a technique to compute high-fidelity backpropagation saliency maps without requiring any external priors and preserving the map sanity. Our method systematically performs multi-scale accumulation and fusion of the activation maps and backpropagated gradients to compute precise saliency maps. From accurate image saliency to articulation of relative importance of input features for different models, and precise discrimination between model perception of visually similar objects, our high-resolution mapping offers multiple novel insights into the black-box deep visual models, which are presented in the paper. We also demonstrate the utility of our saliency maps in adversarial setup by drastically reducing the norm of attack signals by focusing them on the precise regions identified by our maps. Our method also inspires new evaluation metrics and a sanity check for this developing research direction. Code is available here https://github.com/VisMIL/CAMERAS
MonoDETR: Depth-aware Transformer for Monocular 3D Object Detection
Mar 28, 2022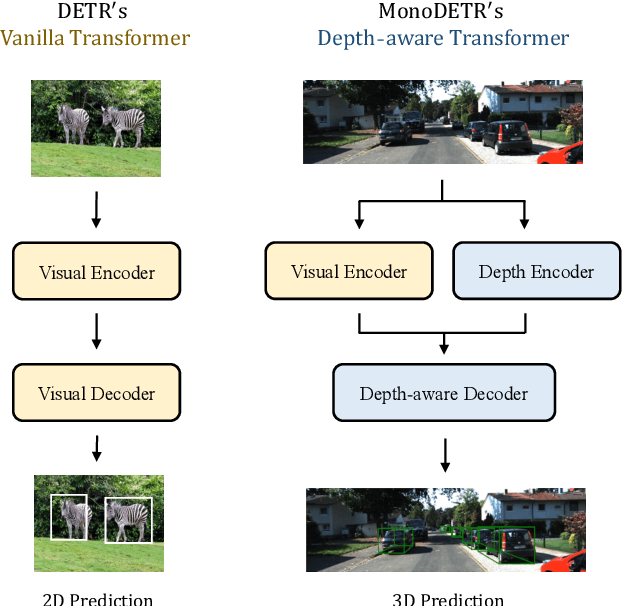
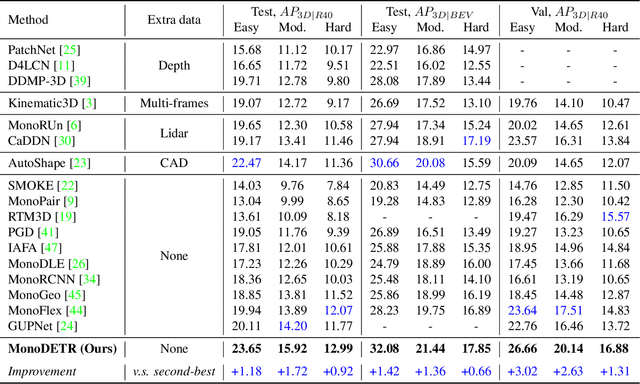

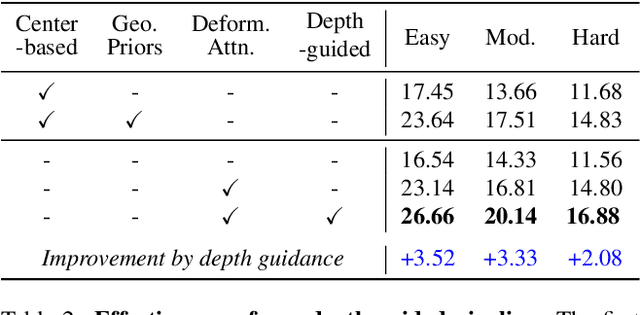
Monocular 3D object detection has long been a challenging task in autonomous driving, which requires to decode 3D predictions solely from a single 2D image. Most existing methods follow conventional 2D object detectors to first localize objects by their centers, and then predict 3D attributes using center-neighboring local features. However, such center-based pipeline views 3D prediction as a subordinate task and lacks inter-object depth interactions with global spatial clues. In this paper, we introduce a simple framework for Monocular DEtection with depth-aware TRansformer, named MonoDETR. We enable the vanilla transformer to be depth-aware and enforce the whole detection process guided by depth. Specifically, we represent 3D object candidates as a set of queries and produce non-local depth embeddings of the input image by a lightweight depth predictor and an attention-based depth encoder. Then, we propose a depth-aware decoder to conduct both inter-query and query-scene depth feature communication. In this way, each object estimates its 3D attributes adaptively from the depth-informative regions on the image, not limited by center-around features. With minimal handcrafted designs, MonoDETR is an end-to-end framework without additional data, anchors or NMS and achieves competitive performance on KITTI benchmark among state-of-the-art center-based networks. Extensive ablation studies demonstrate the effectiveness of our approach and its potential to serve as a transformer baseline for future monocular research. Code is available at https://github.com/ZrrSkywalker/MonoDETR.git.
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
May 27, 2022

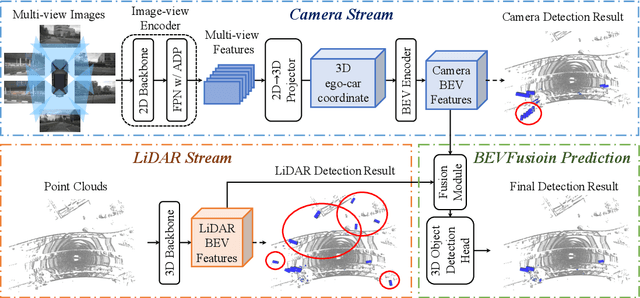
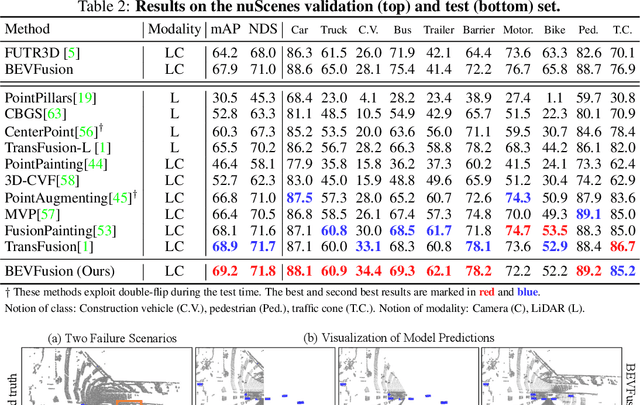
Fusing the camera and LiDAR information has become a de-facto standard for 3D object detection tasks. Current methods rely on point clouds from the LiDAR sensor as queries to leverage the feature from the image space. However, people discover that this underlying assumption makes the current fusion framework infeasible to produce any prediction when there is a LiDAR malfunction, regardless of minor or major. This fundamentally limits the deployment capability to realistic autonomous driving scenarios. In contrast, we propose a surprisingly simple yet novel fusion framework, dubbed BEVFusion, whose camera stream does not depend on the input of LiDAR data, thus addressing the downside of previous methods. We empirically show that our framework surpasses the state-of-the-art methods under the normal training settings. Under the robustness training settings that simulate various LiDAR malfunctions, our framework significantly surpasses the state-of-the-art methods by 15.7% to 28.9% mAP. To the best of our knowledge, we are the first to handle realistic LiDAR malfunction and can be deployed to realistic scenarios without any post-processing procedure. The code is available at https://github.com/ADLab-AutoDrive/BEVFusion.
PCNet: A Structure Similarity Enhancement Method for Multispectral and Multimodal Image Registration
Jun 09, 2021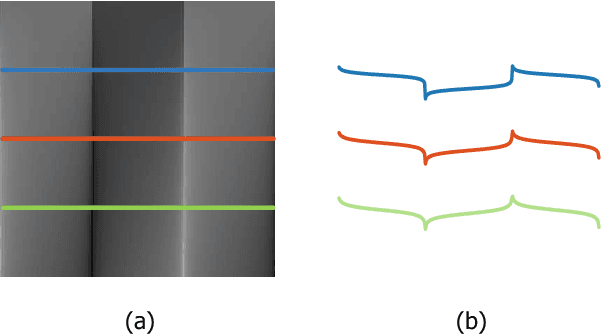
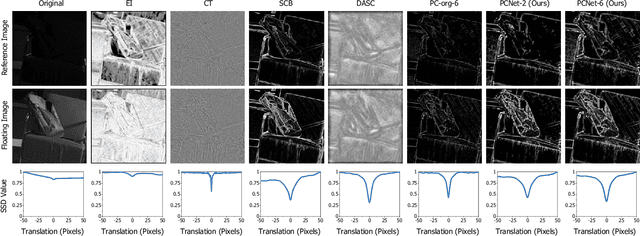


Multispectral and multimodal image processing is important in the community of computer vision and computational photography. As the acquired multispectral and multimodal data are generally misaligned due to the alternation or movement of the image device, the image registration procedure is necessary. The registration of multispectral or multimodal image is challenging due to the non-linear intensity and gradient variation. To cope with this challenge, we propose the phase congruency network (PCNet), which is able to enhance the structure similarity and alleviate the non-linear intensity and gradient variation. The images can then be aligned using the similarity enhanced features produced by the network. PCNet is constructed under the guidance of the phase congruency prior. The network contains three trainable layers accompany with the modified learnable Gabor kernels according to the phase congruency theory. Thanks to the prior knowledge, PCNet is extremely light-weight and can be trained on quite a small amount of multispectral data. PCNet can be viewed to be fully convolutional and hence can take input of arbitrary sizes. Once trained, PCNet is applicable on a variety of multispectral and multimodal data such as RGB/NIR and flash/no-flash images without additional further tuning. Experimental results validate that PCNet outperforms current state-of-the-art registration algorithms, including the deep-learning based ones that have the number of parameters hundreds times compared to PCNet. Thanks to the similarity enhancement training, PCNet outperforms the original phase congruency algorithm with two-thirds less feature channels.
A GAN-Based Input-Size Flexibility Model for Single Image Dehazing
Feb 19, 2021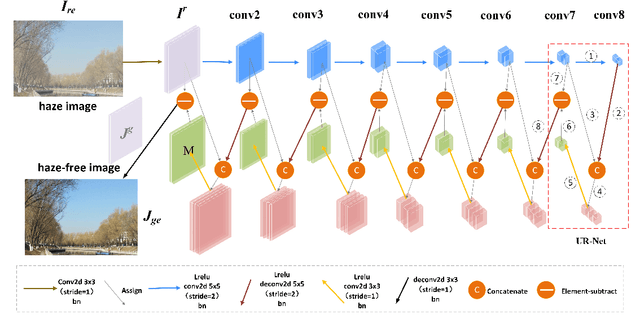
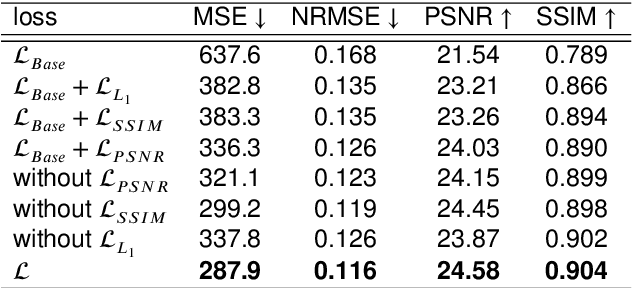
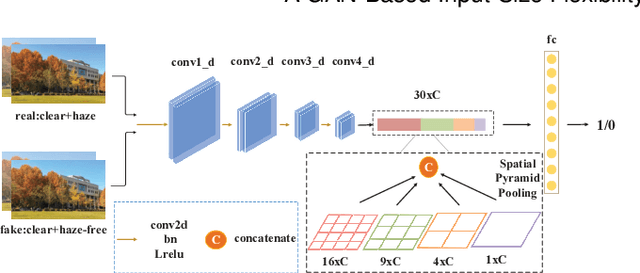
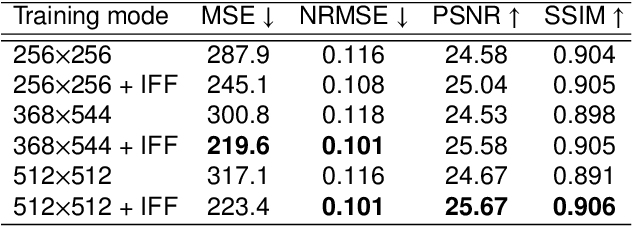
Image-to-image translation based on generative adversarial network (GAN) has achieved state-of-the-art performance in various image restoration applications. Single image dehazing is a typical example, which aims to obtain the haze-free image of a haze one. This paper concentrates on the challenging task of single image dehazing. Based on the atmospheric scattering model, we design a novel model to directly generate the haze-free image. The main challenge of image dehazing is that the atmospheric scattering model has two parameters, i.e., transmission map and atmospheric light. When we estimate them respectively, the errors will be accumulated to compromise dehazing quality. Considering this reason and various image sizes, we propose a novel input-size flexibility conditional generative adversarial network (cGAN) for single image dehazing, which is input-size flexibility at both training and test stages for image-to-image translation with cGAN framework. We propose a simple and effective U-type residual network (UR-Net) to combine the generator and adopt the spatial pyramid pooling (SPP) to design the discriminator. Moreover, the model is trained with multi-loss function, in which the consistency loss is a novel designed loss in this paper. We finally build a multi-scale cGAN fusion model to realize state-of-the-art single image dehazing performance. The proposed models receive a haze image as input and directly output a haze-free one. Experimental results demonstrate the effectiveness and efficiency of the proposed models.
Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Feb 07, 2022
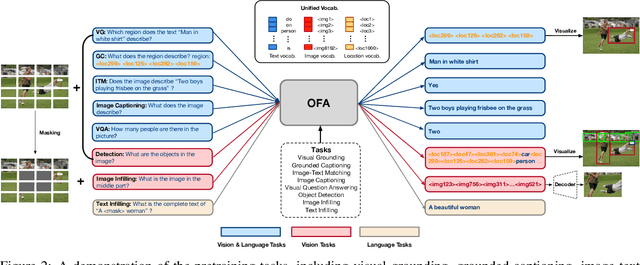
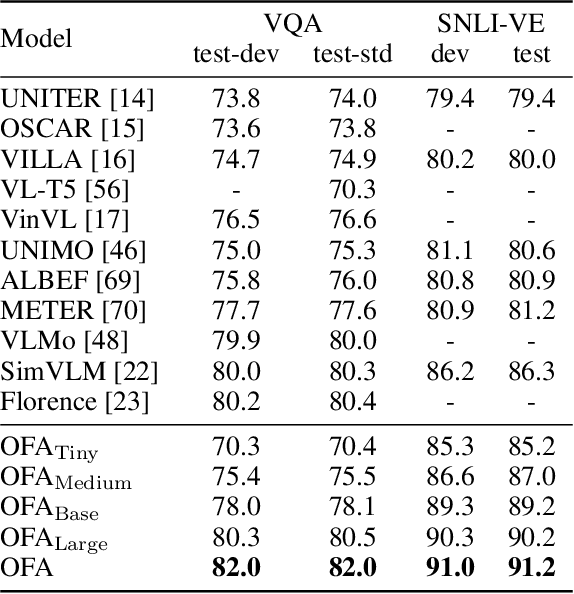
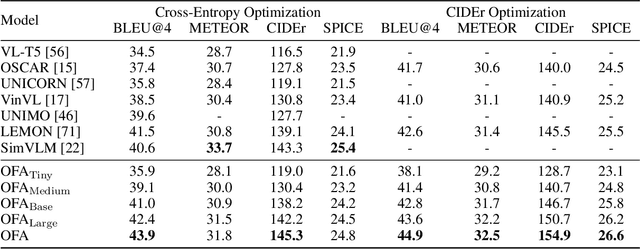
In this work, we pursue a unified paradigm for multimodal pretraining to break the scaffolds of complex task/modality-specific customization. We propose OFA, a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image generation, visual grounding, image captioning, image classification, text generation, etc.) to a simple sequence-to-sequence learning framework based on the encoder-decoder architecture. OFA performs pretraining and finetuning with task instructions and introduces no extra task-specific layers for finetuning. Experimental results show that OFA achieves new state-of-the-arts on a series of multimodal tasks, including image captioning (COCO test CIDEr: 149.6), text-to-image generation (COCO test FID: 10.5), VQA (test-std acc.: 80.02), SNLI-VE (test acc.: 90.20), and referring expression comprehension (RefCOCO / RefCOCO+ / RefCOCOg test acc.: 92.93 / 90.10 / 85.20). Through extensive analyses, we demonstrate that OFA reaches comparable performance with uni-modal pretrained models (e.g., BERT, MAE, MoCo v3, SimCLR v2, etc.) in uni-modal tasks, including NLU, NLG, and image classification, and it effectively transfers to unseen tasks and domains. Code shall be released soon at http://github.com/OFA-Sys/OFA
TarGAN: Target-Aware Generative Adversarial Networks for Multi-modality Medical Image Translation
May 19, 2021
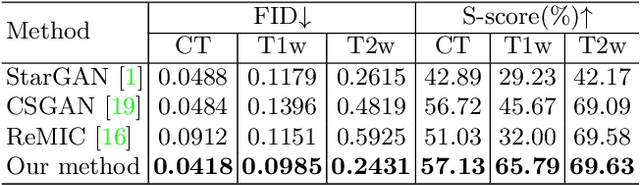
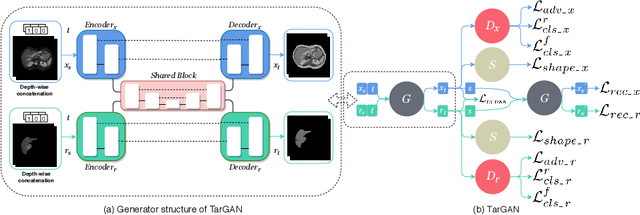
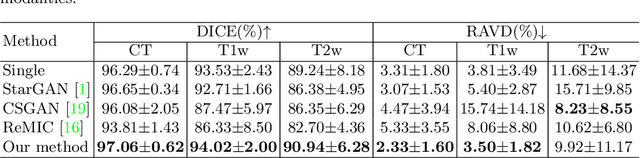
Paired multi-modality medical images, can provide complementary information to help physicians make more reasonable decisions than single modality medical images. But they are difficult to generate due to multiple factors in practice (e.g., time, cost, radiation dose). To address these problems, multi-modality medical image translation has aroused increasing research interest recently. However, the existing works mainly focus on translation effect of a whole image instead of a critical target area or Region of Interest (ROI), e.g., organ and so on. This leads to poor-quality translation of the localized target area which becomes blurry, deformed or even with extra unreasonable textures. In this paper, we propose a novel target-aware generative adversarial network called TarGAN, which is a generic multi-modality medical image translation model capable of (1) learning multi-modality medical image translation without relying on paired data, (2) enhancing quality of target area generation with the help of target area labels. The generator of TarGAN jointly learns mapping at two levels simultaneously - whole image translation mapping and target area translation mapping. These two mappings are interrelated through a proposed crossing loss. The experiments on both quantitative measures and qualitative evaluations demonstrate that TarGAN outperforms the state-of-the-art methods in all cases. Subsequent segmentation task is conducted to demonstrate effectiveness of synthetic images generated by TarGAN in a real-world application. Our code is available at https://github.com/2165998/TarGAN.
Deep Multi-view Semi-supervised Clustering with Sample Pairwise Constraints
Jun 10, 2022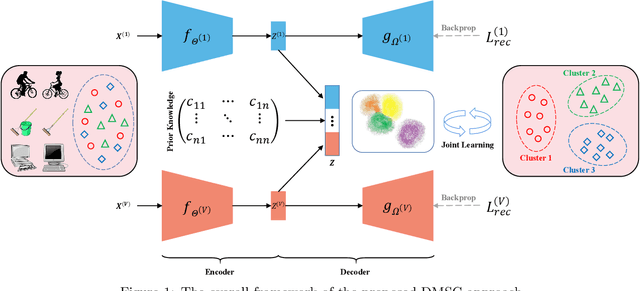


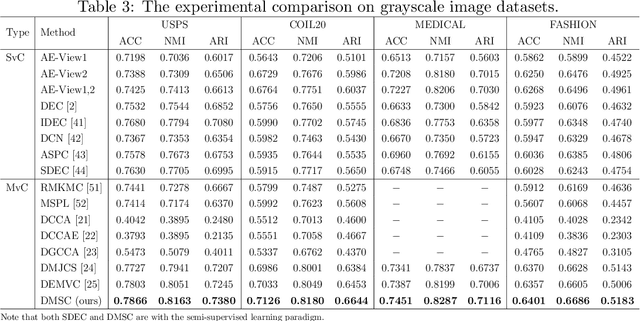
Multi-view clustering has attracted much attention thanks to the capacity of multi-source information integration. Although numerous advanced methods have been proposed in past decades, most of them generally overlook the significance of weakly-supervised information and fail to preserve the feature properties of multiple views, thus resulting in unsatisfactory clustering performance. To address these issues, in this paper, we propose a novel Deep Multi-view Semi-supervised Clustering (DMSC) method, which jointly optimizes three kinds of losses during networks finetuning, including multi-view clustering loss, semi-supervised pairwise constraint loss and multiple autoencoders reconstruction loss. Specifically, a KL divergence based multi-view clustering loss is imposed on the common representation of multi-view data to perform heterogeneous feature optimization, multi-view weighting and clustering prediction simultaneously. Then, we innovatively propose to integrate pairwise constraints into the process of multi-view clustering by enforcing the learned multi-view representation of must-link samples (cannot-link samples) to be similar (dissimilar), such that the formed clustering architecture can be more credible. Moreover, unlike existing rivals that only preserve the encoders for each heterogeneous branch during networks finetuning, we further propose to tune the intact autoencoders frame that contains both encoders and decoders. In this way, the issue of serious corruption of view-specific and view-shared feature space could be alleviated, making the whole training procedure more stable. Through comprehensive experiments on eight popular image datasets, we demonstrate that our proposed approach performs better than the state-of-the-art multi-view and single-view competitors.