 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly Supervised Patch Label Inference Networks for Efficient Pavement Distress Detection and Recognition in the Wild
Mar 31, 2022
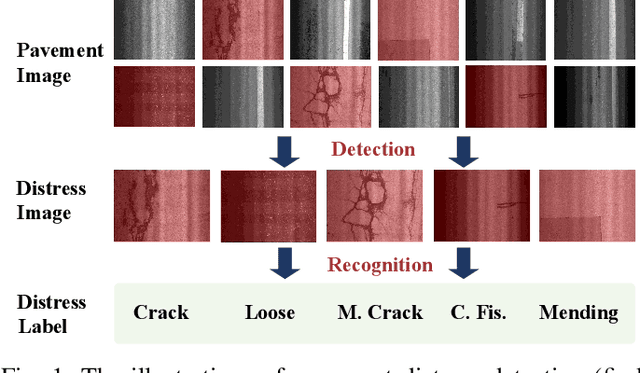
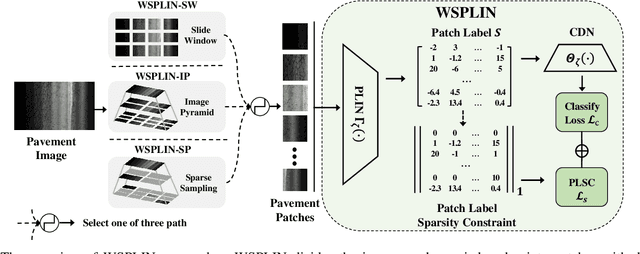

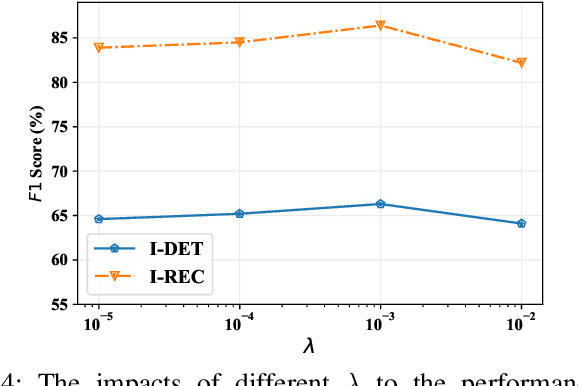
Automatic image-based pavement distress detection and recognition are vital for pavement maintenance and management. However, existing deep learning-based methods largely omit the specific characteristics of pavement images, such as high image resolution and low distress area ratio, and are not end-to-end trainable. In this paper, we present a series of simple yet effective end-to-end deep learning approaches named Weakly Supervised Patch Label Inference Networks (WSPLIN) for efficiently addressing these tasks under various application settings. To fully exploit the resolution and scale information, WSPLIN first divides the pavement image under different scales into patches with different collection strategies and then employs a Patch Label Inference Network (PLIN) to infer the labels of these patches. Notably, we design a patch label sparsity constraint based on the prior knowledge of distress distribution, and leverage the Comprehensive Decision Network (CDN) to guide the training of PLIN in a weakly supervised way. Therefore, the patch labels produced by PLIN provide interpretable intermediate information, such as the rough location and the type of distress. We evaluate our method on a large-scale bituminous pavement distress dataset named CQU-BPDD. Extensive results demonstrate the superiority of our method over baselines in both performance and efficiency.
SketchHairSalon: Deep Sketch-based Hair Image Synthesis
Sep 21, 2021
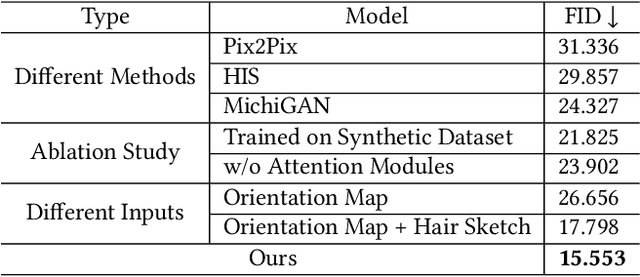
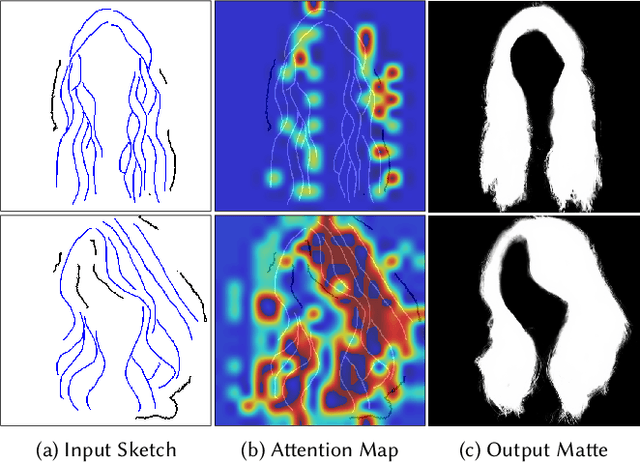
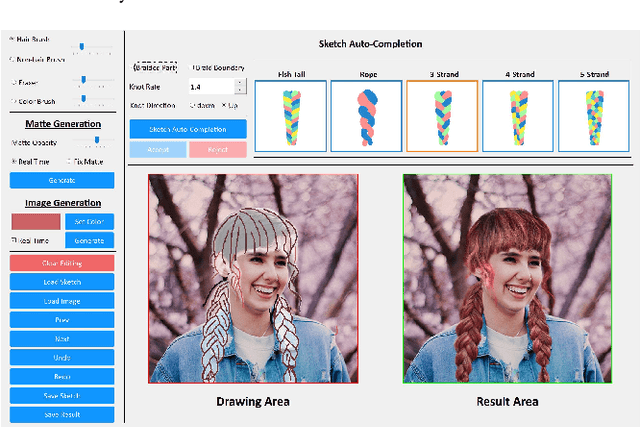
Recent deep generative models allow real-time generation of hair images from sketch inputs. Existing solutions often require a user-provided binary mask to specify a target hair shape. This not only costs users extra labor but also fails to capture complicated hair boundaries. Those solutions usually encode hair structures via orientation maps, which, however, are not very effective to encode complex structures. We observe that colored hair sketches already implicitly define target hair shapes as well as hair appearance and are more flexible to depict hair structures than orientation maps. Based on these observations, we present SketchHairSalon, a two-stage framework for generating realistic hair images directly from freehand sketches depicting desired hair structure and appearance. At the first stage, we train a network to predict a hair matte from an input hair sketch, with an optional set of non-hair strokes. At the second stage, another network is trained to synthesize the structure and appearance of hair images from the input sketch and the generated matte. To make the networks in the two stages aware of long-term dependency of strokes, we apply self-attention modules to them. To train these networks, we present a new dataset containing thousands of annotated hair sketch-image pairs and corresponding hair mattes. Two efficient methods for sketch completion are proposed to automatically complete repetitive braided parts and hair strokes, respectively, thus reducing the workload of users. Based on the trained networks and the two sketch completion strategies, we build an intuitive interface to allow even novice users to design visually pleasing hair images exhibiting various hair structures and appearance via freehand sketches. The qualitative and quantitative evaluations show the advantages of the proposed system over the existing or alternative solutions.
Boosting the Adversarial Transferability of Surrogate Model with Dark Knowledge
Jun 16, 2022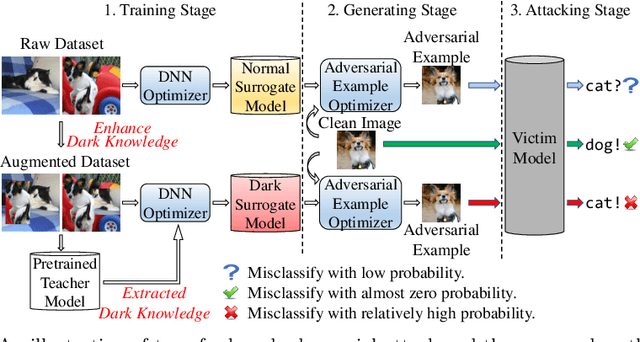
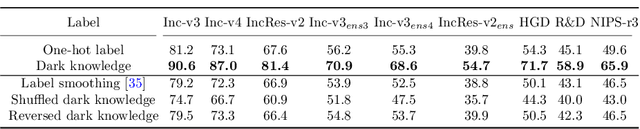
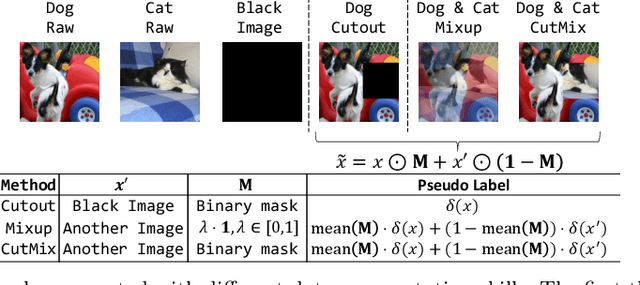
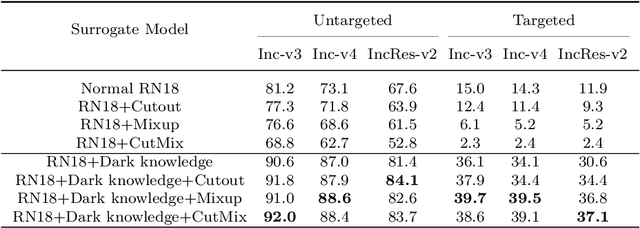
Deep neural networks (DNNs) for image classification are known to be vulnerable to adversarial examples. And, the adversarial examples have transferability, which means an adversarial example for a DNN model can fool another black-box model with a non-trivial probability. This gave birth of the transfer-based adversarial attack where the adversarial examples generated by a pretrained or known model (called surrogate model) are used to conduct black-box attack. There are some work on how to generate the adversarial examples from a given surrogate model to achieve better transferability. However, training a special surrogate model to generate adversarial examples with better transferability is relatively under-explored. In this paper, we propose a method of training a surrogate model with abundant dark knowledge to boost the adversarial transferability of the adversarial examples generated by the surrogate model. This trained surrogate model is named dark surrogate model (DSM), and the proposed method to train DSM consists of two key components: a teacher model extracting dark knowledge and providing soft labels, and the mixing augmentation skill which enhances the dark knowledge of training data. Extensive experiments have been conducted to show that the proposed method can substantially improve the adversarial transferability of surrogate model across different architectures of surrogate model and optimizers for generating adversarial examples. We also show that the proposed method can be applied to other scenarios of transfer-based attack that contain dark knowledge, like face verification.
Hyperspectral Unmixing Based on Nonnegative Matrix Factorization: A Comprehensive Review
May 20, 2022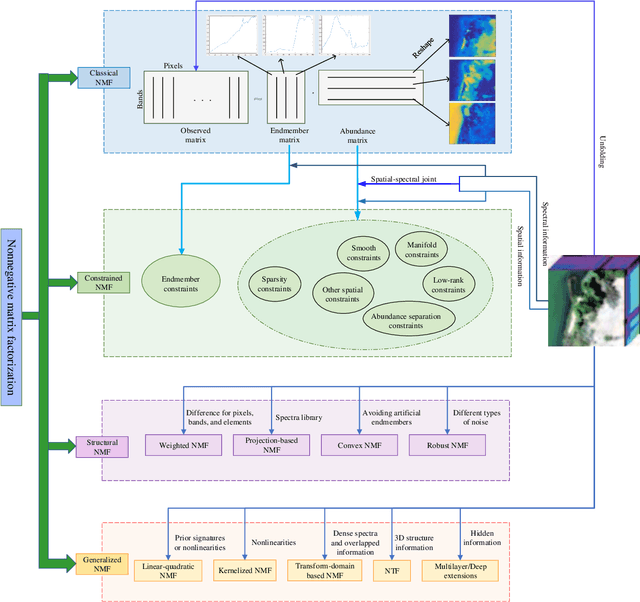
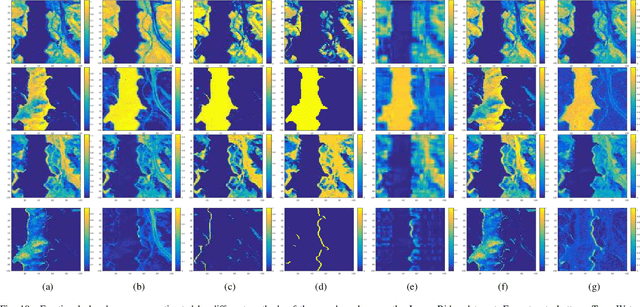
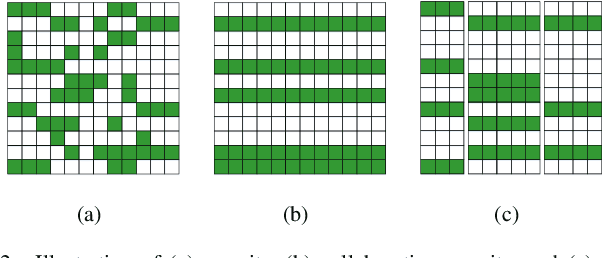
Hyperspectral unmixing has been an important technique that estimates a set of endmembers and their corresponding abundances from a hyperspectral image (HSI). Nonnegative matrix factorization (NMF) plays an increasingly significant role in solving this problem. In this article, we present a comprehensive survey of the NMF-based methods proposed for hyperspectral unmixing. Taking the NMF model as a baseline, we show how to improve NMF by utilizing the main properties of HSIs (e.g., spectral, spatial, and structural information). We categorize three important development directions including constrained NMF, structured NMF, and generalized NMF. Furthermore, several experiments are conducted to illustrate the effectiveness of associated algorithms. Finally, we conclude the article with possible future directions with the purposes of providing guidelines and inspiration to promote the development of hyperspectral unmixing.
VisFIS: Visual Feature Importance Supervision with Right-for-the-Right-Reason Objectives
Jun 22, 2022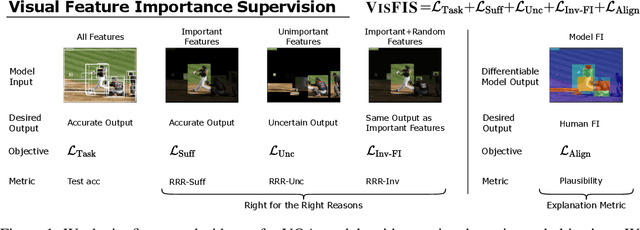
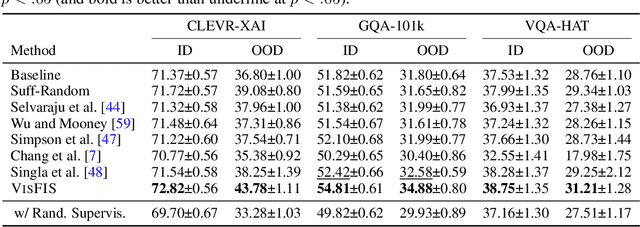
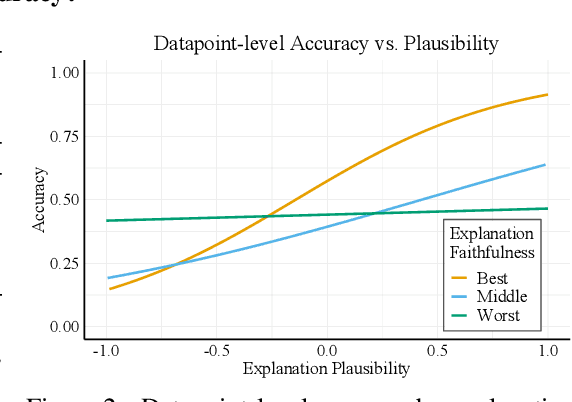
Many past works aim to improve visual reasoning in models by supervising feature importance (estimated by model explanation techniques) with human annotations such as highlights of important image regions. However, recent work has shown that performance gains from feature importance (FI) supervision for Visual Question Answering (VQA) tasks persist even with random supervision, suggesting that these methods do not meaningfully align model FI with human FI. In this paper, we show that model FI supervision can meaningfully improve VQA model accuracy as well as performance on several Right-for-the-Right-Reason (RRR) metrics by optimizing for four key model objectives: (1) accurate predictions given limited but sufficient information (Sufficiency); (2) max-entropy predictions given no important information (Uncertainty); (3) invariance of predictions to changes in unimportant features (Invariance); and (4) alignment between model FI explanations and human FI explanations (Plausibility). Our best performing method, Visual Feature Importance Supervision (VisFIS), outperforms strong baselines on benchmark VQA datasets in terms of both in-distribution and out-of-distribution accuracy. While past work suggests that the mechanism for improved accuracy is through improved explanation plausibility, we show that this relationship depends crucially on explanation faithfulness (whether explanations truly represent the model's internal reasoning). Predictions are more accurate when explanations are plausible and faithful, and not when they are plausible but not faithful. Lastly, we show that, surprisingly, RRR metrics are not predictive of out-of-distribution model accuracy when controlling for a model's in-distribution accuracy, which calls into question the value of these metrics for evaluating model reasoning. All supporting code is available at https://github.com/zfying/visfis
Simple and Efficient Architectures for Semantic Segmentation
Jun 16, 2022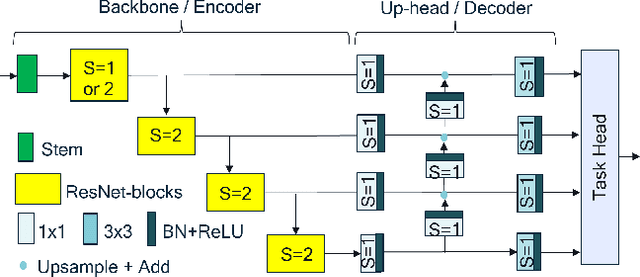
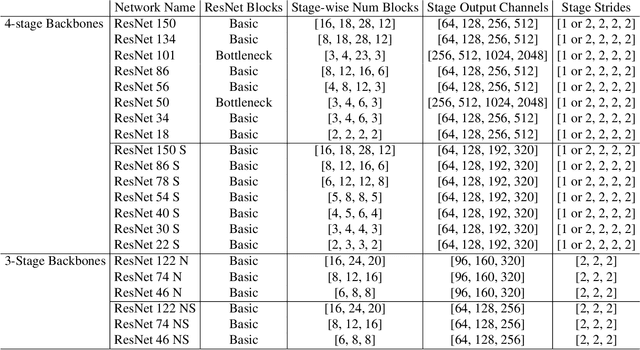
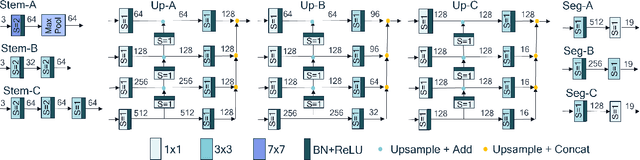
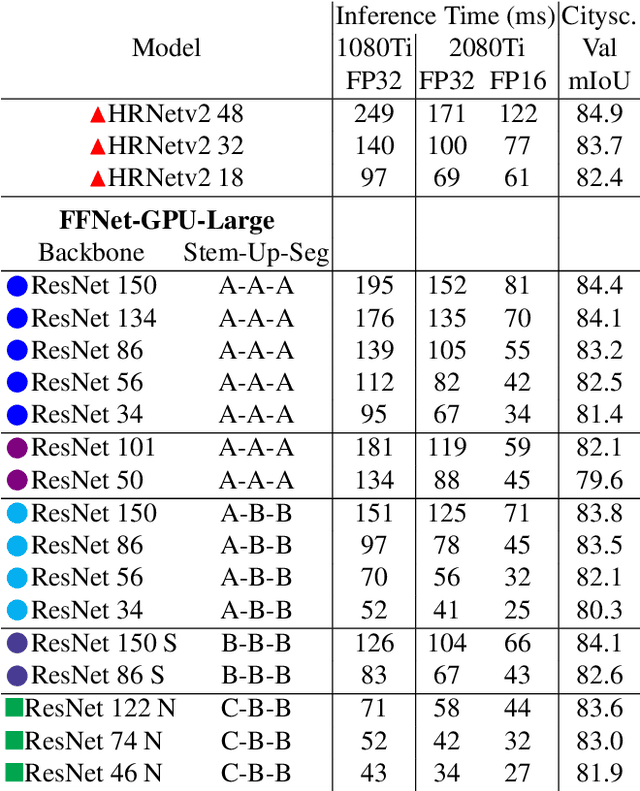
Though the state-of-the architectures for semantic segmentation, such as HRNet, demonstrate impressive accuracy, the complexity arising from their salient design choices hinders a range of model acceleration tools, and further they make use of operations that are inefficient on current hardware. This paper demonstrates that a simple encoder-decoder architecture with a ResNet-like backbone and a small multi-scale head, performs on-par or better than complex semantic segmentation architectures such as HRNet, FANet and DDRNets. Naively applying deep backbones designed for Image Classification to the task of Semantic Segmentation leads to sub-par results, owing to a much smaller effective receptive field of these backbones. Implicit among the various design choices put forth in works like HRNet, DDRNet, and FANet are networks with a large effective receptive field. It is natural to ask if a simple encoder-decoder architecture would compare favorably if comprised of backbones that have a larger effective receptive field, though without the use of inefficient operations like dilated convolutions. We show that with minor and inexpensive modifications to ResNets, enlarging the receptive field, very simple and competitive baselines can be created for Semantic Segmentation. We present a family of such simple architectures for desktop as well as mobile targets, which match or exceed the performance of complex models on the Cityscapes dataset. We hope that our work provides simple yet effective baselines for practitioners to develop efficient semantic segmentation models.
GaussiGAN: Controllable Image Synthesis with 3D Gaussians from Unposed Silhouettes
Jun 24, 2021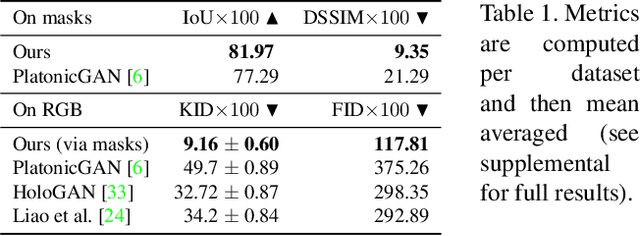
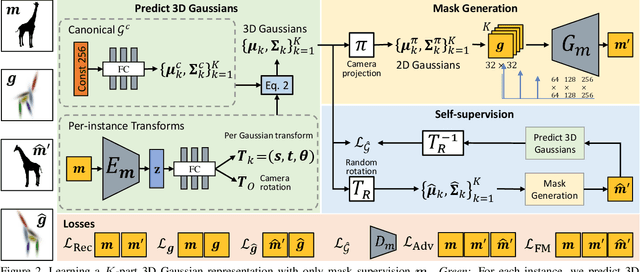
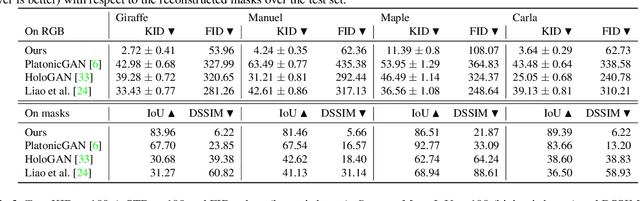
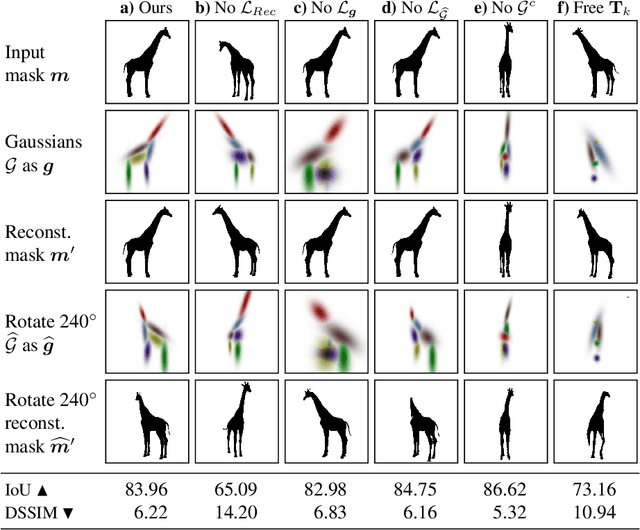
We present an algorithm that learns a coarse 3D representation of objects from unposed multi-view 2D mask supervision, then uses it to generate detailed mask and image texture. In contrast to existing voxel-based methods for unposed object reconstruction, our approach learns to represent the generated shape and pose with a set of self-supervised canonical 3D anisotropic Gaussians via a perspective camera, and a set of per-image transforms. We show that this approach can robustly estimate a 3D space for the camera and object, while recent baselines sometimes struggle to reconstruct coherent 3D spaces in this setting. We show results on synthetic datasets with realistic lighting, and demonstrate object insertion with interactive posing. With our work, we help move towards structured representations that handle more real-world variation in learning-based object reconstruction.
Precise Point Spread Function Estimation
Mar 06, 2022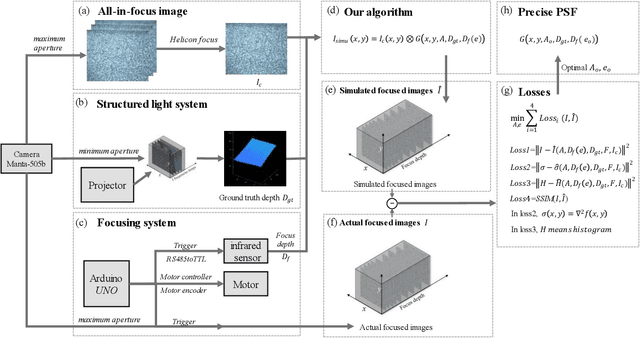

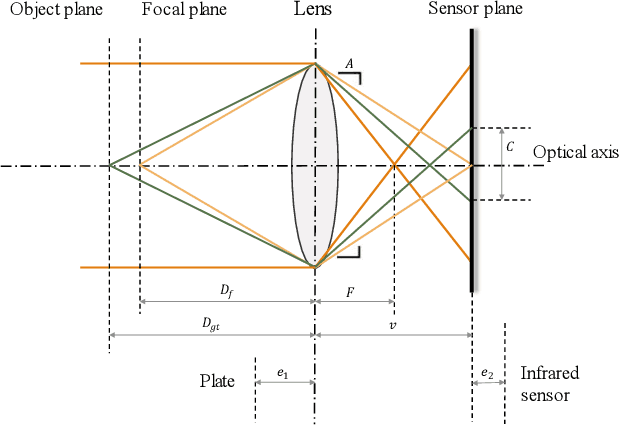
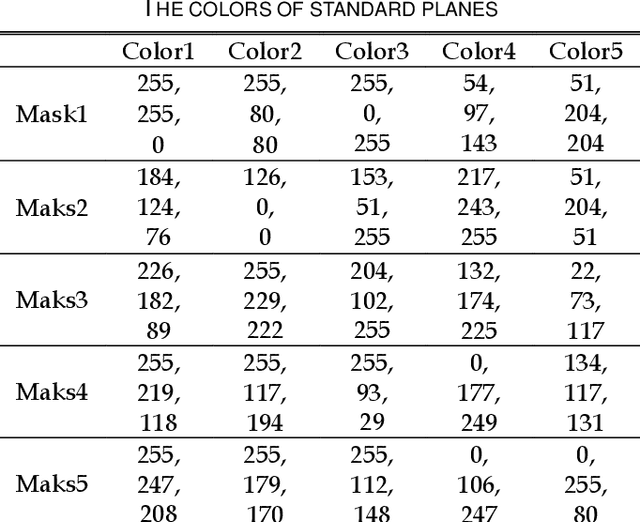
Point spread function (PSF) plays a crucial role in many fields, such as shape from focus/defocus, depth estimation, and imaging process in fluorescence microscopy. However, the mathematical model of the defocus process is still unclear because several variables in the point spread function are hard to measure accurately, such as the f-number of cameras, the physical size of a pixel, the focus depth, etc. In this work, we develop a precise mathematical model of the camera's point spread function to describe the defocus process. We first derive the mathematical algorithm for the PSF and extract two parameters A and e. A is the composite of camera's f-number, pixel-size, output scale, and scaling factor of the circle of confusion; e is the deviation of the focus depth. We design a novel metric based on the defocus histogram to evaluate the difference between the simulated focused image and the actual focused image to obtain optimal A and e. We also construct a hardware system consisting of a focusing system and a structured light system to acquire the all-in-focus image, the focused image with corresponding focus depth, and the depth map in the same view. The three types of images, as a dataset, are used to obtain the precise PSF. Our experiments on standard planes and actual objects show that the proposed algorithm can accurately describe the defocus process. The accuracy of our algorithm is further proved by evaluating the difference among the actual focused images, the focused image generated by our algorithm, the focused image generated by others. The results show that the loss of our algorithm is 40% less than others on average. The dataset, code, and model are available on GitHub: https://github.com/cubhe/ precise-point-spread-function-estimation.
Large Scale Image Completion via Co-Modulated Generative Adversarial Networks
Mar 18, 2021
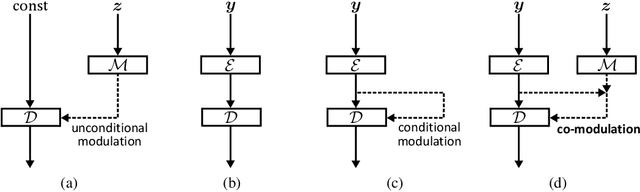

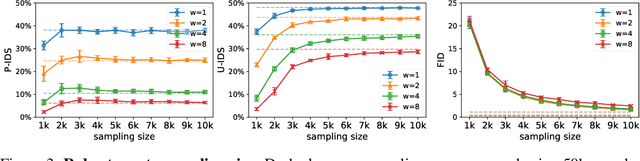
Numerous task-specific variants of conditional generative adversarial networks have been developed for image completion. Yet, a serious limitation remains that all existing algorithms tend to fail when handling large-scale missing regions. To overcome this challenge, we propose a generic new approach that bridges the gap between image-conditional and recent modulated unconditional generative architectures via co-modulation of both conditional and stochastic style representations. Also, due to the lack of good quantitative metrics for image completion, we propose the new Paired/Unpaired Inception Discriminative Score (P-IDS/U-IDS), which robustly measures the perceptual fidelity of inpainted images compared to real images via linear separability in a feature space. Experiments demonstrate superior performance in terms of both quality and diversity over state-of-the-art methods in free-form image completion and easy generalization to image-to-image translation. Code is available at https://github.com/zsyzzsoft/co-mod-gan.
A Novel Disaster Image Dataset and Characteristics Analysis using Attention Model
Jul 02, 2021
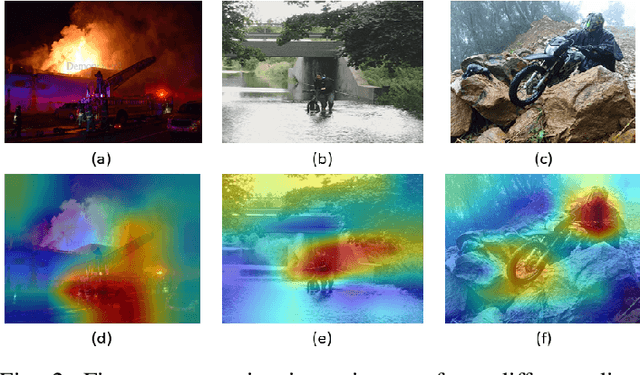

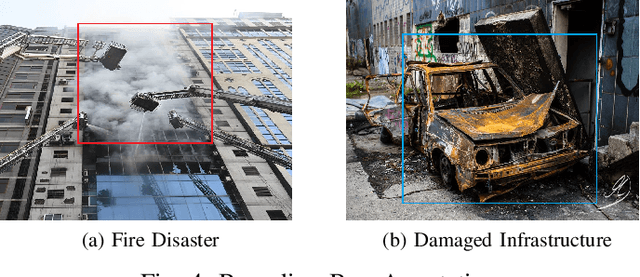
The advancement of deep learning technology has enabled us to develop systems that outperform any other classification technique. However, success of any empirical system depends on the quality and diversity of the data available to train the proposed system. In this research, we have carefully accumulated a relatively challenging dataset that contains images collected from various sources for three different disasters: fire, water and land. Besides this, we have also collected images for various damaged infrastructure due to natural or man made calamities and damaged human due to war or accidents. We have also accumulated image data for a class named non-damage that contains images with no such disaster or sign of damage in them. There are 13,720 manually annotated images in this dataset, each image is annotated by three individuals. We are also providing discriminating image class information annotated manually with bounding box for a set of 200 test images. Images are collected from different news portals, social media, and standard datasets made available by other researchers. A three layer attention model (TLAM) is trained and average five fold validation accuracy of 95.88% is achieved. Moreover, on the 200 unseen test images this accuracy is 96.48%. We also generate and compare attention maps for these test images to determine the characteristics of the trained attention model. Our dataset is available at https://niloy193.github.io/Disaster-Dataset