 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Soft Compression for Lossless Image Coding
Dec 11, 2020
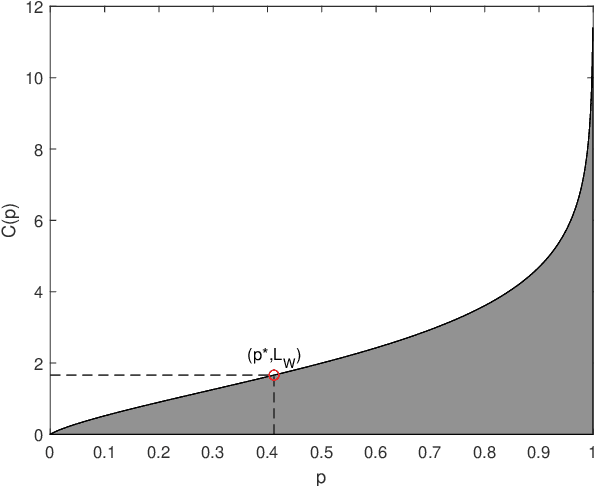
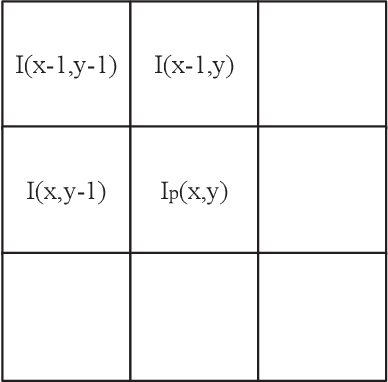

Soft compression is a lossless image compression method, which is committed to eliminating coding redundancy and spatial redundancy at the same time by adopting locations and shapes of codebook to encode an image from the perspective of information theory and statistical distribution. In this paper, we propose a new concept, compressible indicator function with regard to image, which gives a threshold about the average number of bits required to represent a location and can be used for revealing the performance of soft compression. We investigate and analyze soft compression for binary image, gray image and multi-component image by using specific algorithms and compressible indicator value. It is expected that the bandwidth and storage space needed when transmitting and storing the same kind of images can be greatly reduced by applying soft compression.
Benchmarking Generative Latent Variable Models for Speech
Apr 05, 2022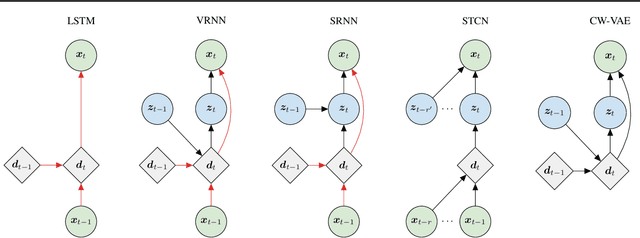
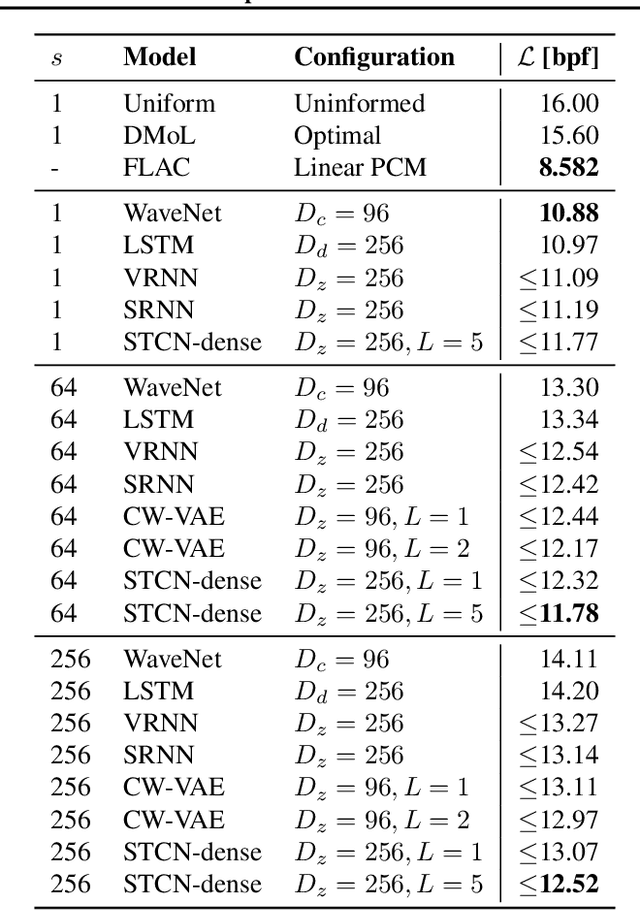
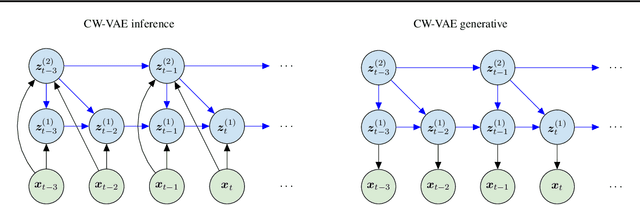
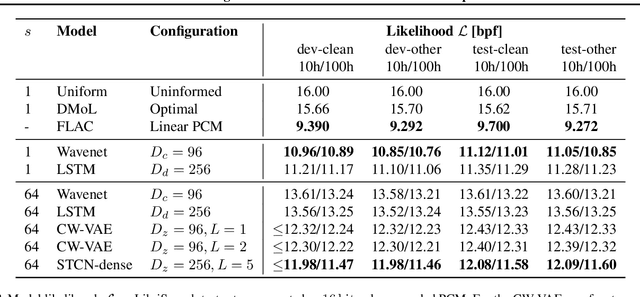
Stochastic latent variable models (LVMs) achieve state-of-the-art performance on natural image generation but are still inferior to deterministic models on speech. In this paper, we develop a speech benchmark of popular temporal LVMs and compare them against state-of-the-art deterministic models. We report the likelihood, which is a much used metric in the image domain, but rarely, or incomparably, reported for speech models. To assess the quality of the learned representations, we also compare their usefulness for phoneme recognition. Finally, we adapt the Clockwork VAE, a state-of-the-art temporal LVM for video generation, to the speech domain. Despite being autoregressive only in latent space, we find that the Clockwork VAE can outperform previous LVMs and reduce the gap to deterministic models by using a hierarchy of latent variables.
Brain Tumor Detection and Classification Using a New Evolutionary Convolutional Neural Network
Apr 26, 2022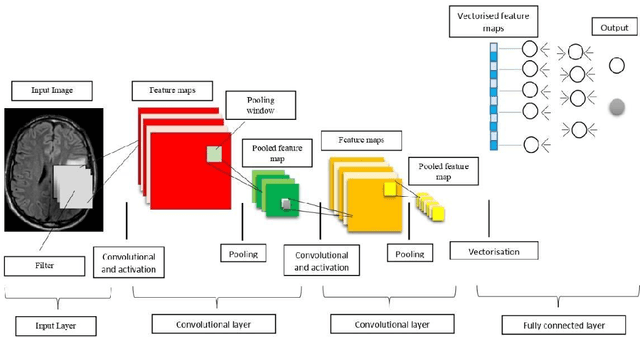
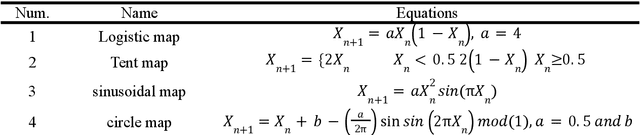

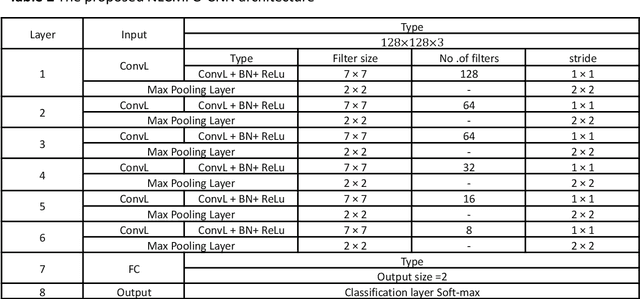
A definitive diagnosis of a brain tumour is essential for enhancing treatment success and patient survival. However, it is difficult to manually evaluate multiple magnetic resonance imaging (MRI) images generated in a clinic. Therefore, more precise computer-based tumour detection methods are required. In recent years, many efforts have investigated classical machine learning methods to automate this process. Deep learning techniques have recently sparked interest as a means of diagnosing brain tumours more accurately and robustly. The goal of this study, therefore, is to employ brain MRI images to distinguish between healthy and unhealthy patients (including tumour tissues). As a result, an enhanced convolutional neural network is developed in this paper for accurate brain image classification. The enhanced convolutional neural network structure is composed of components for feature extraction and optimal classification. Nonlinear L\'evy Chaotic Moth Flame Optimizer (NLCMFO) optimizes hyperparameters for training convolutional neural network layers. Using the BRATS 2015 data set and brain image datasets from Harvard Medical School, the proposed model is assessed and compared with various optimization techniques. The optimized CNN model outperforms other models from the literature by providing 97.4% accuracy, 96.0% sensitivity, 98.6% specificity, 98.4% precision, and 96.6% F1-score, (the mean of the weighted harmonic value of CNN precision and recall).
MedMNIST v2: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification
Oct 27, 2021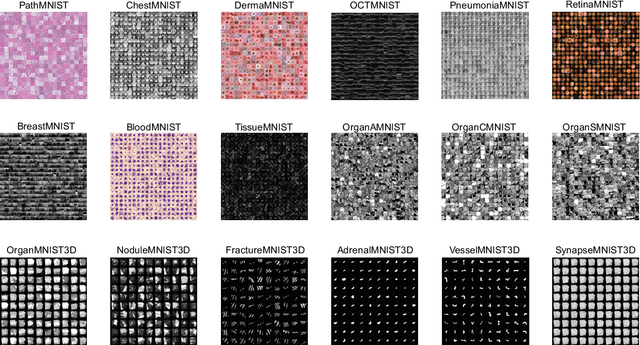

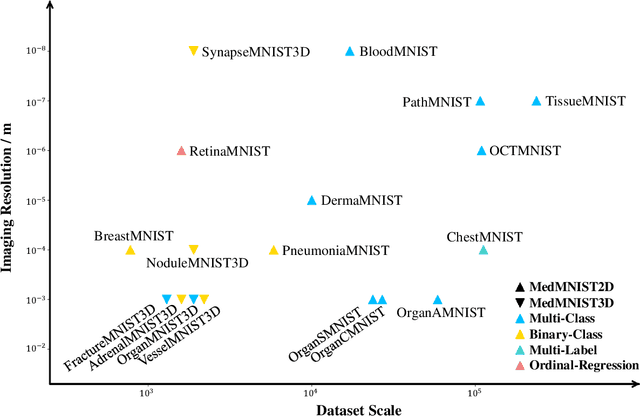
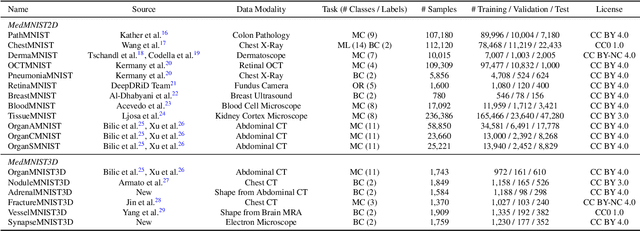
We introduce MedMNIST v2, a large-scale MNIST-like dataset collection of standardized biomedical images, including 12 datasets for 2D and 6 datasets for 3D. All images are pre-processed into a small size of 28x28 (2D) or 28x28x28 (3D) with the corresponding classification labels so that no background knowledge is required for users. Covering primary data modalities in biomedical images, MedMNIST v2 is designed to perform classification on lightweight 2D and 3D images with various dataset scales (from 100 to 100,000) and diverse tasks (binary/multi-class, ordinal regression, and multi-label). The resulting dataset, consisting of 708,069 2D images and 10,214 3D images in total, could support numerous research / educational purposes in biomedical image analysis, computer vision, and machine learning. We benchmark several baseline methods on MedMNIST v2, including 2D / 3D neural networks and open-source / commercial AutoML tools. The data and code are publicly available at https://medmnist.com/.
Swapping Semantic Contents for Mixing Images
May 20, 2022
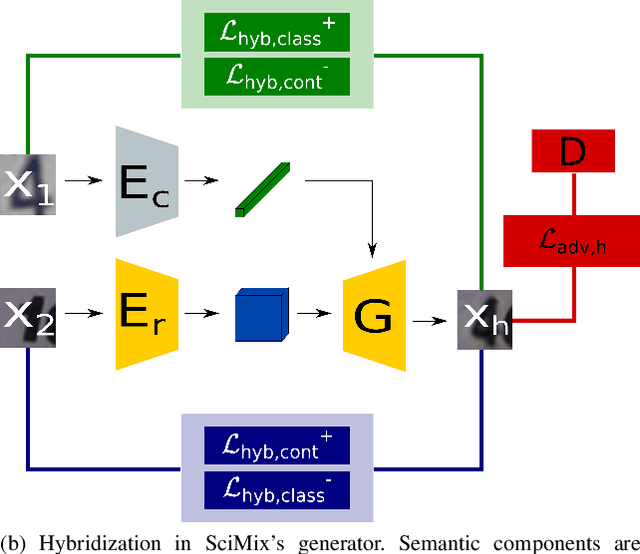


Deep architecture have proven capable of solving many tasks provided a sufficient amount of labeled data. In fact, the amount of available labeled data has become the principal bottleneck in low label settings such as Semi-Supervised Learning. Mixing Data Augmentations do not typically yield new labeled samples, as indiscriminately mixing contents creates between-class samples. In this work, we introduce the SciMix framework that can learn to generator to embed a semantic style code into image backgrounds, we obtain new mixing scheme for data augmentation. We then demonstrate that SciMix yields novel mixed samples that inherit many characteristics from their non-semantic parents. Afterwards, we verify those samples can be used to improve the performance semi-supervised frameworks like Mean Teacher or Fixmatch, and even fully supervised learning on a small labeled dataset.
Patch-level Representation Learning for Self-supervised Vision Transformers
Jun 17, 2022
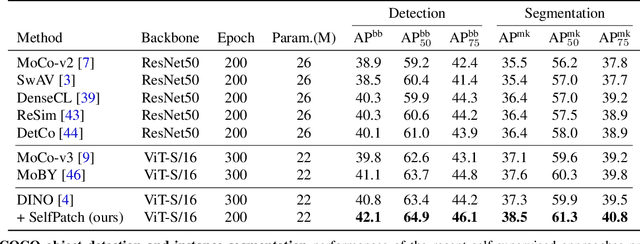
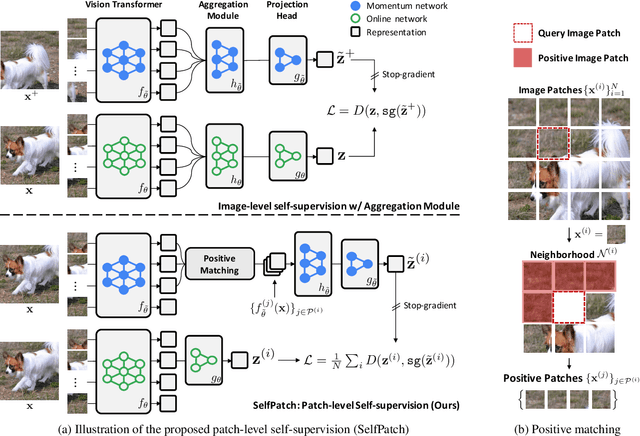
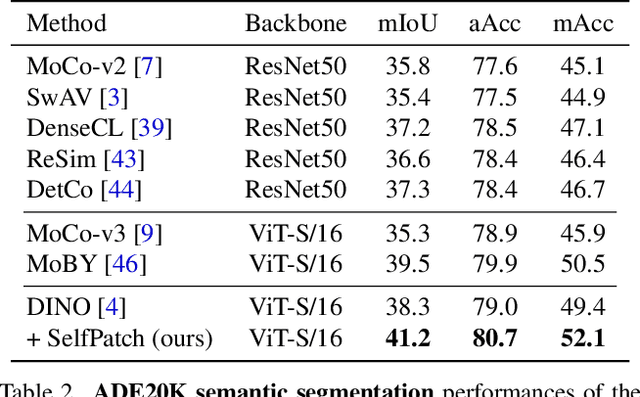
Recent self-supervised learning (SSL) methods have shown impressive results in learning visual representations from unlabeled images. This paper aims to improve their performance further by utilizing the architectural advantages of the underlying neural network, as the current state-of-the-art visual pretext tasks for SSL do not enjoy the benefit, i.e., they are architecture-agnostic. In particular, we focus on Vision Transformers (ViTs), which have gained much attention recently as a better architectural choice, often outperforming convolutional networks for various visual tasks. The unique characteristic of ViT is that it takes a sequence of disjoint patches from an image and processes patch-level representations internally. Inspired by this, we design a simple yet effective visual pretext task, coined SelfPatch, for learning better patch-level representations. To be specific, we enforce invariance against each patch and its neighbors, i.e., each patch treats similar neighboring patches as positive samples. Consequently, training ViTs with SelfPatch learns more semantically meaningful relations among patches (without using human-annotated labels), which can be beneficial, in particular, to downstream tasks of a dense prediction type. Despite its simplicity, we demonstrate that it can significantly improve the performance of existing SSL methods for various visual tasks, including object detection and semantic segmentation. Specifically, SelfPatch significantly improves the recent self-supervised ViT, DINO, by achieving +1.3 AP on COCO object detection, +1.2 AP on COCO instance segmentation, and +2.9 mIoU on ADE20K semantic segmentation.
Image Compression and Classification Using Qubits and Quantum Deep Learning
Oct 08, 2021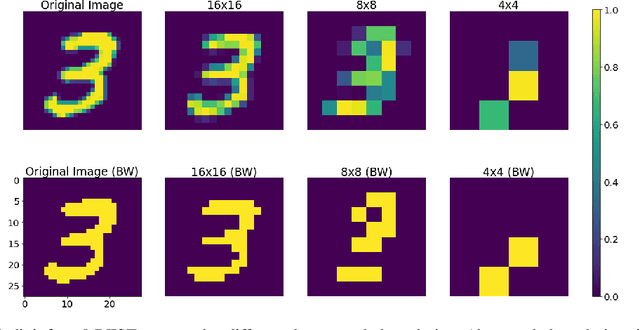
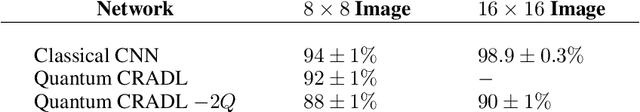

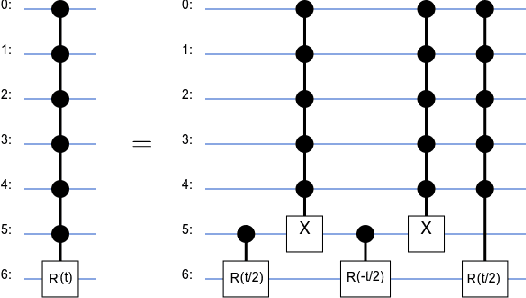
Recent work suggests that quantum machine learning techniques can be used for classical image classification by encoding the images in quantum states and using a quantum neural network for inference. However, such work has been restricted to very small input images, at most 4 x 4, that are unrealistic and cannot even be accurately labeled by humans. The primary difficulties in using larger input images is that hitherto-proposed encoding schemes necessitate more qubits than are physically realizable. We propose a framework to classify larger, realistic images using quantum systems. Our approach relies on a novel encoding mechanism that embeds images in quantum states while necessitating fewer qubits than prior work. Our framework is able to classify images that are larger than previously possible, up to 16 x 16 for the MNIST dataset on a personal laptop, and obtains accuracy comparable to classical neural networks with the same number of learnable parameters. We also propose a technique for further reducing the number of qubits needed to represent images that may result in an easier physical implementation at the expense of final performance. Our work enables quantum machine learning and classification on classical datasets of dimensions that were previously intractable by physically realizable quantum computers or classical simulation
SketchHairSalon: Deep Sketch-based Hair Image Synthesis
Sep 21, 2021
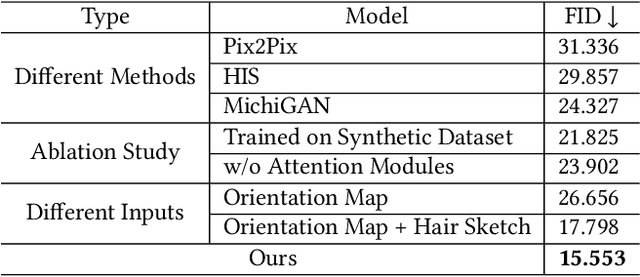
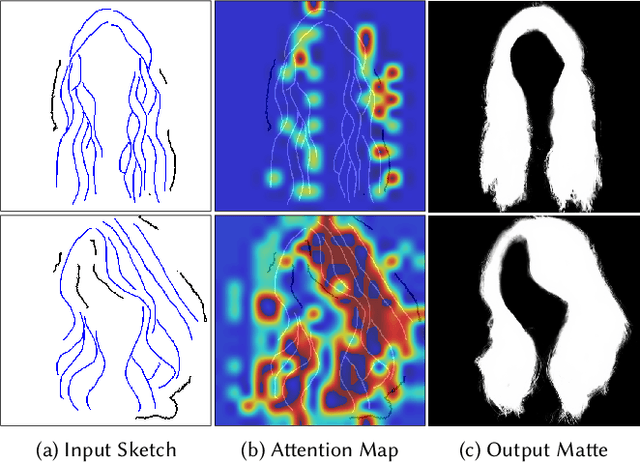
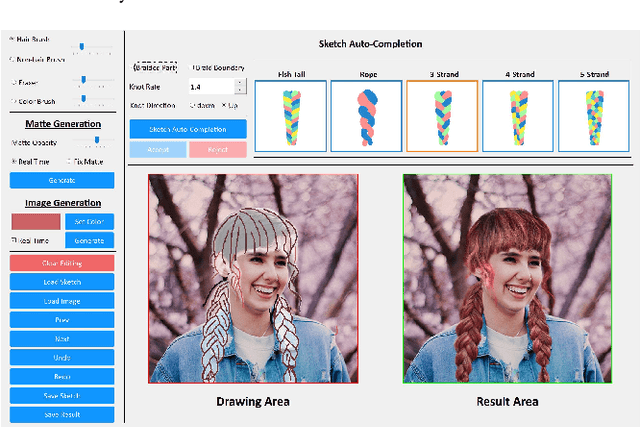
Recent deep generative models allow real-time generation of hair images from sketch inputs. Existing solutions often require a user-provided binary mask to specify a target hair shape. This not only costs users extra labor but also fails to capture complicated hair boundaries. Those solutions usually encode hair structures via orientation maps, which, however, are not very effective to encode complex structures. We observe that colored hair sketches already implicitly define target hair shapes as well as hair appearance and are more flexible to depict hair structures than orientation maps. Based on these observations, we present SketchHairSalon, a two-stage framework for generating realistic hair images directly from freehand sketches depicting desired hair structure and appearance. At the first stage, we train a network to predict a hair matte from an input hair sketch, with an optional set of non-hair strokes. At the second stage, another network is trained to synthesize the structure and appearance of hair images from the input sketch and the generated matte. To make the networks in the two stages aware of long-term dependency of strokes, we apply self-attention modules to them. To train these networks, we present a new dataset containing thousands of annotated hair sketch-image pairs and corresponding hair mattes. Two efficient methods for sketch completion are proposed to automatically complete repetitive braided parts and hair strokes, respectively, thus reducing the workload of users. Based on the trained networks and the two sketch completion strategies, we build an intuitive interface to allow even novice users to design visually pleasing hair images exhibiting various hair structures and appearance via freehand sketches. The qualitative and quantitative evaluations show the advantages of the proposed system over the existing or alternative solutions.
CommerceMM: Large-Scale Commerce MultiModal Representation Learning with Omni Retrieval
Feb 15, 2022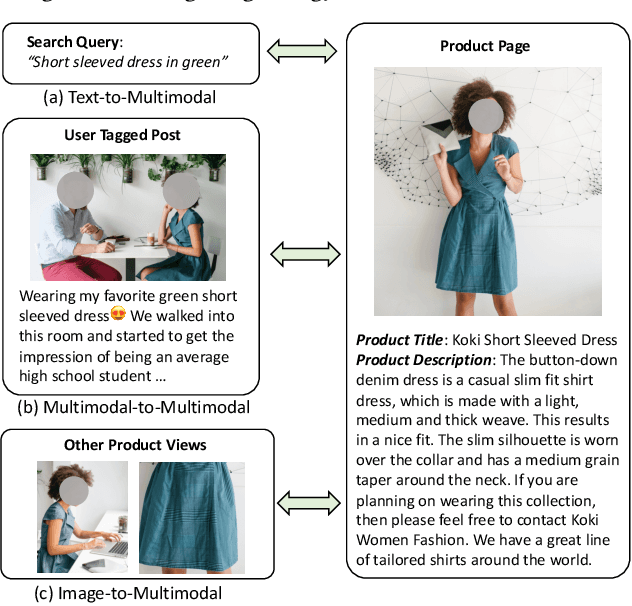
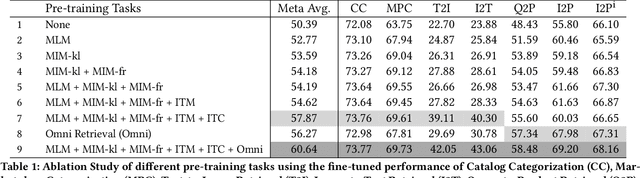
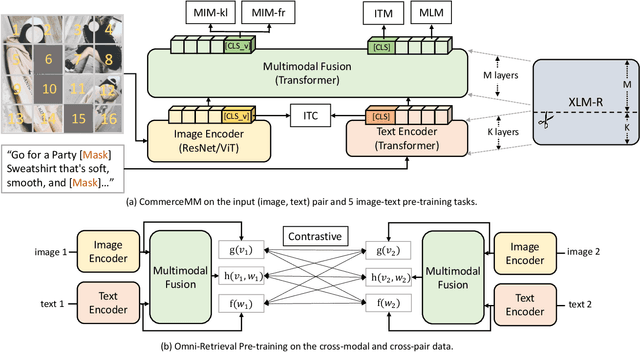

We introduce CommerceMM - a multimodal model capable of providing a diverse and granular understanding of commerce topics associated to the given piece of content (image, text, image+text), and having the capability to generalize to a wide range of tasks, including Multimodal Categorization, Image-Text Retrieval, Query-to-Product Retrieval, Image-to-Product Retrieval, etc. We follow the pre-training + fine-tuning training regime and present 5 effective pre-training tasks on image-text pairs. To embrace more common and diverse commerce data with text-to-multimodal, image-to-multimodal, and multimodal-to-multimodal mapping, we propose another 9 novel cross-modal and cross-pair retrieval tasks, called Omni-Retrieval pre-training. The pre-training is conducted in an efficient manner with only two forward/backward updates for the combined 14 tasks. Extensive experiments and analysis show the effectiveness of each task. When combining all pre-training tasks, our model achieves state-of-the-art performance on 7 commerce-related downstream tasks after fine-tuning. Additionally, we propose a novel approach of modality randomization to dynamically adjust our model under different efficiency constraints.
Large Scale Image Completion via Co-Modulated Generative Adversarial Networks
Mar 18, 2021
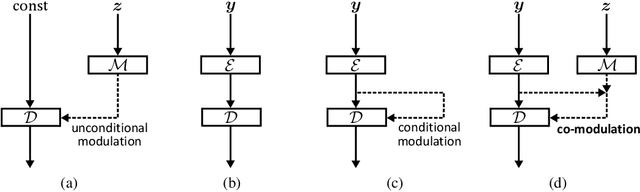

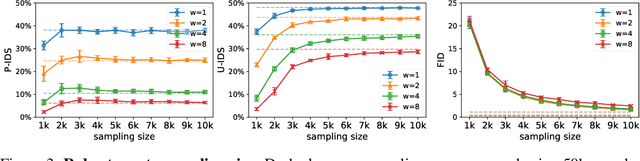
Numerous task-specific variants of conditional generative adversarial networks have been developed for image completion. Yet, a serious limitation remains that all existing algorithms tend to fail when handling large-scale missing regions. To overcome this challenge, we propose a generic new approach that bridges the gap between image-conditional and recent modulated unconditional generative architectures via co-modulation of both conditional and stochastic style representations. Also, due to the lack of good quantitative metrics for image completion, we propose the new Paired/Unpaired Inception Discriminative Score (P-IDS/U-IDS), which robustly measures the perceptual fidelity of inpainted images compared to real images via linear separability in a feature space. Experiments demonstrate superior performance in terms of both quality and diversity over state-of-the-art methods in free-form image completion and easy generalization to image-to-image translation. Code is available at https://github.com/zsyzzsoft/co-mod-gan.