 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Monocular Robot Navigation with Self-Supervised Pretrained Vision Transformers
Mar 07, 2022
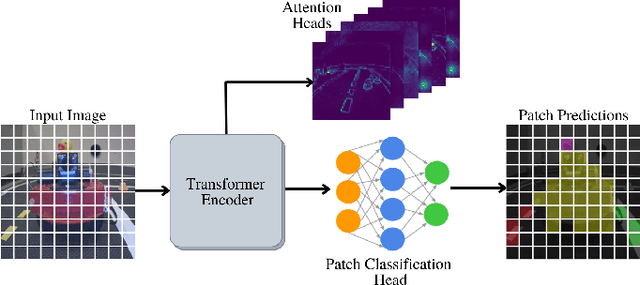

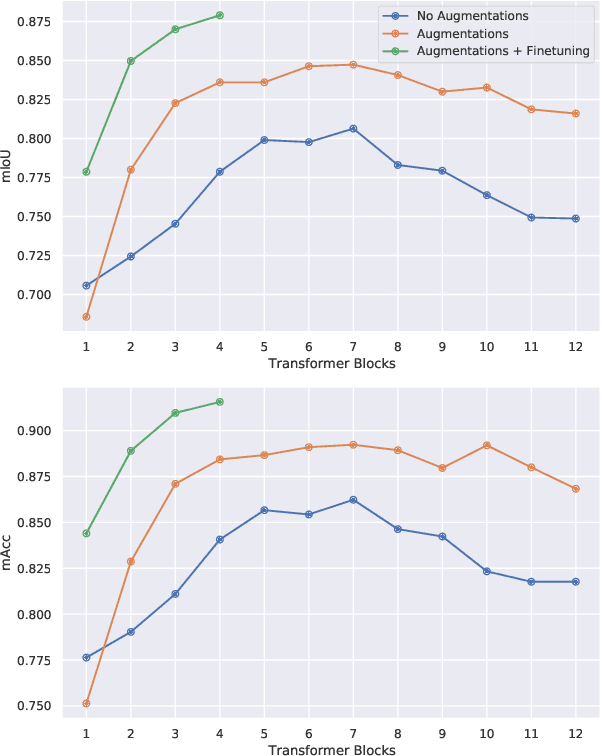

In this work, we consider the problem of learning a perception model for monocular robot navigation using few annotated images. Using a Vision Transformer (ViT) pretrained with a label-free self-supervised method, we successfully train a coarse image segmentation model for the Duckietown environment using 70 training images. Our model performs coarse image segmentation at the 8x8 patch level, and the inference resolution can be adjusted to balance prediction granularity and real-time perception constraints. We study how best to adapt a ViT to our task and environment, and find that some lightweight architectures can yield good single-image segmentations at a usable frame rate, even on CPU. The resulting perception model is used as the backbone for a simple yet robust visual servoing agent, which we deploy on a differential drive mobile robot to perform two tasks: lane following and obstacle avoidance.
OrdinalCLIP: Learning Rank Prompts for Language-Guided Ordinal Regression
Jun 06, 2022
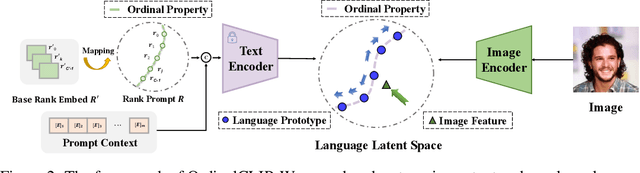
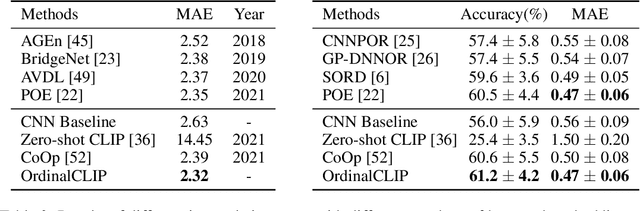
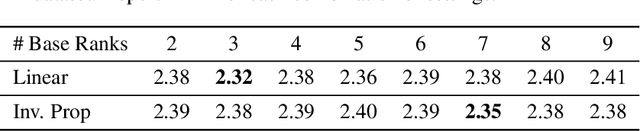
This paper presents a language-powered paradigm for ordinal regression. Existing methods usually treat each rank as a category and employ a set of weights to learn these concepts. These methods are easy to overfit and usually attain unsatisfactory performance as the learned concepts are mainly derived from the training set. Recent large pre-trained vision-language models like CLIP have shown impressive performance on various visual tasks. In this paper, we propose to learn the rank concepts from the rich semantic CLIP latent space. Specifically, we reformulate this task as an image-language matching problem with a contrastive objective, which regards labels as text and obtains a language prototype from a text encoder for each rank. While prompt engineering for CLIP is extremely time-consuming, we propose OrdinalCLIP, a differentiable prompting method for adapting CLIP for ordinal regression. OrdinalCLIP consists of learnable context tokens and learnable rank embeddings; The learnable rank embeddings are constructed by explicitly modeling numerical continuity, resulting in well-ordered, compact language prototypes in the CLIP space. Once learned, we can only save the language prototypes and discard the huge language model, resulting in zero additional computational overhead compared with the linear head counterpart. Experimental results show that our paradigm achieves competitive performance in general ordinal regression tasks, and gains improvements in few-shot and distribution shift settings for age estimation.
Improving the Thermal Infrared Monitoring of Volcanoes: A Deep Learning Approach for Intermittent Image Series
Sep 27, 2021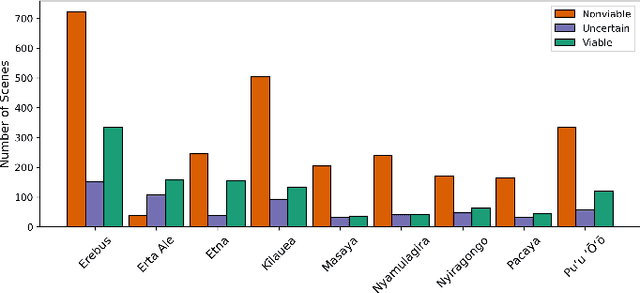
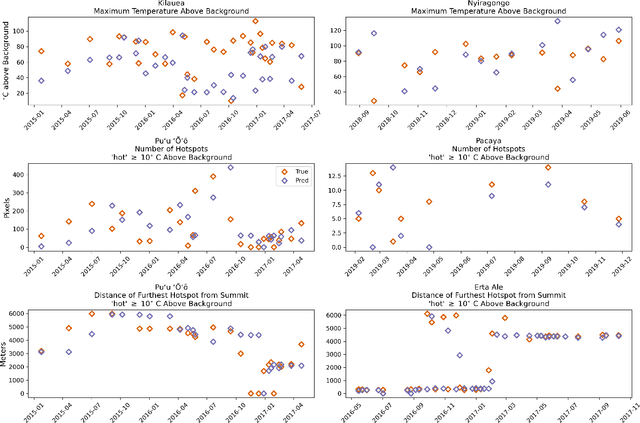
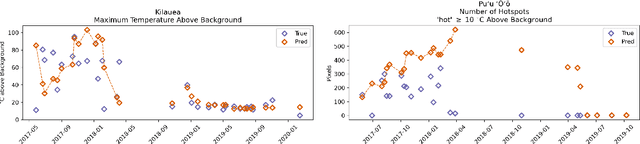

Active volcanoes are globally distributed and pose societal risks at multiple geographic scales, ranging from local hazards to regional/international disruptions. Many volcanoes do not have continuous ground monitoring networks; meaning that satellite observations provide the only record of volcanic behavior and unrest. Among these remote sensing observations, thermal imagery is inspected daily by volcanic observatories for examining the early signs, onset, and evolution of eruptive activity. However, thermal scenes are often obstructed by clouds, meaning that forecasts must be made off image sequences whose scenes are only usable intermittently through time. Here, we explore forecasting this thermal data stream from a deep learning perspective using existing architectures that model sequences with varying spatiotemporal considerations. Additionally, we propose and evaluate new architectures that explicitly model intermittent image sequences. Using ASTER Kinetic Surface Temperature data for $9$ volcanoes between $1999$ and $2020$, we found that a proposed architecture (ConvLSTM + Time-LSTM + U-Net) forecasts volcanic temperature imagery with the lowest RMSE ($4.164^{\circ}$C, other methods: $4.217-5.291^{\circ}$C). Additionally, we examined performance on multiple time series derived from the thermal imagery and the effect of training with data from singular volcanoes. Ultimately, we found that models with the lowest RMSE on forecasting imagery did not possess the lowest RMSE on recreating time series derived from that imagery and that training with individual volcanoes generally worsened performance relative to a multi-volcano data set. This work highlights the potential of data-driven deep learning models for volcanic unrest forecasting while revealing the need for carefully constructed optimization targets.
Convolutional Neural Network to Restore Low-Dose Digital Breast Tomosynthesis Projections in a Variance Stabilization Domain
Mar 22, 2022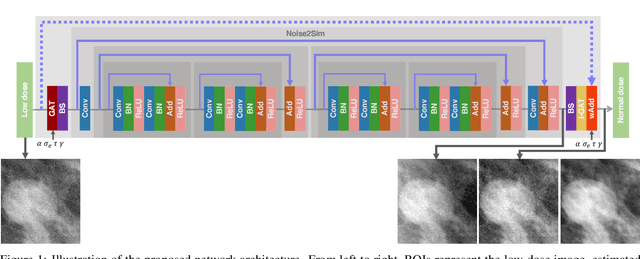
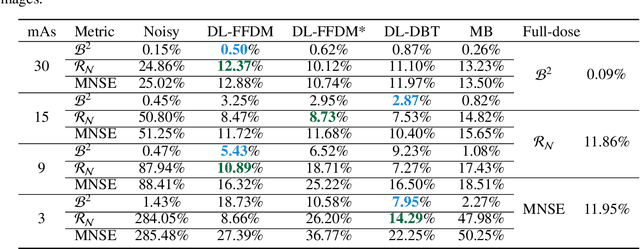

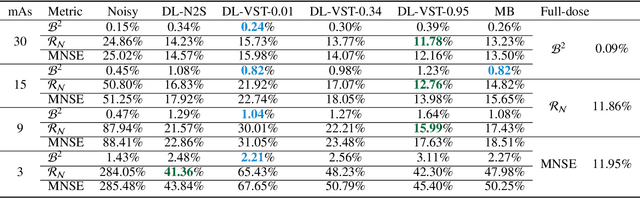
Digital breast tomosynthesis (DBT) exams should utilize the lowest possible radiation dose while maintaining sufficiently good image quality for accurate medical diagnosis. In this work, we propose a convolution neural network (CNN) to restore low-dose (LD) DBT projections to achieve an image quality equivalent to a standard full-dose (FD) acquisition. The proposed network architecture benefits from priors in terms of layers that were inspired by traditional model-based (MB) restoration methods, considering a model-based deep learning approach, where the network is trained to operate in the variance stabilization transformation (VST) domain. To accurately control the network operation point, in terms of noise and blur of the restored image, we propose a loss function that minimizes the bias and matches residual noise between the input and the output. The training dataset was composed of clinical data acquired at the standard FD and low-dose pairs obtained by the injection of quantum noise. The network was tested using real DBT projections acquired with a physical anthropomorphic breast phantom. The proposed network achieved superior results in terms of the mean normalized squared error (MNSE), training time and noise spatial correlation compared with networks trained with traditional data-driven methods. The proposed approach can be extended for other medical imaging application that requires LD acquisitions.
Paying Attention to Multiscale Feature Maps in Multimodal Image Matching
Mar 20, 2021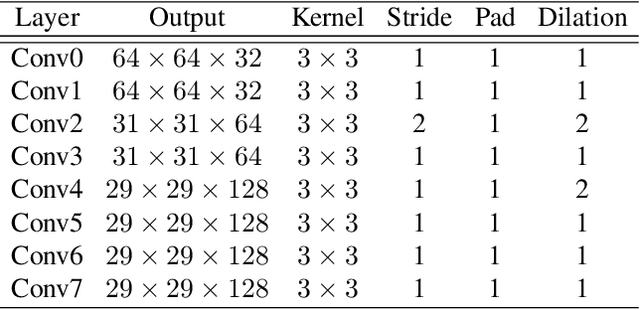
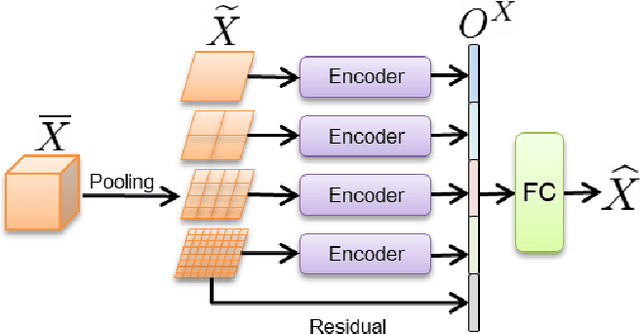
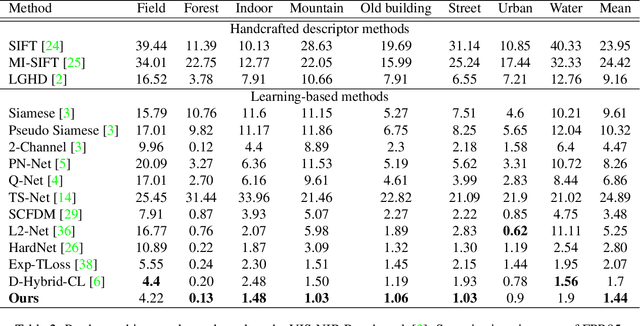
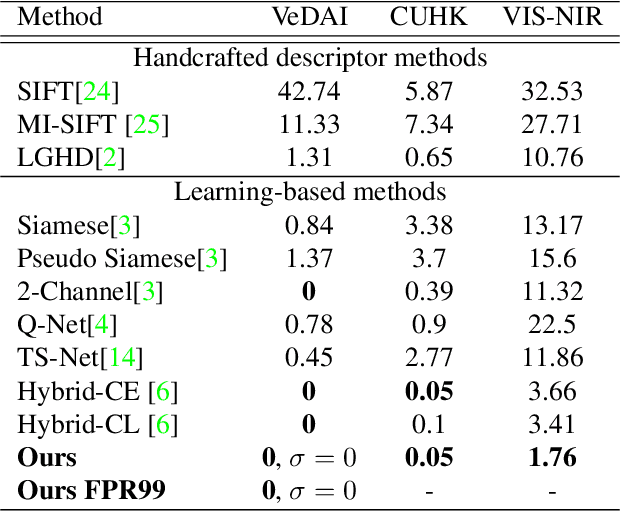
We propose an attention-based approach for multimodal image patch matching using a Transformer encoder attending to the feature maps of a multiscale Siamese CNN. Our encoder is shown to efficiently aggregate multiscale image embeddings while emphasizing task-specific appearance-invariant image cues. We also introduce an attention-residual architecture, using a residual connection bypassing the encoder. This additional learning signal facilitates end-to-end training from scratch. Our approach is experimentally shown to achieve new state-of-the-art accuracy on both multimodal and single modality benchmarks, illustrating its general applicability. To the best of our knowledge, this is the first successful implementation of the Transformer encoder architecture to the multimodal image patch matching task.
InDistill: Transferring Knowledge From Pruned Intermediate Layers
May 20, 2022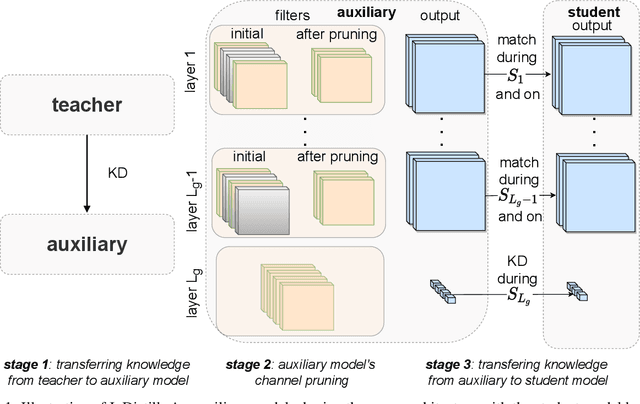
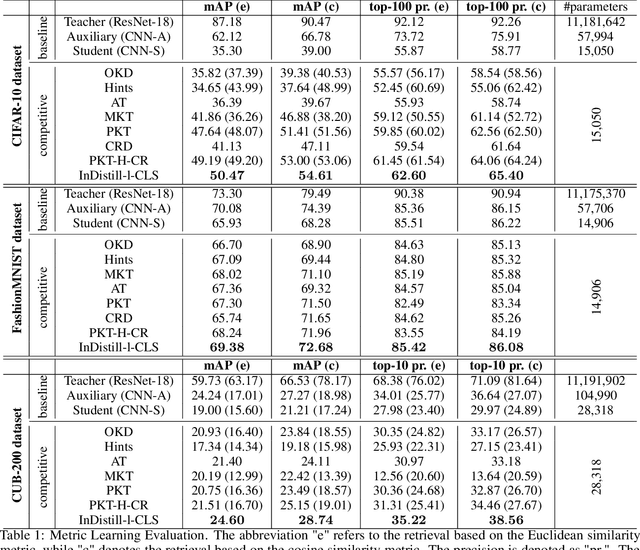
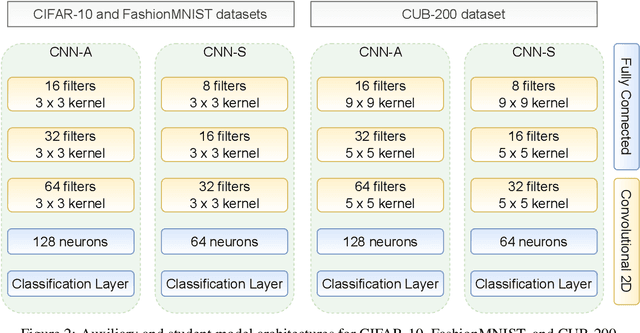
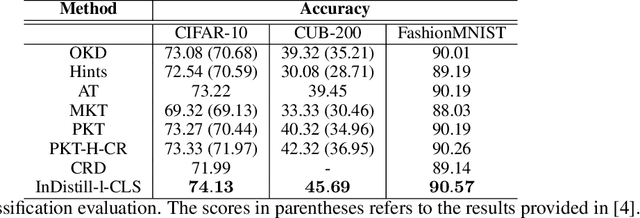
Deploying deep neural networks on hardware with limited resources, such as smartphones and drones, constitutes a great challenge due to their computational complexity. Knowledge distillation approaches aim at transferring knowledge from a large model to a lightweight one, also known as teacher and student respectively, while distilling the knowledge from intermediate layers provides an additional supervision to that task. The capacity gap between the models, the information encoding that collapses its architectural alignment, and the absence of appropriate learning schemes for transferring multiple layers restrict the performance of existing methods. In this paper, we propose a novel method, termed InDistill, that can drastically improve the performance of existing single-layer knowledge distillation methods by leveraging the properties of channel pruning to both reduce the capacity gap between the models and retain the architectural alignment. Furthermore, we propose a curriculum learning based scheme for enhancing the effectiveness of transferring knowledge from multiple intermediate layers. The proposed method surpasses state-of-the-art performance on three benchmark image datasets.
Planning with Diffusion for Flexible Behavior Synthesis
May 20, 2022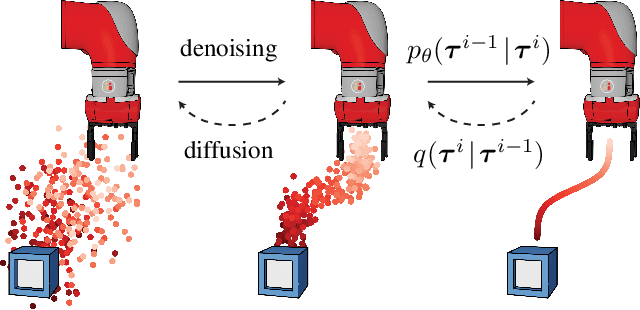
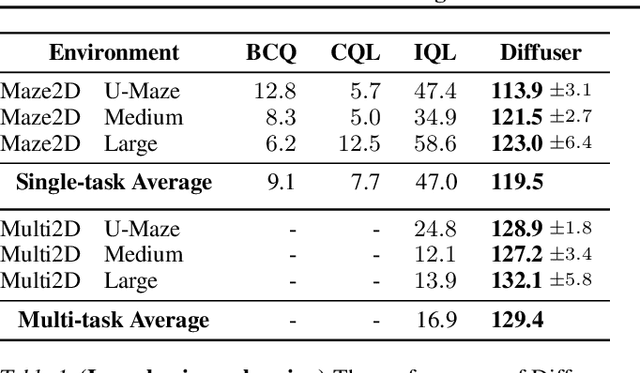
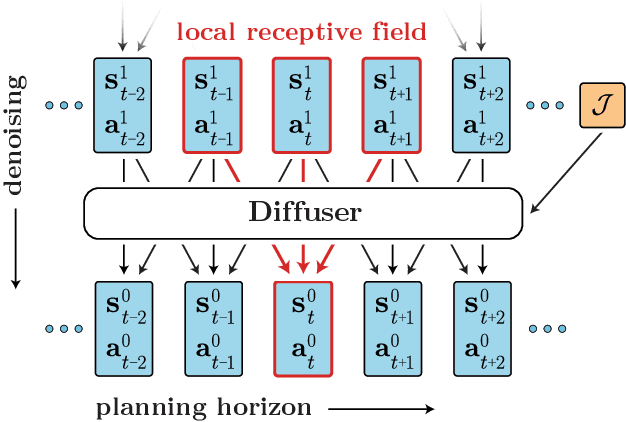
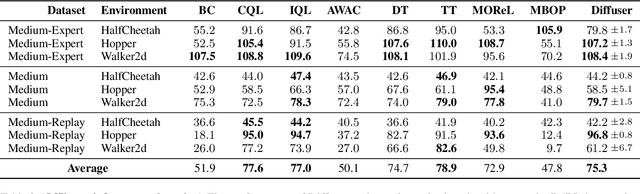
Model-based reinforcement learning methods often use learning only for the purpose of estimating an approximate dynamics model, offloading the rest of the decision-making work to classical trajectory optimizers. While conceptually simple, this combination has a number of empirical shortcomings, suggesting that learned models may not be well-suited to standard trajectory optimization. In this paper, we consider what it would look like to fold as much of the trajectory optimization pipeline as possible into the modeling problem, such that sampling from the model and planning with it become nearly identical. The core of our technical approach lies in a diffusion probabilistic model that plans by iteratively denoising trajectories. We show how classifier-guided sampling and image inpainting can be reinterpreted as coherent planning strategies, explore the unusual and useful properties of diffusion-based planning methods, and demonstrate the effectiveness of our framework in control settings that emphasize long-horizon decision-making and test-time flexibility.
Improving Monocular Visual Odometry Using Learned Depth
Apr 04, 2022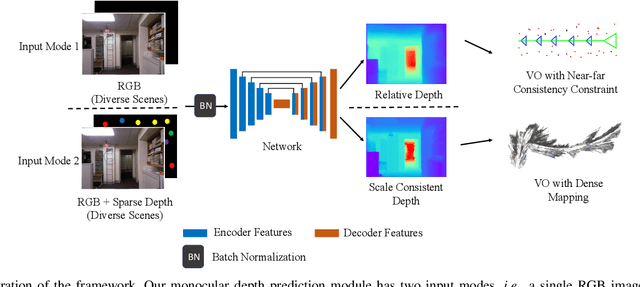
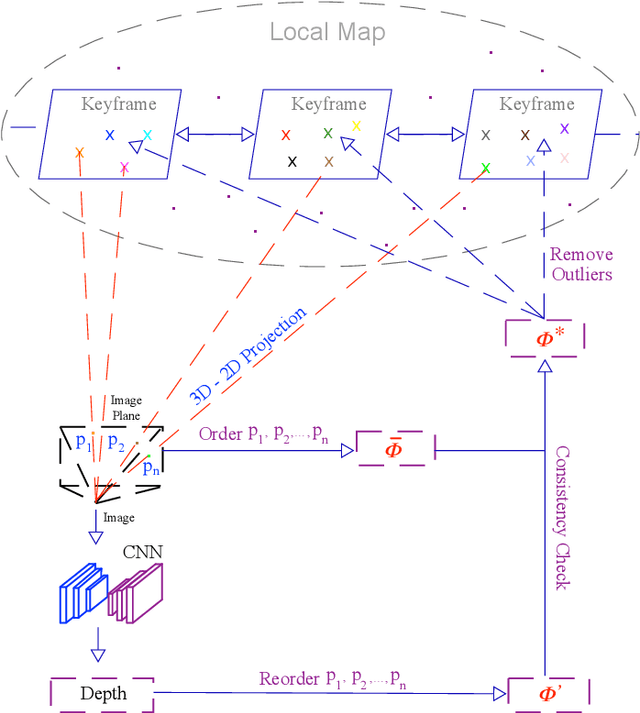
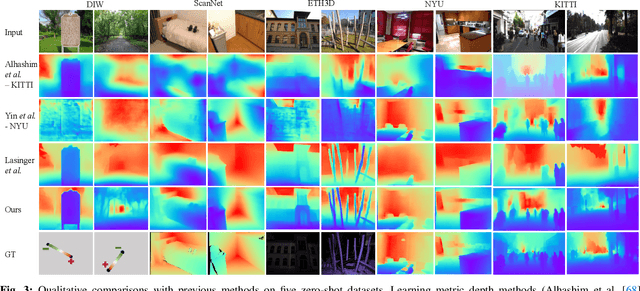
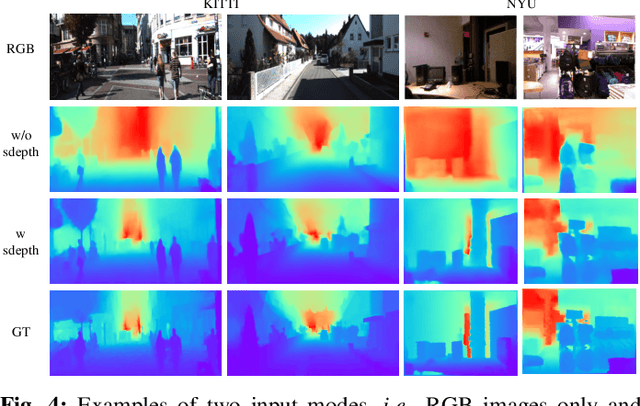
Monocular visual odometry (VO) is an important task in robotics and computer vision. Thus far, how to build accurate and robust monocular VO systems that can work well in diverse scenarios remains largely unsolved. In this paper, we propose a framework to exploit monocular depth estimation for improving VO. The core of our framework is a monocular depth estimation module with a strong generalization capability for diverse scenes. It consists of two separate working modes to assist the localization and mapping. With a single monocular image input, the depth estimation module predicts a relative depth to help the localization module on improving the accuracy. With a sparse depth map and an RGB image input, the depth estimation module can generate accurate scale-consistent depth for dense mapping. Compared with current learning-based VO methods, our method demonstrates a stronger generalization ability to diverse scenes. More significantly, our framework is able to boost the performances of existing geometry-based VO methods by a large margin.
xView3-SAR: Detecting Dark Fishing Activity Using Synthetic Aperture Imagery
Jun 02, 2022
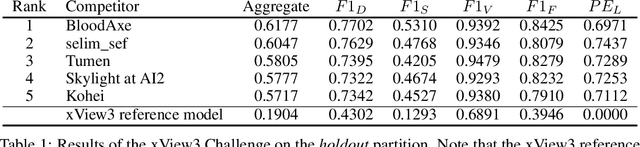

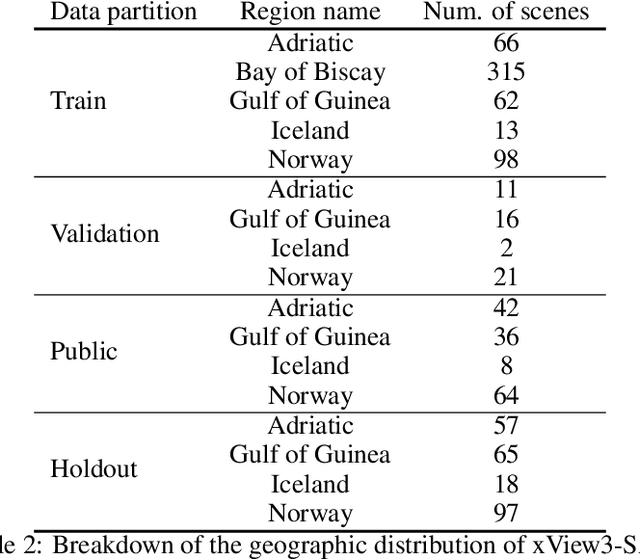
Unsustainable fishing practices worldwide pose a major threat to marine resources and ecosystems. Identifying vessels that evade monitoring systems -- known as "dark vessels" -- is key to managing and securing the health of marine environments. With the rise of satellite-based synthetic aperture radar (SAR) imaging and modern machine learning (ML), it is now possible to automate detection of dark vessels day or night, under all-weather conditions. SAR images, however, require domain-specific treatment and is not widely accessible to the ML community. Moreover, the objects (vessels) are small and sparse, challenging traditional computer vision approaches. We present the largest labeled dataset for training ML models to detect and characterize vessels from SAR. xView3-SAR consists of nearly 1,000 analysis-ready SAR images from the Sentinel-1 mission that are, on average, 29,400-by-24,400 pixels each. The images are annotated using a combination of automated and manual analysis. Co-located bathymetry and wind state rasters accompany every SAR image. We provide an overview of the results from the xView3 Computer Vision Challenge, an international competition using xView3-SAR for ship detection and characterization at large scale. We release the data (https://iuu.xview.us/) and code (https://github.com/DIUx-xView) to support ongoing development and evaluation of ML approaches for this important application.
Unsupervised Segmentation in Real-World Images via Spelke Object Inference
May 17, 2022
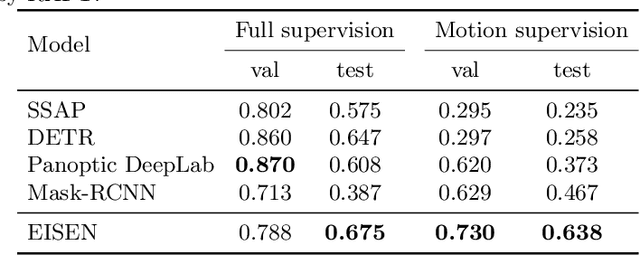
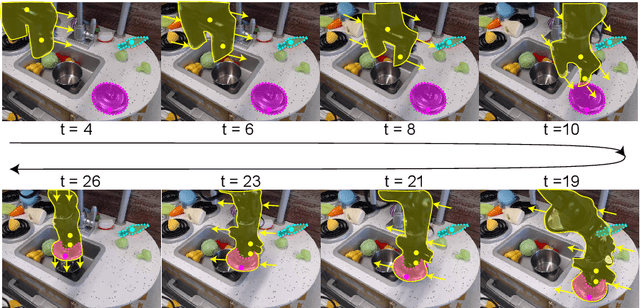

Self-supervised category-agnostic segmentation of real-world images into objects is a challenging open problem in computer vision. Here, we show how to learn static grouping priors from motion self-supervision, building on the cognitive science notion of Spelke Objects: groupings of stuff that move together. We introduce Excitatory-Inhibitory Segment Extraction Network (EISEN), which learns from optical flow estimates to extract pairwise affinity graphs for static scenes. EISEN then produces segments from affinities using a novel graph propagation and competition mechanism. Correlations between independent sources of motion (e.g. robot arms) and objects they move are resolved into separate segments through a bootstrapping training process. We show that EISEN achieves a substantial improvement in the state of the art for self-supervised segmentation on challenging synthetic and real-world robotic image datasets. We also present an ablation analysis illustrating the importance of each element of the EISEN architecture.