 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Series Photo Selection via Multi-view Graph Learning
Mar 18, 2022

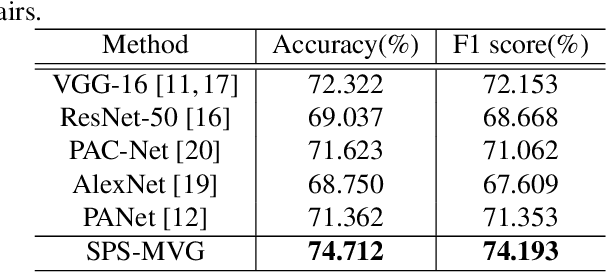
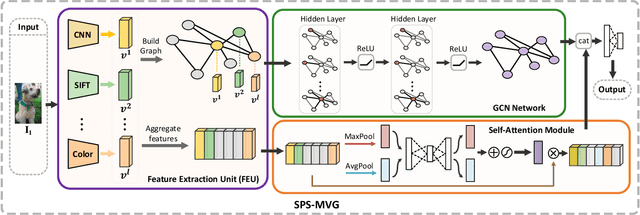
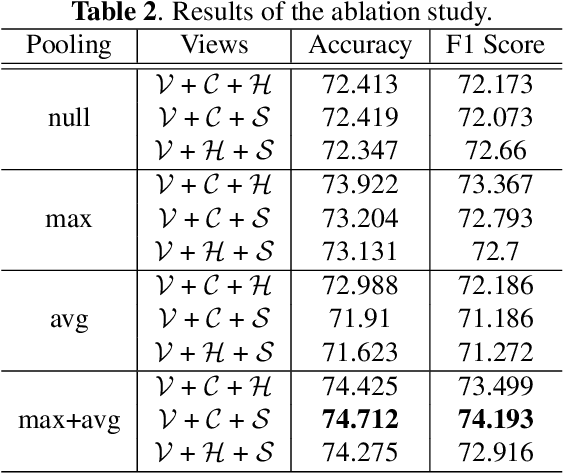
Series photo selection (SPS) is an important branch of the image aesthetics quality assessment, which focuses on finding the best one from a series of nearly identical photos. While a great progress has been observed, most of the existing SPS approaches concentrate solely on extracting features from the original image, neglecting that multiple views, e.g, saturation level, color histogram and depth of field of the image, will be of benefit to successfully reflecting the subtle aesthetic changes. Taken multi-view into consideration, we leverage a graph neural network to construct the relationships between multi-view features. Besides, multiple views are aggregated with an adaptive-weight self-attention module to verify the significance of each view. Finally, a siamese network is proposed to select the best one from a series of nearly identical photos. Experimental results demonstrate that our model accomplish the highest success rates compared with competitive methods.
Exploiting Correspondences with All-pairs Correlations for Multi-view Depth Estimation
May 05, 2022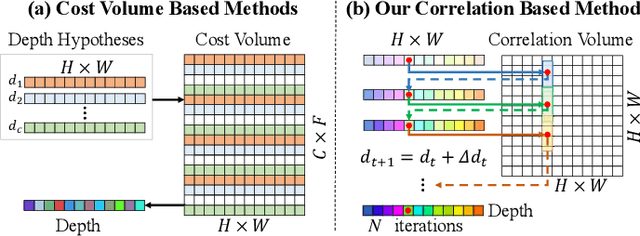
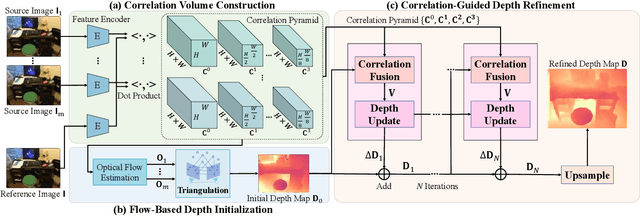
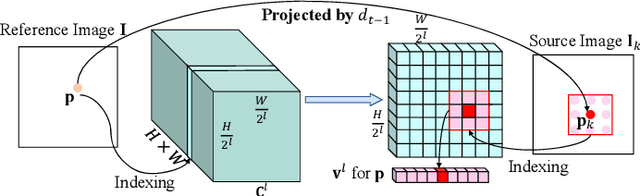
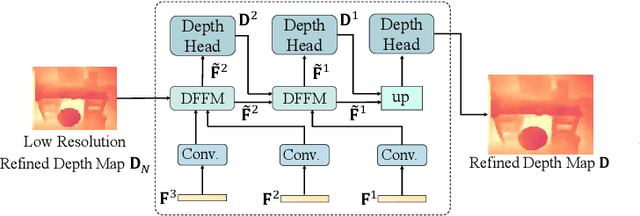
Multi-view depth estimation plays a critical role in reconstructing and understanding the 3D world. Recent learning-based methods have made significant progress in it. However, multi-view depth estimation is fundamentally a correspondence-based optimization problem, but previous learning-based methods mainly rely on predefined depth hypotheses to build correspondence as the cost volume and implicitly regularize it to fit depth prediction, deviating from the essence of iterative optimization based on stereo correspondence. Thus, they suffer unsatisfactory precision and generalization capability. In this paper, we are the first to explore more general image correlations to establish correspondences dynamically for depth estimation. We design a novel iterative multi-view depth estimation framework mimicking the optimization process, which consists of 1) a correlation volume construction module that models the pixel similarity between a reference image and source images as all-to-all correlations; 2) a flow-based depth initialization module that estimates the depth from the 2D optical flow; 3) a novel correlation-guided depth refinement module that reprojects points in different views to effectively fetch relevant correlations for further fusion and integrate the fused correlation for iterative depth update. Without predefined depth hypotheses, the fused correlations establish multi-view correspondence in an efficient way and guide the depth refinement heuristically. We conduct sufficient experiments on ScanNet, DeMoN, ETH3D, and 7Scenes to demonstrate the superiority of our method on multi-view depth estimation and its best generalization ability.
CRISPnet: Color Rendition ISP Net
Mar 22, 2022
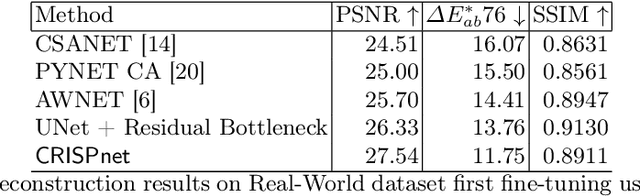
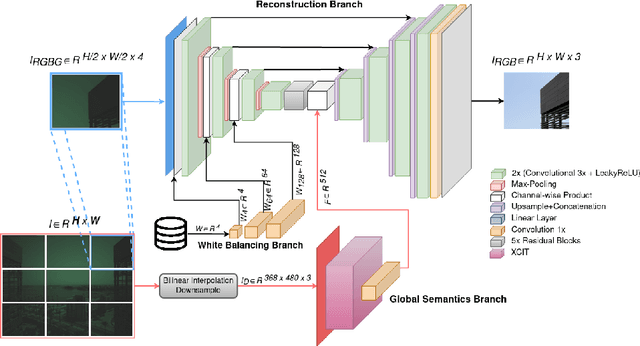
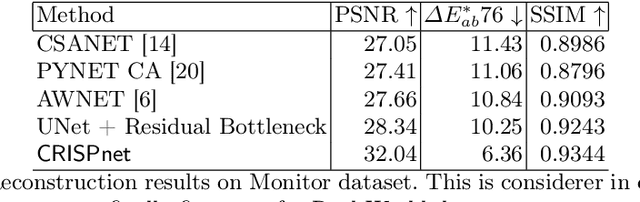
Image signal processors (ISPs) are historically grown legacy software systems for reconstructing color images from noisy raw sensor measurements. They are usually composited of many heuristic blocks for denoising, demosaicking, and color restoration. Color reproduction in this context is of particular importance, since the raw colors are often severely distorted, and each smart phone manufacturer has developed their own characteristic heuristics for improving the color rendition, for example of skin tones and other visually important colors. In recent years there has been strong interest in replacing the historically grown ISP systems with deep learned pipelines. Much progress has been made in approximating legacy ISPs with such learned models. However, so far the focus of these efforts has been on reproducing the structural features of the images, with less attention paid to color rendition. Here we present CRISPnet, the first learned ISP model to specifically target color rendition accuracy relative to a complex, legacy smart phone ISP. We achieve this by utilizing both image metadata (like a legacy ISP would), as well as by learning simple global semantics based on image classification -- similar to what a legacy ISP does to determine the scene type. We also contribute a new ISP image dataset consisting of both high dynamic range monitor data, as well as real-world data, both captured with an actual cell phone ISP pipeline under a variety of lighting conditions, exposure times, and gain settings.
Differentiable Microscopy for Content and Task Aware Compressive Fluorescence Imaging
Mar 28, 2022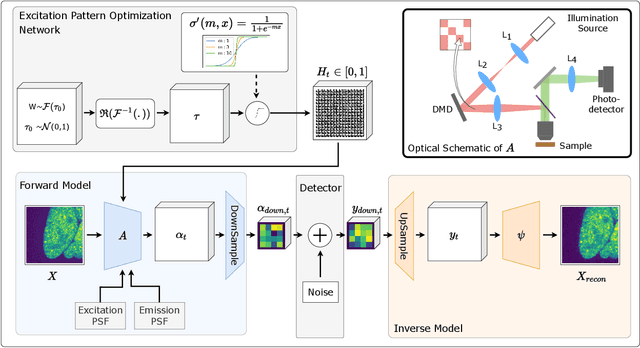

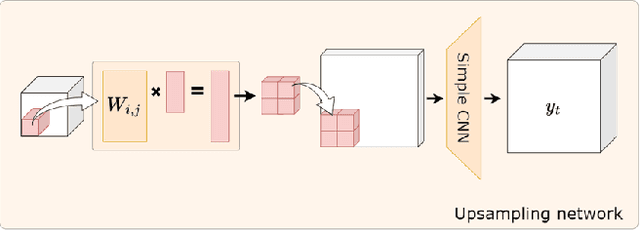
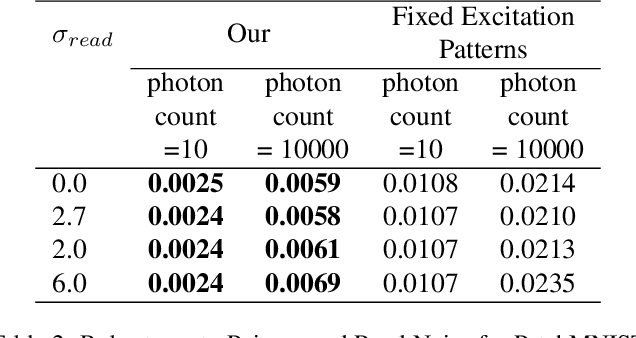
The trade-off between throughput and image quality is an inherent challenge in microscopy. To improve throughput, compressive imaging under-samples image signals; the images are then computationally reconstructed by solving a regularized inverse problem. Compared to traditional regularizers, Deep Learning based methods have achieved greater success in compression and image quality. However, the information loss in the acquisition process sets the compression bounds. Further improvement in compression, without compromising the reconstruction quality is thus a challenge. In this work, we propose differentiable compressive fluorescence microscopy ($\partial \mu$) which includes a realistic generalizable forward model with learnable-physical parameters (e.g. illumination patterns), and a novel physics-inspired inverse model. The cascaded model is end-to-end differentiable and can learn optimal compressive sampling schemes through training data. With our model, we performed thousands of numerical experiments on various compressive microscope configurations. Our results suggest that learned sampling outperforms widely used traditional compressive sampling schemes at higher compressions ($\times 100- 1000$) in terms of reconstruction quality. We further utilize our framework for Task Aware Compression. The experimental results show superior performance on segmentation tasks even at extremely high compression ($\times 4096$).
Deep Learning for Computational Cytology: A Survey
Feb 16, 2022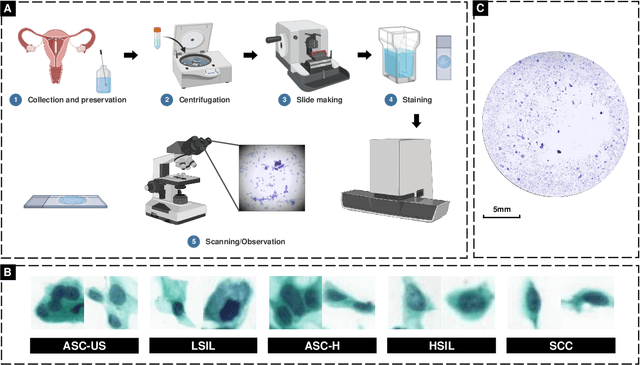
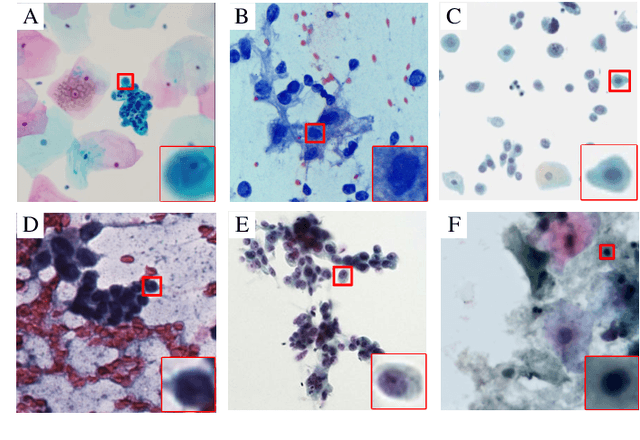
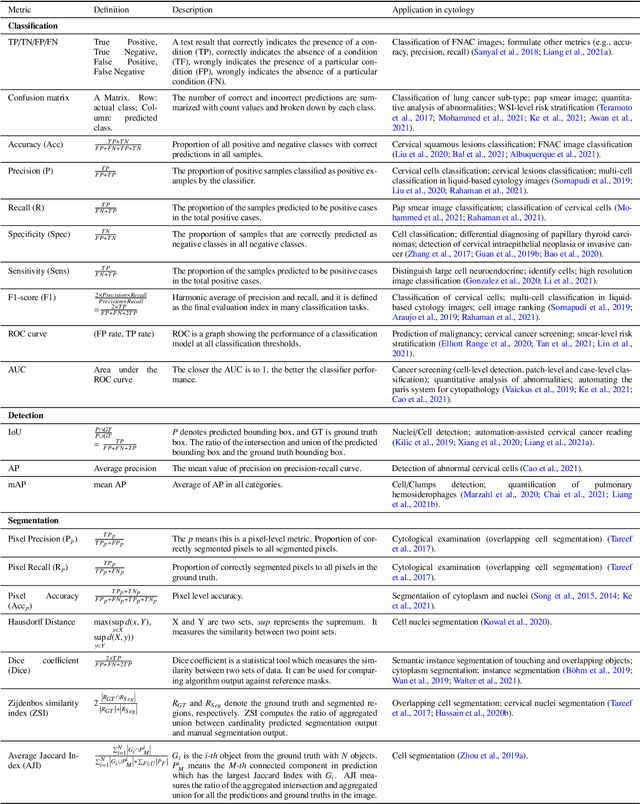
Computational cytology is a critical, rapid-developing, yet challenging topic in the field of medical image computing which analyzes the digitized cytology image by computer-aided technologies for cancer screening. Recently, an increasing number of deep learning (DL) algorithms have made significant progress in medical image analysis, leading to the boosting publications of cytological studies. To investigate the advanced methods and comprehensive applications, we survey more than 120 publications of DL-based cytology image analysis in this article. We first introduce various deep learning methods, including fully supervised, weakly supervised, unsupervised, and transfer learning. Then, we systematically summarize the public datasets, evaluation metrics, versatile cytology image analysis applications including classification, detection, segmentation, and other related tasks. Finally, we discuss current challenges and potential research directions of computational cytology.
Image Augmentation Using a Task Guided Generative Adversarial Network for Age Estimation on Brain MRI
Aug 03, 2021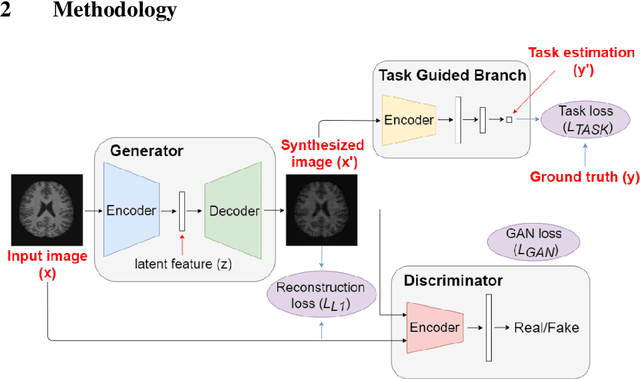

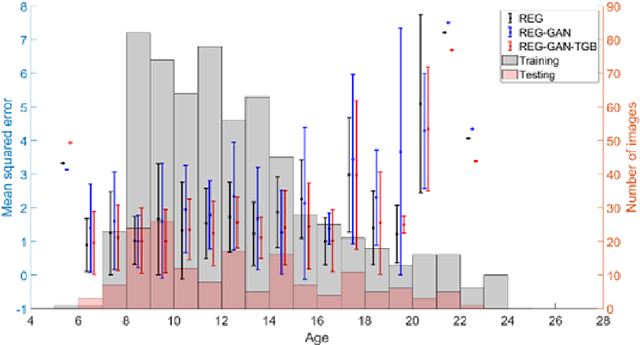
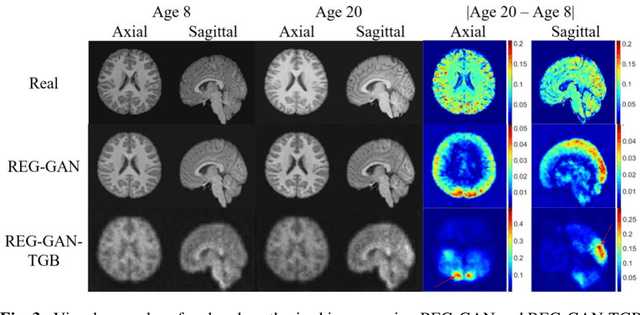
Brain age estimation based on magnetic resonance imaging (MRI) is an active research area in early diagnosis of some neurodegenerative diseases (e.g. Alzheimer, Parkinson, Huntington, etc.) for elderly people or brain underdevelopment for the young group. Deep learning methods have achieved the state-of-the-art performance in many medical image analysis tasks, including brain age estimation. However, the performance and generalisability of the deep learning model are highly dependent on the quantity and quality of the training data set. Both collecting and annotating brain MRI data are extremely time-consuming. In this paper, to overcome the data scarcity problem, we propose a generative adversarial network (GAN) based image synthesis method. Different from the existing GAN-based methods, we integrate a task-guided branch (a regression model for age estimation) to the end of the generator in GAN. By adding a task-guided loss to the conventional GAN loss, the learned low-dimensional latent space and the synthesised images are more task-specific. It helps to boost the performance of the down-stream task by combining the synthesised images and real images for model training. The proposed method was evaluated on a public brain MRI data set for age estimation. Our proposed method outperformed (statistically significant) a deep convolutional neural network based regression model and the GAN-based image synthesis method without the task-guided branch. More importantly, it enables the identification of age-related brain regions in the image space. The code is available on GitHub (https://github.com/ruizhe-l/tgb-gan).
Learned Image Compression with Discretized Gaussian-Laplacian-Logistic Mixture Model and Concatenated Residual Modules
Jul 14, 2021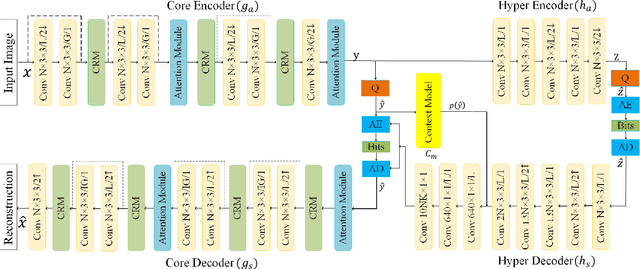
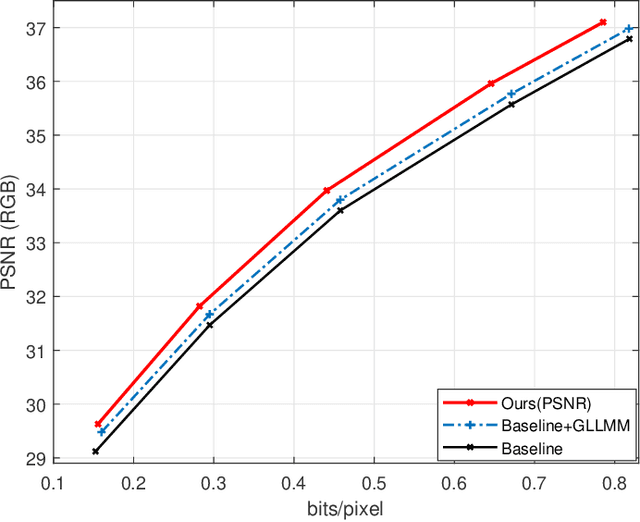
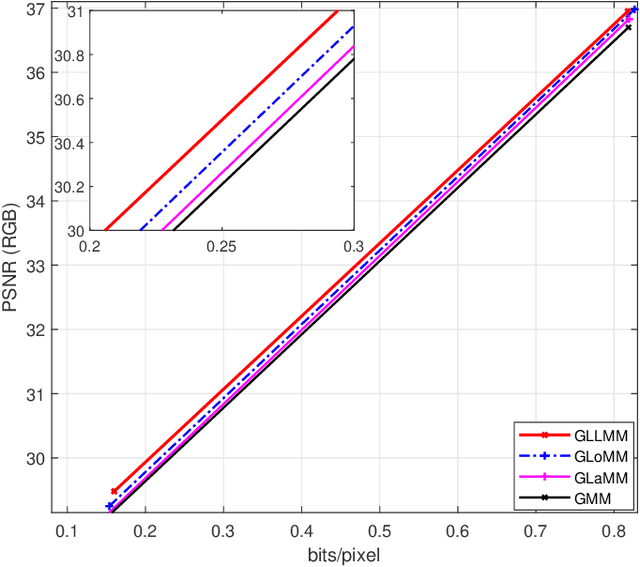
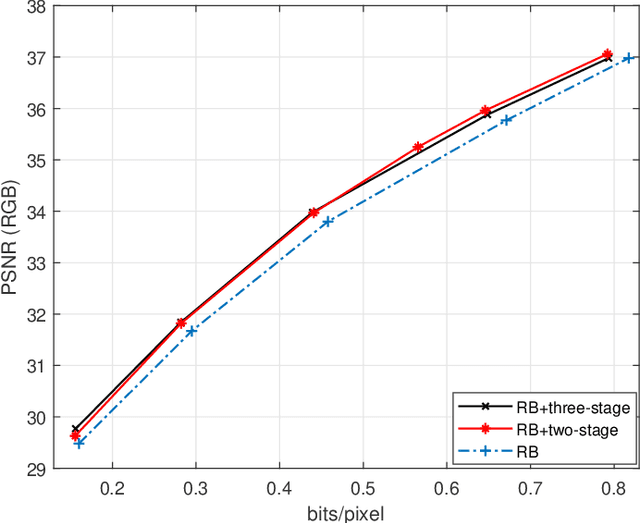
Recently deep learning-based image compression methods have achieved significant achievements and gradually outperformed traditional approaches including the latest standard Versatile Video Coding (VVC) in both PSNR and MS-SSIM metrics. Two key components of learned image compression frameworks are the entropy model of the latent representations and the encoding/decoding network architectures. Various models have been proposed, such as autoregressive, softmax, logistic mixture, Gaussian mixture, and Laplacian. Existing schemes only use one of these models. However, due to the vast diversity of images, it is not optimal to use one model for all images, even different regions of one image. In this paper, we propose a more flexible discretized Gaussian-Laplacian-Logistic mixture model (GLLMM) for the latent representations, which can adapt to different contents in different images and different regions of one image more accurately. Besides, in the encoding/decoding network design part, we propose a concatenated residual blocks (CRB), where multiple residual blocks are serially connected with additional shortcut connections. The CRB can improve the learning ability of the network, which can further improve the compression performance. Experimental results using the Kodak and Tecnick datasets show that the proposed scheme outperforms all the state-of-the-art learning-based methods and existing compression standards including VVC intra coding (4:4:4 and 4:2:0) in terms of the PSNR and MS-SSIM.
A case for using rotation invariant features in state of the art feature matchers
Apr 21, 2022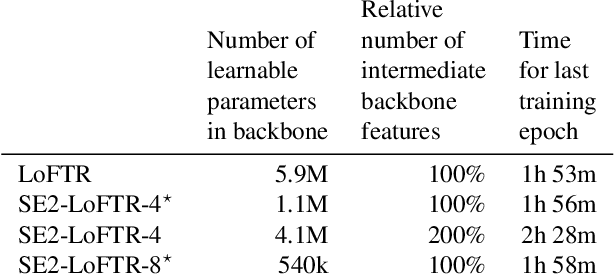

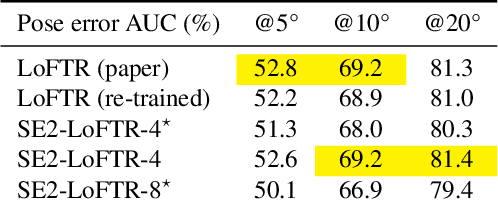
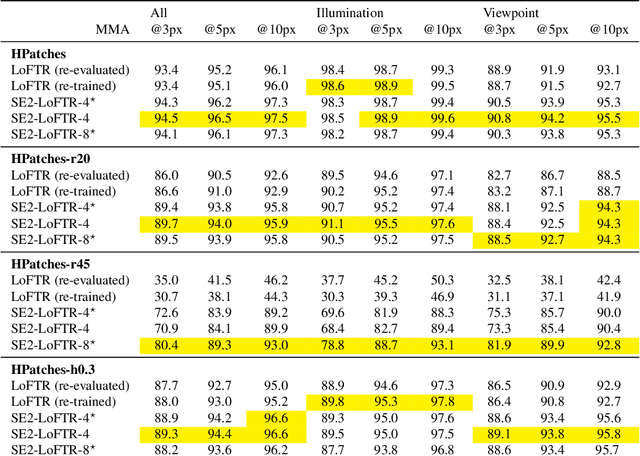
The aim of this paper is to demonstrate that a state of the art feature matcher (LoFTR) can be made more robust to rotations by simply replacing the backbone CNN with a steerable CNN which is equivariant to translations and image rotations. It is experimentally shown that this boost is obtained without reducing performance on ordinary illumination and viewpoint matching sequences.
Pruning-as-Search: Efficient Neural Architecture Search via Channel Pruning and Structural Reparameterization
Jun 02, 2022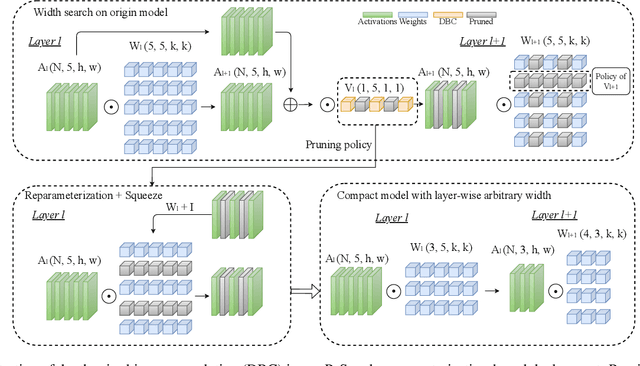
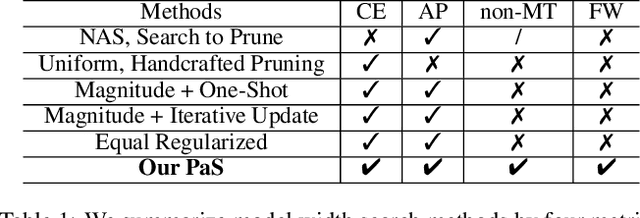

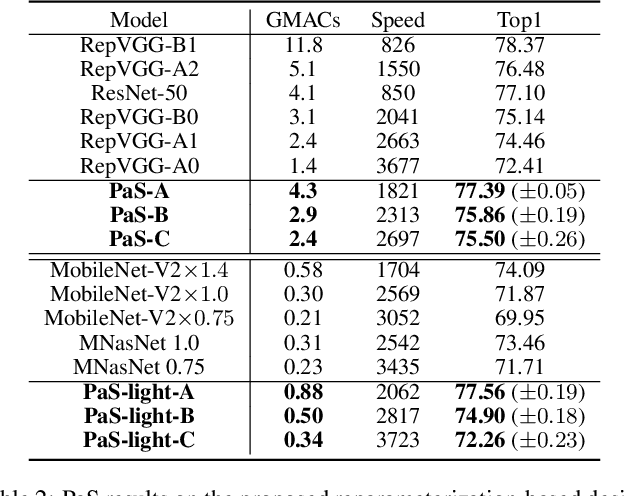
Neural architecture search (NAS) and network pruning are widely studied efficient AI techniques, but not yet perfect. NAS performs exhaustive candidate architecture search, incurring tremendous search cost. Though (structured) pruning can simply shrink model dimension, it remains unclear how to decide the per-layer sparsity automatically and optimally. In this work, we revisit the problem of layer-width optimization and propose Pruning-as-Search (PaS), an end-to-end channel pruning method to search out desired sub-network automatically and efficiently. Specifically, we add a depth-wise binary convolution to learn pruning policies directly through gradient descent. By combining the structural reparameterization and PaS, we successfully searched out a new family of VGG-like and lightweight networks, which enable the flexibility of arbitrary width with respect to each layer instead of each stage. Experimental results show that our proposed architecture outperforms prior arts by around $1.0\%$ top-1 accuracy under similar inference speed on ImageNet-1000 classification task. Furthermore, we demonstrate the effectiveness of our width search on complex tasks including instance segmentation and image translation. Code and models are released.
Diverse facial inpainting guided by exemplars
Feb 15, 2022
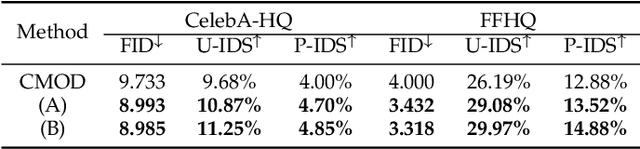
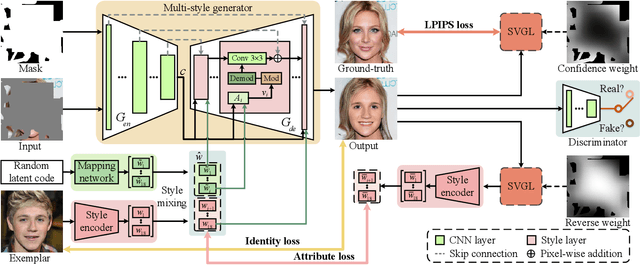
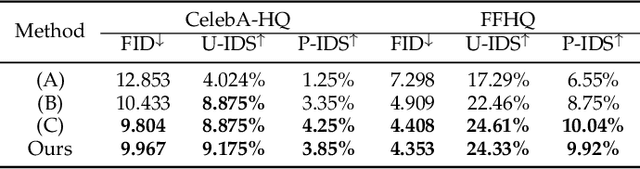
Facial image inpainting is a task of filling visually realistic and semantically meaningful contents for missing or masked pixels in a face image. Although existing methods have made significant progress in achieving high visual quality, the controllable diversity of facial image inpainting remains an open problem in this field. This paper introduces EXE-GAN, a novel diverse and interactive facial inpainting framework, which can not only preserve the high-quality visual effect of the whole image but also complete the face image with exemplar-like facial attributes. The proposed facial inpainting is achieved based on generative adversarial networks by leveraging the global style of input image, the stochastic style, and the exemplar style of exemplar image. A novel attribute similarity metric is introduced to encourage networks to learn the style of facial attributes from the exemplar in a self-supervised way. To guarantee the natural transition across the boundary of inpainted regions, a novel spatial variant gradient backpropagation technique is designed to adjust the loss gradients based on the spatial location. A variety of experimental results and comparisons on public CelebA-HQ and FFHQ datasets are presented to demonstrate the superiority of the proposed method in terms of both the quality and diversity in facial inpainting.