 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Segmentation in Real-World Images via Spelke Object Inference
May 17, 2022

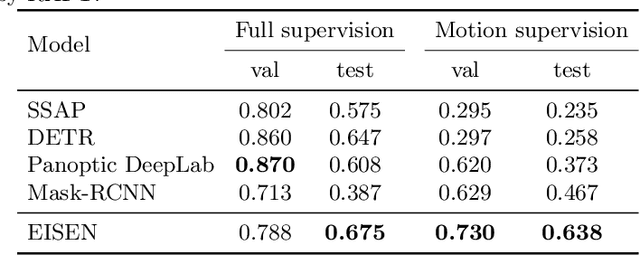
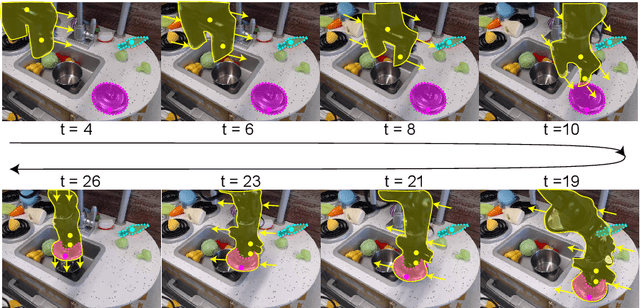

Self-supervised category-agnostic segmentation of real-world images into objects is a challenging open problem in computer vision. Here, we show how to learn static grouping priors from motion self-supervision, building on the cognitive science notion of Spelke Objects: groupings of stuff that move together. We introduce Excitatory-Inhibitory Segment Extraction Network (EISEN), which learns from optical flow estimates to extract pairwise affinity graphs for static scenes. EISEN then produces segments from affinities using a novel graph propagation and competition mechanism. Correlations between independent sources of motion (e.g. robot arms) and objects they move are resolved into separate segments through a bootstrapping training process. We show that EISEN achieves a substantial improvement in the state of the art for self-supervised segmentation on challenging synthetic and real-world robotic image datasets. We also present an ablation analysis illustrating the importance of each element of the EISEN architecture.
CLCNet: Rethinking of Ensemble Modeling with Classification Confidence Network
May 24, 2022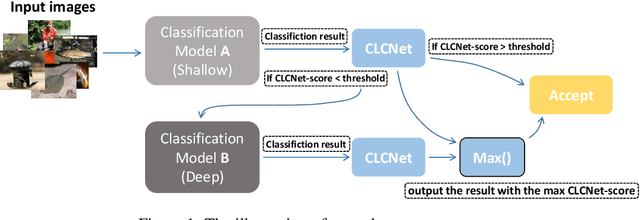
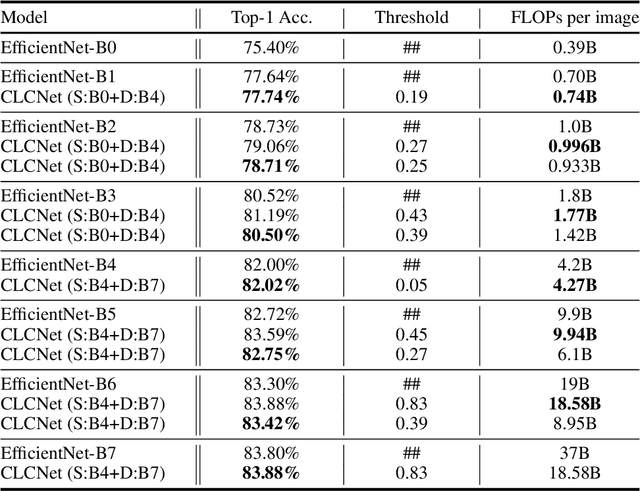
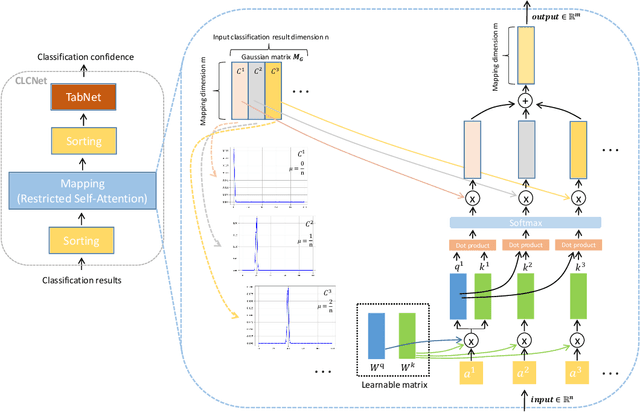
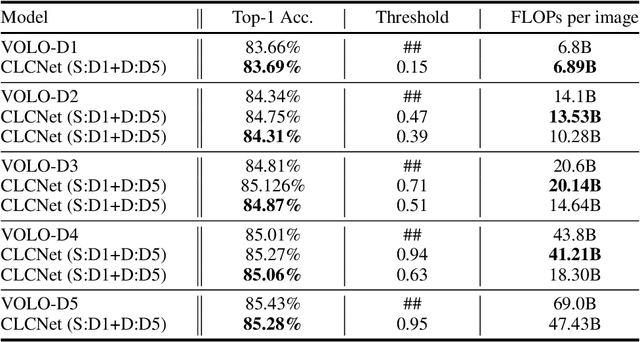
In this paper, we propose a Classification Confidence Network (CLCNet) that can determine whether the classification model classifies input samples correctly. It can take a classification result in the form of vector in any dimension, and return a confidence score as output, which represents the probability of an instance being classified correctly. We can utilize CLCNet in a simple cascade structure system consisting of several SOTA (state-of-the-art) classification models, and our experiments show that the system can achieve the following advantages: 1. The system can customize the average computation requirement (FLOPs) per image while inference. 2. Under the same computation requirement, the performance of the system can exceed any model that has identical structure with the model in the system, but different in size. In fact, this is a new type of ensemble modeling. Like general ensemble modeling, it can achieve higher performance than single classification model, yet our system requires much less computation than general ensemble modeling. We have uploaded our code to a github repository: https://github.com/yaoching0/CLCNet-Rethinking-of-Ensemble-Modeling.
Differentiable Dynamics for Articulated 3d Human Motion Reconstruction
May 24, 2022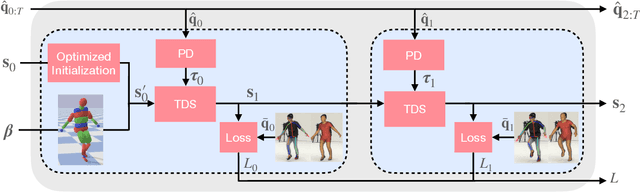
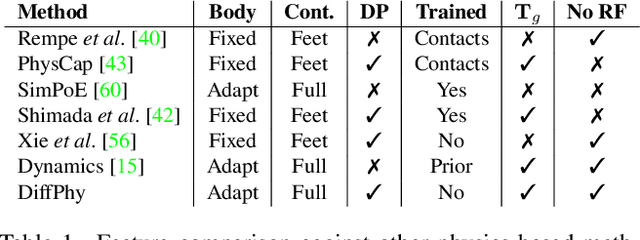

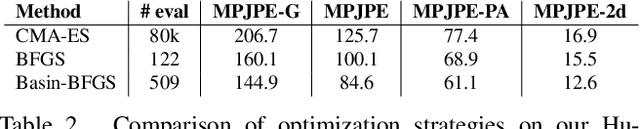
We introduce DiffPhy, a differentiable physics-based model for articulated 3d human motion reconstruction from video. Applications of physics-based reasoning in human motion analysis have so far been limited, both by the complexity of constructing adequate physical models of articulated human motion, and by the formidable challenges of performing stable and efficient inference with physics in the loop. We jointly address such modeling and inference challenges by proposing an approach that combines a physically plausible body representation with anatomical joint limits, a differentiable physics simulator, and optimization techniques that ensure good performance and robustness to suboptimal local optima. In contrast to several recent methods, our approach readily supports full-body contact including interactions with objects in the scene. Most importantly, our model connects end-to-end with images, thus supporting direct gradient-based physics optimization by means of image-based loss functions. We validate the model by demonstrating that it can accurately reconstruct physically plausible 3d human motion from monocular video, both on public benchmarks with available 3d ground-truth, and on videos from the internet.
BiX-NAS: Searching Efficient Bi-directional Architecture for Medical Image Segmentation
Jun 30, 2021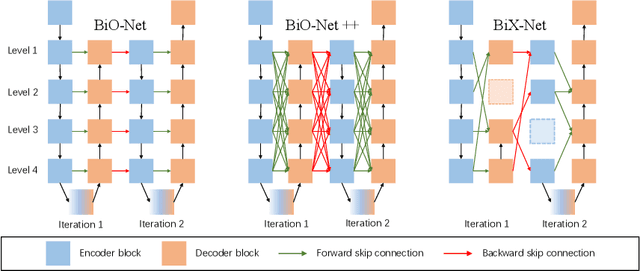
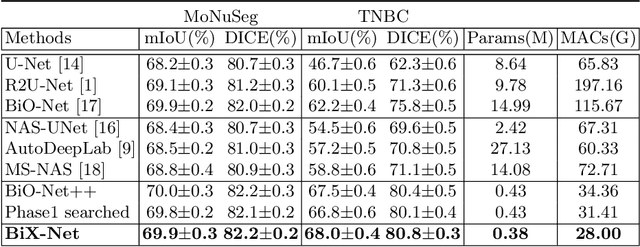
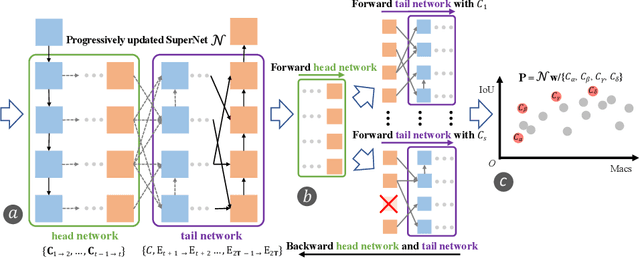
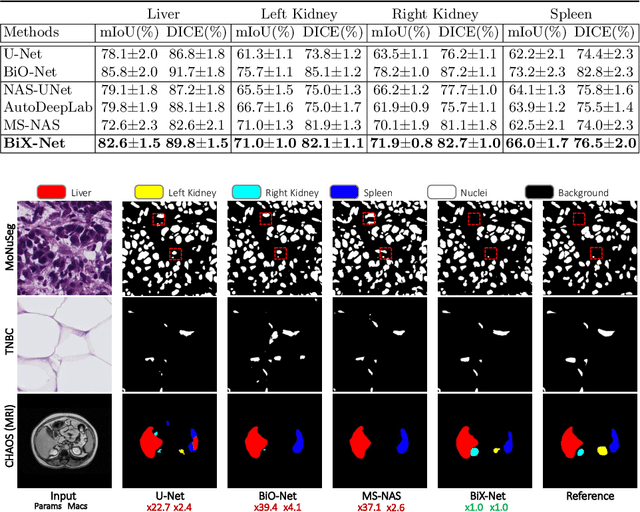
The recurrent mechanism has recently been introduced into U-Net in various medical image segmentation tasks. Existing studies have focused on promoting network recursion via reusing building blocks. Although network parameters could be greatly saved, computational costs still increase inevitably in accordance with the pre-set iteration time. In this work, we study a multi-scale upgrade of a bi-directional skip connected network and then automatically discover an efficient architecture by a novel two-phase Neural Architecture Search (NAS) algorithm, namely BiX-NAS. Our proposed method reduces the network computational cost by sifting out ineffective multi-scale features at different levels and iterations. We evaluate BiX-NAS on two segmentation tasks using three different medical image datasets, and the experimental results show that our BiX-NAS searched architecture achieves the state-of-the-art performance with significantly lower computational cost.
MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Resolution
Jun 04, 2021
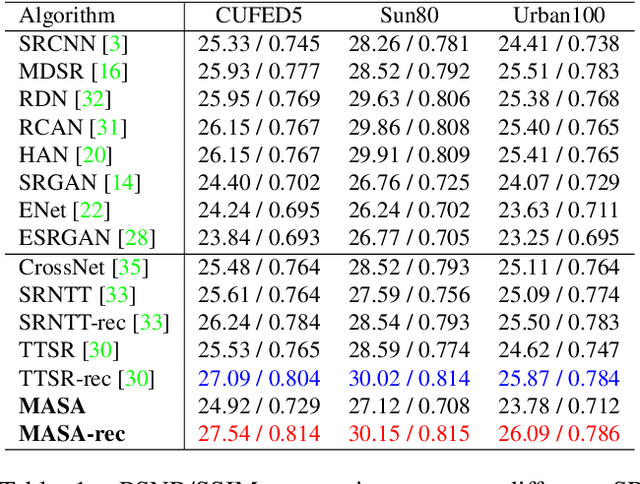
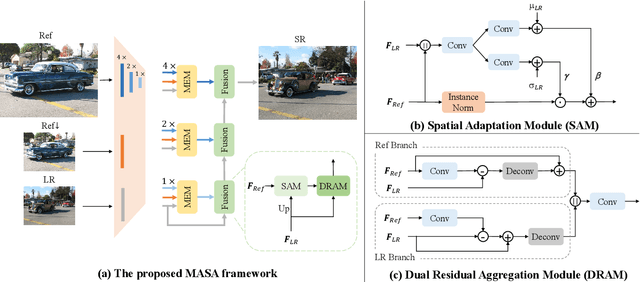

Reference-based image super-resolution (RefSR) has shown promising success in recovering high-frequency details by utilizing an external reference image (Ref). In this task, texture details are transferred from the Ref image to the low-resolution (LR) image according to their point- or patch-wise correspondence. Therefore, high-quality correspondence matching is critical. It is also desired to be computationally efficient. Besides, existing RefSR methods tend to ignore the potential large disparity in distributions between the LR and Ref images, which hurts the effectiveness of the information utilization. In this paper, we propose the MASA network for RefSR, where two novel modules are designed to address these problems. The proposed Match & Extraction Module significantly reduces the computational cost by a coarse-to-fine correspondence matching scheme. The Spatial Adaptation Module learns the difference of distribution between the LR and Ref images, and remaps the distribution of Ref features to that of LR features in a spatially adaptive way. This scheme makes the network robust to handle different reference images. Extensive quantitative and qualitative experiments validate the effectiveness of our proposed model.
Can Foundation Models Wrangle Your Data?
May 20, 2022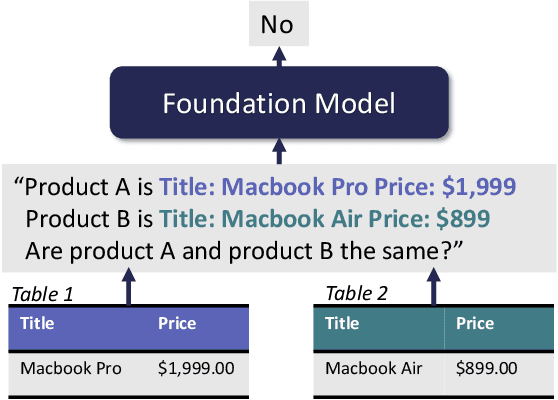
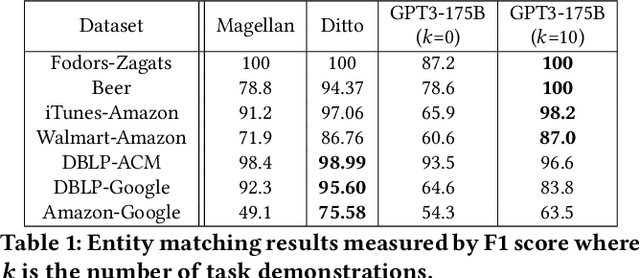
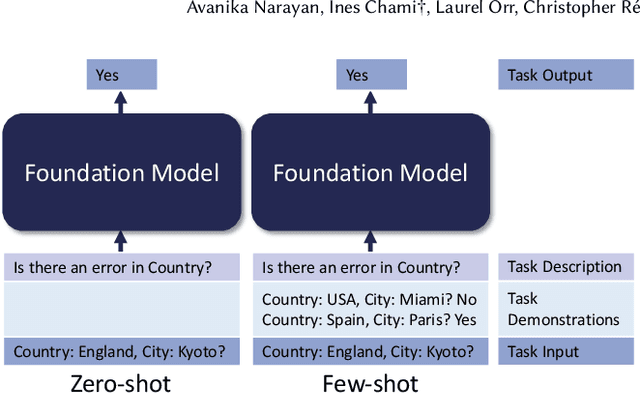
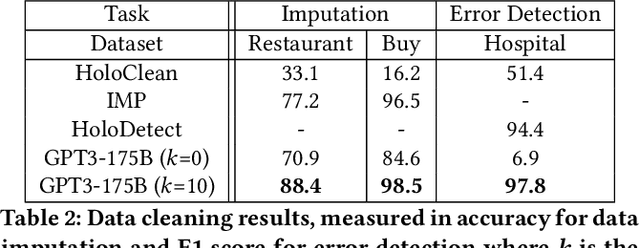
Foundation Models (FMs) are models trained on large corpora of data that, at very large scale, can generalize to new tasks without any task-specific finetuning. As these models continue to grow in size, innovations continue to push the boundaries of what these models can do on language and image tasks. This paper aims to understand an underexplored area of FMs: classical data tasks like cleaning and integration. As a proof-of-concept, we cast three data cleaning and integration tasks as prompting tasks and evaluate the performance of FMs on these tasks. We find that large FMs generalize and achieve SoTA performance on data cleaning and integration tasks, even though they are not trained for these data tasks. We identify specific research challenges and opportunities that these models present, including challenges with private and temporal data, and opportunities to make data driven systems more accessible to non-experts. We make our code and experiments publicly available at: https://github.com/HazyResearch/fm_data_tasks.
Font Style that Fits an Image -- Font Generation Based on Image Context
May 19, 2021
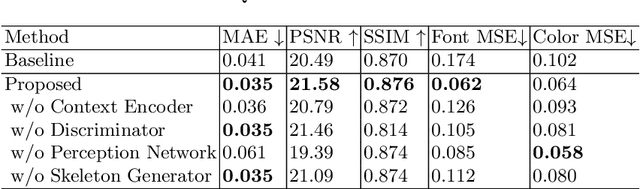
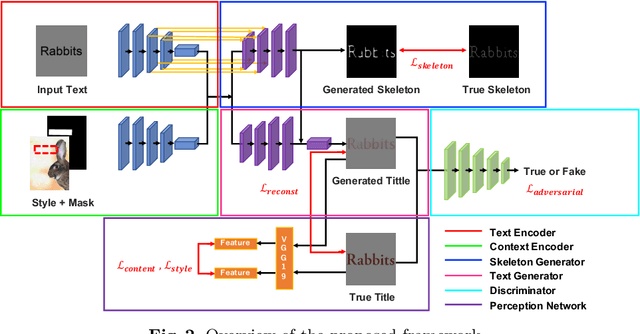

When fonts are used on documents, they are intentionally selected by designers. For example, when designing a book cover, the typography of the text is an important factor in the overall feel of the book. In addition, it needs to be an appropriate font for the rest of the book cover. Thus, we propose a method of generating a book title image based on its context within a book cover. We propose an end-to-end neural network that inputs the book cover, a target location mask, and a desired book title and outputs stylized text suitable for the cover. The proposed network uses a combination of a multi-input encoder-decoder, a text skeleton prediction network, a perception network, and an adversarial discriminator. We demonstrate that the proposed method can effectively produce desirable and appropriate book cover text through quantitative and qualitative results.
Do it Like the Doctor: How We Can Design a Model That Uses Domain Knowledge to Diagnose Pneumothorax
May 24, 2022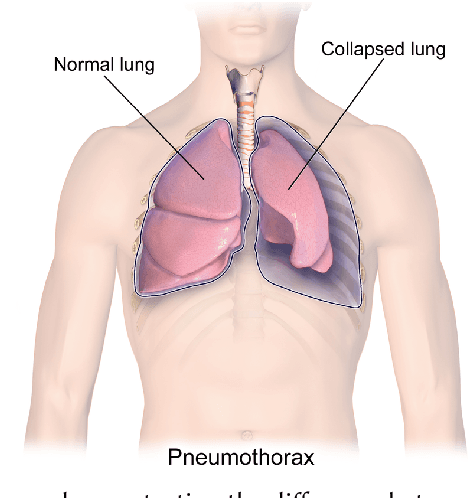
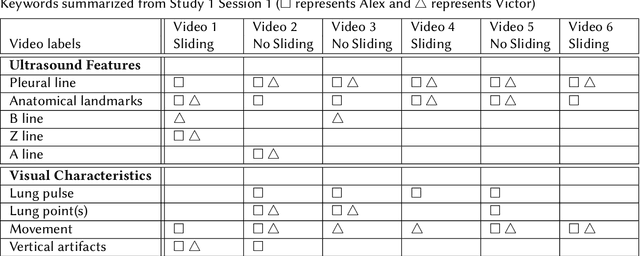
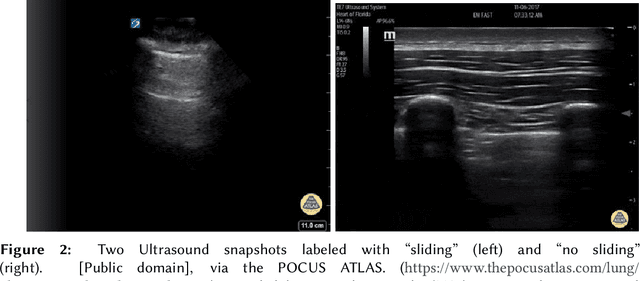
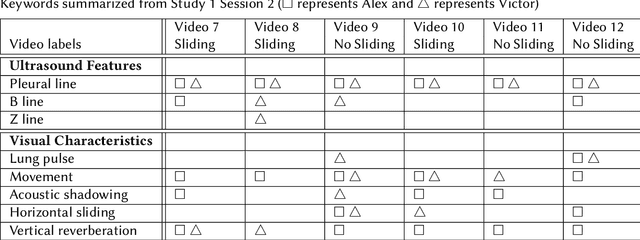
Computer-aided diagnosis for medical imaging is a well-studied field that aims to provide real-time decision support systems for physicians. These systems attempt to detect and diagnose a plethora of medical conditions across a variety of image diagnostic technologies including ultrasound, x-ray, MRI, and CT. When designing AI models for these systems, we are often limited by little training data, and for rare medical conditions, positive examples are difficult to obtain. These issues often cause models to perform poorly, so we needed a way to design an AI model in light of these limitations. Thus, our approach was to incorporate expert domain knowledge into the design of an AI model. We conducted two qualitative think-aloud studies with doctors trained in the interpretation of lung ultrasound diagnosis to extract relevant domain knowledge for the condition Pneumothorax. We extracted knowledge of key features and procedures used to make a diagnosis. With this knowledge, we employed knowledge engineering concepts to make recommendations for an AI model design to automatically diagnose Pneumothorax.
MulT: An End-to-End Multitask Learning Transformer
May 17, 2022
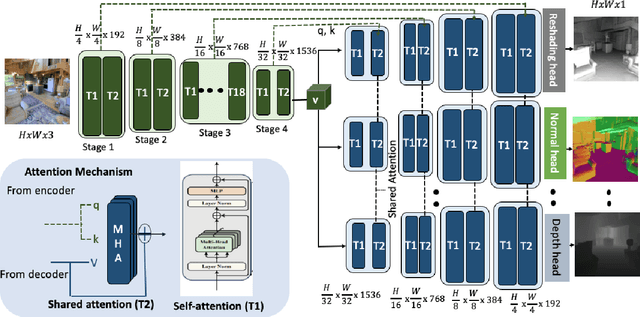
We propose an end-to-end Multitask Learning Transformer framework, named MulT, to simultaneously learn multiple high-level vision tasks, including depth estimation, semantic segmentation, reshading, surface normal estimation, 2D keypoint detection, and edge detection. Based on the Swin transformer model, our framework encodes the input image into a shared representation and makes predictions for each vision task using task-specific transformer-based decoder heads. At the heart of our approach is a shared attention mechanism modeling the dependencies across the tasks. We evaluate our model on several multitask benchmarks, showing that our MulT framework outperforms both the state-of-the art multitask convolutional neural network models and all the respective single task transformer models. Our experiments further highlight the benefits of sharing attention across all the tasks, and demonstrate that our MulT model is robust and generalizes well to new domains. Our project website is at https://ivrl.github.io/MulT/.
Accurate 3D Body Shape Regression using Metric and Semantic Attributes
Jun 14, 2022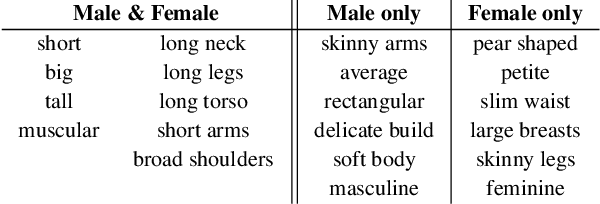

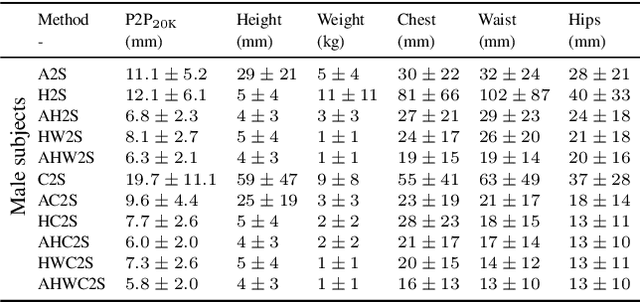
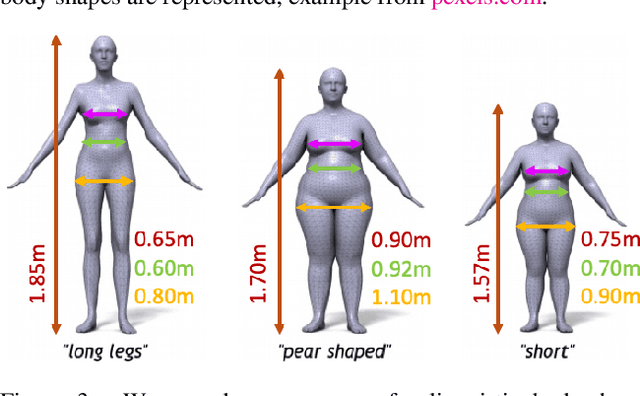
While methods that regress 3D human meshes from images have progressed rapidly, the estimated body shapes often do not capture the true human shape. This is problematic since, for many applications, accurate body shape is as important as pose. The key reason that body shape accuracy lags pose accuracy is the lack of data. While humans can label 2D joints, and these constrain 3D pose, it is not so easy to "label" 3D body shape. Since paired data with images and 3D body shape are rare, we exploit two sources of information: (1) we collect internet images of diverse "fashion" models together with a small set of anthropometric measurements; (2) we collect linguistic shape attributes for a wide range of 3D body meshes and the model images. Taken together, these datasets provide sufficient constraints to infer dense 3D shape. We exploit the anthropometric measurements and linguistic shape attributes in several novel ways to train a neural network, called SHAPY, that regresses 3D human pose and shape from an RGB image. We evaluate SHAPY on public benchmarks, but note that they either lack significant body shape variation, ground-truth shape, or clothing variation. Thus, we collect a new dataset for evaluating 3D human shape estimation, called HBW, containing photos of "Human Bodies in the Wild" for which we have ground-truth 3D body scans. On this new benchmark, SHAPY significantly outperforms state-of-the-art methods on the task of 3D body shape estimation. This is the first demonstration that 3D body shape regression from images can be trained from easy-to-obtain anthropometric measurements and linguistic shape attributes. Our model and data are available at: shapy.is.tue.mpg.de
* First two authors contributed equally