 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D Hand Reconstruction via Aggregating Intra and Inter Graphs Guided by Prior Knowledge for Hand-Object Interaction Scenario
Mar 04, 2024
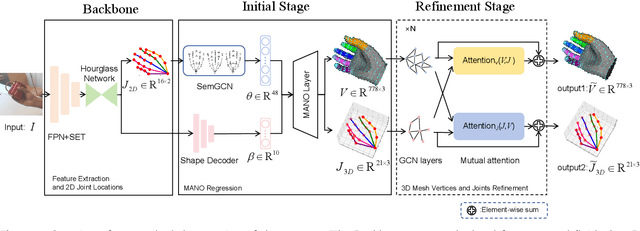
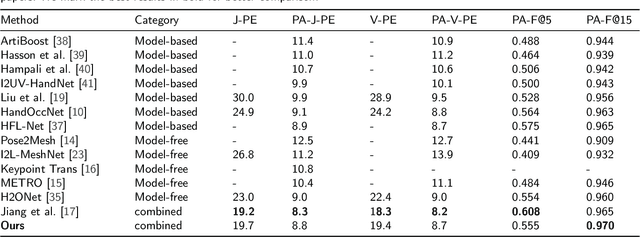
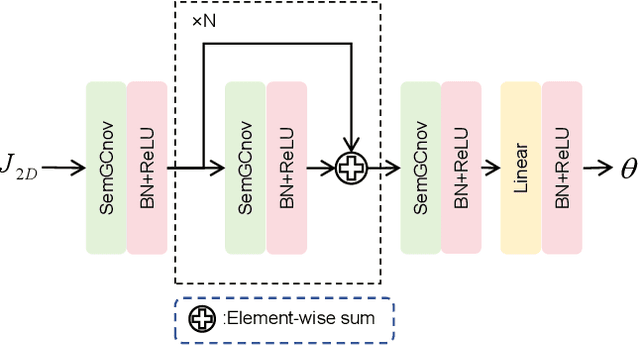
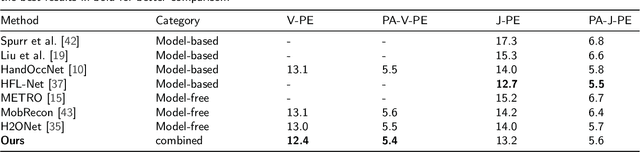
Recently, 3D hand reconstruction has gained more attention in human-computer cooperation, especially for hand-object interaction scenario. However, it still remains huge challenge due to severe hand-occlusion caused by interaction, which contain the balance of accuracy and physical plausibility, highly nonlinear mapping of model parameters and occlusion feature enhancement. To overcome these issues, we propose a 3D hand reconstruction network combining the benefits of model-based and model-free approaches to balance accuracy and physical plausibility for hand-object interaction scenario. Firstly, we present a novel MANO pose parameters regression module from 2D joints directly, which avoids the process of highly nonlinear mapping from abstract image feature and no longer depends on accurate 3D joints. Moreover, we further propose a vertex-joint mutual graph-attention model guided by MANO to jointly refine hand meshes and joints, which model the dependencies of vertex-vertex and joint-joint and capture the correlation of vertex-joint for aggregating intra-graph and inter-graph node features respectively. The experimental results demonstrate that our method achieves a competitive performance on recently benchmark datasets HO3DV2 and Dex-YCB, and outperforms all only model-base approaches and model-free approaches.
xT: Nested Tokenization for Larger Context in Large Images
Mar 04, 2024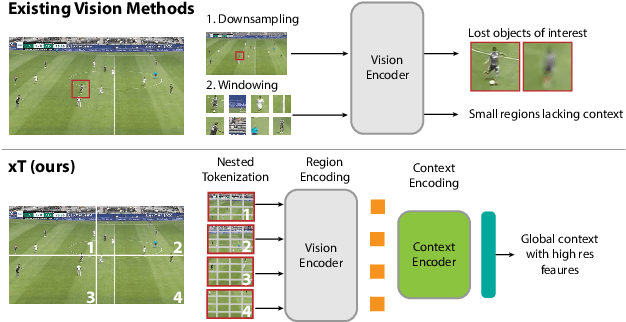
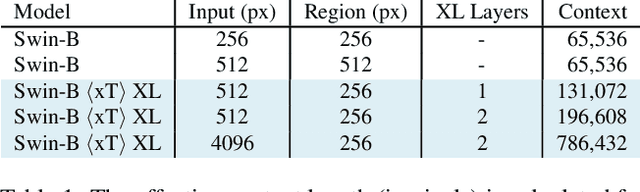
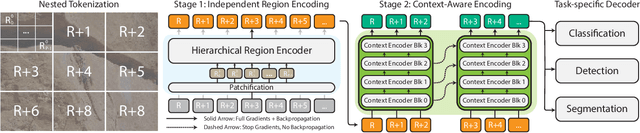
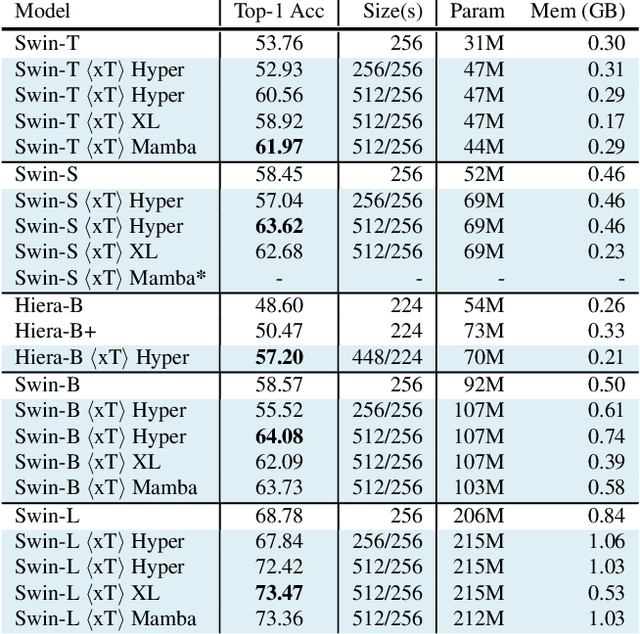
Modern computer vision pipelines handle large images in one of two sub-optimal ways: down-sampling or cropping. These two methods incur significant losses in the amount of information and context present in an image. There are many downstream applications in which global context matters as much as high frequency details, such as in real-world satellite imagery; in such cases researchers have to make the uncomfortable choice of which information to discard. We introduce xT, a simple framework for vision transformers which effectively aggregates global context with local details and can model large images end-to-end on contemporary GPUs. We select a set of benchmark datasets across classic vision tasks which accurately reflect a vision model's ability to understand truly large images and incorporate fine details over large scales and assess our method's improvement on them. By introducing a nested tokenization scheme for large images in conjunction with long-sequence length models normally used for natural language processing, we are able to increase accuracy by up to 8.6% on challenging classification tasks and $F_1$ score by 11.6 on context-dependent segmentation in large images.
Analysis of the Two-Step Heterogeneous Transfer Learning for Laryngeal Blood Vessel Classification: Issue and Improvement
Mar 05, 2024Transferring features learned from natural to medical images for classification is common. However, challenges arise due to the scarcity of certain medical image types and the feature disparities between natural and medical images. Two-step transfer learning has been recognized as a promising solution for this issue. However, choosing an appropriate intermediate domain would be critical in further improving the classification performance. In this work, we explore the effectiveness of using color fundus photographs of the diabetic retina dataset as an intermediate domain for two-step heterogeneous learning (THTL) to classify laryngeal vascular images with nine deep-learning models. Experiment results confirm that although the images in both the intermediate and target domains share vascularized characteristics, the accuracy is drastically reduced compared to one-step transfer learning, where only the last layer is fine-tuned (e.g., ResNet18 drops 14.7%, ResNet50 drops 14.8%). By analyzing the Layer Class Activation Maps (LayerCAM), we uncover a novel finding that the prevalent radial vascular pattern in the intermediate domain prevents learning the features of twisted and tangled vessels that distinguish the malignant class in the target domain. To address the performance drop, we propose the Step-Wise Fine-Tuning (SWFT) method on ResNet in the second step of THTL, resulting in substantial accuracy improvements. Compared to THTL's second step, where only the last layer is fine-tuned, accuracy increases by 26.1% for ResNet18 and 20.4% for ResNet50. Additionally, compared to training from scratch, using ImageNet as the source domain could slightly improve classification performance for laryngeal vascular, but the differences are insignificant.
Radio-astronomical Image Reconstruction with Conditional Denoising Diffusion Model
Feb 15, 2024Reconstructing sky models from dirty radio images for accurate source localization and flux estimation is crucial for studying galaxy evolution at high redshift, especially in deep fields using instruments like the Atacama Large Millimetre Array (ALMA). With new projects like the Square Kilometre Array (SKA), there's a growing need for better source extraction methods. Current techniques, such as CLEAN and PyBDSF, often fail to detect faint sources, highlighting the need for more accurate methods. This study proposes using stochastic neural networks to rebuild sky models directly from dirty images. This method can pinpoint radio sources and measure their fluxes with related uncertainties, marking a potential improvement in radio source characterization. We tested this approach on 10164 images simulated with the CASA tool simalma, based on ALMA's Cycle 5.3 antenna setup. We applied conditional Denoising Diffusion Probabilistic Models (DDPMs) for sky models reconstruction, then used Photutils to determine source coordinates and fluxes, assessing the model's performance across different water vapor levels. Our method showed excellence in source localization, achieving more than 90% completeness at a signal-to-noise ratio (SNR) as low as 2. It also surpassed PyBDSF in flux estimation, accurately identifying fluxes for 96% of sources in the test set, a significant improvement over CLEAN+ PyBDSF's 57%. Conditional DDPMs is a powerful tool for image-to-image translation, yielding accurate and robust characterisation of radio sources, and outperforming existing methodologies. While this study underscores its significant potential for applications in radio astronomy, we also acknowledge certain limitations that accompany its usage, suggesting directions for further refinement and research.
A Simple yet Effective Network based on Vision Transformer for Camouflaged Object and Salient Object Detection
Feb 29, 2024Camouflaged object detection (COD) and salient object detection (SOD) are two distinct yet closely-related computer vision tasks widely studied during the past decades. Though sharing the same purpose of segmenting an image into binary foreground and background regions, their distinction lies in the fact that COD focuses on concealed objects hidden in the image, while SOD concentrates on the most prominent objects in the image. Previous works achieved good performance by stacking various hand-designed modules and multi-scale features. However, these carefully-designed complex networks often performed well on one task but not on another. In this work, we propose a simple yet effective network (SENet) based on vision Transformer (ViT), by employing a simple design of an asymmetric ViT-based encoder-decoder structure, we yield competitive results on both tasks, exhibiting greater versatility than meticulously crafted ones. Furthermore, to enhance the Transformer's ability to model local information, which is important for pixel-level binary segmentation tasks, we propose a local information capture module (LICM). We also propose a dynamic weighted loss (DW loss) based on Binary Cross-Entropy (BCE) and Intersection over Union (IoU) loss, which guides the network to pay more attention to those smaller and more difficult-to-find target objects according to their size. Moreover, we explore the issue of joint training of SOD and COD, and propose a preliminary solution to the conflict in joint training, further improving the performance of SOD. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of our method. The code is available at https://github.com/linuxsino/SENet.
Data-efficient Event Camera Pre-training via Disentangled Masked Modeling
Mar 01, 2024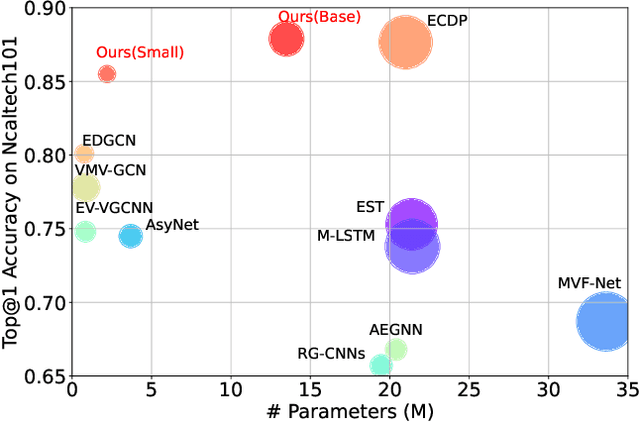


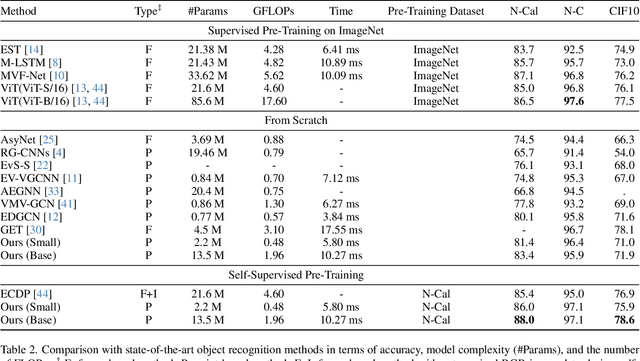
In this paper, we present a new data-efficient voxel-based self-supervised learning method for event cameras. Our pre-training overcomes the limitations of previous methods, which either sacrifice temporal information by converting event sequences into 2D images for utilizing pre-trained image models or directly employ paired image data for knowledge distillation to enhance the learning of event streams. In order to make our pre-training data-efficient, we first design a semantic-uniform masking method to address the learning imbalance caused by the varying reconstruction difficulties of different regions in non-uniform data when using random masking. In addition, we ease the traditional hybrid masked modeling process by explicitly decomposing it into two branches, namely local spatio-temporal reconstruction and global semantic reconstruction to encourage the encoder to capture local correlations and global semantics, respectively. This decomposition allows our selfsupervised learning method to converge faster with minimal pre-training data. Compared to previous approaches, our self-supervised learning method does not rely on paired RGB images, yet enables simultaneous exploration of spatial and temporal cues in multiple scales. It exhibits excellent generalization performance and demonstrates significant improvements across various tasks with fewer parameters and lower computational costs.
Optimization of Array Encoding for Ultrasound Imaging
Mar 01, 2024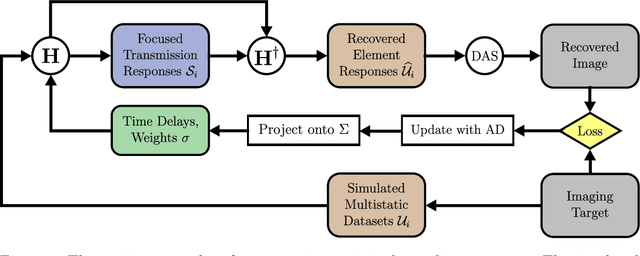

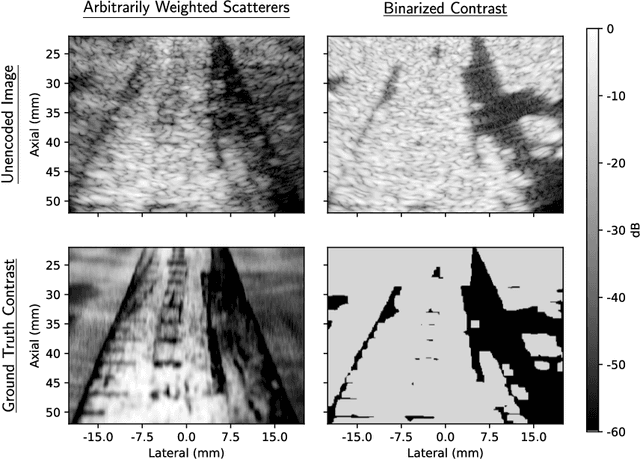
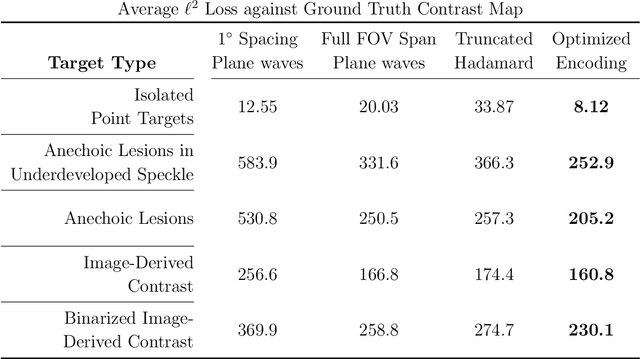
Objective: The transmit encoding model for synthetic aperture imaging is a robust and flexible framework for understanding the effect of acoustic transmission on ultrasound image reconstruction. Our objective is to use machine learning (ML) to construct scanning sequences, parameterized by time delays and apodization weights, that produce high quality B-mode images. Approach: We use an ML model in PyTorch and simulated RF data from Field II to probe the space of possible encoding sequences for those that minimize a loss function that describes image quality. This approach is made computationally feasible by a novel formulation of the derivative for delay-and-sum beamforming. We demonstrate these results experimentally on wire targets and a tissue-mimicking phantom. Main Results: When trained according to a given set of imaging parameters (imaging domain, hardware restrictions), our ML imaging model produces optimized encoding sequences that improve a number of standard quality metrics including resolution, field of view, and contrast, over conventional sequences. Significance: This work demonstrates that the set of encoding schemes that are commonly used represent only a narrow subset of those available. Additionally, it demonstrates the value for ML tasks in synthetic transmit aperture imaging to consider the beamformer within the model, instead of as purely post-processing.
ToDo: Token Downsampling for Efficient Generation of High-Resolution Images
Feb 28, 2024Attention mechanism has been crucial for image diffusion models, however, their quadratic computational complexity limits the sizes of images we can process within reasonable time and memory constraints. This paper investigates the importance of dense attention in generative image models, which often contain redundant features, making them suitable for sparser attention mechanisms. We propose a novel training-free method ToDo that relies on token downsampling of key and value tokens to accelerate Stable Diffusion inference by up to 2x for common sizes and up to 4.5x or more for high resolutions like 2048x2048. We demonstrate that our approach outperforms previous methods in balancing efficient throughput and fidelity.
RKHS-BA: A Semantic Correspondence-Free Multi-View Registration Framework with Global Tracking
Mar 02, 2024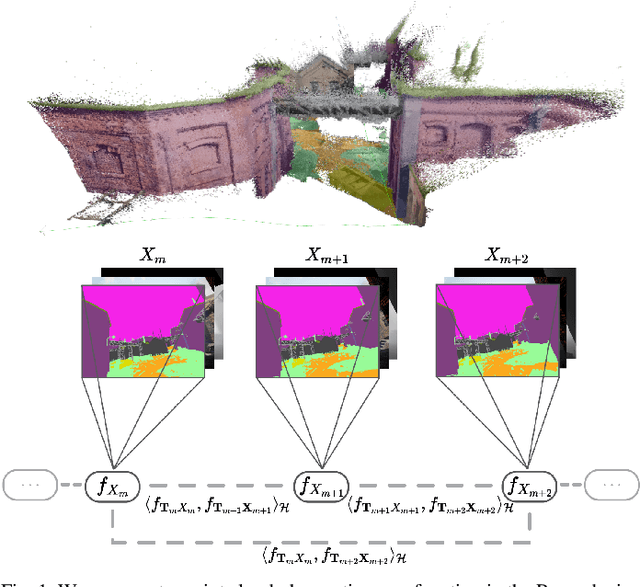
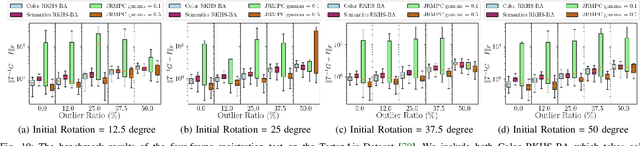
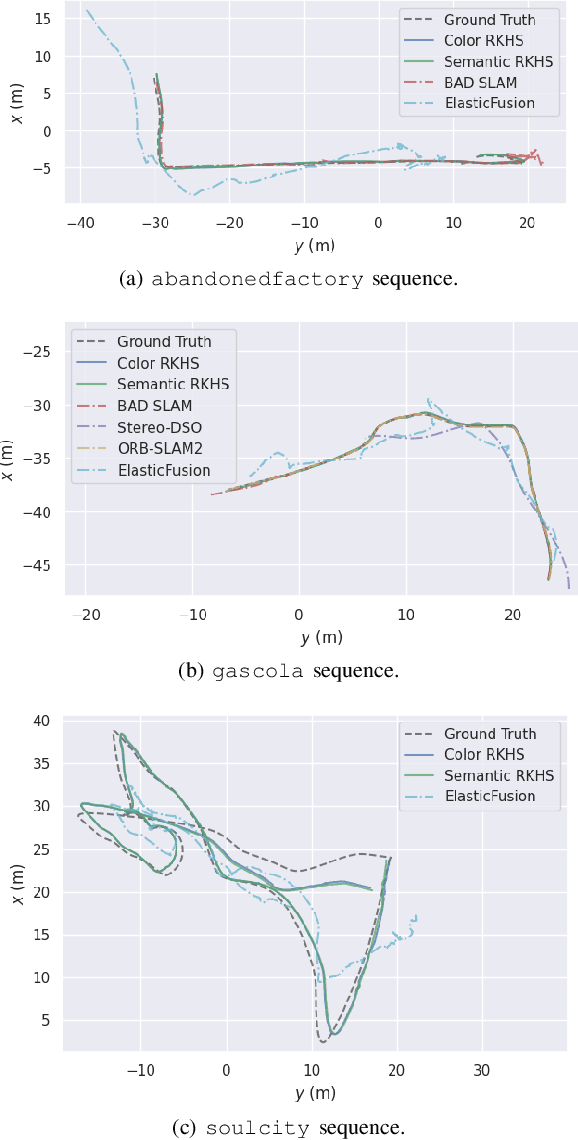

This work reports a novel Bundle Adjustment (BA) formulation using a Reproducing Kernel Hilbert Space (RKHS) representation called RKHS-BA. The proposed formulation is correspondence-free, enables the BA to use RGB-D/LiDAR and semantic labels in the optimization directly, and provides a generalization for the photometric loss function commonly used in direct methods. RKHS-BA can incorporate appearance and semantic labels within a continuous spatial-semantic functional representation that does not require optimization via image pyramids. We demonstrate its applications in sliding-window odometry and global LiDAR mapping, which show highly robust performance in extremely challenging scenes and the best trade-off of generalization and accuracy.
SIFT-Aided Rectified 2D-DIC for Displacement and Strain Measurements in Asphalt Concrete Testing
Feb 29, 2024Two-dimensional digital image correlation (2D-DIC) is a widely used optical technique to measure displacement and strain during asphalt concrete (AC) testing. An accurate 2-D DIC measurement can only be achieved when the camera's principal axis is perpendicular to the planar specimen surface. However, this requirement may not be met during testing due to device constraints. This paper proposes a simple and reliable method to correct errors induced by non-perpendicularity. The method is based on image feature matching and rectification. No additional equipment is needed. A theoretical error analysis was conducted to quantify the effect of a non-perpendicular camera alignment on measurement accuracy. The proposed method was validated numerically using synthetic images and experimentally in an AC fracture test. It achieved relatively high accuracy, even under considerable camera rotation angle and large deformation. As a pre-processing technique, the proposed method showed promising performance in assisting the recently developed CrackPropNet for automated crack propagation measurement under a non-perpendicular camera alignment.