 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Controllable Confidence-Based Image Denoising
Jun 17, 2021
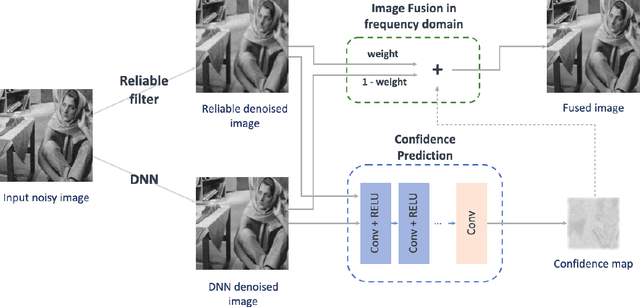
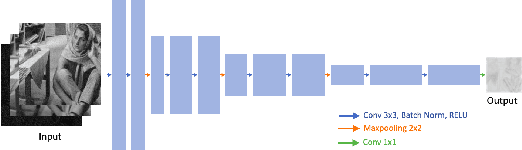
Image denoising is a classic restoration problem. Yet, current deep learning methods are subject to the problems of generalization and interpretability. To mitigate these problems, in this project, we present a framework that is capable of controllable, confidence-based noise removal. The framework is based on the fusion between two different denoised images, both derived from the same noisy input. One of the two is denoised using generic algorithms (e.g. Gaussian), which make few assumptions on the input images, therefore, generalize in all scenarios. The other is denoised using deep learning, performing well on seen datasets. We introduce a set of techniques to fuse the two components smoothly in the frequency domain. Beyond that, we estimate the confidence of a deep learning denoiser to allow users to interpret the output, and provide a fusion strategy that safeguards them against out-of-distribution inputs. Through experiments, we demonstrate the effectiveness of the proposed framework in different use cases.
Zero-Shot Text-to-Image Generation
Feb 26, 2021


Text-to-image generation has traditionally focused on finding better modeling assumptions for training on a fixed dataset. These assumptions might involve complex architectures, auxiliary losses, or side information such as object part labels or segmentation masks supplied during training. We describe a simple approach for this task based on a transformer that autoregressively models the text and image tokens as a single stream of data. With sufficient data and scale, our approach is competitive with previous domain-specific models when evaluated in a zero-shot fashion.
Granular Generalized Variable Precision Rough Sets and Rational Approximations
May 31, 2022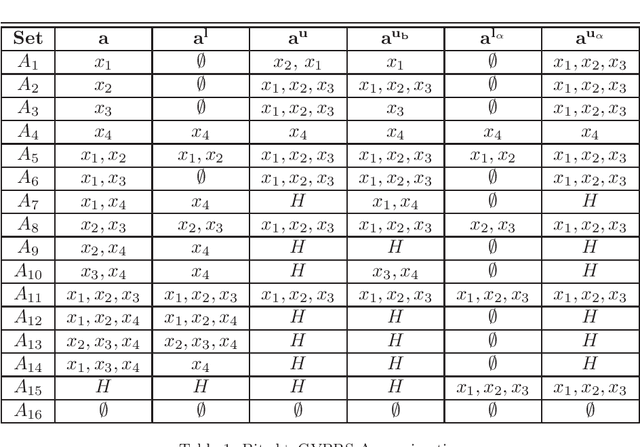
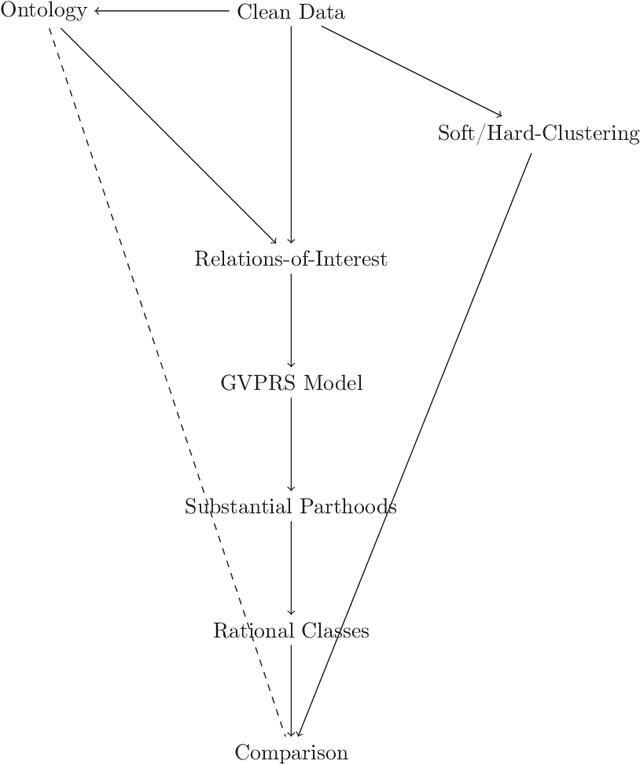
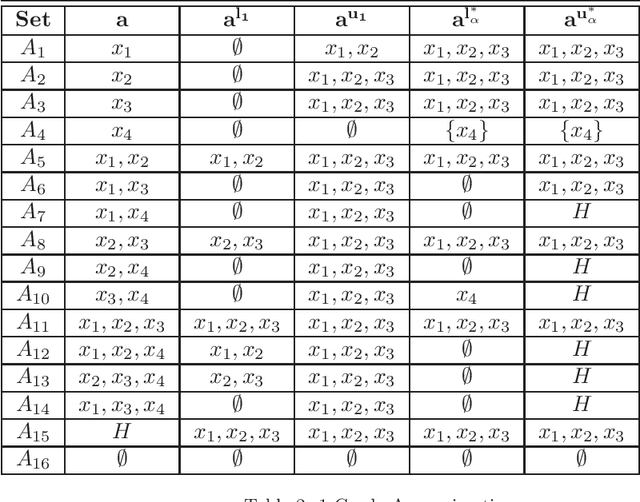
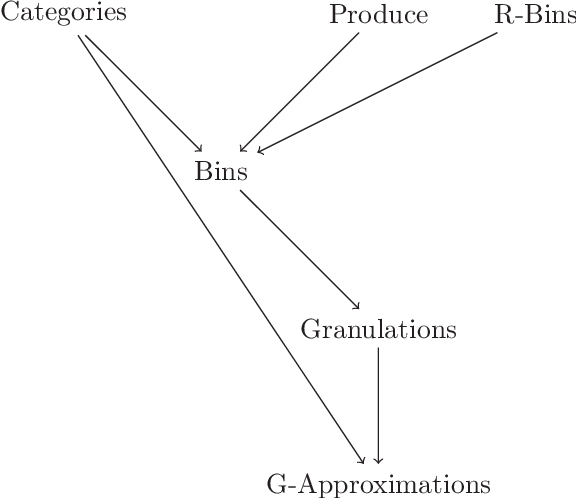
Rational approximations are introduced and studied in granular graded sets and generalizations thereof by the first author in recent research papers. The concept of rationality is determined by related ontologies and coherence between granularity, parthood perspective and approximations used in the context. In addition, a framework is introduced by her in the mentioned paper(s). Granular approximations constructed as per the procedures of VPRS are likely to be more rational than those constructed from a classical perspective under certain conditions. This may continue to hold for some generalizations of the former; however, a formal characterization of such conditions is not available in the previously published literature. In this research, theoretical aspects of the problem are critically examined, uniform generalizations of granular VPRS are introduced, new connections with granular graded rough sets are proved, appropriate concepts of substantial parthood are introduced, and their extent of compatibility with the framework is accessed. Furthermore, meta applications to cluster validation, image segmentation and dynamic sorting are invented. Basic assumptions made are explained, and additional examples are constructed for readability.
SimCVD: Simple Contrastive Voxel-Wise Representation Distillation for Semi-Supervised Medical Image Segmentation
Aug 16, 2021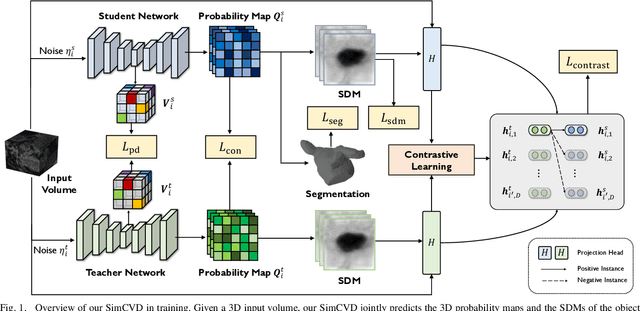
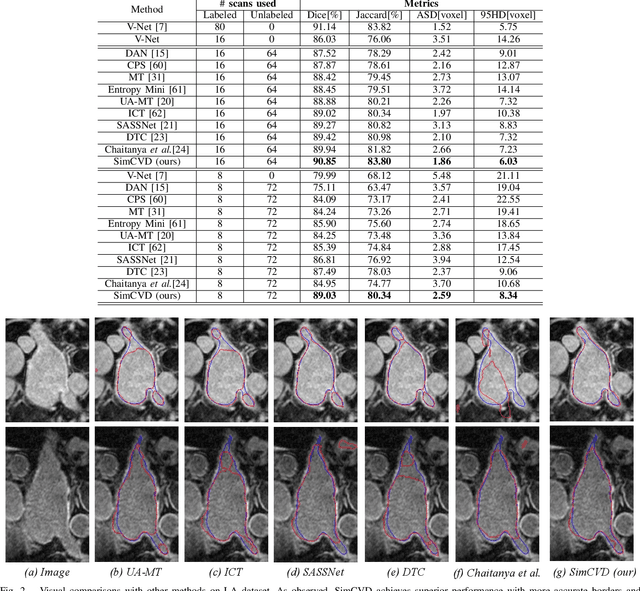
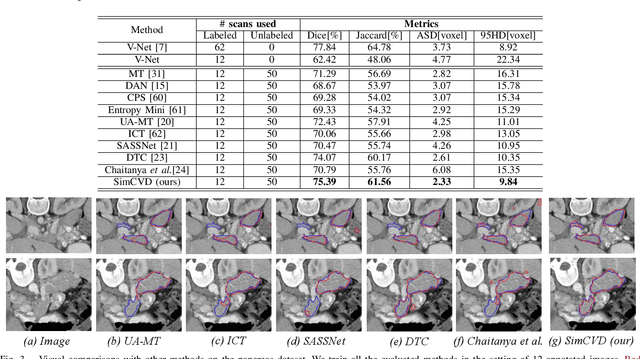
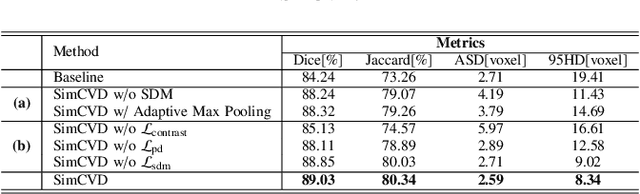
Automated segmentation in medical image analysis is a challenging task that requires a large amount of manually labeled data. However, most existing learning-based approaches usually suffer from limited manually annotated medical data, which poses a major practical problem for accurate and robust medical image segmentation. In addition, most existing semi-supervised approaches are usually not robust compared with the supervised counterparts, and also lack explicit modeling of geometric structure and semantic information, both of which limit the segmentation accuracy. In this work, we present SimCVD, a simple contrastive distillation framework that significantly advances state-of-the-art voxel-wise representation learning. We first describe an unsupervised training strategy, which takes two views of an input volume and predicts their signed distance maps of object boundaries in a contrastive objective, with only two independent dropout as mask. This simple approach works surprisingly well, performing on the same level as previous fully supervised methods with much less labeled data. We hypothesize that dropout can be viewed as a minimal form of data augmentation and makes the network robust to representation collapse. Then, we propose to perform structural distillation by distilling pair-wise similarities. We evaluate SimCVD on two popular datasets: the Left Atrial Segmentation Challenge (LA) and the NIH pancreas CT dataset. The results on the LA dataset demonstrate that, in two types of labeled ratios (i.e., 20% and 10%), SimCVD achieves an average Dice score of 90.85% and 89.03% respectively, a 0.91% and 2.22% improvement compared to previous best results. Our method can be trained in an end-to-end fashion, showing the promise of utilizing SimCVD as a general framework for downstream tasks, such as medical image synthesis and registration.
Impact of deep learning-based image super-resolution on binary signal detection
Jul 06, 2021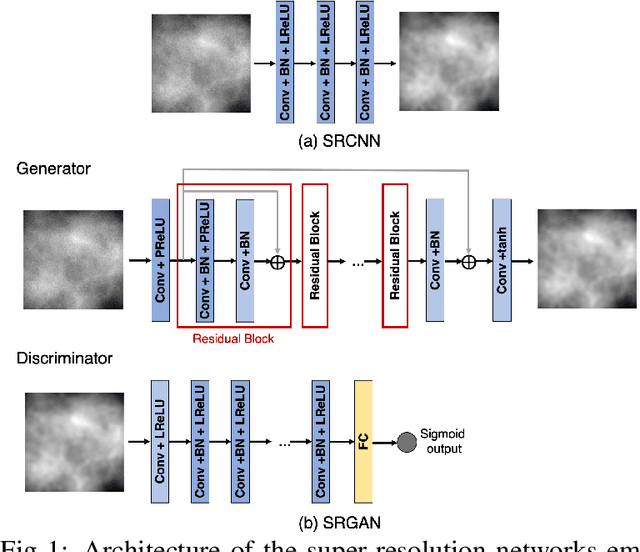


Deep learning-based image super-resolution (DL-SR) has shown great promise in medical imaging applications. To date, most of the proposed methods for DL-SR have only been assessed by use of traditional measures of image quality (IQ) that are commonly employed in the field of computer vision. However, the impact of these methods on objective measures of image quality that are relevant to medical imaging tasks remains largely unexplored. In this study, we investigate the impact of DL-SR methods on binary signal detection performance. Two popular DL-SR methods, the super-resolution convolutional neural network (SRCNN) and the super-resolution generative adversarial network (SRGAN), were trained by use of simulated medical image data. Binary signal-known-exactly with background-known-statistically (SKE/BKS) and signal-known-statistically with background-known-statistically (SKS/BKS) detection tasks were formulated. Numerical observers, which included a neural network-approximated ideal observer and common linear numerical observers, were employed to assess the impact of DL-SR on task performance. The impact of the complexity of the DL-SR network architectures on task-performance was quantified. In addition, the utility of DL-SR for improving the task-performance of sub-optimal observers was investigated. Our numerical experiments confirmed that, as expected, DL-SR could improve traditional measures of IQ. However, for many of the study designs considered, the DL-SR methods provided little or no improvement in task performance and could even degrade it. It was observed that DL-SR could improve the task-performance of sub-optimal observers under certain conditions. The presented study highlights the urgent need for the objective assessment of DL-SR methods and suggests avenues for improving their efficacy in medical imaging applications.
Future Artificial Intelligence tools and perspectives in medicine
Jun 04, 2022Purpose of review: Artificial intelligence (AI) has become popular in medical applications, specifically as a clinical support tool for computer-aided diagnosis. These tools are typically employed on medical data (i.e., image, molecular data, clinical variables, etc.) and used the statistical and machine learning methods to measure the model performance. In this review, we summarized and discussed the most recent radiomic pipeline used for clinical analysis. Recent findings:Currently, limited management of cancers benefits from artificial intelligence, mostly related to a computer-aided diagnosis that avoids a biopsy analysis that presents additional risks and costs. Most AI tools are based on imaging features, known as radiomic analysis that can be refined into predictive models in non-invasively acquired imaging data. This review explores the progress of AI-based radiomic tools for clinical applications with a brief description of necessary technical steps. Explaining new radiomic approaches based on deep learning techniques will explain how the new radiomic models (deep radiomic analysis) can benefit from deep convolutional neural networks and be applied on limited data sets. Summary: To consider the radiomic algorithms, further investigations are recommended to involve deep learning in radiomic models with additional validation steps on various cancer types.
Colorectal cancer survival prediction using deep distribution based multiple-instance learning
Apr 24, 2022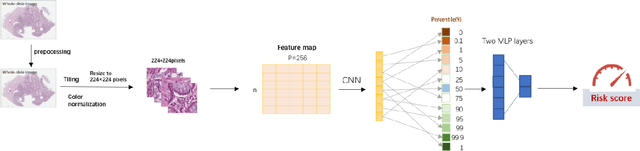
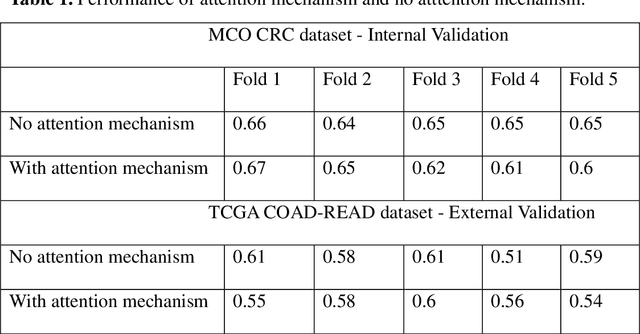
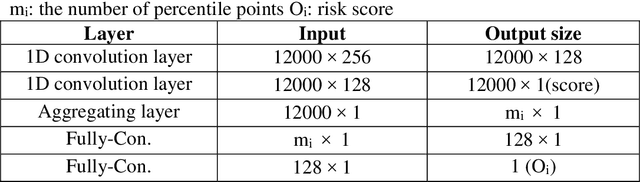
Several deep learning algorithms have been developed to predict survival of cancer patients using whole slide images (WSIs).However, identification of image phenotypes within the WSIs that are relevant to patient survival and disease progression is difficult for both clinicians, and deep learning algorithms. Most deep learning based Multiple Instance Learning (MIL) algorithms for survival prediction use either top instances (e.g., maxpooling) or top/bottom instances (e.g., MesoNet) to identify image phenotypes. In this study, we hypothesize that wholistic information of the distribution of the patch scores within a WSI can predict the cancer survival better. We developed a distribution based multiple-instance survival learning algorithm (DeepDisMISL) to validate this hypothesis. We designed and executed experiments using two large international colorectal cancer WSIs datasets - MCO CRC and TCGA COAD-READ. Our results suggest that the more information about the distribution of the patch scores for a WSI, the better is the prediction performance. Including multiple neighborhood instances around each selected distribution location (e.g., percentiles) could further improve the prediction. DeepDisMISL demonstrated superior predictive ability compared to other recently published, state-of-the-art algorithms. Furthermore, our algorithm is interpretable and could assist in understanding the relationship between cancer morphological phenotypes and patients cancer survival risk.
DU-VLG: Unifying Vision-and-Language Generation via Dual Sequence-to-Sequence Pre-training
Mar 17, 2022
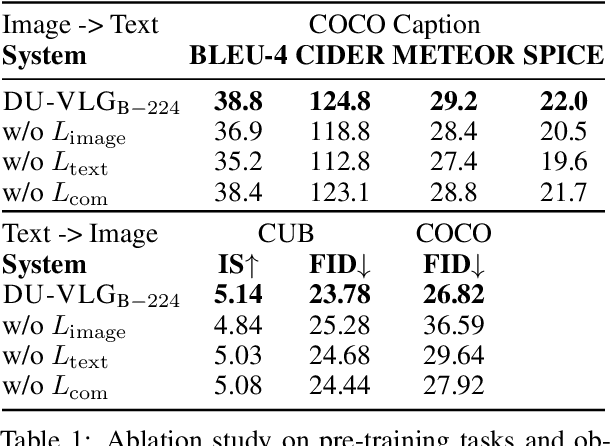
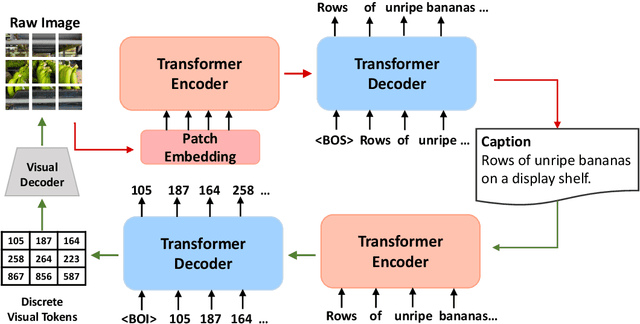
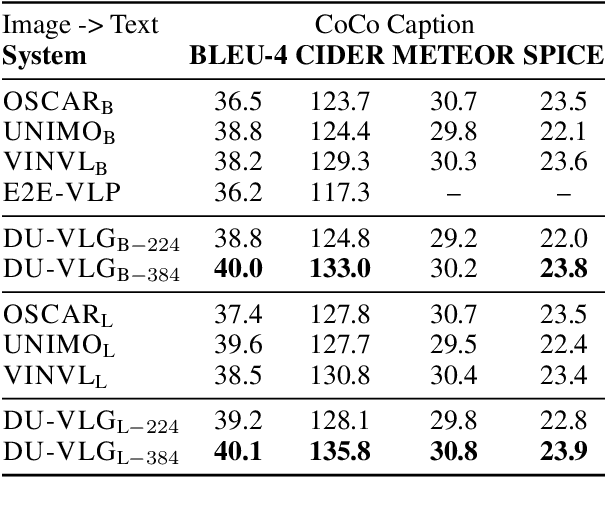
Due to the limitations of the model structure and pre-training objectives, existing vision-and-language generation models cannot utilize pair-wise images and text through bi-directional generation. In this paper, we propose DU-VLG, a framework which unifies vision-and-language generation as sequence generation problems. DU-VLG is trained with novel dual pre-training tasks: multi-modal denoising autoencoder tasks and modality translation tasks. To bridge the gap between image understanding and generation, we further design a novel commitment loss. We compare pre-training objectives on image captioning and text-to-image generation datasets. Results show that DU-VLG yields better performance than variants trained with uni-directional generation objectives or the variant without the commitment loss. We also obtain higher scores compared to previous state-of-the-art systems on three vision-and-language generation tasks. In addition, human judges further confirm that our model generates real and relevant images as well as faithful and informative captions.
Variational Deep Image Denoising
Apr 02, 2021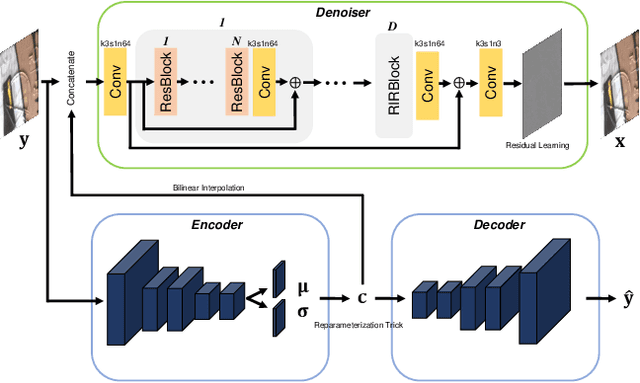
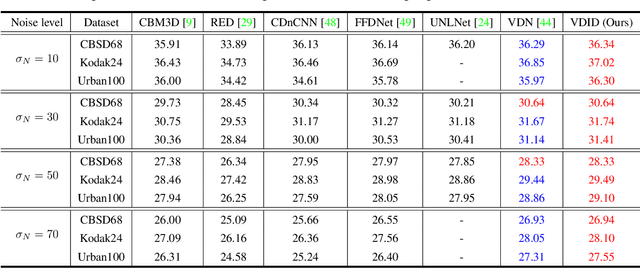
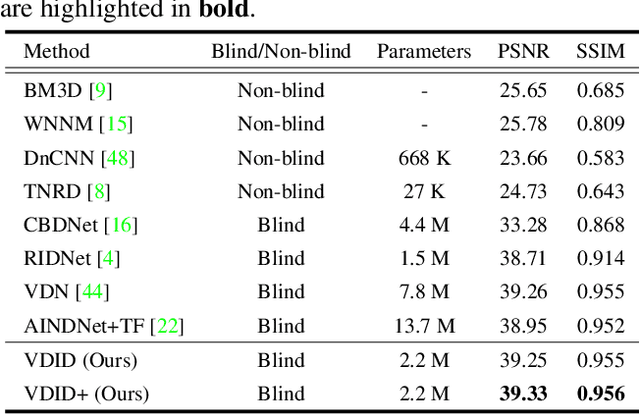

Convolutional neural networks (CNNs) have shown outstanding performance on image denoising with the help of large-scale datasets. Earlier methods naively trained a single CNN with many pairs of clean-noisy images. However, the conditional distribution of the clean image given a noisy one is too complicated and diverse, so that a single CNN cannot well learn such distributions. Therefore, there have also been some methods that exploit additional noise level parameters or train a separate CNN for a specific noise level parameter. These methods separate the original problem into easier sub-problems and thus have shown improved performance than the naively trained CNN. In this step, we raise two questions. The first one is whether it is an optimal approach to relate the conditional distribution only to noise level parameters. The second is what if we do not have noise level information, such as in a real-world scenario. To answer the questions and provide a better solution, we propose a novel Bayesian framework based on the variational approximation of objective functions. This enables us to separate the complicated target distribution into simpler sub-distributions. Eventually, the denoising CNN can conquer noise from each sub-distribution, which is generally an easier problem than the original. Experiments show that the proposed method provides remarkable performance on additive white Gaussian noise (AWGN) and real-noise denoising while requiring fewer parameters than recent state-of-the-art denoisers.
Learning 6-DoF Object Poses to Grasp Category-level Objects by Language Instructions
May 09, 2022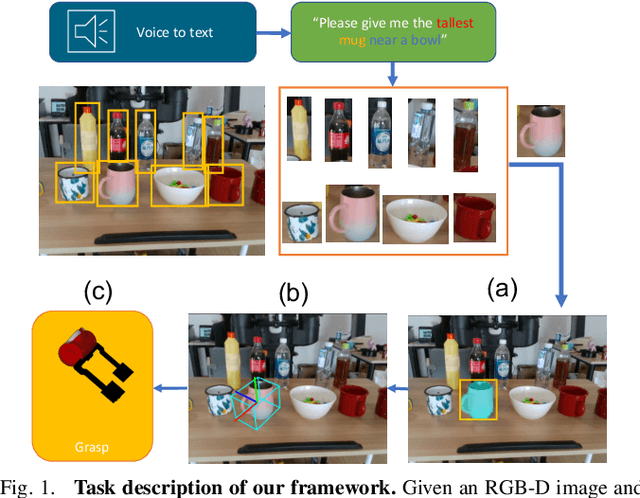

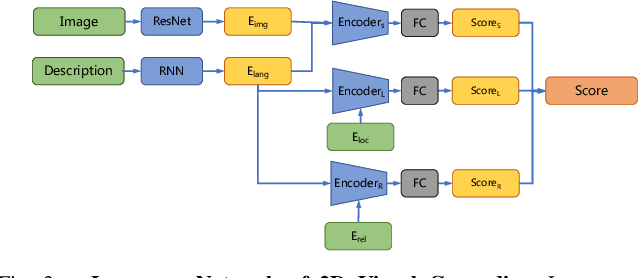

This paper studies the task of any objects grasping from the known categories by free-form language instructions. This task demands the technique in computer vision, natural language processing, and robotics. We bring these disciplines together on this open challenge, which is essential to human-robot interaction. Critically, the key challenge lies in inferring the category of objects from linguistic instructions and accurately estimating the 6-DoF information of unseen objects from the known classes. In contrast, previous works focus on inferring the pose of object candidates at the instance level. This significantly limits its applications in real-world scenarios.In this paper, we propose a language-guided 6-DoF category-level object localization model to achieve robotic grasping by comprehending human intention. To this end, we propose a novel two-stage method. Particularly, the first stage grounds the target in the RGB image through language description of names, attributes, and spatial relations of objects. The second stage extracts and segments point clouds from the cropped depth image and estimates the full 6-DoF object pose at category-level. Under such a manner, our approach can locate the specific object by following human instructions, and estimate the full 6-DoF pose of a category-known but unseen instance which is not utilized for training the model. Extensive experimental results show that our method is competitive with the state-of-the-art language-conditioned grasp method. Importantly, we deploy our approach on a physical robot to validate the usability of our framework in real-world applications. Please refer to the supplementary for the demo videos of our robot experiments.