 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AttrLostGAN: Attribute Controlled Image Synthesis from Reconfigurable Layout and Style
Mar 25, 2021
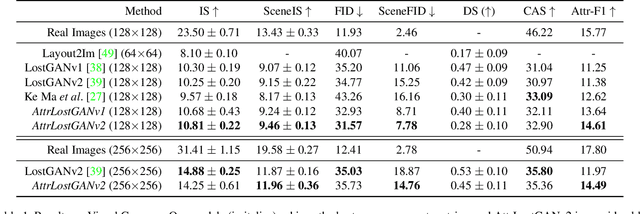
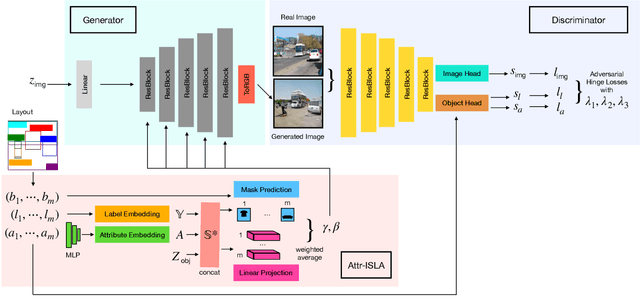
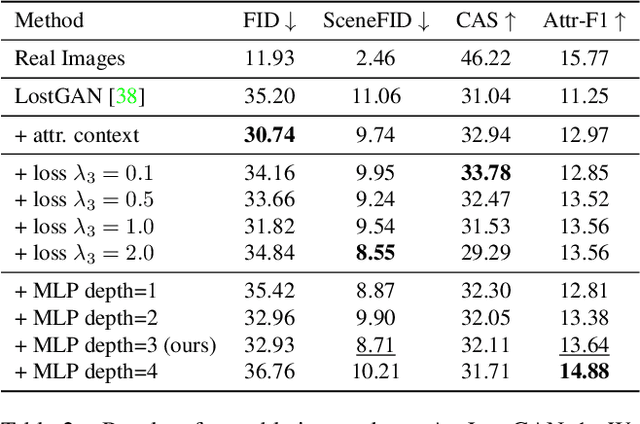
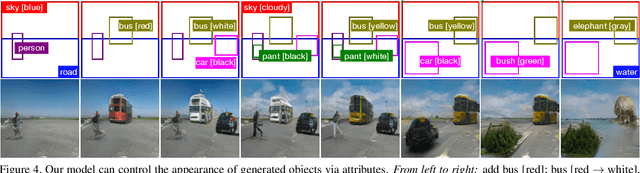
Conditional image synthesis from layout has recently attracted much interest. Previous approaches condition the generator on object locations as well as class labels but lack fine-grained control over the diverse appearance aspects of individual objects. Gaining control over the image generation process is fundamental to build practical applications with a user-friendly interface. In this paper, we propose a method for attribute controlled image synthesis from layout which allows to specify the appearance of individual objects without affecting the rest of the image. We extend a state-of-the-art approach for layout-to-image generation to additionally condition individual objects on attributes. We create and experiment on a synthetic, as well as the challenging Visual Genome dataset. Our qualitative and quantitative results show that our method can successfully control the fine-grained details of individual objects when modelling complex scenes with multiple objects.
FvOR: Robust Joint Shape and Pose Optimization for Few-view Object Reconstruction
May 16, 2022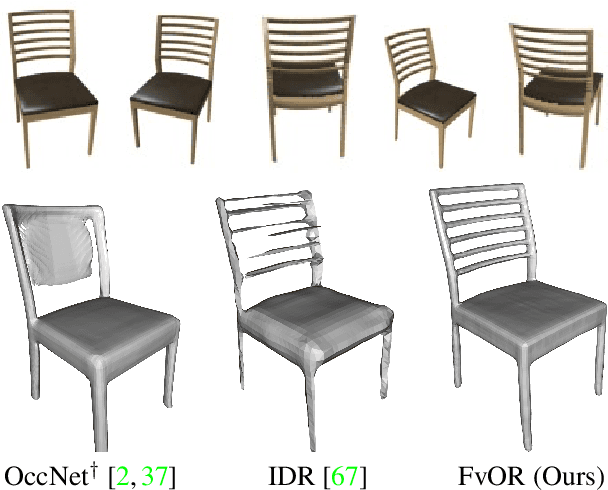

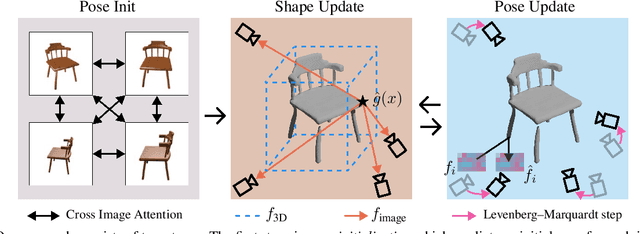

Reconstructing an accurate 3D object model from a few image observations remains a challenging problem in computer vision. State-of-the-art approaches typically assume accurate camera poses as input, which could be difficult to obtain in realistic settings. In this paper, we present FvOR, a learning-based object reconstruction method that predicts accurate 3D models given a few images with noisy input poses. The core of our approach is a fast and robust multi-view reconstruction algorithm to jointly refine 3D geometry and camera pose estimation using learnable neural network modules. We provide a thorough benchmark of state-of-the-art approaches for this problem on ShapeNet. Our approach achieves best-in-class results. It is also two orders of magnitude faster than the recent optimization-based approach IDR. Our code is released at \url{https://github.com/zhenpeiyang/FvOR/}
On Explaining Multimodal Hateful Meme Detection Models
Apr 06, 2022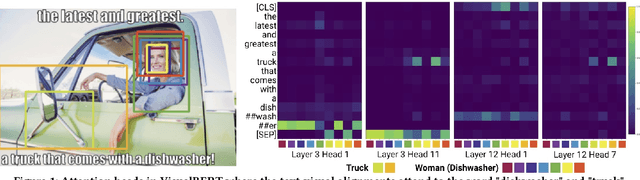
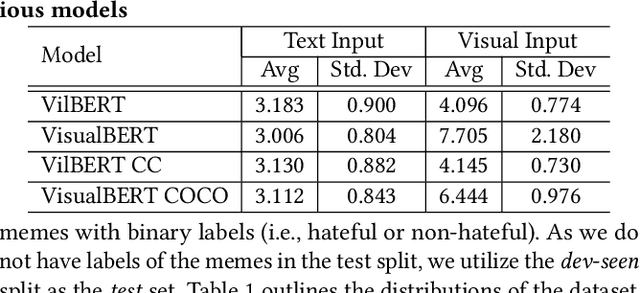
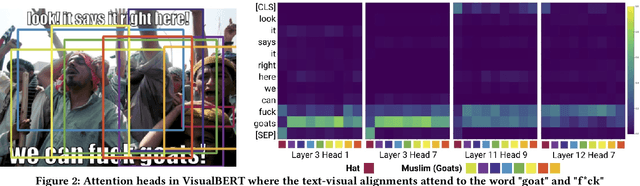

Hateful meme detection is a new multimodal task that has gained significant traction in academic and industry research communities. Recently, researchers have applied pre-trained visual-linguistic models to perform the multimodal classification task, and some of these solutions have yielded promising results. However, what these visual-linguistic models learn for the hateful meme classification task remains unclear. For instance, it is unclear if these models are able to capture the derogatory or slurs references in multimodality (i.e., image and text) of the hateful memes. To fill this research gap, this paper propose three research questions to improve our understanding of these visual-linguistic models performing the hateful meme classification task. We found that the image modality contributes more to the hateful meme classification task, and the visual-linguistic models are able to perform visual-text slurs grounding to a certain extent. Our error analysis also shows that the visual-linguistic models have acquired biases, which resulted in false-positive predictions.
Jekyll: Attacking Medical Image Diagnostics using Deep Generative Models
Apr 05, 2021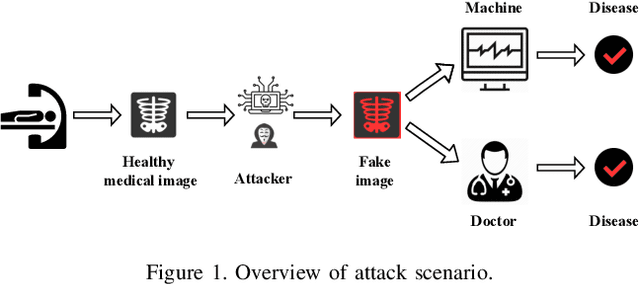
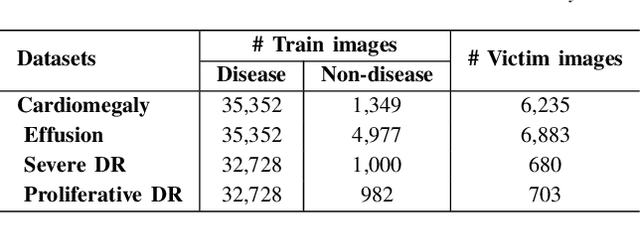
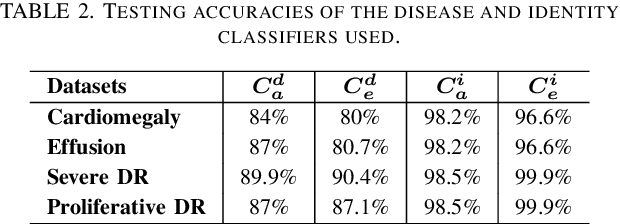
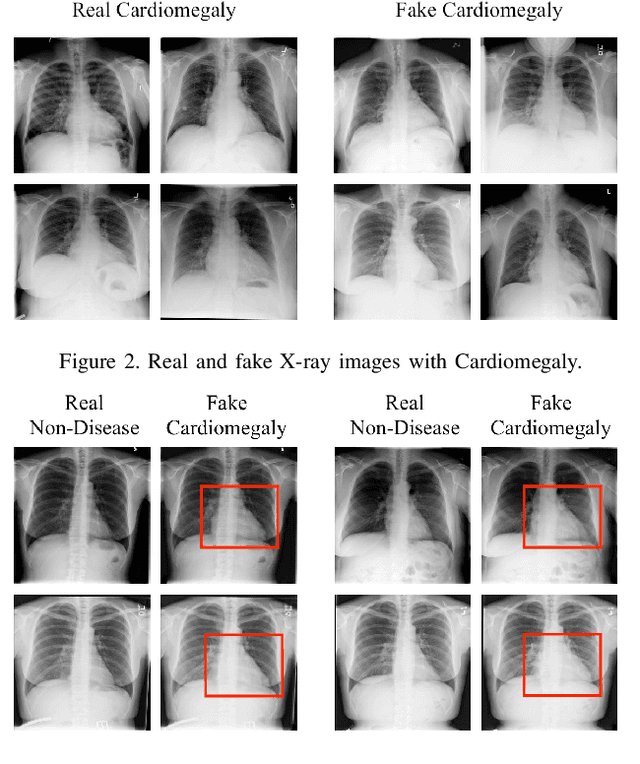
Advances in deep neural networks (DNNs) have shown tremendous promise in the medical domain. However, the deep learning tools that are helping the domain, can also be used against it. Given the prevalence of fraud in the healthcare domain, it is important to consider the adversarial use of DNNs in manipulating sensitive data that is crucial to patient healthcare. In this work, we present the design and implementation of a DNN-based image translation attack on biomedical imagery. More specifically, we propose Jekyll, a neural style transfer framework that takes as input a biomedical image of a patient and translates it to a new image that indicates an attacker-chosen disease condition. The potential for fraudulent claims based on such generated 'fake' medical images is significant, and we demonstrate successful attacks on both X-rays and retinal fundus image modalities. We show that these attacks manage to mislead both medical professionals and algorithmic detection schemes. Lastly, we also investigate defensive measures based on machine learning to detect images generated by Jekyll.
RPLHR-CT Dataset and Transformer Baseline for Volumetric Super-Resolution from CT Scans
Jun 13, 2022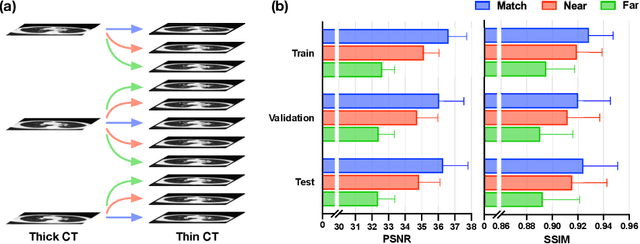
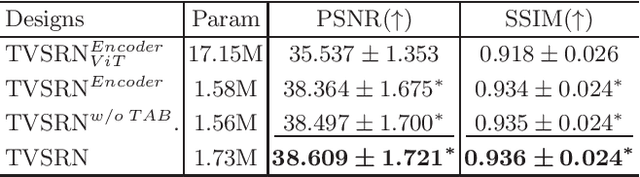
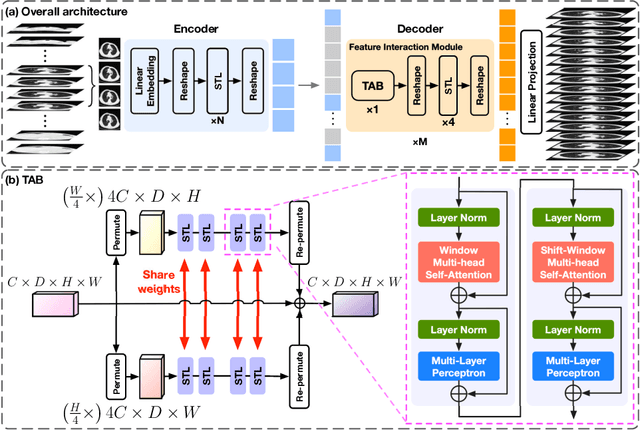
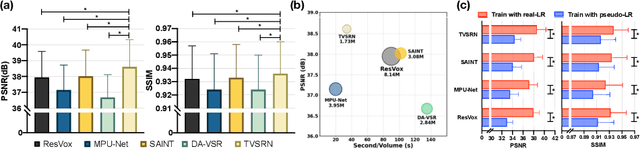
In clinical practice, anisotropic volumetric medical images with low through-plane resolution are commonly used due to short acquisition time and lower storage cost. Nevertheless, the coarse resolution may lead to difficulties in medical diagnosis by either physicians or computer-aided diagnosis algorithms. Deep learning-based volumetric super-resolution (SR) methods are feasible ways to improve resolution, with convolutional neural networks (CNN) at their core. Despite recent progress, these methods are limited by inherent properties of convolution operators, which ignore content relevance and cannot effectively model long-range dependencies. In addition, most of the existing methods use pseudo-paired volumes for training and evaluation, where pseudo low-resolution (LR) volumes are generated by a simple degradation of their high-resolution (HR) counterparts. However, the domain gap between pseudo- and real-LR volumes leads to the poor performance of these methods in practice. In this paper, we build the first public real-paired dataset RPLHR-CT as a benchmark for volumetric SR, and provide baseline results by re-implementing four state-of-the-art CNN-based methods. Considering the inherent shortcoming of CNN, we also propose a transformer volumetric super-resolution network (TVSRN) based on attention mechanisms, dispensing with convolutions entirely. This is the first research to use a pure transformer for CT volumetric SR. The experimental results show that TVSRN significantly outperforms all baselines on both PSNR and SSIM. Moreover, the TVSRN method achieves a better trade-off between the image quality, the number of parameters, and the running time. Data and code are available at https://github.com/smilenaxx/RPLHR-CT.
Towards Open-World Text-Guided Face Image Generation and Manipulation
Apr 18, 2021



The existing text-guided image synthesis methods can only produce limited quality results with at most \mbox{$\text{256}^2$} resolution and the textual instructions are constrained in a small Corpus. In this work, we propose a unified framework for both face image generation and manipulation that produces diverse and high-quality images with an unprecedented resolution at 1024 from multimodal inputs. More importantly, our method supports open-world scenarios, including both image and text, without any re-training, fine-tuning, or post-processing. To be specific, we propose a brand new paradigm of text-guided image generation and manipulation based on the superior characteristics of a pretrained GAN model. Our proposed paradigm includes two novel strategies. The first strategy is to train a text encoder to obtain latent codes that align with the hierarchically semantic of the aforementioned pretrained GAN model. The second strategy is to directly optimize the latent codes in the latent space of the pretrained GAN model with guidance from a pretrained language model. The latent codes can be randomly sampled from a prior distribution or inverted from a given image, which provides inherent supports for both image generation and manipulation from multi-modal inputs, such as sketches or semantic labels, with textual guidance. To facilitate text-guided multi-modal synthesis, we propose the Multi-Modal CelebA-HQ, a large-scale dataset consisting of real face images and corresponding semantic segmentation map, sketch, and textual descriptions. Extensive experiments on the introduced dataset demonstrate the superior performance of our proposed method. Code and data are available at https://github.com/weihaox/TediGAN.
CONSENT: Context Sensitive Transformer for Bold Words Classification
May 16, 2022



We present CONSENT, a simple yet effective CONtext SENsitive Transformer framework for context-dependent object classification within a fully-trainable end-to-end deep learning pipeline. We exemplify the proposed framework on the task of bold words detection proving state-of-the-art results. Given an image containing text of unknown font-types (e.g. Arial, Calibri, Helvetica), unknown language, taken under various degrees of illumination, angle distortion and scale variation, we extract all the words and learn a context-dependent binary classification (i.e. bold versus non-bold) using an end-to-end transformer-based neural network ensemble. To prove the extensibility of our framework, we demonstrate competitive results against state-of-the-art for the game of rock-paper-scissors by training the model to determine the winner given a sequence with $2$ pictures depicting hand poses.
Median Pixel Difference Convolutional Network for Robust Face Recognition
May 30, 2022
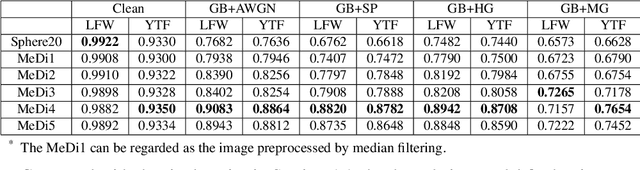
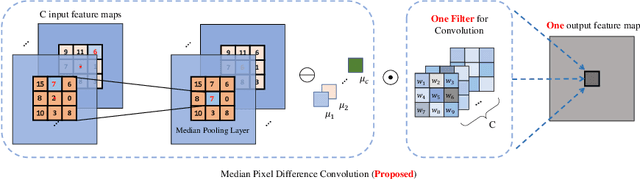
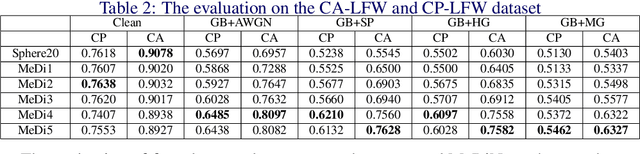
Face recognition is one of the most active tasks in computer vision and has been widely used in the real world. With great advances made in convolutional neural networks (CNN), lots of face recognition algorithms have achieved high accuracy on various face datasets. However, existing face recognition algorithms based on CNNs are vulnerable to noise. Noise corrupted image patterns could lead to false activations, significantly decreasing face recognition accuracy in noisy situations. To equip CNNs with built-in robustness to noise of different levels, we proposed a Median Pixel Difference Convolutional Network (MeDiNet) by replacing some traditional convolutional layers with the proposed novel Median Pixel Difference Convolutional Layer (MeDiConv) layer. The proposed MeDiNet integrates the idea of traditional multiscale median filtering with deep CNNs. The MeDiNet is tested on the four face datasets (LFW, CA-LFW, CP-LFW, and YTF) with versatile settings on blur kernels, noise intensities, scales, and JPEG quality factors. Extensive experiments show that our MeDiNet can effectively remove noisy pixels in the feature map and suppress the negative impact of noise, leading to achieving limited accuracy loss under these practical noises compared with the standard CNN under clean conditions.
In-Orbit Lunar Satellite Image Super Resolution for Selective Data Transmission
Oct 19, 2021Rapid technological advancements have tremendously increased the data acquisition capabilities of remote sensing satellites. However, the data utilization efficiency in satellite missions is very low. This growing data also escalates the cost required for data downlink transmission and post-processing. Selective data transmission based on in-orbit inferences will address these issues to a great extent. Therefore, to decrease the cost of the satellite mission, we propose a novel system design for selective data transmission, based on in-orbit inferences. As the resolution of images plays a critical role in making precise inferences, we also include in-orbit super-resolution (SR) in the system design. We introduce a new image reconstruction technique and a unique loss function to enable the execution of the SR model on low-power devices suitable for satellite environments. We present a residual dense non-local attention network (RDNLA) that provides enhanced super-resolution outputs to improve the SR performance. SR experiments on Kaguya digital ortho maps (DOMs) demonstrate that the proposed SR algorithm outperforms the residual dense network (RDN) in terms of PSNR and block-sensitive PSNR by a margin of +0.1 dB and +0.19 dB, respectively. The proposed SR system consumes 48% less memory and 67% less peak instantaneous power than the standard SR model, RDN, making it more suitable for execution on a low-powered device platform.
Camera View Adjustment Prediction for Improving Image Composition
Apr 15, 2021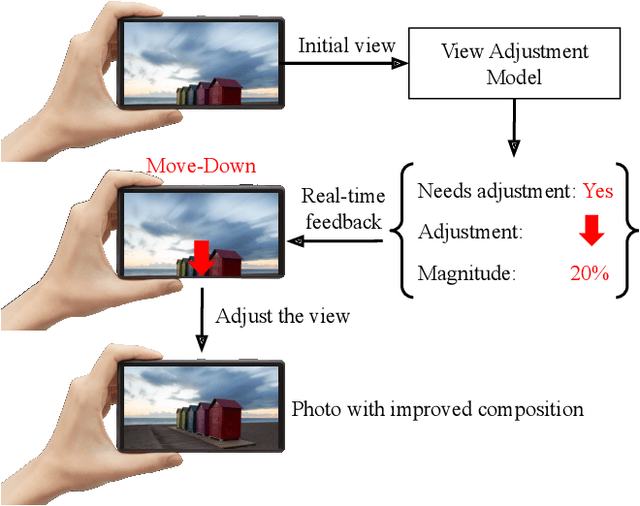
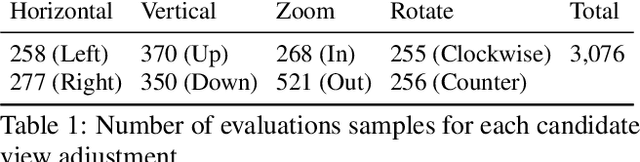


Image composition plays an important role in the quality of a photo. However, not every camera user possesses the knowledge and expertise required for capturing well-composed photos. While post-capture cropping can improve the composition sometimes, it does not work in many common scenarios in which the photographer needs to adjust the camera view to capture the best shot. To address this issue, we propose a deep learning-based approach that provides suggestions to the photographer on how to adjust the camera view before capturing. By optimizing the composition before a photo is captured, our system helps photographers to capture better photos. As there is no publicly-available dataset for this task, we create a view adjustment dataset by repurposing existing image cropping datasets. Furthermore, we propose a two-stage semi-supervised approach that utilizes both labeled and unlabeled images for training a view adjustment model. Experiment results show that the proposed semi-supervised approach outperforms the corresponding supervised alternatives, and our user study results show that the suggested view adjustment improves image composition 79% of the time.