 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Collaborative Intelligence Orchestration: Inconsistency-Based Fusion of Semi-Supervised Learning and Active Learning
Jun 07, 2022
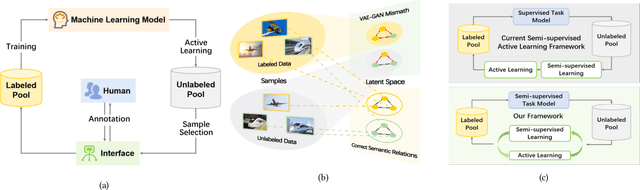
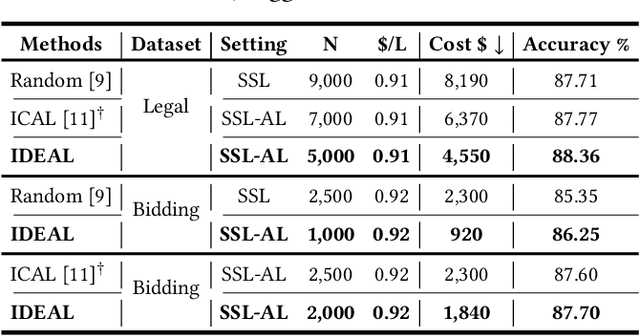
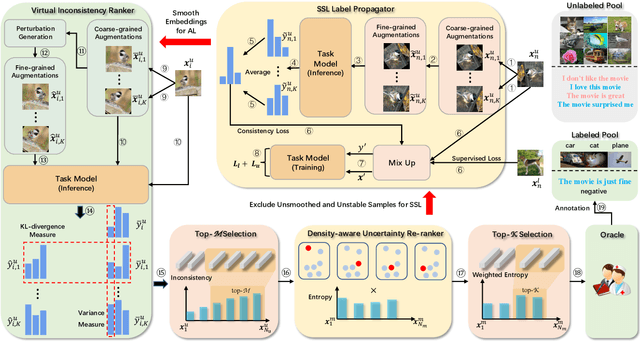
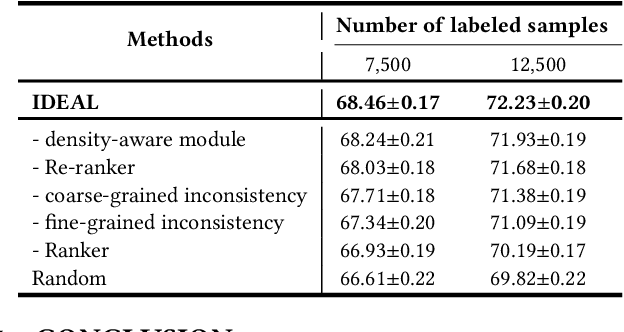
While annotating decent amounts of data to satisfy sophisticated learning models can be cost-prohibitive for many real-world applications. Active learning (AL) and semi-supervised learning (SSL) are two effective, but often isolated, means to alleviate the data-hungry problem. Some recent studies explored the potential of combining AL and SSL to better probe the unlabeled data. However, almost all these contemporary SSL-AL works use a simple combination strategy, ignoring SSL and AL's inherent relation. Further, other methods suffer from high computational costs when dealing with large-scale, high-dimensional datasets. Motivated by the industry practice of labeling data, we propose an innovative Inconsistency-based virtual aDvErsarial Active Learning (IDEAL) algorithm to further investigate SSL-AL's potential superiority and achieve mutual enhancement of AL and SSL, i.e., SSL propagates label information to unlabeled samples and provides smoothed embeddings for AL, while AL excludes samples with inconsistent predictions and considerable uncertainty for SSL. We estimate unlabeled samples' inconsistency by augmentation strategies of different granularities, including fine-grained continuous perturbation exploration and coarse-grained data transformations. Extensive experiments, in both text and image domains, validate the effectiveness of the proposed algorithm, comparing it against state-of-the-art baselines. Two real-world case studies visualize the practical industrial value of applying and deploying the proposed data sampling algorithm.
Evaluating the Generalization Ability of Super-Resolution Networks
May 14, 2022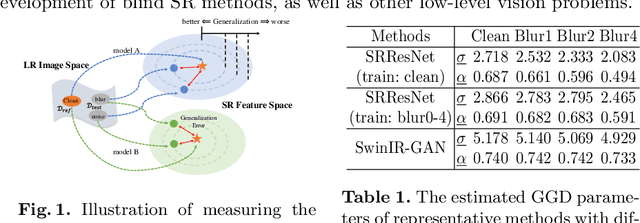


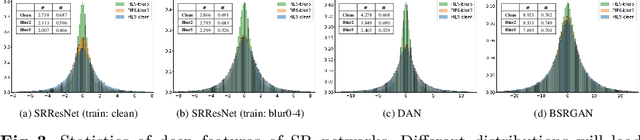
Performance and generalization ability are two important aspects to evaluate deep learning models. However, research on the generalization ability of Super-Resolution (SR) networks is currently absent. We make the first attempt to propose a Generalization Assessment Index for SR networks, namely SRGA. SRGA exploits the statistical characteristics of internal features of deep networks, not output images to measure the generalization ability. Specially, it is a non-parametric and non-learning metric. To better validate our method, we collect a patch-based image evaluation set (PIES) that includes both synthetic and real-world images, covering a wide range of degradations. With SRGA and PIES dataset, we benchmark existing SR models on the generalization ability. This work could lay the foundation for future research on model generalization in low-level vision.
Human Perception Modeling for Automatic Natural Image Matting
Mar 31, 2021
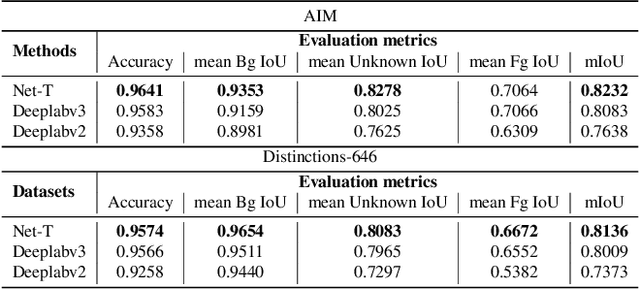
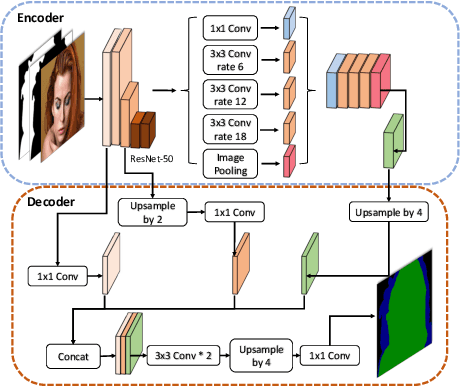

Natural image matting aims to precisely separate foreground objects from background using alpha matte. Fully automatic natural image matting without external annotation is quite challenging. Well-performed matting methods usually require accurate handcrafted trimap as extra input, which is labor-intensive and time-consuming, while the performance of automatic trimap generation method of dilating foreground segmentation fluctuates with segmentation quality. In this paper, we argue that how to handle trade-off of additional information input is a major issue in automatic matting, which we decompose into two subtasks: trimap and alpha estimation. By leveraging easily-accessible coarse annotations and modeling alpha matte handmade process of capturing rough foreground/background/transition boundary and carving delicate details in transition region, we propose an intuitively-designed trimap-free two-stage matting approach without additional annotations, e.g. trimap and background image. Specifically, given an image and its coarse foreground segmentation, Trimap Generation Network estimates probabilities of foreground, unknown, and background regions to guide alpha feature flow of our proposed Non-Local Matting network, which is equipped with trimap-guided global aggregation attention block. Experimental results show that our matting algorithm has competitive performance with current state-of-the-art methods in both trimap-free and trimap-needed aspects.
Multimodal Image-to-Image Translation via Mutual Information Estimation and Maximization
Aug 20, 2020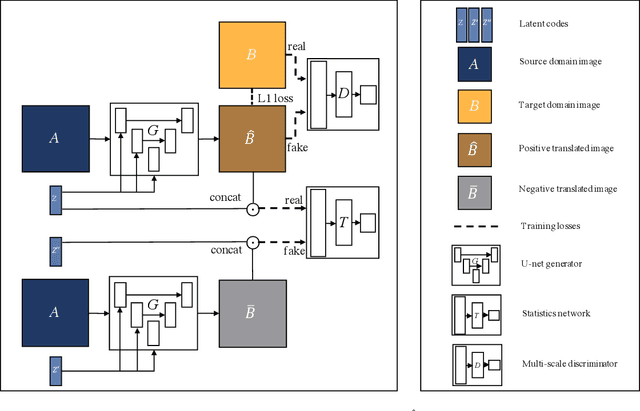
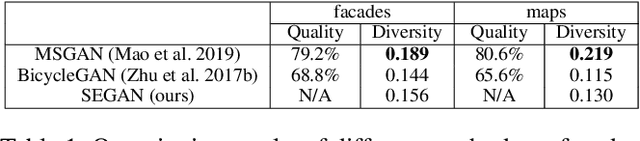

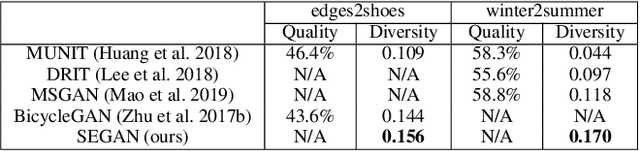
In this paper, we present a novel framework that can achieve multimodal image-to-image translation by simply encouraging the statistical dependence between the latent code and the output image in conditional generative adversarial networks. In addition, by incorporating a U-net generator into our framework, our method only needs to learn a one-sided translation model from the source image domain to the target image domain for both supervised and unsupervised multimodal image-to-image translation. Furthermore, our method also achieves disentanglement between the source domain content and the target domain style for free. We conduct experiments under supervised and unsupervised settings on various benchmark image-to-image translation datasets compared with the state-of-the-art methods, showing the effectiveness and simplicity of our method to achieve multimodal and high-quality results.
SemAffiNet: Semantic-Affine Transformation for Point Cloud Segmentation
May 26, 2022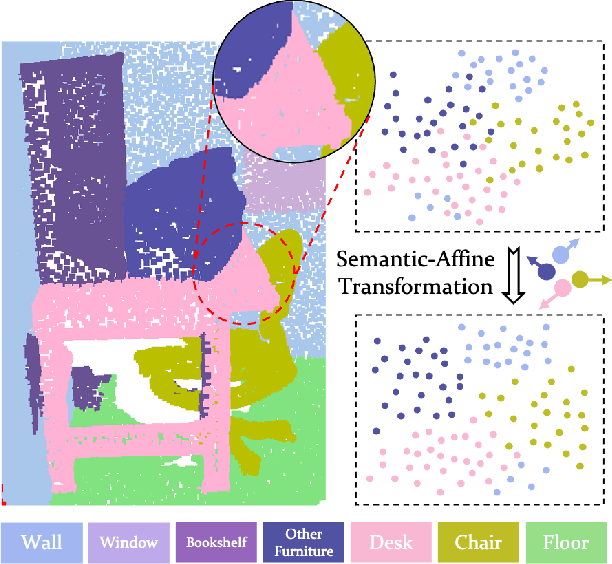
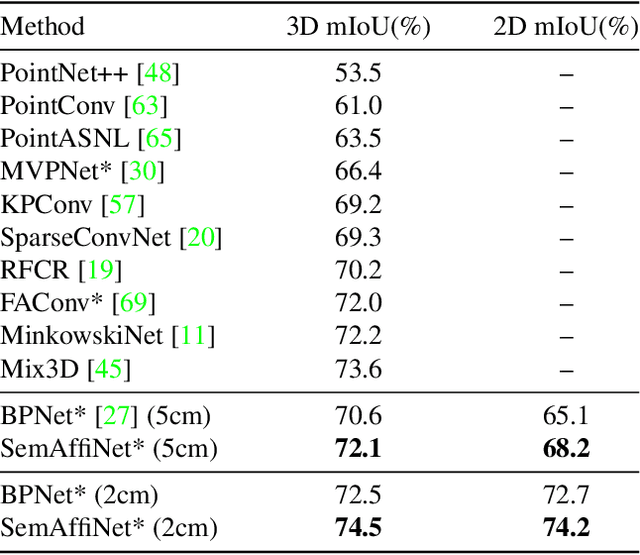
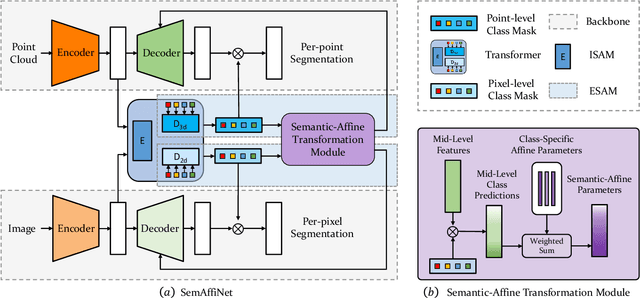
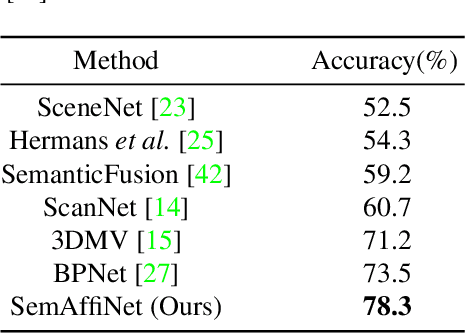
Conventional point cloud semantic segmentation methods usually employ an encoder-decoder architecture, where mid-level features are locally aggregated to extract geometric information. However, the over-reliance on these class-agnostic local geometric representations may raise confusion between local parts from different categories that are similar in appearance or spatially adjacent. To address this issue, we argue that mid-level features can be further enhanced with semantic information, and propose semantic-affine transformation that transforms features of mid-level points belonging to different categories with class-specific affine parameters. Based on this technique, we propose SemAffiNet for point cloud semantic segmentation, which utilizes the attention mechanism in the Transformer module to implicitly and explicitly capture global structural knowledge within local parts for overall comprehension of each category. We conduct extensive experiments on the ScanNetV2 and NYUv2 datasets, and evaluate semantic-affine transformation on various 3D point cloud and 2D image segmentation baselines, where both qualitative and quantitative results demonstrate the superiority and generalization ability of our proposed approach. Code is available at https://github.com/wangzy22/SemAffiNet.
Domain Adaptation for Medical Image Analysis: A Survey
Feb 18, 2021
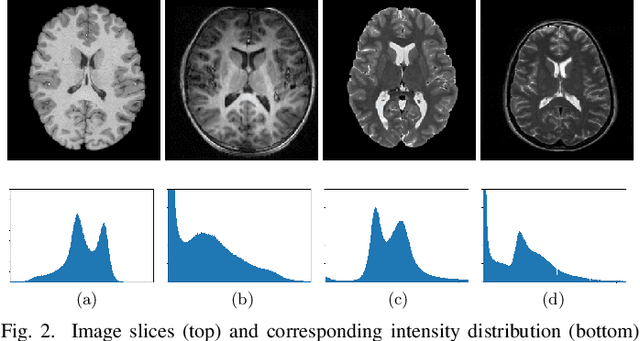
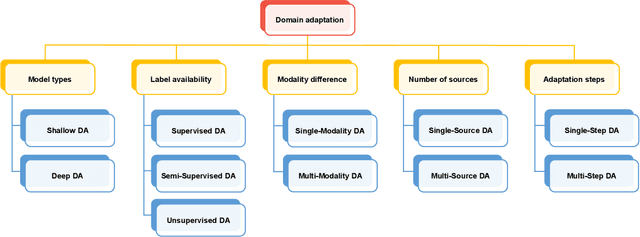
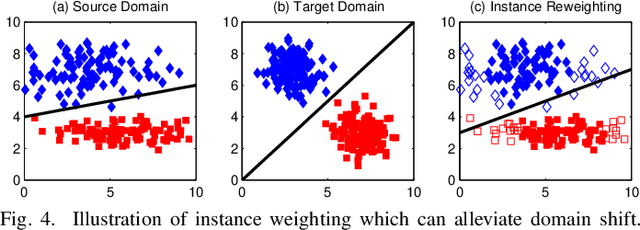
Machine learning techniques used in computer-aided medical image analysis usually suffer from the domain shift problem caused by different distributions between source/reference data and target data. As a promising solution, domain adaptation has attracted considerable attention in recent years. The aim of this paper is to survey the recent advances of domain adaptation methods in medical image analysis. We first present the motivation of introducing domain adaptation techniques to tackle domain heterogeneity issues for medical image analysis. Then we provide a review of recent domain adaptation models in various medical image analysis tasks. We categorize the existing methods into shallow and deep models, and each of them is further divided into supervised, semi-supervised and unsupervised methods. We also provide a brief summary of the benchmark medical image datasets that support current domain adaptation research. This survey will enable researchers to gain a better understanding of the current status, challenges.
On the Kullback-Leibler divergence between pairwise isotropic Gaussian-Markov random fields
Mar 24, 2022
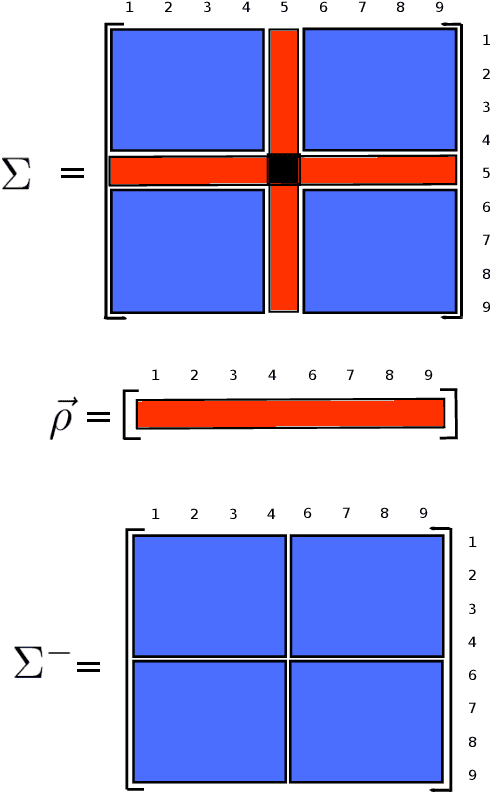
The Kullback-Leibler divergence or relative entropy is an information-theoretic measure between statistical models that play an important role in measuring a distance between random variables. In the study of complex systems, random fields are mathematical structures that models the interaction between these variables by means of an inverse temperature parameter, responsible for controlling the spatial dependence structure along the field. In this paper, we derive closed-form expressions for the Kullback-Leibler divergence between two pairwise isotropic Gaussian-Markov random fields in both univariate and multivariate cases. The proposed equation allows the development of novel similarity measures in image processing and machine learning applications, such as image denoising and unsupervised metric learning.
Matching Visual Features to Hierarchical Semantic Topics for Image Paragraph Captioning
May 10, 2021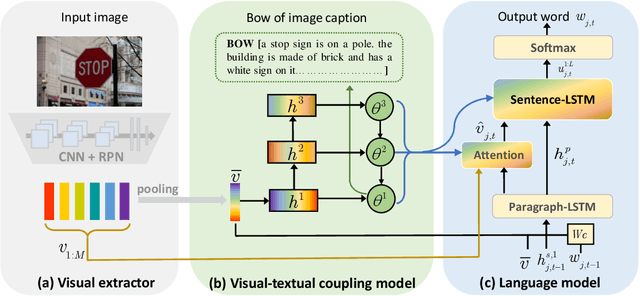
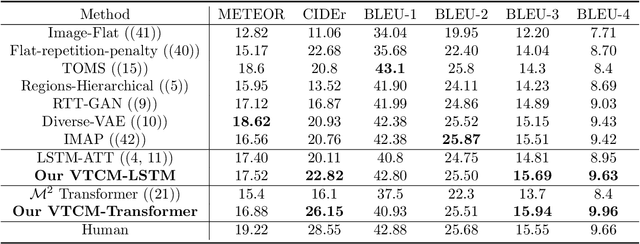
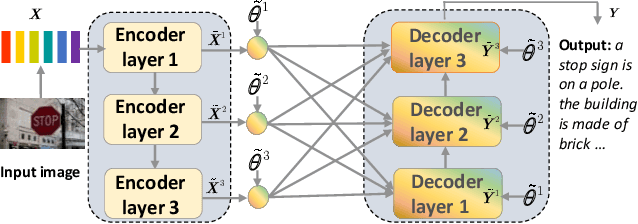
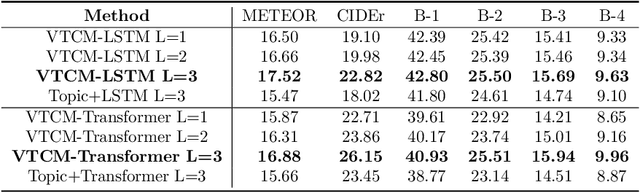
Observing a set of images and their corresponding paragraph-captions, a challenging task is to learn how to produce a semantically coherent paragraph to describe the visual content of an image. Inspired by recent successes in integrating semantic topics into this task, this paper develops a plug-and-play hierarchical-topic-guided image paragraph generation framework, which couples a visual extractor with a deep topic model to guide the learning of a language model. To capture the correlations between the image and text at multiple levels of abstraction and learn the semantic topics from images, we design a variational inference network to build the mapping from image features to textual captions. To guide the paragraph generation, the learned hierarchical topics and visual features are integrated into the language model, including Long Short-Term Memory (LSTM) and Transformer, and jointly optimized. Experiments on public dataset demonstrate that the proposed models, which are competitive with many state-of-the-art approaches in terms of standard evaluation metrics, can be used to both distill interpretable multi-layer topics and generate diverse and coherent captions.
In-Orbit Lunar Satellite Image Super Resolution for Selective Data Transmission
Oct 19, 2021Rapid technological advancements have tremendously increased the data acquisition capabilities of remote sensing satellites. However, the data utilization efficiency in satellite missions is very low. This growing data also escalates the cost required for data downlink transmission and post-processing. Selective data transmission based on in-orbit inferences will address these issues to a great extent. Therefore, to decrease the cost of the satellite mission, we propose a novel system design for selective data transmission, based on in-orbit inferences. As the resolution of images plays a critical role in making precise inferences, we also include in-orbit super-resolution (SR) in the system design. We introduce a new image reconstruction technique and a unique loss function to enable the execution of the SR model on low-power devices suitable for satellite environments. We present a residual dense non-local attention network (RDNLA) that provides enhanced super-resolution outputs to improve the SR performance. SR experiments on Kaguya digital ortho maps (DOMs) demonstrate that the proposed SR algorithm outperforms the residual dense network (RDN) in terms of PSNR and block-sensitive PSNR by a margin of +0.1 dB and +0.19 dB, respectively. The proposed SR system consumes 48% less memory and 67% less peak instantaneous power than the standard SR model, RDN, making it more suitable for execution on a low-powered device platform.
From CNNs to Vision Transformers -- A Comprehensive Evaluation of Deep Learning Models for Histopathology
Apr 11, 2022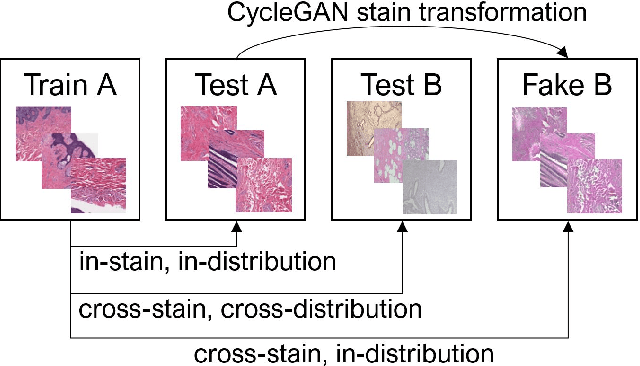
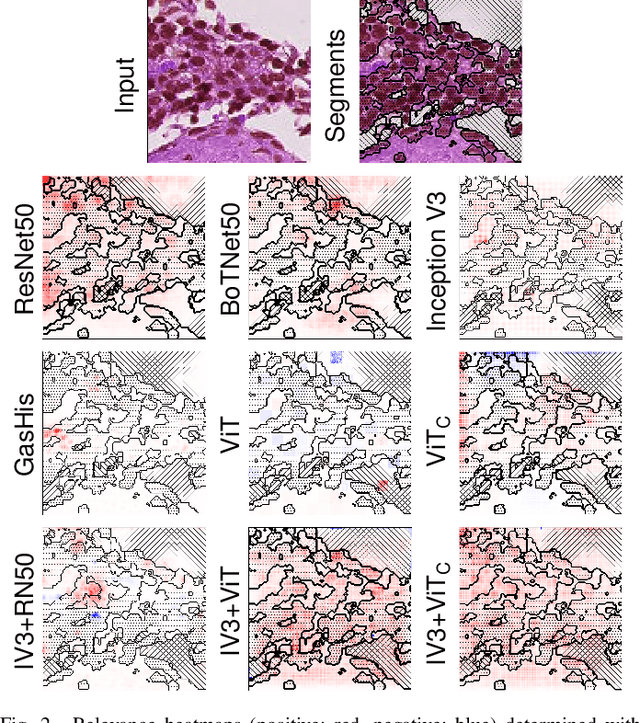
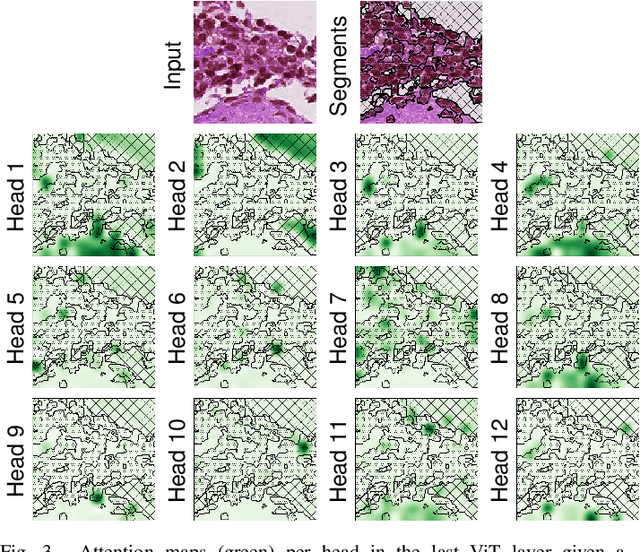
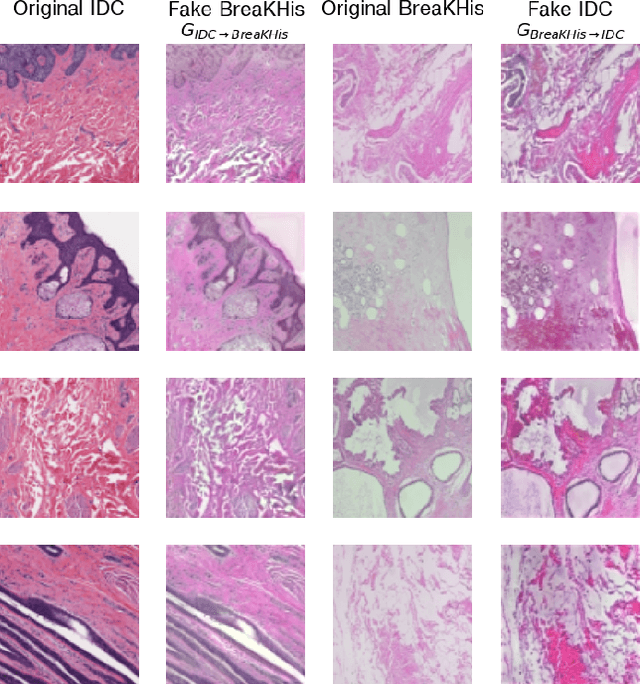
While machine learning is currently transforming the field of histopathology, the domain lacks a comprehensive evaluation of state-of-the-art models based on essential but complementary quality requirements beyond a mere classification accuracy. In order to fill this gap, we conducted an extensive evaluation by benchmarking a wide range of classification models, including recent vision transformers, convolutional neural networks and hybrid models comprising transformer and convolutional models. We thoroughly tested the models on five widely used histopathology datasets containing whole slide images of breast, gastric, and colorectal cancer and developed a novel approach using an image-to-image translation model to assess the robustness of a cancer classification model against stain variations. Further, we extended existing interpretability methods to previously unstudied models and systematically reveal insights of the models' classification strategies that allow for plausibility checks and systematic comparisons. The study resulted in specific model recommendations for practitioners as well as putting forward a general methodology to quantify a model's quality according to complementary requirements that can be transferred to future model architectures.