 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Holistic Approach to Measure Sample-level Adversarial Vulnerability and its Utility in Building Trustworthy Systems
May 05, 2022
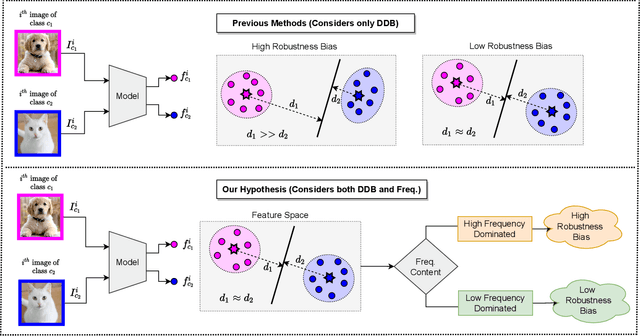
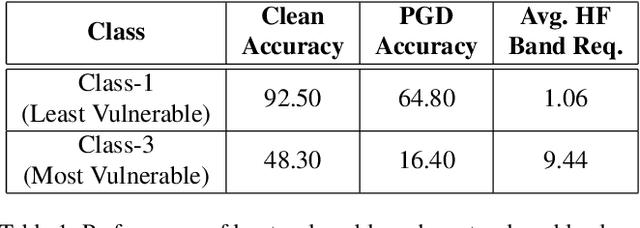
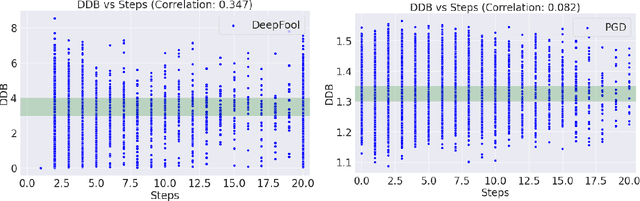

Adversarial attack perturbs an image with an imperceptible noise, leading to incorrect model prediction. Recently, a few works showed inherent bias associated with such attack (robustness bias), where certain subgroups in a dataset (e.g. based on class, gender, etc.) are less robust than others. This bias not only persists even after adversarial training, but often results in severe performance discrepancies across these subgroups. Existing works characterize the subgroup's robustness bias by only checking individual sample's proximity to the decision boundary. In this work, we argue that this measure alone is not sufficient and validate our argument via extensive experimental analysis. It has been observed that adversarial attacks often corrupt the high-frequency components of the input image. We, therefore, propose a holistic approach for quantifying adversarial vulnerability of a sample by combining these different perspectives, i.e., degree of model's reliance on high-frequency features and the (conventional) sample-distance to the decision boundary. We demonstrate that by reliably estimating adversarial vulnerability at the sample level using the proposed holistic metric, it is possible to develop a trustworthy system where humans can be alerted about the incoming samples that are highly likely to be misclassified at test time. This is achieved with better precision when our holistic metric is used over individual measures. To further corroborate the utility of the proposed holistic approach, we perform knowledge distillation in a limited-sample setting. We observe that the student network trained with the subset of samples selected using our combined metric performs better than both the competing baselines, viz., where samples are selected randomly or based on their distances to the decision boundary.
Multi-organ Segmentation Network with Adversarial Performance Validator
Apr 16, 2022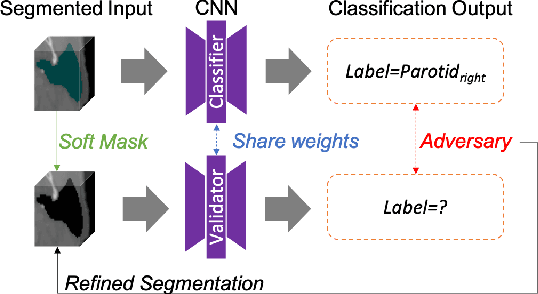
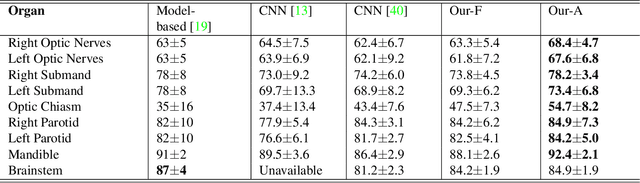
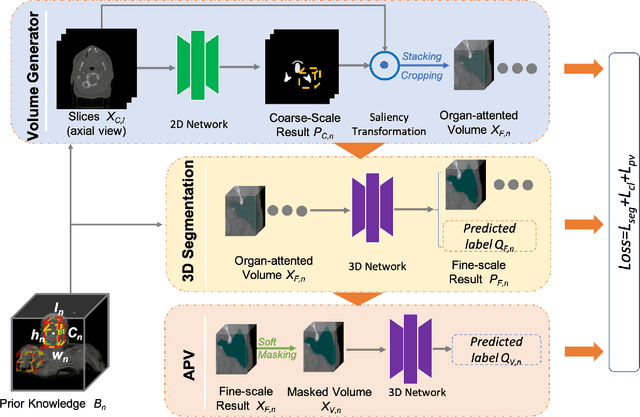
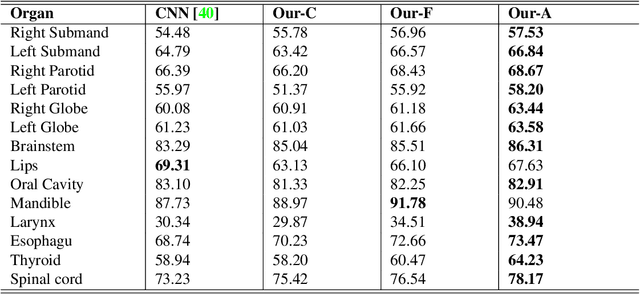
CT organ segmentation on computed tomography (CT) images becomes a significant brick for modern medical image analysis, supporting clinic workflows in multiple domains. Previous segmentation methods include 2D convolution neural networks (CNN) based approaches, fed by CT image slices that lack the structural knowledge in axial view, and 3D CNN-based methods with the expensive computation cost in multi-organ segmentation applications. This paper introduces an adversarial performance validation network into a 2D-to-3D segmentation framework. The classifier and performance validator competition contribute to accurate segmentation results via back-propagation. The proposed network organically converts the 2D-coarse result to 3D high-quality segmentation masks in a coarse-to-fine manner, allowing joint optimization to improve segmentation accuracy. Besides, the structural information of one specific organ is depicted by a statistics-meaningful prior bounding box, which is transformed into a global feature leveraging the learning process in 3D fine segmentation. The experiments on the NIH pancreas segmentation dataset demonstrate the proposed network achieves state-of-the-art accuracy on small organ segmentation and outperforms the previous best. High accuracy is also reported on multi-organ segmentation in a dataset collected by ourselves.
R2RNet: Low-light Image Enhancement via Real-low to Real-normal Network
Jun 28, 2021

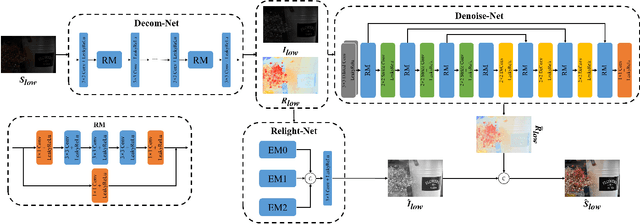

Images captured in weak illumination conditions will seriously degrade the image quality. Solving a series of degradation of low-light images can effectively improve the visual quality of the image and the performance of high-level visual tasks. In this paper, we propose a novel Real-low to Real-normal Network for low-light image enhancement, dubbed R2RNet, based on the Retinex theory, which includes three subnets: a Decom-Net, a Denoise-Net, and a Relight-Net. These three subnets are used for decomposing, denoising, and contrast enhancement, respectively. Unlike most previous methods trained on synthetic images, we collect the first Large-Scale Real-World paired low/normal-light images dataset (LSRW dataset) for training. Our method can properly improve the contrast and suppress noise simultaneously. Extensive experiments on publicly available datasets demonstrate that our method outperforms the existing state-of-the-art methods by a large margin both quantitatively and visually. And we also show that the performance of the high-level visual task (\emph{i.e.} face detection) can be effectively improved by using the enhanced results obtained by our method in low-light conditions. Our codes and the LSRW dataset are available at: https://github.com/abcdef2000/R2RNet.
Self-Supervised Learning of Multi-Object Keypoints for Robotic Manipulation
May 17, 2022
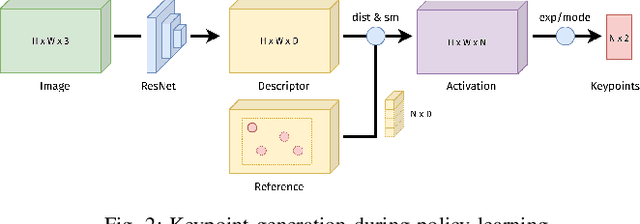

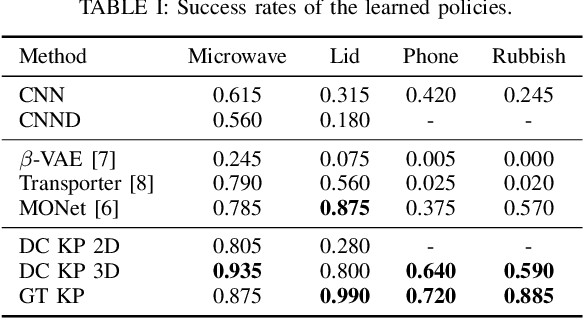
In recent years, policy learning methods using either reinforcement or imitation have made significant progress. However, both techniques still suffer from being computationally expensive and requiring large amounts of training data. This problem is especially prevalent in real-world robotic manipulation tasks, where access to ground truth scene features is not available and policies are instead learned from raw camera observations. In this paper, we demonstrate the efficacy of learning image keypoints via the Dense Correspondence pretext task for downstream policy learning. Extending prior work to challenging multi-object scenes, we show that our model can be trained to deal with important problems in representation learning, primarily scale-invariance and occlusion. We evaluate our approach on diverse robot manipulation tasks, compare it to other visual representation learning approaches, and demonstrate its flexibility and effectiveness for sample-efficient policy learning.
3SD: Self-Supervised Saliency Detection With No Labels
Mar 09, 2022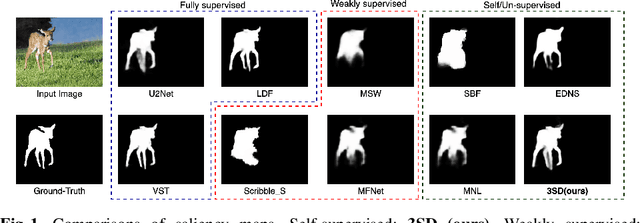
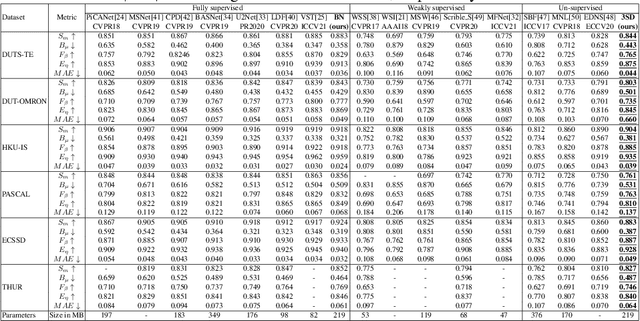

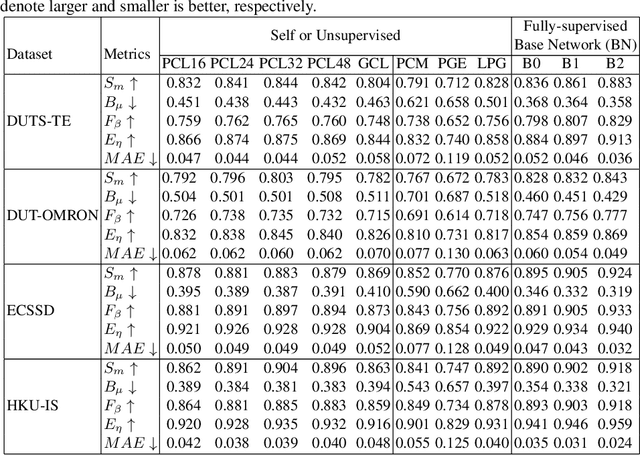
We present a conceptually simple self-supervised method for saliency detection. Our method generates and uses pseudo-ground truth labels for training. The generated pseudo-GT labels don't require any kind of human annotations (e.g., pixel-wise labels or weak labels like scribbles). Recent works show that features extracted from classification tasks provide important saliency cues like structure and semantic information of salient objects in the image. Our method, called 3SD, exploits this idea by adding a branch for a self-supervised classification task in parallel with salient object detection, to obtain class activation maps (CAM maps). These CAM maps along with the edges of the input image are used to generate the pseudo-GT saliency maps to train our 3SD network. Specifically, we propose a contrastive learning-based training on multiple image patches for the classification task. We show the multi-patch classification with contrastive loss improves the quality of the CAM maps compared to naive classification on the entire image. Experiments on six benchmark datasets demonstrate that without any labels, our 3SD method outperforms all existing weakly supervised and unsupervised methods, and its performance is on par with the fully-supervised methods. Code is available at :https://github.com/rajeevyasarla/3SD
MultiPathGAN: Structure Preserving Stain Normalization using Unsupervised Multi-domain Adversarial Network with Perception Loss
Apr 20, 2022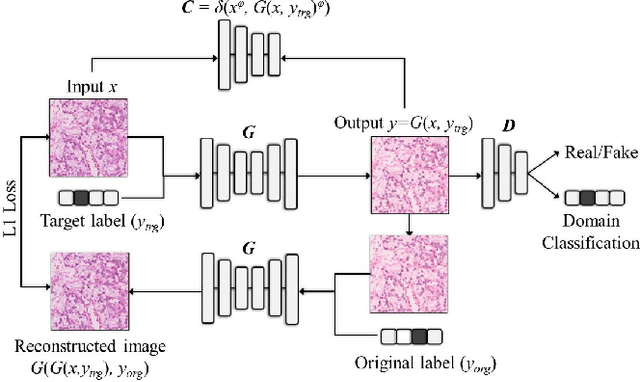
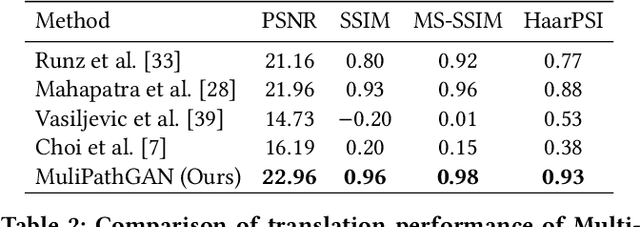
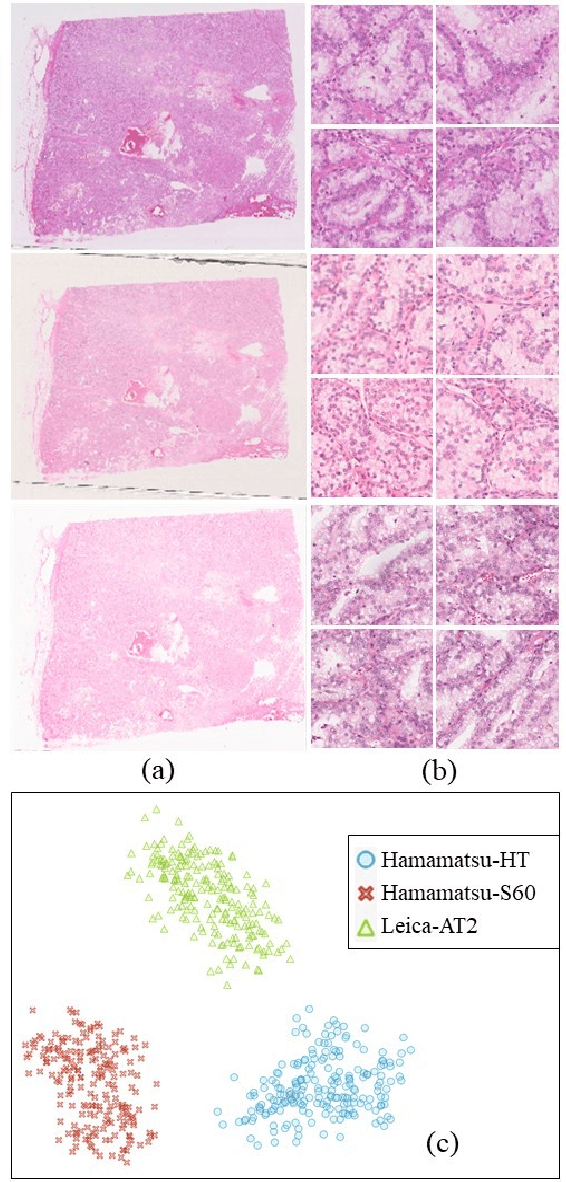
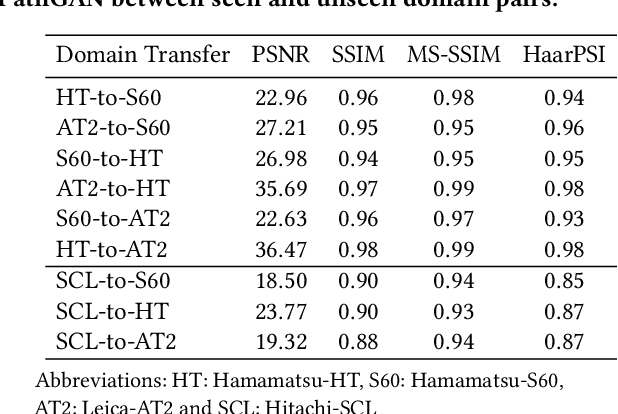
Histopathology relies on the analysis of microscopic tissue images to diagnose disease. A crucial part of tissue preparation is staining whereby a dye is used to make the salient tissue components more distinguishable. However, differences in laboratory protocols and scanning devices result in significant confounding appearance variation in the corresponding images. This variation increases both human error and the inter-rater variability, as well as hinders the performance of automatic or semi-automatic methods. In the present paper we introduce an unsupervised adversarial network to translate (and hence normalize) whole slide images across multiple data acquisition domains. Our key contributions are: (i) an adversarial architecture which learns across multiple domains with a single generator-discriminator network using an information flow branch which optimizes for perceptual loss, and (ii) the inclusion of an additional feature extraction network during training which guides the transformation network to keep all the structural features in the tissue image intact. We: (i) demonstrate the effectiveness of the proposed method firstly on H\&E slides of 120 cases of kidney cancer, as well as (ii) show the benefits of the approach on more general problems, such as flexible illumination based natural image enhancement and light source adaptation.
CLMLF:A Contrastive Learning and Multi-Layer Fusion Method for Multimodal Sentiment Detection
Apr 12, 2022
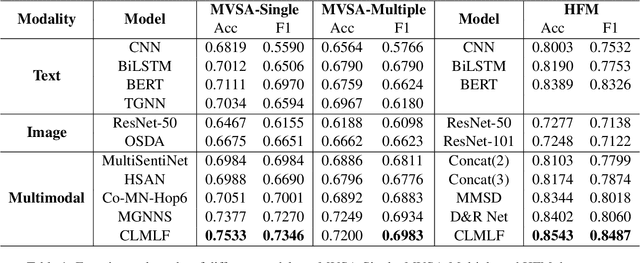
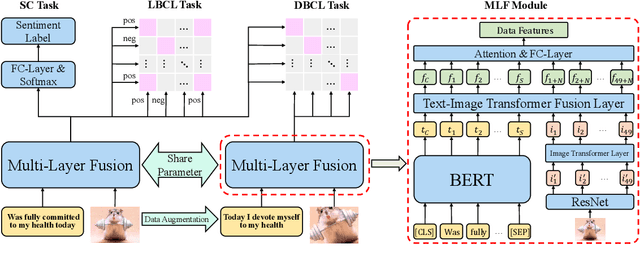
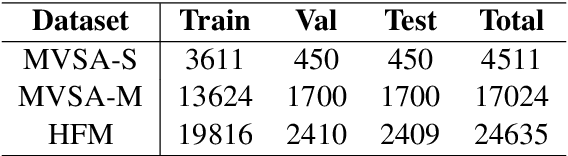
Compared with unimodal data, multimodal data can provide more features to help the model analyze the sentiment of data. Previous research works rarely consider token-level feature fusion, and few works explore learning the common features related to sentiment in multimodal data to help the model fuse multimodal features. In this paper, we propose a Contrastive Learning and Multi-Layer Fusion (CLMLF) method for multimodal sentiment detection. Specifically, we first encode text and image to obtain hidden representations, and then use a multi-layer fusion module to align and fuse the token-level features of text and image. In addition to the sentiment analysis task, we also designed two contrastive learning tasks, label based contrastive learning and data based contrastive learning tasks, which will help the model learn common features related to sentiment in multimodal data. Extensive experiments conducted on three publicly available multimodal datasets demonstrate the effectiveness of our approach for multimodal sentiment detection compared with existing methods. The codes are available for use at https://github.com/Link-Li/CLMLF
Domain Adaptor Networks for Hyperspectral Image Recognition
Aug 03, 2021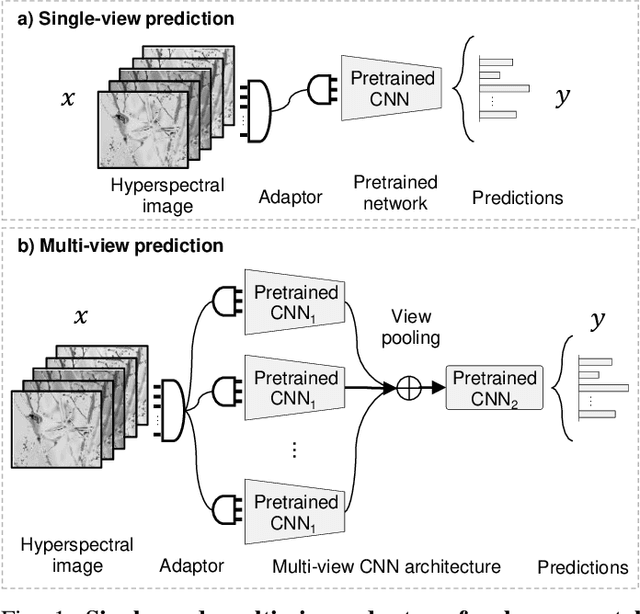
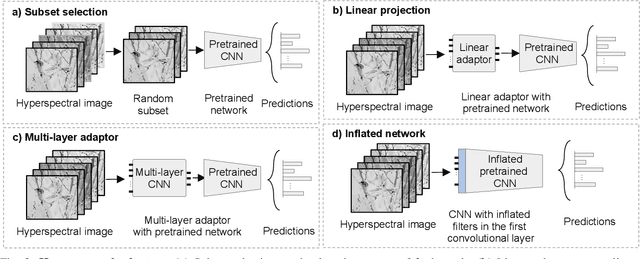
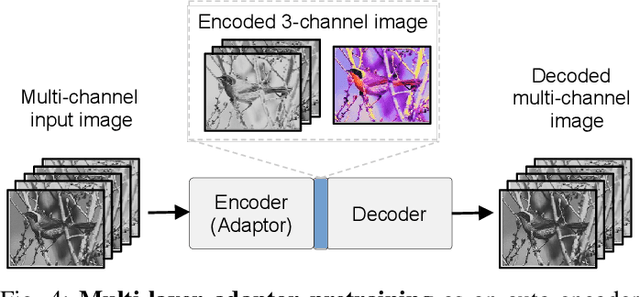
We consider the problem of adapting a network trained on three-channel color images to a hyperspectral domain with a large number of channels. To this end, we propose domain adaptor networks that map the input to be compatible with a network trained on large-scale color image datasets such as ImageNet. Adaptors enable learning on small hyperspectral datasets where training a network from scratch may not be effective. We investigate architectures and strategies for training adaptors and evaluate them on a benchmark consisting of multiple hyperspectral datasets. We find that simple schemes such as linear projection or subset selection are often the most effective, but can lead to a loss in performance in some cases. We also propose a novel multi-view adaptor where of the inputs are combined in an intermediate layer of the network in an order invariant manner that provides further improvements. We present extensive experiments by varying the number of training examples in the benchmark to characterize the accuracy and computational trade-offs offered by these adaptors.
Image Compression with Encoder-Decoder Matched Semantic Segmentation
Jan 24, 2021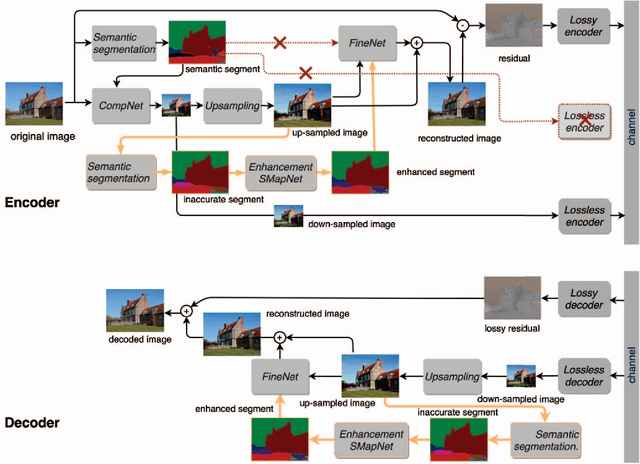

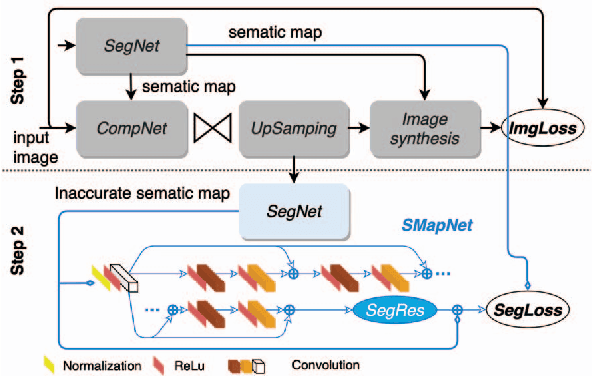
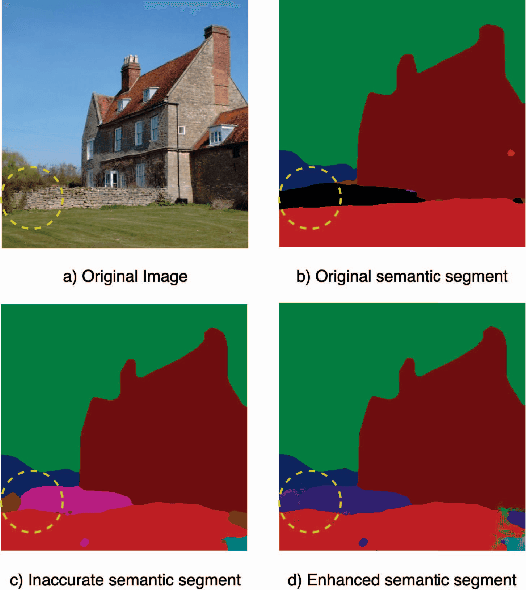
In recent years, layered image compression is demonstrated to be a promising direction, which encodes a compact representation of the input image and apply an up-sampling network to reconstruct the image. To further improve the quality of the reconstructed image, some works transmit the semantic segment together with the compressed image data. Consequently, the compression ratio is also decreased because extra bits are required for transmitting the semantic segment. To solve this problem, we propose a new layered image compression framework with encoder-decoder matched semantic segmentation (EDMS). And then, followed by the semantic segmentation, a special convolution neural network is used to enhance the inaccurate semantic segment. As a result, the accurate semantic segment can be obtained in the decoder without requiring extra bits. The experimental results show that the proposed EDMS framework can get up to 35.31% BD-rate reduction over the HEVC-based (BPG) codec, 5% bitrate, and 24% encoding time saving compare to the state-of-the-art semantic-based image codec.
Zero-Shot Text-to-Image Generation
Feb 24, 2021


Text-to-image generation has traditionally focused on finding better modeling assumptions for training on a fixed dataset. These assumptions might involve complex architectures, auxiliary losses, or side information such as object part labels or segmentation masks supplied during training. We describe a simple approach for this task based on a transformer that autoregressively models the text and image tokens as a single stream of data. With sufficient data and scale, our approach is competitive with previous domain-specific models when evaluated in a zero-shot fashion.