 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
All Mistakes Are Not Equal: Comprehensive Hierarchy Aware Multi-label Predictions (CHAMP)
Jun 17, 2022
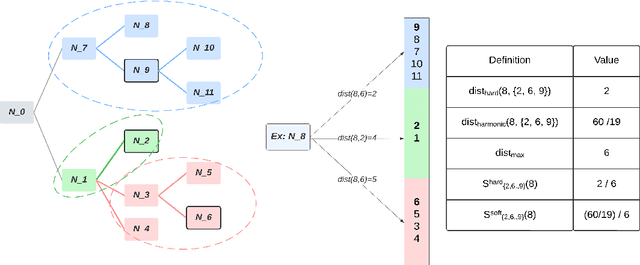
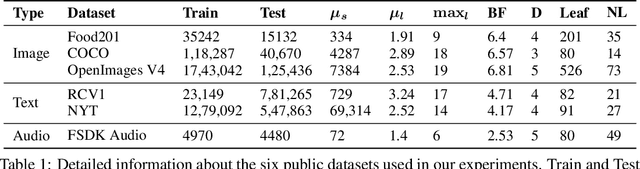
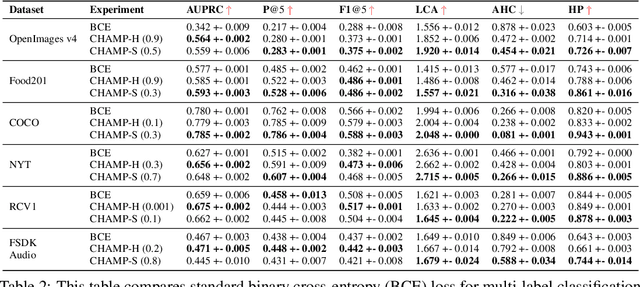
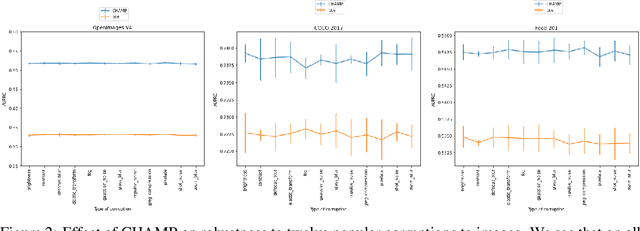
This paper considers the problem of Hierarchical Multi-Label Classification (HMC), where (i) several labels can be present for each example, and (ii) labels are related via a domain-specific hierarchy tree. Guided by the intuition that all mistakes are not equal, we present Comprehensive Hierarchy Aware Multi-label Predictions (CHAMP), a framework that penalizes a misprediction depending on its severity as per the hierarchy tree. While there have been works that apply such an idea to single-label classification, to the best of our knowledge, there are limited such works for multilabel classification focusing on the severity of mistakes. The key reason is that there is no clear way of quantifying the severity of a misprediction a priori in the multilabel setting. In this work, we propose a simple but effective metric to quantify the severity of a mistake in HMC, naturally leading to CHAMP. Extensive experiments on six public HMC datasets across modalities (image, audio, and text) demonstrate that incorporating hierarchical information leads to substantial gains as CHAMP improves both AUPRC (2.6% median percentage improvement) and hierarchical metrics (2.85% median percentage improvement), over stand-alone hierarchical or multilabel classification methods. Compared to standard multilabel baselines, CHAMP provides improved AUPRC in both robustness (8.87% mean percentage improvement ) and less data regimes. Further, our method provides a framework to enhance existing multilabel classification algorithms with better mistakes (18.1% mean percentage increment).
A Multi-purpose Real Haze Benchmark with Quantifiable Haze Levels and Ground Truth
Jun 13, 2022


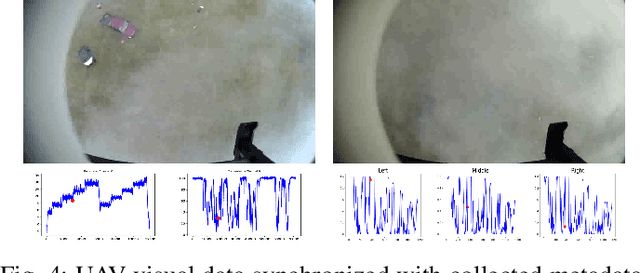
Imagery collected from outdoor visual environments is often degraded due to the presence of dense smoke or haze. A key challenge for research in scene understanding in these degraded visual environments (DVE) is the lack of representative benchmark datasets. These datasets are required to evaluate state-of-the-art object recognition and other computer vision algorithms in degraded settings. In this paper, we address some of these limitations by introducing the first paired real image benchmark dataset with hazy and haze-free images, and in-situ haze density measurements. This dataset was produced in a controlled environment with professional smoke generating machines that covered the entire scene, and consists of images captured from the perspective of both an unmanned aerial vehicle (UAV) and an unmanned ground vehicle (UGV). We also evaluate a set of representative state-of-the-art dehazing approaches as well as object detectors on the dataset. The full dataset presented in this paper, including the ground truth object classification bounding boxes and haze density measurements, is provided for the community to evaluate their algorithms at: https://a2i2-archangel.vision. A subset of this dataset has been used for the Object Detection in Haze Track of CVPR UG2 2022 challenge.
CASIA-Face-Africa: A Large-scale African Face Image Database
May 11, 2021
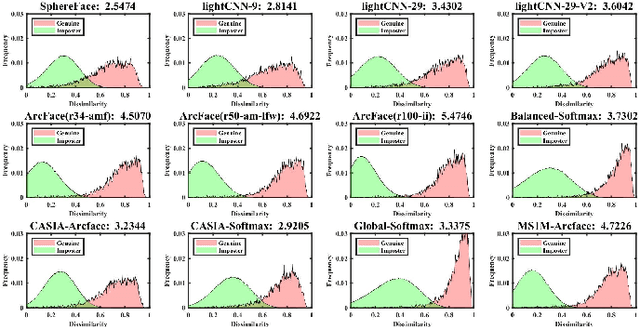
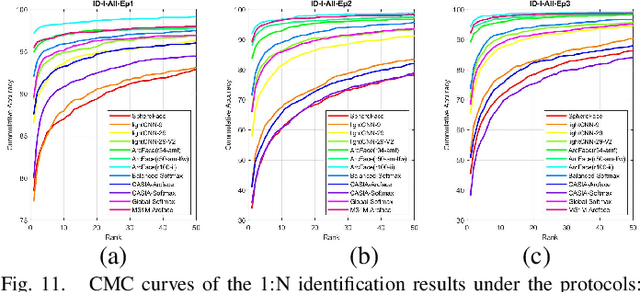

Face recognition is a popular and well-studied area with wide applications in our society. However, racial bias had been proven to be inherent in most State Of The Art (SOTA) face recognition systems. Many investigative studies on face recognition algorithms have reported higher false positive rates of African subjects cohorts than the other cohorts. Lack of large-scale African face image databases in public domain is one of the main restrictions in studying the racial bias problem of face recognition. To this end, we collect a face image database namely CASIA-Face-Africa which contains 38,546 images of 1,183 African subjects. Multi-spectral cameras are utilized to capture the face images under various illumination settings. Demographic attributes and facial expressions of the subjects are also carefully recorded. For landmark detection, each face image in the database is manually labeled with 68 facial keypoints. A group of evaluation protocols are constructed according to different applications, tasks, partitions and scenarios. The performances of SOTA face recognition algorithms without re-training are reported as baselines. The proposed database along with its face landmark annotations, evaluation protocols and preliminary results form a good benchmark to study the essential aspects of face biometrics for African subjects, especially face image preprocessing, face feature analysis and matching, facial expression recognition, sex/age estimation, ethnic classification, face image generation, etc. The database can be downloaded from our http://www.cripacsir.cn/dataset/
Neural Maximum A Posteriori Estimation on Unpaired Data for Motion Deblurring
Apr 26, 2022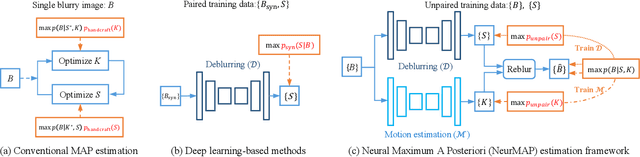
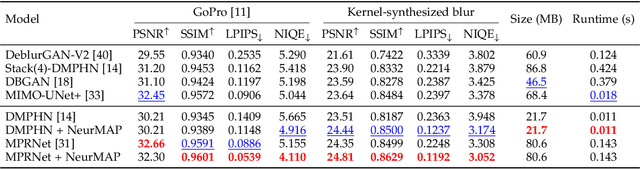

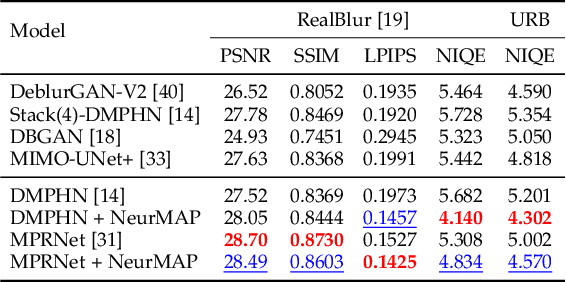
Real-world dynamic scene deblurring has long been a challenging task since paired blurry-sharp training data is unavailable. Conventional Maximum A Posteriori estimation and deep learning-based deblurring methods are restricted by handcrafted priors and synthetic blurry-sharp training pairs respectively, thereby failing to generalize to real dynamic blurriness. To this end, we propose a Neural Maximum A Posteriori (NeurMAP) estimation framework for training neural networks to recover blind motion information and sharp content from unpaired data. The proposed NeruMAP consists of a motion estimation network and a deblurring network which are trained jointly to model the (re)blurring process (i.e. likelihood function). Meanwhile, the motion estimation network is trained to explore the motion information in images by applying implicit dynamic motion prior, and in return enforces the deblurring network training (i.e. providing sharp image prior). The proposed NeurMAP is an orthogonal approach to existing deblurring neural networks, and is the first framework that enables training image deblurring networks on unpaired datasets. Experiments demonstrate our superiority on both quantitative metrics and visual quality over state-of-the-art methods. Codes are available on https://github.com/yjzhang96/NeurMAP-deblur.
Image Super-Resolution Quality Assessment: Structural Fidelity Versus Statistical Naturalness
May 15, 2021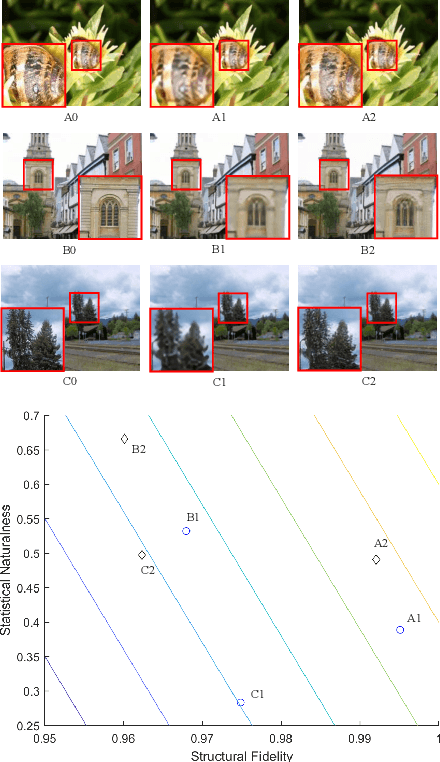
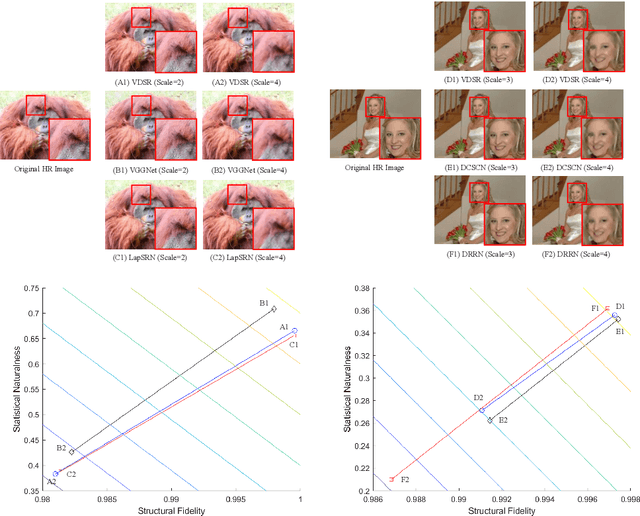
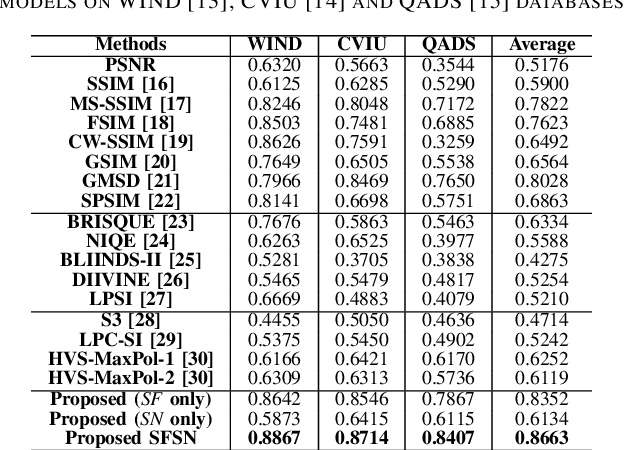
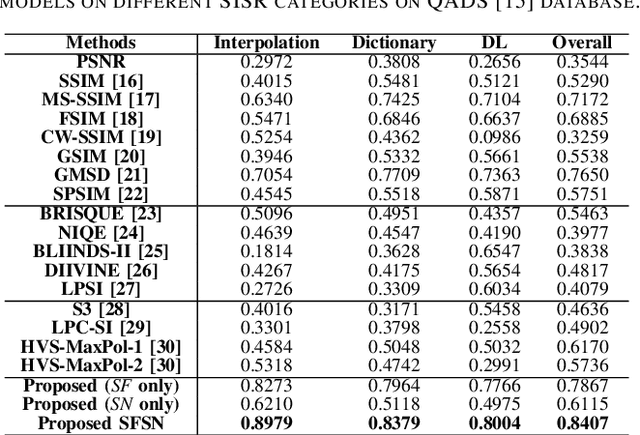
Single image super-resolution (SISR) algorithms reconstruct high-resolution (HR) images with their low-resolution (LR) counterparts. It is desirable to develop image quality assessment (IQA) methods that can not only evaluate and compare SISR algorithms, but also guide their future development. In this paper, we assess the quality of SISR generated images in a two-dimensional (2D) space of structural fidelity versus statistical naturalness. This allows us to observe the behaviors of different SISR algorithms as a tradeoff in the 2D space. Specifically, SISR methods are traditionally designed to achieve high structural fidelity but often sacrifice statistical naturalness, while recent generative adversarial network (GAN) based algorithms tend to create more natural-looking results but lose significantly on structural fidelity. Furthermore, such a 2D evaluation can be easily fused to a scalar quality prediction. Interestingly, we find that a simple linear combination of a straightforward local structural fidelity and a global statistical naturalness measures produce surprisingly accurate predictions of SISR image quality when tested using public subject-rated SISR image datasets. Code of the proposed SFSN model is publicly available at \url{https://github.com/weizhou-geek/SFSN}.
Discovering Object Masks with Transformers for Unsupervised Semantic Segmentation
Jun 13, 2022
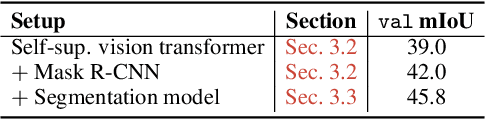
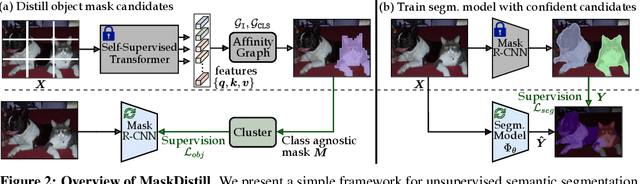
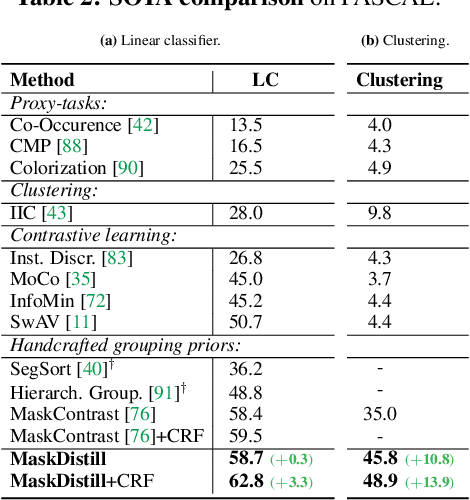
The task of unsupervised semantic segmentation aims to cluster pixels into semantically meaningful groups. Specifically, pixels assigned to the same cluster should share high-level semantic properties like their object or part category. This paper presents MaskDistill: a novel framework for unsupervised semantic segmentation based on three key ideas. First, we advocate a data-driven strategy to generate object masks that serve as a pixel grouping prior for semantic segmentation. This approach omits handcrafted priors, which are often designed for specific scene compositions and limit the applicability of competing frameworks. Second, MaskDistill clusters the object masks to obtain pseudo-ground-truth for training an initial object segmentation model. Third, we leverage this model to filter out low-quality object masks. This strategy mitigates the noise in our pixel grouping prior and results in a clean collection of masks which we use to train a final segmentation model. By combining these components, we can considerably outperform previous works for unsupervised semantic segmentation on PASCAL (+11% mIoU) and COCO (+4% mask AP50). Interestingly, as opposed to existing approaches, our framework does not latch onto low-level image cues and is not limited to object-centric datasets. The code and models will be made available.
Domain-Generalized Textured Surface Anomaly Detection
Mar 23, 2022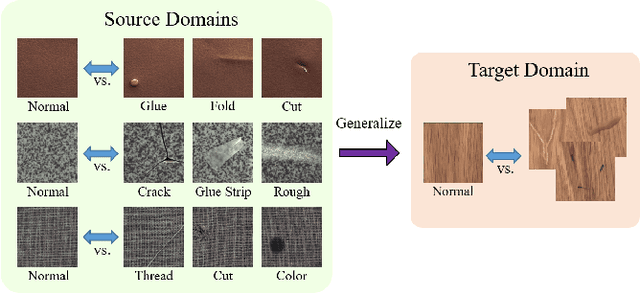
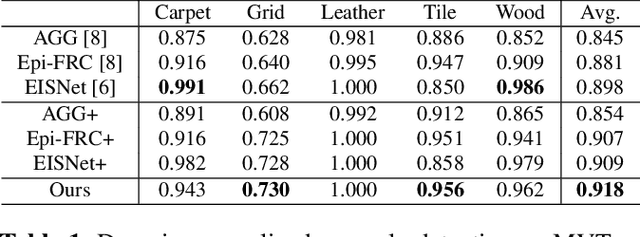
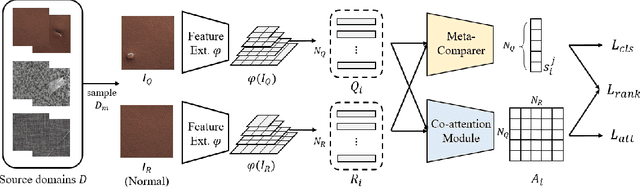
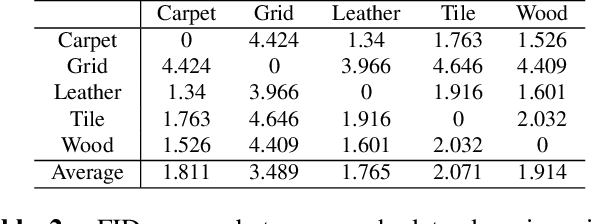
Anomaly detection aims to identify abnormal data that deviates from the normal ones, while typically requiring a sufficient amount of normal data to train the model for performing this task. Despite the success of recent anomaly detection methods, performing anomaly detection in an unseen domain remain a challenging task. In this paper, we address the task of domain-generalized textured surface anomaly detection. By observing normal and abnormal surface data across multiple source domains, our model is expected to be generalized to an unseen textured surface of interest, in which only a small number of normal data can be observed during testing. Although with only image-level labels observed in the training data, our patch-based meta-learning model exhibits promising generalization ability: not only can it generalize to unseen image domains, but it can also localize abnormal regions in the query image. Our experiments verify that our model performs favorably against state-of-the-art anomaly detection and domain generalization approaches in various settings.
Active Data Discovery: Mining Unknown Data using Submodular Information Measures
Jun 17, 2022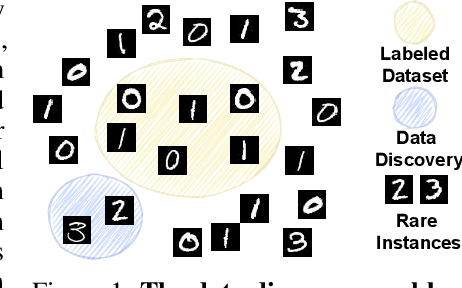
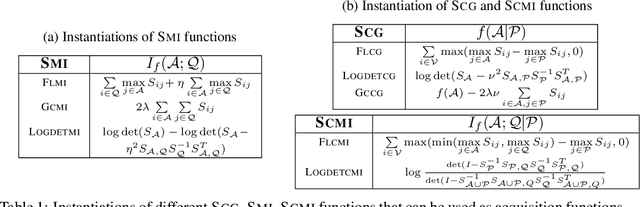
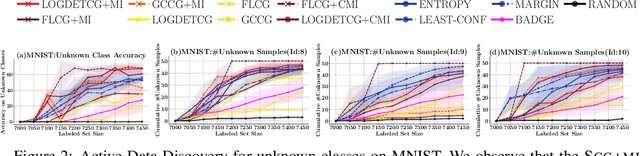
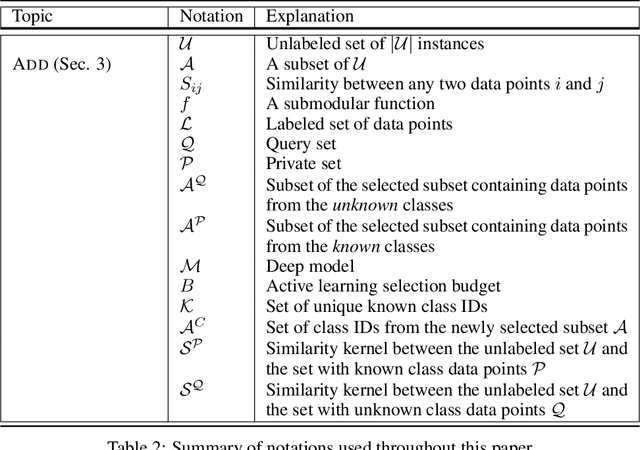
Active Learning is a very common yet powerful framework for iteratively and adaptively sampling subsets of the unlabeled sets with a human in the loop with the goal of achieving labeling efficiency. Most real world datasets have imbalance either in classes and slices, and correspondingly, parts of the dataset are rare. As a result, there has been a lot of work in designing active learning approaches for mining these rare data instances. Most approaches assume access to a seed set of instances which contain these rare data instances. However, in the event of more extreme rareness, it is reasonable to assume that these rare data instances (either classes or slices) may not even be present in the seed labeled set, and a critical need for the active learning paradigm is to efficiently discover these rare data instances. In this work, we provide an active data discovery framework which can mine unknown data slices and classes efficiently using the submodular conditional gain and submodular conditional mutual information functions. We provide a general algorithmic framework which works in a number of scenarios including image classification and object detection and works with both rare classes and rare slices present in the unlabeled set. We show significant accuracy and labeling efficiency gains with our approach compared to existing state-of-the-art active learning approaches for actively discovering these rare classes and slices.
AnomalyHop: An SSL-based Image Anomaly Localization Method
May 08, 2021

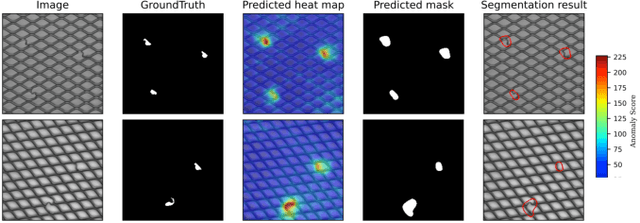
An image anomaly localization method based on the successive subspace learning (SSL) framework, called AnomalyHop, is proposed in this work. AnomalyHop consists of three modules: 1) feature extraction via successive subspace learning (SSL), 2) normality feature distributions modeling via Gaussian models, and 3) anomaly map generation and fusion. Comparing with state-of-the-art image anomaly localization methods based on deep neural networks (DNNs), AnomalyHop is mathematically transparent, easy to train, and fast in its inference speed. Besides, its area under the ROC curve (ROC-AUC) performance on the MVTec AD dataset is 95.9%, which is among the best of several benchmarking methods. Our codes are publicly available at Github.
BagFlip: A Certified Defense against Data Poisoning
May 26, 2022



Machine learning models are vulnerable to data-poisoning attacks, in which an attacker maliciously modifies the training set to change the prediction of a learned model. In a trigger-less attack, the attacker can modify the training set but not the test inputs, while in a backdoor attack the attacker can also modify test inputs. Existing model-agnostic defense approaches either cannot handle backdoor attacks or do not provide effective certificates (i.e., a proof of a defense). We present BagFlip, a model-agnostic certified approach that can effectively defend against both trigger-less and backdoor attacks. We evaluate BagFlip on image classification and malware detection datasets. BagFlip is equal to or more effective than the state-of-the-art approaches for trigger-less attacks and more effective than the state-of-the-art approaches for backdoor attacks.