 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning self-calibrated optic disc and cup segmentation from multi-rater annotations
Jun 14, 2022
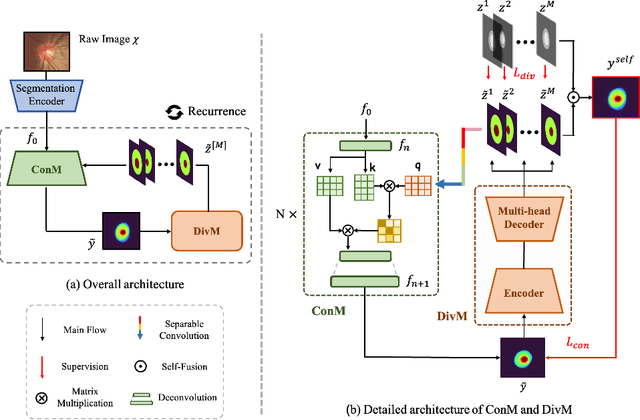
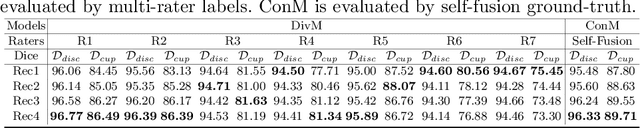
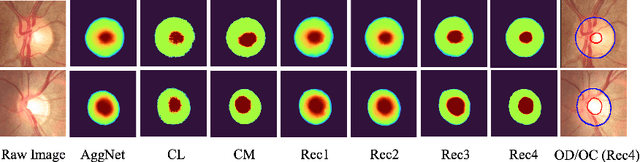
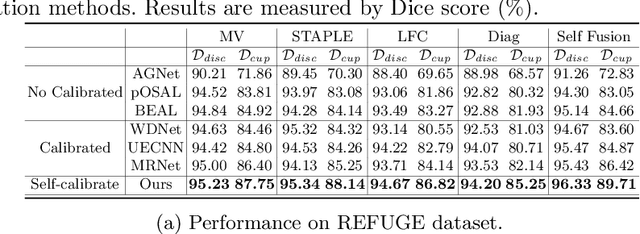
The segmentation of optic disc(OD) and optic cup(OC) from fundus images is an important fundamental task for glaucoma diagnosis. In the clinical practice, it is often necessary to collect opinions from multiple experts to obtain the final OD/OC annotation. This clinical routine helps to mitigate the individual bias. But when data is multiply annotated, standard deep learning models will be inapplicable. In this paper, we propose a novel neural network framework to learn OD/OC segmentation from multi-rater annotations. The segmentation results are self-calibrated through the iterative optimization of multi-rater expertness estimation and calibrated OD/OC segmentation. In this way, the proposed method can realize a mutual improvement of both tasks and finally obtain a refined segmentation result. Specifically, we propose Diverging Model(DivM) and Converging Model(ConM) to process the two tasks respectively. ConM segments the raw image based on the multi-rater expertness map provided by DivM. DivM generates multi-rater expertness map from the segmentation mask provided by ConM. The experiment results show that by recurrently running ConM and DivM, the results can be self-calibrated so as to outperform a range of state-of-the-art(SOTA) multi-rater segmentation methods.
Better Teacher Better Student: Dynamic Prior Knowledge for Knowledge Distillation
Jun 14, 2022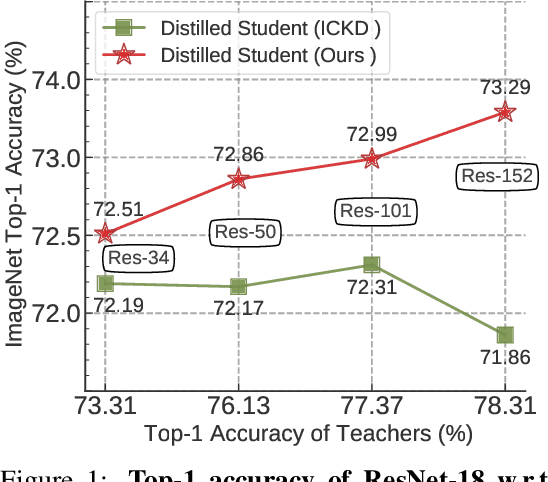
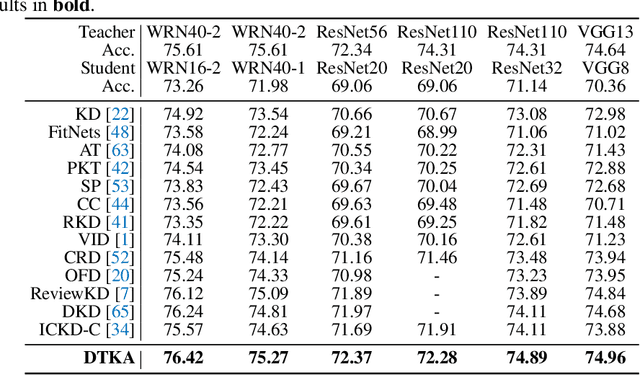
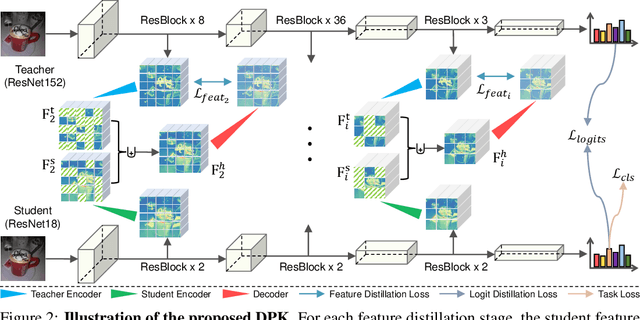

Knowledge distillation (KD) has shown very promising capabilities in transferring learning representations from large models (teachers) to small models (students). However, as the capacity gap between students and teachers becomes larger, existing KD methods fail to achieve better results. Our work shows that the 'prior knowledge' is vital to KD, especially when applying large teachers. Particularly, we propose the dynamic prior knowledge (DPK), which integrates part of the teacher's features as the prior knowledge before the feature distillation. This means that our method also takes the teacher's feature as `input', not just `target'. Besides, we dynamically adjust the ratio of the prior knowledge during the training phase according to the feature gap, thus guiding the student in an appropriate difficulty. To evaluate the proposed method, we conduct extensive experiments on two image classification benchmarks (i.e. CIFAR100 and ImageNet) and an object detection benchmark (i.e. MS COCO). The results demonstrate the superiority of our method in performance under varying settings. More importantly, our DPK makes the performance of the student model is positively correlated with that of the teacher model, which means that we can further boost the accuracy of students by applying larger teachers. Our codes will be publicly available for the reproducibility.
Generative Adversarial Network Applications in Creating a Meta-Universe
Jan 23, 2022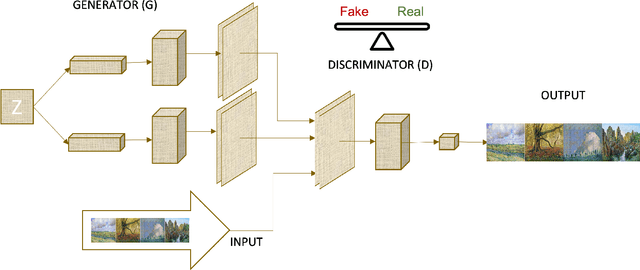


Generative Adversarial Networks (GANs) are machine learning methods that are used in many important and novel applications. For example, in imaging science, GANs are effectively utilized in generating image datasets, photographs of human faces, image and video captioning, image-to-image translation, text-to-image translation, video prediction, and 3D object generation to name a few. In this paper, we discuss how GANs can be used to create an artificial world. More specifically, we discuss how GANs help to describe an image utilizing image/video captioning methods and how to translate the image to a new image using image-to-image translation frameworks in a theme we desire. We articulate how GANs impact creating a customized world.
Decoupling Predictions in Distributed Learning for Multi-Center Left Atrial MRI Segmentation
Jun 10, 2022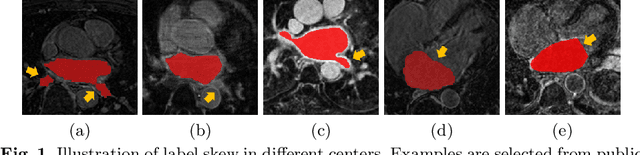
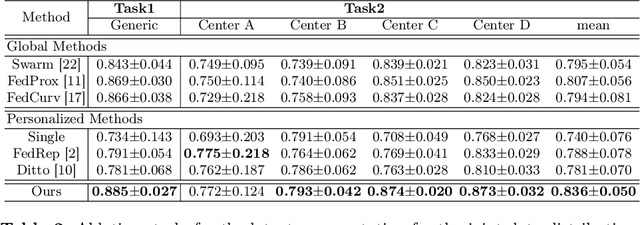

Distributed learning has shown great potential in medical image analysis. It allows to use multi-center training data with privacy protection. However, data distributions in local centers can vary from each other due to different imaging vendors, and annotation protocols. Such variation degrades the performance of learning-based methods. To mitigate the influence, two groups of methods have been proposed for different aims, i.e., the global methods and the personalized methods. The former are aimed to improve the performance of a single global model for all test data from unseen centers (known as generic data); while the latter target multiple models for each center (denoted as local data). However, little has been researched to achieve both goals simultaneously. In this work, we propose a new framework of distributed learning that bridges the gap between two groups, and improves the performance for both generic and local data. Specifically, our method decouples the predictions for generic data and local data, via distribution-conditioned adaptation matrices. Results on multi-center left atrial (LA) MRI segmentation showed that our method demonstrated superior performance over existing methods on both generic and local data. Our code is available at https://github.com/key1589745/decouple_predict
Fairness for Image Generation with Uncertain Sensitive Attributes
Jul 02, 2021
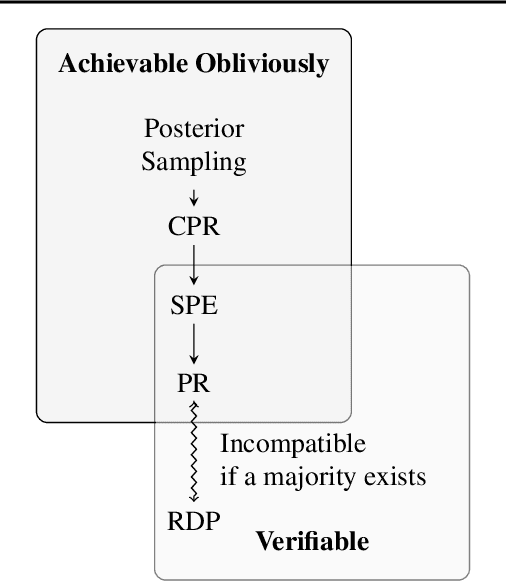
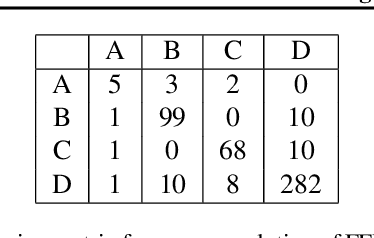
This work tackles the issue of fairness in the context of generative procedures, such as image super-resolution, which entail different definitions from the standard classification setting. Moreover, while traditional group fairness definitions are typically defined with respect to specified protected groups -- camouflaging the fact that these groupings are artificial and carry historical and political motivations -- we emphasize that there are no ground truth identities. For instance, should South and East Asians be viewed as a single group or separate groups? Should we consider one race as a whole or further split by gender? Choosing which groups are valid and who belongs in them is an impossible dilemma and being "fair" with respect to Asians may require being "unfair" with respect to South Asians. This motivates the introduction of definitions that allow algorithms to be \emph{oblivious} to the relevant groupings. We define several intuitive notions of group fairness and study their incompatibilities and trade-offs. We show that the natural extension of demographic parity is strongly dependent on the grouping, and \emph{impossible} to achieve obliviously. On the other hand, the conceptually new definition we introduce, Conditional Proportional Representation, can be achieved obliviously through Posterior Sampling. Our experiments validate our theoretical results and achieve fair image reconstruction using state-of-the-art generative models.
CD$^2$: Fine-grained 3D Mesh Reconstruction with Twice Chamfer Distance
Jun 01, 2022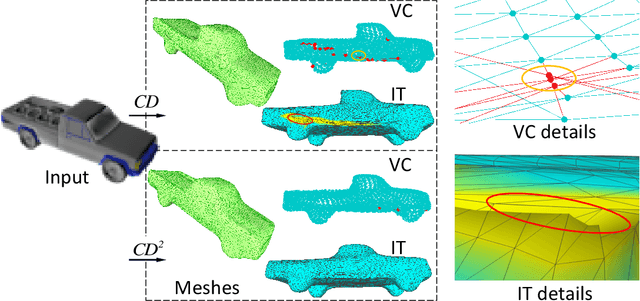


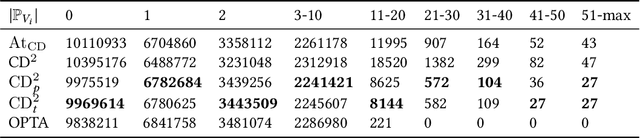
Monocular 3D reconstruction is to reconstruct the shape of object and its other detailed information from a single RGB image. In 3D reconstruction, polygon mesh is the most prevalent expression form obtained from deep learning models, with detailed surface information and low computational cost. However, some state-of-the-art works fail to generate well-structured meshes, these meshes have two severe problems which we call Vertices Clustering and Illegal Twist. By delving into the mesh deformation procedure, we pinpoint the inadequate usage of Chamfer Distance(CD) metric in deep learning model. In this paper, we initially demonstrate the problems resulting from CD with visual examples and quantitative analyses. To solve these problems, we propose a fine-grained reconstruction method CD$^2$ with Chamfer distance adopted twice to perform a plausible and adaptive deformation. Extensive experiments on two 3D datasets and the comparison of our newly proposed mesh quality metrics demonstrate that our CD$^2$ outperforms others by generating better-structured meshes.
Translating Clinical Delineation of Diabetic Foot Ulcers into Machine Interpretable Segmentation
Apr 22, 2022
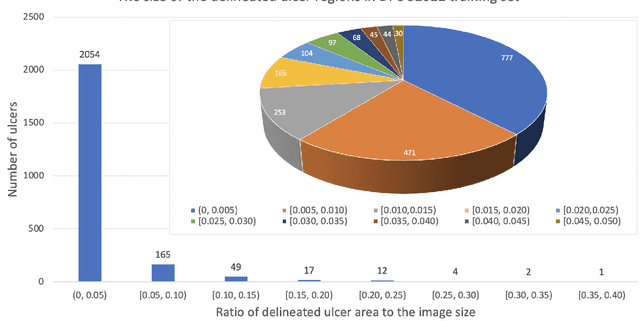
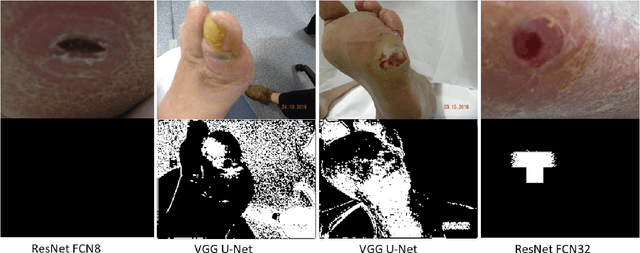
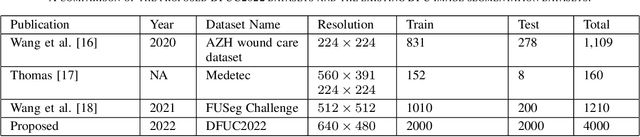
Diabetic foot ulcer is a severe condition that requires close monitoring and management. For training machine learning methods to auto-delineate the ulcer, clinical staff must provide ground truth annotations. In this paper, we propose a new diabetic foot ulcers dataset, namely DFUC2022, the largest segmentation dataset where ulcer regions were manually delineated by clinicians. We assess whether the clinical delineations are machine interpretable by deep learning networks or if image processing refined contour should be used. By providing benchmark results using a selection of popular deep learning algorithms, we draw new insights into the limitations of DFU wound delineation and report on the associated issues. This paper provides some observations on baseline models to facilitate DFUC2022 Challenge in conjunction with MICCAI 2022. The leaderboard will be ranked by Dice score, where the best FCN-based method is 0.5708 and DeepLabv3+ achieved the best score of 0.6277. This paper demonstrates that image processing using refined contour as ground truth can provide better agreement with machine predicted results. DFUC2022 will be released on the 27th April 2022.
Learning Invariant Visual Representations for Compositional Zero-Shot Learning
Jun 01, 2022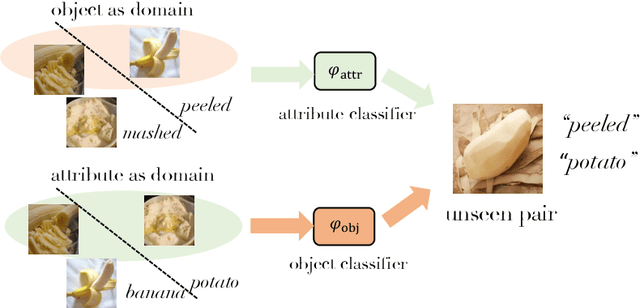
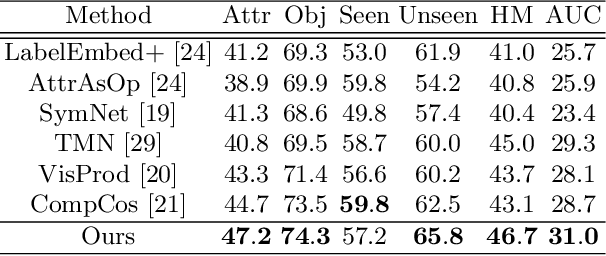
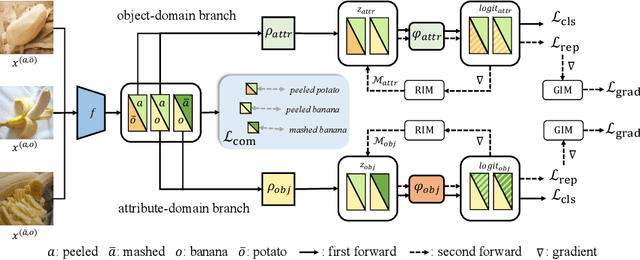
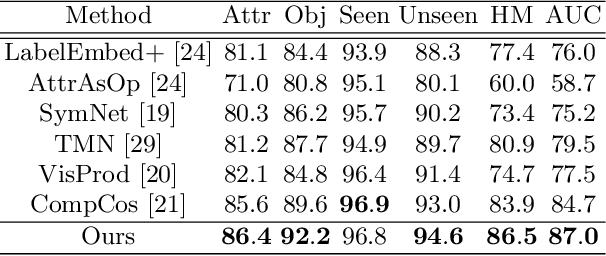
Compositional Zero-Shot Learning (CZSL) aims to recognize novel compositions using knowledge learned from seen attribute-object compositions in the training set. Previous works mainly project an image and a composition into a common embedding space to measure their compatibility score. However, both attributes and objects share the visual representations learned above, leading the model to exploit spurious correlations and bias towards seen pairs. Instead, we reconsider CZSL as an out-of-distribution generalization problem. If an object is treated as a domain, we can learn object-invariant features to recognize the attributes attached to any object reliably. Similarly, attribute-invariant features can also be learned when recognizing the objects with attributes as domains. Specifically, we propose an invariant feature learning framework to align different domains at the representation and gradient levels to capture the intrinsic characteristics associated with the tasks. Experiments on two CZSL benchmarks demonstrate that the proposed method significantly outperforms the previous state-of-the-art.
Explore Image Deblurring via Blur Kernel Space
Apr 03, 2021

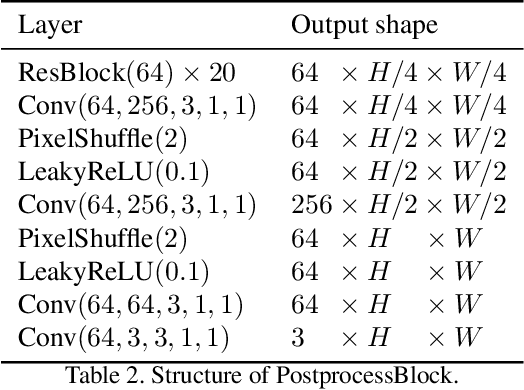
This paper introduces a method to encode the blur operators of an arbitrary dataset of sharp-blur image pairs into a blur kernel space. Assuming the encoded kernel space is close enough to in-the-wild blur operators, we propose an alternating optimization algorithm for blind image deblurring. It approximates an unseen blur operator by a kernel in the encoded space and searches for the corresponding sharp image. Unlike recent deep-learning-based methods, our system can handle unseen blur kernel, while avoiding using complicated handcrafted priors on the blur operator often found in classical methods. Due to the method's design, the encoded kernel space is fully differentiable, thus can be easily adopted in deep neural network models. Moreover, our method can be used for blur synthesis by transferring existing blur operators from a given dataset into a new domain. Finally, we provide experimental results to confirm the effectiveness of the proposed method.
Interactive Portrait Harmonization
Mar 15, 2022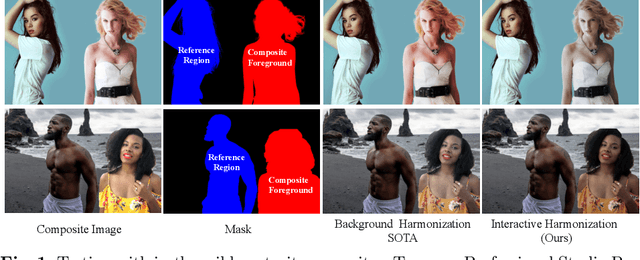
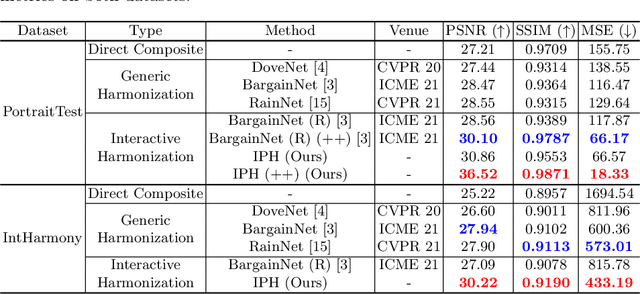

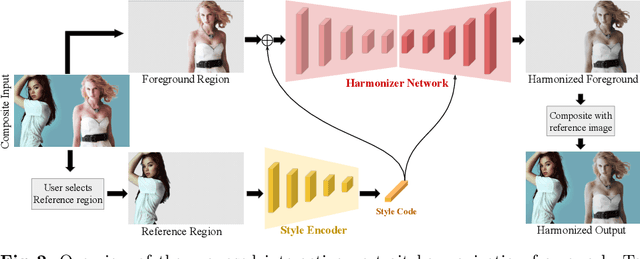
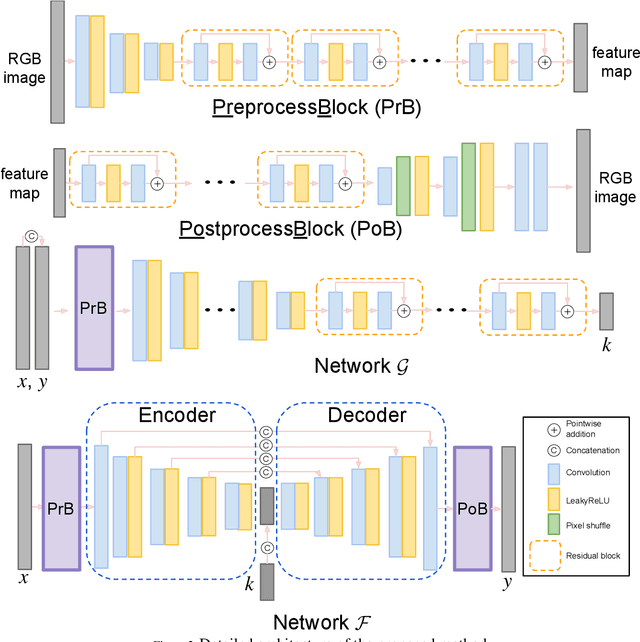
Current image harmonization methods consider the entire background as the guidance for harmonization. However, this may limit the capability for user to choose any specific object/person in the background to guide the harmonization. To enable flexible interaction between user and harmonization, we introduce interactive harmonization, a new setting where the harmonization is performed with respect to a selected \emph{region} in the reference image instead of the entire background. A new flexible framework that allows users to pick certain regions of the background image and use it to guide the harmonization is proposed. Inspired by professional portrait harmonization users, we also introduce a new luminance matching loss to optimally match the color/luminance conditions between the composite foreground and select reference region. This framework provides more control to the image harmonization pipeline achieving visually pleasing portrait edits. Furthermore, we also introduce a new dataset carefully curated for validating portrait harmonization. Extensive experiments on both synthetic and real-world datasets show that the proposed approach is efficient and robust compared to previous harmonization baselines, especially for portraits. Project Webpage at \href{https://jeya-maria-jose.github.io/IPH-web/}{https://jeya-maria-jose.github.io/IPH-web/}