 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic MRI using Learned Transform-based Deep Tensor Low-Rank Network (DTLR-Net)
Jun 02, 2022
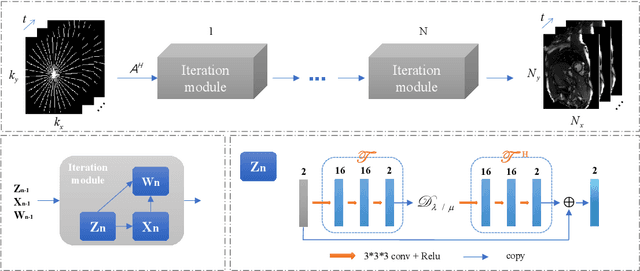
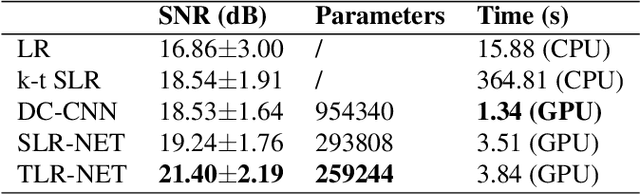
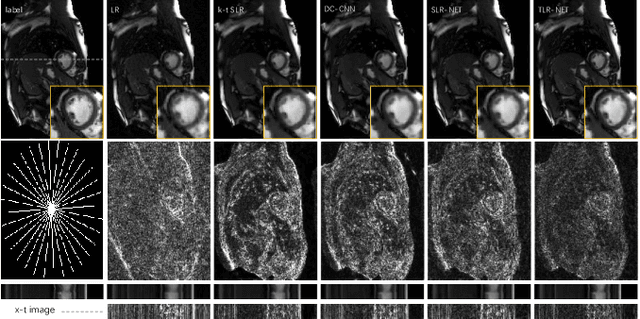
While low-rank matrix prior has been exploited in dynamic MR image reconstruction and has obtained satisfying performance, low-rank tensors models have recently emerged as powerful alternative representations for three-dimensional dynamic MR datasets. In this paper, we introduce a model-based deep learning network by learning the tensor low-rank prior of the cardiac dynamic MR images. Instead of representing the dynamic dataset as a low-rank tensor directly, we propose a learned transformation operator to exploit the tensor low-rank property in a transform domain. In particular, by generalizing the t-SVD tensor decomposition into a unitary transformed t-SVD, we define a transformed tensor nuclear norm (TTNN) to enforce the tensor low-rankness. The dynamic MRI reconstruction problem is thus formulated using a TTNN regularized optimization problem. An iterative algorithm based on ADMM used to minimize the cost is unrolled into a deep network, where the transform is learned using convolutional neural networks (CNNs) to promote the reconstruction quality in the feature domain. Experimental results on cardiac cine MRI reconstruction demonstrate that the proposed framework is able to provide improved recovery results compared with the state-of-the-art algorithms.
Slimmable Video Codec
May 13, 2022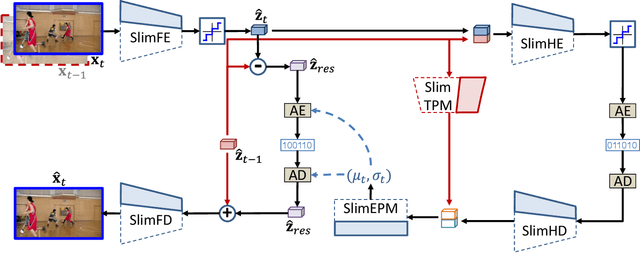

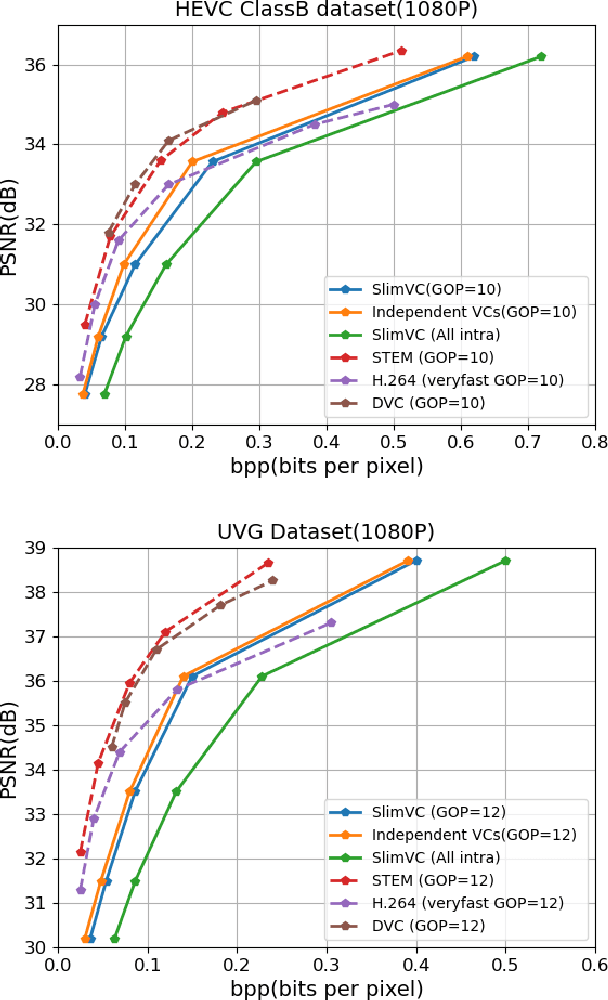
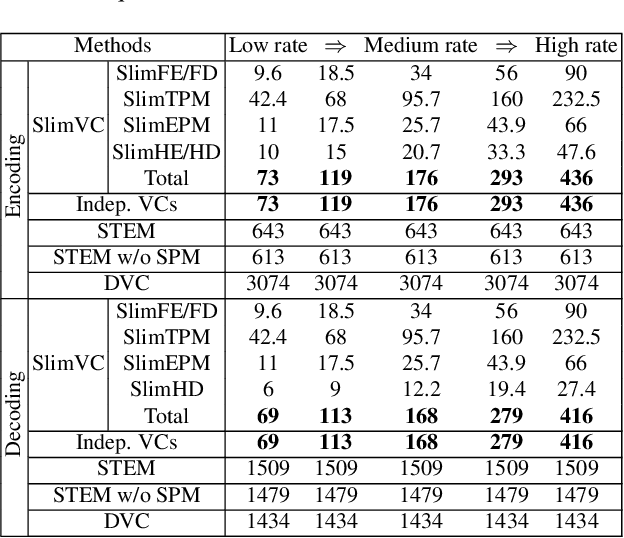
Neural video compression has emerged as a novel paradigm combining trainable multilayer neural networks and machine learning, achieving competitive rate-distortion (RD) performances, but still remaining impractical due to heavy neural architectures, with large memory and computational demands. In addition, models are usually optimized for a single RD tradeoff. Recent slimmable image codecs can dynamically adjust their model capacity to gracefully reduce the memory and computation requirements, without harming RD performance. In this paper we propose a slimmable video codec (SlimVC), by integrating a slimmable temporal entropy model in a slimmable autoencoder. Despite a significantly more complex architecture, we show that slimming remains a powerful mechanism to control rate, memory footprint, computational cost and latency, all being important requirements for practical video compression.
Effect of Parameter Optimization on Classical and Learning-based Image Matching Methods
Aug 18, 2021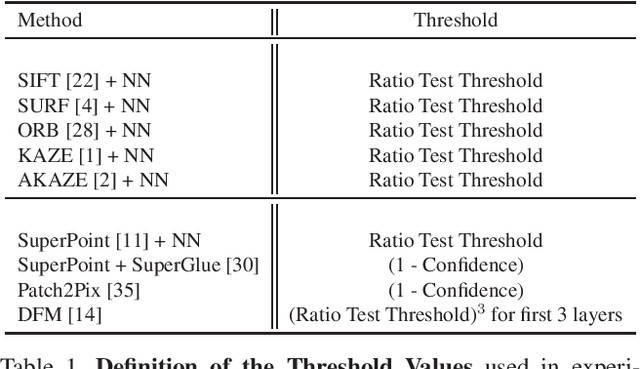
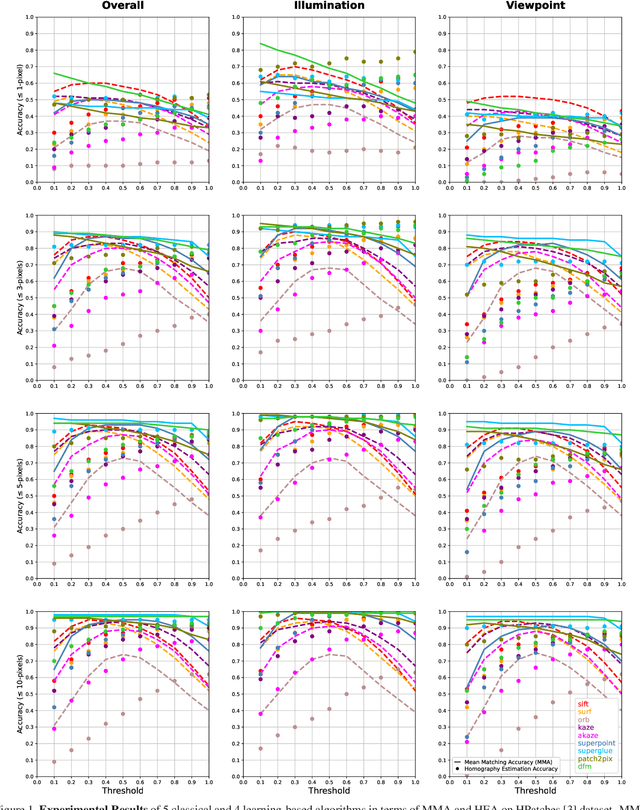
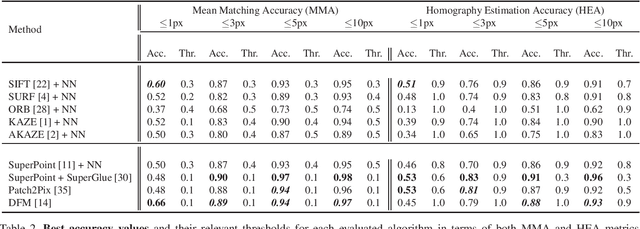
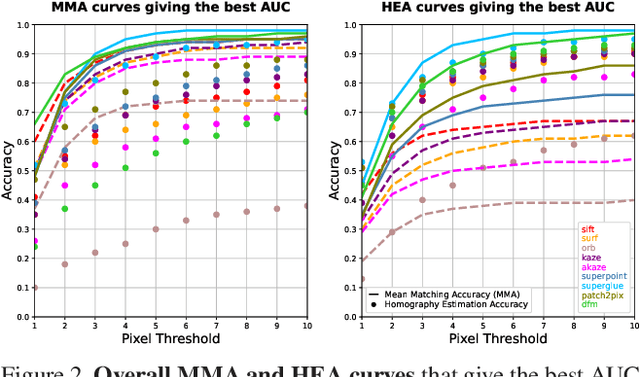
Deep learning-based image matching methods are improved significantly during the recent years. Although these methods are reported to outperform the classical techniques, the performance of the classical methods is not examined in detail. In this study, we compare classical and learning-based methods by employing mutual nearest neighbor search with ratio test and optimizing the ratio test threshold to achieve the best performance on two different performance metrics. After a fair comparison, the experimental results on HPatches dataset reveal that the performance gap between classical and learning-based methods is not that significant. Throughout the experiments, we demonstrated that SuperGlue is the state-of-the-art technique for the image matching problem on HPatches dataset. However, if a single parameter, namely ratio test threshold, is carefully optimized, a well-known traditional method SIFT performs quite close to SuperGlue and even outperforms in terms of mean matching accuracy (MMA) under 1 and 2 pixel thresholds. Moreover, a recent approach, DFM, which only uses pre-trained VGG features as descriptors and ratio test, is shown to outperform most of the well-trained learning-based methods. Therefore, we conclude that the parameters of any classical method should be analyzed carefully before comparing against a learning-based technique.
Towards Metrical Reconstruction of Human Faces
Apr 13, 2022
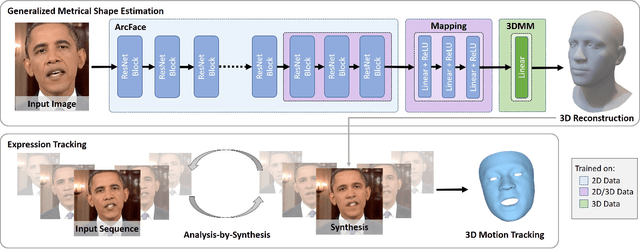
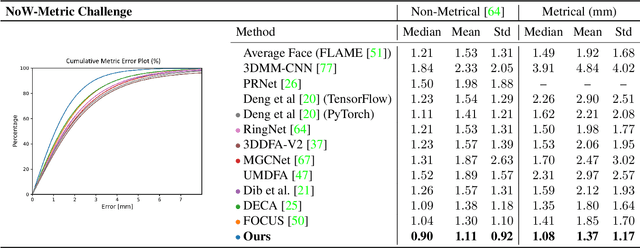
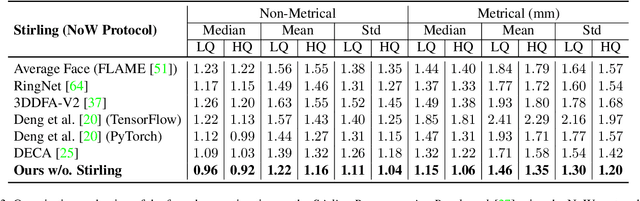
Face reconstruction and tracking is a building block of numerous applications in AR/VR, human-machine interaction, as well as medical applications. Most of these applications rely on a metrically correct prediction of the shape, especially, when the reconstructed subject is put into a metrical context (i.e., when there is a reference object of known size). A metrical reconstruction is also needed for any application that measures distances and dimensions of the subject (e.g., to virtually fit a glasses frame). State-of-the-art methods for face reconstruction from a single image are trained on large 2D image datasets in a self-supervised fashion. However, due to the nature of a perspective projection they are not able to reconstruct the actual face dimensions, and even predicting the average human face outperforms some of these methods in a metrical sense. To learn the actual shape of a face, we argue for a supervised training scheme. Since there exists no large-scale 3D dataset for this task, we annotated and unified small- and medium-scale databases. The resulting unified dataset is still a medium-scale dataset with more than 2k identities and training purely on it would lead to overfitting. To this end, we take advantage of a face recognition network pretrained on a large-scale 2D image dataset, which provides distinct features for different faces and is robust to expression, illumination, and camera changes. Using these features, we train our face shape estimator in a supervised fashion, inheriting the robustness and generalization of the face recognition network. Our method, which we call MICA (MetrIC fAce), outperforms the state-of-the-art reconstruction methods by a large margin, both on current non-metric benchmarks as well as on our metric benchmarks (15% and 24% lower average error on NoW, respectively).
Blind Image Deblurring based on Kernel Mixture
Jan 15, 2021
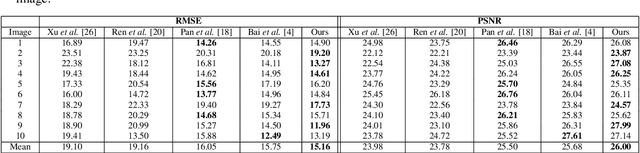
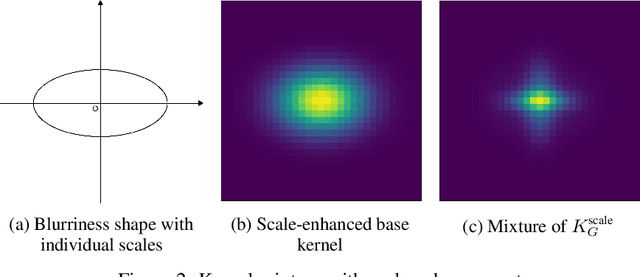
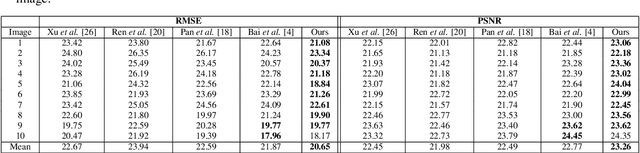
Blind Image deblurring tries to estimate blurriness and a latent image out of a blurred image. This estimation, as being an ill-posed problem, requires imposing restrictions on the latent image or a blur kernel that represents blurriness. Different from recent studies that impose some priors on the latent image, this paper regulates the structure of the blur kernel. We propose a kernel mixture structure while using the Gaussian kernel as a base kernel. By combining multiple Gaussian kernels structurally enhanced in terms of scales and centers, the kernel mixture becomes capable of modeling nearly non-parametric shape of blurriness. A data-driven decision for the number of base kernels to combine makes the structure even more flexible. We apply this approach to a remote sensing problem to recover images from blurry images of satellite. This case study shows the superiority of the proposed method regulating the blur kernel in comparison with state-of-the-art methods that regulates the latent image.
Reducing the Gibbs effect in multimodal medical imaging by the Fake Nodes Approach
Feb 21, 2022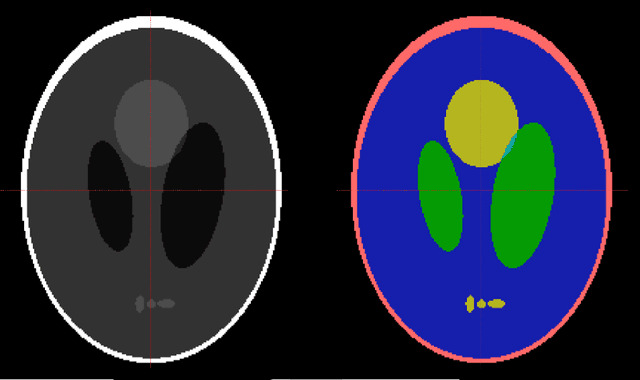
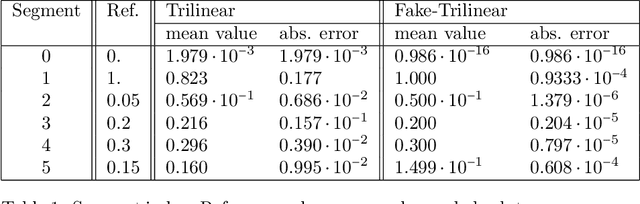

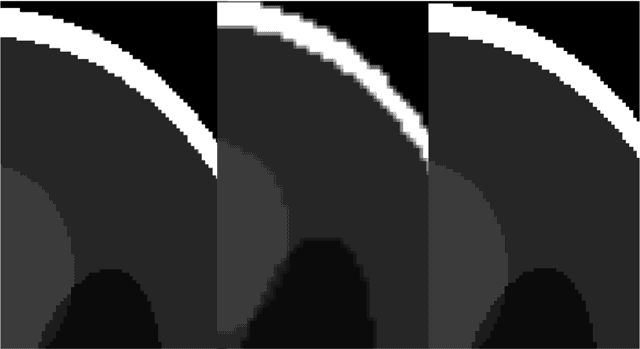
It is a common practice in multimodal medical imaging to undersample the anatomically-derived segmentation images to measure the mean activity of a co-acquired functional image. This practice avoids the resampling-related Gibbs effect that would occur in oversampling the functional image. As sides effect, waste of time and efforts are produced since the anatomical segmentation at full resolution is performed in many hours of computations or manual work. In this work we explain the commonly-used resampling methods and give errors bound in the cases of continuous and discontinuous signals. Then we propose a Fake Nodes scheme for image resampling designed to reduce the Gibbs effect when oversampling the functional image. This new approach is compared to the traditional counterpart in two significant experiments, both showing that Fake Nodes resampling gives smaller errors.
Graph Convolutional Networks for Multi-modality Medical Imaging: Methods, Architectures, and Clinical Applications
Feb 17, 2022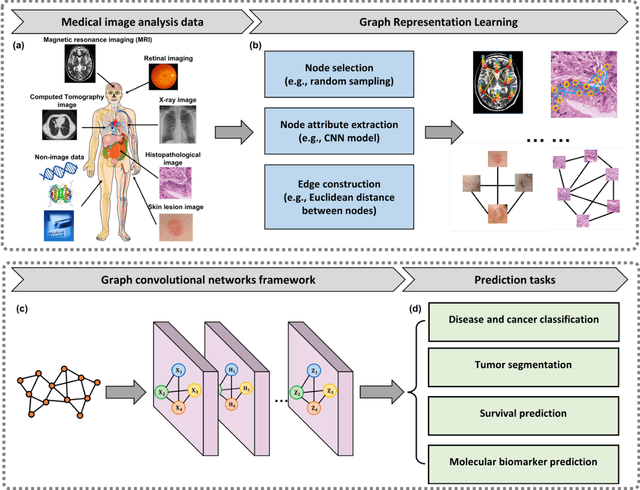

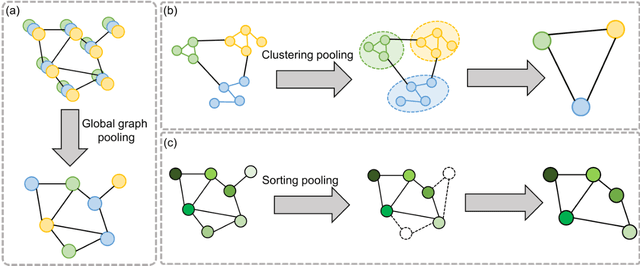
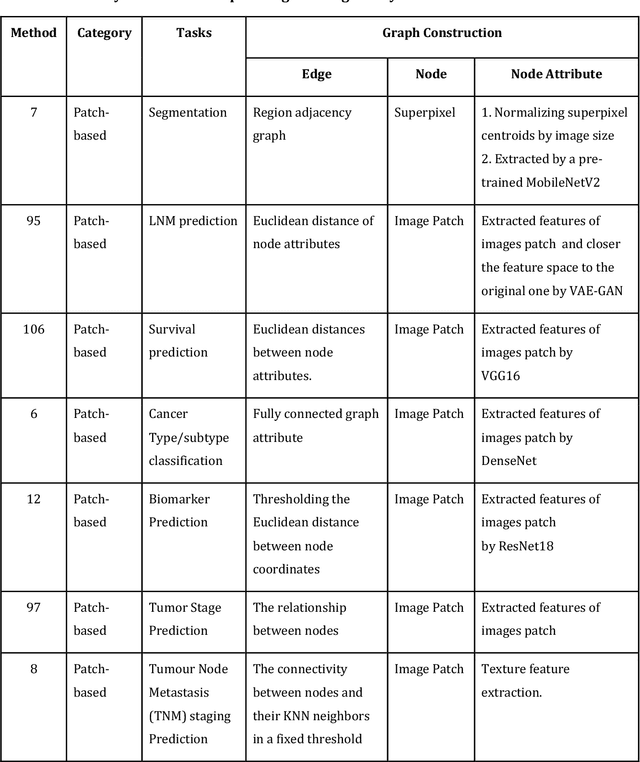
Image-based characterization and disease understanding involve integrative analysis of morphological, spatial, and topological information across biological scales. The development of graph convolutional networks (GCNs) has created the opportunity to address this information complexity via graph-driven architectures, since GCNs can perform feature aggregation, interaction, and reasoning with remarkable flexibility and efficiency. These GCNs capabilities have spawned a new wave of research in medical imaging analysis with the overarching goal of improving quantitative disease understanding, monitoring, and diagnosis. Yet daunting challenges remain for designing the important image-to-graph transformation for multi-modality medical imaging and gaining insights into model interpretation and enhanced clinical decision support. In this review, we present recent GCNs developments in the context of medical image analysis including imaging data from radiology and histopathology. We discuss the fast-growing use of graph network architectures in medical image analysis to improve disease diagnosis and patient outcomes in clinical practice. To foster cross-disciplinary research, we present GCNs technical advancements, emerging medical applications, identify common challenges in the use of image-based GCNs and their extensions in model interpretation, large-scale benchmarks that promise to transform the scope of medical image studies and related graph-driven medical research.
A Closer Look at Self-supervised Lightweight Vision Transformers
May 28, 2022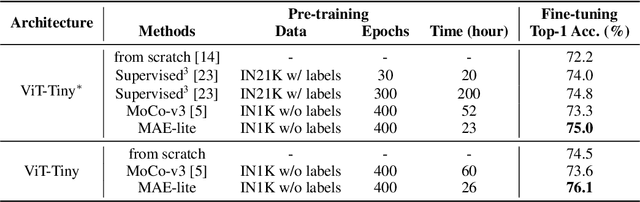
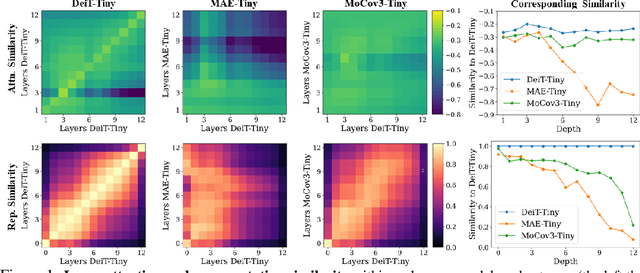
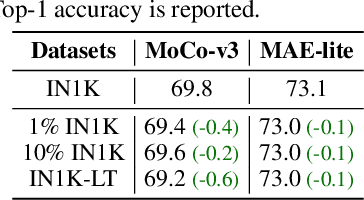
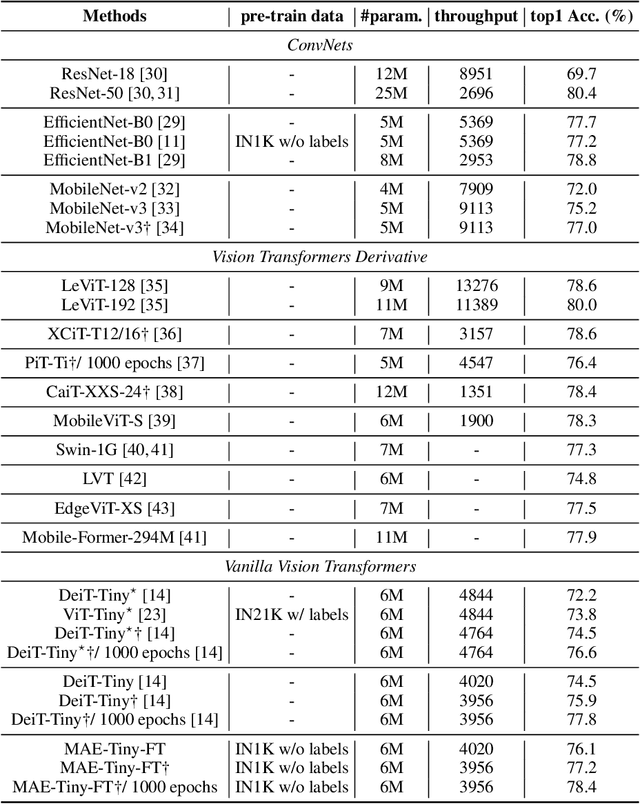
Self-supervised learning on large-scale Vision Transformers (ViTs) as pre-training methods has achieved promising downstream performance. Yet, how such pre-training paradigms promote lightweight ViTs' performance is considerably less studied. In this work, we mainly produce recipes for pre-training high-performance lightweight ViTs using masked-image-modeling-based MAE, namely MAE-lite, which achieves 78.4% top-1 accuracy on ImageNet with ViT-Tiny (5.7M). Furthermore, we develop and benchmark other fully-supervised and self-supervised pre-training counterparts, e.g., contrastive-learning-based MoCo-v3, on both ImageNet and other classification tasks. We analyze and clearly show the effect of such pre-training, and reveal that properly-learned lower layers of the pre-trained models matter more than higher ones in data-sufficient downstream tasks. Finally, by further comparing with the pre-trained representations of the up-scaled models, a distillation strategy during pre-training is developed to improve the pre-trained representations as well, leading to further downstream performance improvement. The code and models will be made publicly available.
Hyperparameter Sensitivity in Deep Outlier Detection: Analysis and a Scalable Hyper-Ensemble Solution
Jun 15, 2022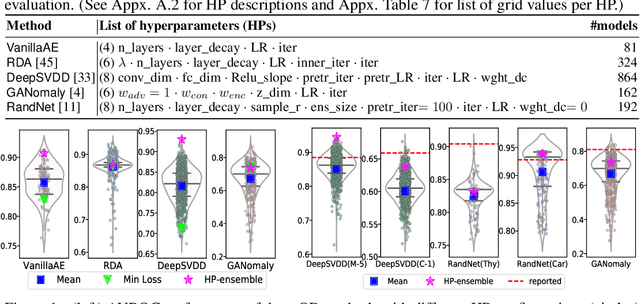

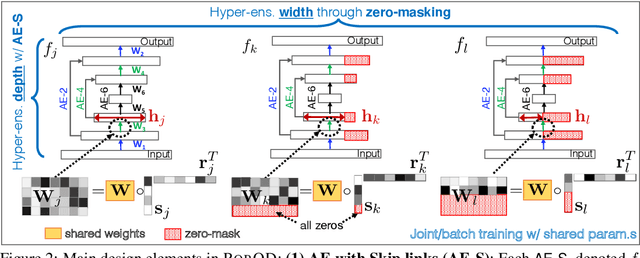
Outlier detection (OD) literature exhibits numerous algorithms as it applies to diverse domains. However, given a new detection task, it is unclear how to choose an algorithm to use, nor how to set its hyperparameter(s) (HPs) in unsupervised settings. HP tuning is an ever-growing problem with the arrival of many new detectors based on deep learning. While they have appealing properties such as task- driven representation learning and end-to-end optimization, deep models come with a long list of HPs. Surprisingly, the issue of model selection in the outlier mining literature has been "the elephant in the room"; a significant factor in unlocking the utmost potential of deep methods, yet little said or done to systematically tackle the issue. In the first part of this paper, we conduct the first large-scale analysis on the HP sensitivity of deep OD methods, and through more than 35,000 trained models, quantitatively demonstrate that model selection is inevitable. Next, we design a HP-robust and scalable deep hyper-ensemble model called ROBOD that assembles models with varying HP configurations, bypassing the choice paralysis. Importantly, we introduce novel strategies to speed up ensemble training, such as parameter sharing, batch/simultaneous training, and data subsampling, that allow us to train fewer models with fewer parameters. Extensive experiments on both image and tabular datasets show that ROBOD achieves and retains robust, state-of-the-art detection performance as compared to its modern counterparts, while taking only 2-10% of the time by the naive hyper-ensemble with independent training.
Variational Deep Image Denoising
Apr 02, 2021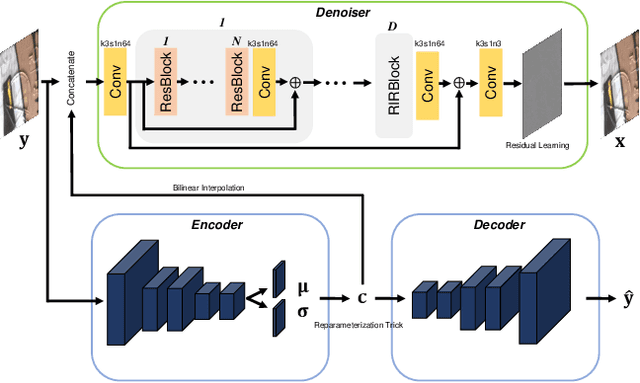
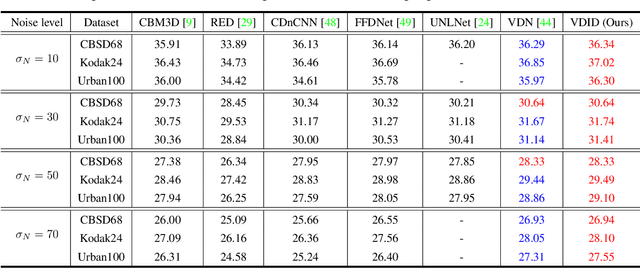
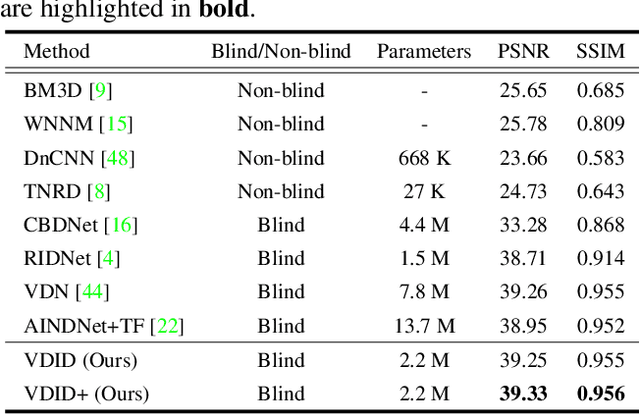

Convolutional neural networks (CNNs) have shown outstanding performance on image denoising with the help of large-scale datasets. Earlier methods naively trained a single CNN with many pairs of clean-noisy images. However, the conditional distribution of the clean image given a noisy one is too complicated and diverse, so that a single CNN cannot well learn such distributions. Therefore, there have also been some methods that exploit additional noise level parameters or train a separate CNN for a specific noise level parameter. These methods separate the original problem into easier sub-problems and thus have shown improved performance than the naively trained CNN. In this step, we raise two questions. The first one is whether it is an optimal approach to relate the conditional distribution only to noise level parameters. The second is what if we do not have noise level information, such as in a real-world scenario. To answer the questions and provide a better solution, we propose a novel Bayesian framework based on the variational approximation of objective functions. This enables us to separate the complicated target distribution into simpler sub-distributions. Eventually, the denoising CNN can conquer noise from each sub-distribution, which is generally an easier problem than the original. Experiments show that the proposed method provides remarkable performance on additive white Gaussian noise (AWGN) and real-noise denoising while requiring fewer parameters than recent state-of-the-art denoisers.