 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Omni-Directional Image Generation from Single Snapshot Image
Oct 12, 2020
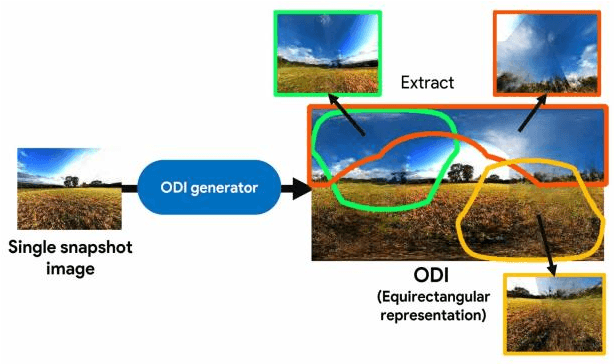
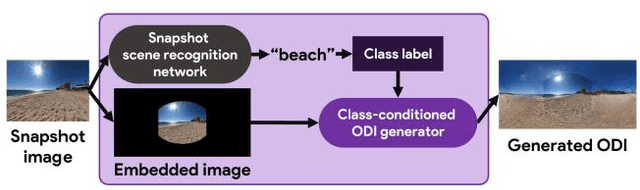
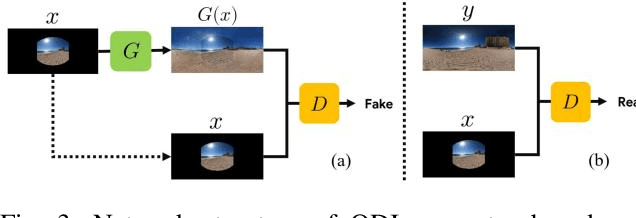
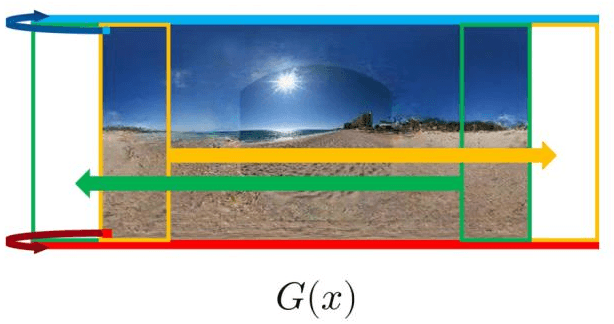
An omni-directional image (ODI) is the image that has a field of view covering the entire sphere around the camera. The ODIs have begun to be used in a wide range of fields such as virtual reality (VR), robotics, and social network services. Although the contents using ODI have increased, the available images and videos are still limited, compared with widespread snapshot images. A large number of ODIs are desired not only for the VR contents, but also for training deep learning models for ODI. For these purposes, a novel computer vision task to generate ODI from a single snapshot image is proposed in this paper. To tackle this problem, the conditional generative adversarial network was applied in combination with class-conditioned convolution layers. With this novel task, VR images and videos will be easily created even with a smartphone camera.
SimCVD: Simple Contrastive Voxel-Wise Representation Distillation for Semi-Supervised Medical Image Segmentation
Aug 16, 2021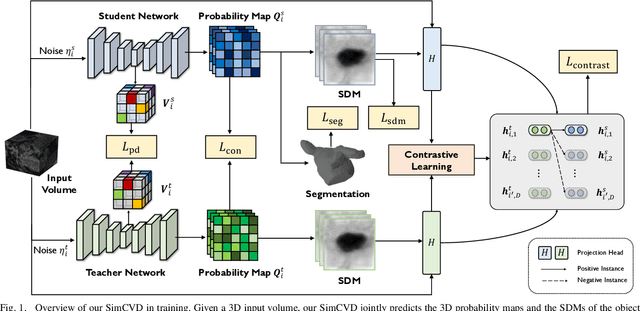
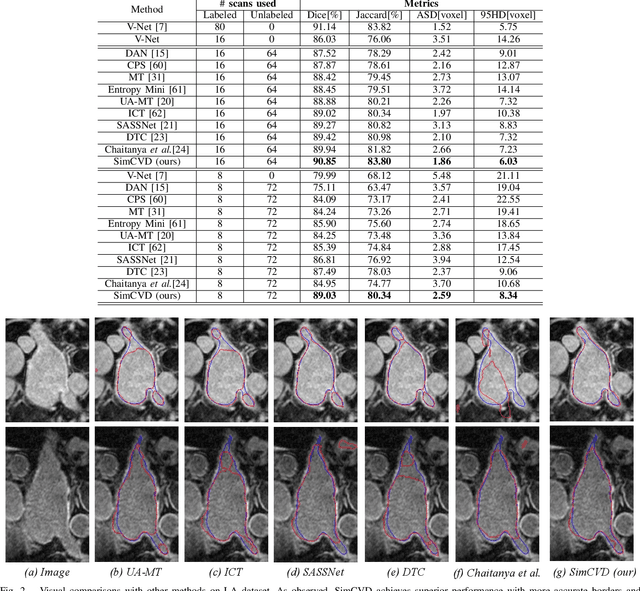
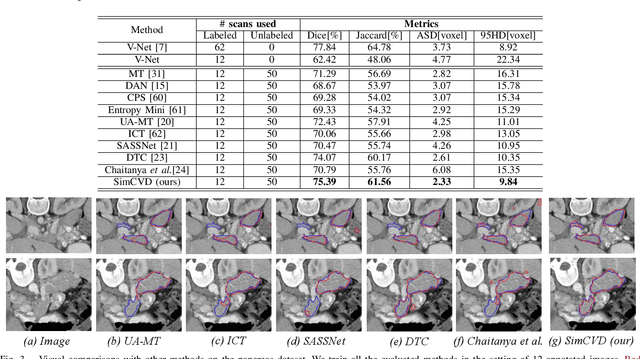
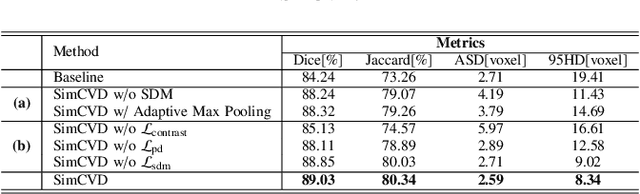
Automated segmentation in medical image analysis is a challenging task that requires a large amount of manually labeled data. However, most existing learning-based approaches usually suffer from limited manually annotated medical data, which poses a major practical problem for accurate and robust medical image segmentation. In addition, most existing semi-supervised approaches are usually not robust compared with the supervised counterparts, and also lack explicit modeling of geometric structure and semantic information, both of which limit the segmentation accuracy. In this work, we present SimCVD, a simple contrastive distillation framework that significantly advances state-of-the-art voxel-wise representation learning. We first describe an unsupervised training strategy, which takes two views of an input volume and predicts their signed distance maps of object boundaries in a contrastive objective, with only two independent dropout as mask. This simple approach works surprisingly well, performing on the same level as previous fully supervised methods with much less labeled data. We hypothesize that dropout can be viewed as a minimal form of data augmentation and makes the network robust to representation collapse. Then, we propose to perform structural distillation by distilling pair-wise similarities. We evaluate SimCVD on two popular datasets: the Left Atrial Segmentation Challenge (LA) and the NIH pancreas CT dataset. The results on the LA dataset demonstrate that, in two types of labeled ratios (i.e., 20% and 10%), SimCVD achieves an average Dice score of 90.85% and 89.03% respectively, a 0.91% and 2.22% improvement compared to previous best results. Our method can be trained in an end-to-end fashion, showing the promise of utilizing SimCVD as a general framework for downstream tasks, such as medical image synthesis and registration.
Slimmable Video Codec
May 13, 2022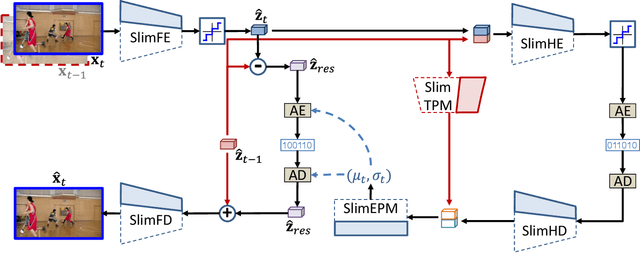

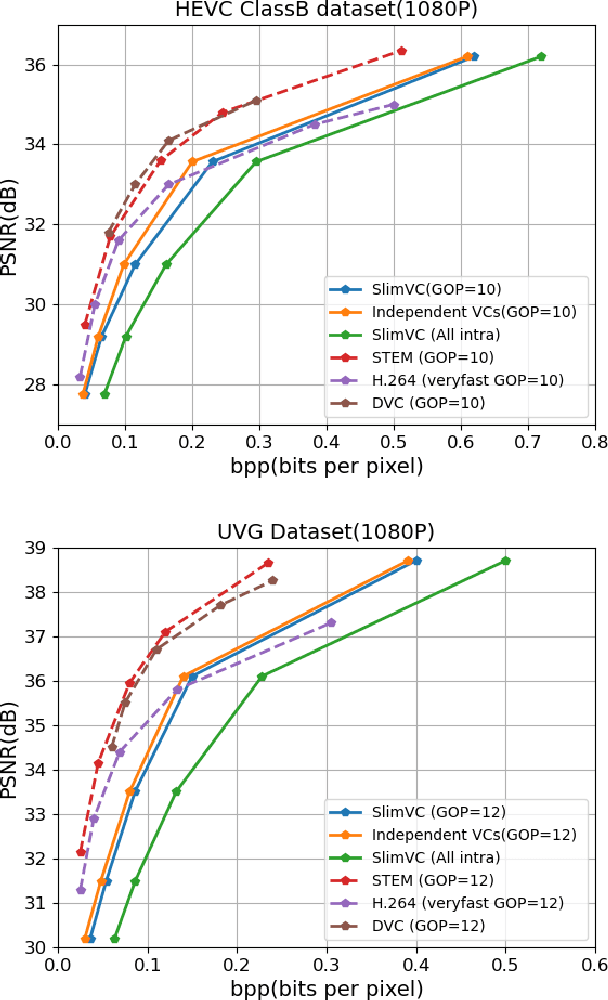
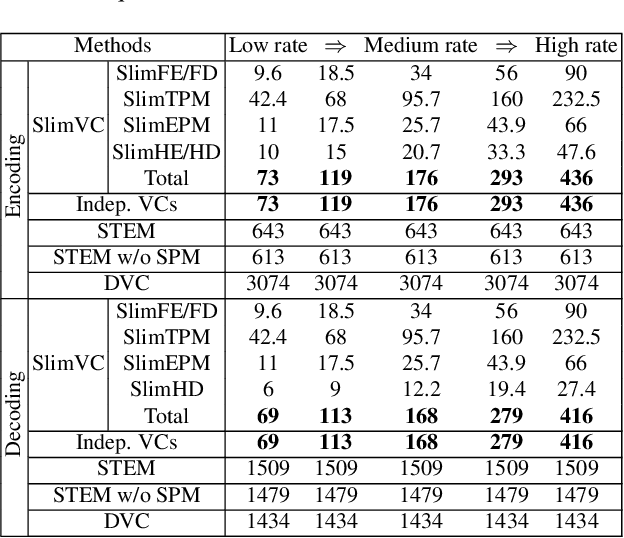
Neural video compression has emerged as a novel paradigm combining trainable multilayer neural networks and machine learning, achieving competitive rate-distortion (RD) performances, but still remaining impractical due to heavy neural architectures, with large memory and computational demands. In addition, models are usually optimized for a single RD tradeoff. Recent slimmable image codecs can dynamically adjust their model capacity to gracefully reduce the memory and computation requirements, without harming RD performance. In this paper we propose a slimmable video codec (SlimVC), by integrating a slimmable temporal entropy model in a slimmable autoencoder. Despite a significantly more complex architecture, we show that slimming remains a powerful mechanism to control rate, memory footprint, computational cost and latency, all being important requirements for practical video compression.
Soft Compression for Lossless Image Coding
Dec 11, 2020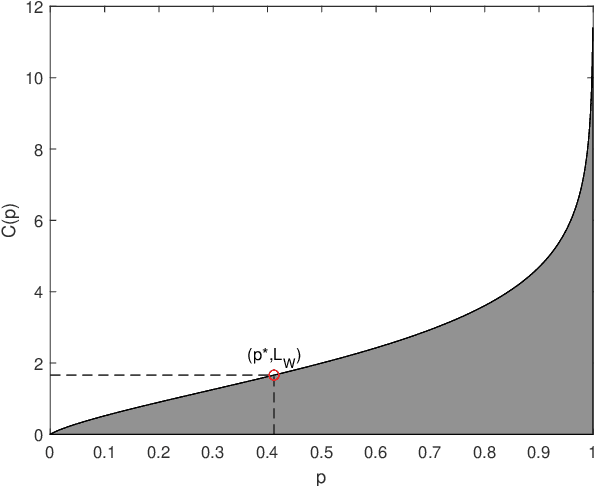

Soft compression is a lossless image compression method, which is committed to eliminating coding redundancy and spatial redundancy at the same time by adopting locations and shapes of codebook to encode an image from the perspective of information theory and statistical distribution. In this paper, we propose a new concept, compressible indicator function with regard to image, which gives a threshold about the average number of bits required to represent a location and can be used for revealing the performance of soft compression. We investigate and analyze soft compression for binary image, gray image and multi-component image by using specific algorithms and compressible indicator value. It is expected that the bandwidth and storage space needed when transmitting and storing the same kind of images can be greatly reduced by applying soft compression.
A Novel Falling-Ball Algorithm for Image Segmentation
May 06, 2021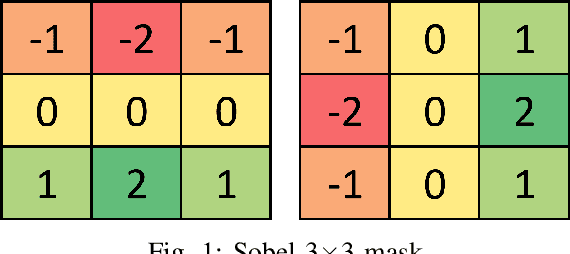
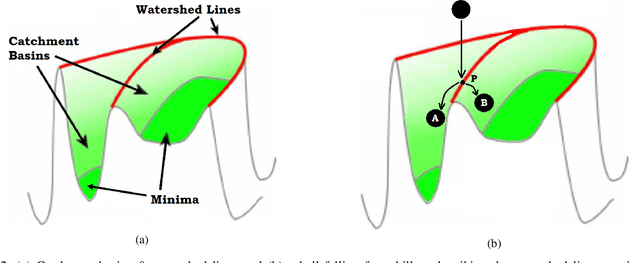
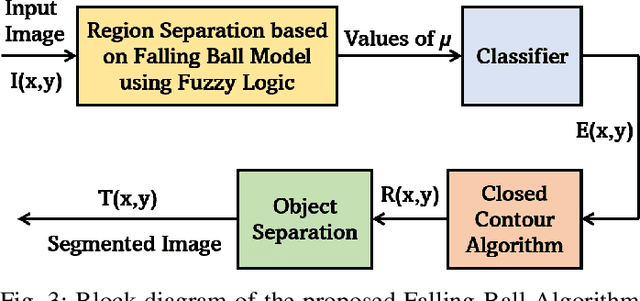
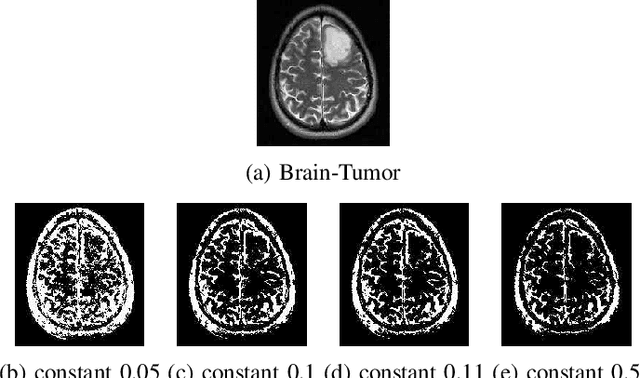
Image segmentation refers to the separation of objects from the background, and has been one of the most challenging aspects of digital image processing. Practically it is impossible to design a segmentation algorithm which has 100% accuracy, and therefore numerous segmentation techniques have been proposed in the literature, each with certain limitations. In this paper, a novel Falling-Ball algorithm is presented, which is a region-based segmentation algorithm, and an alternative to watershed transform (based on waterfall model). The proposed algorithm detects the catchment basins by assuming that a ball falling from hilly terrains will stop in a catchment basin. Once catchment basins are identified, the association of each pixel with one of the catchment basin is obtained using multi-criterion fuzzy logic. Edges are constructed by dividing image into different catchment basins with the help of a membership function. Finally closed contour algorithm is applied to find closed regions and objects within closed regions are segmented using intensity information. The performance of the proposed algorithm is evaluated both objectively as well as subjectively. Simulation results show that the proposed algorithms gives superior performance over conventional Sobel edge detection methods and the watershed segmentation algorithm. For comparative analysis, various comparison methods are used for demonstrating the superiority of proposed methods over existing segmentation methods.
Towards Metrical Reconstruction of Human Faces
Apr 13, 2022
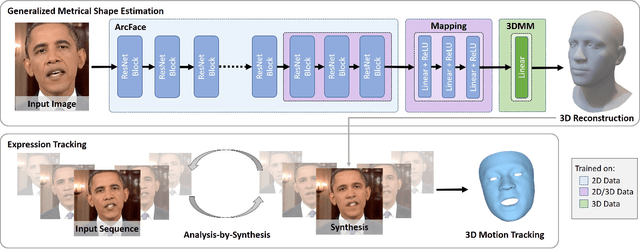
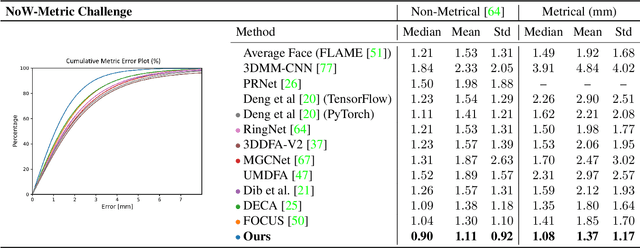
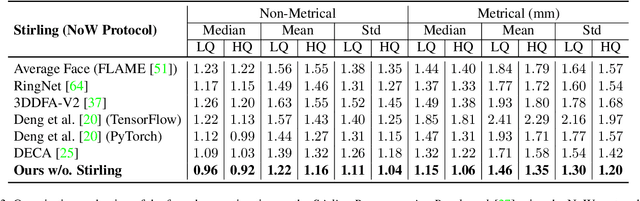
Face reconstruction and tracking is a building block of numerous applications in AR/VR, human-machine interaction, as well as medical applications. Most of these applications rely on a metrically correct prediction of the shape, especially, when the reconstructed subject is put into a metrical context (i.e., when there is a reference object of known size). A metrical reconstruction is also needed for any application that measures distances and dimensions of the subject (e.g., to virtually fit a glasses frame). State-of-the-art methods for face reconstruction from a single image are trained on large 2D image datasets in a self-supervised fashion. However, due to the nature of a perspective projection they are not able to reconstruct the actual face dimensions, and even predicting the average human face outperforms some of these methods in a metrical sense. To learn the actual shape of a face, we argue for a supervised training scheme. Since there exists no large-scale 3D dataset for this task, we annotated and unified small- and medium-scale databases. The resulting unified dataset is still a medium-scale dataset with more than 2k identities and training purely on it would lead to overfitting. To this end, we take advantage of a face recognition network pretrained on a large-scale 2D image dataset, which provides distinct features for different faces and is robust to expression, illumination, and camera changes. Using these features, we train our face shape estimator in a supervised fashion, inheriting the robustness and generalization of the face recognition network. Our method, which we call MICA (MetrIC fAce), outperforms the state-of-the-art reconstruction methods by a large margin, both on current non-metric benchmarks as well as on our metric benchmarks (15% and 24% lower average error on NoW, respectively).
A Deep Residual Star Generative Adversarial Network for multi-domain Image Super-Resolution
Jul 07, 2021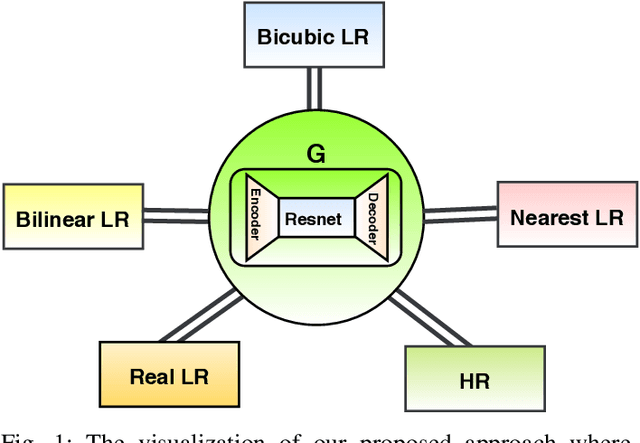
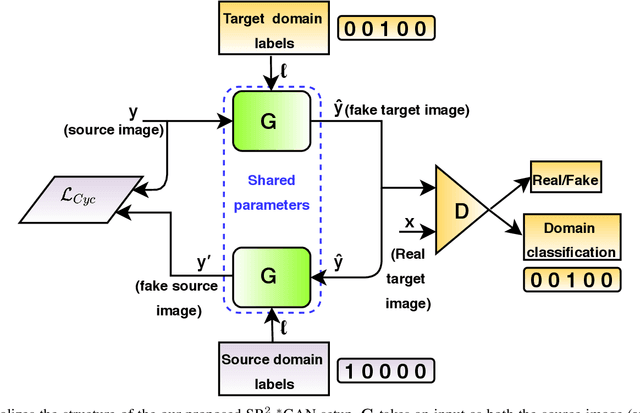
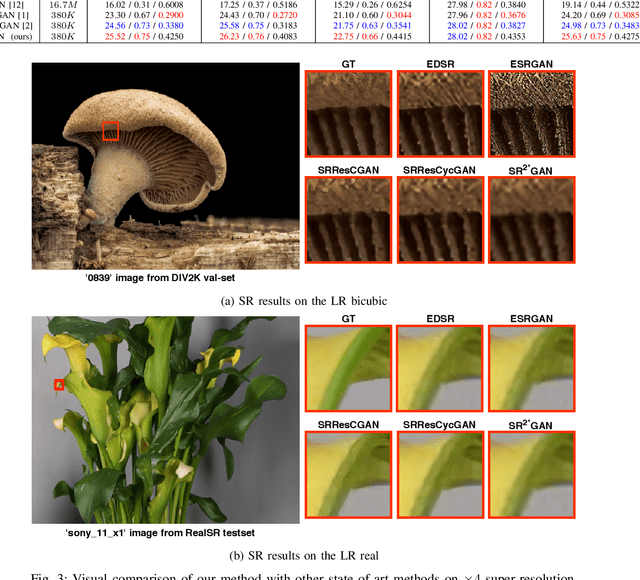
Recently, most of state-of-the-art single image super-resolution (SISR) methods have attained impressive performance by using deep convolutional neural networks (DCNNs). The existing SR methods have limited performance due to a fixed degradation settings, i.e. usually a bicubic downscaling of low-resolution (LR) image. However, in real-world settings, the LR degradation process is unknown which can be bicubic LR, bilinear LR, nearest-neighbor LR, or real LR. Therefore, most SR methods are ineffective and inefficient in handling more than one degradation settings within a single network. To handle the multiple degradation, i.e. refers to multi-domain image super-resolution, we propose a deep Super-Resolution Residual StarGAN (SR2*GAN), a novel and scalable approach that super-resolves the LR images for the multiple LR domains using only a single model. The proposed scheme is trained in a StarGAN like network topology with a single generator and discriminator networks. We demonstrate the effectiveness of our proposed approach in quantitative and qualitative experiments compared to other state-of-the-art methods.
Cervical Optical Coherence Tomography Image Classification Based on Contrastive Self-Supervised Texture Learning
Aug 11, 2021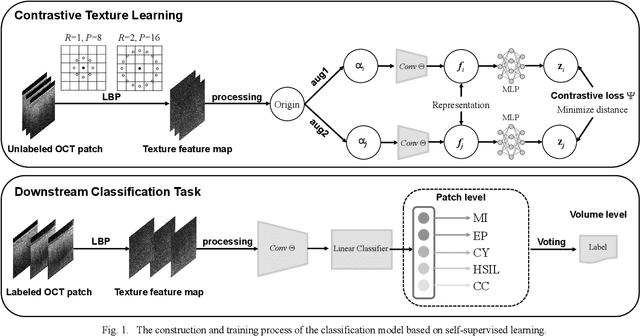
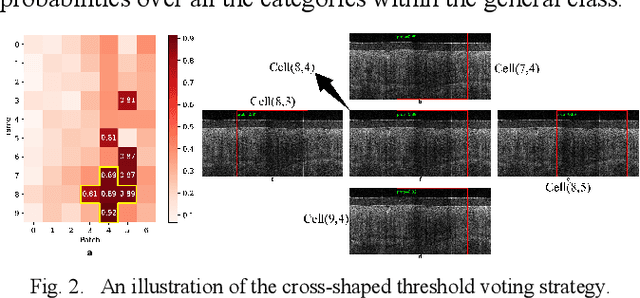
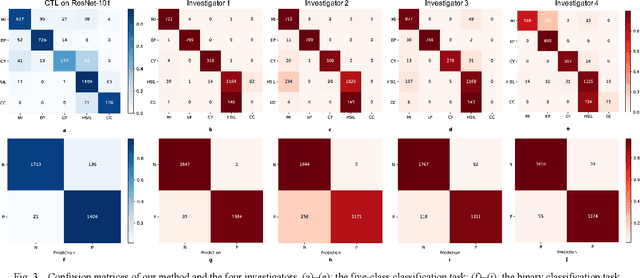
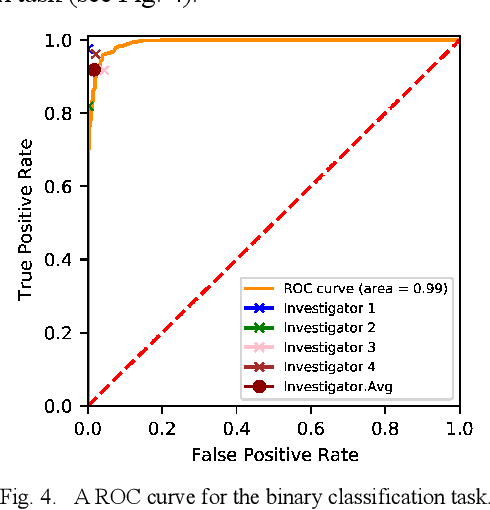
Background: Cervical cancer seriously affects the health of the female reproductive system. Optical coherence tomography (OCT) emerges as a non-invasive, high-resolution imaging technology for cervical disease detection. However, OCT image annotation is knowledge-intensive and time-consuming, which impedes the training process of deep-learning-based classification models. Objective: This study aims to develop a computer-aided diagnosis (CADx) approach to classifying in-vivo cervical OCT images based on self-supervised learning. Methods: Besides high-level semantic features extracted by a convolutional neural network (CNN), the proposed CADx approach leverages unlabeled cervical OCT images' texture features learned by contrastive texture learning. We conducted ten-fold cross-validation on the OCT image dataset from a multi-center clinical study on 733 patients from China. Results: In a binary classification task for detecting high-risk diseases, including high-grade squamous intraepithelial lesion (HSIL) and cervical cancer, our method achieved an area-under-the-curve (AUC) value of 0.9798 Plus or Minus 0.0157 with a sensitivity of 91.17 Plus or Minus 4.99% and a specificity of 93.96 Plus or Minus 4.72% for OCT image patches; also, it outperformed two out of four medical experts on the test set. Furthermore, our method achieved a 91.53% sensitivity and 97.37% specificity on an external validation dataset containing 287 3D OCT volumes from 118 Chinese patients in a new hospital using a cross-shaped threshold voting strategy. Conclusion: The proposed contrastive-learning-based CADx method outperformed the end-to-end CNN models and provided better interpretability based on texture features, which holds great potential to be used in the clinical protocol of "see-and-treat."
Asymmetric CNN for image super-resolution
Mar 30, 2021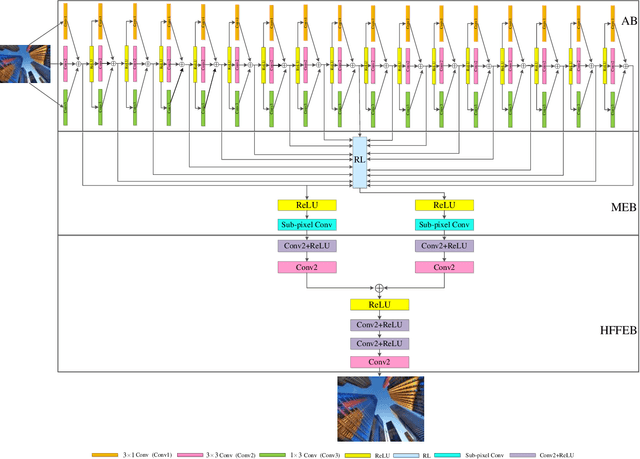
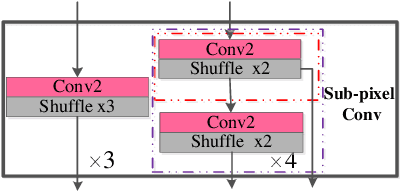
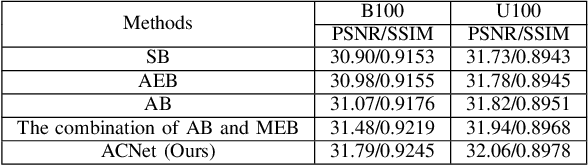
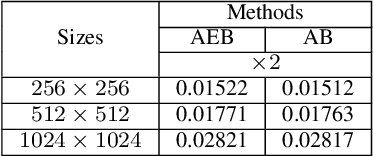
Deep convolutional neural networks (CNNs) have been widely applied for low-level vision over the past five years. According to nature of different applications, designing appropriate CNN architectures is developed. However, customized architectures gather different features via treating all pixel points as equal to improve the performance of given application, which ignores the effects of local power pixel points and results in low training efficiency. In this paper, we propose an asymmetric CNN (ACNet) comprising an asymmetric block (AB), a memory enhancement block (MEB) and a high-frequency feature enhancement block (HFFEB) for image super-resolution. The AB utilizes one-dimensional asymmetric convolutions to intensify the square convolution kernels in horizontal and vertical directions for promoting the influences of local salient features for SISR. The MEB fuses all hierarchical low-frequency features from the AB via residual learning (RL) technique to resolve the long-term dependency problem and transforms obtained low-frequency features into high-frequency features. The HFFEB exploits low- and high-frequency features to obtain more robust super-resolution features and address excessive feature enhancement problem. Addditionally, it also takes charge of reconstructing a high-resolution (HR) image. Extensive experiments show that our ACNet can effectively address single image super-resolution (SISR), blind SISR and blind SISR of blind noise problems. The code of the ACNet is shown at https://github.com/hellloxiaotian/ACNet.
Controllable Confidence-Based Image Denoising
Jun 17, 2021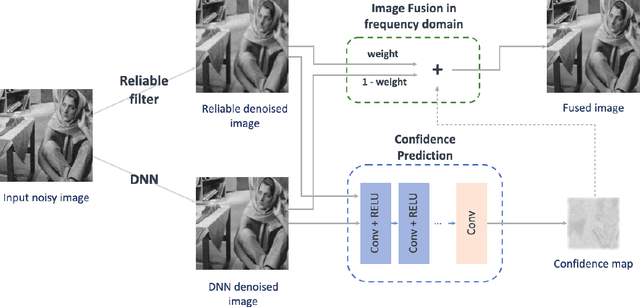
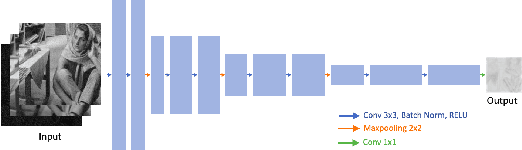
Image denoising is a classic restoration problem. Yet, current deep learning methods are subject to the problems of generalization and interpretability. To mitigate these problems, in this project, we present a framework that is capable of controllable, confidence-based noise removal. The framework is based on the fusion between two different denoised images, both derived from the same noisy input. One of the two is denoised using generic algorithms (e.g. Gaussian), which make few assumptions on the input images, therefore, generalize in all scenarios. The other is denoised using deep learning, performing well on seen datasets. We introduce a set of techniques to fuse the two components smoothly in the frequency domain. Beyond that, we estimate the confidence of a deep learning denoiser to allow users to interpret the output, and provide a fusion strategy that safeguards them against out-of-distribution inputs. Through experiments, we demonstrate the effectiveness of the proposed framework in different use cases.