 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel Disaster Image Dataset and Characteristics Analysis using Attention Model
Jul 02, 2021

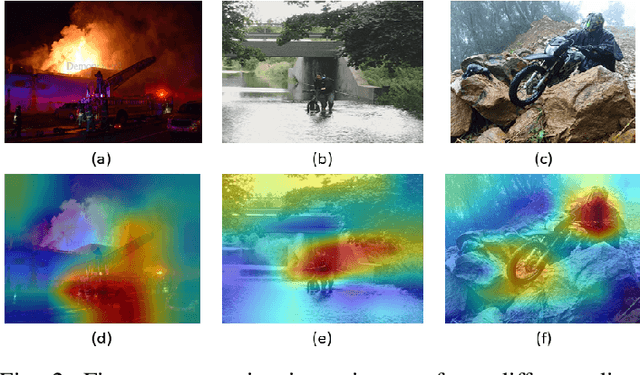

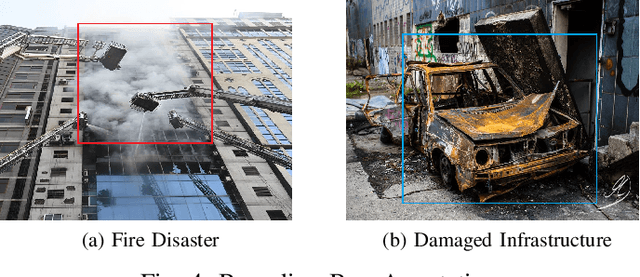
The advancement of deep learning technology has enabled us to develop systems that outperform any other classification technique. However, success of any empirical system depends on the quality and diversity of the data available to train the proposed system. In this research, we have carefully accumulated a relatively challenging dataset that contains images collected from various sources for three different disasters: fire, water and land. Besides this, we have also collected images for various damaged infrastructure due to natural or man made calamities and damaged human due to war or accidents. We have also accumulated image data for a class named non-damage that contains images with no such disaster or sign of damage in them. There are 13,720 manually annotated images in this dataset, each image is annotated by three individuals. We are also providing discriminating image class information annotated manually with bounding box for a set of 200 test images. Images are collected from different news portals, social media, and standard datasets made available by other researchers. A three layer attention model (TLAM) is trained and average five fold validation accuracy of 95.88% is achieved. Moreover, on the 200 unseen test images this accuracy is 96.48%. We also generate and compare attention maps for these test images to determine the characteristics of the trained attention model. Our dataset is available at https://niloy193.github.io/Disaster-Dataset
Convolutional Dictionary Learning by End-To-End Training of Iterative Neural Networks
Jun 09, 2022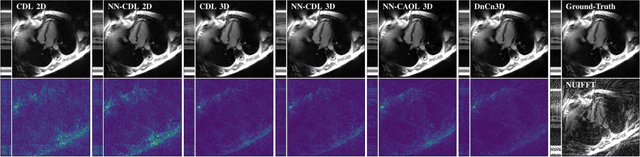
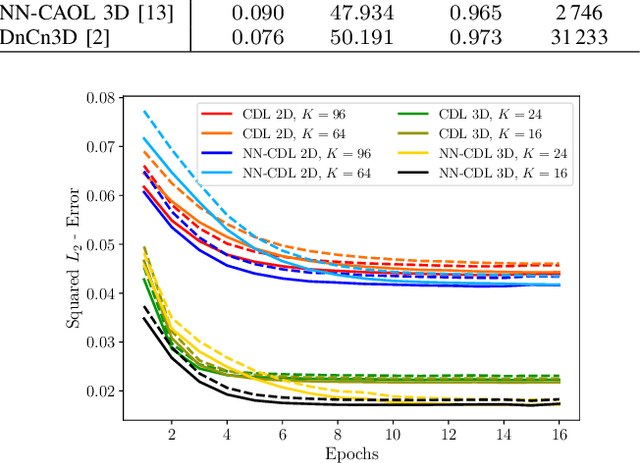

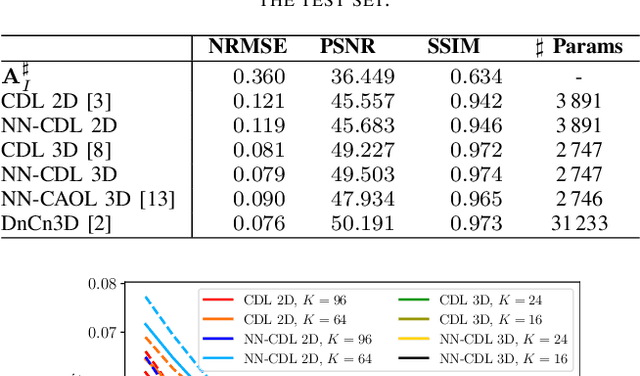
Sparsity-based methods have a long history in the field of signal processing and have been successfully applied to various image reconstruction problems. The involved sparsifying transformations or dictionaries are typically either pre-trained using a model which reflects the assumed properties of the signals or adaptively learned during the reconstruction - yielding so-called blind Compressed Sensing approaches. However, by doing so, the transforms are never explicitly trained in conjunction with the physical model which generates the signals. In addition, properly choosing the involved regularization parameters remains a challenging task. Another recently emerged training-paradigm for regularization methods is to use iterative neural networks (INNs) - also known as unrolled networks - which contain the physical model. In this work, we construct an INN which can be used as a supervised and physics-informed online convolutional dictionary learning algorithm. We evaluated the proposed approach by applying it to a realistic large-scale dynamic MR reconstruction problem and compared it to several other recently published works. We show that the proposed INN improves over two conventional model-agnostic training methods and yields competitive results also compared to a deep INN. Further, it does not require to choose the regularization parameters and - in contrast to deep INNs - each network component is entirely interpretable.
Semi-Supervised Learning for Mars Imagery Classification and Segmentation
Jun 05, 2022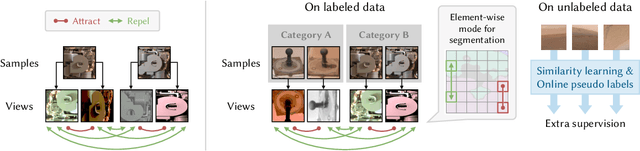
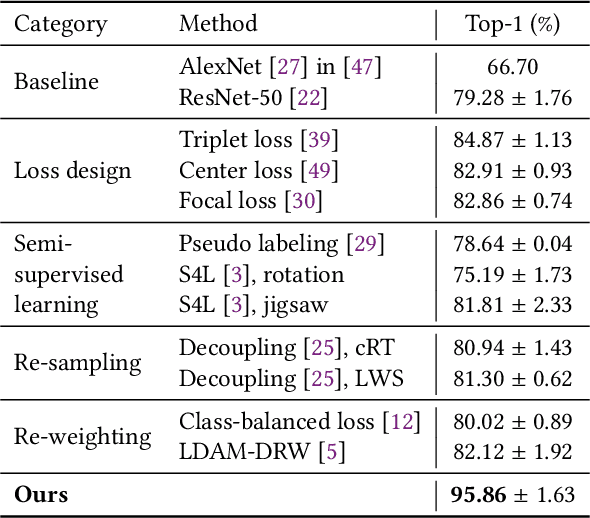
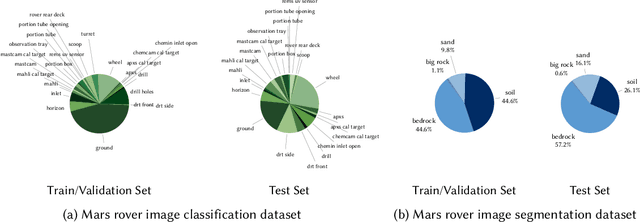
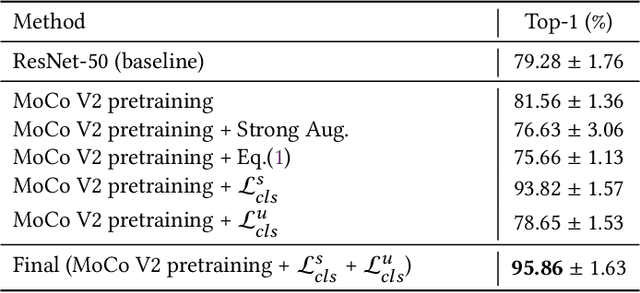
With the progress of Mars exploration, numerous Mars image data are collected and need to be analyzed. However, due to the imbalance and distortion of Martian data, the performance of existing computer vision models is unsatisfactory. In this paper, we introduce a semi-supervised framework for machine vision on Mars and try to resolve two specific tasks: classification and segmentation. Contrastive learning is a powerful representation learning technique. However, there is too much information overlap between Martian data samples, leading to a contradiction between contrastive learning and Martian data. Our key idea is to reconcile this contradiction with the help of annotations and further take advantage of unlabeled data to improve performance. For classification, we propose to ignore inner-class pairs on labeled data as well as neglect negative pairs on unlabeled data, forming supervised inter-class contrastive learning and unsupervised similarity learning. For segmentation, we extend supervised inter-class contrastive learning into an element-wise mode and use online pseudo labels for supervision on unlabeled areas. Experimental results show that our learning strategies can improve the classification and segmentation models by a large margin and outperform state-of-the-art approaches.
Towards disease-aware image editing of chest X-rays
Sep 03, 2021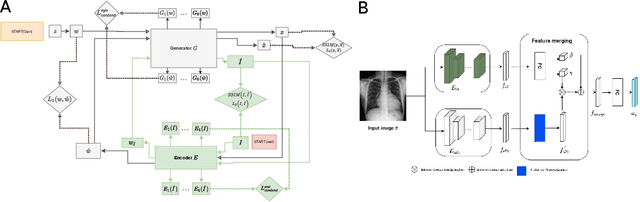
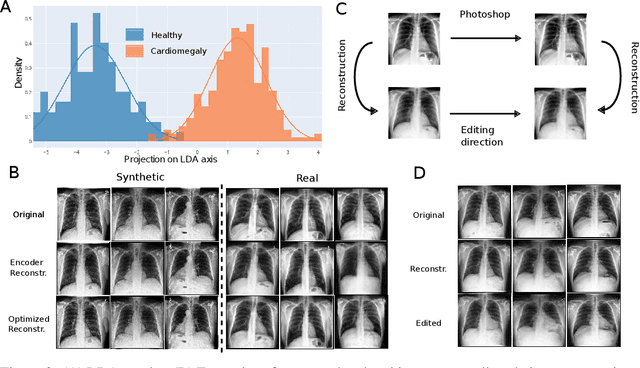
Disease-aware image editing by means of generative adversarial networks (GANs) constitutes a promising avenue for advancing the use of AI in the healthcare sector. Here, we present a proof of concept of this idea. While GAN-based techniques have been successful in generating and manipulating natural images, their application to the medical domain, however, is still in its infancy. Working with the CheXpert data set, we show that StyleGAN can be trained to generate realistic chest X-rays. Inspired by the Cyclic Reverse Generator (CRG) framework, we train an encoder that allows for faithfully inverting the generator on synthetic X-rays and provides organ-level reconstructions of real ones. Employing a guided manipulation of latent codes, we confer the medical condition of cardiomegaly (increased heart size) onto real X-rays from healthy patients. This work was presented in the Medical Imaging meets Neurips Workshop 2020, which was held as part of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020) in Vancouver, Canada
StyleGAN-Human: A Data-Centric Odyssey of Human Generation
Apr 25, 2022

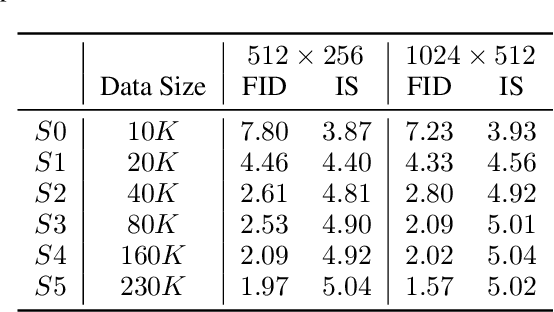
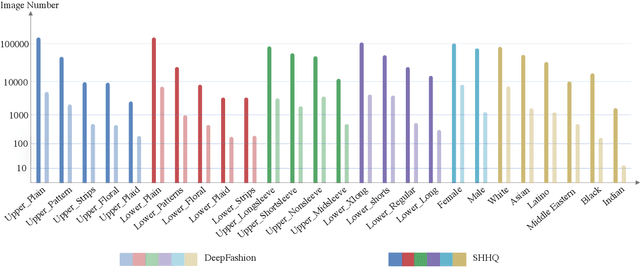
Unconditional human image generation is an important task in vision and graphics, which enables various applications in the creative industry. Existing studies in this field mainly focus on "network engineering" such as designing new components and objective functions. This work takes a data-centric perspective and investigates multiple critical aspects in "data engineering", which we believe would complement the current practice. To facilitate a comprehensive study, we collect and annotate a large-scale human image dataset with over 230K samples capturing diverse poses and textures. Equipped with this large dataset, we rigorously investigate three essential factors in data engineering for StyleGAN-based human generation, namely data size, data distribution, and data alignment. Extensive experiments reveal several valuable observations w.r.t. these aspects: 1) Large-scale data, more than 40K images, are needed to train a high-fidelity unconditional human generation model with vanilla StyleGAN. 2) A balanced training set helps improve the generation quality with rare face poses compared to the long-tailed counterpart, whereas simply balancing the clothing texture distribution does not effectively bring an improvement. 3) Human GAN models with body centers for alignment outperform models trained using face centers or pelvis points as alignment anchors. In addition, a model zoo and human editing applications are demonstrated to facilitate future research in the community.
UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes
May 27, 2022

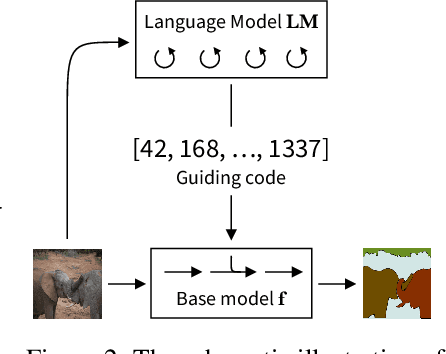

We introduce UViM, a unified approach capable of modeling a wide range of computer vision tasks. In contrast to previous models, UViM has the same functional form for all tasks; it requires no task-specific modifications which require extensive human expertise. The approach involves two components: (I) a base model (feed-forward) which is trained to directly predict raw vision outputs, guided by a learned discrete code and (II) a language model (autoregressive) that is trained to generate the guiding code. These components complement each other: the language model is well-suited to modeling structured interdependent data, while the base model is efficient at dealing with high-dimensional outputs. We demonstrate the effectiveness of UViM on three diverse and challenging vision tasks: panoptic segmentation, depth prediction and image colorization, where we achieve competitive and near state-of-the-art results. Our experimental results suggest that UViM is a promising candidate for a unified modeling approach in computer vision.
Fault Diagnosis of Inter-turn Short Circuit in Permanent Magnet Synchronous Motors with Current Signal Imaging and Unsupervised Learning
Jun 09, 2022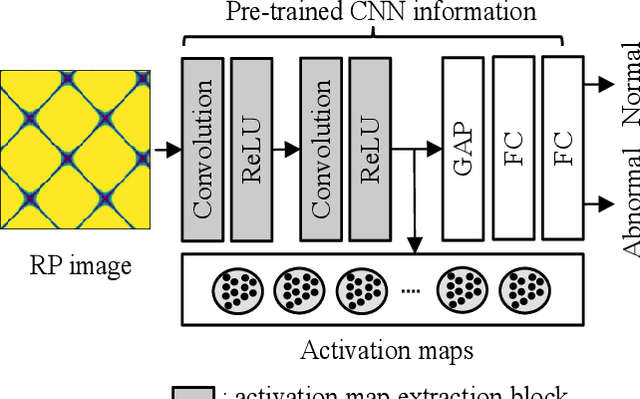
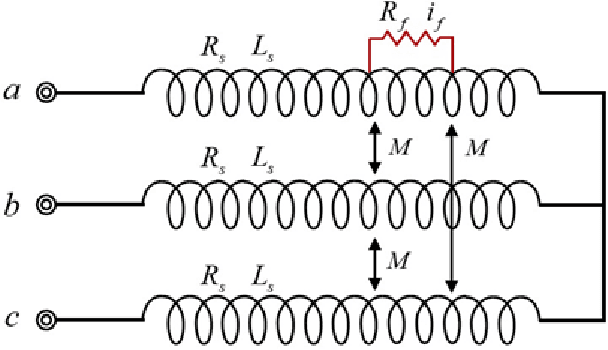

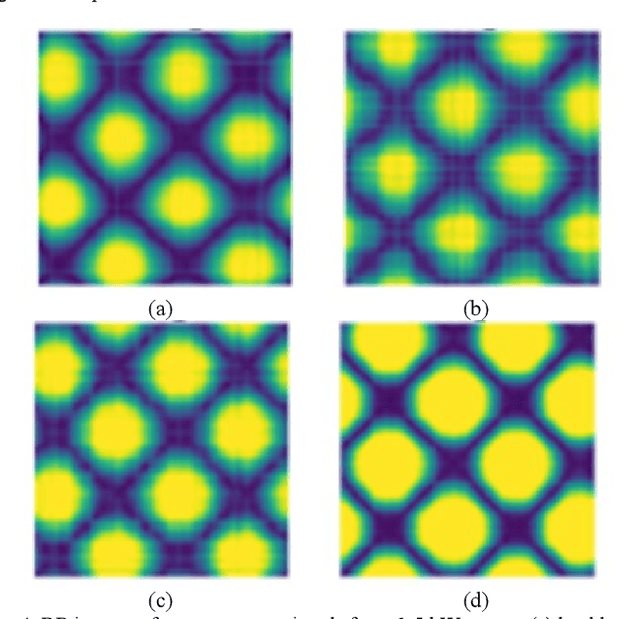
This paper proposes machine-independent feature engineering for winding inter-turn short circuit fault that uses electrical current signals. Electrical current signal collected from permanent magnet synchronous motor (PMSM) is subjected to different environmental and operational conditions. To solve these problems, robust current signal imaging method and deep learning-based feature extraction method are developed. The overall procedure includes the following three key steps: (1) transformation of a time-series current signal to two-dimensional image, (2) extracting features using convolutional neural networks, and (3) calculating a health indicator using Mahalanobis distance. Transformation of the time-series signal is based on recurrence plots (RP). The proposed RP method develops from feature engineering that provides the dominant fault feature representations in a robust way. The proposed RP is designed that maximizes the features of inter-turn short fault and minimizes the effect of noise from systems with various capacities. To demonstrate the validity of the proposed method, two case studies are conducted using an artificial fault seeded testbed with two different capacities of motor. By calculating the feature using only the electrical current signal of the motor without the parameters related to the capacity of the motor, the proposed feature can be applied to motors with different capacities while maintaining the same performance.
Attention-Guided NIR Image Colorization via Adaptive Fusion of Semantic and Texture Clues
Jul 20, 2021



Near infrared (NIR) imaging has been widely applied in low-light imaging scenarios; however, it is difficult for human and algorithms to perceive the real scene in the colorless NIR domain. While Generative Adversarial Network (GAN) has been widely employed in various image colorization tasks, it is challenging for a direct mapping mechanism, such as a conventional GAN, to transform an image from the NIR to the RGB domain with correct semantic reasoning, well-preserved textures, and vivid color combinations concurrently. In this work, we propose a novel Attention-based NIR image colorization framework via Adaptive Fusion of Semantic and Texture clues, aiming at achieving these goals within the same framework. The tasks of texture transfer and semantic reasoning are carried out in two separate network blocks. Specifically, the Texture Transfer Block (TTB) aims at extracting texture features from the NIR image's Laplacian component and transferring them for subsequent color fusion. The Semantic Reasoning Block (SRB) extracts semantic clues and maps the NIR pixel values to the RGB domain. Finally, a Fusion Attention Block (FAB) is proposed to adaptively fuse the features from the two branches and generate an optimized colorization result. In order to enhance the network's learning capacity in semantic reasoning as well as mapping precision in texture transfer, we have proposed the Residual Coordinate Attention Block (RCAB), which incorporates coordinate attention into a residual learning framework, enabling the network to capture long-range dependencies along the channel direction and meanwhile precise positional information can be preserved along spatial directions. RCAB is also incorporated into FAB to facilitate accurate texture alignment during fusion. Both quantitative and qualitative evaluations show that the proposed method outperforms state-of-the-art NIR image colorization methods.
Fairness for Image Generation with Uncertain Sensitive Attributes
Jun 23, 2021
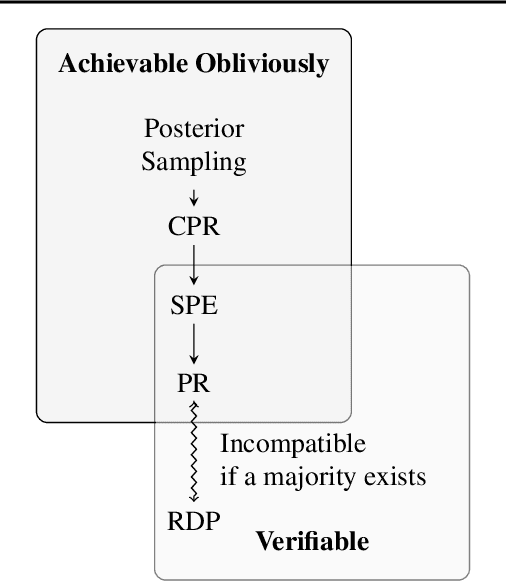
This work tackles the issue of fairness in the context of generative procedures, such as image super-resolution, which entail different definitions from the standard classification setting. Moreover, while traditional group fairness definitions are typically defined with respect to specified protected groups -- camouflaging the fact that these groupings are artificial and carry historical and political motivations -- we emphasize that there are no ground truth identities. For instance, should South and East Asians be viewed as a single group or separate groups? Should we consider one race as a whole or further split by gender? Choosing which groups are valid and who belongs in them is an impossible dilemma and being ``fair'' with respect to Asians may require being ``unfair'' with respect to South Asians. This motivates the introduction of definitions that allow algorithms to be \emph{oblivious} to the relevant groupings. We define several intuitive notions of group fairness and study their incompatibilities and trade-offs. We show that the natural extension of demographic parity is strongly dependent on the grouping, and \emph{impossible} to achieve obliviously. On the other hand, the conceptually new definition we introduce, Conditional Proportional Representation, can be achieved obliviously through Posterior Sampling. Our experiments validate our theoretical results and achieve fair image reconstruction using state-of-the-art generative models.
Non-Iterative Recovery from Nonlinear Observations using Generative Models
Jun 01, 2022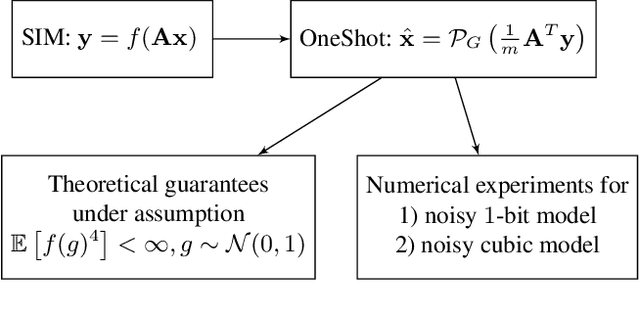
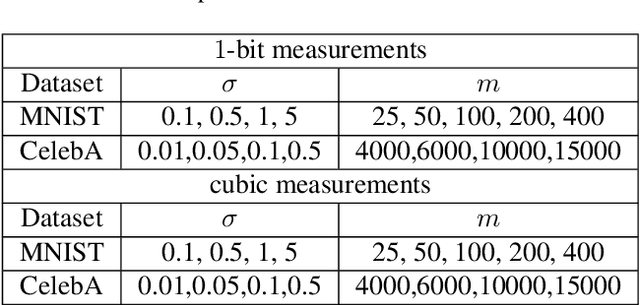
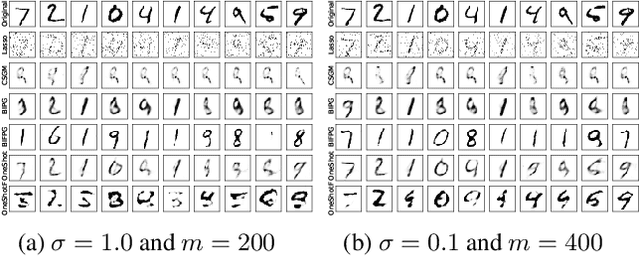
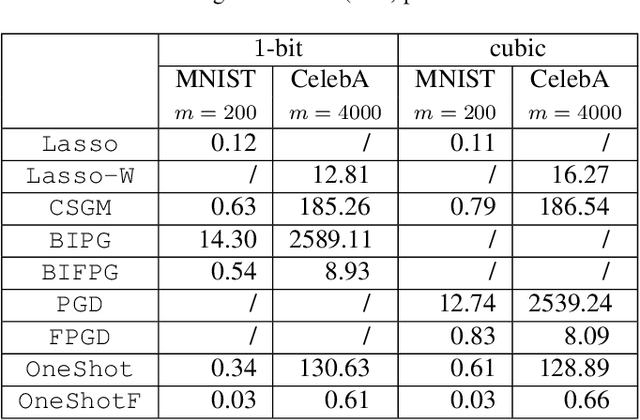
In this paper, we aim to estimate the direction of an underlying signal from its nonlinear observations following the semi-parametric single index model (SIM). Unlike conventional compressed sensing where the signal is assumed to be sparse, we assume that the signal lies in the range of an $L$-Lipschitz continuous generative model with bounded $k$-dimensional inputs. This is mainly motivated by the tremendous success of deep generative models in various real applications. Our reconstruction method is non-iterative (though approximating the projection step may use an iterative procedure) and highly efficient, and it is shown to attain the near-optimal statistical rate of order $\sqrt{(k \log L)/m}$, where $m$ is the number of measurements. We consider two specific instances of the SIM, namely noisy $1$-bit and cubic measurement models, and perform experiments on image datasets to demonstrate the efficacy of our method. In particular, for the noisy $1$-bit measurement model, we show that our non-iterative method significantly outperforms a state-of-the-art iterative method in terms of both accuracy and efficiency.