 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Subspace Representation Learning for Few-shot Image Classification
May 02, 2021
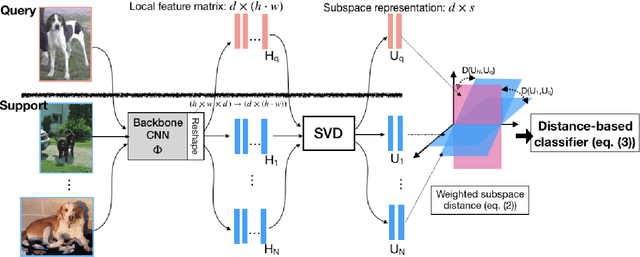
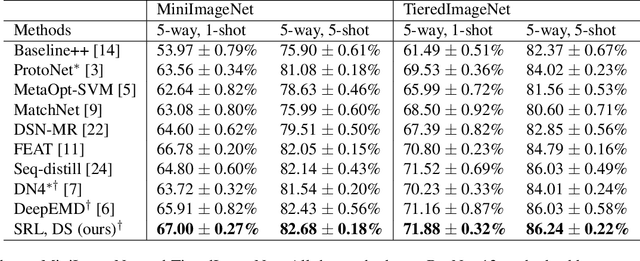
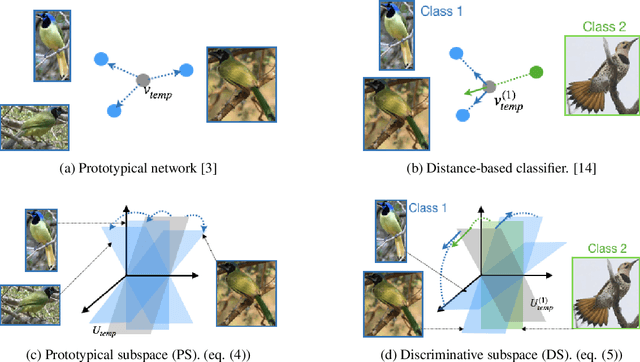
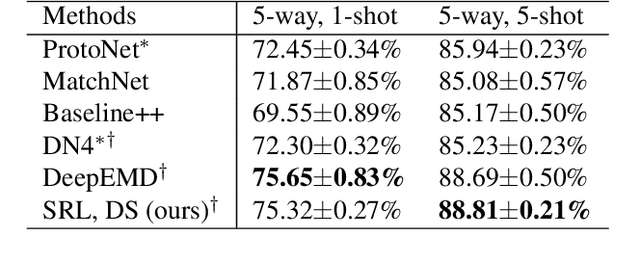
In this paper, we propose a subspace representation learning (SRL) framework to tackle few-shot image classification tasks. It exploits a subspace in local CNN feature space to represent an image, and measures the similarity between two images according to a weighted subspace distance (WSD). When K images are available for each class, we develop two types of template subspaces to aggregate K-shot information: the prototypical subspace (PS) and the discriminative subspace (DS). Based on the SRL framework, we extend metric learning based techniques from vector to subspace representation. While most previous works adopted global vector representation, using subspace representation can effectively preserve the spatial structure, and diversity within an image. We demonstrate the effectiveness of the SRL framework on three public benchmark datasets: MiniImageNet, TieredImageNet and Caltech-UCSD Birds-200-2011 (CUB), and the experimental results illustrate competitive/superior performance of our method compared to the previous state-of-the-art.
Learning to Erase the Bayer-Filter to See in the Dark
Mar 08, 2022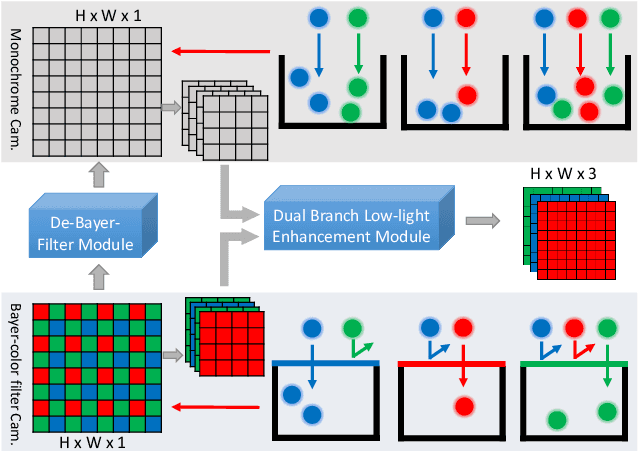


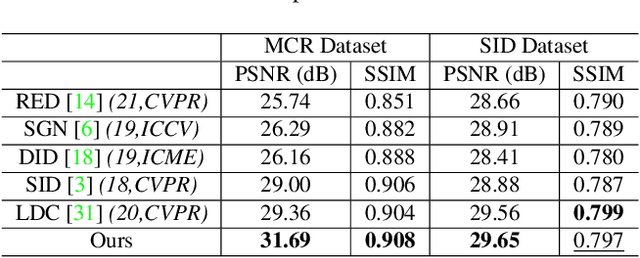
Low-light image enhancement - a pervasive but challenging problem, plays a central role in enhancing the visibility of an image captured in a poor illumination environment. Due to the fact that not all photons can pass the Bayer-Filter on the sensor of the color camera, in this work, we first present a De-Bayer-Filter simulator based on deep neural networks to generate a monochrome raw image from the colored raw image. Next, a fully convolutional network is proposed to achieve the low-light image enhancement by fusing colored raw data with synthesized monochrome raw data. Channel-wise attention is also introduced to the fusion process to establish a complementary interaction between features from colored and monochrome raw images. To train the convolutional networks, we propose a dataset with monochrome and color raw pairs named Mono-Colored Raw paired dataset (MCR) collected by using a monochrome camera without Bayer-Filter and a color camera with Bayer-Filter. The proposed pipeline take advantages of the fusion of the virtual monochrome and the color raw images and our extensive experiments indicate that significant improvement can be achieved by leveraging raw sensor data and data-driven learning.
Image content dependent semi-fragile watermarking with localized tamper detection
Jun 27, 2021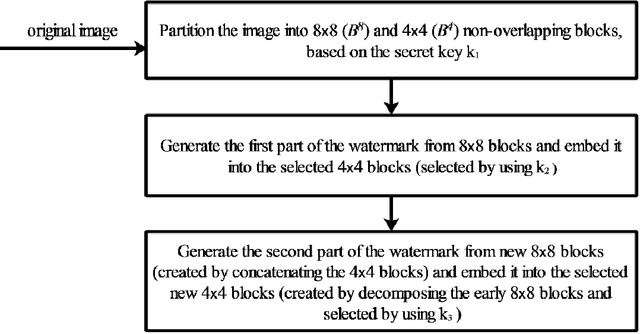
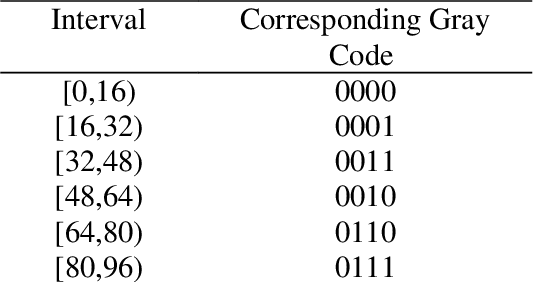
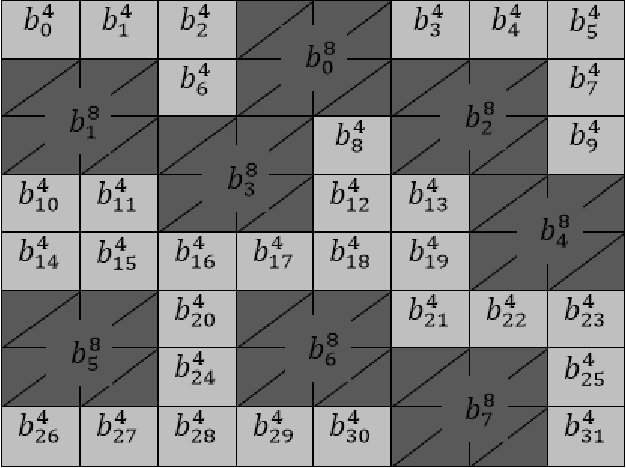
Content-independent watermarks and block-wise independency can be considered as vulnerabilities in semi-fragile watermarking methods. In this paper to achieve the objectives of semi-fragile watermarking techniques, a method is proposed to not have the mentioned shortcomings. In the proposed method, the watermark is generated by relying on image content and a key. Furthermore, the embedding scheme causes the watermarked blocks to become dependent on each other, using a key. In the embedding phase, the image is partitioned into non-overlapping blocks. In order to detect and separate the different types of attacks more precisely, the proposed method embeds three copies of each watermark bit into LWT coefficients of each 4x4 block. In the authentication phase, by voting between the extracted bits the error maps are created; these maps indicate image authenticity and reveal the modified regions. Also, in order to automate the authentication, the images are classified into four categories using seven features. Classification accuracy in the experiments is 97.97 percent. It is noted that our experiments demonstrate that the proposed method is robust against JPEG compression and is competitive with a state-of-the-art semi-fragile watermarking method, in terms of robustness and semi-fragility.
SNeS: Learning Probably Symmetric Neural Surfaces from Incomplete Data
Jun 13, 2022
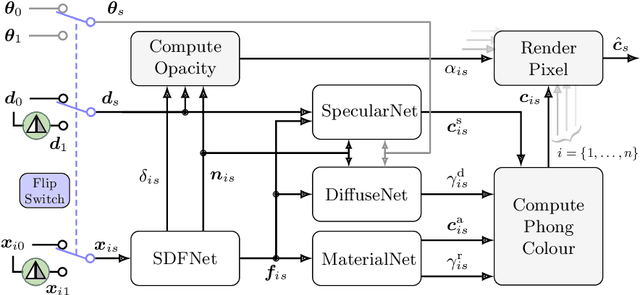
We present a method for the accurate 3D reconstruction of partly-symmetric objects. We build on the strengths of recent advances in neural reconstruction and rendering such as Neural Radiance Fields (NeRF). A major shortcoming of such approaches is that they fail to reconstruct any part of the object which is not clearly visible in the training image, which is often the case for in-the-wild images and videos. When evidence is lacking, structural priors such as symmetry can be used to complete the missing information. However, exploiting such priors in neural rendering is highly non-trivial: while geometry and non-reflective materials may be symmetric, shadows and reflections from the ambient scene are not symmetric in general. To address this, we apply a soft symmetry constraint to the 3D geometry and material properties, having factored appearance into lighting, albedo colour and reflectivity. We evaluate our method on the recently introduced CO3D dataset, focusing on the car category due to the challenge of reconstructing highly-reflective materials. We show that it can reconstruct unobserved regions with high fidelity and render high-quality novel view images.
Beyond 3DMM: Learning to Capture High-fidelity 3D Face Shape
Apr 09, 2022

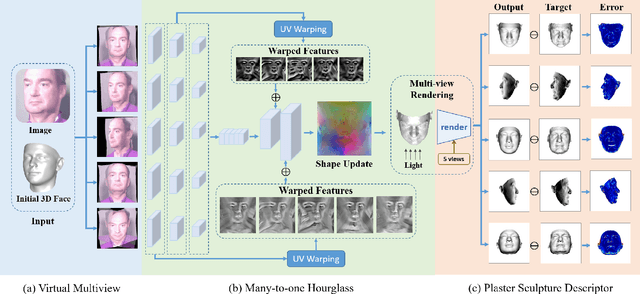
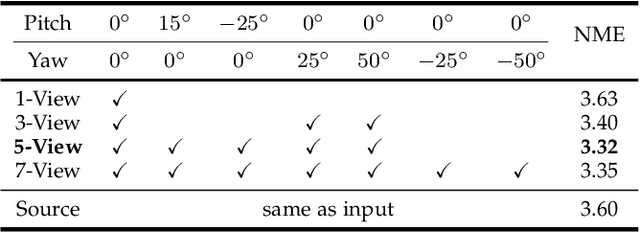
3D Morphable Model (3DMM) fitting has widely benefited face analysis due to its strong 3D priori. However, previous reconstructed 3D faces suffer from degraded visual verisimilitude due to the loss of fine-grained geometry, which is attributed to insufficient ground-truth 3D shapes, unreliable training strategies and limited representation power of 3DMM. To alleviate this issue, this paper proposes a complete solution to capture the personalized shape so that the reconstructed shape looks identical to the corresponding person. Specifically, given a 2D image as the input, we virtually render the image in several calibrated views to normalize pose variations while preserving the original image geometry. A many-to-one hourglass network serves as the encode-decoder to fuse multiview features and generate vertex displacements as the fine-grained geometry. Besides, the neural network is trained by directly optimizing the visual effect, where two 3D shapes are compared by measuring the similarity between the multiview images rendered from the shapes. Finally, we propose to generate the ground-truth 3D shapes by registering RGB-D images followed by pose and shape augmentation, providing sufficient data for network training. Experiments on several challenging protocols demonstrate the superior reconstruction accuracy of our proposal on the face shape.
Counting Varying Density Crowds Through Density Guided Adaptive Selection CNN and Transformer Estimation
Jun 21, 2022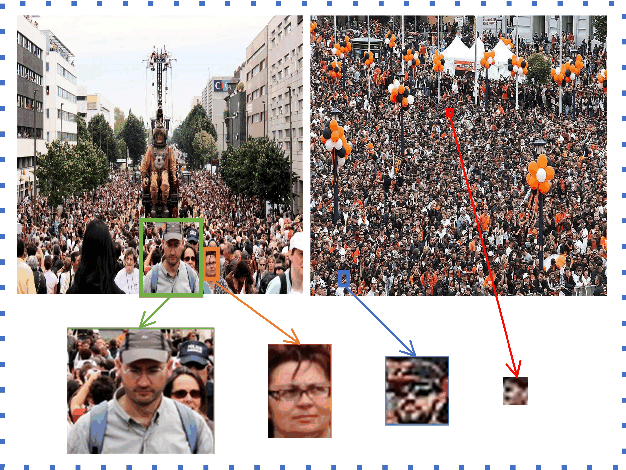

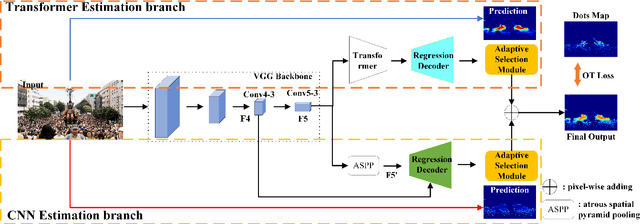
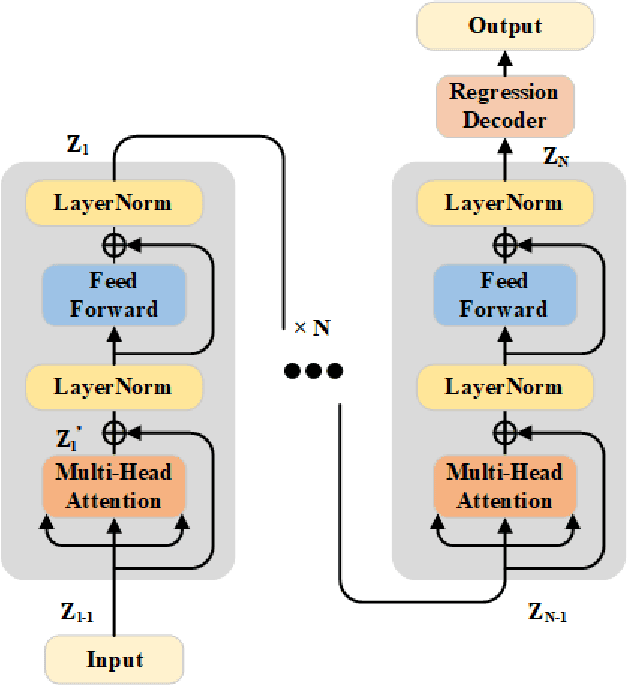
In real-world crowd counting applications, the crowd densities in an image vary greatly. When facing with density variation, human tend to locate and count the target in low-density regions, and reason the number in high-density regions. We observe that CNN focus on the local information correlation using a fixed-size convolution kernel and the Transformer could effectively extract the semantic crowd information by using the global self-attention mechanism. Thus, CNN could locate and estimate crowd accurately in low-density regions, while it is hard to properly perceive density in high-density regions. On the contrary, Transformer, has a high reliability in high-density regions, but fails to locate the target in sparse regions. Neither CNN or Transformer can well deal with this kind of density variations. To address this problem, we propose a CNN and Transformer Adaptive Selection Network (CTASNet) which can adaptively select the appropriate counting branch for different density regions. Firstly, CTASNet generates the prediction results of CNN and Transformer. Then, considering that CNN/Transformer are appropriate for low/high-density regions, a density guided Adaptive Selection Module is designed to automatically combine the predictions of CNN and Transformer. Moreover, to reduce the influences of annotation noise, we introduce a Correntropy based Optimal Transport loss. Extensive experiments on four challenging crowd counting datasets have validated the proposed method.
End-to-End Learned Image Compression with Quantized Weights and Activations
Nov 17, 2021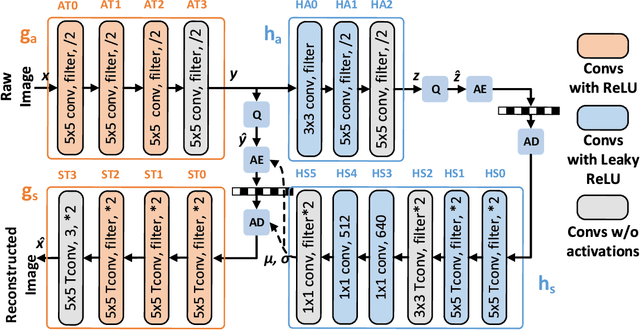

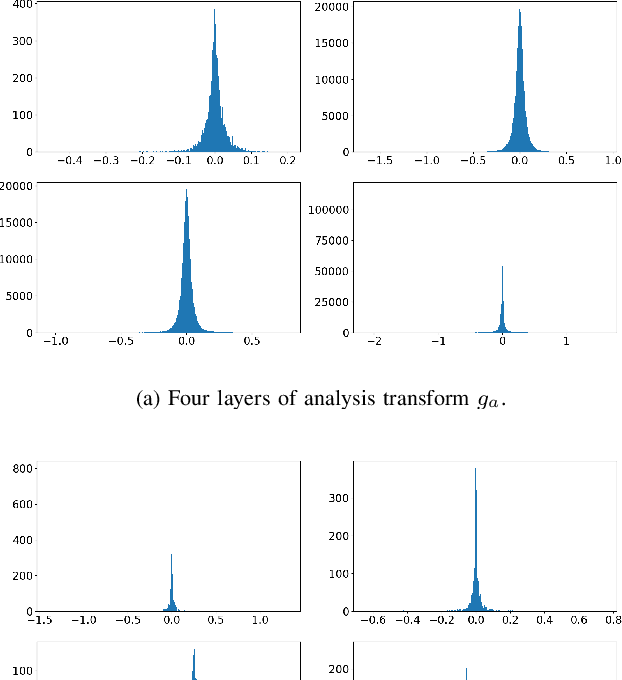
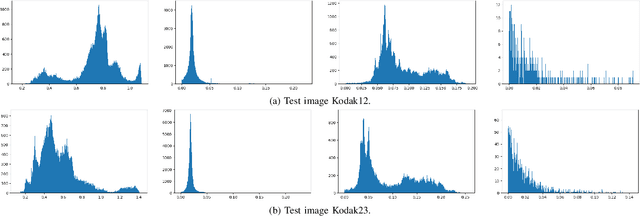
End-to-end Learned image compression (LIC) has reached the traditional hand-crafted methods such as BPG (HEVC intra) in terms of the coding gain. However, the large network size prohibits the usage of LIC on resource-limited embedded systems. This paper reduces the network complexity by quantizing both weights and activations. 1) For the weight quantization, we study different kinds of grouping and quantization scheme at first. A channel-wise non-linear quantization scheme is determined based on the coding gain analysis. After that, we propose a fine tuning scheme to clip the weights within a certain range so that the quantization error can be reduced. 2) For the activation quantization, we first propose multiple non-linear quantization codebooks with different maximum dynamic ranges. By selecting an optimal one through a multiplexer, the quantization range can be saturated to the greatest extent. In addition, we also exploit the mean-removed quantization for the analysis transform outputs in order to reduce the bit-width cost for the specific channel with the large non-zero mean. By quantizing each weight and activation element from 32-bit floating point to 8-bit fixed point, the memory cost for both weight and activation can be reduced by 75% with negligible coding performance loss. As a result, our quantized LIC can still outperform BPG in terms of MS-SSIM. To our best knowledge, this is the first work to give a complete analysis on the coding gain and the memory cost for a quantized LIC network, which validates the feasibility of the hardware implementation.
DeepPortraitDrawing: Generating Human Body Images from Freehand Sketches
May 04, 2022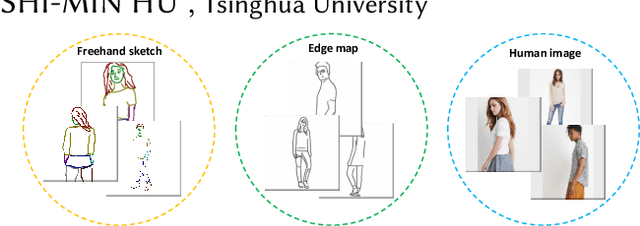
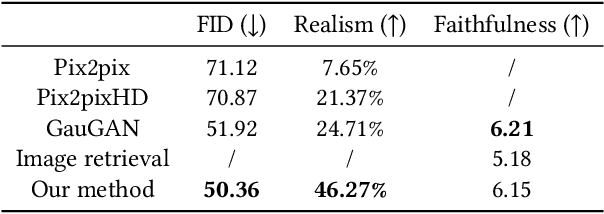
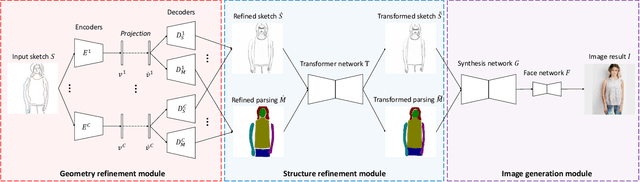
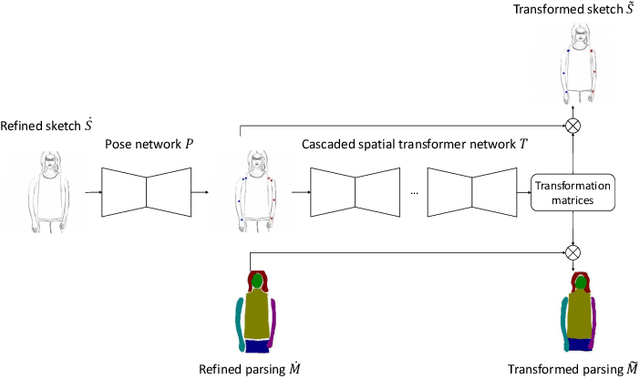
Researchers have explored various ways to generate realistic images from freehand sketches, e.g., for objects and human faces. However, how to generate realistic human body images from sketches is still a challenging problem. It is, first because of the sensitivity to human shapes, second because of the complexity of human images caused by body shape and pose changes, and third because of the domain gap between realistic images and freehand sketches. In this work, we present DeepPortraitDrawing, a deep generative framework for converting roughly drawn sketches to realistic human body images. To encode complicated body shapes under various poses, we take a local-to-global approach. Locally, we employ semantic part auto-encoders to construct part-level shape spaces, which are useful for refining the geometry of an input pre-segmented hand-drawn sketch. Globally, we employ a cascaded spatial transformer network to refine the structure of body parts by adjusting their spatial locations and relative proportions. Finally, we use a global synthesis network for the sketch-to-image translation task, and a face refinement network to enhance facial details. Extensive experiments have shown that given roughly sketched human portraits, our method produces more realistic images than the state-of-the-art sketch-to-image synthesis techniques.
Specifying and Testing $k$-Safety Properties for Machine-Learning Models
Jun 13, 2022
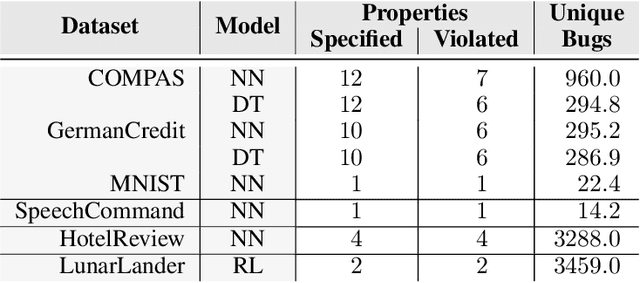

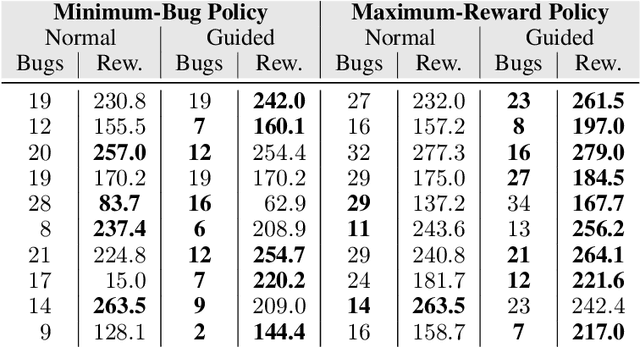
Machine-learning models are becoming increasingly prevalent in our lives, for instance assisting in image-classification or decision-making tasks. Consequently, the reliability of these models is of critical importance and has resulted in the development of numerous approaches for validating and verifying their robustness and fairness. However, beyond such specific properties, it is challenging to specify, let alone check, general functional-correctness expectations from models. In this paper, we take inspiration from specifications used in formal methods, expressing functional-correctness properties by reasoning about $k$ different executions, so-called $k$-safety properties. Considering a credit-screening model of a bank, the expected property that "if a person is denied a loan and their income decreases, they should still be denied the loan" is a 2-safety property. Here, we show the wide applicability of $k$-safety properties for machine-learning models and present the first specification language for expressing them. We also operationalize the language in a framework for automatically validating such properties using metamorphic testing. Our experiments show that our framework is effective in identifying property violations, and that detected bugs could be used to train better models.
All the attention you need: Global-local, spatial-channel attention for image retrieval
Jul 16, 2021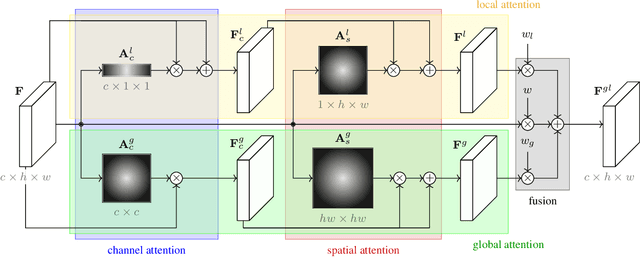
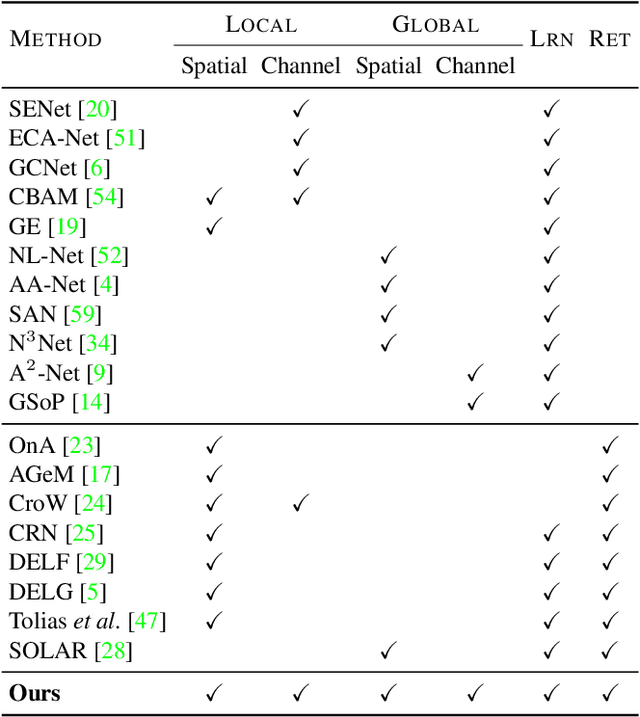
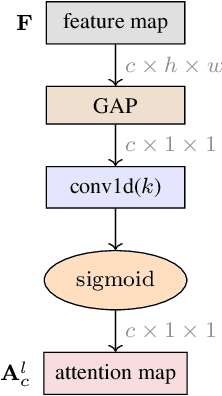
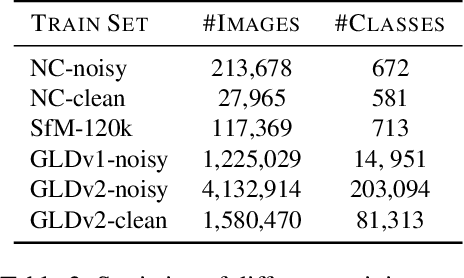
We address representation learning for large-scale instance-level image retrieval. Apart from backbone, training pipelines and loss functions, popular approaches have focused on different spatial pooling and attention mechanisms, which are at the core of learning a powerful global image representation. There are different forms of attention according to the interaction of elements of the feature tensor (local and global) and the dimensions where it is applied (spatial and channel). Unfortunately, each study addresses only one or two forms of attention and applies it to different problems like classification, detection or retrieval. We present global-local attention module (GLAM), which is attached at the end of a backbone network and incorporates all four forms of attention: local and global, spatial and channel. We obtain a new feature tensor and, by spatial pooling, we learn a powerful embedding for image retrieval. Focusing on global descriptors, we provide empirical evidence of the interaction of all forms of attention and improve the state of the art on standard benchmarks.