 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Human-in-the-loop System for Guiding DNNs Attention
Jun 14, 2022
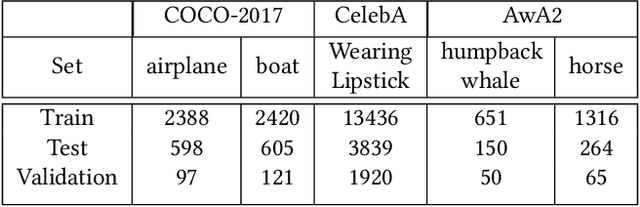

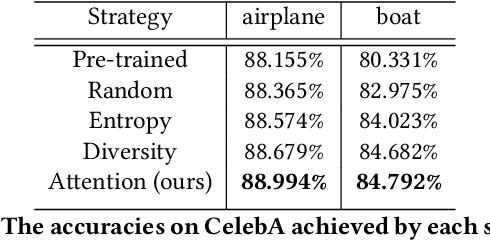
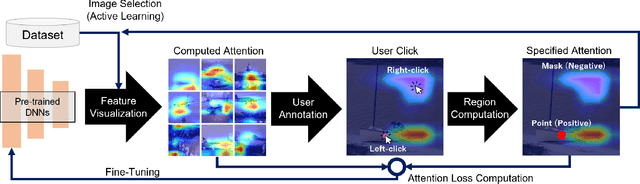
Attention guidance is an approach to addressing dataset bias in deep learning, where the model relies on incorrect features to make decisions. Focusing on image classification tasks, we propose an efficient human-in-the-loop system to interactively direct the attention of classifiers to the regions specified by users, thereby reducing the influence of co-occurrence bias and improving the transferability and interpretability of a DNN. Previous approaches for attention guidance require the preparation of pixel-level annotations and are not designed as interactive systems. We present a new interactive method to allow users to annotate images with simple clicks, and study a novel active learning strategy to significantly reduce the number of annotations. We conducted both a numerical evaluation and a user study to evaluate the proposed system on multiple datasets. Compared to the existing non-active-learning approach which usually relies on huge amounts of polygon-based segmentation masks to fine-tune or train the DNNs, our system can save lots of labor and money and obtain a fine-tuned network that works better even when the dataset is biased. The experiment results indicate that the proposed system is efficient, reasonable, and reliable.
Shallow camera pipeline for night photography rendering
Apr 19, 2022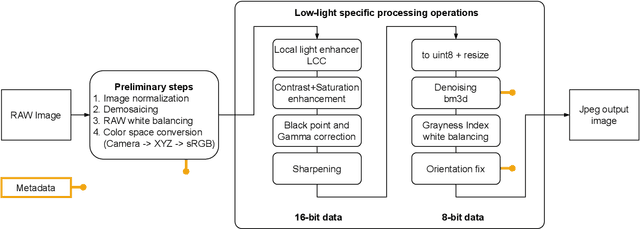
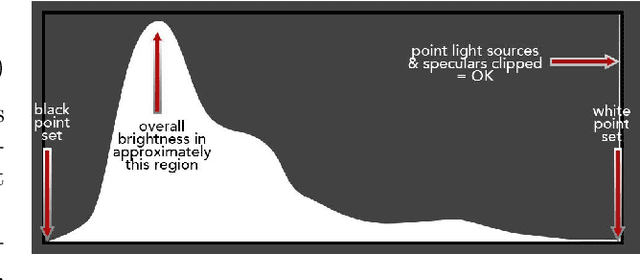

We introduce a camera pipeline for rendering visually pleasing photographs in low light conditions, as part of the NTIRE2022 Night Photography Rendering challenge. Given the nature of the task, where the objective is verbally defined by an expert photographer instead of relying on explicit ground truth images, we design an handcrafted solution, characterized by a shallow structure and by a low parameter count. Our pipeline exploits a local light enhancer as a form of high dynamic range correction, followed by a global adjustment of the image histogram to prevent washed-out results. We proportionally apply image denoising to darker regions, where it is more easily perceived, without losing details on brighter regions. The solution reached the fifth place in the competition, with a preference vote count comparable to those of other entries, based on deep convolutional neural networks. Code is available at www.github.com/AvailableAfterAcceptance.
SpecNet2: Orthogonalization-free spectral embedding by neural networks
Jun 14, 2022
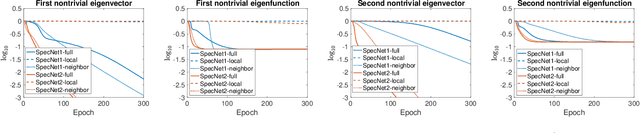

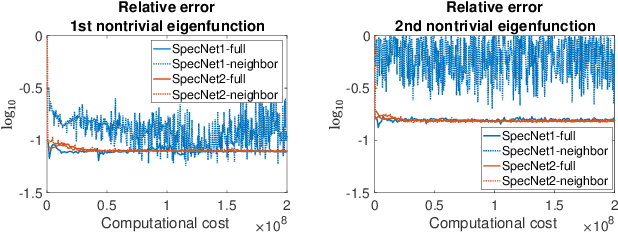
Spectral methods which represent data points by eigenvectors of kernel matrices or graph Laplacian matrices have been a primary tool in unsupervised data analysis. In many application scenarios, parametrizing the spectral embedding by a neural network that can be trained over batches of data samples gives a promising way to achieve automatic out-of-sample extension as well as computational scalability. Such an approach was taken in the original paper of SpectralNet (Shaham et al. 2018), which we call SpecNet1. The current paper introduces a new neural network approach, named SpecNet2, to compute spectral embedding which optimizes an equivalent objective of the eigen-problem and removes the orthogonalization layer in SpecNet1. SpecNet2 also allows separating the sampling of rows and columns of the graph affinity matrix by tracking the neighbors of each data point through the gradient formula. Theoretically, we show that any local minimizer of the new orthogonalization-free objective reveals the leading eigenvectors. Furthermore, global convergence for this new orthogonalization-free objective using a batch-based gradient descent method is proved. Numerical experiments demonstrate the improved performance and computational efficiency of SpecNet2 on simulated data and image datasets.
How Many Events do You Need? Event-based Visual Place Recognition Using Sparse But Varying Pixels
Jun 28, 2022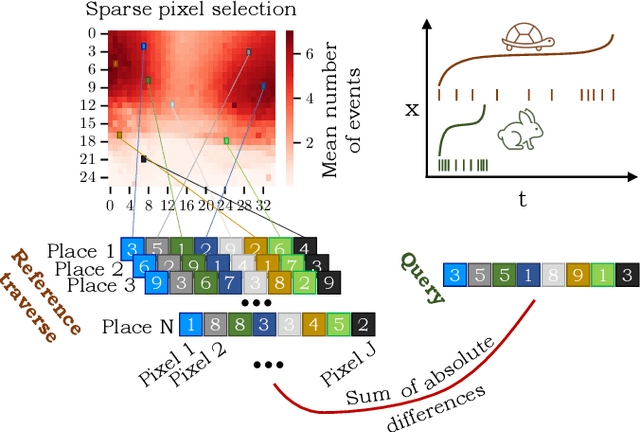
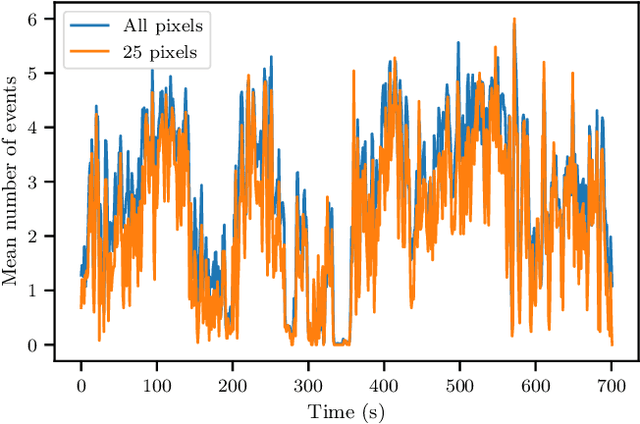
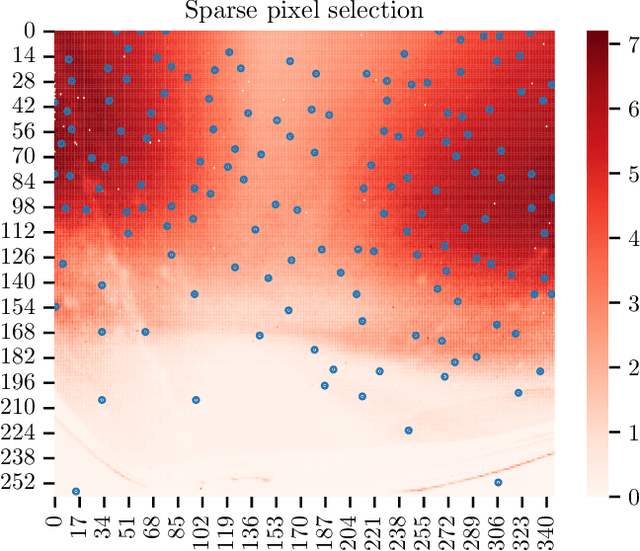

Event cameras continue to attract interest due to desirable characteristics such as high dynamic range, low latency, virtually no motion blur, and high energy efficiency. One of the potential applications of event camera research lies in visual place recognition for robot localization, where a query observation has to be matched to the corresponding reference place in the database. In this letter, we explore the distinctiveness of event streams from a small subset of pixels (in the tens or hundreds). We demonstrate that the absolute difference in the number of events at those pixel locations accumulated into event frames can be sufficient for the place recognition task, when pixels that display large variations in the reference set are used. Using such sparse (over image coordinates) but varying (variance over the number of events per pixel location) pixels enables frequent and computationally cheap updates of the location estimates. Furthermore, when event frames contain a constant number of events, our method takes full advantage of the event-driven nature of the sensory stream and displays promising robustness to changes in velocity. We evaluate our proposed approach on the Brisbane-Event-VPR dataset in an outdoor driving scenario, as well as the newly contributed indoor QCR-Event-VPR dataset that was captured with a DAVIS346 camera mounted on a mobile robotic platform. Our results show that our approach achieves competitive performance when compared to several baseline methods on those datasets, and is particularly well suited for compute- and energy-constrained platforms such as interplanetary rovers.
Shifts 2.0: Extending The Dataset of Real Distributional Shifts
Jun 30, 2022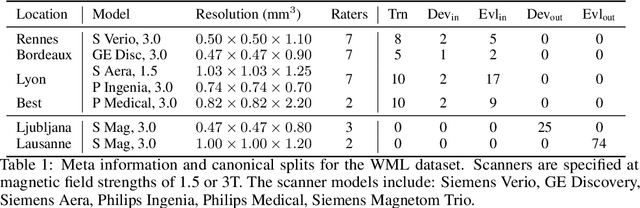
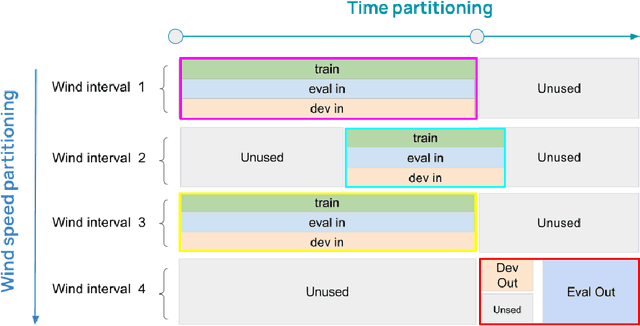
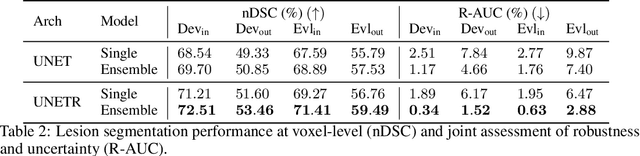
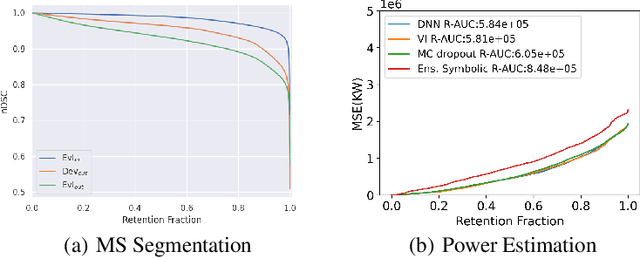
Distributional shift, or the mismatch between training and deployment data, is a significant obstacle to the usage of machine learning in high-stakes industrial applications, such as autonomous driving and medicine. This creates a need to be able to assess how robustly ML models generalize as well as the quality of their uncertainty estimates. Standard ML baseline datasets do not allow these properties to be assessed, as the training, validation and test data are often identically distributed. Recently, a range of dedicated benchmarks have appeared, featuring both distributionally matched and shifted data. Among these benchmarks, the Shifts dataset stands out in terms of the diversity of tasks as well as the data modalities it features. While most of the benchmarks are heavily dominated by 2D image classification tasks, Shifts contains tabular weather forecasting, machine translation, and vehicle motion prediction tasks. This enables the robustness properties of models to be assessed on a diverse set of industrial-scale tasks and either universal or directly applicable task-specific conclusions to be reached. In this paper, we extend the Shifts Dataset with two datasets sourced from industrial, high-risk applications of high societal importance. Specifically, we consider the tasks of segmentation of white matter Multiple Sclerosis lesions in 3D magnetic resonance brain images and the estimation of power consumption in marine cargo vessels. Both tasks feature ubiquitous distributional shifts and a strict safety requirement due to the high cost of errors. These new datasets will allow researchers to further explore robust generalization and uncertainty estimation in new situations. In this work, we provide a description of the dataset and baseline results for both tasks.
Motion Estimation for Large Displacements and Deformations
Jun 24, 2022
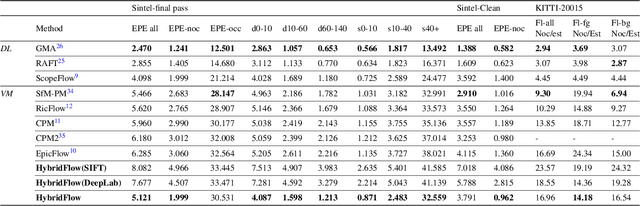


Large displacement optical flow is an integral part of many computer vision tasks. Variational optical flow techniques based on a coarse-to-fine scheme interpolate sparse matches and locally optimize an energy model conditioned on colour, gradient and smoothness, making them sensitive to noise in the sparse matches, deformations, and arbitrarily large displacements. This paper addresses this problem and presents HybridFlow, a variational motion estimation framework for large displacements and deformations. A multi-scale hybrid matching approach is performed on the image pairs. Coarse-scale clusters formed by classifying pixels according to their feature descriptors are matched using the clusters' context descriptors. We apply a multi-scale graph matching on the finer-scale superpixels contained within each matched pair of coarse-scale clusters. Small clusters that cannot be further subdivided are matched using localized feature matching. Together, these initial matches form the flow, which is propagated by an edge-preserving interpolation and variational refinement. Our approach does not require training and is robust to substantial displacements and rigid and non-rigid transformations due to motion in the scene, making it ideal for large-scale imagery such as Wide-Area Motion Imagery (WAMI). More notably, HybridFlow works on directed graphs of arbitrary topology representing perceptual groups, which improves motion estimation in the presence of significant deformations. We demonstrate HybridFlow's superior performance to state-of-the-art variational techniques on two benchmark datasets and report comparable results with state-of-the-art deep-learning-based techniques.
An Effective Fusion Method to Enhance the Robustness of CNN
May 31, 2022
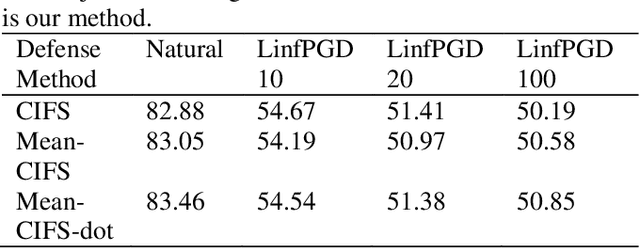
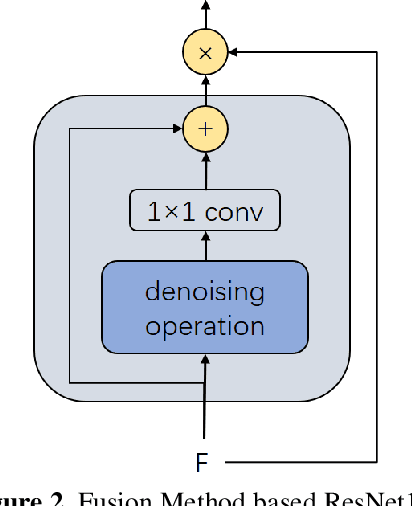
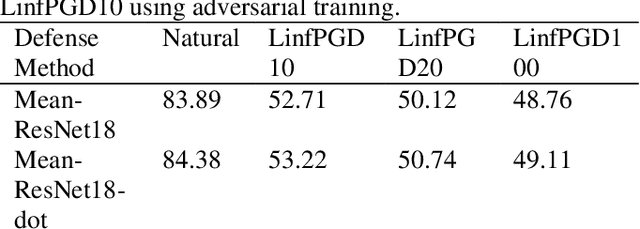
With the development of technology rapidly, applications of convolutional neural networks have improved the convenience of our life. However, in image classification field, it has been found that when some perturbations are added to images, the CNN would misclassify it. Thus various defense methods have been proposed. The previous approach only considered how to incorporate modules in the network to improve robustness, but did not focus on the way the modules were incorporated. In this paper, we design a new fusion method to enhance the robustness of CNN. We use a dot product-based approach to add the denoising module to ResNet18 and the attention mechanism to further improve the robustness of the model. The experimental results on CIFAR10 have shown that our method is effective and better than the state-of-the-art methods under the attack of FGSM and PGD.
Subspace Representation Learning for Few-shot Image Classification
May 02, 2021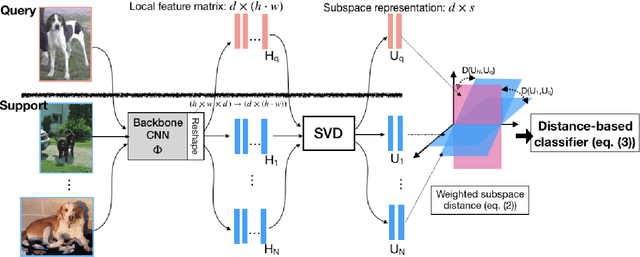
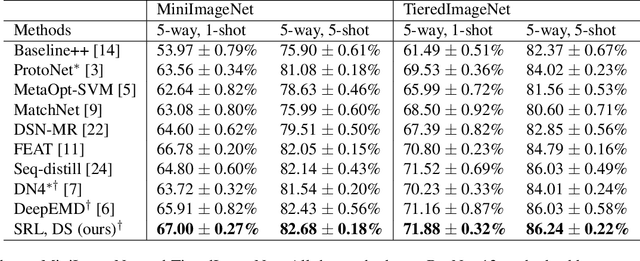
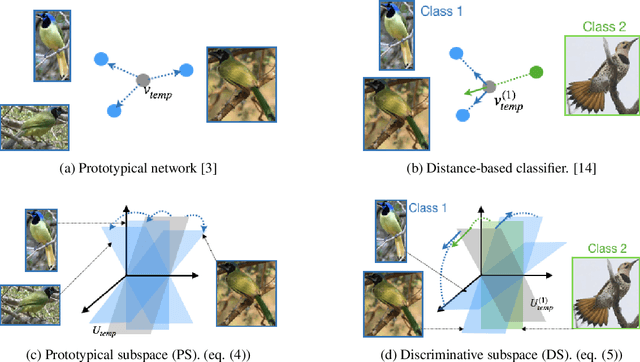
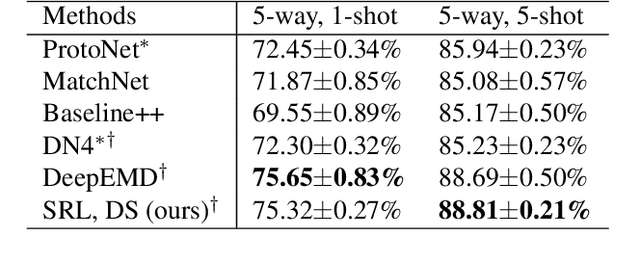
In this paper, we propose a subspace representation learning (SRL) framework to tackle few-shot image classification tasks. It exploits a subspace in local CNN feature space to represent an image, and measures the similarity between two images according to a weighted subspace distance (WSD). When K images are available for each class, we develop two types of template subspaces to aggregate K-shot information: the prototypical subspace (PS) and the discriminative subspace (DS). Based on the SRL framework, we extend metric learning based techniques from vector to subspace representation. While most previous works adopted global vector representation, using subspace representation can effectively preserve the spatial structure, and diversity within an image. We demonstrate the effectiveness of the SRL framework on three public benchmark datasets: MiniImageNet, TieredImageNet and Caltech-UCSD Birds-200-2011 (CUB), and the experimental results illustrate competitive/superior performance of our method compared to the previous state-of-the-art.
Improving Aleatoric Uncertainty Quantification in Multi-Annotated Medical Image Segmentation with Normalizing Flows
Aug 05, 2021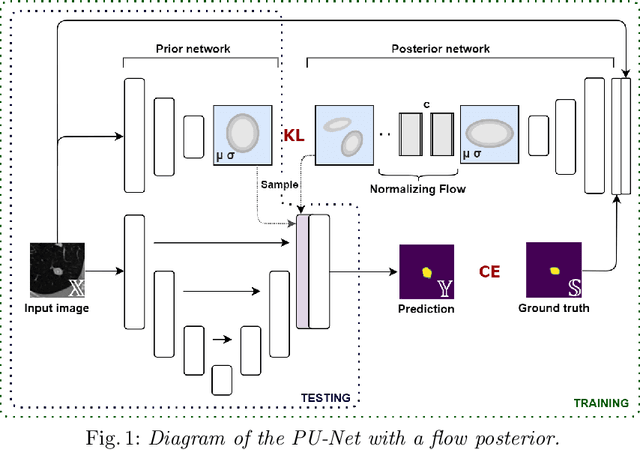
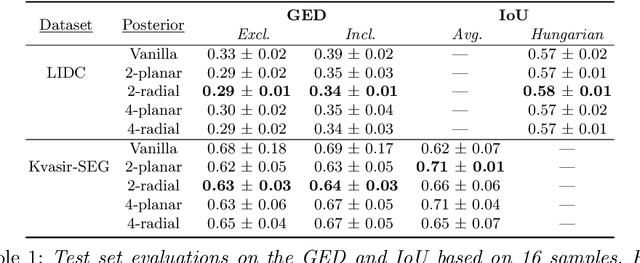
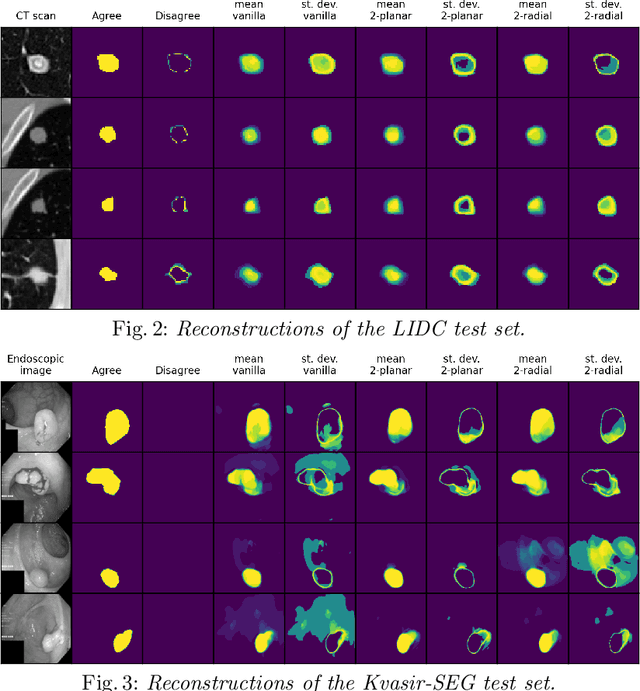
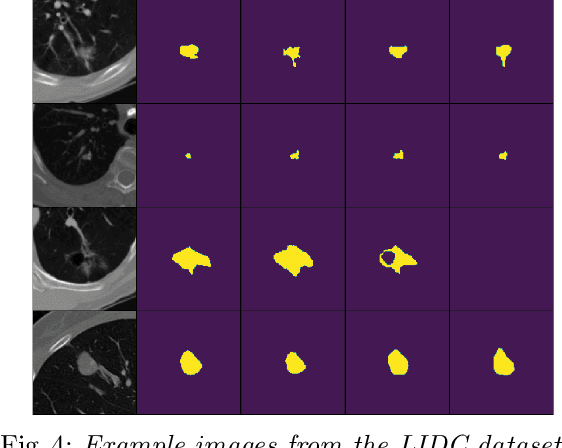
Quantifying uncertainty in medical image segmentation applications is essential, as it is often connected to vital decision-making. Compelling attempts have been made in quantifying the uncertainty in image segmentation architectures, e.g. to learn a density segmentation model conditioned on the input image. Typical work in this field restricts these learnt densities to be strictly Gaussian. In this paper, we propose to use a more flexible approach by introducing Normalizing Flows (NFs), which enables the learnt densities to be more complex and facilitate more accurate modeling for uncertainty. We prove this hypothesis by adopting the Probabilistic U-Net and augmenting the posterior density with an NF, allowing it to be more expressive. Our qualitative as well as quantitative (GED and IoU) evaluations on the multi-annotated and single-annotated LIDC-IDRI and Kvasir-SEG segmentation datasets, respectively, show a clear improvement. This is mostly apparent in the quantification of aleatoric uncertainty and the increased predictive performance of up to 14 percent. This result strongly indicates that a more flexible density model should be seriously considered in architectures that attempt to capture segmentation ambiguity through density modeling. The benefit of this improved modeling will increase human confidence in annotation and segmentation, and enable eager adoption of the technology in practice.
Image content dependent semi-fragile watermarking with localized tamper detection
Jun 27, 2021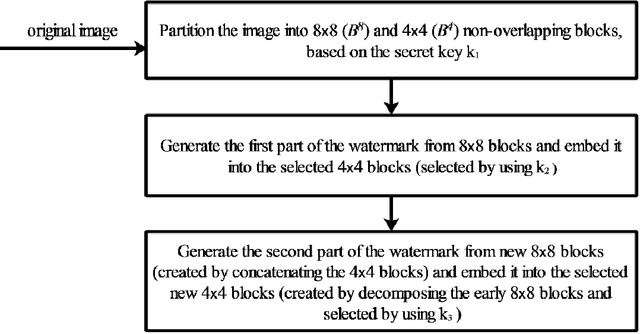
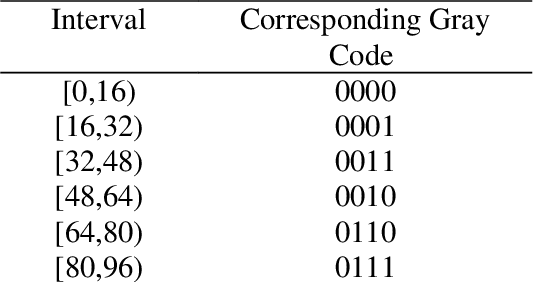
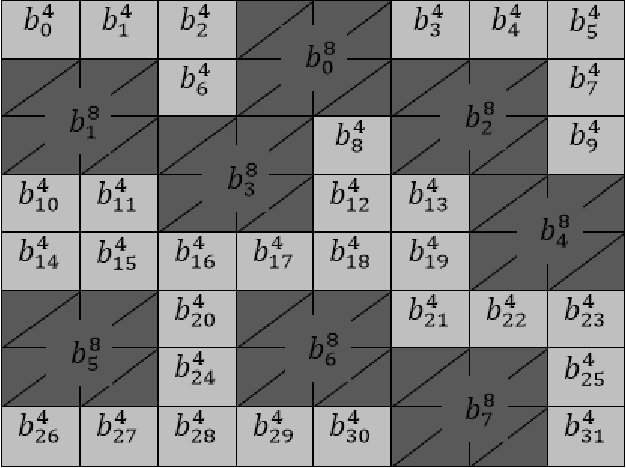
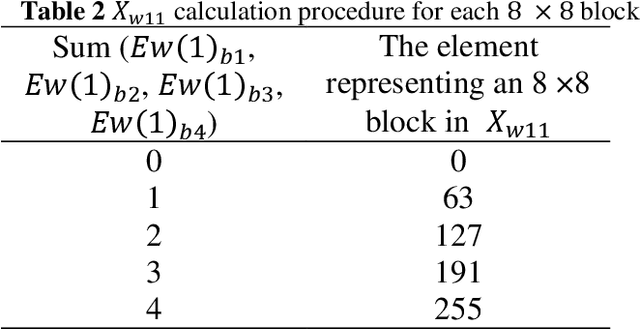
Content-independent watermarks and block-wise independency can be considered as vulnerabilities in semi-fragile watermarking methods. In this paper to achieve the objectives of semi-fragile watermarking techniques, a method is proposed to not have the mentioned shortcomings. In the proposed method, the watermark is generated by relying on image content and a key. Furthermore, the embedding scheme causes the watermarked blocks to become dependent on each other, using a key. In the embedding phase, the image is partitioned into non-overlapping blocks. In order to detect and separate the different types of attacks more precisely, the proposed method embeds three copies of each watermark bit into LWT coefficients of each 4x4 block. In the authentication phase, by voting between the extracted bits the error maps are created; these maps indicate image authenticity and reveal the modified regions. Also, in order to automate the authentication, the images are classified into four categories using seven features. Classification accuracy in the experiments is 97.97 percent. It is noted that our experiments demonstrate that the proposed method is robust against JPEG compression and is competitive with a state-of-the-art semi-fragile watermarking method, in terms of robustness and semi-fragility.