 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Few-shot Unsupervised Domain Adaptation with Image-to-class Sparse Similarity Encoding
Aug 06, 2021
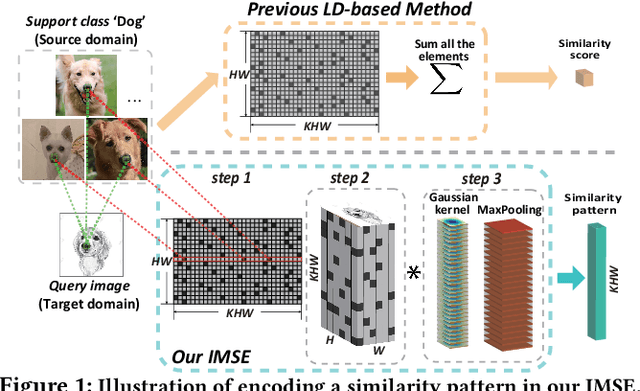

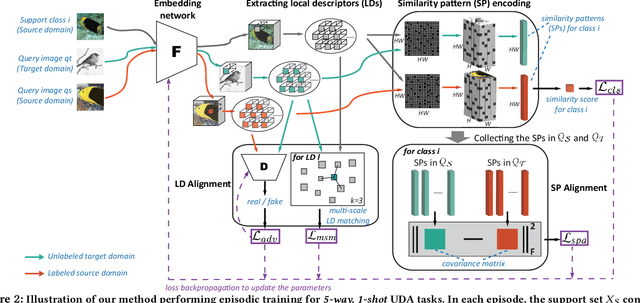
This paper investigates a valuable setting called few-shot unsupervised domain adaptation (FS-UDA), which has not been sufficiently studied in the literature. In this setting, the source domain data are labelled, but with few-shot per category, while the target domain data are unlabelled. To address the FS-UDA setting, we develop a general UDA model to solve the following two key issues: the few-shot labeled data per category and the domain adaptation between support and query sets. Our model is general in that once trained it will be able to be applied to various FS-UDA tasks from the same source and target domains. Inspired by the recent local descriptor based few-shot learning (FSL), our general UDA model is fully built upon local descriptors (LDs) for image classification and domain adaptation. By proposing a novel concept called similarity patterns (SPs), our model not only effectively considers the spatial relationship of LDs that was ignored in previous FSL methods, but also makes the learned image similarity better serve the required domain alignment. Specifically, we propose a novel IMage-to-class sparse Similarity Encoding (IMSE) method. It learns SPs to extract the local discriminative information for classification and meanwhile aligns the covariance matrix of the SPs for domain adaptation. Also, domain adversarial training and multi-scale local feature matching are performed upon LDs. Extensive experiments conducted on a multi-domain benchmark dataset DomainNet demonstrates the state-of-the-art performance of our IMSE for the novel setting of FS-UDA. In addition, for FSL, our IMSE can also show better performance than most of recent FSL methods on miniImageNet.
Benchmarking Generative Latent Variable Models for Speech
Apr 05, 2022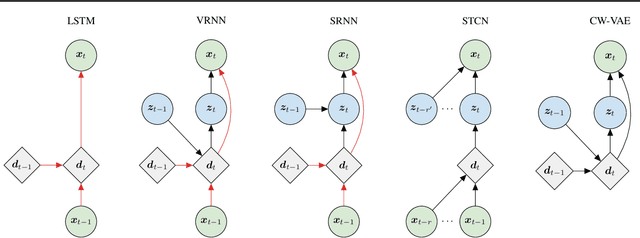
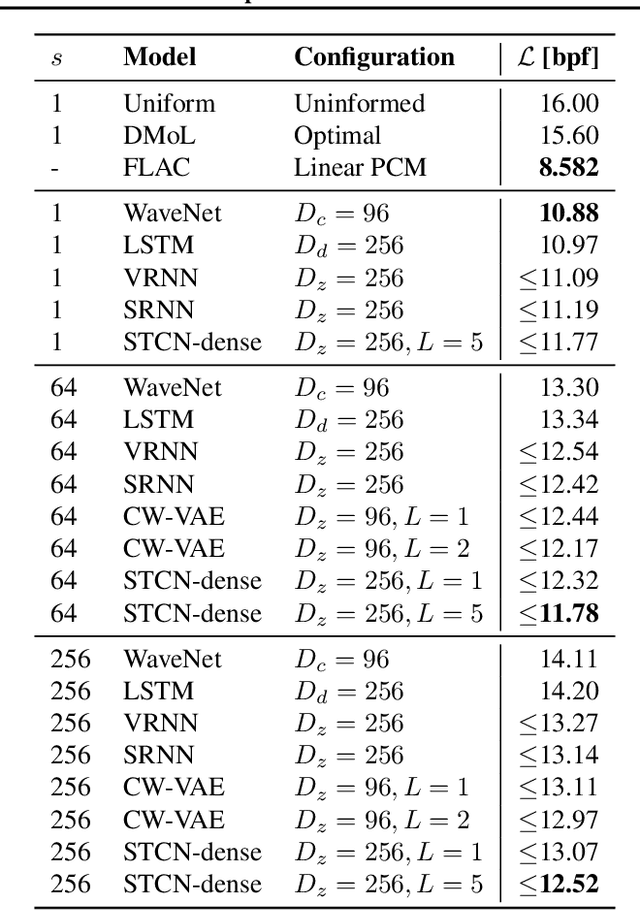
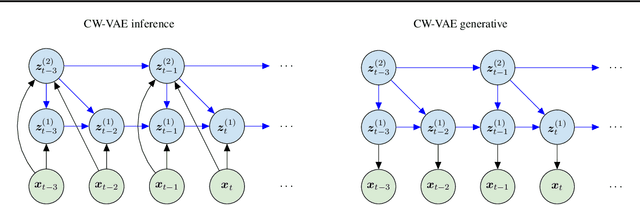
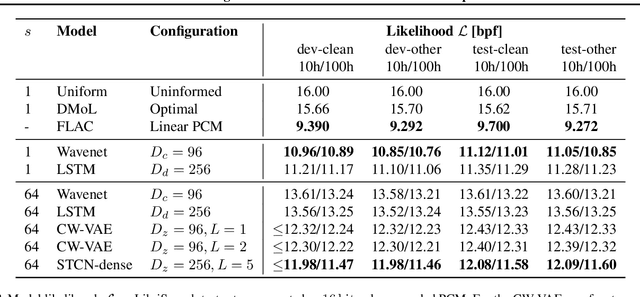
Stochastic latent variable models (LVMs) achieve state-of-the-art performance on natural image generation but are still inferior to deterministic models on speech. In this paper, we develop a speech benchmark of popular temporal LVMs and compare them against state-of-the-art deterministic models. We report the likelihood, which is a much used metric in the image domain, but rarely, or incomparably, reported for speech models. To assess the quality of the learned representations, we also compare their usefulness for phoneme recognition. Finally, we adapt the Clockwork VAE, a state-of-the-art temporal LVM for video generation, to the speech domain. Despite being autoregressive only in latent space, we find that the Clockwork VAE can outperform previous LVMs and reduce the gap to deterministic models by using a hierarchy of latent variables.
Restoration of Video Frames from a Single Blurred Image with Motion Understanding
Apr 19, 2021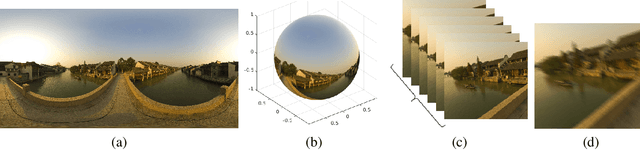
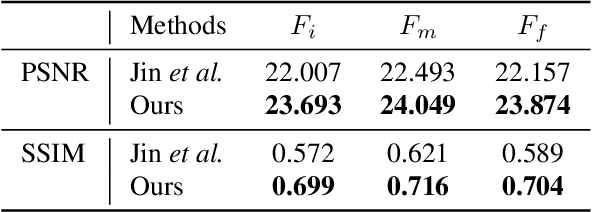
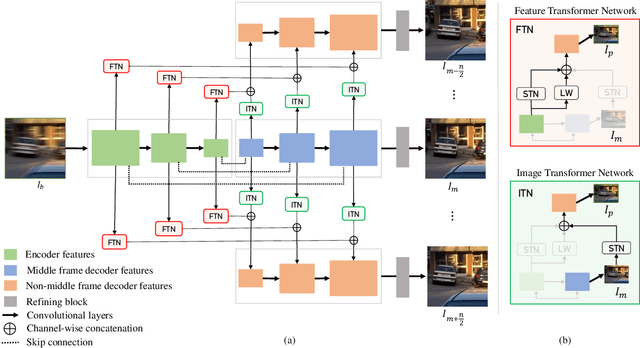
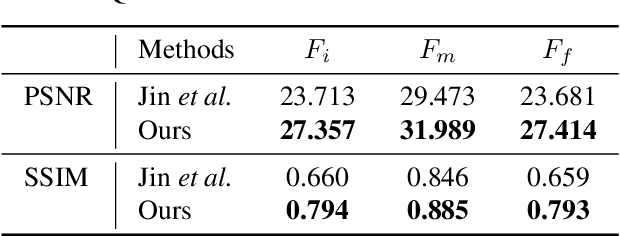
We propose a novel framework to generate clean video frames from a single motion-blurred image. While a broad range of literature focuses on recovering a single image from a blurred image, in this work, we tackle a more challenging task i.e. video restoration from a blurred image. We formulate video restoration from a single blurred image as an inverse problem by setting clean image sequence and their respective motion as latent factors, and the blurred image as an observation. Our framework is based on an encoder-decoder structure with spatial transformer network modules to restore a video sequence and its underlying motion in an end-to-end manner. We design a loss function and regularizers with complementary properties to stabilize the training and analyze variant models of the proposed network. The effectiveness and transferability of our network are highlighted through a large set of experiments on two different types of datasets: camera rotation blurs generated from panorama scenes and dynamic motion blurs in high speed videos.
A Frequency Domain Constraint for Synthetic X-ray Image Super Resolution
May 14, 2021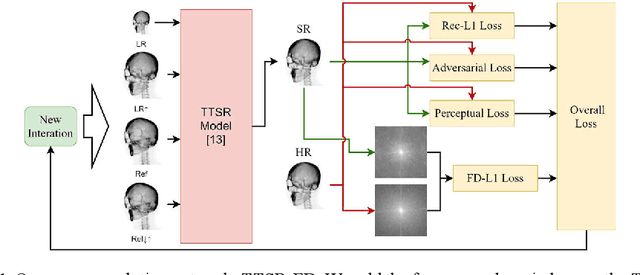

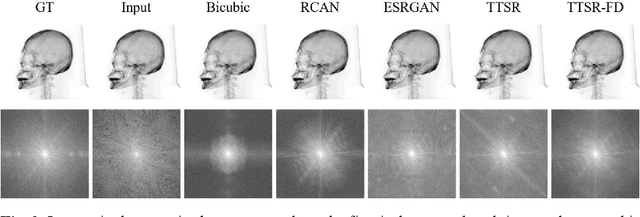

Synthetic X-ray images can be helpful for image guiding systems and VR simulations. However, it is difficult to produce high-quality arbitrary view synthetic X-ray images in real-time due to limited CT scanning resolution, high computation resource demand or algorithm complexity. Our goal is to generate high-resolution synthetic X-ray images in real-time by upsampling low-resolution im-ages. Reference-based Super Resolution (RefSR) has been well studied in recent years and has been proven to be more powerful than traditional Single Image Su-per-Resolution (SISR). RefSR can produce fine details by utilizing the reference image but it still inevitably generates some artifacts and noise. In this paper, we propose texture transformer super-resolution with frequency domain (TTSR-FD). We introduce frequency domain loss as a constraint to further improve the quality of the RefSR results with fine details and without obvious artifacts. This makes a real-time synthetic X-ray image-guided procedure VR simulation system possible. To the best of our knowledge, this is the first paper utilizing the frequency domain as part of the loss functions in the field of super-resolution. We evaluated TTSR-FD on our synthetic X-ray image dataset and achieved state-of-the-art results.
Deep learning facilitates fully automated brain image registration of optoacoustic tomography and magnetic resonance imaging
Sep 04, 2021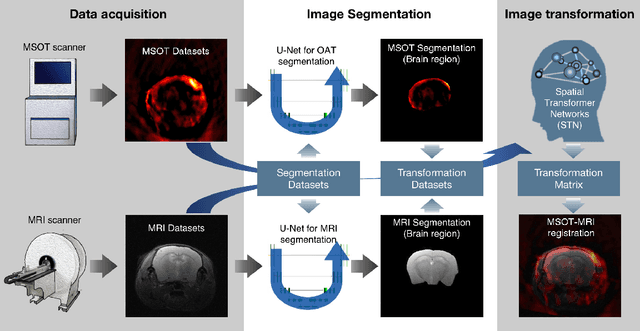
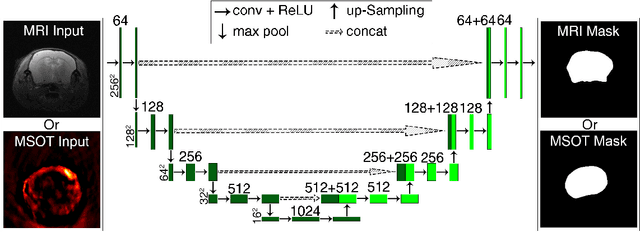
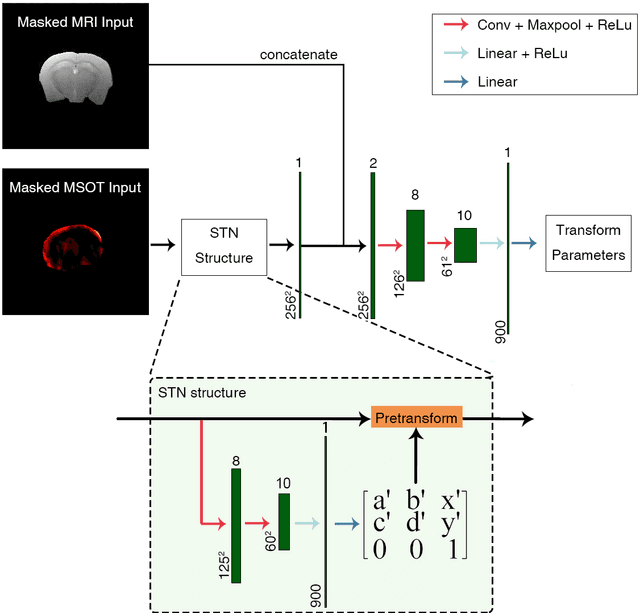
Multi-spectral optoacoustic tomography (MSOT) is an emerging optical imaging method providing multiplex molecular and functional information from the rodent brain. It can be greatly augmented by magnetic resonance imaging (MRI) that offers excellent soft-tissue contrast and high-resolution brain anatomy. Nevertheless, registration of multi-modal images remains challenging, chiefly due to the entirely different image contrast rendered by these modalities. Previously reported registration algorithms mostly relied on manual user-dependent brain segmentation, which compromised data interpretation and accurate quantification. Here we propose a fully automated registration method for MSOT-MRI multimodal imaging empowered by deep learning. The automated workflow includes neural network-based image segmentation to generate suitable masks, which are subsequently registered using an additional neural network. Performance of the algorithm is showcased with datasets acquired by cross-sectional MSOT and high-field MRI preclinical scanners. The automated registration method is further validated with manual and half-automated registration, demonstrating its robustness and accuracy.
Accurate Scoliosis Vertebral Landmark Localization on X-ray Images via Shape-constrained Multi-stage Cascaded CNNs
Jun 05, 2022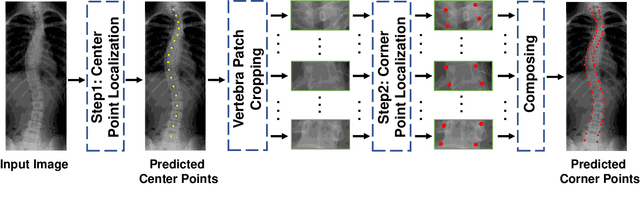
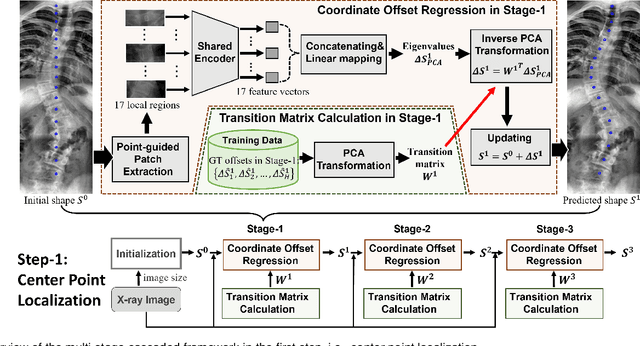
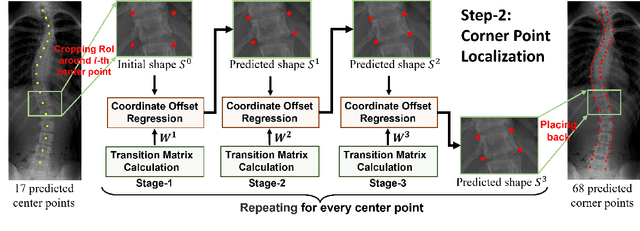
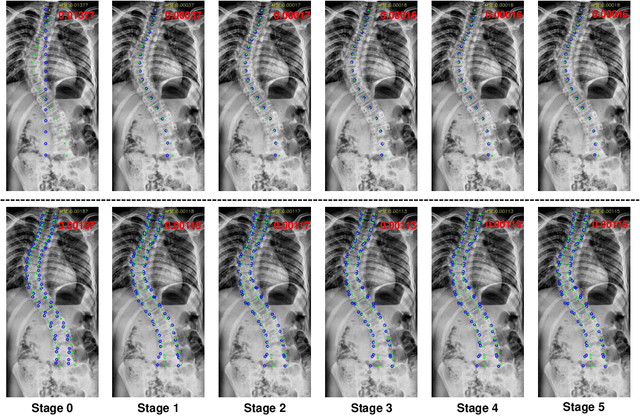
Vertebral landmark localization is a crucial step for variant spine-related clinical applications, which requires detecting the corner points of 17 vertebrae. However, the neighbor landmarks often disturb each other for the homogeneous appearance of vertebrae, which makes vertebral landmark localization extremely difficult. In this paper, we propose multi-stage cascaded convolutional neural networks (CNNs) to split the single task into two sequential steps, i.e., center point localization to roughly locate 17 center points of vertebrae, and corner point localization to find 4 corner points for each vertebra without distracted by others. Landmarks in each step are located gradually from a set of initialized points by regressing offsets via cascaded CNNs. Principal Component Analysis (PCA) is employed to preserve a shape constraint in offset regression to resist the mutual attraction of vertebrae. We evaluate our method on the AASCE dataset that consists of 609 tight spinal anterior-posterior X-ray images and each image contains 17 vertebrae composed of the thoracic and lumbar spine for spinal shape characterization. Experimental results demonstrate our superior performance of vertebral landmark localization over other state-of-the-arts with the relative error decreasing from 3.2e-3 to 7.2e-4.
A Two-stage Deep Network for High Dynamic Range Image Reconstruction
Apr 19, 2021
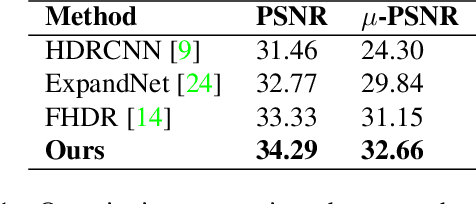


Mapping a single exposure low dynamic range (LDR) image into a high dynamic range (HDR) is considered among the most strenuous image to image translation tasks due to exposure-related missing information. This study tackles the challenges of single-shot LDR to HDR mapping by proposing a novel two-stage deep network. Notably, our proposed method aims to reconstruct an HDR image without knowing hardware information, including camera response function (CRF) and exposure settings. Therefore, we aim to perform image enhancement task like denoising, exposure correction, etc., in the first stage. Additionally, the second stage of our deep network learns tone mapping and bit-expansion from a convex set of data samples. The qualitative and quantitative comparisons demonstrate that the proposed method can outperform the existing LDR to HDR works with a marginal difference. Apart from that, we collected an LDR image dataset incorporating different camera systems. The evaluation with our collected real-world LDR images illustrates that the proposed method can reconstruct plausible HDR images without presenting any visual artefacts. Code available: https://github. com/sharif-apu/twostageHDR_NTIRE21.
A Systematic Benchmarking Analysis of Transfer Learning for Medical Image Analysis
Aug 12, 2021
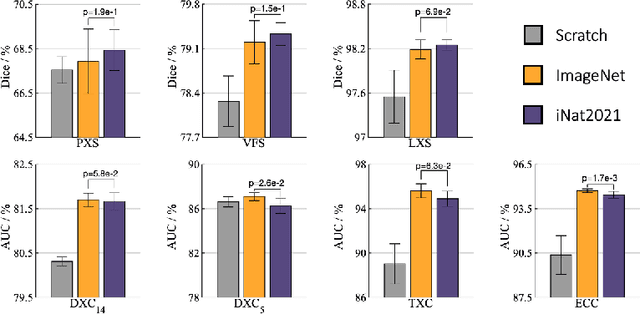
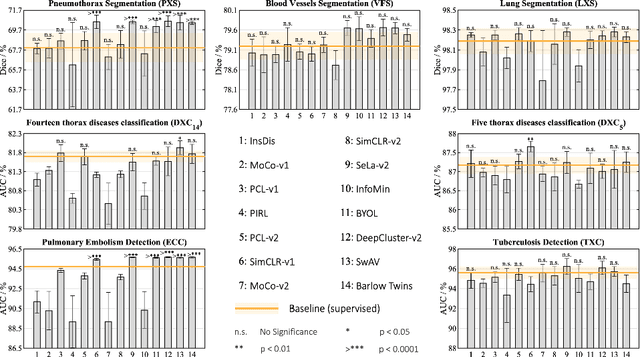
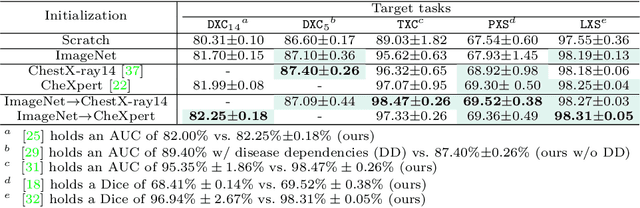
Transfer learning from supervised ImageNet models has been frequently used in medical image analysis. Yet, no large-scale evaluation has been conducted to benchmark the efficacy of newly-developed pre-training techniques for medical image analysis, leaving several important questions unanswered. As the first step in this direction, we conduct a systematic study on the transferability of models pre-trained on iNat2021, the most recent large-scale fine-grained dataset, and 14 top self-supervised ImageNet models on 7 diverse medical tasks in comparison with the supervised ImageNet model. Furthermore, we present a practical approach to bridge the domain gap between natural and medical images by continually (pre-)training supervised ImageNet models on medical images. Our comprehensive evaluation yields new insights: (1) pre-trained models on fine-grained data yield distinctive local representations that are more suitable for medical segmentation tasks, (2) self-supervised ImageNet models learn holistic features more effectively than supervised ImageNet models, and (3) continual pre-training can bridge the domain gap between natural and medical images. We hope that this large-scale open evaluation of transfer learning can direct the future research of deep learning for medical imaging. As open science, all codes and pre-trained models are available on our GitHub page https://github.com/JLiangLab/BenchmarkTransferLearning.
Condensing Graphs via One-Step Gradient Matching
Jun 15, 2022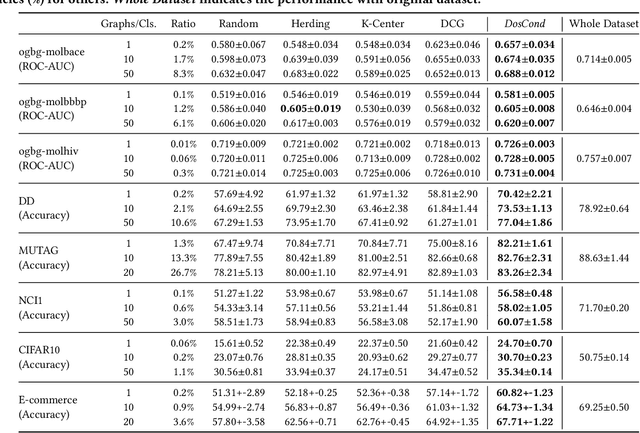
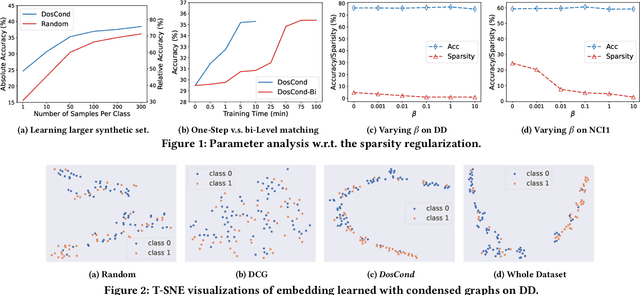
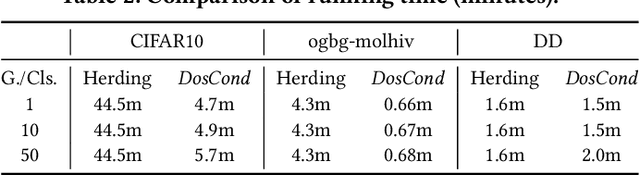
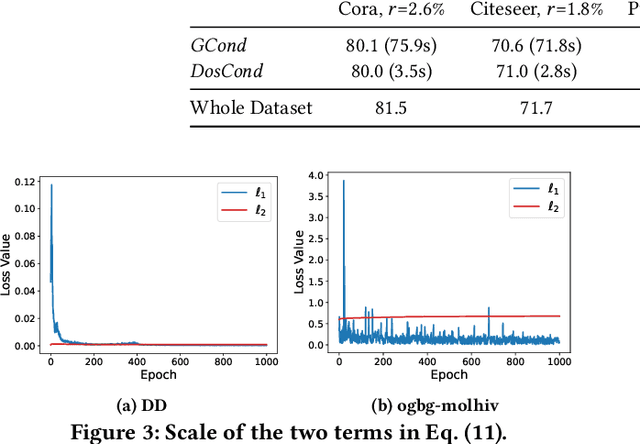
As training deep learning models on large dataset takes a lot of time and resources, it is desired to construct a small synthetic dataset with which we can train deep learning models sufficiently. There are recent works that have explored solutions on condensing image datasets through complex bi-level optimization. For instance, dataset condensation (DC) matches network gradients w.r.t. large-real data and small-synthetic data, where the network weights are optimized for multiple steps at each outer iteration. However, existing approaches have their inherent limitations: (1) they are not directly applicable to graphs where the data is discrete; and (2) the condensation process is computationally expensive due to the involved nested optimization. To bridge the gap, we investigate efficient dataset condensation tailored for graph datasets where we model the discrete graph structure as a probabilistic model. We further propose a one-step gradient matching scheme, which performs gradient matching for only one single step without training the network weights. Our theoretical analysis shows this strategy can generate synthetic graphs that lead to lower classification loss on real graphs. Extensive experiments on various graph datasets demonstrate the effectiveness and efficiency of the proposed method. In particular, we are able to reduce the dataset size by 90% while approximating up to 98% of the original performance and our method is significantly faster than multi-step gradient matching (e.g. 15x in CIFAR10 for synthesizing 500 graphs).
Diverse facial inpainting guided by exemplars
Feb 15, 2022
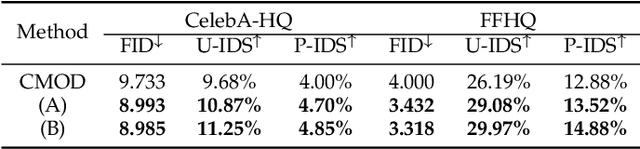
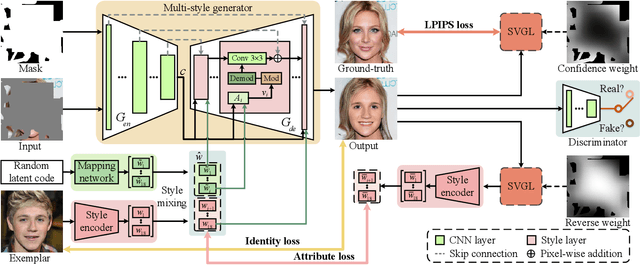
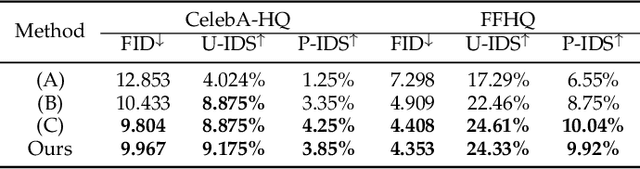
Facial image inpainting is a task of filling visually realistic and semantically meaningful contents for missing or masked pixels in a face image. Although existing methods have made significant progress in achieving high visual quality, the controllable diversity of facial image inpainting remains an open problem in this field. This paper introduces EXE-GAN, a novel diverse and interactive facial inpainting framework, which can not only preserve the high-quality visual effect of the whole image but also complete the face image with exemplar-like facial attributes. The proposed facial inpainting is achieved based on generative adversarial networks by leveraging the global style of input image, the stochastic style, and the exemplar style of exemplar image. A novel attribute similarity metric is introduced to encourage networks to learn the style of facial attributes from the exemplar in a self-supervised way. To guarantee the natural transition across the boundary of inpainted regions, a novel spatial variant gradient backpropagation technique is designed to adjust the loss gradients based on the spatial location. A variety of experimental results and comparisons on public CelebA-HQ and FFHQ datasets are presented to demonstrate the superiority of the proposed method in terms of both the quality and diversity in facial inpainting.