 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
INDIGO: Intrinsic Multimodality for Domain Generalization
Jun 13, 2022
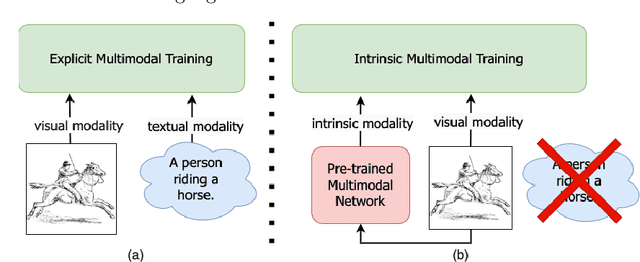
For models to generalize under unseen domains (a.k.a domain generalization), it is crucial to learn feature representations that are domain-agnostic and capture the underlying semantics that makes up an object category. Recent advances towards weakly supervised vision-language models that learn holistic representations from cheap weakly supervised noisy text annotations have shown their ability on semantic understanding by capturing object characteristics that generalize under different domains. However, when multiple source domains are involved, the cost of curating textual annotations for every image in the dataset can blow up several times, depending on their number. This makes the process tedious and infeasible, hindering us from directly using these supervised vision-language approaches to achieve the best generalization on an unseen domain. Motivated from this, we study how multimodal information from existing pre-trained multimodal networks can be leveraged in an "intrinsic" way to make systems generalize under unseen domains. To this end, we propose IntriNsic multimodality for DomaIn GeneralizatiOn (INDIGO), a simple and elegant way of leveraging the intrinsic modality present in these pre-trained multimodal networks along with the visual modality to enhance generalization to unseen domains at test-time. We experiment on several Domain Generalization settings (ClosedDG, OpenDG, and Limited sources) and show state-of-the-art generalization performance on unseen domains. Further, we provide a thorough analysis to develop a holistic understanding of INDIGO.
FL-MISR: Fast Large-Scale Multi-Image Super-Resolution for Computed Tomography Based on Multi-GPU Acceleration
Aug 09, 2021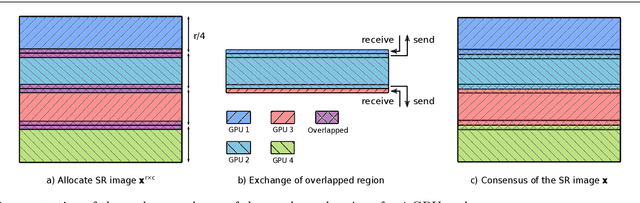

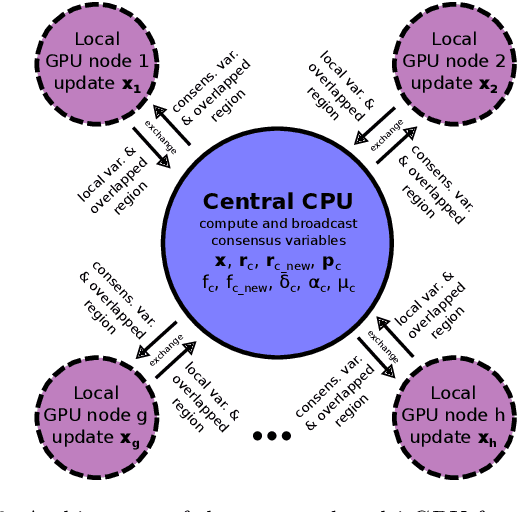

Multi-image super-resolution (MISR) usually outperforms single-image super-resolution (SISR) under a proper inter-image alignment by explicitly exploiting the inter-image correlation. However, the large computational demand encumbers the deployment of MISR methods in practice. In this work, we propose a distributed optimization framework based on data parallelism for fast large-scale MISR which supports multi- GPU acceleration, named FL-MISR. Inter-GPU communication for the exchange of local variables and over-lapped regions is enabled to impose a consensus convergence of the distributed task allocated to each GPU node. We have seamlessly integrated FL-MISR into the computed tomography (CT) imaging system by super-resolving multiple projections of the same view acquired by subpixel detector shift. The SR reconstruction is performed on the fly during the CT acquisition such that no additional computation time is introduced. We evaluated FL-MISR quantitatively and qualitatively on multiple objects including aluminium cylindrical phantoms, QRM bar pattern phantoms, and concrete joints. Experiments show that FL-MISR can effectively improve the spatial resolution of CT systems in modulation transfer function (MTF) and visual perception. Besides, comparing to a multi-core CPU implementation, FL-MISR achieves a more than 50x speedup on an off-the-shelf 4-GPU system.
Explore Image Deblurring via Blur Kernel Space
Apr 01, 2021

This paper introduces a method to encode the blur operators of an arbitrary dataset of sharp-blur image pairs into a blur kernel space. Assuming the encoded kernel space is close enough to in-the-wild blur operators, we propose an alternating optimization algorithm for blind image deblurring. It approximates an unseen blur operator by a kernel in the encoded space and searches for the corresponding sharp image. Unlike recent deep-learning-based methods, our system can handle unseen blur kernel, while avoiding using complicated handcrafted priors on the blur operator often found in classical methods. Due to the method's design, the encoded kernel space is fully differentiable, thus can be easily adopted in deep neural network models. Moreover, our method can be used for blur synthesis by transferring existing blur operators from a given dataset into a new domain. Finally, we provide experimental results to confirm the effectiveness of the proposed method.
Toward Interactive Modulation for Photo-Realistic Image Restoration
May 07, 2021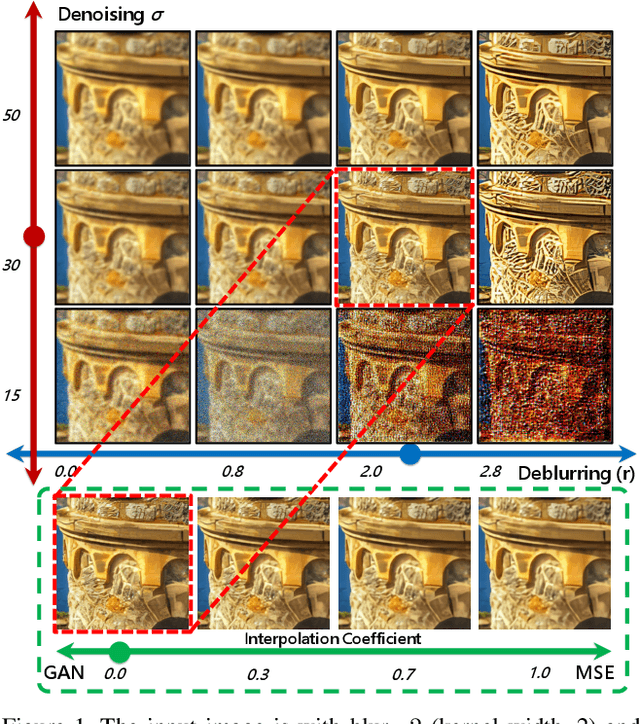
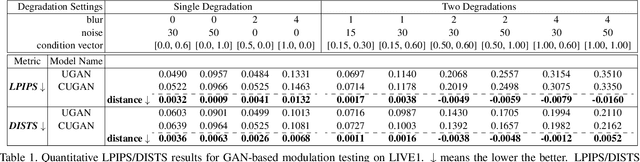

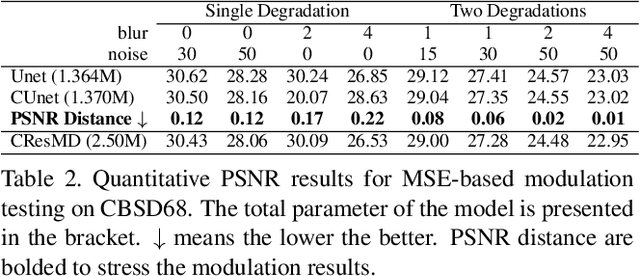
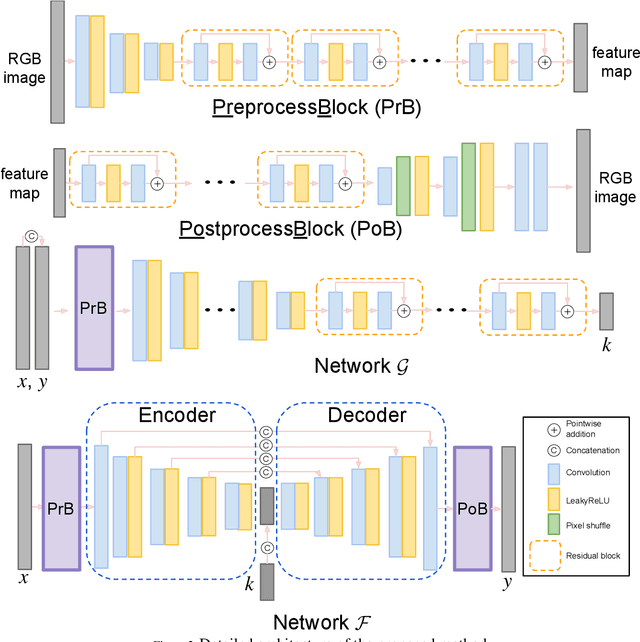
Modulating image restoration level aims to generate a restored image by altering a factor that represents the restoration strength. Previous works mainly focused on optimizing the mean squared reconstruction error, which brings high reconstruction accuracy but lacks finer texture details. This paper presents a Controllable Unet Generative Adversarial Network (CUGAN) to generate high-frequency textures in the modulation tasks. CUGAN consists of two modules -- base networks and condition networks. The base networks comprise a generator and a discriminator. In the generator, we realize the interactive control of restoration levels by tuning the weights of different features from different scales in the Unet architecture. Moreover, we adaptively modulate the intermediate features in the discriminator according to the severity of degradations. The condition networks accept the condition vector (encoded degradation information) as input, then generate modulation parameters for both the generator and the discriminator. During testing, users can control the output effects by tweaking the condition vector. We also provide a smooth transition between GAN and MSE effects by a simple transition method. Extensive experiments demonstrate that the proposed CUGAN achieves excellent performance on image restoration modulation tasks.
Task Fingerprinting for Meta Learning in Biomedical Image Analysis
Jul 08, 2021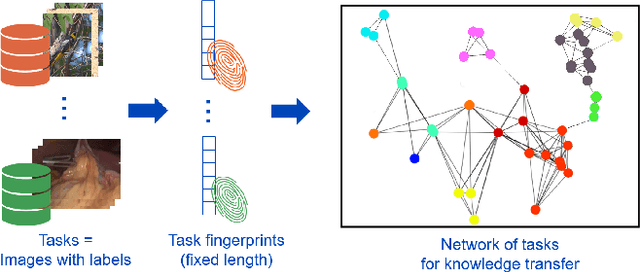
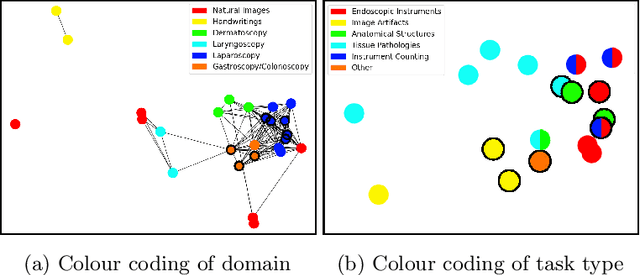
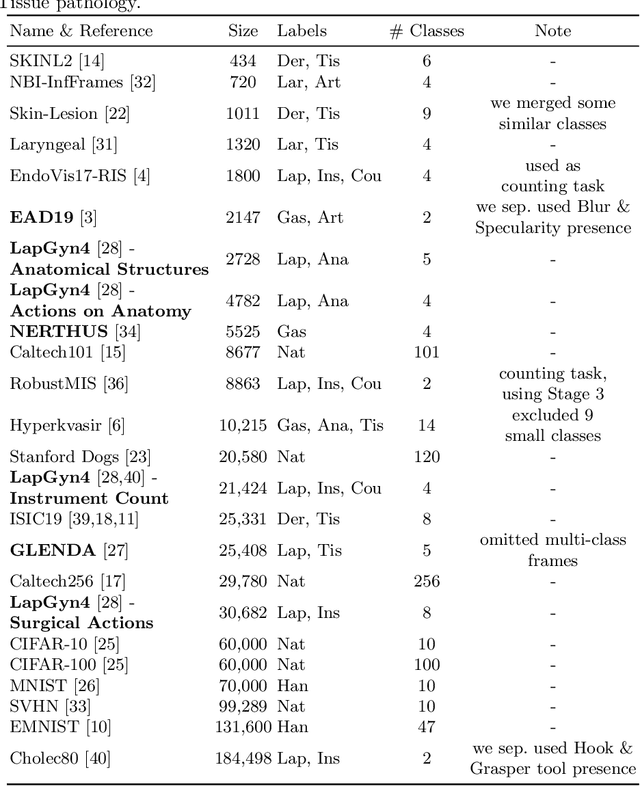
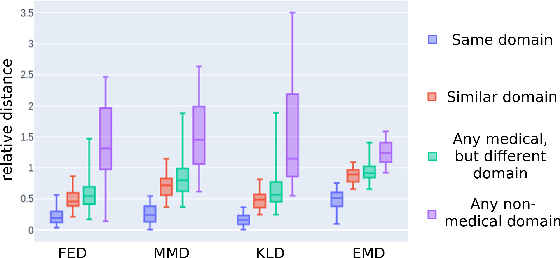
Shortage of annotated data is one of the greatest bottlenecks in biomedical image analysis. Meta learning studies how learning systems can increase in efficiency through experience and could thus evolve as an important concept to overcome data sparsity. However, the core capability of meta learning-based approaches is the identification of similar previous tasks given a new task - a challenge largely unexplored in the biomedical imaging domain. In this paper, we address the problem of quantifying task similarity with a concept that we refer to as task fingerprinting. The concept involves converting a given task, represented by imaging data and corresponding labels, to a fixed-length vector representation. In fingerprint space, different tasks can be directly compared irrespective of their data set sizes, types of labels or specific resolutions. An initial feasibility study in the field of surgical data science (SDS) with 26 classification tasks from various medical and non-medical domains suggests that task fingerprinting could be leveraged for both (1) selecting appropriate data sets for pretraining and (2) selecting appropriate architectures for a new task. Task fingerprinting could thus become an important tool for meta learning in SDS and other fields of biomedical image analysis.
Convolutional Dictionary Learning by End-To-End Training of Iterative Neural Networks
Jun 09, 2022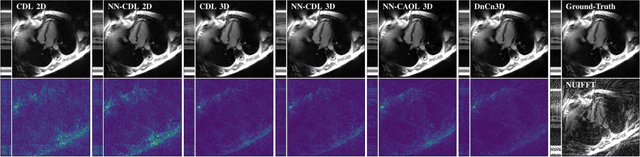
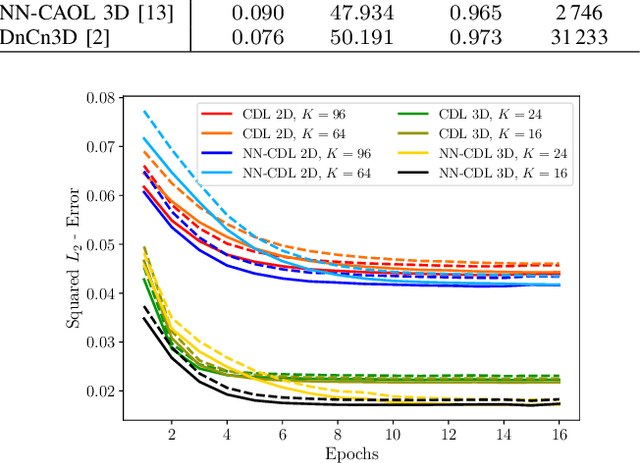

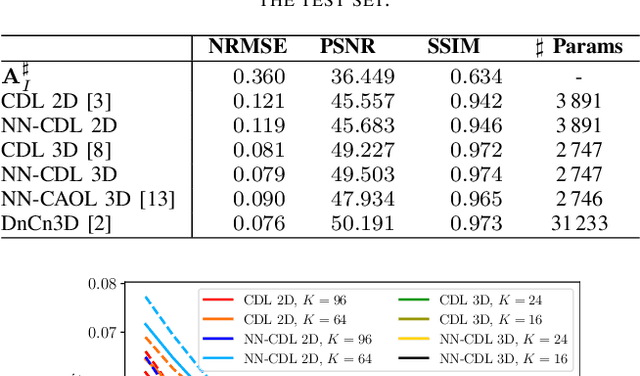
Sparsity-based methods have a long history in the field of signal processing and have been successfully applied to various image reconstruction problems. The involved sparsifying transformations or dictionaries are typically either pre-trained using a model which reflects the assumed properties of the signals or adaptively learned during the reconstruction - yielding so-called blind Compressed Sensing approaches. However, by doing so, the transforms are never explicitly trained in conjunction with the physical model which generates the signals. In addition, properly choosing the involved regularization parameters remains a challenging task. Another recently emerged training-paradigm for regularization methods is to use iterative neural networks (INNs) - also known as unrolled networks - which contain the physical model. In this work, we construct an INN which can be used as a supervised and physics-informed online convolutional dictionary learning algorithm. We evaluated the proposed approach by applying it to a realistic large-scale dynamic MR reconstruction problem and compared it to several other recently published works. We show that the proposed INN improves over two conventional model-agnostic training methods and yields competitive results also compared to a deep INN. Further, it does not require to choose the regularization parameters and - in contrast to deep INNs - each network component is entirely interpretable.
Brain Tumor Detection and Classification Using a New Evolutionary Convolutional Neural Network
Apr 26, 2022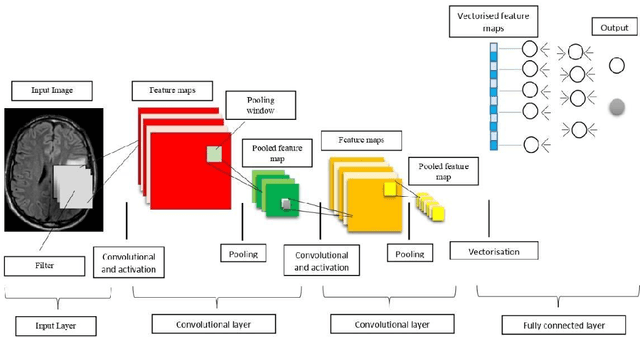
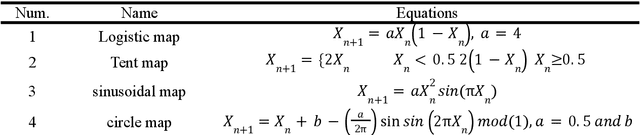

A definitive diagnosis of a brain tumour is essential for enhancing treatment success and patient survival. However, it is difficult to manually evaluate multiple magnetic resonance imaging (MRI) images generated in a clinic. Therefore, more precise computer-based tumour detection methods are required. In recent years, many efforts have investigated classical machine learning methods to automate this process. Deep learning techniques have recently sparked interest as a means of diagnosing brain tumours more accurately and robustly. The goal of this study, therefore, is to employ brain MRI images to distinguish between healthy and unhealthy patients (including tumour tissues). As a result, an enhanced convolutional neural network is developed in this paper for accurate brain image classification. The enhanced convolutional neural network structure is composed of components for feature extraction and optimal classification. Nonlinear L\'evy Chaotic Moth Flame Optimizer (NLCMFO) optimizes hyperparameters for training convolutional neural network layers. Using the BRATS 2015 data set and brain image datasets from Harvard Medical School, the proposed model is assessed and compared with various optimization techniques. The optimized CNN model outperforms other models from the literature by providing 97.4% accuracy, 96.0% sensitivity, 98.6% specificity, 98.4% precision, and 96.6% F1-score, (the mean of the weighted harmonic value of CNN precision and recall).
A Survey on Deep Learning for Skin Lesion Segmentation
Jun 01, 2022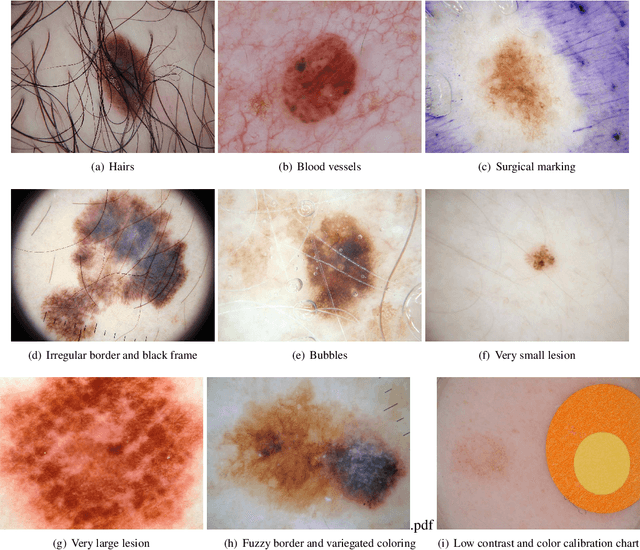
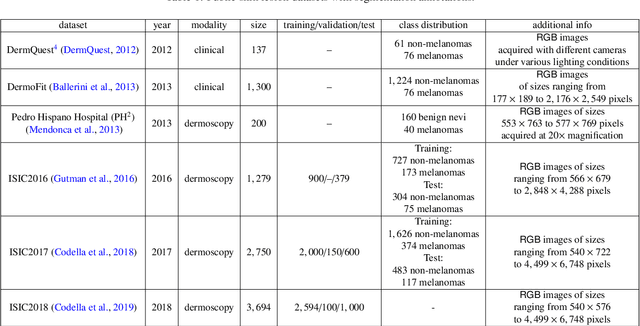
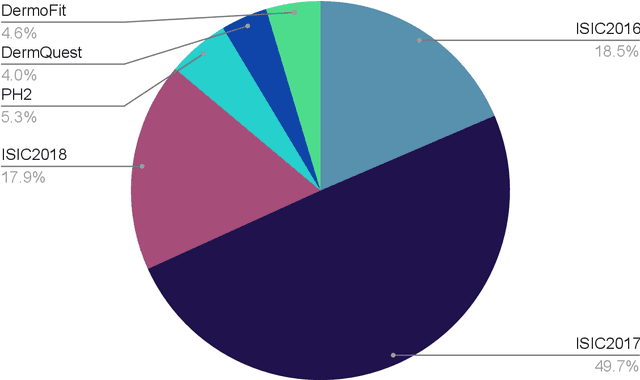
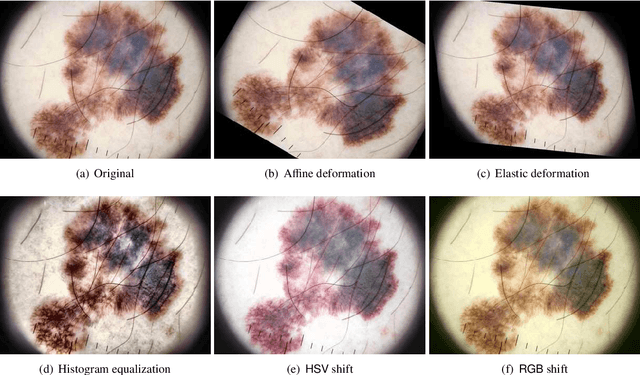
Skin cancer is a major public health problem that could benefit from computer-aided diagnosis to reduce the burden of this common disease. Skin lesion segmentation from images is an important step toward achieving this goal. However, the presence of natural and artificial artifacts (e.g., hair and air bubbles), intrinsic factors (e.g., lesion shape and contrast), and variations in image acquisition conditions make skin lesion segmentation a challenging task. Recently, various researchers have explored the applicability of deep learning models to skin lesion segmentation. In this survey, we cross-examine 134 research papers that deal with deep learning based segmentation of skin lesions. We analyze these works along several dimensions, including input data (datasets, preprocessing, and synthetic data generation), model design (architecture, modules, and losses), and evaluation aspects (data annotation requirements and segmentation performance). We discuss these dimensions both from the viewpoint of select seminal works, and from a systematic viewpoint, examining how those choices have influenced current trends, and how their limitations should be addressed. We summarize all examined works in a comprehensive table to facilitate comparisons.
Semi-Supervised Learning for Mars Imagery Classification and Segmentation
Jun 05, 2022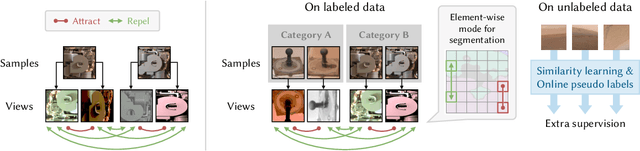
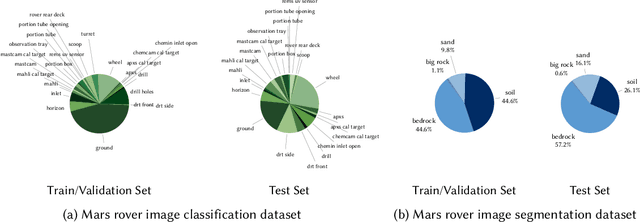
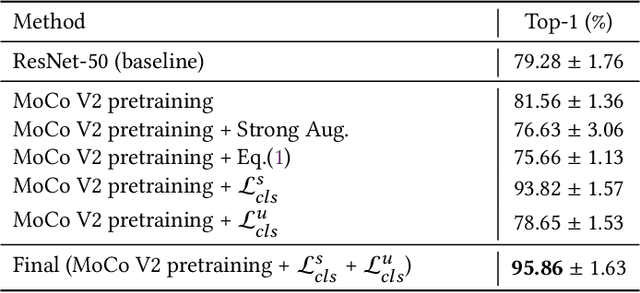
With the progress of Mars exploration, numerous Mars image data are collected and need to be analyzed. However, due to the imbalance and distortion of Martian data, the performance of existing computer vision models is unsatisfactory. In this paper, we introduce a semi-supervised framework for machine vision on Mars and try to resolve two specific tasks: classification and segmentation. Contrastive learning is a powerful representation learning technique. However, there is too much information overlap between Martian data samples, leading to a contradiction between contrastive learning and Martian data. Our key idea is to reconcile this contradiction with the help of annotations and further take advantage of unlabeled data to improve performance. For classification, we propose to ignore inner-class pairs on labeled data as well as neglect negative pairs on unlabeled data, forming supervised inter-class contrastive learning and unsupervised similarity learning. For segmentation, we extend supervised inter-class contrastive learning into an element-wise mode and use online pseudo labels for supervision on unlabeled areas. Experimental results show that our learning strategies can improve the classification and segmentation models by a large margin and outperform state-of-the-art approaches.
BI-GCN: Boundary-Aware Input-Dependent Graph Convolution Network for Biomedical Image Segmentation
Oct 31, 2021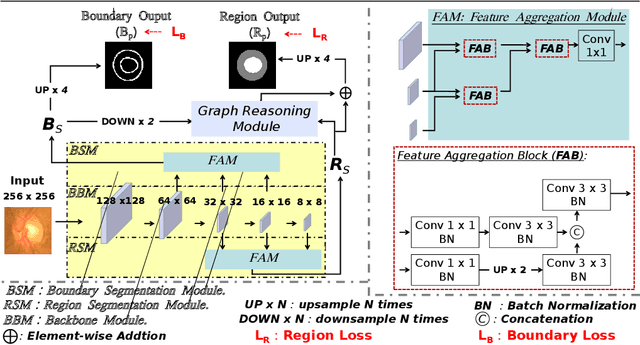



Segmentation is an essential operation of image processing. The convolution operation suffers from a limited receptive field, while global modelling is fundamental to segmentation tasks. In this paper, we apply graph convolution into the segmentation task and propose an improved \textit{Laplacian}. Different from existing methods, our \textit{Laplacian} is data-dependent, and we introduce two attention diagonal matrices to learn a better vertex relationship. In addition, it takes advantage of both region and boundary information when performing graph-based information propagation. Specifically, we model and reason about the boundary-aware region-wise correlations of different classes through learning graph representations, which is capable of manipulating long range semantic reasoning across various regions with the spatial enhancement along the object's boundary. Our model is well-suited to obtain global semantic region information while also accommodates local spatial boundary characteristics simultaneously. Experiments on two types of challenging datasets demonstrate that our method outperforms the state-of-the-art approaches on the segmentation of polyps in colonoscopy images and of the optic disc and optic cup in colour fundus images.