 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SATBench: Benchmarking the speed-accuracy tradeoff in object recognition by humans and dynamic neural networks
Jun 16, 2022

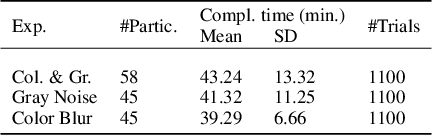
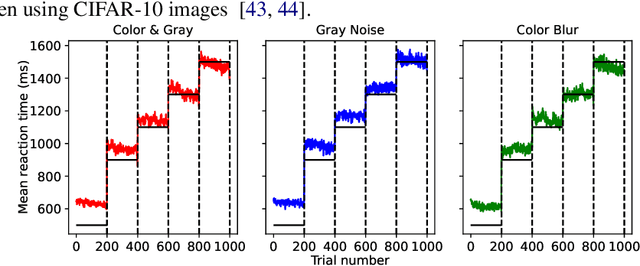
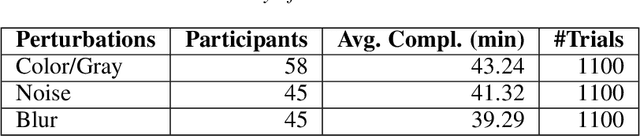
The core of everyday tasks like reading and driving is active object recognition. Attempts to model such tasks are currently stymied by the inability to incorporate time. People show a flexible tradeoff between speed and accuracy and this tradeoff is a crucial human skill. Deep neural networks have emerged as promising candidates for predicting peak human object recognition performance and neural activity. However, modeling the temporal dimension i.e., the speed-accuracy tradeoff (SAT), is essential for them to serve as useful computational models for how humans recognize objects. To this end, we here present the first large-scale (148 observers, 4 neural networks, 8 tasks) dataset of the speed-accuracy tradeoff (SAT) in recognizing ImageNet images. In each human trial, a beep, indicating the desired reaction time, sounds at a fixed delay after the image is presented, and observer's response counts only if it occurs near the time of the beep. In a series of blocks, we test many beep latencies, i.e., reaction times. We observe that human accuracy increases with reaction time and proceed to compare its characteristics with the behavior of several dynamic neural networks that are capable of inference-time adaptive computation. Using FLOPs as an analog for reaction time, we compare networks with humans on curve-fit error, category-wise correlation, and curve steepness, and conclude that cascaded dynamic neural networks are a promising model of human reaction time in object recognition tasks.
Explore Image Deblurring via Blur Kernel Space
Apr 01, 2021

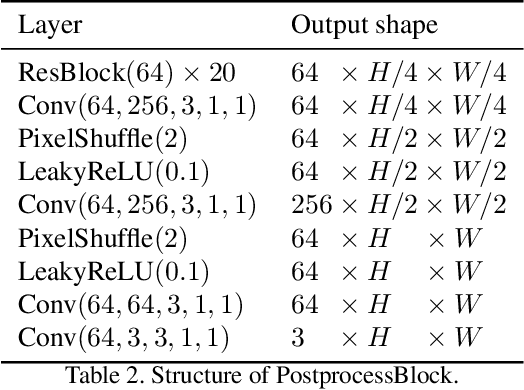
This paper introduces a method to encode the blur operators of an arbitrary dataset of sharp-blur image pairs into a blur kernel space. Assuming the encoded kernel space is close enough to in-the-wild blur operators, we propose an alternating optimization algorithm for blind image deblurring. It approximates an unseen blur operator by a kernel in the encoded space and searches for the corresponding sharp image. Unlike recent deep-learning-based methods, our system can handle unseen blur kernel, while avoiding using complicated handcrafted priors on the blur operator often found in classical methods. Due to the method's design, the encoded kernel space is fully differentiable, thus can be easily adopted in deep neural network models. Moreover, our method can be used for blur synthesis by transferring existing blur operators from a given dataset into a new domain. Finally, we provide experimental results to confirm the effectiveness of the proposed method.
Effectiveness of Delivered Information Trade Study
Feb 28, 2022
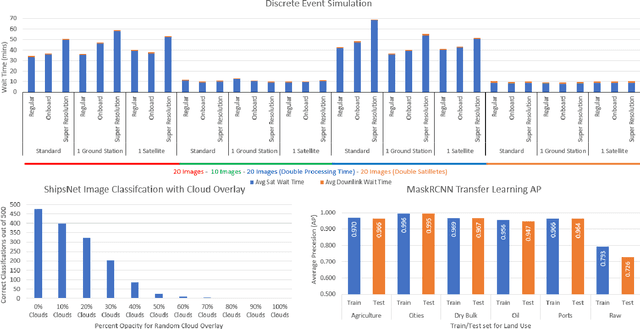

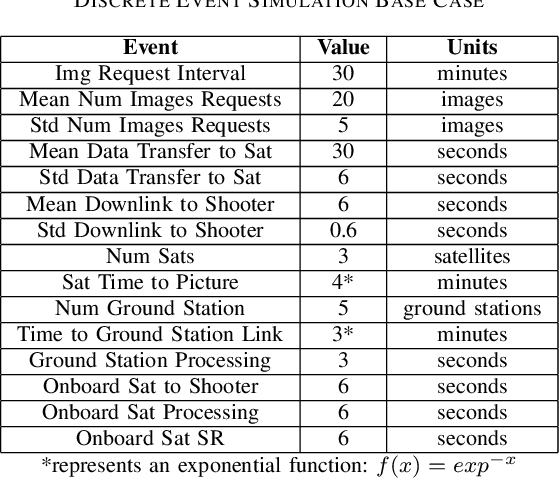
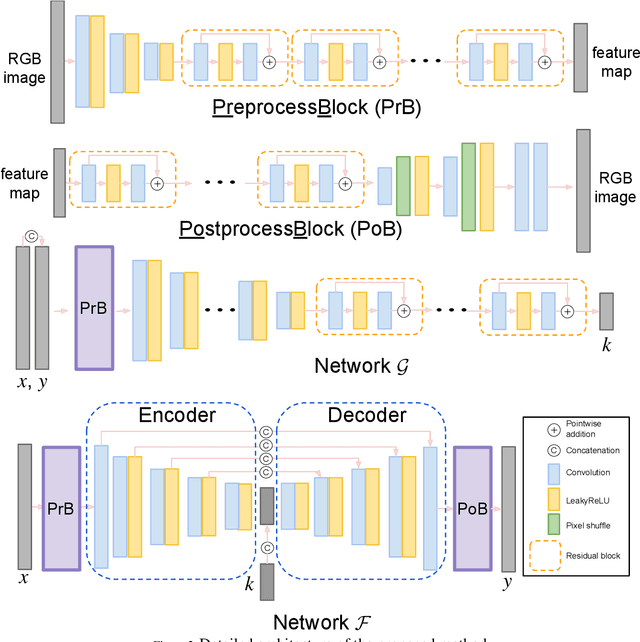
The sensor to shooter timeline is affected by two main variables: satellite positioning and asset positioning. Speeding up satellite positioning by adding more sensors or by decreasing processing time is important only if there is a prepared shooter, otherwise the main source of time is getting the shooter into position. However, the intelligence community should work towards the exploitation of sensors to the highest speed and effectiveness possible. Achieving a high effectiveness while keeping speed high is a tradeoff that must be considered in the sensor to shooter timeline. In this paper we investigate two main ideas, increasing the effectiveness of satellite imagery through image manipulation and how on-board image manipulation would affect the sensor to shooter timeline. We cover these ideas in four scenarios: Discrete Event Simulation of onboard processing versus ground station processing, quality of information with cloud cover removal, information improvement with super resolution, and data reduction with image to caption. This paper will show how image manipulation techniques such as Super Resolution, Cloud Removal, and Image to Caption will improve the quality of delivered information in addition to showing how those processes effect the sensor to shooter timeline.
FL-MISR: Fast Large-Scale Multi-Image Super-Resolution for Computed Tomography Based on Multi-GPU Acceleration
Aug 09, 2021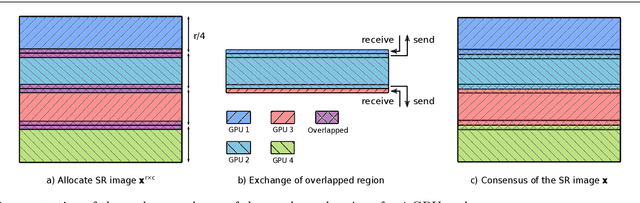

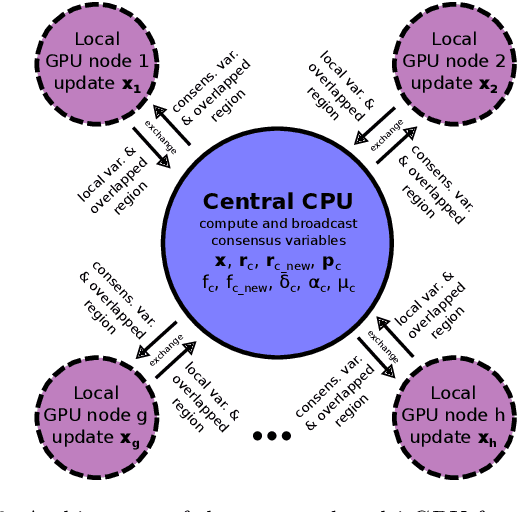

Multi-image super-resolution (MISR) usually outperforms single-image super-resolution (SISR) under a proper inter-image alignment by explicitly exploiting the inter-image correlation. However, the large computational demand encumbers the deployment of MISR methods in practice. In this work, we propose a distributed optimization framework based on data parallelism for fast large-scale MISR which supports multi- GPU acceleration, named FL-MISR. Inter-GPU communication for the exchange of local variables and over-lapped regions is enabled to impose a consensus convergence of the distributed task allocated to each GPU node. We have seamlessly integrated FL-MISR into the computed tomography (CT) imaging system by super-resolving multiple projections of the same view acquired by subpixel detector shift. The SR reconstruction is performed on the fly during the CT acquisition such that no additional computation time is introduced. We evaluated FL-MISR quantitatively and qualitatively on multiple objects including aluminium cylindrical phantoms, QRM bar pattern phantoms, and concrete joints. Experiments show that FL-MISR can effectively improve the spatial resolution of CT systems in modulation transfer function (MTF) and visual perception. Besides, comparing to a multi-core CPU implementation, FL-MISR achieves a more than 50x speedup on an off-the-shelf 4-GPU system.
VisFIS: Visual Feature Importance Supervision with Right-for-the-Right-Reason Objectives
Jun 22, 2022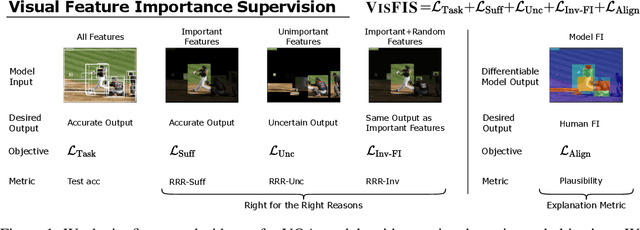
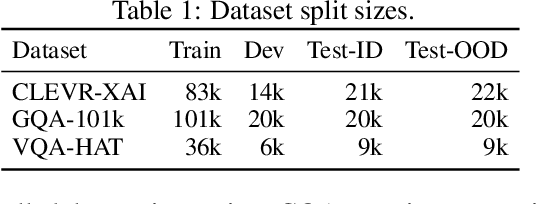
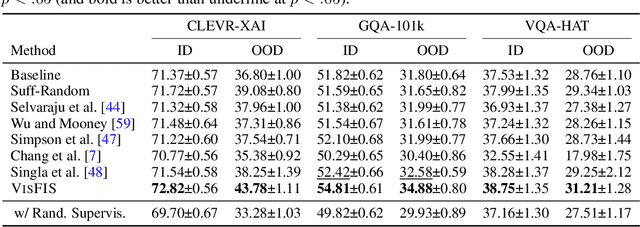
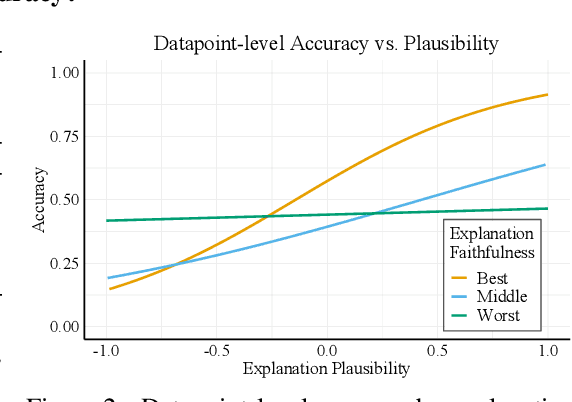
Many past works aim to improve visual reasoning in models by supervising feature importance (estimated by model explanation techniques) with human annotations such as highlights of important image regions. However, recent work has shown that performance gains from feature importance (FI) supervision for Visual Question Answering (VQA) tasks persist even with random supervision, suggesting that these methods do not meaningfully align model FI with human FI. In this paper, we show that model FI supervision can meaningfully improve VQA model accuracy as well as performance on several Right-for-the-Right-Reason (RRR) metrics by optimizing for four key model objectives: (1) accurate predictions given limited but sufficient information (Sufficiency); (2) max-entropy predictions given no important information (Uncertainty); (3) invariance of predictions to changes in unimportant features (Invariance); and (4) alignment between model FI explanations and human FI explanations (Plausibility). Our best performing method, Visual Feature Importance Supervision (VisFIS), outperforms strong baselines on benchmark VQA datasets in terms of both in-distribution and out-of-distribution accuracy. While past work suggests that the mechanism for improved accuracy is through improved explanation plausibility, we show that this relationship depends crucially on explanation faithfulness (whether explanations truly represent the model's internal reasoning). Predictions are more accurate when explanations are plausible and faithful, and not when they are plausible but not faithful. Lastly, we show that, surprisingly, RRR metrics are not predictive of out-of-distribution model accuracy when controlling for a model's in-distribution accuracy, which calls into question the value of these metrics for evaluating model reasoning. All supporting code is available at https://github.com/zfying/visfis
CRISPnet: Color Rendition ISP Net
Mar 22, 2022
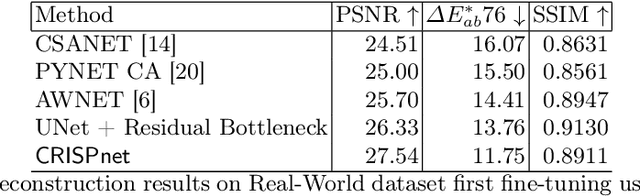
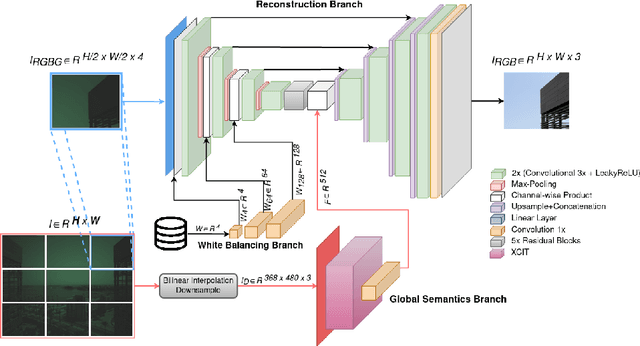
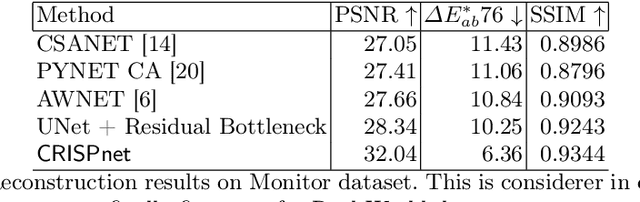
Image signal processors (ISPs) are historically grown legacy software systems for reconstructing color images from noisy raw sensor measurements. They are usually composited of many heuristic blocks for denoising, demosaicking, and color restoration. Color reproduction in this context is of particular importance, since the raw colors are often severely distorted, and each smart phone manufacturer has developed their own characteristic heuristics for improving the color rendition, for example of skin tones and other visually important colors. In recent years there has been strong interest in replacing the historically grown ISP systems with deep learned pipelines. Much progress has been made in approximating legacy ISPs with such learned models. However, so far the focus of these efforts has been on reproducing the structural features of the images, with less attention paid to color rendition. Here we present CRISPnet, the first learned ISP model to specifically target color rendition accuracy relative to a complex, legacy smart phone ISP. We achieve this by utilizing both image metadata (like a legacy ISP would), as well as by learning simple global semantics based on image classification -- similar to what a legacy ISP does to determine the scene type. We also contribute a new ISP image dataset consisting of both high dynamic range monitor data, as well as real-world data, both captured with an actual cell phone ISP pipeline under a variety of lighting conditions, exposure times, and gain settings.
Series Photo Selection via Multi-view Graph Learning
Mar 18, 2022
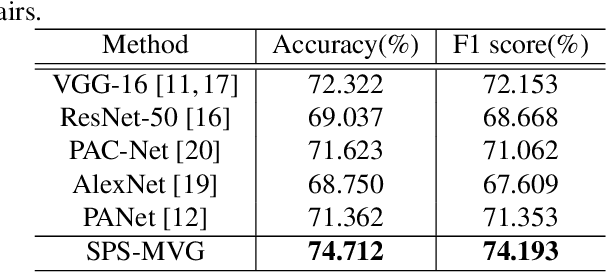
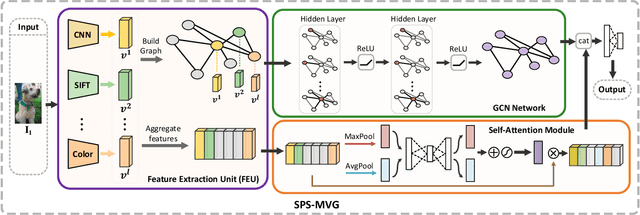
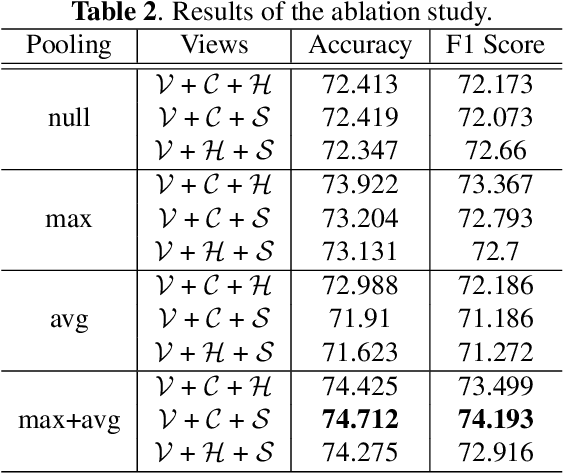
Series photo selection (SPS) is an important branch of the image aesthetics quality assessment, which focuses on finding the best one from a series of nearly identical photos. While a great progress has been observed, most of the existing SPS approaches concentrate solely on extracting features from the original image, neglecting that multiple views, e.g, saturation level, color histogram and depth of field of the image, will be of benefit to successfully reflecting the subtle aesthetic changes. Taken multi-view into consideration, we leverage a graph neural network to construct the relationships between multi-view features. Besides, multiple views are aggregated with an adaptive-weight self-attention module to verify the significance of each view. Finally, a siamese network is proposed to select the best one from a series of nearly identical photos. Experimental results demonstrate that our model accomplish the highest success rates compared with competitive methods.
SegDiscover: Visual Concept Discovery via Unsupervised Semantic Segmentation
Apr 22, 2022Visual concept discovery has long been deemed important to improve interpretability of neural networks, because a bank of semantically meaningful concepts would provide us with a starting point for building machine learning models that exhibit intelligible reasoning process. Previous methods have disadvantages: either they rely on labelled support sets that incorporate human biases for objects that are "useful," or they fail to identify multiple concepts that occur within a single image. We reframe the concept discovery task as an unsupervised semantic segmentation problem, and present SegDiscover, a novel framework that discovers semantically meaningful visual concepts from imagery datasets with complex scenes without supervision. Our method contains three important pieces: generating concept primitives from raw images, discovering concepts by clustering in the latent space of a self-supervised pretrained encoder, and concept refinement via neural network smoothing. Experimental results provide evidence that our method can discover multiple concepts within a single image and outperforms state-of-the-art unsupervised methods on complex datasets such as Cityscapes and COCO-Stuff. Our method can be further used as a neural network explanation tool by comparing results obtained by different encoders.
Boosting the Adversarial Transferability of Surrogate Model with Dark Knowledge
Jun 16, 2022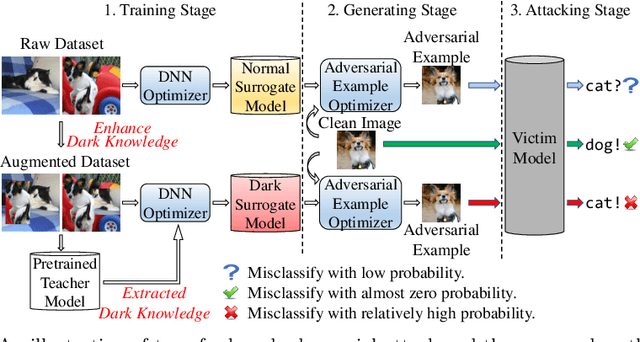
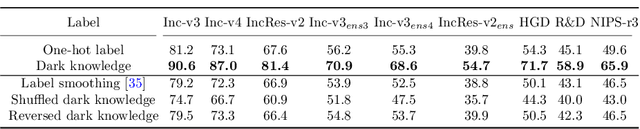
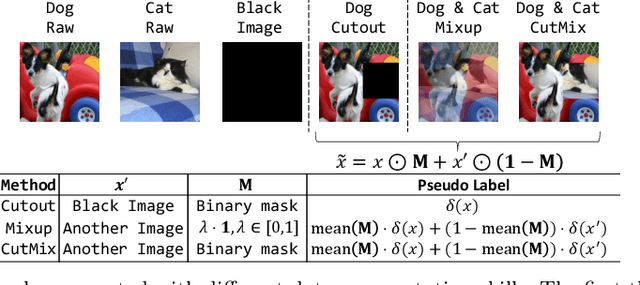
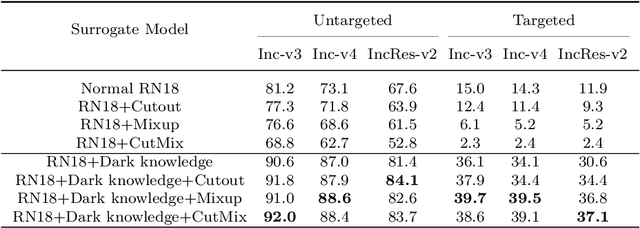
Deep neural networks (DNNs) for image classification are known to be vulnerable to adversarial examples. And, the adversarial examples have transferability, which means an adversarial example for a DNN model can fool another black-box model with a non-trivial probability. This gave birth of the transfer-based adversarial attack where the adversarial examples generated by a pretrained or known model (called surrogate model) are used to conduct black-box attack. There are some work on how to generate the adversarial examples from a given surrogate model to achieve better transferability. However, training a special surrogate model to generate adversarial examples with better transferability is relatively under-explored. In this paper, we propose a method of training a surrogate model with abundant dark knowledge to boost the adversarial transferability of the adversarial examples generated by the surrogate model. This trained surrogate model is named dark surrogate model (DSM), and the proposed method to train DSM consists of two key components: a teacher model extracting dark knowledge and providing soft labels, and the mixing augmentation skill which enhances the dark knowledge of training data. Extensive experiments have been conducted to show that the proposed method can substantially improve the adversarial transferability of surrogate model across different architectures of surrogate model and optimizers for generating adversarial examples. We also show that the proposed method can be applied to other scenarios of transfer-based attack that contain dark knowledge, like face verification.
Toward Interactive Modulation for Photo-Realistic Image Restoration
May 07, 2021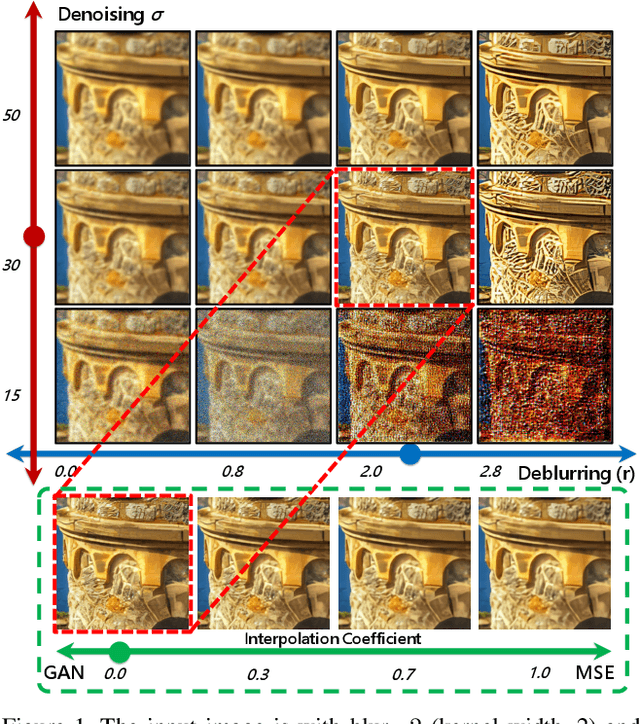
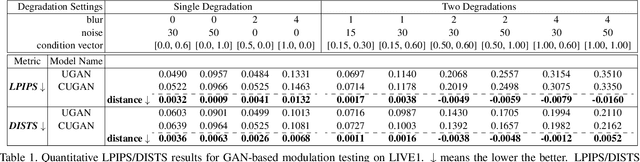

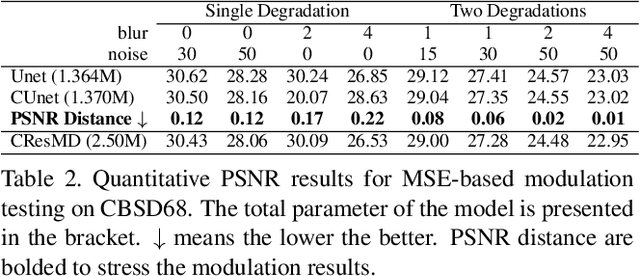
Modulating image restoration level aims to generate a restored image by altering a factor that represents the restoration strength. Previous works mainly focused on optimizing the mean squared reconstruction error, which brings high reconstruction accuracy but lacks finer texture details. This paper presents a Controllable Unet Generative Adversarial Network (CUGAN) to generate high-frequency textures in the modulation tasks. CUGAN consists of two modules -- base networks and condition networks. The base networks comprise a generator and a discriminator. In the generator, we realize the interactive control of restoration levels by tuning the weights of different features from different scales in the Unet architecture. Moreover, we adaptively modulate the intermediate features in the discriminator according to the severity of degradations. The condition networks accept the condition vector (encoded degradation information) as input, then generate modulation parameters for both the generator and the discriminator. During testing, users can control the output effects by tweaking the condition vector. We also provide a smooth transition between GAN and MSE effects by a simple transition method. Extensive experiments demonstrate that the proposed CUGAN achieves excellent performance on image restoration modulation tasks.