 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On a Neural Implementation of Brenier's Polar Factorization
Mar 05, 2024
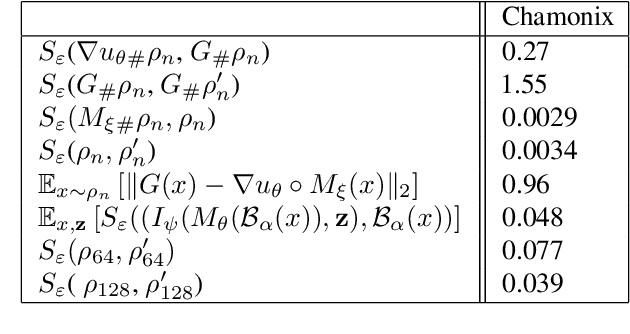
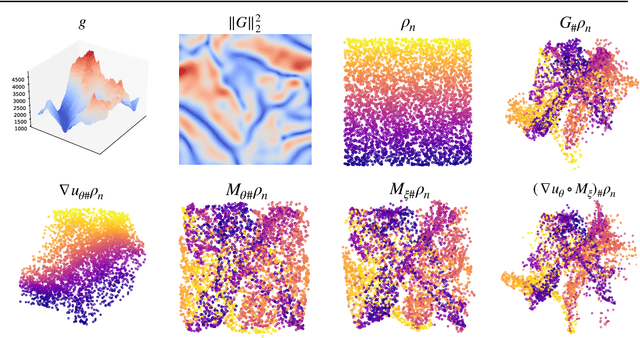

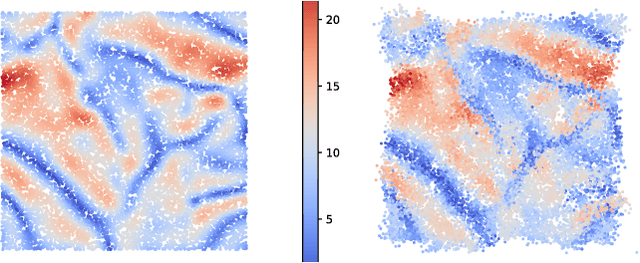
In 1991, Brenier proved a theorem that generalizes the $QR$ decomposition for square matrices -- factored as PSD $\times$ unitary -- to any vector field $F:\mathbb{R}^d\rightarrow \mathbb{R}^d$. The theorem, known as the polar factorization theorem, states that any field $F$ can be recovered as the composition of the gradient of a convex function $u$ with a measure-preserving map $M$, namely $F=\nabla u \circ M$. We propose a practical implementation of this far-reaching theoretical result, and explore possible uses within machine learning. The theorem is closely related to optimal transport (OT) theory, and we borrow from recent advances in the field of neural optimal transport to parameterize the potential $u$ as an input convex neural network. The map $M$ can be either evaluated pointwise using $u^*$, the convex conjugate of $u$, through the identity $M=\nabla u^* \circ F$, or learned as an auxiliary network. Because $M$ is, in general, not injective, we consider the additional task of estimating the ill-posed inverse map that can approximate the pre-image measure $M^{-1}$ using a stochastic generator. We illustrate possible applications of \citeauthor{Brenier1991PolarFA}'s polar factorization to non-convex optimization problems, as well as sampling of densities that are not log-concave.
FSL Model can Score Higher as It Is
Feb 28, 2024In daily life, we tend to present the front of our faces by staring squarely at a facial recognition machine, instead of facing it sideways, in order to increase the chance of being correctly recognised. Few-shot-learning (FSL) classification is challenging in itself because a model has to identify images that belong to classes previously unseen during training. Therefore, a warped and non-typical query or support image during testing can make it even more challenging for a model to predict correctly. In our work, to increase the chance of correct prediction during testing, we aim to rectify the test input of a trained FSL model by generating new samples of the tested classes through image-to-image translation. An FSL model is usually trained on classes with sufficient samples, and then tested on classes with few-shot samples. Our proposed method first captures the style or shape of the test image, and then identifies a suitable trained class sample. It then transfers the style or shape of the test image to the train-class images for generation of more test-class samples, before performing classification based on a set of generated samples instead of just one sample. Our method has potential in empowering a trained FSL model to score higher during the testing phase without any extra training nor dataset. According to our experiments, by augmenting the support set with just 1 additional generated sample, we can achieve around 2% improvement for trained FSL models on datasets consisting of either animal faces or traffic signs. By augmenting both the support set and the queries, we can achieve even more performance improvement. Our Github Repository is publicly available.
Discovering Universal Semantic Triggers for Text-to-Image Synthesis
Feb 12, 2024Recently text-to-image models have gained widespread attention in the community due to their controllable and high-quality generation ability. However, the robustness of such models and their potential ethical issues have not been fully explored. In this paper, we introduce Universal Semantic Trigger, a meaningless token sequence that can be added at any location within the input text yet can induce generated images towards a preset semantic target.To thoroughly investigate it, we propose Semantic Gradient-based Search (SGS) framework. SGS automatically discovers the potential universal semantic triggers based on the given semantic targets. Furthermore, we design evaluation metrics to comprehensively evaluate semantic shift of images caused by these triggers. And our empirical analyses reveal that the mainstream open-source text-to-image models are vulnerable to our triggers, which could pose significant ethical threats. Our work contributes to a further understanding of text-to-image synthesis and helps users to automatically auditing their models before deployment.
How to Understand "Support"? An Implicit-enhanced Causal Inference Approach for Weakly-supervised Phrase Grounding
Mar 04, 2024Weakly-supervised Phrase Grounding (WPG) is an emerging task of inferring the fine-grained phrase-region matching, while merely leveraging the coarse-grained sentence-image pairs for training. However, existing studies on WPG largely ignore the implicit phrase-region matching relations, which are crucial for evaluating the capability of models in understanding the deep multimodal semantics. To this end, this paper proposes an Implicit-Enhanced Causal Inference (IECI) approach to address the challenges of modeling the implicit relations and highlighting them beyond the explicit. Specifically, this approach leverages both the intervention and counterfactual techniques to tackle the above two challenges respectively. Furthermore, a high-quality implicit-enhanced dataset is annotated to evaluate IECI and detailed evaluations show the great advantages of IECI over the state-of-the-art baselines. Particularly, we observe an interesting finding that IECI outperforms the advanced multimodal LLMs by a large margin on this implicit-enhanced dataset, which may facilitate more research to evaluate the multimodal LLMs in this direction.
TEXterity -- Tactile Extrinsic deXterity: Simultaneous Tactile Estimation and Control for Extrinsic Dexterity
Mar 04, 2024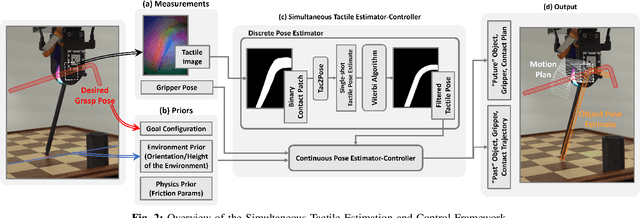
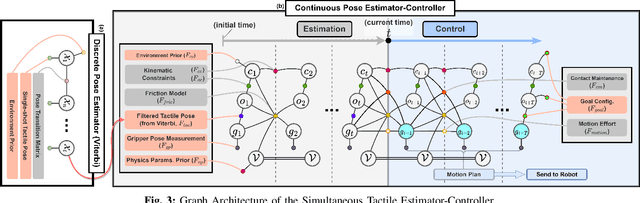
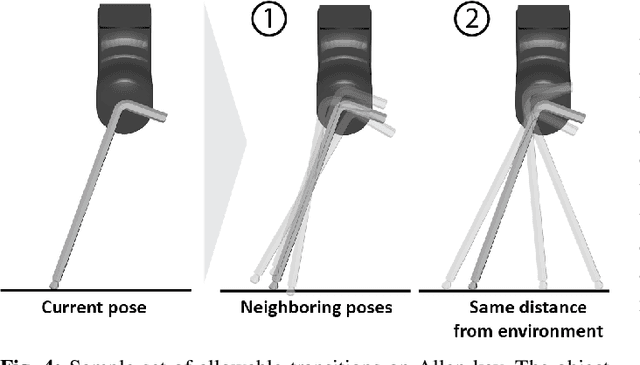
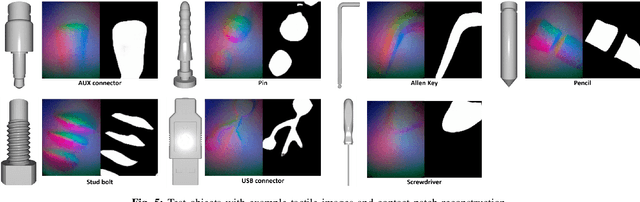
We introduce a novel approach that combines tactile estimation and control for in-hand object manipulation. By integrating measurements from robot kinematics and an image-based tactile sensor, our framework estimates and tracks object pose while simultaneously generating motion plans in a receding horizon fashion to control the pose of a grasped object. This approach consists of a discrete pose estimator that tracks the most likely sequence of object poses in a coarsely discretized grid, and a continuous pose estimator-controller to refine the pose estimate and accurately manipulate the pose of the grasped object. Our method is tested on diverse objects and configurations, achieving desired manipulation objectives and outperforming single-shot methods in estimation accuracy. The proposed approach holds potential for tasks requiring precise manipulation and limited intrinsic in-hand dexterity under visual occlusion, laying the foundation for closed-loop behavior in applications such as regrasping, insertion, and tool use. Please see https://sites.google.com/view/texterity for videos of real-world demonstrations.
Making Pre-trained Language Models Great on Tabular Prediction
Mar 04, 2024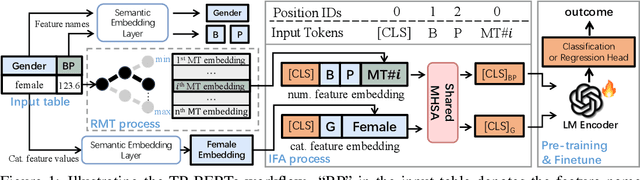
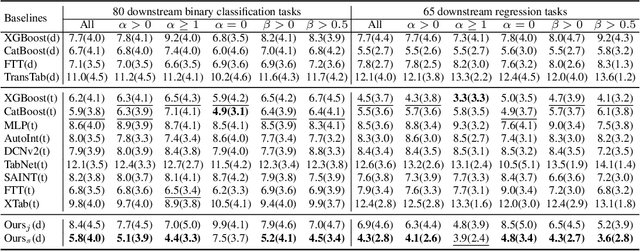
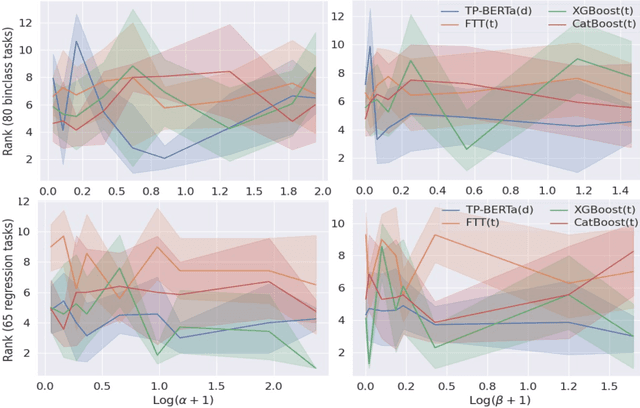
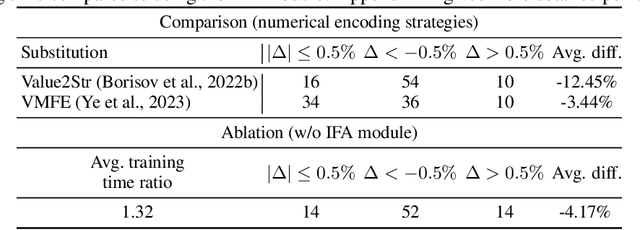
The transferability of deep neural networks (DNNs) has made significant progress in image and language processing. However, due to the heterogeneity among tables, such DNN bonus is still far from being well exploited on tabular data prediction (e.g., regression or classification tasks). Condensing knowledge from diverse domains, language models (LMs) possess the capability to comprehend feature names from various tables, potentially serving as versatile learners in transferring knowledge across distinct tables and diverse prediction tasks, but their discrete text representation space is inherently incompatible with numerical feature values in tables. In this paper, we present TP-BERTa, a specifically pre-trained LM model for tabular data prediction. Concretely, a novel relative magnitude tokenization converts scalar numerical feature values to finely discrete, high-dimensional tokens, and an intra-feature attention approach integrates feature values with the corresponding feature names. Comprehensive experiments demonstrate that our pre-trained TP-BERTa leads the performance among tabular DNNs and is competitive with Gradient Boosted Decision Tree models in typical tabular data regime.
VTG-GPT: Tuning-Free Zero-Shot Video Temporal Grounding with GPT
Mar 04, 2024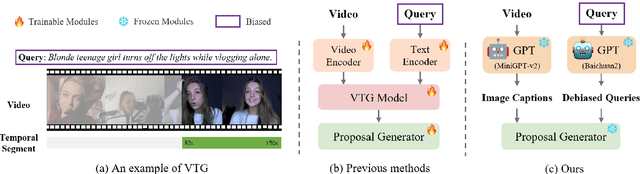
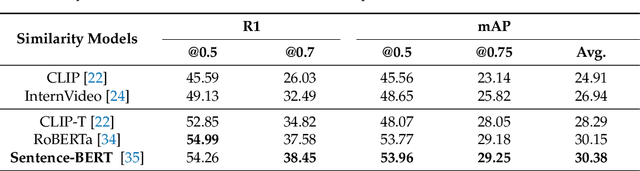

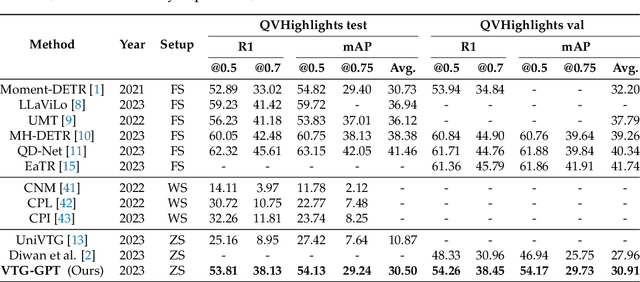
Video temporal grounding (VTG) aims to locate specific temporal segments from an untrimmed video based on a linguistic query. Most existing VTG models are trained on extensive annotated video-text pairs, a process that not only introduces human biases from the queries but also incurs significant computational costs. To tackle these challenges, we propose VTG-GPT, a GPT-based method for zero-shot VTG without training or fine-tuning. To reduce prejudice in the original query, we employ Baichuan2 to generate debiased queries. To lessen redundant information in videos, we apply MiniGPT-v2 to transform visual content into more precise captions. Finally, we devise the proposal generator and post-processing to produce accurate segments from debiased queries and image captions. Extensive experiments demonstrate that VTG-GPT significantly outperforms SOTA methods in zero-shot settings and surpasses unsupervised approaches. More notably, it achieves competitive performance comparable to supervised methods. The code is available on https://github.com/YoucanBaby/VTG-GPT
Weighted Monte Carlo augmented spherical Fourier-Bessel convolutional layers for 3D abdominal organ segmentation
Feb 27, 2024Filter-decomposition-based group equivariant convolutional neural networks show promising stability and data efficiency for 3D image feature extraction. However, the existing filter-decomposition-based 3D group equivariant neural networks rely on parameter-sharing designs and are mostly limited to rotation transform groups, where the chosen spherical harmonic filter bases consider only angular orthogonality. These limitations hamper its application to deep neural network architectures for medical image segmentation. To address these issues, this paper describes a non-parameter-sharing affine group equivariant neural network for 3D medical image segmentation based on an adaptive aggregation of Monte Carlo augmented spherical Fourier Bessel filter bases. The efficiency and flexibility of the adopted non-parameter strategy enable for the first time an efficient implementation of 3D affine group equivariant convolutional neural networks for volumetric data. The introduced spherical Bessel Fourier filter basis combines both angular and radial orthogonality for better feature extraction. The 3D image segmentation experiments on two abdominal image sets, BTCV and the NIH Pancreas datasets, show that the proposed methods excel the state-of-the-art 3D neural networks with high training stability and data efficiency. The code will be available at https://github.com/ZhaoWenzhao/WVMS.
Cobra Effect in Reference-Free Image Captioning Metrics
Feb 18, 2024Evaluating the compatibility between textual descriptions and corresponding images represents a core endeavor within multi-modal research. In recent years, a proliferation of reference-free methods, leveraging visual-language pre-trained models (VLMs), has emerged. Empirical evidence has substantiated that these innovative approaches exhibit a higher correlation with human judgment, marking a significant advancement in the field. However, does a higher correlation with human evaluations alone sufficiently denote the complete of a metric? In response to this question, in this paper, we study if there are any deficiencies in reference-free metrics. Specifically, inspired by the Cobra Effect, we utilize metric scores as rewards to direct the captioning model toward generating descriptions that closely align with the metric's criteria. If a certain metric has flaws, it will be exploited by the model and reflected in the generated sentences. Our findings reveal that descriptions guided by these metrics contain significant flaws, e.g. incoherent statements and excessive repetition. Subsequently, we propose a novel method termed Self-Improving to rectify the identified shortcomings within these metrics. We employ GPT-4V as an evaluative tool to assess generated sentences and the result reveals that our approach achieves state-of-the-art (SOTA) performance. In addition, we also introduce a challenging evaluation benchmark called Flaws Caption to evaluate reference-free image captioning metrics comprehensively. Our code is available at https://github.com/aaronma2020/robust_captioning_metric
A Lightweight Parallel Framework for Blind Image Quality Assessment
Feb 19, 2024Existing blind image quality assessment (BIQA) methods focus on designing complicated networks based on convolutional neural networks (CNNs) or transformer. In addition, some BIQA methods enhance the performance of the model in a two-stage training manner. Despite the significant advancements, these methods remarkably raise the parameter count of the model, thus requiring more training time and computational resources. To tackle the above issues, we propose a lightweight parallel framework (LPF) for BIQA. First, we extract the visual features using a pre-trained feature extraction network. Furthermore, we construct a simple yet effective feature embedding network (FEN) to transform the visual features, aiming to generate the latent representations that contain salient distortion information. To improve the robustness of the latent representations, we present two novel self-supervised subtasks, including a sample-level category prediction task and a batch-level quality comparison task. The sample-level category prediction task is presented to help the model with coarse-grained distortion perception. The batch-level quality comparison task is formulated to enhance the training data and thus improve the robustness of the latent representations. Finally, the latent representations are fed into a distortion-aware quality regression network (DaQRN), which simulates the human vision system (HVS) and thus generates accurate quality scores. Experimental results on multiple benchmark datasets demonstrate that the proposed method achieves superior performance over state-of-the-art approaches. Moreover, extensive analyses prove that the proposed method has lower computational complexity and faster convergence speed.