 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Real-Time Super-Resolution for Real-World Images on Mobile Devices
Jun 03, 2022
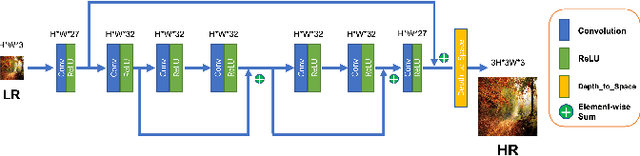
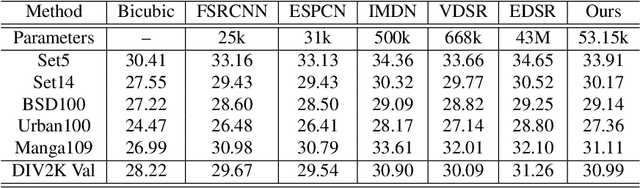
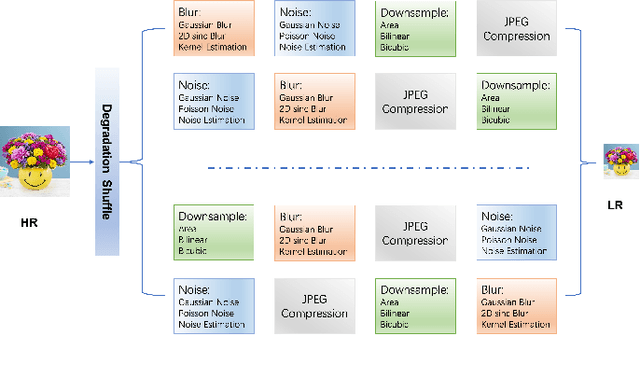
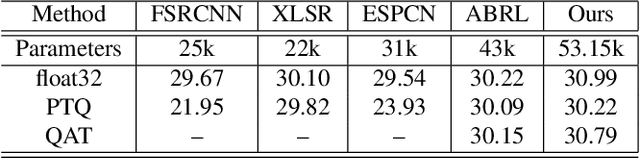
Image Super-Resolution (ISR), which aims at recovering High-Resolution (HR) images from the corresponding Low-Resolution (LR) counterparts. Although recent progress in ISR has been remarkable. However, they are way too computationally intensive to be deployed on edge devices, since most of the recent approaches are deep learning-based. Besides, these methods always fail in real-world scenes, since most of them adopt a simple fixed "ideal" bicubic downsampling kernel from high-quality images to construct LR/HR training pairs which may lose track of frequency-related details. In this work, an approach for real-time ISR on mobile devices is presented, which is able to deal with a wide range of degradations in real-world scenarios. Extensive experiments on traditional super-resolution datasets (Set5, Set14, BSD100, Urban100, Manga109, DIV2K) and real-world images with a variety of degradations demonstrate that our method outperforms the state-of-art methods, resulting in higher PSNR and SSIM, lower noise and better visual quality. Most importantly, our method achieves real-time performance on mobile or edge devices.
Video Diffusion Models
Apr 07, 2022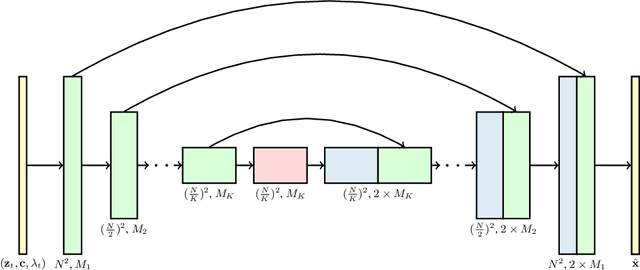
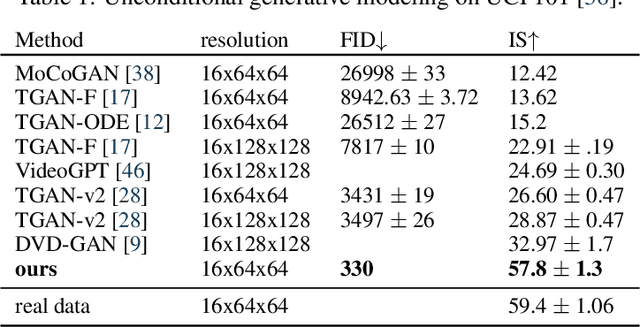


Generating temporally coherent high fidelity video is an important milestone in generative modeling research. We make progress towards this milestone by proposing a diffusion model for video generation that shows very promising initial results. Our model is a natural extension of the standard image diffusion architecture, and it enables jointly training from image and video data, which we find to reduce the variance of minibatch gradients and speed up optimization. To generate long and higher resolution videos we introduce a new conditional sampling technique for spatial and temporal video extension that performs better than previously proposed methods. We present the first results on a large text-conditioned video generation task, as well as state-of-the-art results on an established unconditional video generation benchmark. Supplementary material is available at https://video-diffusion.github.io/
Fine-Grained Counting with Crowd-Sourced Supervision
May 30, 2022
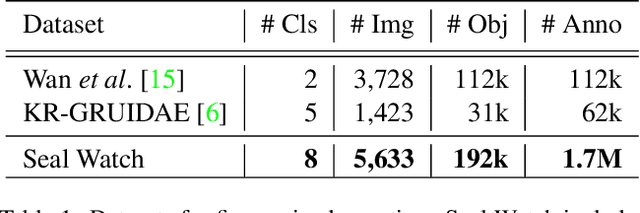

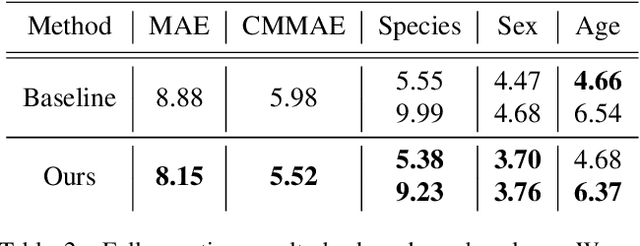
Crowd-sourcing is an increasingly popular tool for image analysis in animal ecology. Computer vision methods that can utilize crowd-sourced annotations can help scale up analysis further. In this work we study the potential to do so on the challenging task of fine-grained counting. As opposed to the standard crowd counting task, fine-grained counting also involves classifying attributes of individuals in dense crowds. We introduce a new dataset from animal ecology to enable this study that contains 1.7M crowd-sourced annotations of 8 fine-grained classes. It is the largest available dataset for fine-grained counting and the first to enable the study of the task with crowd-sourced annotations. We introduce methods for generating aggregate "ground truths" from the collected annotations, as well as a counting method that can utilize the aggregate information. Our method improves results by 8% over a comparable baseline, indicating the potential for algorithms to learn fine-grained counting using crowd-sourced supervision.
Task Fingerprinting for Meta Learning in Biomedical Image Analysis
Jul 08, 2021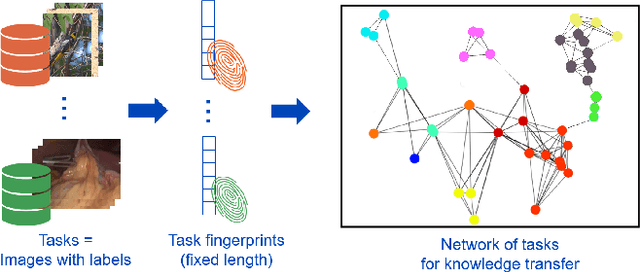
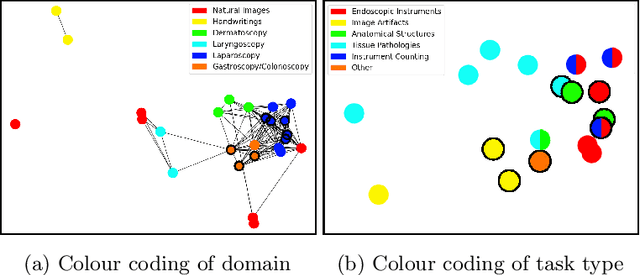
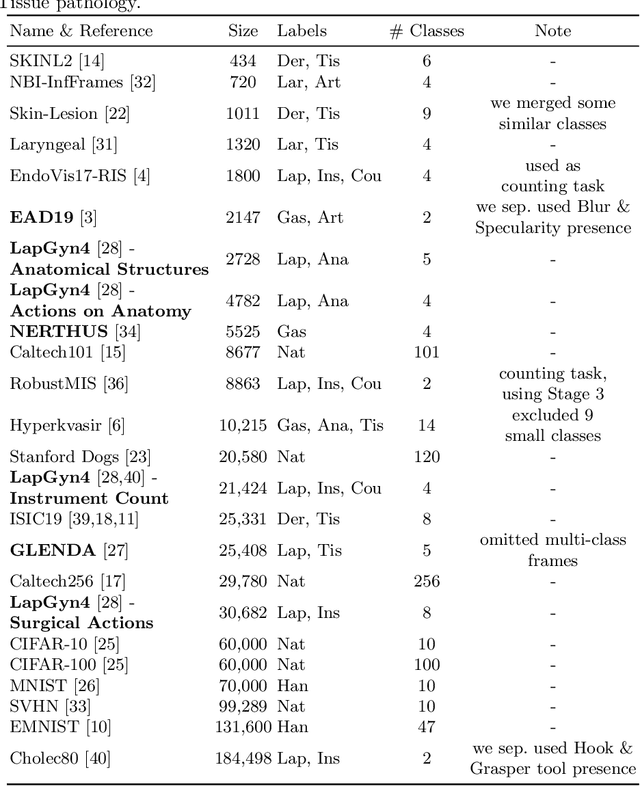
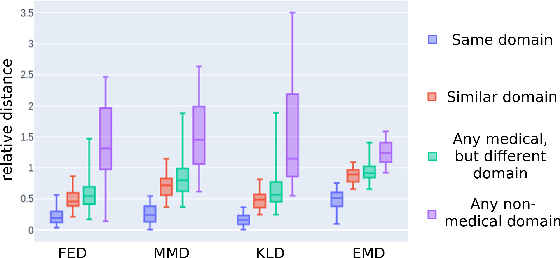
Shortage of annotated data is one of the greatest bottlenecks in biomedical image analysis. Meta learning studies how learning systems can increase in efficiency through experience and could thus evolve as an important concept to overcome data sparsity. However, the core capability of meta learning-based approaches is the identification of similar previous tasks given a new task - a challenge largely unexplored in the biomedical imaging domain. In this paper, we address the problem of quantifying task similarity with a concept that we refer to as task fingerprinting. The concept involves converting a given task, represented by imaging data and corresponding labels, to a fixed-length vector representation. In fingerprint space, different tasks can be directly compared irrespective of their data set sizes, types of labels or specific resolutions. An initial feasibility study in the field of surgical data science (SDS) with 26 classification tasks from various medical and non-medical domains suggests that task fingerprinting could be leveraged for both (1) selecting appropriate data sets for pretraining and (2) selecting appropriate architectures for a new task. Task fingerprinting could thus become an important tool for meta learning in SDS and other fields of biomedical image analysis.
Tracking Urbanization in Developing Regions with Remote Sensing Spatial-Temporal Super-Resolution
Apr 04, 2022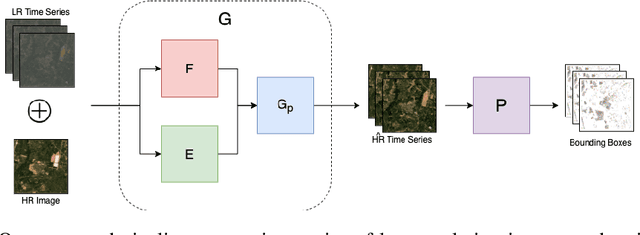
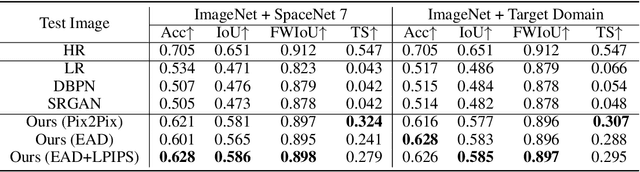

Automated tracking of urban development in areas where construction information is not available became possible with recent advancements in machine learning and remote sensing. Unfortunately, these solutions perform best on high-resolution imagery, which is expensive to acquire and infrequently available, making it difficult to scale over long time spans and across large geographies. In this work, we propose a pipeline that leverages a single high-resolution image and a time series of publicly available low-resolution images to generate accurate high-resolution time series for object tracking in urban construction. Our method achieves significant improvement in comparison to baselines using single image super-resolution, and can assist in extending the accessibility and scalability of building construction tracking across the developing world.
Implicit Feature Decoupling with Depthwise Quantization
Mar 29, 2022

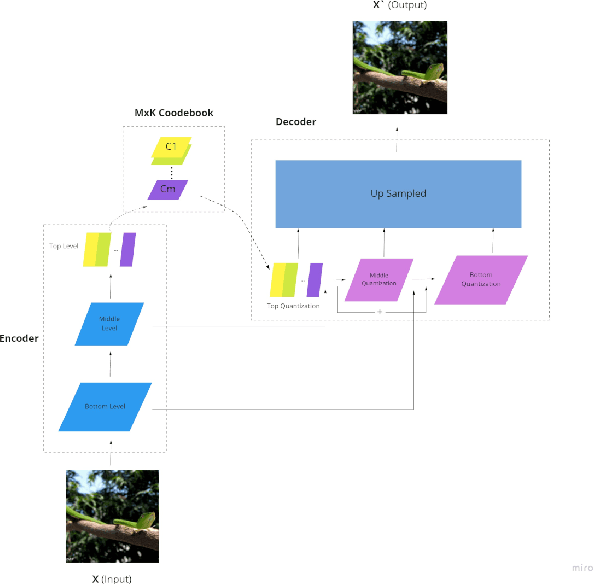
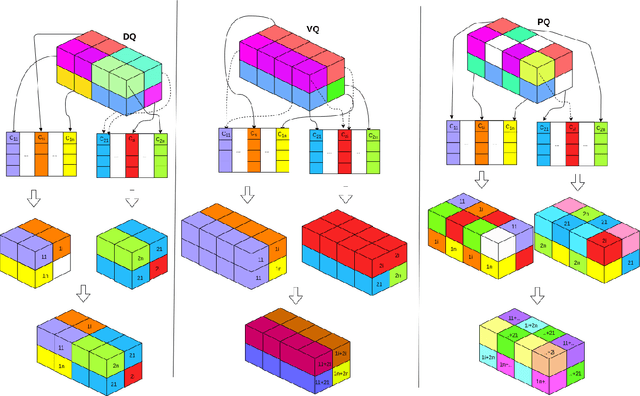
Quantization has been applied to multiple domains in Deep Neural Networks (DNNs). We propose Depthwise Quantization (DQ) where $\textit{quantization}$ is applied to a decomposed sub-tensor along the $\textit{feature axis}$ of weak statistical dependence. The feature decomposition leads to an exponential increase in $\textit{representation capacity}$ with a linear increase in memory and parameter cost. In addition, DQ can be directly applied to existing encoder-decoder frameworks without modification of the DNN architecture. We use DQ in the context of Hierarchical Auto-Encoder and train end-to-end on an image feature representation. We provide an analysis on cross-correlation between spatial and channel features and we propose a decomposition of the image feature representation along the channel axis. The improved performance of the depthwise operator is due to the increased representation capacity from implicit feature decoupling. We evaluate DQ on the likelihood estimation task, where it outperforms the previous state-of-the-art on CIFAR-10, ImageNet-32 and ImageNet-64. We progressively train with increasing image size a single hierarchical model that uses 69% less parameters and has a faster convergence than the previous works.
Learning Spatially Varying Pixel Exposures for Motion Deblurring
Apr 14, 2022
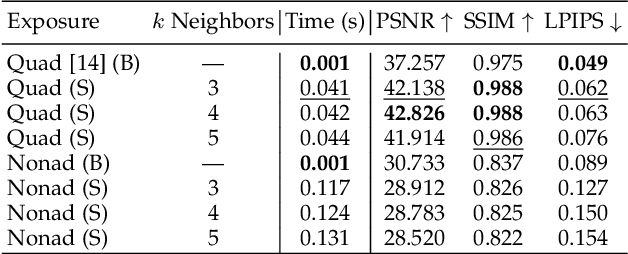
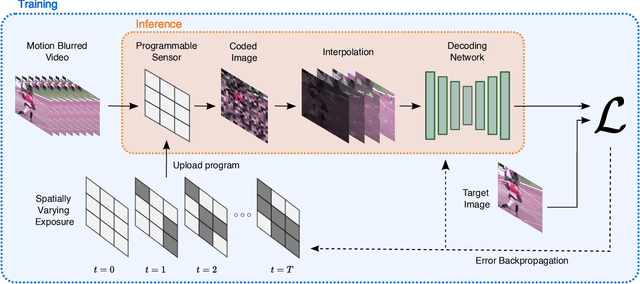
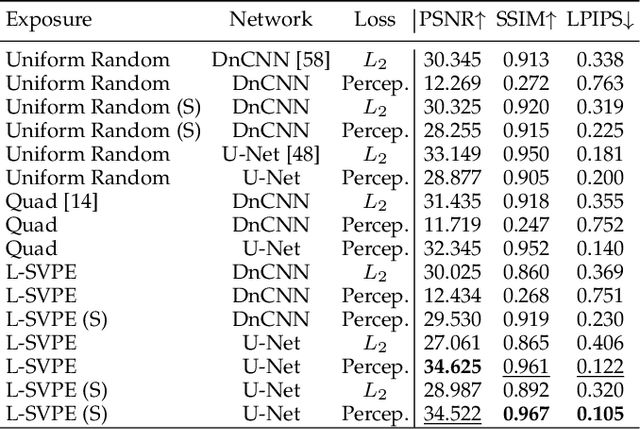
Computationally removing the motion blur introduced by camera shake or object motion in a captured image remains a challenging task in computational photography. Deblurring methods are often limited by the fixed global exposure time of the image capture process. The post-processing algorithm either must deblur a longer exposure that contains relatively little noise or denoise a short exposure that intentionally removes the opportunity for blur at the cost of increased noise. We present a novel approach of leveraging spatially varying pixel exposures for motion deblurring using next-generation focal-plane sensor--processors along with an end-to-end design of these exposures and a machine learning--based motion-deblurring framework. We demonstrate in simulation and a physical prototype that learned spatially varying pixel exposures (L-SVPE) can successfully deblur scenes while recovering high frequency detail. Our work illustrates the promising role that focal-plane sensor--processors can play in the future of computational imaging.
Contrastive Learning for Unpaired Image-to-Image Translation
Jul 30, 2020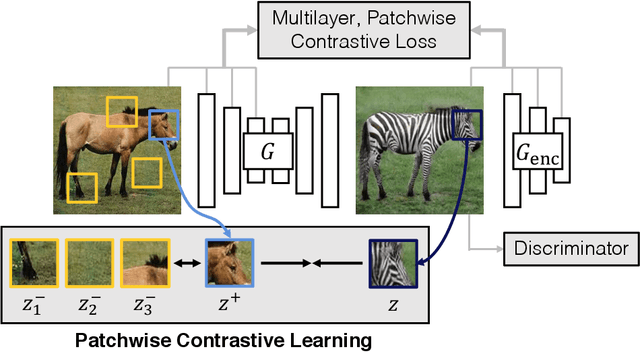
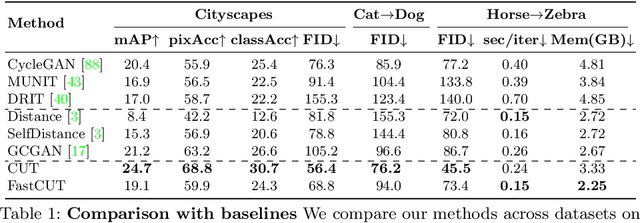
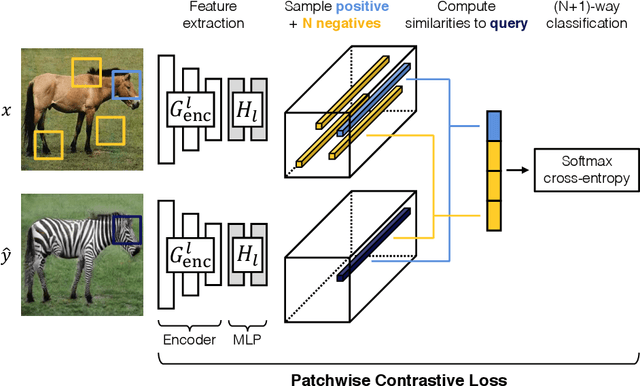
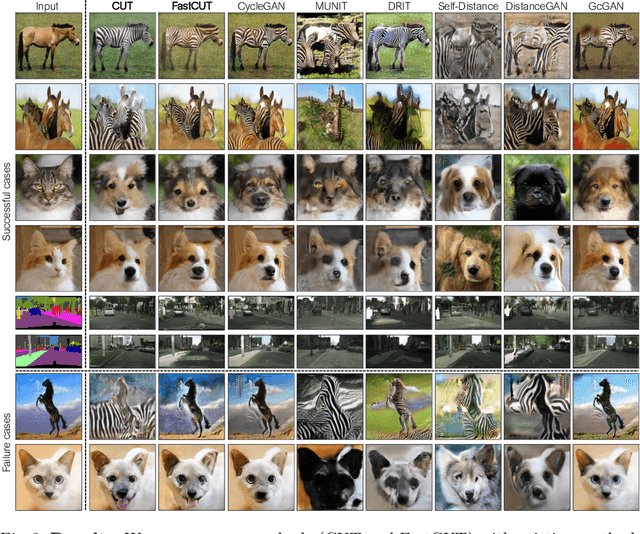
In image-to-image translation, each patch in the output should reflect the content of the corresponding patch in the input, independent of domain. We propose a straightforward method for doing so -- maximizing mutual information between the two, using a framework based on contrastive learning. The method encourages two elements (corresponding patches) to map to a similar point in a learned feature space, relative to other elements (other patches) in the dataset, referred to as negatives. We explore several critical design choices for making contrastive learning effective in the image synthesis setting. Notably, we use a multilayer, patch-based approach, rather than operate on entire images. Furthermore, we draw negatives from within the input image itself, rather than from the rest of the dataset. We demonstrate that our framework enables one-sided translation in the unpaired image-to-image translation setting, while improving quality and reducing training time. In addition, our method can even be extended to the training setting where each "domain" is only a single image.
On Outer Bi-Lipschitz Extensions of Linear Johnson-Lindenstrauss Embeddings of Low-Dimensional Submanifolds of $\mathbb{R}^N$
Jun 07, 2022
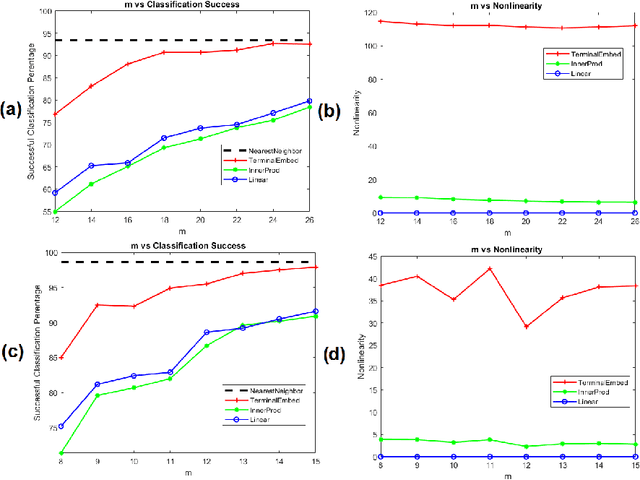
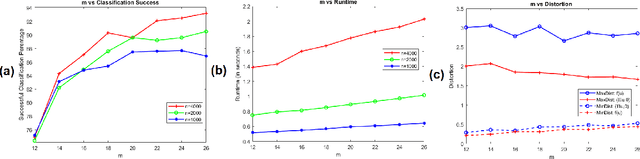
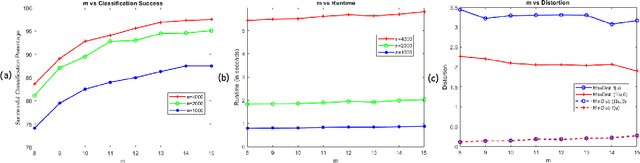
Let $\mathcal{M}$ be a compact $d$-dimensional submanifold of $\mathbb{R}^N$ with reach $\tau$ and volume $V_{\mathcal M}$. Fix $\epsilon \in (0,1)$. In this paper we prove that a nonlinear function $f: \mathbb{R}^N \rightarrow \mathbb{R}^{m}$ exists with $m \leq C \left(d / \epsilon^2 \right) \log \left(\frac{\sqrt[d]{V_{\mathcal M}}}{\tau} \right)$ such that $$(1 - \epsilon) \| {\bf x} - {\bf y} \|_2 \leq \left\| f({\bf x}) - f({\bf y}) \right\|_2 \leq (1 + \epsilon) \| {\bf x} - {\bf y} \|_2$$ holds for all ${\bf x} \in \mathcal{M}$ and ${\bf y} \in \mathbb{R}^N$. In effect, $f$ not only serves as a bi-Lipschitz function from $\mathcal{M}$ into $\mathbb{R}^{m}$ with bi-Lipschitz constants close to one, but also approximately preserves all distances from points not in $\mathcal{M}$ to all points in $\mathcal{M}$ in its image. Furthermore, the proof is constructive and yields an algorithm which works well in practice. In particular, it is empirically demonstrated herein that such nonlinear functions allow for more accurate compressive nearest neighbor classification than standard linear Johnson-Lindenstrauss embeddings do in practice.
Hierarchical Image Peeling: A Flexible Scale-space Filtering Framework
Apr 04, 2021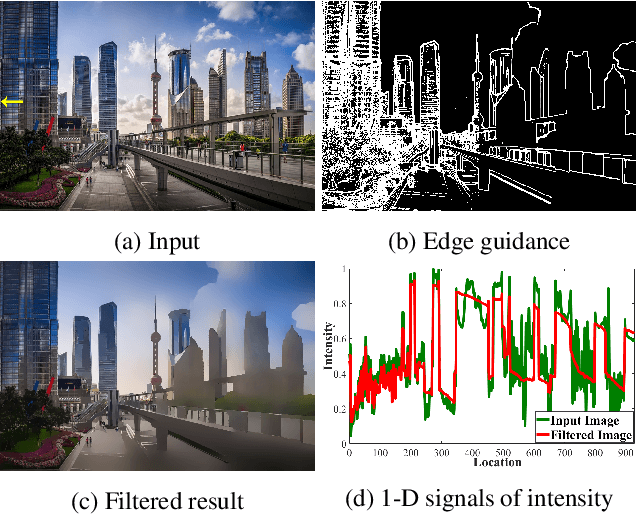
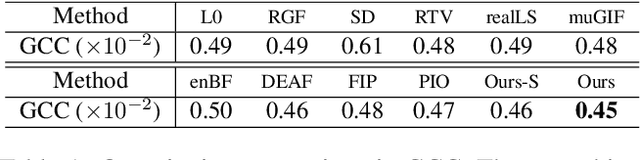
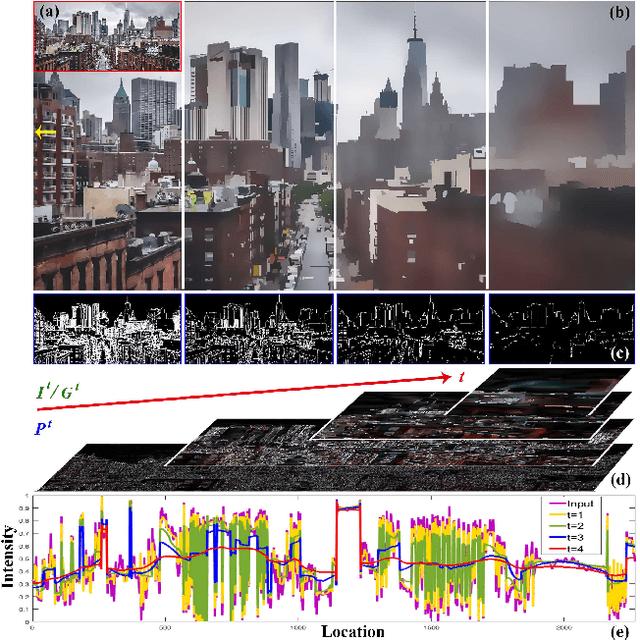
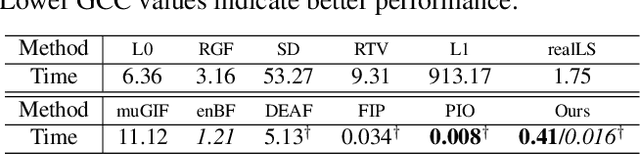
The importance of hierarchical image organization has been witnessed by a wide spectrum of applications in computer vision and graphics. Different from image segmentation with the spatial whole-part consideration, this work designs a modern framework for disassembling an image into a family of derived signals from a scale-space perspective. Specifically, we first offer a formal definition of image disassembly. Then, by concerning desired properties, such as peeling hierarchy and structure preservation, we convert the original complex problem into a series of two-component separation sub-problems, significantly reducing the complexity. The proposed framework is flexible to both supervised and unsupervised settings. A compact recurrent network, namely hierarchical image peeling net, is customized to efficiently and effectively fulfill the task, which is about 3.5Mb in size, and can handle 1080p images in more than 60 fps per recurrence on a GTX 2080Ti GPU, making it attractive for practical use. Both theoretical findings and experimental results are provided to demonstrate the efficacy of the proposed framework, reveal its superiority over other state-of-the-art alternatives, and show its potential to various applicable scenarios. Our code is available at \url{https://github.com/ForawardStar/HIPe}.