 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Vision-and-Language Pre-training via Retrieval-based Multi-Granular Alignment
Mar 01, 2022
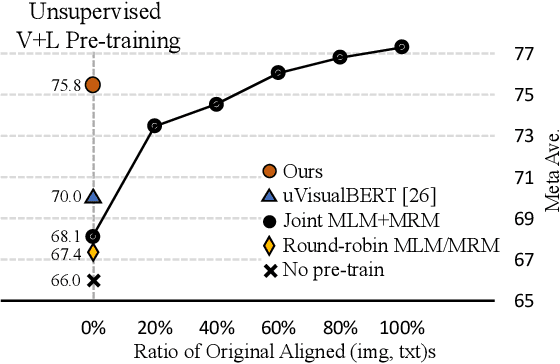
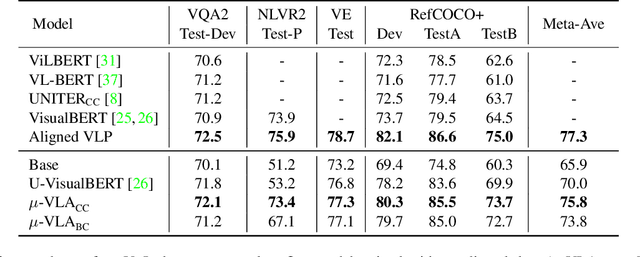
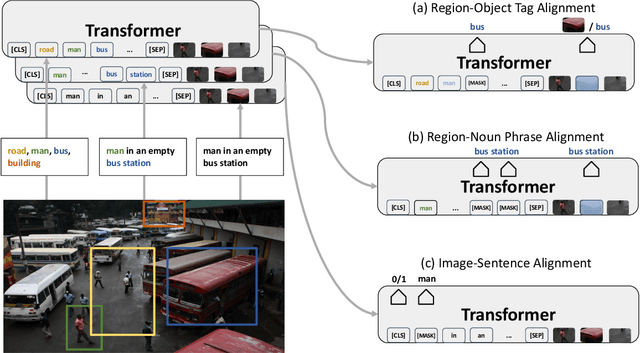
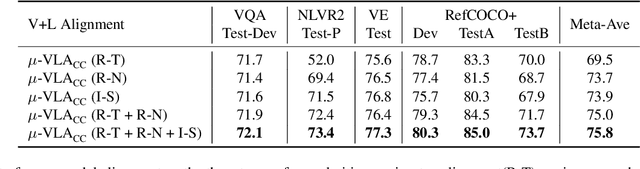
Vision-and-Language (V+L) pre-training models have achieved tremendous success in recent years on various multi-modal benchmarks. However, the majority of existing models require pre-training on a large set of parallel image-text data, which is costly to collect, compared to image-only or text-only data. In this paper, we explore unsupervised Vision-and-Language pre-training (UVLP) to learn the cross-modal representation from non-parallel image and text datasets. We found two key factors that lead to good unsupervised V+L pre-training without parallel data: (i) joint image-and-text input (ii) overall image-text alignment (even for non-parallel data). Accordingly, we propose a novel unsupervised V+L pre-training curriculum for non-parallel texts and images. We first construct a weakly aligned image-text corpus via a retrieval-based approach, then apply a set of multi-granular alignment pre-training tasks, including region-to-tag, region-to-phrase, and image-to-sentence alignment, to bridge the gap between the two modalities. A comprehensive ablation study shows each granularity is helpful to learn a stronger pre-trained model. We adapt our pre-trained model to a set of V+L downstream tasks, including VQA, NLVR2, Visual Entailment, and RefCOCO+. Our model achieves the state-of-art performance in all these tasks under the unsupervised setting.
A Unified Sequence Interface for Vision Tasks
Jun 15, 2022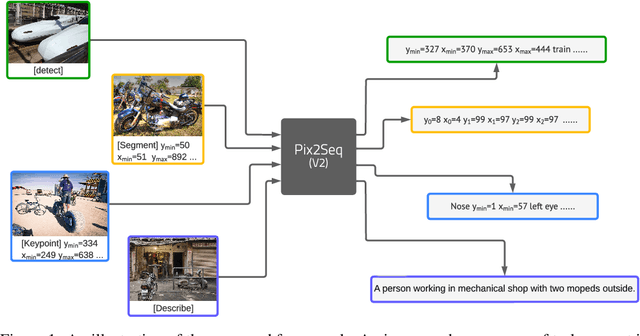
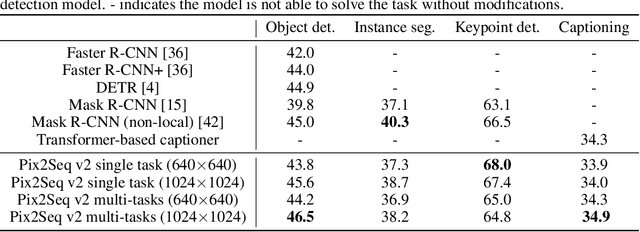
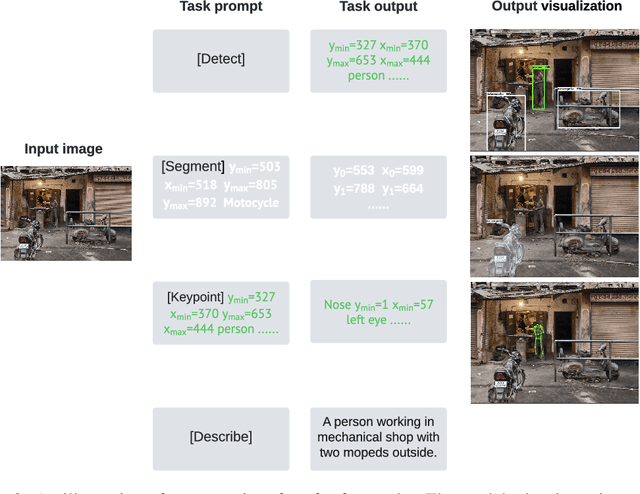

While language tasks are naturally expressed in a single, unified, modeling framework, i.e., generating sequences of tokens, this has not been the case in computer vision. As a result, there is a proliferation of distinct architectures and loss functions for different vision tasks. In this work we show that a diverse set of "core" computer vision tasks can also be unified if formulated in terms of a shared pixel-to-sequence interface. We focus on four tasks, namely, object detection, instance segmentation, keypoint detection, and image captioning, all with diverse types of outputs, e.g., bounding boxes or dense masks. Despite that, by formulating the output of each task as a sequence of discrete tokens with a unified interface, we show that one can train a neural network with a single model architecture and loss function on all these tasks, with no task-specific customization. To solve a specific task, we use a short prompt as task description, and the sequence output adapts to the prompt so it can produce task-specific output. We show that such a model can achieve competitive performance compared to well-established task-specific models.
Neural Space-filling Curves
Apr 18, 2022
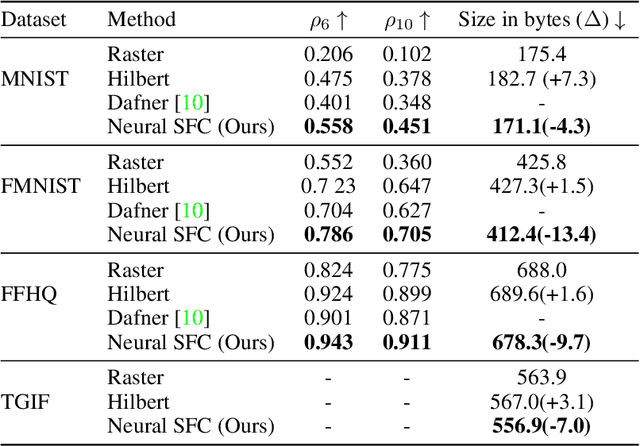
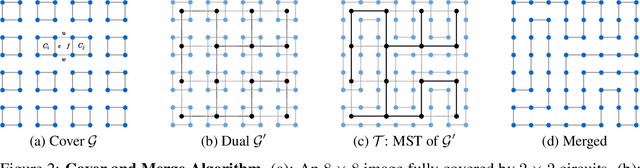
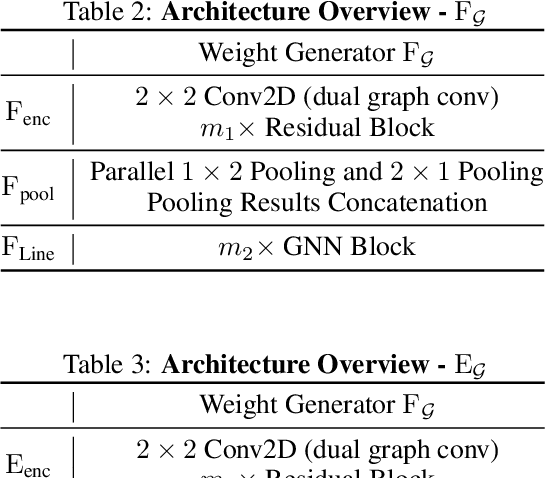
We present Neural Space-filling Curves (SFCs), a data-driven approach to infer a context-based scan order for a set of images. Linear ordering of pixels forms the basis for many applications such as video scrambling, compression, and auto-regressive models that are used in generative modeling for images. Existing algorithms resort to a fixed scanning algorithm such as Raster scan or Hilbert scan. Instead, our work learns a spatially coherent linear ordering of pixels from the dataset of images using a graph-based neural network. The resulting Neural SFC is optimized for an objective suitable for the downstream task when the image is traversed along with the scan line order. We show the advantage of using Neural SFCs in downstream applications such as image compression. Code and additional results will be made available at https://hywang66.github.io/publication/neuralsfc.
Image-Graph-Image Translation via Auto-Encoding
Dec 10, 2020

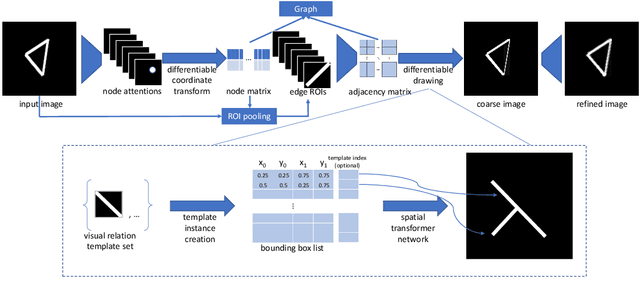
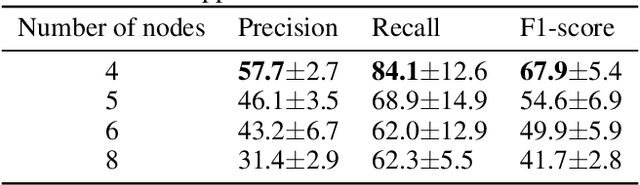
This work presents the first convolutional neural network that learns an image-to-graph translation task without needing external supervision. Obtaining graph representations of image content, where objects are represented as nodes and their relationships as edges, is an important task in scene understanding. Current approaches follow a fully-supervised approach thereby requiring meticulous annotations. To overcome this, we are the first to present a self-supervised approach based on a fully-differentiable auto-encoder in which the bottleneck encodes the graph's nodes and edges. This self-supervised approach can currently encode simple line drawings into graphs and obtains comparable results to a fully-supervised baseline in terms of F1 score on triplet matching. Besides these promising results, we provide several directions for future research on how our approach can be extended to cover more complex imagery.
Label-Efficient Self-Supervised Federated Learning for Tackling Data Heterogeneity in Medical Imaging
May 17, 2022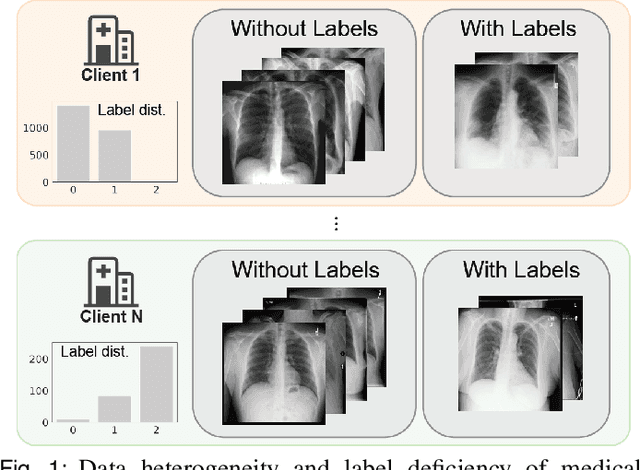
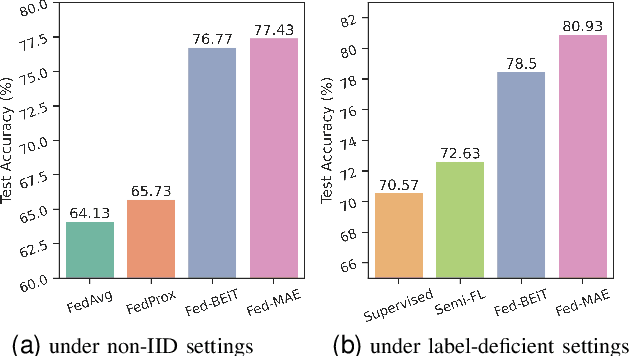
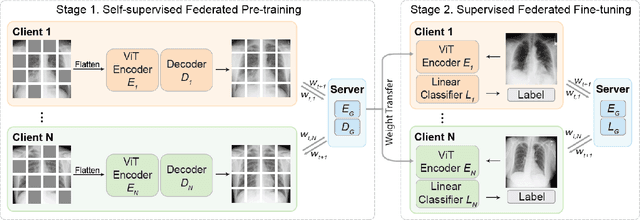
The curation of large-scale medical datasets from multiple institutions necessary for training deep learning models is challenged by the difficulty in sharing patient data with privacy-preserving. Federated learning (FL), a paradigm that enables privacy-protected collaborative learning among different institutions, is a promising solution to this challenge. However, FL generally suffers from performance deterioration due to heterogeneous data distributions across institutions and the lack of quality labeled data. In this paper, we present a robust and label-efficient self-supervised FL framework for medical image analysis. Specifically, we introduce a novel distributed self-supervised pre-training paradigm into the existing FL pipeline (i.e., pre-training the models directly on the decentralized target task datasets). Built upon the recent success of Vision Transformers, we employ masked image encoding tasks for self-supervised pre-training, to facilitate more effective knowledge transfer to downstream federated models. Extensive empirical results on simulated and real-world medical imaging federated datasets show that self-supervised pre-training largely benefits the robustness of federated models against various degrees of data heterogeneity. Notably, under severe data heterogeneity, our method, without relying on any additional pre-training data, achieves an improvement of 5.06%, 1.53% and 4.58% in test accuracy on retinal, dermatology and chest X-ray classification compared with the supervised baseline with ImageNet pre-training. Moreover, we show that our self-supervised FL algorithm generalizes well to out-of-distribution data and learns federated models more effectively in limited label scenarios, surpassing the supervised baseline by 10.36% and the semi-supervised FL method by 8.3% in test accuracy.
Efficient and Accurate Hyperspectral Pansharpening Using 3D VolumeNet and 2.5D Texture Transfer
Mar 08, 2022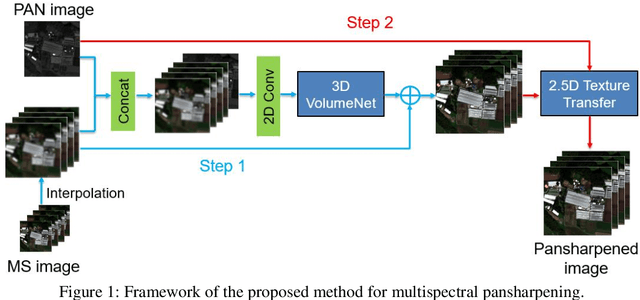
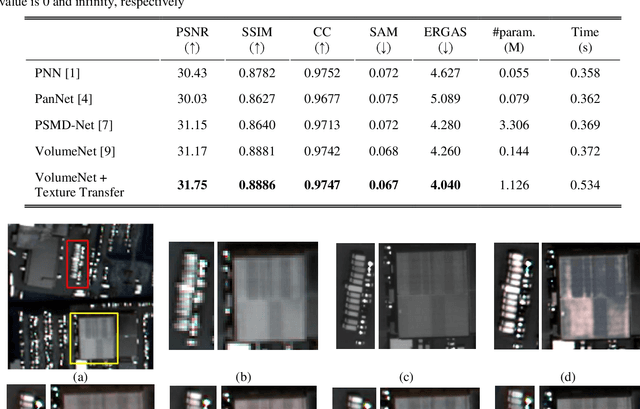
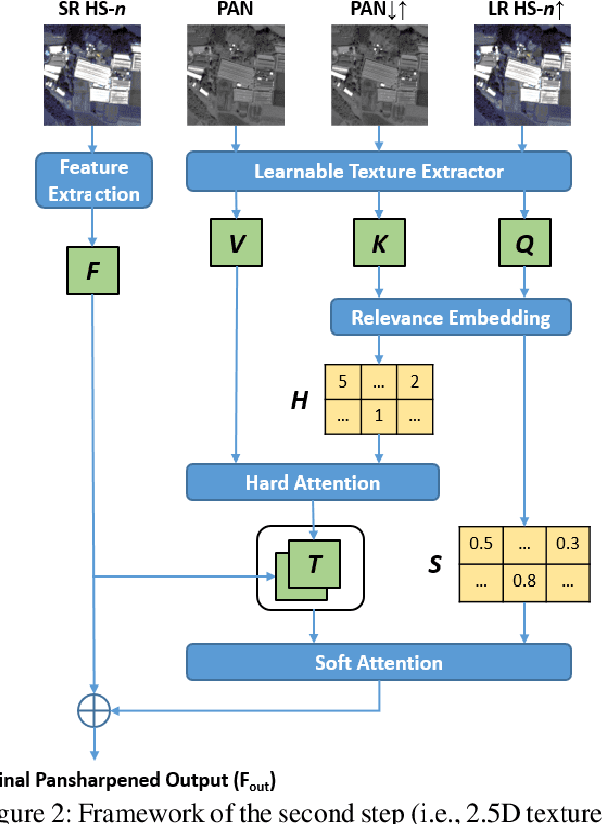
Recently, convolutional neural networks (CNN) have obtained promising results in single-image SR for hyperspectral pansharpening. However, enhancing CNNs' representation ability with fewer parameters and a shorter prediction time is a challenging and critical task. In this paper, we propose a novel multi-spectral image fusion method using a combination of the previously proposed 3D CNN model VolumeNet and 2.5D texture transfer method using other modality high resolution (HR) images. Since a multi-spectral (MS) image consists of several bands and each band is a 2D image slice, MS images can be seen as 3D data. Thus, we use the previously proposed VolumeNet to fuse HR panchromatic (PAN) images and bicubic interpolated MS images. Because the proposed 3D VolumeNet can effectively improve the accuracy by expanding the receptive field of the model, and due to its lightweight structure, we can achieve better performance against the existing method without purchasing a large number of remote sensing images for training. In addition, VolumeNet can restore the high-frequency information lost in the HR MR image as much as possible, reducing the difficulty of feature extraction in the following step: 2.5D texture transfer. As one of the latest technologies, deep learning-based texture transfer has been demonstrated to effectively and efficiently improve the visual performance and quality evaluation indicators of image reconstruction. Different from the texture transfer processing of RGB image, we use HR PAN images as the reference images and perform texture transfer for each frequency band of MS images, which is named 2.5D texture transfer. The experimental results show that the proposed method outperforms the existing methods in terms of objective accuracy assessment, method efficiency, and visual subjective evaluation.
Monocular Depth Estimation Using Cues Inspired by Biological Vision Systems
Apr 21, 2022
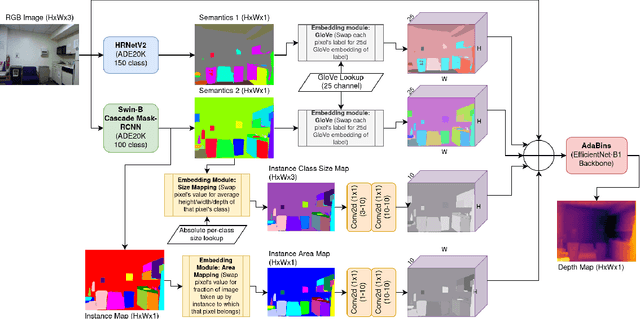
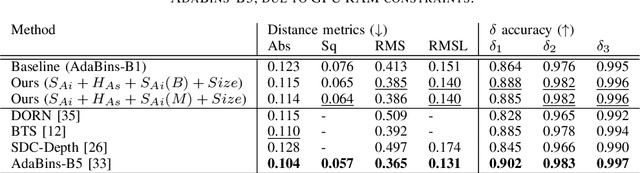
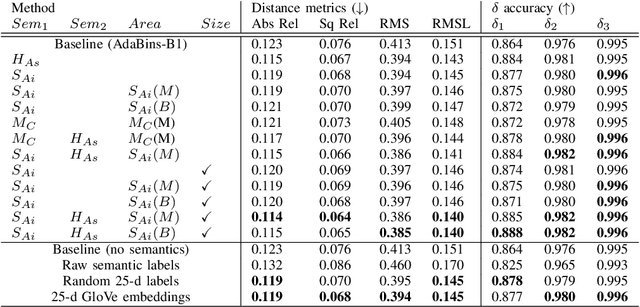
Monocular depth estimation (MDE) aims to transform an RGB image of a scene into a pixelwise depth map from the same camera view. It is fundamentally ill-posed due to missing information: any single image can have been taken from many possible 3D scenes. Part of the MDE task is, therefore, to learn which visual cues in the image can be used for depth estimation, and how. With training data limited by cost of annotation or network capacity limited by computational power, this is challenging. In this work we demonstrate that explicitly injecting visual cue information into the model is beneficial for depth estimation. Following research into biological vision systems, we focus on semantic information and prior knowledge of object sizes and their relations, to emulate the biological cues of relative size, familiar size, and absolute size. We use state-of-the-art semantic and instance segmentation models to provide external information, and exploit language embeddings to encode relational information between classes. We also provide a prior on the average real-world size of objects. This external information overcomes the limitation in data availability, and ensures that the limited capacity of a given network is focused on known-helpful cues, therefore improving performance. We experimentally validate our hypothesis and evaluate the proposed model on the widely used NYUD2 indoor depth estimation benchmark. The results show improvements in depth prediction when the semantic information, size prior and instance size are explicitly provided along with the RGB images, and our method can be easily adapted to any depth estimation system.
Common Limitations of Image Processing Metrics: A Picture Story
Apr 12, 2021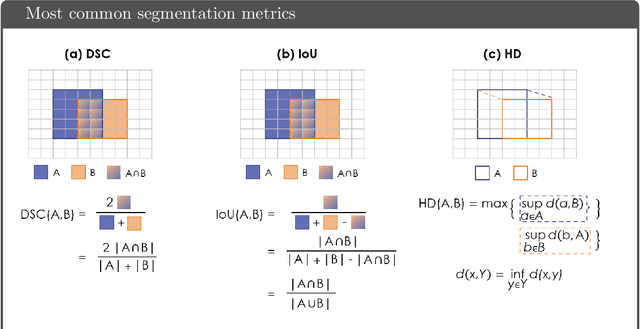
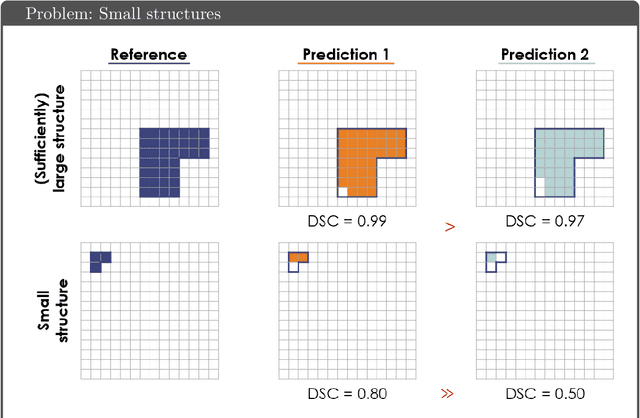
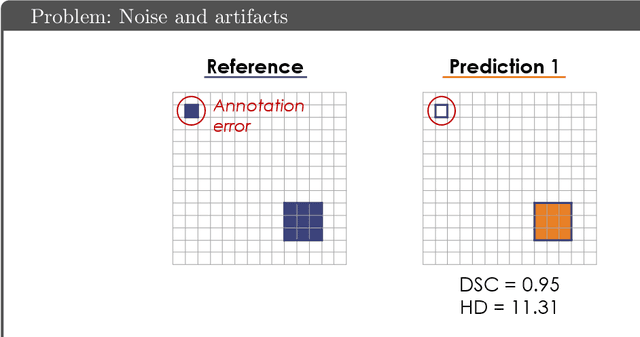
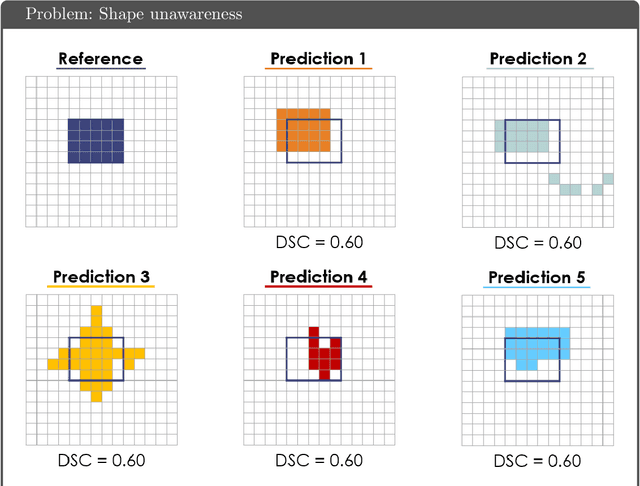
While the importance of automatic image analysis is increasing at an enormous pace, recent meta-research revealed major flaws with respect to algorithm validation. Specifically, performance metrics are key for objective, transparent and comparative performance assessment, but relatively little attention has been given to the practical pitfalls when using specific metrics for a given image analysis task. A common mission of several international initiatives is therefore to provide researchers with guidelines and tools to choose the performance metrics in a problem-aware manner. This dynamically updated document has the purpose to illustrate important limitations of performance metrics commonly applied in the field of image analysis. The current version is based on a Delphi process on metrics conducted by an international consortium of image analysis experts.
X-ViT: High Performance Linear Vision Transformer without Softmax
May 27, 2022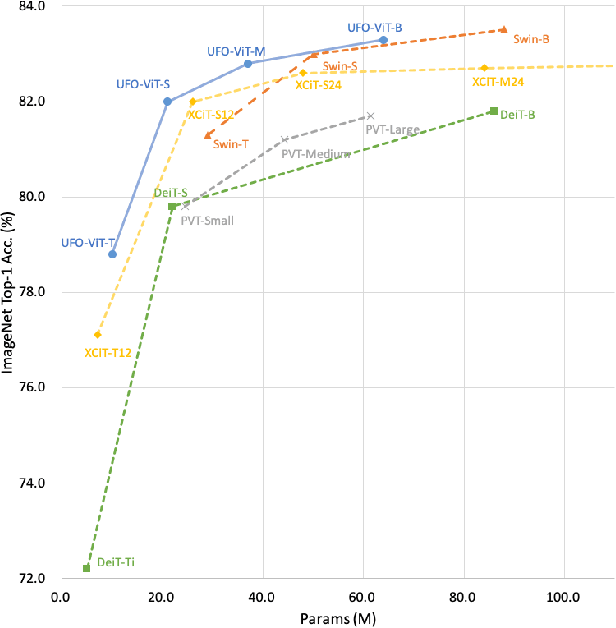

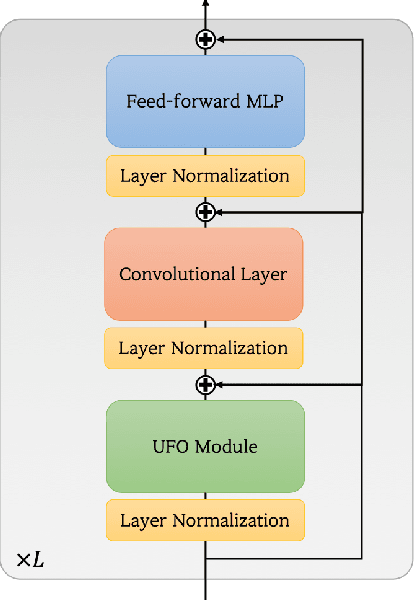

Vision transformers have become one of the most important models for computer vision tasks. Although they outperform prior works, they require heavy computational resources on a scale that is quadratic to the number of tokens, $N$. This is a major drawback of the traditional self-attention (SA) algorithm. Here, we propose the X-ViT, ViT with a novel SA mechanism that has linear complexity. The main approach of this work is to eliminate nonlinearity from the original SA. We factorize the matrix multiplication of the SA mechanism without complicated linear approximation. By modifying only a few lines of code from the original SA, the proposed models outperform most transformer-based models on image classification and dense prediction tasks on most capacity regimes.
Mask DINO: Towards A Unified Transformer-based Framework for Object Detection and Segmentation
Jun 06, 2022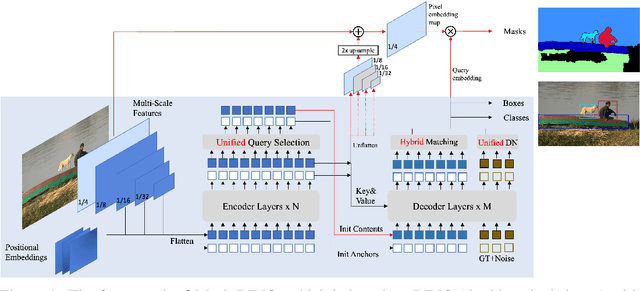



In this paper we present Mask DINO, a unified object detection and segmentation framework. Mask DINO extends DINO (DETR with Improved Denoising Anchor Boxes) by adding a mask prediction branch which supports all image segmentation tasks (instance, panoptic, and semantic). It makes use of the query embeddings from DINO to dot-product a high-resolution pixel embedding map to predict a set of binary masks. Some key components in DINO are extended for segmentation through a shared architecture and training process. Mask DINO is simple, efficient, scalable, and benefits from joint large-scale detection and segmentation datasets. Our experiments show that Mask DINO significantly outperforms all existing specialized segmentation methods, both on a ResNet-50 backbone and a pre-trained model with SwinL backbone. Notably, Mask DINO establishes the best results to date on instance segmentation (54.5 AP on COCO), panoptic segmentation (59.4 PQ on COCO), and semantic segmentation (60.8 mIoU on ADE20K). Code will be avaliable at \url{https://github.com/IDEACVR/MaskDINO}.