 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Geodesic Gramian Denoising Applied to the Images Contaminated With Noise Sampled From Diverse Probability Distributions
Mar 04, 2022

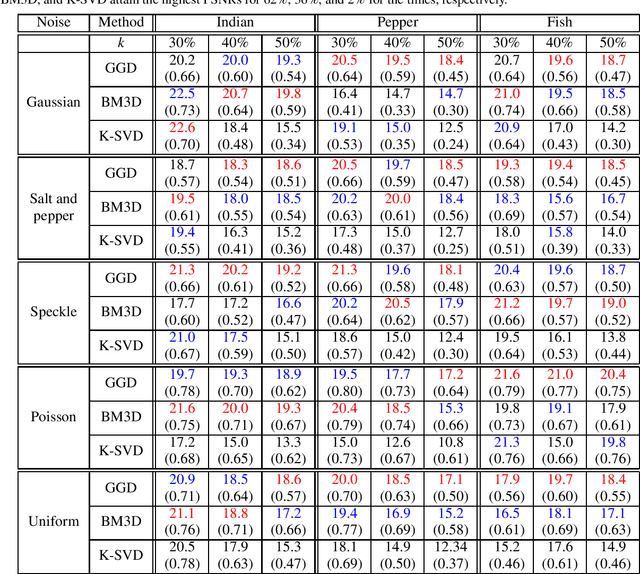


As quotidian use of sophisticated cameras surges, people in modern society are more interested in capturing fine-quality images. However, the quality of the images might be inferior to people's expectations due to the noise contamination in the images. Thus, filtering out the noise while preserving vital image features is an essential requirement. Current existing denoising methods have their own assumptions on the probability distribution in which the contaminated noise is sampled for the method to attain its expected denoising performance. In this paper, we utilize our recent Gramian-based filtering scheme to remove noise sampled from five prominent probability distributions from selected images. This method preserves image smoothness by adopting patches partitioned from the image, rather than pixels, and retains vital image features by performing denoising on the manifold underlying the patch space rather than in the image domain. We validate its denoising performance, using three benchmark computer vision test images applied to two state-of-the-art denoising methods, namely BM3D and K-SVD.
Segmenting Medical Instruments in Minimally Invasive Surgeries using AttentionMask
Mar 21, 2022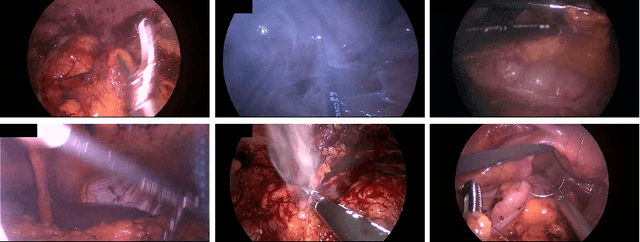
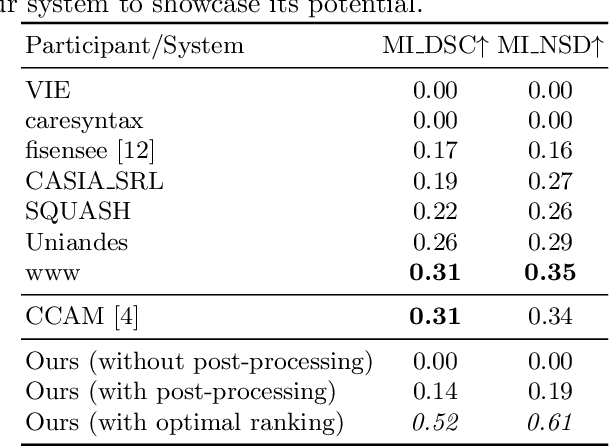
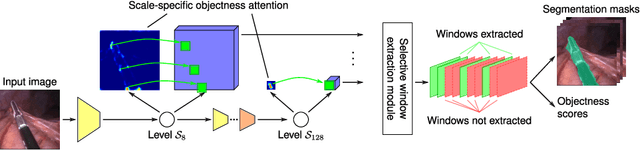
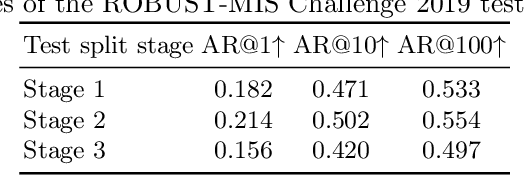
Precisely locating and segmenting medical instruments in images of minimally invasive surgeries, medical instrument segmentation, is an essential first step for several tasks in medical image processing. However, image degradations, small instruments, and the generalization between different surgery types make medical instrument segmentation challenging. To cope with these challenges, we adapt the object proposal generation system AttentionMask and propose a dedicated post-processing to select promising proposals. The results on the ROBUST-MIS Challenge 2019 show that our adapted AttentionMask system is a strong foundation for generating state-of-the-art performance. Our evaluation in an object proposal generation framework shows that our adapted AttentionMask system is robust to image degradations, generalizes well to unseen types of surgeries, and copes well with small instruments.
Privacy-Preserving Image Acquisition Using Trainable Optical Kernel
Jun 28, 2021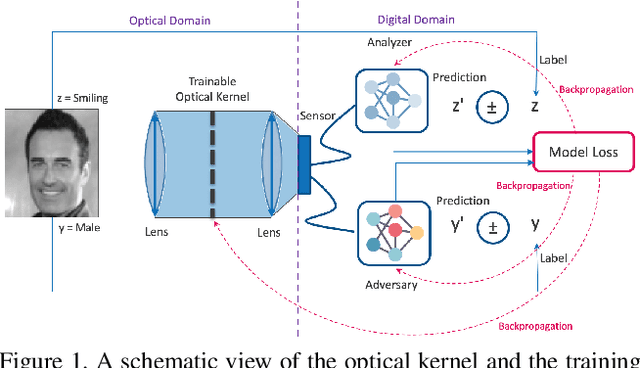
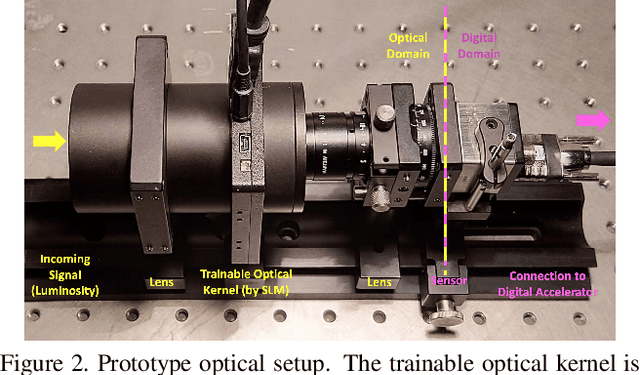
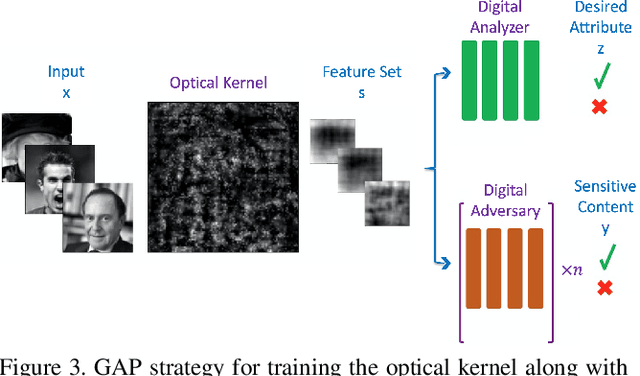

Preserving privacy is a growing concern in our society where sensors and cameras are ubiquitous. In this work, for the first time, we propose a trainable image acquisition method that removes the sensitive identity revealing information in the optical domain before it reaches the image sensor. The method benefits from a trainable optical convolution kernel which transmits the desired information while filters out the sensitive content. As the sensitive content is suppressed before it reaches the image sensor, it does not enter the digital domain therefore is unretrievable by any sort of privacy attack. This is in contrast with the current digital privacy-preserving methods that are all vulnerable to direct access attack. Also, in contrast with the previous optical privacy-preserving methods that cannot be trained, our method is data-driven and optimized for the specific application at hand. Moreover, there is no additional computation, memory, or power burden on the acquisition system since this processing happens passively in the optical domain and can even be used together and on top of the fully digital privacy-preserving systems. The proposed approach is adaptable to different digital neural networks and content. We demonstrate it for several scenarios such as smile detection as the desired attribute while the gender is filtered out as the sensitive content. We trained the optical kernel in conjunction with two adversarial neural networks where the analysis network tries to detect the desired attribute and the adversarial network tries to detect the sensitive content. We show that this method can reduce 65.1% of sensitive content when it is selected to be the gender and it only loses 7.3% of the desired content. Moreover, we reconstruct the original faces using the deep reconstruction method that confirms the ineffectiveness of reconstruction attacks to obtain the sensitive content.
Raw Image Deblurring
Dec 08, 2020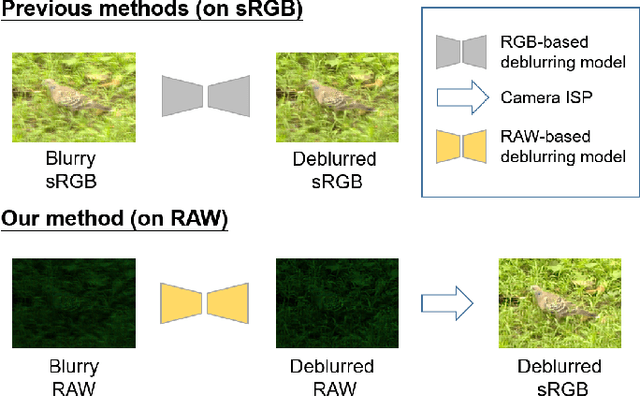
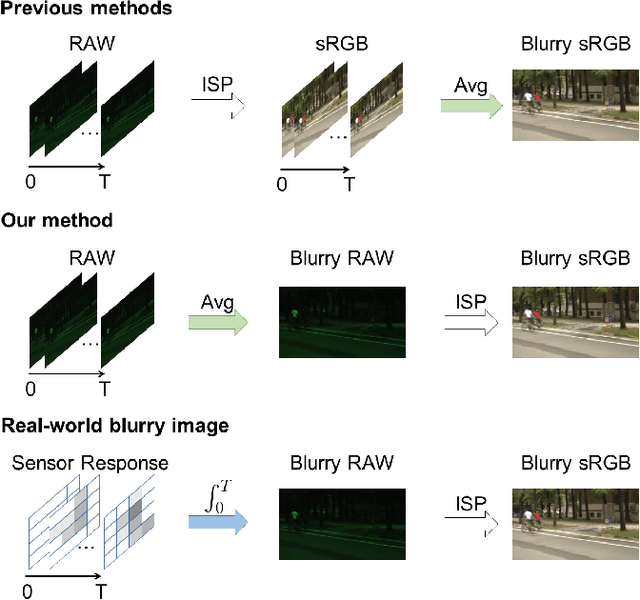

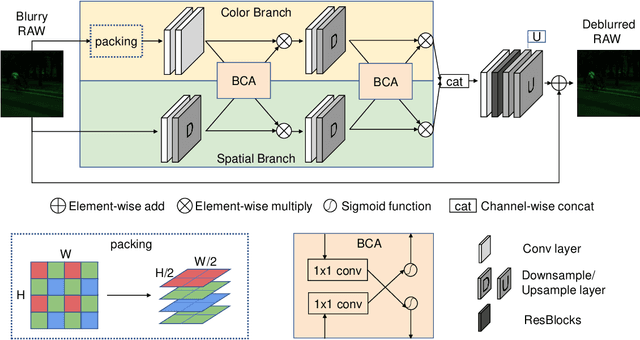
Deep learning-based blind image deblurring plays an essential role in solving image blur since all existing kernels are limited in modeling the real world blur. Thus far, researchers focus on powerful models to handle the deblurring problem and achieve decent results. For this work, in a new aspect, we discover the great opportunity for image enhancement (e.g., deblurring) directly from RAW images and investigate novel neural network structures benefiting RAW-based learning. However, to the best of our knowledge, there is no available RAW image deblurring dataset. Therefore, we built a new dataset containing both RAW images and processed sRGB images and design a new model to utilize the unique characteristics of RAW images. The proposed deblurring model, trained solely from RAW images, achieves the state-of-art performance and outweighs those trained on processed sRGB images. Furthermore, with fine-tuning, the proposed model, trained on our new dataset, can generalize to other sensors. Additionally, by a series of experiments, we demonstrate that existing deblurring models can also be improved by training on the RAW images in our new dataset. Ultimately, we show a new venue for further opportunities based on the devised novel raw-based deblurring method and the brand-new Deblur-RAW dataset.
Balanced-MixUp for Highly Imbalanced Medical Image Classification
Sep 20, 2021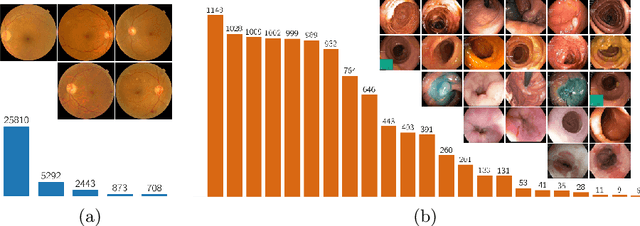
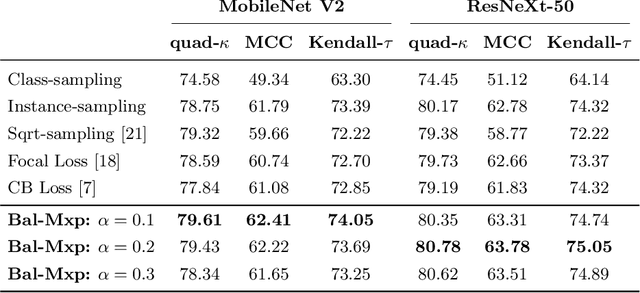

Highly imbalanced datasets are ubiquitous in medical image classification problems. In such problems, it is often the case that rare classes associated to less prevalent diseases are severely under-represented in labeled databases, typically resulting in poor performance of machine learning algorithms due to overfitting in the learning process. In this paper, we propose a novel mechanism for sampling training data based on the popular MixUp regularization technique, which we refer to as Balanced-MixUp. In short, Balanced-MixUp simultaneously performs regular (i.e., instance-based) and balanced (i.e., class-based) sampling of the training data. The resulting two sets of samples are then mixed-up to create a more balanced training distribution from which a neural network can effectively learn without incurring in heavily under-fitting the minority classes. We experiment with a highly imbalanced dataset of retinal images (55K samples, 5 classes) and a long-tail dataset of gastro-intestinal video frames (10K images, 23 classes), using two CNNs of varying representation capabilities. Experimental results demonstrate that applying Balanced-MixUp outperforms other conventional sampling schemes and loss functions specifically designed to deal with imbalanced data. Code is released at https://github.com/agaldran/balanced_mixup .
A Generalized Framework for Edge-preserving and Structure-preserving Image Smoothing
Jul 28, 2021
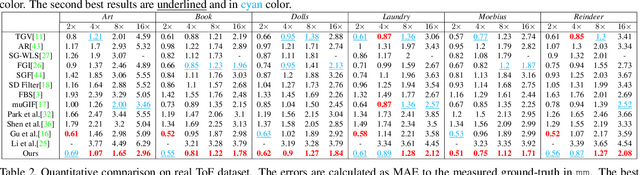
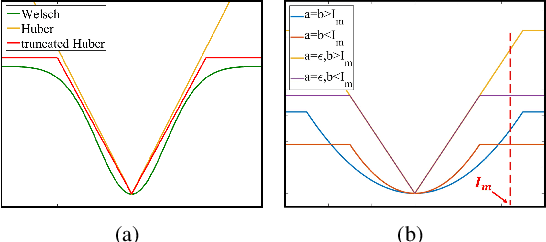

Image smoothing is a fundamental procedure in applications of both computer vision and graphics. The required smoothing properties can be different or even contradictive among different tasks. Nevertheless, the inherent smoothing nature of one smoothing operator is usually fixed and thus cannot meet the various requirements of different applications. In this paper, we first introduce the truncated Huber penalty function which shows strong flexibility under different parameter settings. A generalized framework is then proposed with the introduced truncated Huber penalty function. When combined with its strong flexibility, our framework is able to achieve diverse smoothing natures where contradictive smoothing behaviors can even be achieved. It can also yield the smoothing behavior that can seldom be achieved by previous methods, and superior performance is thus achieved in challenging cases. These together enable our framework capable of a range of applications and able to outperform the state-of-the-art approaches in several tasks, such as image detail enhancement, clip-art compression artifacts removal, guided depth map restoration, image texture removal, etc. In addition, an efficient numerical solution is provided and its convergence is theoretically guaranteed even the optimization framework is non-convex and non-smooth. A simple yet effective approach is further proposed to reduce the computational cost of our method while maintaining its performance. The effectiveness and superior performance of our approach are validated through comprehensive experiments in a range of applications. Our code is available at https://github.com/wliusjtu/Generalized-Smoothing-Framework.
Transductive image segmentation: Self-training and effect of uncertainty estimation
Jul 30, 2021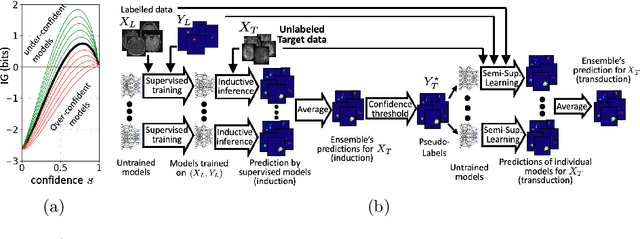

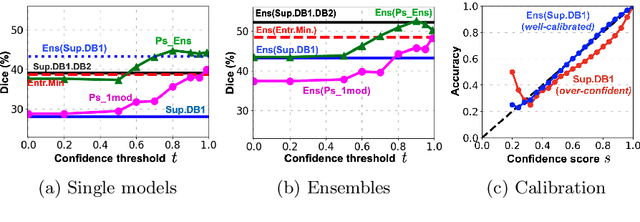
Semi-supervised learning (SSL) uses unlabeled data during training to learn better models. Previous studies on SSL for medical image segmentation focused mostly on improving model generalization to unseen data. In some applications, however, our primary interest is not generalization but to obtain optimal predictions on a specific unlabeled database that is fully available during model development. Examples include population studies for extracting imaging phenotypes. This work investigates an often overlooked aspect of SSL, transduction. It focuses on the quality of predictions made on the unlabeled data of interest when they are included for optimization during training, rather than improving generalization. We focus on the self-training framework and explore its potential for transduction. We analyze it through the lens of Information Gain and reveal that learning benefits from the use of calibrated or under-confident models. Our extensive experiments on a large MRI database for multi-class segmentation of traumatic brain lesions shows promising results when comparing transductive with inductive predictions. We believe this study will inspire further research on transductive learning, a well-suited paradigm for medical image analysis.
Surgical-VQA: Visual Question Answering in Surgical Scenes using Transformer
Jun 26, 2022
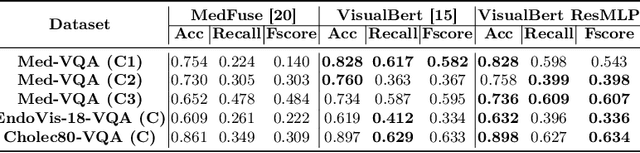
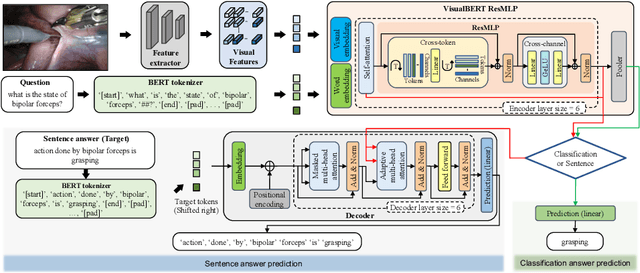
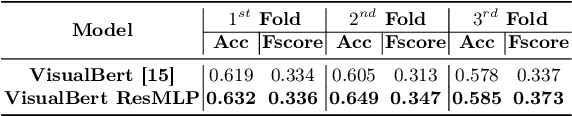
Visual question answering (VQA) in surgery is largely unexplored. Expert surgeons are scarce and are often overloaded with clinical and academic workloads. This overload often limits their time answering questionnaires from patients, medical students or junior residents related to surgical procedures. At times, students and junior residents also refrain from asking too many questions during classes to reduce disruption. While computer-aided simulators and recording of past surgical procedures have been made available for them to observe and improve their skills, they still hugely rely on medical experts to answer their questions. Having a Surgical-VQA system as a reliable 'second opinion' could act as a backup and ease the load on the medical experts in answering these questions. The lack of annotated medical data and the presence of domain-specific terms has limited the exploration of VQA for surgical procedures. In this work, we design a Surgical-VQA task that answers questionnaires on surgical procedures based on the surgical scene. Extending the MICCAI endoscopic vision challenge 2018 dataset and workflow recognition dataset further, we introduce two Surgical-VQA datasets with classification and sentence-based answers. To perform Surgical-VQA, we employ vision-text transformers models. We further introduce a residual MLP-based VisualBert encoder model that enforces interaction between visual and text tokens, improving performance in classification-based answering. Furthermore, we study the influence of the number of input image patches and temporal visual features on the model performance in both classification and sentence-based answering.
Multi-scale Self-calibrated Network for Image Light Source Transfer
Apr 18, 2021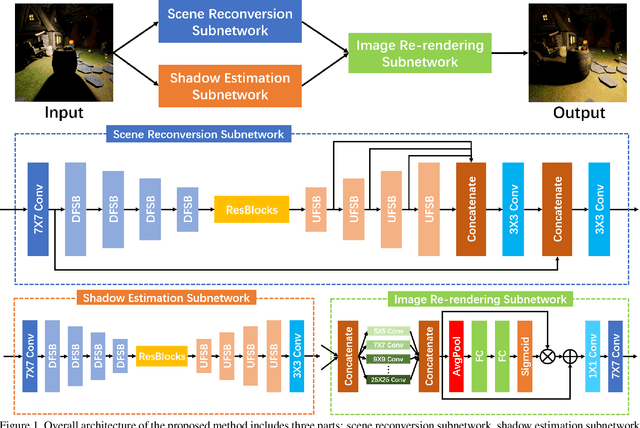
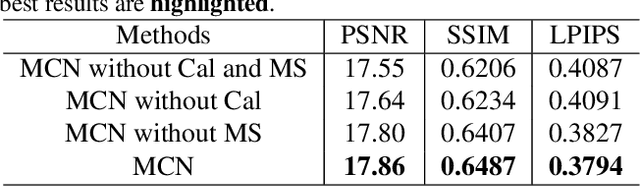
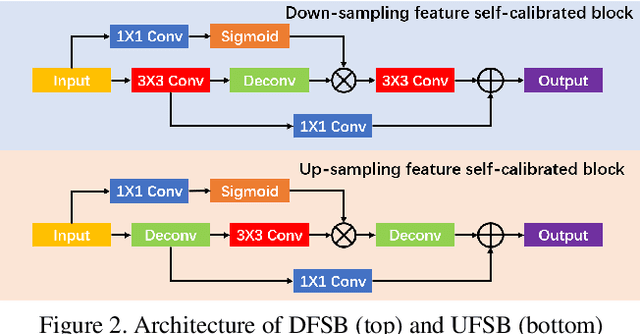
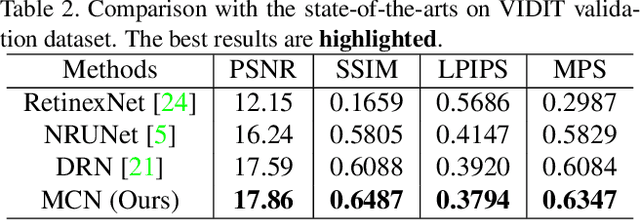
Image light source transfer (LLST), as the most challenging task in the domain of image relighting, has attracted extensive attention in recent years. In the latest research, LLST is decomposed three sub-tasks: scene reconversion, shadow estimation, and image re-rendering, which provides a new paradigm for image relighting. However, many problems for scene reconversion and shadow estimation tasks, including uncalibrated feature information and poor semantic information, are still unresolved, thereby resulting in insufficient feature representation. In this paper, we propose novel down-sampling feature self-calibrated block (DFSB) and up-sampling feature self-calibrated block (UFSB) as the basic blocks of feature encoder and decoder to calibrate feature representation iteratively because the LLST is similar to the recalibration of image light source. In addition, we fuse the multi-scale features of the decoder in scene reconversion task to further explore and exploit more semantic information, thereby providing more accurate primary scene structure for image re-rendering. Experimental results in the VIDIT dataset show that the proposed approach significantly improves the performance for LLST.
Task-Oriented Low-Dose CT Image Denoising
Mar 25, 2021



The extensive use of medical CT has raised a public concern over the radiation dose to the patient. Reducing the radiation dose leads to increased CT image noise and artifacts, which can adversely affect not only the radiologists judgement but also the performance of downstream medical image analysis tasks. Various low-dose CT denoising methods, especially the recent deep learning based approaches, have produced impressive results. However, the existing denoising methods are all downstream-task-agnostic and neglect the diverse needs of the downstream applications. In this paper, we introduce a novel Task-Oriented Denoising Network (TOD-Net) with a task-oriented loss leveraging knowledge from the downstream tasks. Comprehensive empirical analysis shows that the task-oriented loss complements other task agnostic losses by steering the denoiser to enhance the image quality in the task related regions of interest. Such enhancement in turn brings general boosts on the performance of various methods for the downstream task. The presented work may shed light on the future development of context-aware image denoising methods.