 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Algorithms for TRISO Fuel Identification Based on X-ray CT Validated on Tungsten-Carbide Compacts
Apr 28, 2022
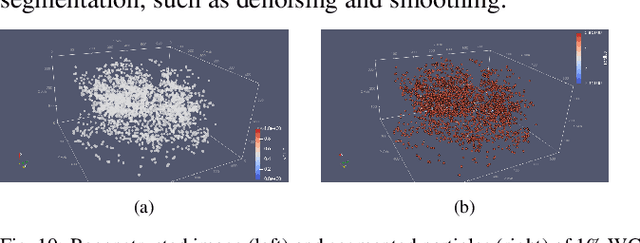
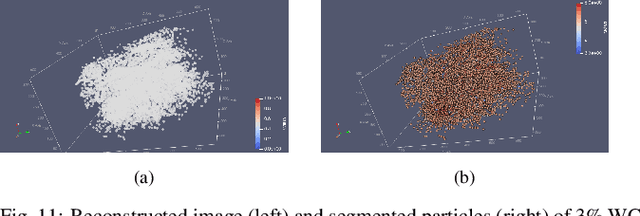

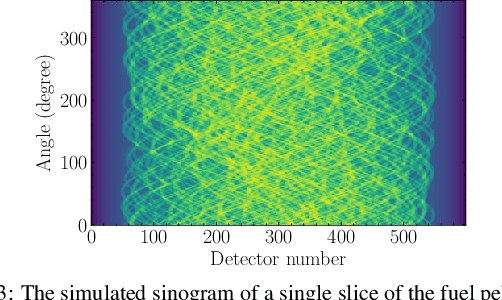
Tristructural-isotropic (TRISO) fuel is one of the most mature fuel types for candidate advanced reactor types under development. TRISO-fuel pebbles flow continuously through the reactor core and can be reinserted into the reactor several times until a target burnup is reached. The capability of identifying individual fuel pebbles would allow us to calculate the fuel residence time in the core and validate pebble flow computational models, prevent excessive burnup accumulation or premature fuel discharge, and maintain accountability of special nuclear materials during fuel circulation. In this work, we have developed a 3D image reconstruction and segmentation algorithm to accurately segment TRISO particles and extract the unique 3D distribution. We have developed a rotation-invariant and noise-robust identification algorithm that allows us to identify the pebble and retrieve the pebble ID in the presence of rotations and noises. We also report the results of 200kV X-ray CT image reconstruction of a mock-up fuel sample consisting of tungsten-carbide (WC) kernels in a lucite matrix. The 3D distribution of TRISO particles along with other signatures such as $^{235}$U enrichment and burnup level extracted through neutron multiplicity counting, would enable accurate fuel identification in a reasonable amount of time.
SG2Caps: Revisiting Scene Graphs for Image Captioning
Feb 09, 2021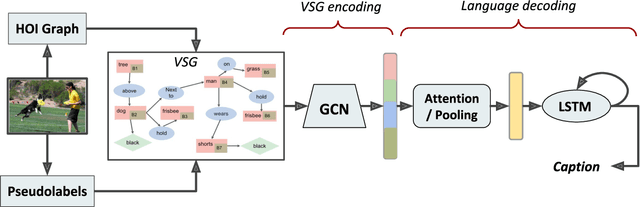
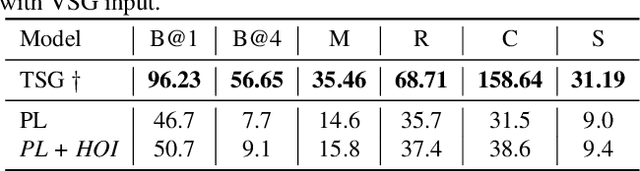
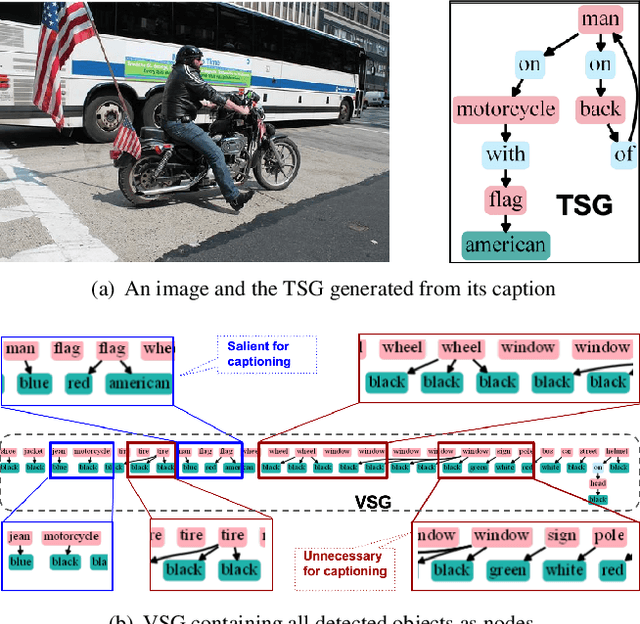
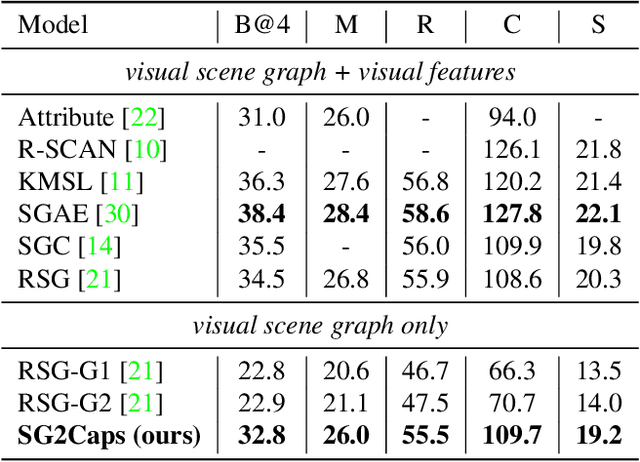
The mainstream image captioning models rely on Convolutional Neural Network (CNN) image features with an additional attention to salient regions and objects to generate captions via recurrent models. Recently, scene graph representations of images have been used to augment captioning models so as to leverage their structural semantics, such as object entities, relationships and attributes. Several studies have noted that naive use of scene graphs from a black-box scene graph generator harms image caption-ing performance, and scene graph-based captioning mod-els have to incur the overhead of explicit use of image features to generate decent captions. Addressing these challenges, we propose a framework, SG2Caps, that utilizes only the scene graph labels for competitive image caption-ing performance. The basic idea is to close the semantic gap between two scene graphs - one derived from the input image and the other one from its caption. In order to achieve this, we leverage the spatial location of objects and the Human-Object-Interaction (HOI) labels as an additional HOI graph. Our framework outperforms existing scene graph-only captioning models by a large margin (CIDEr score of 110 vs 71) indicating scene graphs as a promising representation for image captioning. Direct utilization of the scene graph labels avoids expensive graph convolutions over high-dimensional CNN features resulting in 49%fewer trainable parameters.
Flow-based Deformation Guidance for Unpaired Multi-Contrast MRI Image-to-Image Translation
Dec 03, 2020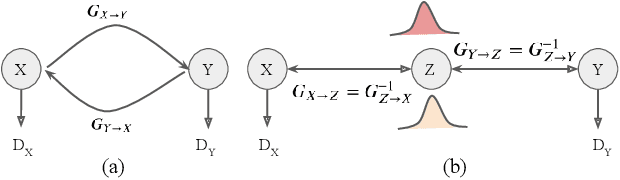
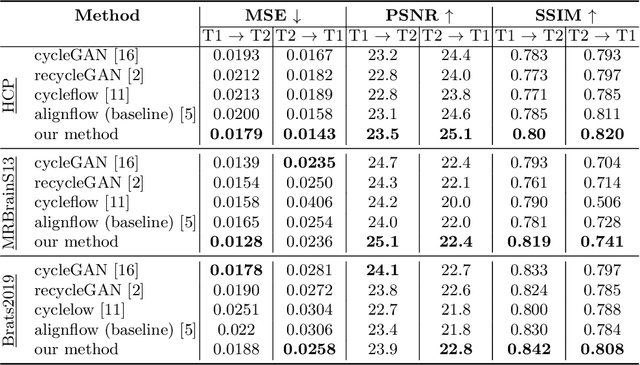
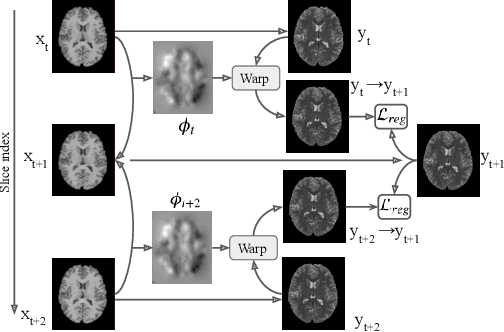
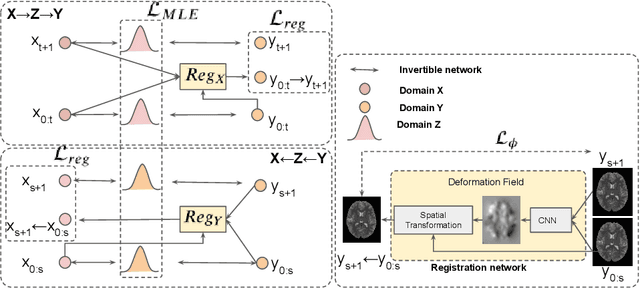
Image synthesis from corrupted contrasts increases the diversity of diagnostic information available for many neurological diseases. Recently the image-to-image translation has experienced significant levels of interest within medical research, beginning with the successful use of the Generative Adversarial Network (GAN) to the introduction of cyclic constraint extended to multiple domains. However, in current approaches, there is no guarantee that the mapping between the two image domains would be unique or one-to-one. In this paper, we introduce a novel approach to unpaired image-to-image translation based on the invertible architecture. The invertible property of the flow-based architecture assures a cycle-consistency of image-to-image translation without additional loss functions. We utilize the temporal information between consecutive slices to provide more constraints to the optimization for transforming one domain to another in unpaired volumetric medical images. To capture temporal structures in the medical images, we explore the displacement between the consecutive slices using a deformation field. In our approach, the deformation field is used as a guidance to keep the translated slides realistic and consistent across the translation. The experimental results have shown that the synthesized images using our proposed approach are able to archive a competitive performance in terms of mean squared error, peak signal-to-noise ratio, and structural similarity index when compared with the existing deep learning-based methods on three standard datasets, i.e. HCP, MRBrainS13, and Brats2019.
On Outer Bi-Lipschitz Extensions of Linear Johnson-Lindenstrauss Embeddings of Low-Dimensional Submanifolds of $\mathbb{R}^N$
Jun 07, 2022
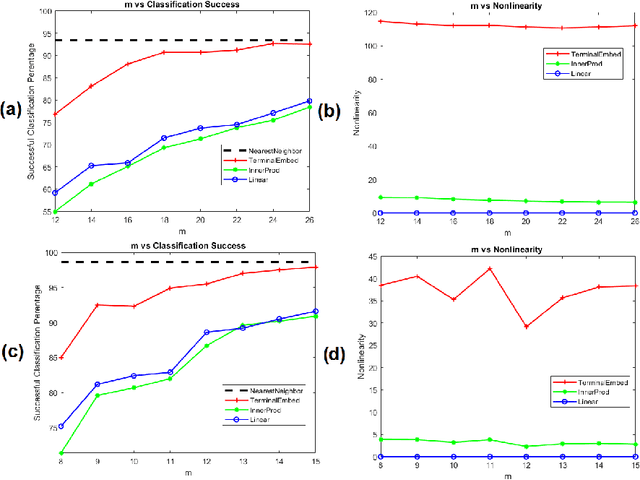
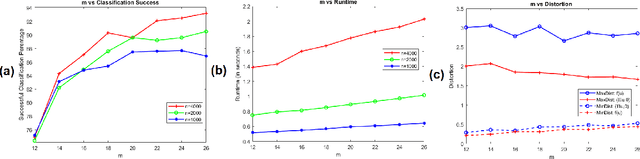
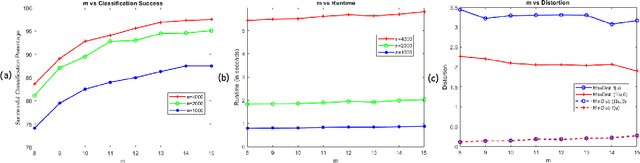
Let $\mathcal{M}$ be a compact $d$-dimensional submanifold of $\mathbb{R}^N$ with reach $\tau$ and volume $V_{\mathcal M}$. Fix $\epsilon \in (0,1)$. In this paper we prove that a nonlinear function $f: \mathbb{R}^N \rightarrow \mathbb{R}^{m}$ exists with $m \leq C \left(d / \epsilon^2 \right) \log \left(\frac{\sqrt[d]{V_{\mathcal M}}}{\tau} \right)$ such that $$(1 - \epsilon) \| {\bf x} - {\bf y} \|_2 \leq \left\| f({\bf x}) - f({\bf y}) \right\|_2 \leq (1 + \epsilon) \| {\bf x} - {\bf y} \|_2$$ holds for all ${\bf x} \in \mathcal{M}$ and ${\bf y} \in \mathbb{R}^N$. In effect, $f$ not only serves as a bi-Lipschitz function from $\mathcal{M}$ into $\mathbb{R}^{m}$ with bi-Lipschitz constants close to one, but also approximately preserves all distances from points not in $\mathcal{M}$ to all points in $\mathcal{M}$ in its image. Furthermore, the proof is constructive and yields an algorithm which works well in practice. In particular, it is empirically demonstrated herein that such nonlinear functions allow for more accurate compressive nearest neighbor classification than standard linear Johnson-Lindenstrauss embeddings do in practice.
Direction-aware Feature-level Frequency Decomposition for Single Image Deraining
Jun 15, 2021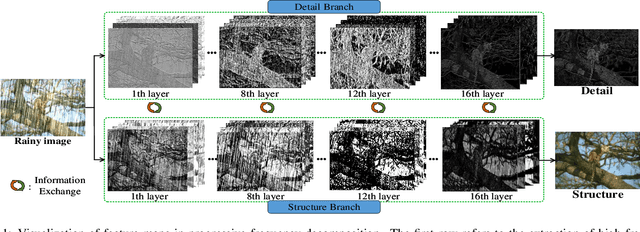

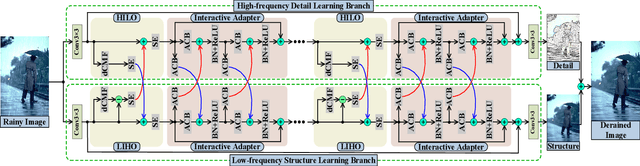
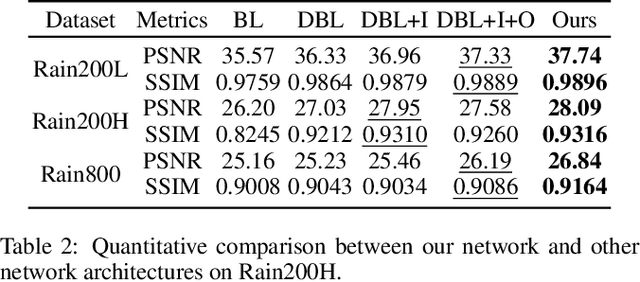
We present a novel direction-aware feature-level frequency decomposition network for single image deraining. Compared with existing solutions, the proposed network has three compelling characteristics. First, unlike previous algorithms, we propose to perform frequency decomposition at feature-level instead of image-level, allowing both low-frequency maps containing structures and high-frequency maps containing details to be continuously refined during the training procedure. Second, we further establish communication channels between low-frequency maps and high-frequency maps to interactively capture structures from high-frequency maps and add them back to low-frequency maps and, simultaneously, extract details from low-frequency maps and send them back to high-frequency maps, thereby removing rain streaks while preserving more delicate features in the input image. Third, different from existing algorithms using convolutional filters consistent in all directions, we propose a direction-aware filter to capture the direction of rain streaks in order to more effectively and thoroughly purge the input images of rain streaks. We extensively evaluate the proposed approach in three representative datasets and experimental results corroborate our approach consistently outperforms state-of-the-art deraining algorithms.
Joint Manifold Learning and Density Estimation Using Normalizing Flows
Jun 07, 2022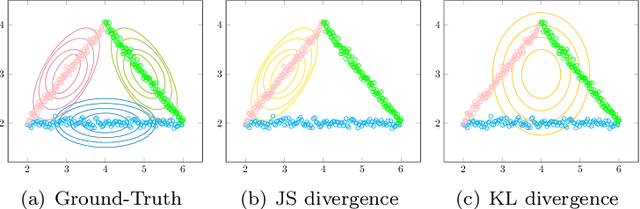
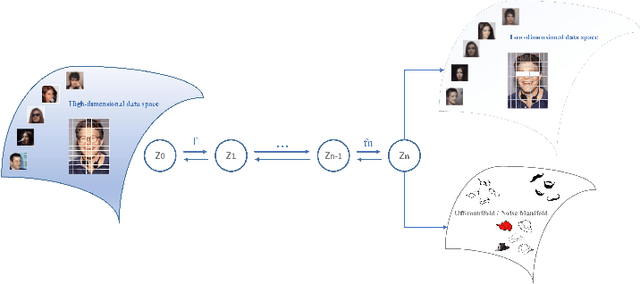

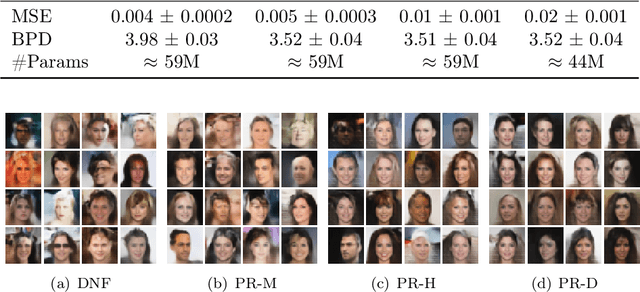
Based on the manifold hypothesis, real-world data often lie on a low-dimensional manifold, while normalizing flows as a likelihood-based generative model are incapable of finding this manifold due to their structural constraints. So, one interesting question arises: $\textit{"Can we find sub-manifold(s) of data in normalizing flows and estimate the density of the data on the sub-manifold(s)?"}$. In this paper, we introduce two approaches, namely per-pixel penalized log-likelihood and hierarchical training, to answer the mentioned question. We propose a single-step method for joint manifold learning and density estimation by disentangling the transformed space obtained by normalizing flows to manifold and off-manifold parts. This is done by a per-pixel penalized likelihood function for learning a sub-manifold of the data. Normalizing flows assume the transformed data is Gaussianizationed, but this imposed assumption is not necessarily true, especially in high dimensions. To tackle this problem, a hierarchical training approach is employed to improve the density estimation on the sub-manifold. The results validate the superiority of the proposed methods in simultaneous manifold learning and density estimation using normalizing flows in terms of generated image quality and likelihood.
Federated Multi-organ Segmentation with Partially Labeled Data
Jun 14, 2022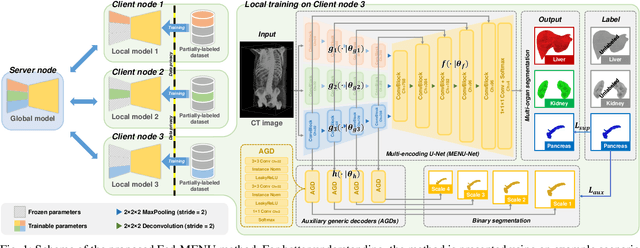
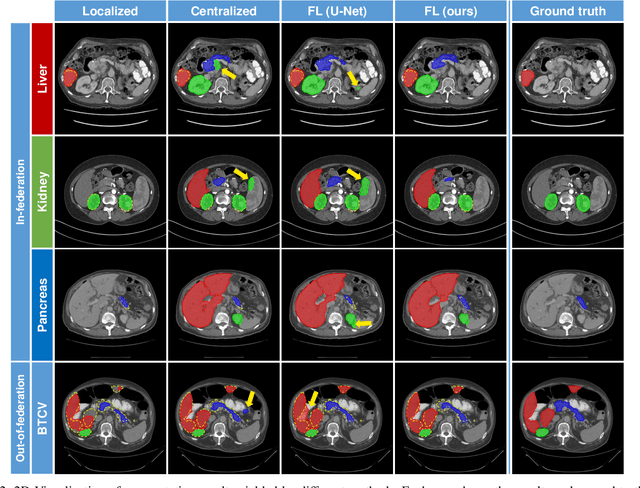
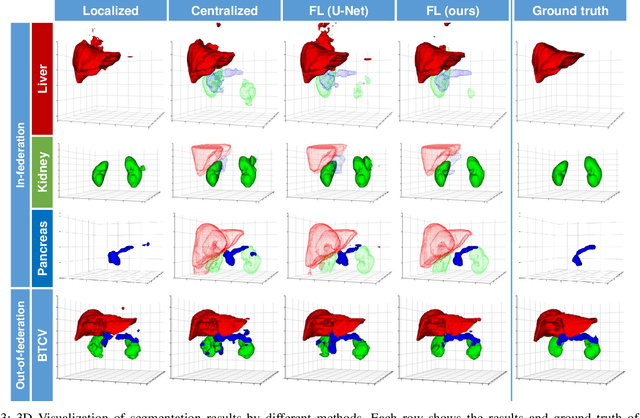
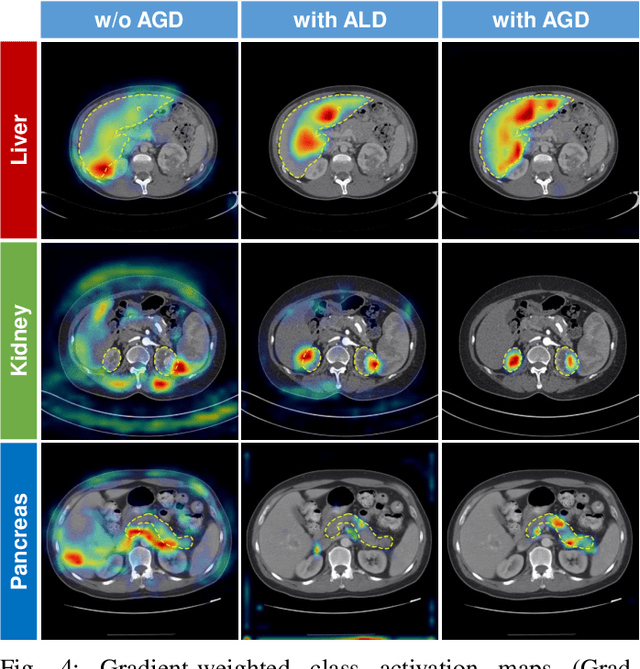
Federated learning is an emerging paradigm allowing large-scale decentralized learning without sharing data across different data owners, which helps address the concern of data privacy in medical image analysis. However, the requirement for label consistency across clients by the existing methods largely narrows its application scope. In practice, each clinical site may only annotate certain organs of interest with partial or no overlap with other sites. Incorporating such partially labeled data into a unified federation is an unexplored problem with clinical significance and urgency. This work tackles the challenge by using a novel federated multi-encoding U-Net (Fed-MENU) method for multi-organ segmentation. In our method, a multi-encoding U-Net (MENU-Net) is proposed to extract organ-specific features through different encoding sub-networks. Each sub-network can be seen as an expert of a specific organ and trained for that client. Moreover, to encourage the organ-specific features extracted by different sub-networks to be informative and distinctive, we regularize the training of the MENU-Net by designing an auxiliary generic decoder (AGD). Extensive experiments on four public datasets show that our Fed-MENU method can effectively obtain a federated learning model using the partially labeled datasets with superior performance to other models trained by either localized or centralized learning methods. Source code will be made publicly available at the time of paper publication.
ProCST: Boosting Semantic Segmentation using Progressive Cyclic Style-Transfer
Apr 25, 2022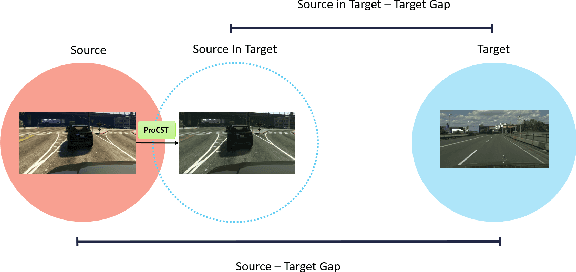
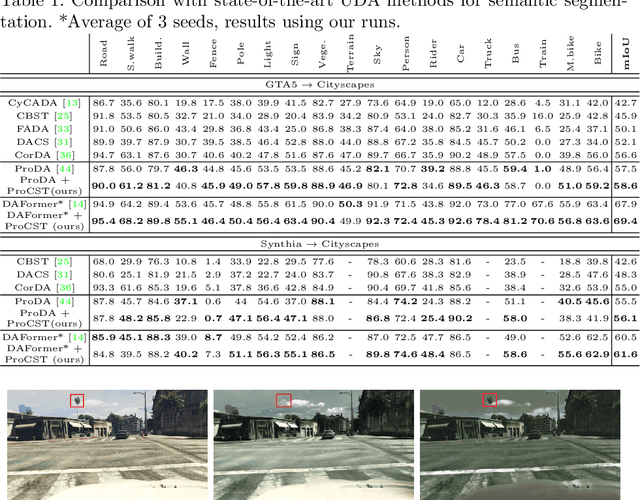
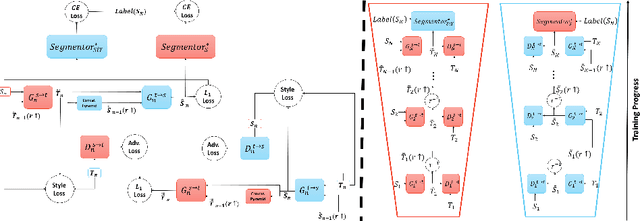

Using synthetic data for training neural networks that achieve good performance on real-world data is an important task as it has the potential to reduce the need for costly data annotation. Yet, a network that is trained on synthetic data alone does not perform well on real data due to the domain gap between the two. Reducing this gap, also known as domain adaptation, has been widely studied in recent years. In the unsupervised domain adaptation (UDA) framework, unlabeled real data is used during training with labeled synthetic data to obtain a neural network that performs well on real data. In this work, we focus on image data. For the semantic segmentation task, it has been shown that performing image-to-image translation from source to target, and then training a network for segmentation on source annotations - leads to poor results. Therefore a joint training of both is essential, which has been a common practice in many techniques. Yet, closing the large domain gap between the source and the target by directly performing the adaptation between the two is challenging. In this work, we propose a novel two-stage framework for improving domain adaptation techniques. In the first step, we progressively train a multi-scale neural network to perform an initial transfer between the source data to the target data. We denote the new transformed data as "Source in Target" (SiT). Then, we use the generated SiT data as the input to any standard UDA approach. This new data has a reduced domain gap from the desired target domain, and the applied UDA approach further closes the gap. We demonstrate the improvement achieved by our framework with two state-of-the-art methods for semantic segmentation, DAFormer and ProDA, on two UDA tasks, GTA5 to Cityscapes and Synthia to Cityscapes. Code and state-of-the-art checkpoints of ProCST+DAFormer are provided.
A Mixed-Supervision Multilevel GAN Framework for Image Quality Enhancement
Jun 29, 2021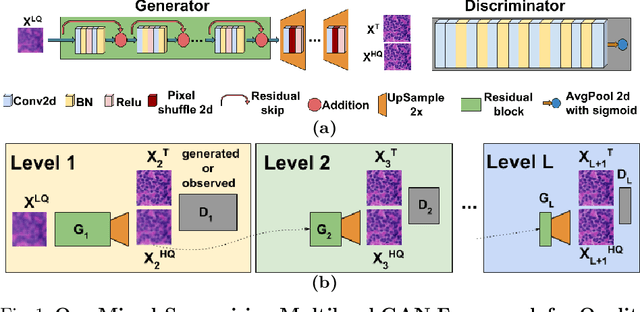
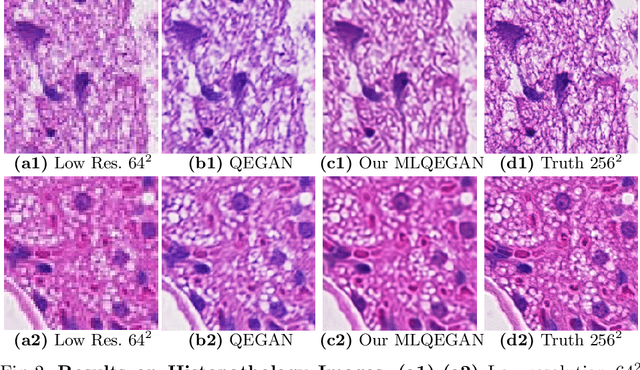
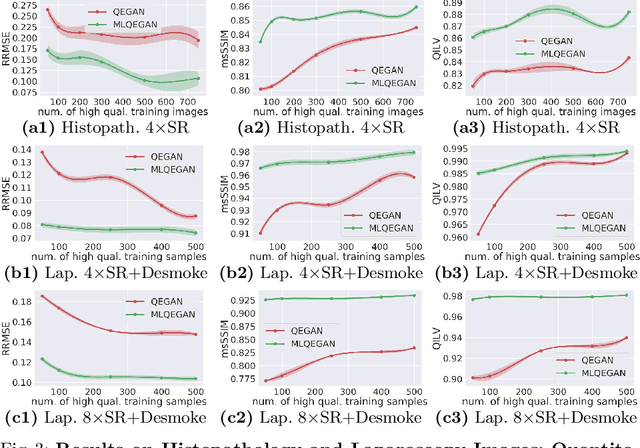
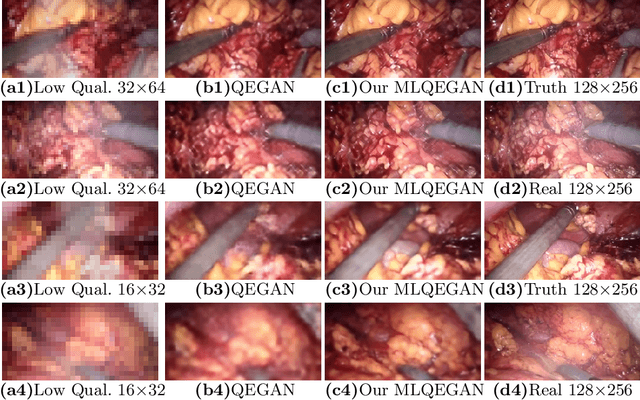
Deep neural networks for image quality enhancement typically need large quantities of highly-curated training data comprising pairs of low-quality images and their corresponding high-quality images. While high-quality image acquisition is typically expensive and time-consuming, medium-quality images are faster to acquire, at lower equipment costs, and available in larger quantities. Thus, we propose a novel generative adversarial network (GAN) that can leverage training data at multiple levels of quality (e.g., high and medium quality) to improve performance while limiting costs of data curation. We apply our mixed-supervision GAN to (i) super-resolve histopathology images and (ii) enhance laparoscopy images by combining super-resolution and surgical smoke removal. Results on large clinical and pre-clinical datasets show the benefits of our mixed-supervision GAN over the state of the art.
Effect of Parameter Optimization on Classical and Learning-based Image Matching Methods
Aug 28, 2021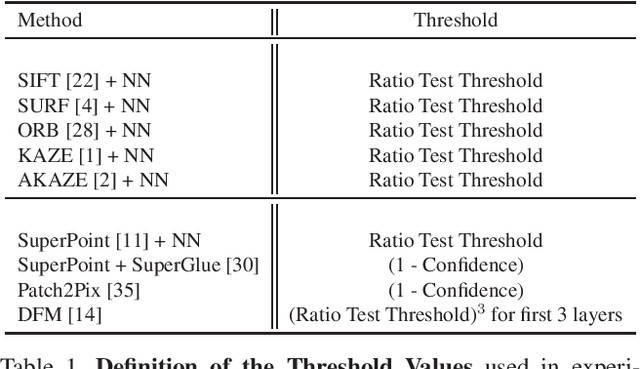
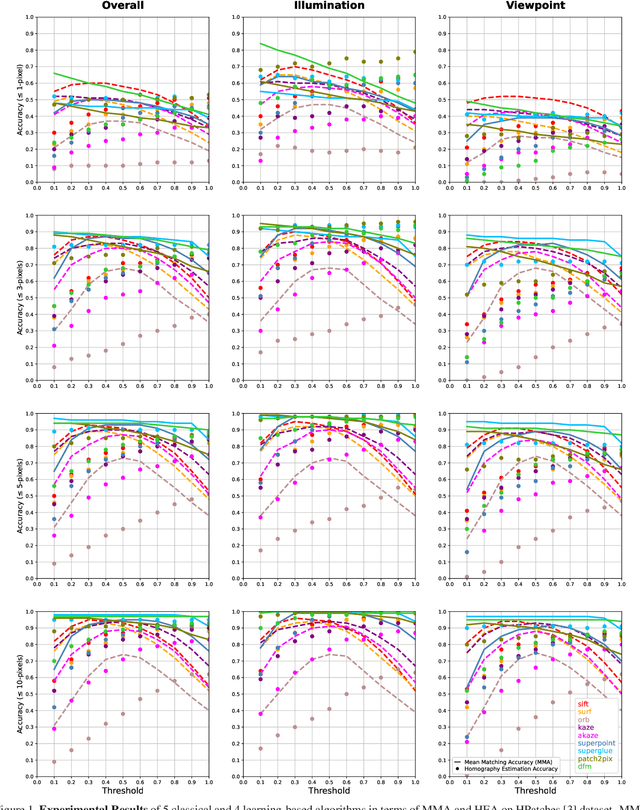
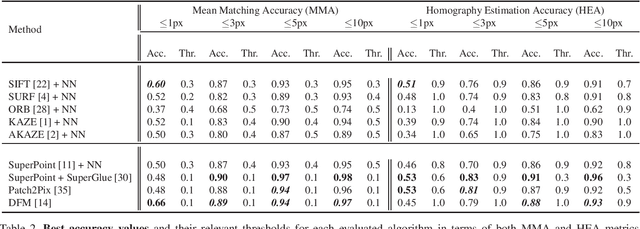
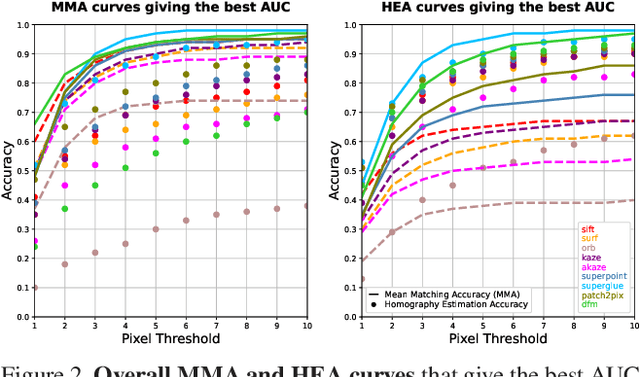
Deep learning-based image matching methods are improved significantly during the recent years. Although these methods are reported to outperform the classical techniques, the performance of the classical methods is not examined in detail. In this study, we compare classical and learning-based methods by employing mutual nearest neighbor search with ratio test and optimizing the ratio test threshold to achieve the best performance on two different performance metrics. After a fair comparison, the experimental results on HPatches dataset reveal that the performance gap between classical and learning-based methods is not that significant. Throughout the experiments, we demonstrated that SuperGlue is the state-of-the-art technique for the image matching problem on HPatches dataset. However, if a single parameter, namely ratio test threshold, is carefully optimized, a well-known traditional method SIFT performs quite close to SuperGlue and even outperforms in terms of mean matching accuracy (MMA) under 1 and 2 pixel thresholds. Moreover, a recent approach, DFM, which only uses pre-trained VGG features as descriptors and ratio test, is shown to outperform most of the well-trained learning-based methods. Therefore, we conclude that the parameters of any classical method should be analyzed carefully before comparing against a learning-based technique.