 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Efficient Calculation of Quaternion Correlation of Signals and Color Images
May 10, 2022



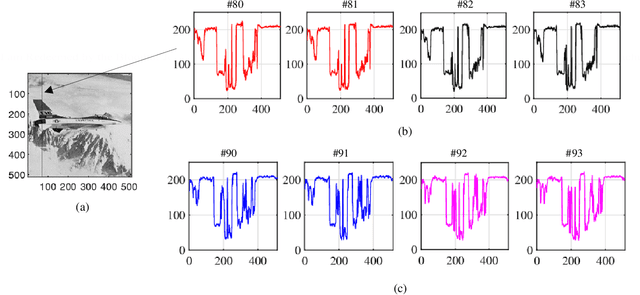
Over the past century, a correlation has been an essential mathematical technique utilized in engineering sciences, including practically every signal/image processing field. This paper describes an effective method of calculating the correlation function of signals and color images in quaternion algebra. We propose using the quaternions with a commutative multiplication operation and defining the corresponding correlation function in this arithmetic. The correlation between quaternion signals and images can be calculated by multiplying two quaternion DFTs of signals and images. The complexity of the correlation of color images is three times higher than in complex algebra.
CP2: Copy-Paste Contrastive Pretraining for Semantic Segmentation
Mar 22, 2022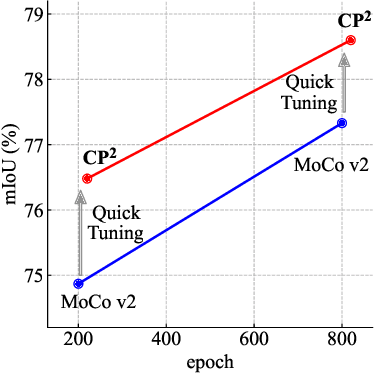
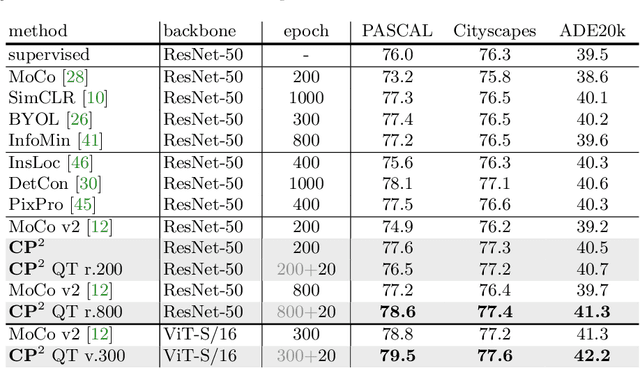
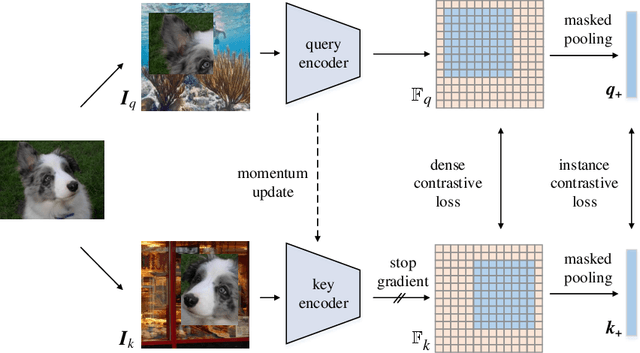
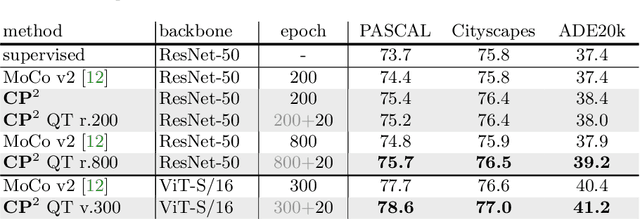
Recent advances in self-supervised contrastive learning yield good image-level representation, which favors classification tasks but usually neglects pixel-level detailed information, leading to unsatisfactory transfer performance to dense prediction tasks such as semantic segmentation. In this work, we propose a pixel-wise contrastive learning method called CP2 (Copy-Paste Contrastive Pretraining), which facilitates both image- and pixel-level representation learning and therefore is more suitable for downstream dense prediction tasks. In detail, we copy-paste a random crop from an image (the foreground) onto different background images and pretrain a semantic segmentation model with the objective of 1) distinguishing the foreground pixels from the background pixels, and 2) identifying the composed images that share the same foreground.Experiments show the strong performance of CP2 in downstream semantic segmentation: By finetuning CP2 pretrained models on PASCAL VOC 2012, we obtain 78.6% mIoU with a ResNet-50 and 79.5% with a ViT-S.
Transformer Decoders with MultiModal Regularization for Cross-Modal Food Retrieval
Apr 20, 2022



Cross-modal image-recipe retrieval has gained significant attention in recent years. Most work focuses on improving cross-modal embeddings using unimodal encoders, that allow for efficient retrieval in large-scale databases, leaving aside cross-attention between modalities which is more computationally expensive. We propose a new retrieval framework, T-Food (Transformer Decoders with MultiModal Regularization for Cross-Modal Food Retrieval) that exploits the interaction between modalities in a novel regularization scheme, while using only unimodal encoders at test time for efficient retrieval. We also capture the intra-dependencies between recipe entities with a dedicated recipe encoder, and propose new variants of triplet losses with dynamic margins that adapt to the difficulty of the task. Finally, we leverage the power of the recent Vision and Language Pretraining (VLP) models such as CLIP for the image encoder. Our approach outperforms existing approaches by a large margin on the Recipe1M dataset. Specifically, we achieve absolute improvements of 8.1 % (72.6 R@1) and +10.9 % (44.6 R@1) on the 1k and 10k test sets respectively. The code is available here:https://github.com/mshukor/TFood
COLA-Net: Collaborative Attention Network for Image Restoration
Mar 10, 2021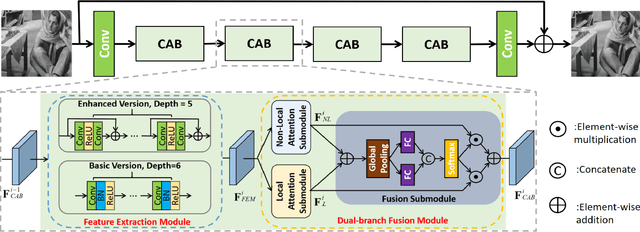

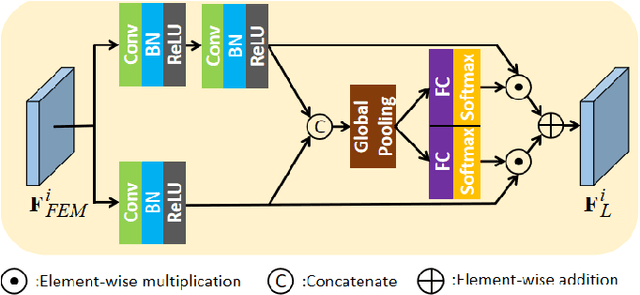

Local and non-local attention-based methods have been well studied in various image restoration tasks while leading to promising performance. However, most of the existing methods solely focus on one type of attention mechanism (local or non-local). Furthermore, by exploiting the self-similarity of natural images, existing pixel-wise non-local attention operations tend to give rise to deviations in the process of characterizing long-range dependence due to image degeneration. To overcome these problems, in this paper we propose a novel collaborative attention network (COLA-Net) for image restoration, as the first attempt to combine local and non-local attention mechanisms to restore image content in the areas with complex textures and with highly repetitive details respectively. In addition, an effective and robust patch-wise non-local attention model is developed to capture long-range feature correspondences through 3D patches. Extensive experiments on synthetic image denoising, real image denoising and compression artifact reduction tasks demonstrate that our proposed COLA-Net is able to achieve state-of-the-art performance in both peak signal-to-noise ratio and visual perception, while maintaining an attractive computational complexity. The source code is available on https://github.com/MC-E/COLA-Net.
Large Loss Matters in Weakly Supervised Multi-Label Classification
Jun 08, 2022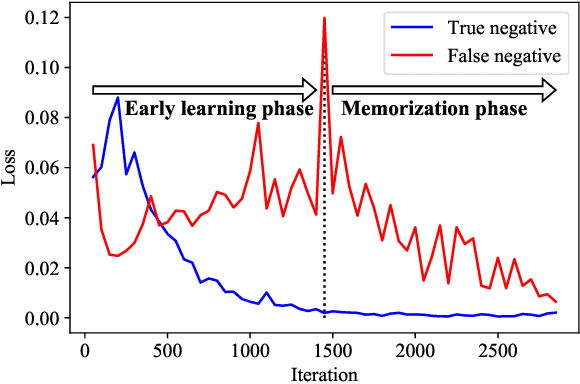

Weakly supervised multi-label classification (WSML) task, which is to learn a multi-label classification using partially observed labels per image, is becoming increasingly important due to its huge annotation cost. In this work, we first regard unobserved labels as negative labels, casting the WSML task into noisy multi-label classification. From this point of view, we empirically observe that memorization effect, which was first discovered in a noisy multi-class setting, also occurs in a multi-label setting. That is, the model first learns the representation of clean labels, and then starts memorizing noisy labels. Based on this finding, we propose novel methods for WSML which reject or correct the large loss samples to prevent model from memorizing the noisy label. Without heavy and complex components, our proposed methods outperform previous state-of-the-art WSML methods on several partial label settings including Pascal VOC 2012, MS COCO, NUSWIDE, CUB, and OpenImages V3 datasets. Various analysis also show that our methodology actually works well, validating that treating large loss properly matters in a weakly supervised multi-label classification. Our code is available at https://github.com/snucml/LargeLossMatters.
Disentangled Ontology Embedding for Zero-shot Learning
Jun 08, 2022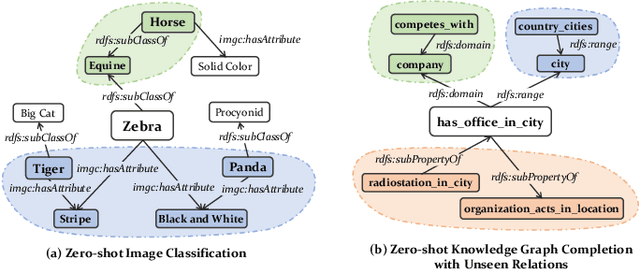
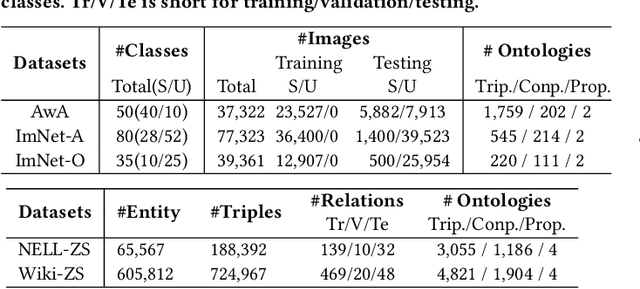
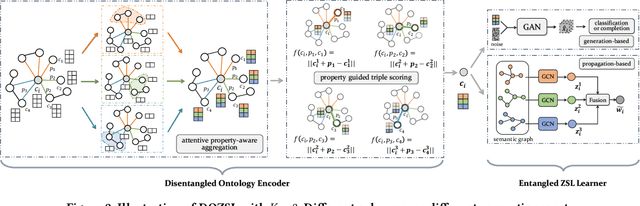
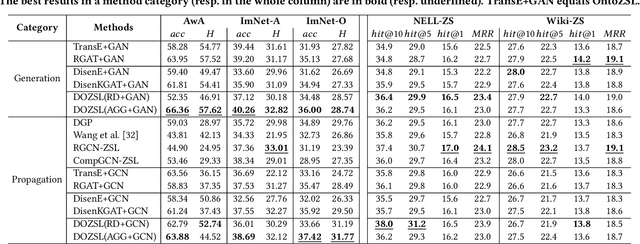
Knowledge Graph (KG) and its variant of ontology have been widely used for knowledge representation, and have shown to be quite effective in augmenting Zero-shot Learning (ZSL). However, existing ZSL methods that utilize KGs all neglect the intrinsic complexity of inter-class relationships represented in KGs. One typical feature is that a class is often related to other classes in different semantic aspects. In this paper, we focus on ontologies for augmenting ZSL, and propose to learn disentangled ontology embeddings guided by ontology properties to capture and utilize more fine-grained class relationships in different aspects. We also contribute a new ZSL framework named DOZSL, which contains two new ZSL solutions based on generative models and graph propagation models, respectively, for effectively utilizing the disentangled ontology embeddings. Extensive evaluations have been conducted on five benchmarks across zero-shot image classification (ZS-IMGC) and zero-shot KG completion (ZS-KGC). DOZSL often achieves better performance than the state-of-the-art, and its components have been verified by ablation studies and case studies. Our codes and datasets are available at https://github.com/zjukg/DOZSL.
Improving Diversity with Adversarially Learned Transformations for Domain Generalization
Jun 15, 2022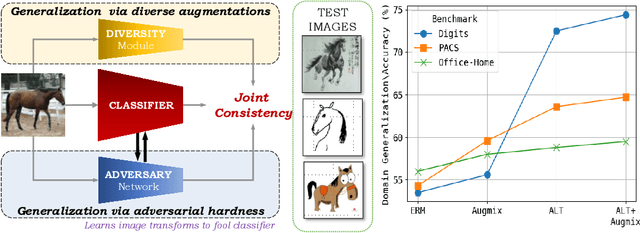
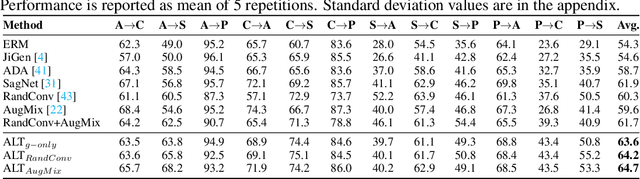
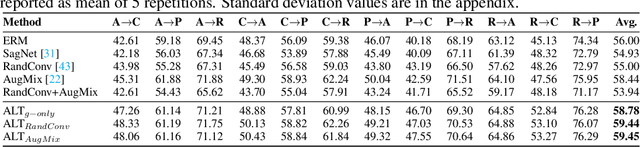
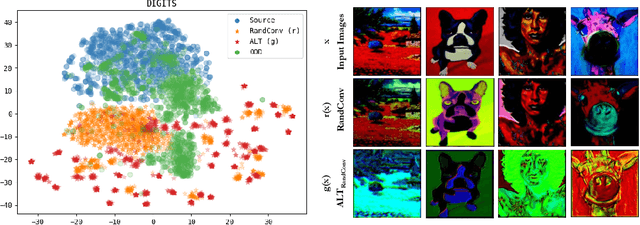
To be successful in single source domain generalization, maximizing diversity of synthesized domains has emerged as one of the most effective strategies. Many of the recent successes have come from methods that pre-specify the types of diversity that a model is exposed to during training, so that it can ultimately generalize well to new domains. However, na\"ive diversity based augmentations do not work effectively for domain generalization either because they cannot model large domain shift, or because the span of transforms that are pre-specified do not cover the types of shift commonly occurring in domain generalization. To address this issue, we present a novel framework that uses adversarially learned transformations (ALT) using a neural network to model plausible, yet hard image transformations that fool the classifier. This network is randomly initialized for each batch and trained for a fixed number of steps to maximize classification error. Further, we enforce consistency between the classifier's predictions on the clean and transformed images. With extensive empirical analysis, we find that this new form of adversarial transformations achieve both objectives of diversity and hardness simultaneously, outperforming all existing techniques on competitive benchmarks for single source domain generalization. We also show that ALT can naturally work with existing diversity modules to produce highly distinct, and large transformations of the source domain leading to state-of-the-art performance.
Multimodal Multi-Head Convolutional Attention with Various Kernel Sizes for Medical Image Super-Resolution
Apr 12, 2022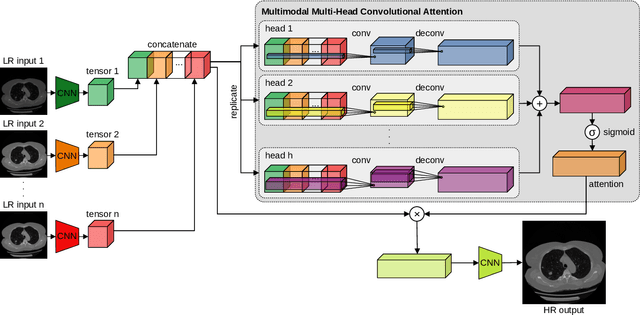
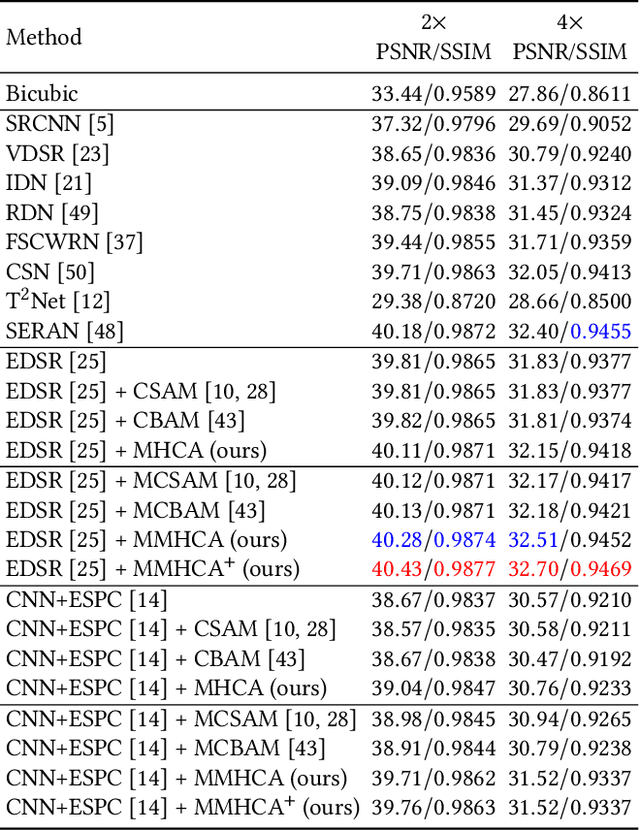
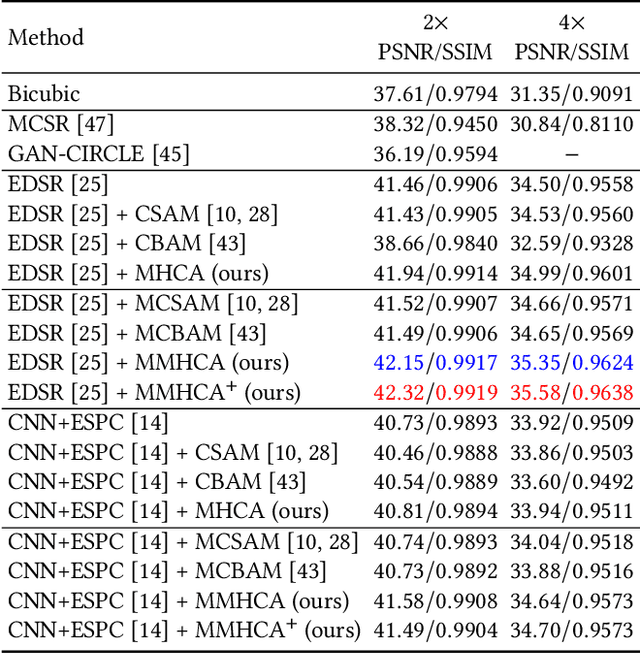
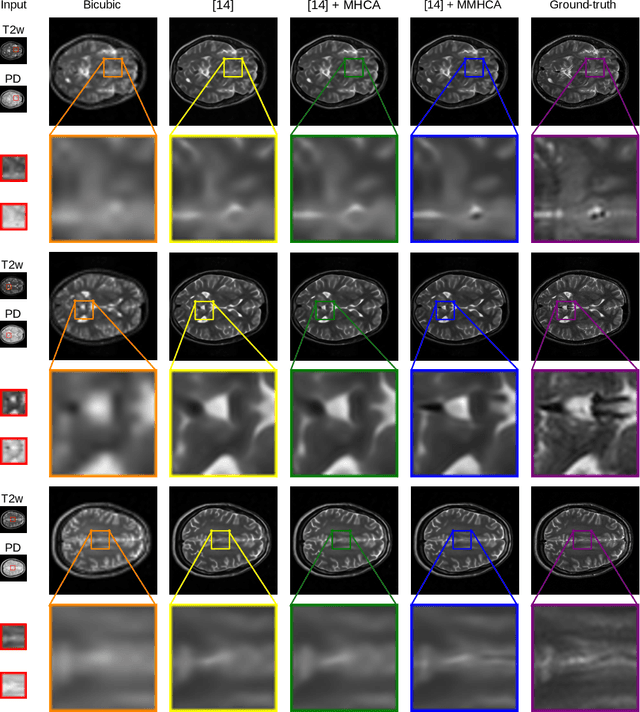
Super-resolving medical images can help physicians in providing more accurate diagnostics. In many situations, computed tomography (CT) or magnetic resonance imaging (MRI) techniques output several scans (modes) during a single investigation, which can jointly be used (in a multimodal fashion) to further boost the quality of super-resolution results. To this end, we propose a novel multimodal multi-head convolutional attention module to super-resolve CT and MRI scans. Our attention module uses the convolution operation to perform joint spatial-channel attention on multiple concatenated input tensors, where the kernel (receptive field) size controls the reduction rate of the spatial attention and the number of convolutional filters controls the reduction rate of the channel attention, respectively. We introduce multiple attention heads, each head having a distinct receptive field size corresponding to a particular reduction rate for the spatial attention. We integrate our multimodal multi-head convolutional attention (MMHCA) into two deep neural architectures for super-resolution and conduct experiments on three data sets. Our empirical results show the superiority of our attention module over the state-of-the-art attention mechanisms used in super-resolution. Moreover, we conduct an ablation study to assess the impact of the components involved in our attention module, e.g. the number of inputs or the number of heads.
OpenICS: Open Image Compressive Sensing Toolbox and Benchmark
Mar 04, 2021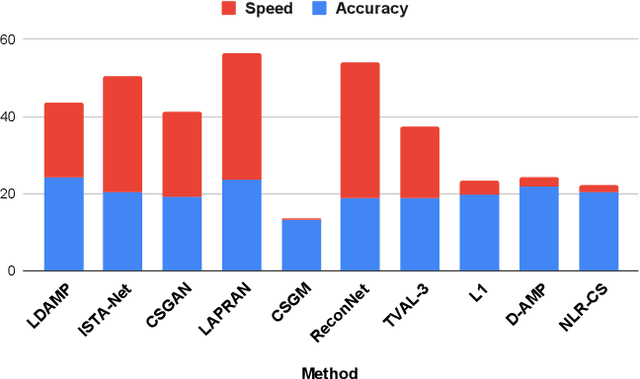

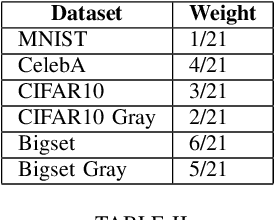

We present OpenICS, an image compressive sensing toolbox that includes multiple image compressive sensing and reconstruction algorithms proposed in the past decade. Due to the lack of standardization in the implementation and evaluation of the proposed algorithms, the application of image compressive sensing in the real-world is limited. We believe this toolbox is the first framework that provides a unified and standardized implementation of multiple image compressive sensing algorithms. In addition, we also conduct a benchmarking study on the methods included in this framework from two aspects: reconstruction accuracy and reconstruction efficiency. We wish this toolbox and benchmark can serve the growing research community of compressive sensing and the industry applying image compressive sensing to new problems as well as developing new methods more efficiently. Code and models are available at https://github.com/PSCLab-ASU/OpenICS. The project is still under maintenance, and we will keep this document updated.
Survey of Visual-Semantic Embedding Methods for Zero-Shot Image Retrieval
May 16, 2021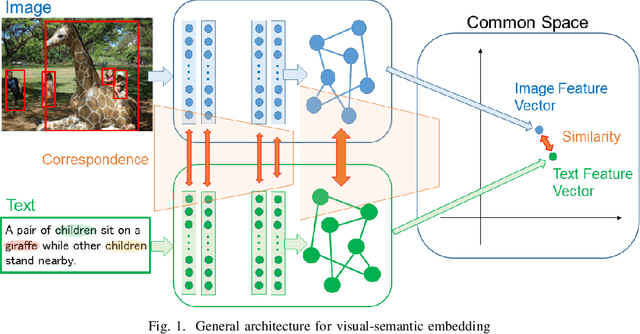
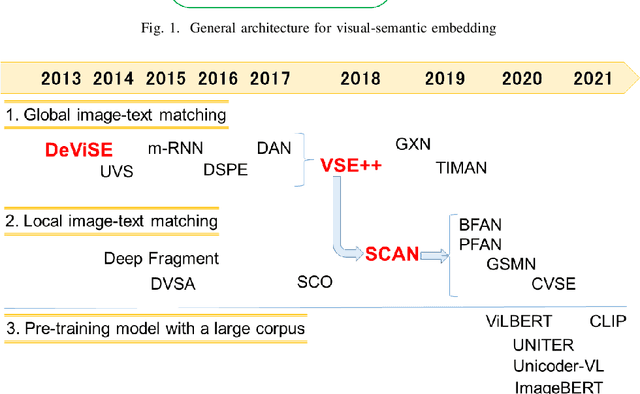
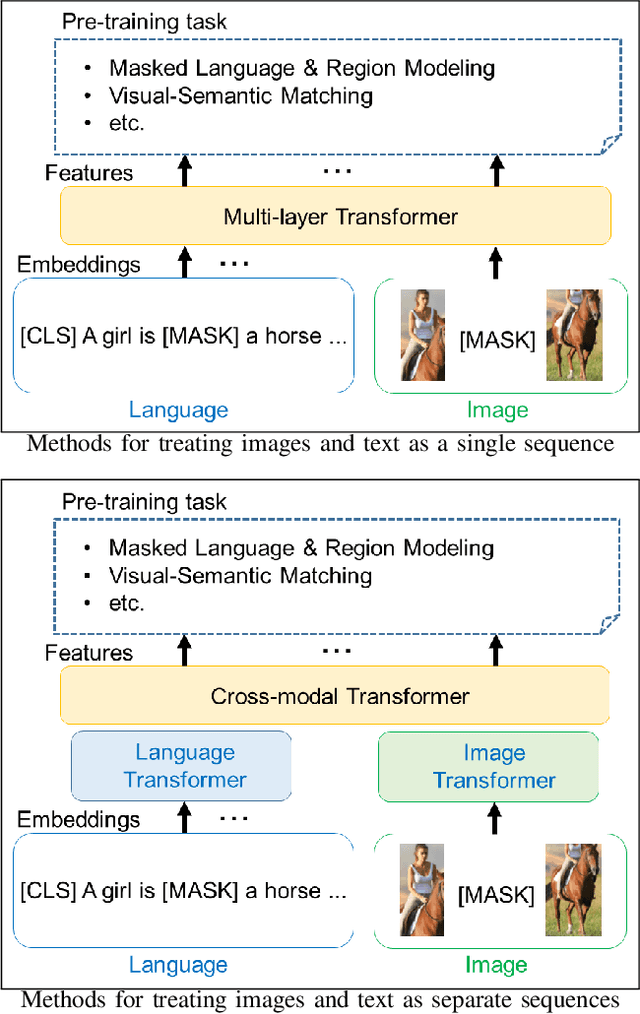
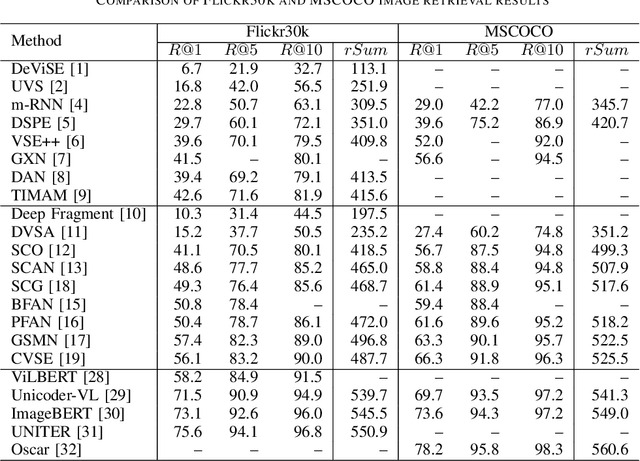
Visual-semantic embedding is an interesting research topic because it is useful for various tasks, such as visual question answering (VQA), image-text retrieval, image captioning, and scene graph generation. In this paper, we focus on zero-shot image retrieval using sentences as queries and present a survey of the technological trends in this area. First, we provide a comprehensive overview of the history of the technology, starting with a discussion of the early studies of image-to-text matching and how the technology has evolved over time. In addition, a description of the datasets commonly used in experiments and a comparison of the evaluation results of each method are presented. We also introduce the implementation available on github for use in confirming the accuracy of experiments and for further improvement. We hope that this survey paper will encourage researchers to further develop their research on bridging images and languages.