 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Emergence of Double-slit Interference by Representing Visual Space in Artificial Neural Networks
May 20, 2022
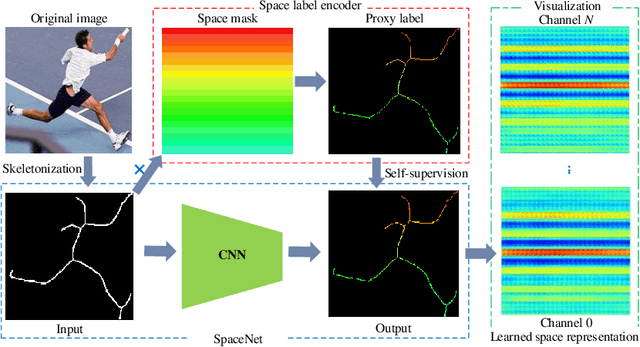
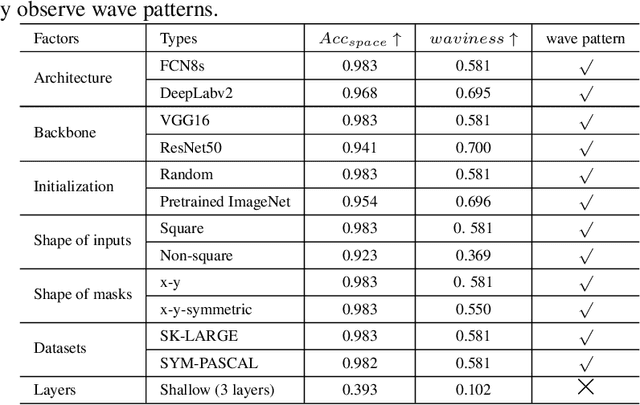
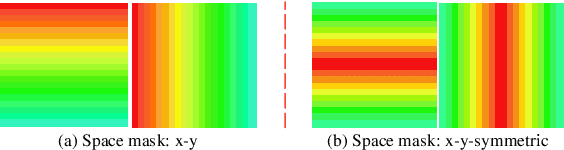
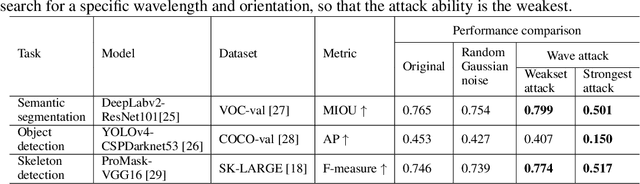
Artificial neural networks have realized incredible successes at image recognition, but the underlying mechanism of visual space representation remains a huge mystery. Grid cells (2014 Nobel Prize) in the entorhinal cortex support a periodic representation as a metric for coding space. Here, we develop a self-supervised convolutional neural network to perform visual space location, leading to the emergence of single-slit diffraction and double-slit interference patterns of waves. Our discoveries reveal the nature of CNN encoding visual space to a certain extent. CNN is no longer a black box in terms of visual spatial encoding, it is interpretable. Our findings indicate that the periodicity property of waves provides a space metric, suggesting a general role of spatial coordinate frame in artificial neural networks.
Domain-Generalized Textured Surface Anomaly Detection
Mar 23, 2022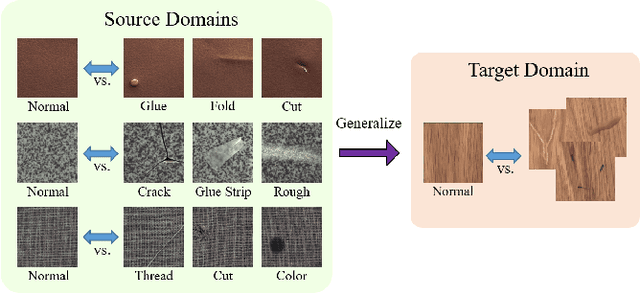
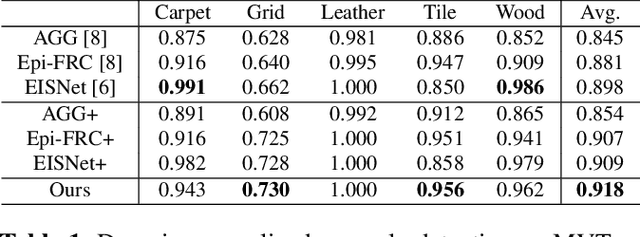
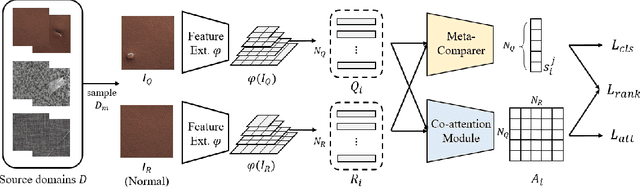
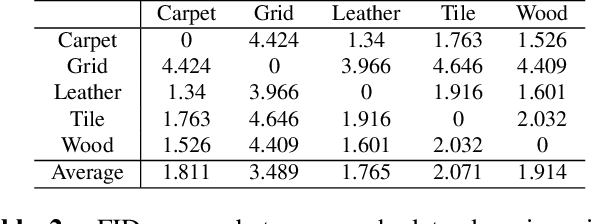
Anomaly detection aims to identify abnormal data that deviates from the normal ones, while typically requiring a sufficient amount of normal data to train the model for performing this task. Despite the success of recent anomaly detection methods, performing anomaly detection in an unseen domain remain a challenging task. In this paper, we address the task of domain-generalized textured surface anomaly detection. By observing normal and abnormal surface data across multiple source domains, our model is expected to be generalized to an unseen textured surface of interest, in which only a small number of normal data can be observed during testing. Although with only image-level labels observed in the training data, our patch-based meta-learning model exhibits promising generalization ability: not only can it generalize to unseen image domains, but it can also localize abnormal regions in the query image. Our experiments verify that our model performs favorably against state-of-the-art anomaly detection and domain generalization approaches in various settings.
Multimodal Multi-Head Convolutional Attention with Various Kernel Sizes for Medical Image Super-Resolution
Apr 12, 2022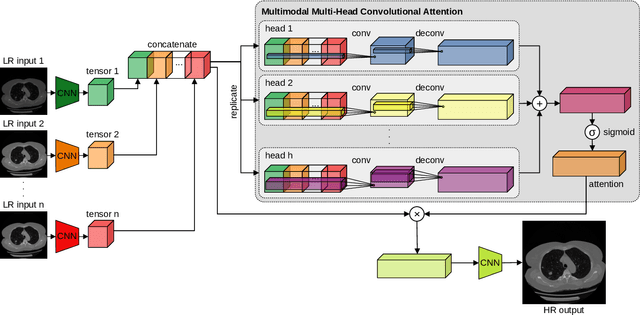
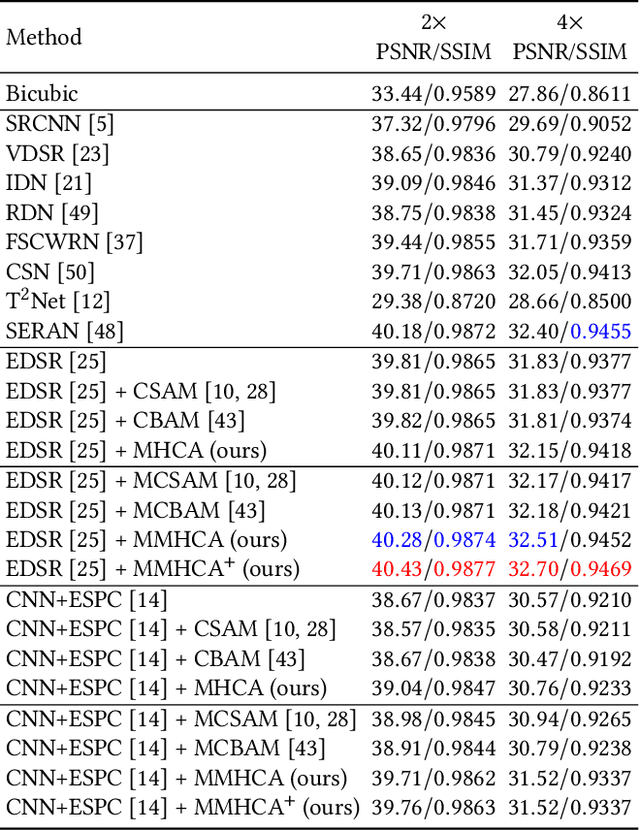
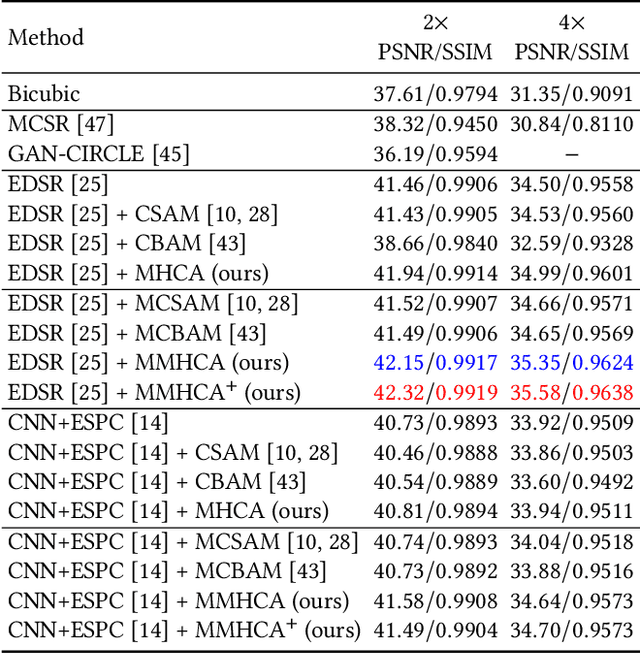
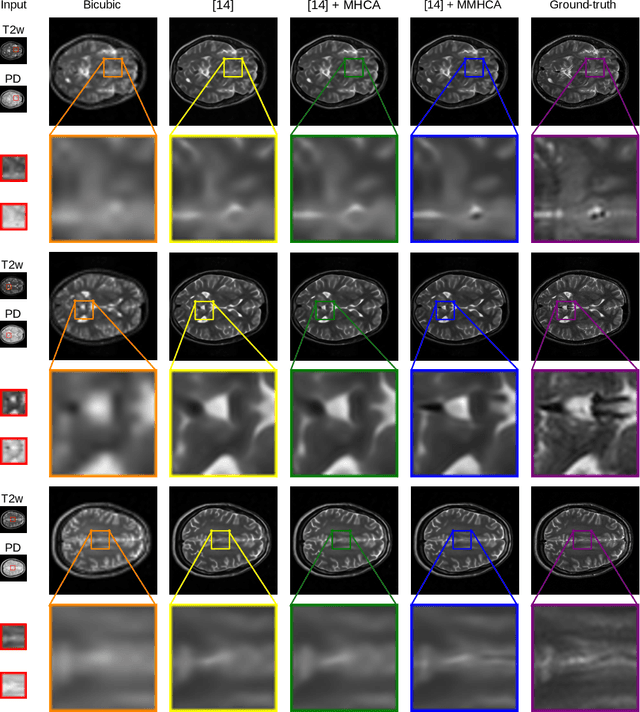
Super-resolving medical images can help physicians in providing more accurate diagnostics. In many situations, computed tomography (CT) or magnetic resonance imaging (MRI) techniques output several scans (modes) during a single investigation, which can jointly be used (in a multimodal fashion) to further boost the quality of super-resolution results. To this end, we propose a novel multimodal multi-head convolutional attention module to super-resolve CT and MRI scans. Our attention module uses the convolution operation to perform joint spatial-channel attention on multiple concatenated input tensors, where the kernel (receptive field) size controls the reduction rate of the spatial attention and the number of convolutional filters controls the reduction rate of the channel attention, respectively. We introduce multiple attention heads, each head having a distinct receptive field size corresponding to a particular reduction rate for the spatial attention. We integrate our multimodal multi-head convolutional attention (MMHCA) into two deep neural architectures for super-resolution and conduct experiments on three data sets. Our empirical results show the superiority of our attention module over the state-of-the-art attention mechanisms used in super-resolution. Moreover, we conduct an ablation study to assess the impact of the components involved in our attention module, e.g. the number of inputs or the number of heads.
Generative Myocardial Motion Tracking via Latent Space Exploration with Biomechanics-informed Prior
Jun 08, 2022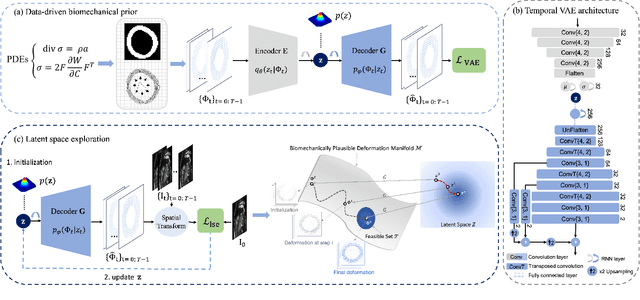
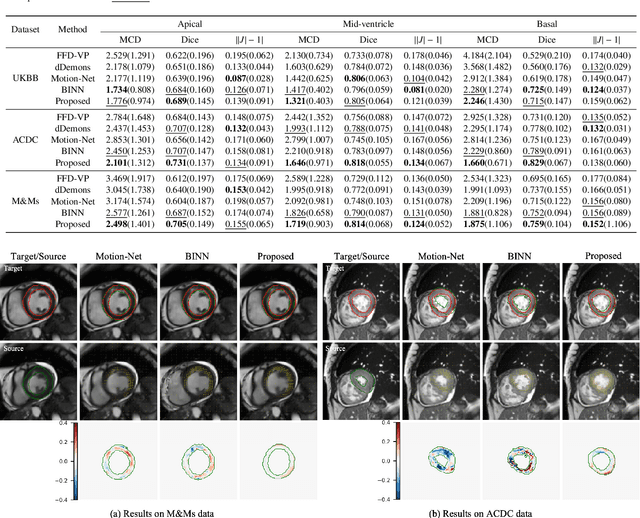
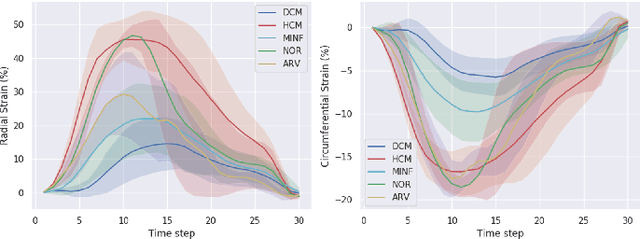
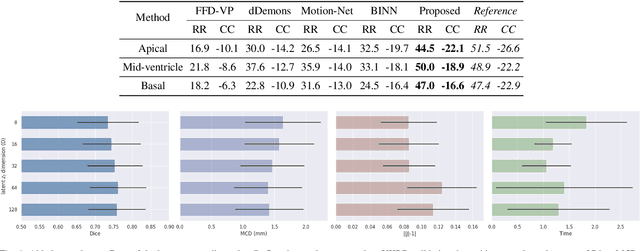
Myocardial motion and deformation are rich descriptors that characterize cardiac function. Image registration, as the most commonly used technique for myocardial motion tracking, is an ill-posed inverse problem which often requires prior assumptions on the solution space. In contrast to most existing approaches which impose explicit generic regularization such as smoothness, in this work we propose a novel method that can implicitly learn an application-specific biomechanics-informed prior and embed it into a neural network-parameterized transformation model. Particularly, the proposed method leverages a variational autoencoder-based generative model to learn a manifold for biomechanically plausible deformations. The motion tracking then can be performed via traversing the learnt manifold to search for the optimal transformations while considering the sequence information. The proposed method is validated on three public cardiac cine MRI datasets with comprehensive evaluations. The results demonstrate that the proposed method can outperform other approaches, yielding higher motion tracking accuracy with reasonable volume preservation and better generalizability to varying data distributions. It also enables better estimates of myocardial strains, which indicates the potential of the method in characterizing spatiotemporal signatures for understanding cardiovascular diseases.
Automatic Generation of Synthetic Colonoscopy Videos for Domain Randomization
May 20, 2022
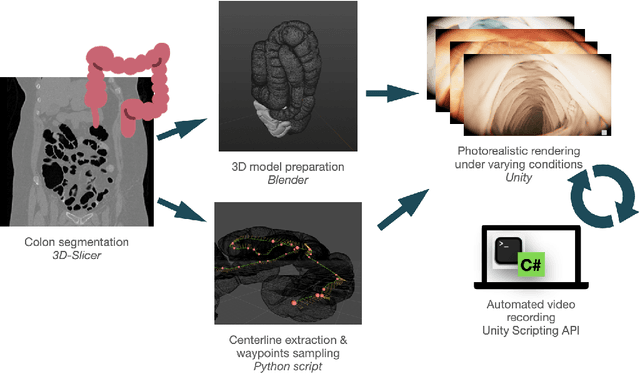
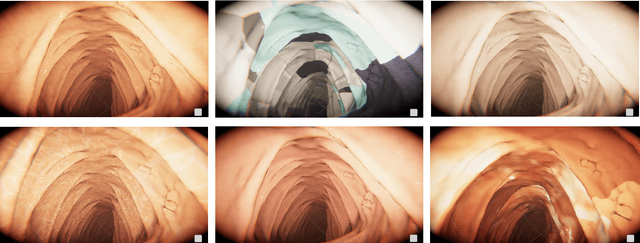
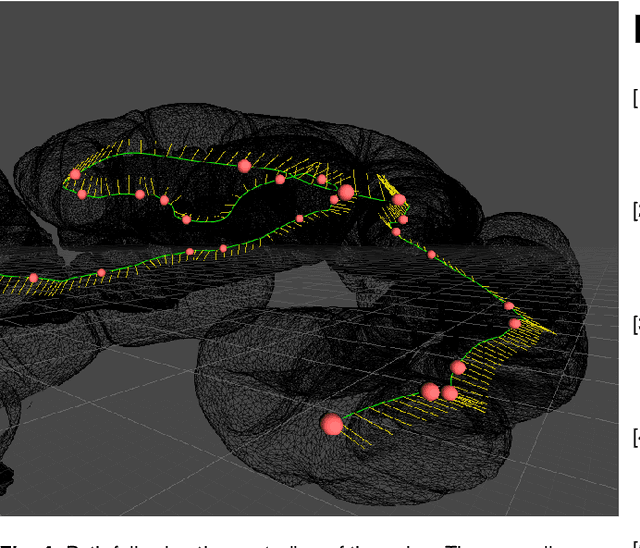
An increasing number of colonoscopic guidance and assistance systems rely on machine learning algorithms which require a large amount of high-quality training data. In order to ensure high performance, the latter has to resemble a substantial portion of possible configurations. This particularly addresses varying anatomy, mucosa appearance and image sensor characteristics which are likely deteriorated by motion blur and inadequate illumination. The limited amount of readily available training data hampers to account for all of these possible configurations which results in reduced generalization capabilities of machine learning models. We propose an exemplary solution for synthesizing colonoscopy videos with substantial appearance and anatomical variations which enables to learn discriminative domain-randomized representations of the interior colon while mimicking real-world settings.
Guided Diffusion Model for Adversarial Purification
Jun 04, 2022
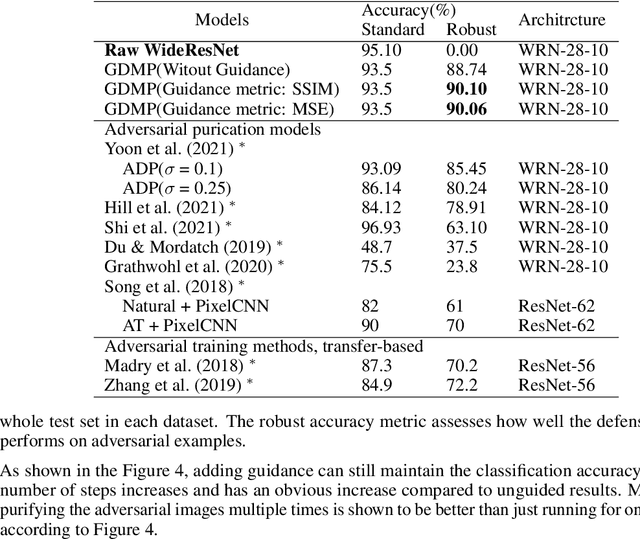
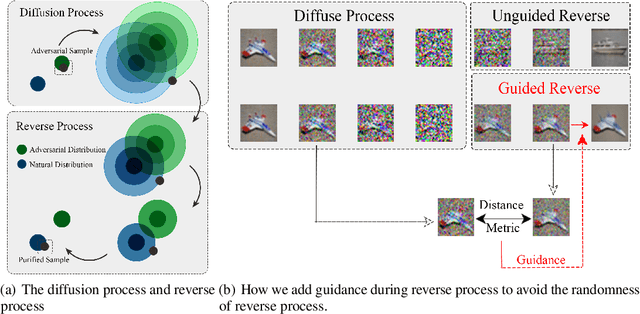
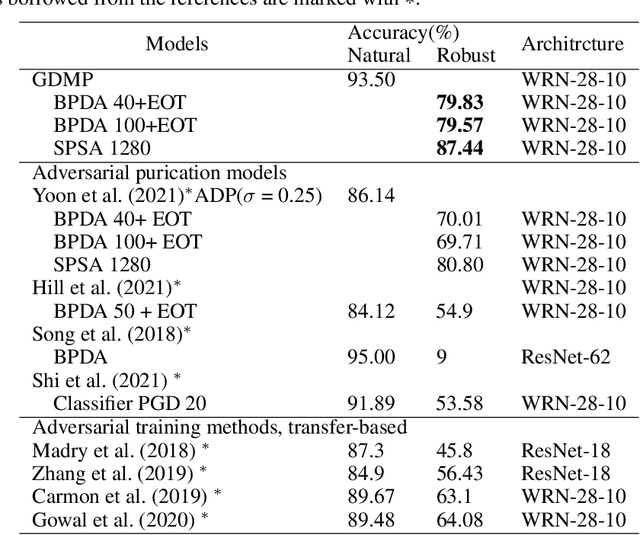
With wider application of deep neural networks (DNNs) in various algorithms and frameworks, security threats have become one of the concerns. Adversarial attacks disturb DNN-based image classifiers, in which attackers can intentionally add imperceptible adversarial perturbations on input images to fool the classifiers. In this paper, we propose a novel purification approach, referred to as guided diffusion model for purification (GDMP), to help protect classifiers from adversarial attacks. The core of our approach is to embed purification into the diffusion denoising process of a Denoised Diffusion Probabilistic Model (DDPM), so that its diffusion process could submerge the adversarial perturbations with gradually added Gaussian noises, and both of these noises can be simultaneously removed following a guided denoising process. On our comprehensive experiments across various datasets, the proposed GDMP is shown to reduce the perturbations raised by adversarial attacks to a shallow range, thereby significantly improving the correctness of classification. GDMP improves the robust accuracy by 5%, obtaining 90.1% under PGD attack on the CIFAR10 dataset. Moreover, GDMP achieves 70.94% robustness on the challenging ImageNet dataset.
BoundarySqueeze: Image Segmentation as Boundary Squeezing
May 25, 2021
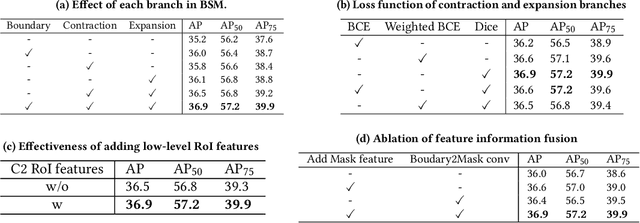

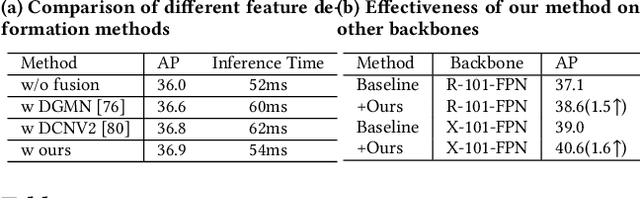
We propose a novel method for fine-grained high-quality image segmentation of both objects and scenes. Inspired by dilation and erosion from morphological image processing techniques, we treat the pixel level segmentation problems as squeezing object boundary. From this perspective, we propose \textbf{Boundary Squeeze} module: a novel and efficient module that squeezes the object boundary from both inner and outer directions which leads to precise mask representation. To generate such squeezed representation, we propose a new bidirectionally flow-based warping process and design specific loss signals to supervise the learning process. Boundary Squeeze Module can be easily applied to both instance and semantic segmentation tasks as a plug-and-play module by building on top of existing models. We show that our simple yet effective design can lead to high qualitative results on several different datasets and we also provide several different metrics on boundary to prove the effectiveness over previous work. Moreover, the proposed module is light-weighted and thus has potential for practical usage. Our method yields large gains on COCO, Cityscapes, for both instance and semantic segmentation and outperforms previous state-of-the-art PointRend in both accuracy and speed under the same setting. Code and model will be available.
Binary Single-dimensional Convolutional Neural Network for Seizure Prediction
Jun 08, 2022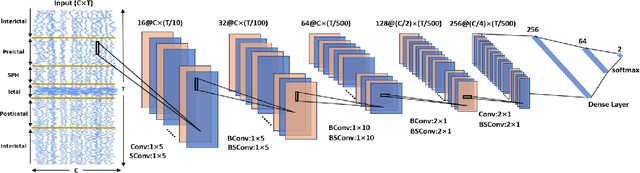
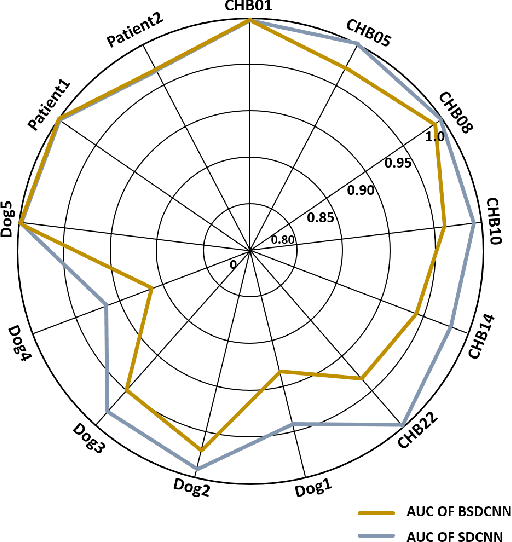
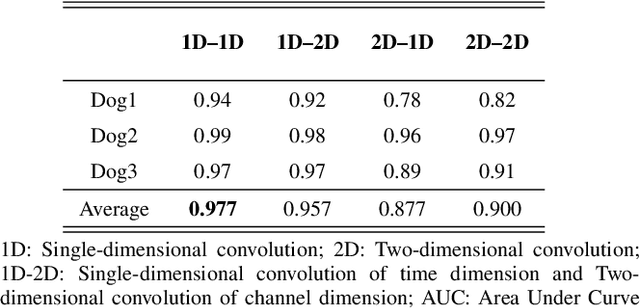
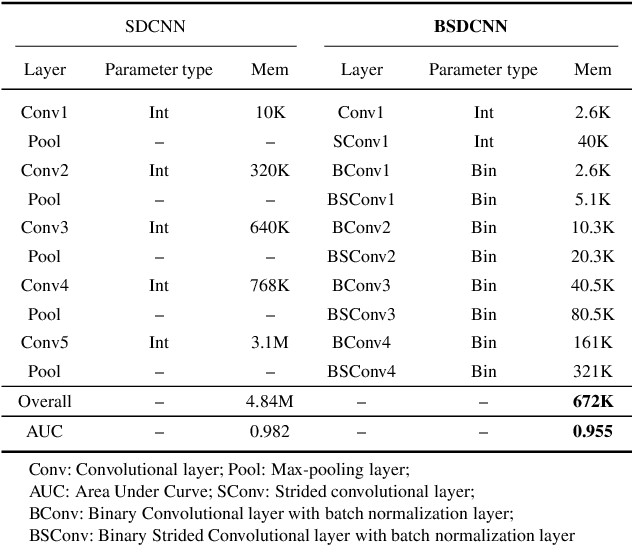
Nowadays, several deep learning methods are proposed to tackle the challenge of epileptic seizure prediction. However, these methods still cannot be implemented as part of implantable or efficient wearable devices due to their large hardware and corresponding high-power consumption. They usually require complex feature extraction process, large memory for storing high precision parameters and complex arithmetic computation, which greatly increases required hardware resources. Moreover, available yield poor prediction performance, because they adopt network architecture directly from image recognition applications fails to accurately consider the characteristics of EEG signals. We propose in this paper a hardware-friendly network called Binary Single-dimensional Convolutional Neural Network (BSDCNN) intended for epileptic seizure prediction. BSDCNN utilizes 1D convolutional kernels to improve prediction performance. All parameters are binarized to reduce the required computation and storage, except the first layer. Overall area under curve, sensitivity, and false prediction rate reaches 0.915, 89.26%, 0.117/h and 0.970, 94.69%, 0.095/h on American Epilepsy Society Seizure Prediction Challenge (AES) dataset and the CHB-MIT one respectively. The proposed architecture outperforms recent works while offering 7.2 and 25.5 times reductions on the size of parameter and computation, respectively.
Improving Diversity with Adversarially Learned Transformations for Domain Generalization
Jun 15, 2022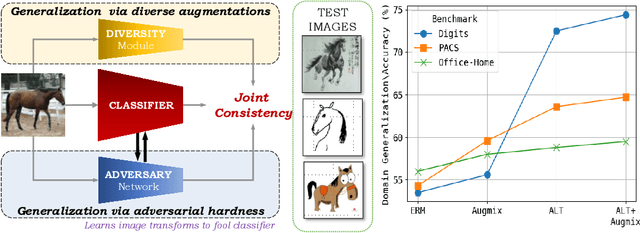
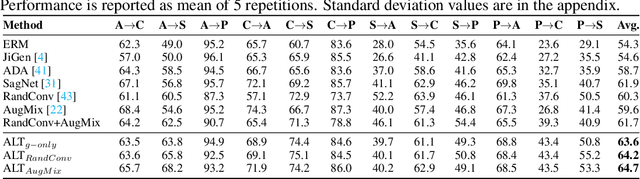
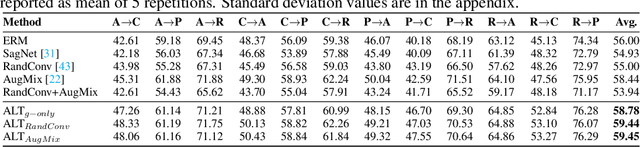
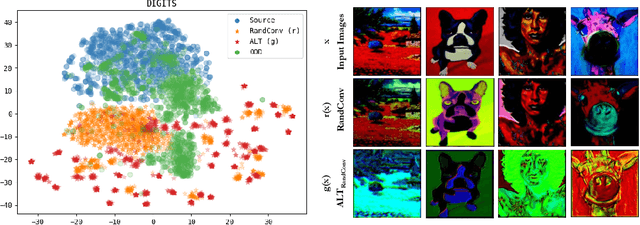
To be successful in single source domain generalization, maximizing diversity of synthesized domains has emerged as one of the most effective strategies. Many of the recent successes have come from methods that pre-specify the types of diversity that a model is exposed to during training, so that it can ultimately generalize well to new domains. However, na\"ive diversity based augmentations do not work effectively for domain generalization either because they cannot model large domain shift, or because the span of transforms that are pre-specified do not cover the types of shift commonly occurring in domain generalization. To address this issue, we present a novel framework that uses adversarially learned transformations (ALT) using a neural network to model plausible, yet hard image transformations that fool the classifier. This network is randomly initialized for each batch and trained for a fixed number of steps to maximize classification error. Further, we enforce consistency between the classifier's predictions on the clean and transformed images. With extensive empirical analysis, we find that this new form of adversarial transformations achieve both objectives of diversity and hardness simultaneously, outperforming all existing techniques on competitive benchmarks for single source domain generalization. We also show that ALT can naturally work with existing diversity modules to produce highly distinct, and large transformations of the source domain leading to state-of-the-art performance.
Performance Evaluation of Infrared Image Enhancement Techniques
Feb 07, 2022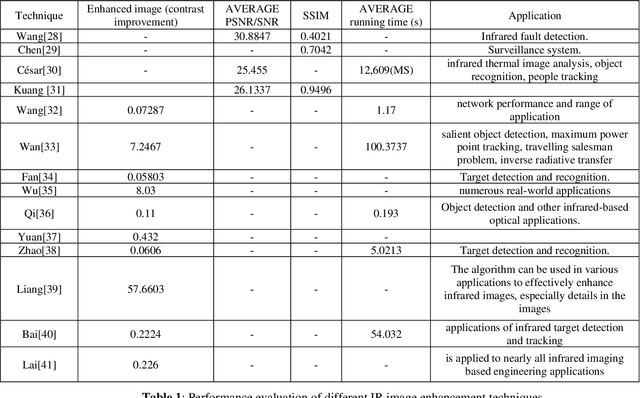
Infrared (IR) images are widely used in many fields such as medical imaging, object tracking, astronomy and military purposes for securing borders. Infrared images can be captured day or night based on the type of capturing device. The capturing devices use electromagnetic radiation with longer wavelengths. There are several types of IR radiation based on the range of wavelength and corresponding frequency. Due to noising and other artifacts, IR images are not clearly visible. In this paper, we present a complete up-todate survey on IR imaging enhancement techniques. The survey includes IR radiation types and devices and existing IR datasets. The survey covers spatial enhancement techniques, frequency-domain based enhancement techniques and Deep learning-based techniques.