 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
How Much is Enough? A Study on Diffusion Times in Score-based Generative Models
Jun 10, 2022
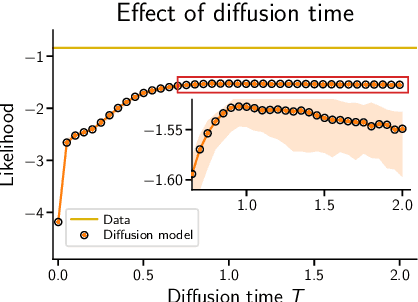
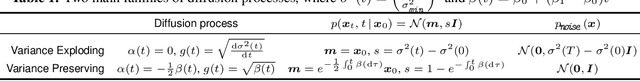

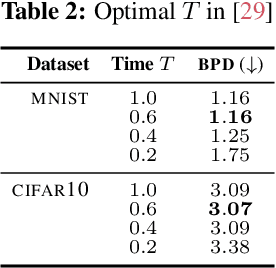
Score-based diffusion models are a class of generative models whose dynamics is described by stochastic differential equations that map noise into data. While recent works have started to lay down a theoretical foundation for these models, an analytical understanding of the role of the diffusion time T is still lacking. Current best practice advocates for a large T to ensure that the forward dynamics brings the diffusion sufficiently close to a known and simple noise distribution; however, a smaller value of T should be preferred for a better approximation of the score-matching objective and higher computational efficiency. Starting from a variational interpretation of diffusion models, in this work we quantify this trade-off, and suggest a new method to improve quality and efficiency of both training and sampling, by adopting smaller diffusion times. Indeed, we show how an auxiliary model can be used to bridge the gap between the ideal and the simulated forward dynamics, followed by a standard reverse diffusion process. Empirical results support our analysis; for image data, our method is competitive w.r.t. the state-of-the-art, according to standard sample quality metrics and log-likelihood.
Globally-Optimal Contrast Maximisation for Event Cameras
Jun 10, 2022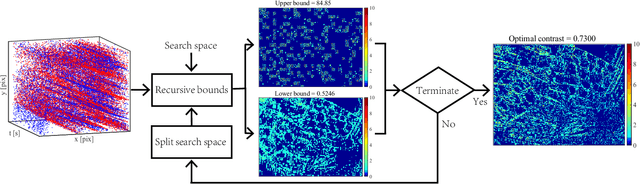

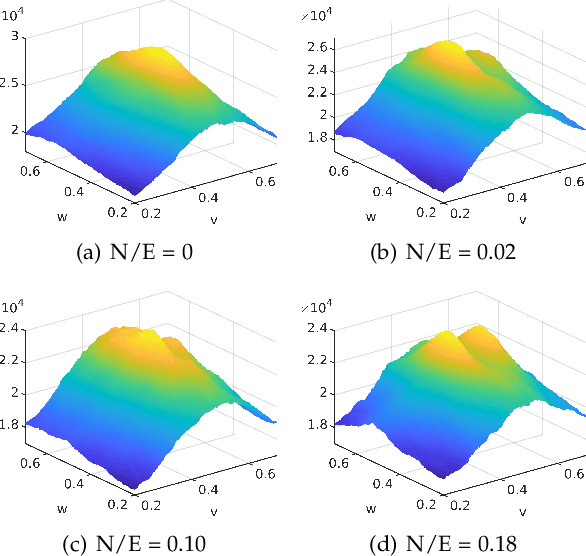
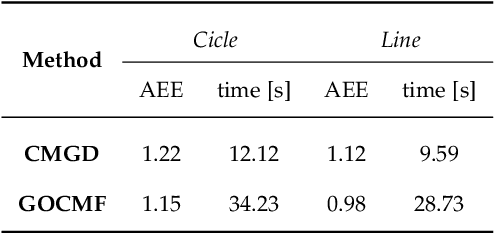
Event cameras are bio-inspired sensors that perform well in challenging illumination conditions and have high temporal resolution. However, their concept is fundamentally different from traditional frame-based cameras. The pixels of an event camera operate independently and asynchronously. They measure changes of the logarithmic brightness and return them in the highly discretised form of time-stamped events indicating a relative change of a certain quantity since the last event. New models and algorithms are needed to process this kind of measurements. The present work looks at several motion estimation problems with event cameras. The flow of the events is modelled by a general homographic warping in a space-time volume, and the objective is formulated as a maximisation of contrast within the image of warped events. Our core contribution consists of deriving globally optimal solutions to these generally non-convex problems, which removes the dependency on a good initial guess plaguing existing methods. Our methods rely on branch-and-bound optimisation and employ novel and efficient, recursive upper and lower bounds derived for six different contrast estimation functions. The practical validity of our approach is demonstrated by a successful application to three different event camera motion estimation problems.
* arXiv admin note: substantial text overlap with arXiv:2203.03914
Tackling covariate shift with node-based Bayesian neural networks
Jun 06, 2022

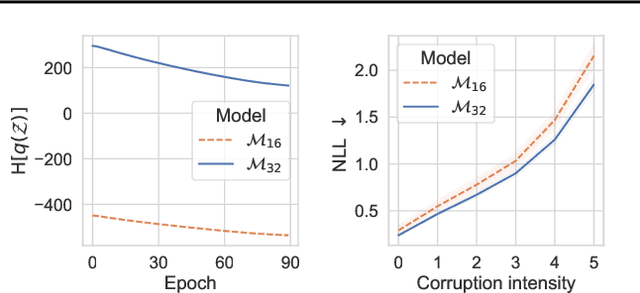
Bayesian neural networks (BNNs) promise improved generalization under covariate shift by providing principled probabilistic representations of epistemic uncertainty. However, weight-based BNNs often struggle with high computational complexity of large-scale architectures and datasets. Node-based BNNs have recently been introduced as scalable alternatives, which induce epistemic uncertainty by multiplying each hidden node with latent random variables, while learning a point-estimate of the weights. In this paper, we interpret these latent noise variables as implicit representations of simple and domain-agnostic data perturbations during training, producing BNNs that perform well under covariate shift due to input corruptions. We observe that the diversity of the implicit corruptions depends on the entropy of the latent variables, and propose a straightforward approach to increase the entropy of these variables during training. We evaluate the method on out-of-distribution image classification benchmarks, and show improved uncertainty estimation of node-based BNNs under covariate shift due to input perturbations. As a side effect, the method also provides robustness against noisy training labels.
Subjective Quality Assessment for Images Generated by Computer Graphics
Jun 10, 2022
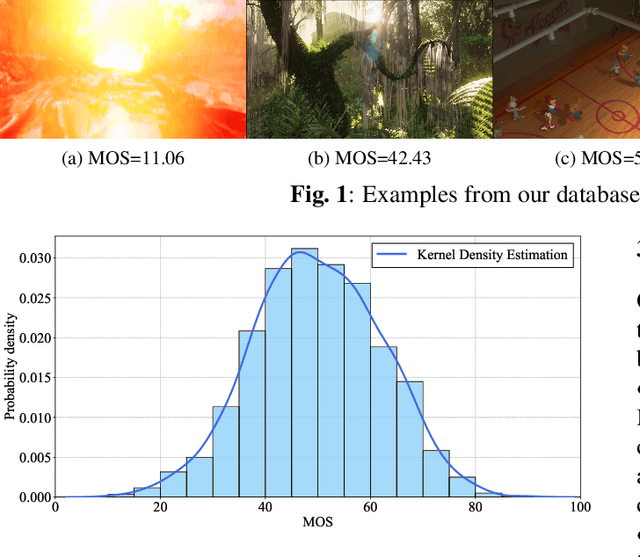
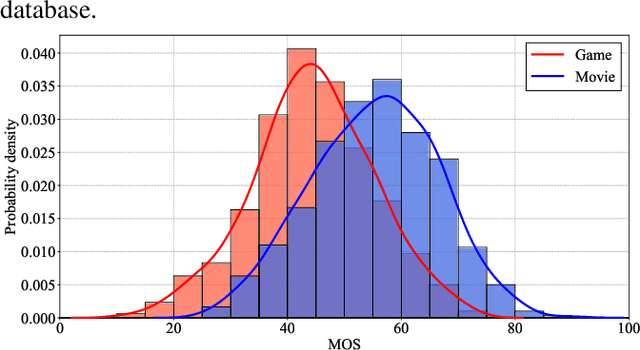

With the development of rendering techniques, computer graphics generated images (CGIs) have been widely used in practical application scenarios such as architecture design, video games, simulators, movies, etc. Different from natural scene images (NSIs), the distortions of CGIs are usually caused by poor rending settings and limited computation resources. What's more, some CGIs may also suffer from compression distortions in transmission systems like cloud gaming and stream media. However, limited work has been put forward to tackle the problem of computer graphics generated images' quality assessment (CG-IQA). Therefore, in this paper, we establish a large-scale subjective CG-IQA database to deal with the challenge of CG-IQA tasks. We collect 25,454 in-the-wild CGIs through previous databases and personal collection. After data cleaning, we carefully select 1,200 CGIs to conduct the subjective experiment. Several popular no-reference image quality assessment (NR-IQA) methods are tested on our database. The experimental results show that the handcrafted-based methods achieve low correlation with subjective judgment and deep learning based methods obtain relatively better performance, which demonstrates that the current NR-IQA models are not suitable for CG-IQA tasks and more effective models are urgently needed.
Unpaired Adversarial Learning for Single Image Deraining with Rain-Space Contrastive Constraints
Sep 08, 2021
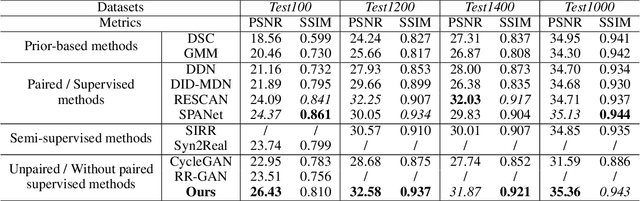
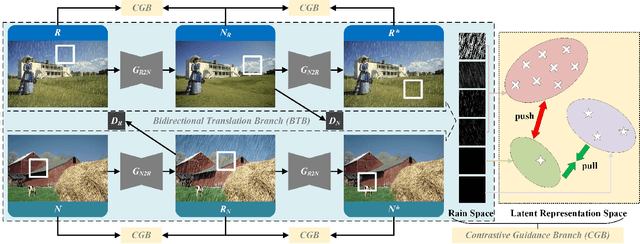
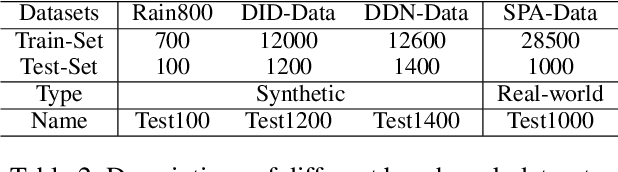
Deep learning-based single image deraining (SID) with unpaired information is of immense importance, as relying on paired synthetic data often limits their generality and scalability in real-world applications. However, we noticed that direct employ of unpaired adversarial learning and cycle-consistency constraints in the SID task is insufficient to learn the underlying relationship from rainy input to clean outputs, since the domain knowledge between rainy and rain-free images is asymmetrical. To address such limitation, we develop an effective unpaired SID method which explores mutual properties of the unpaired exemplars by a contrastive learning manner in a GAN framework, named as CDR-GAN. The proposed method mainly consists of two cooperative branches: Bidirectional Translation Branch (BTB) and Contrastive Guidance Branch (CGB). Specifically, BTB takes full advantage of the circulatory architecture of adversarial consistency to exploit latent feature distributions and guide transfer ability between two domains by equipping it with bidirectional mapping. Simultaneously, CGB implicitly constrains the embeddings of different exemplars in rain space by encouraging the similar feature distributions closer while pushing the dissimilar further away, in order to better help rain removal and image restoration. During training, we explore several loss functions to further constrain the proposed CDR-GAN. Extensive experiments show that our method performs favorably against existing unpaired deraining approaches on both synthetic and real-world datasets, even outperforms several fully-supervised or semi-supervised models.
Learning self-calibrated optic disc and cup segmentation from multi-rater annotations
Jun 14, 2022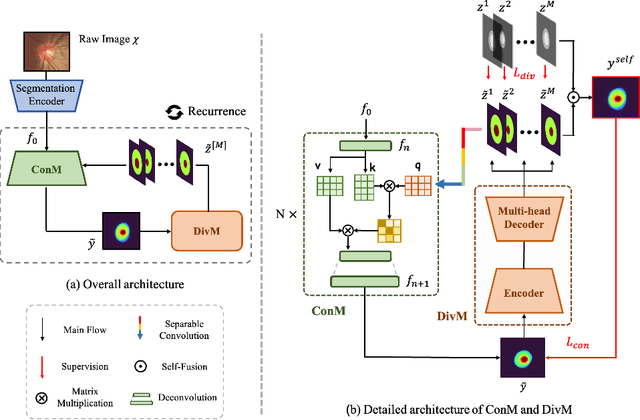
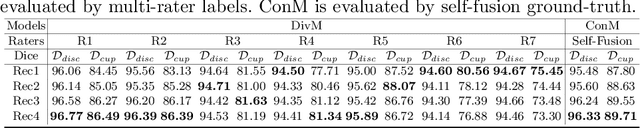
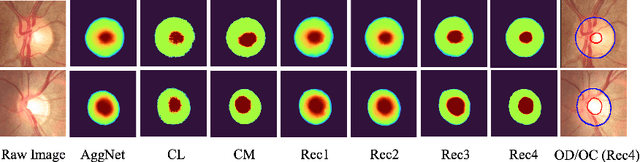
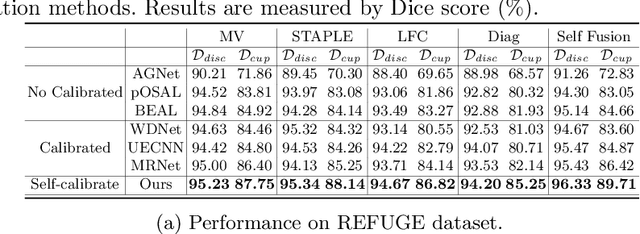
The segmentation of optic disc(OD) and optic cup(OC) from fundus images is an important fundamental task for glaucoma diagnosis. In the clinical practice, it is often necessary to collect opinions from multiple experts to obtain the final OD/OC annotation. This clinical routine helps to mitigate the individual bias. But when data is multiply annotated, standard deep learning models will be inapplicable. In this paper, we propose a novel neural network framework to learn OD/OC segmentation from multi-rater annotations. The segmentation results are self-calibrated through the iterative optimization of multi-rater expertness estimation and calibrated OD/OC segmentation. In this way, the proposed method can realize a mutual improvement of both tasks and finally obtain a refined segmentation result. Specifically, we propose Diverging Model(DivM) and Converging Model(ConM) to process the two tasks respectively. ConM segments the raw image based on the multi-rater expertness map provided by DivM. DivM generates multi-rater expertness map from the segmentation mask provided by ConM. The experiment results show that by recurrently running ConM and DivM, the results can be self-calibrated so as to outperform a range of state-of-the-art(SOTA) multi-rater segmentation methods.
Exemplar Free Class Agnostic Counting
May 27, 2022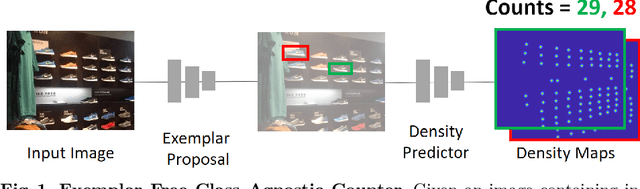
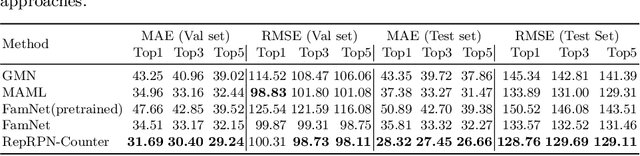
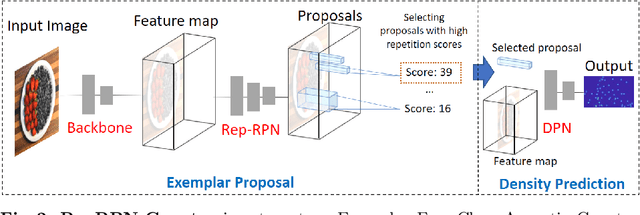
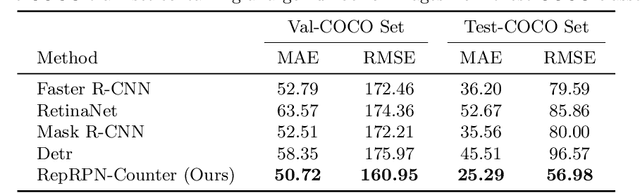
We tackle the task of Class Agnostic Counting, which aims to count objects in a novel object category at test time without any access to labeled training data for that category. All previous class agnostic counting methods cannot work in a fully automated setting, and require computationally expensive test time adaptation. To address these challenges, we propose a visual counter which operates in a fully automated setting and does not require any test time adaptation. Our proposed approach first identifies exemplars from repeating objects in an image, and then counts the repeating objects. We propose a novel region proposal network for identifying the exemplars. After identifying the exemplars, we obtain the corresponding count by using a density estimation based Visual Counter. We evaluate our proposed approach on FSC-147 dataset, and show that it achieves superior performance compared to the existing approaches.
Better Teacher Better Student: Dynamic Prior Knowledge for Knowledge Distillation
Jun 14, 2022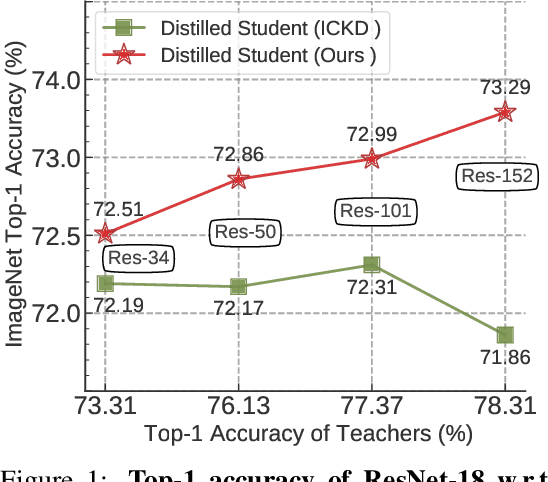
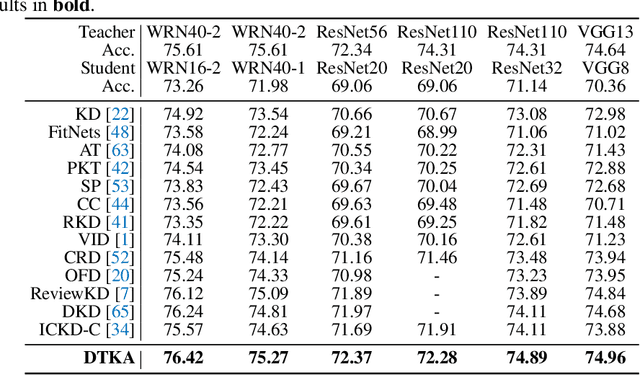
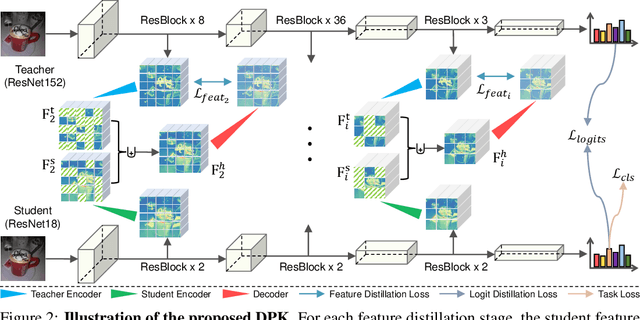

Knowledge distillation (KD) has shown very promising capabilities in transferring learning representations from large models (teachers) to small models (students). However, as the capacity gap between students and teachers becomes larger, existing KD methods fail to achieve better results. Our work shows that the 'prior knowledge' is vital to KD, especially when applying large teachers. Particularly, we propose the dynamic prior knowledge (DPK), which integrates part of the teacher's features as the prior knowledge before the feature distillation. This means that our method also takes the teacher's feature as `input', not just `target'. Besides, we dynamically adjust the ratio of the prior knowledge during the training phase according to the feature gap, thus guiding the student in an appropriate difficulty. To evaluate the proposed method, we conduct extensive experiments on two image classification benchmarks (i.e. CIFAR100 and ImageNet) and an object detection benchmark (i.e. MS COCO). The results demonstrate the superiority of our method in performance under varying settings. More importantly, our DPK makes the performance of the student model is positively correlated with that of the teacher model, which means that we can further boost the accuracy of students by applying larger teachers. Our codes will be publicly available for the reproducibility.
Federated Learning in Non-IID Settings Aided by Differentially Private Synthetic Data
Jun 01, 2022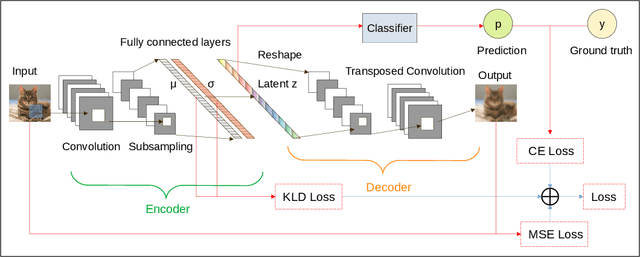
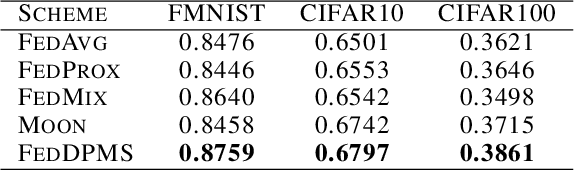
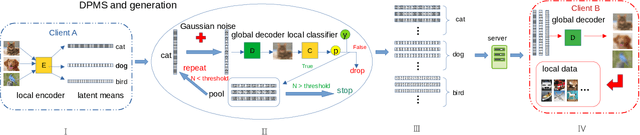
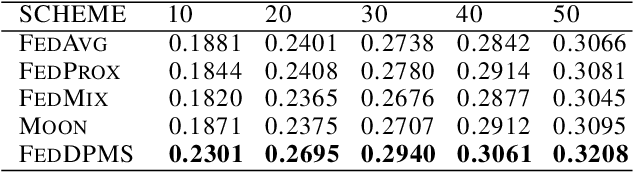
Federated learning (FL) is a privacy-promoting framework that enables potentially large number of clients to collaboratively train machine learning models. In a FL system, a server coordinates the collaboration by collecting and aggregating clients' model updates while the clients' data remains local and private. A major challenge in federated learning arises when the local data is heterogeneous -- the setting in which performance of the learned global model may deteriorate significantly compared to the scenario where the data is identically distributed across the clients. In this paper we propose FedDPMS (Federated Differentially Private Means Sharing), an FL algorithm in which clients deploy variational auto-encoders to augment local datasets with data synthesized using differentially private means of latent data representations communicated by a trusted server. Such augmentation ameliorates effects of data heterogeneity across the clients without compromising privacy. Our experiments on deep image classification tasks demonstrate that FedDPMS outperforms competing state-of-the-art FL methods specifically designed for heterogeneous data settings.
CorticalFlow: A Diffeomorphic Mesh Deformation Module for Cortical Surface Reconstruction
Jun 06, 2022
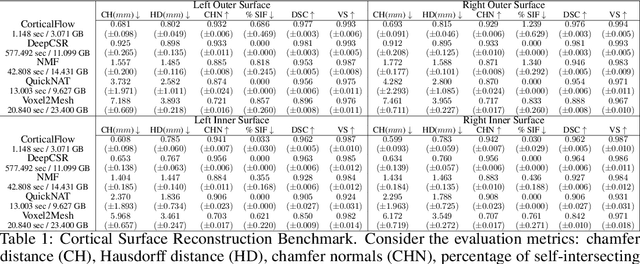
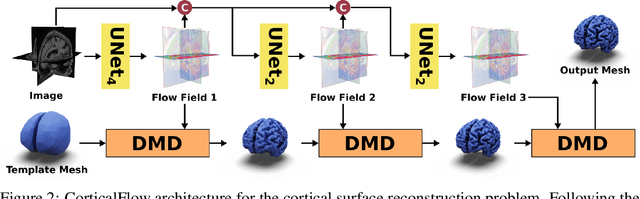
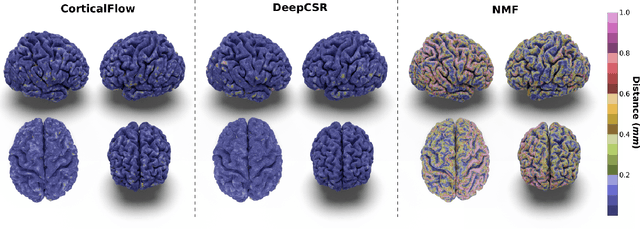
In this paper we introduce CorticalFlow, a new geometric deep-learning model that, given a 3-dimensional image, learns to deform a reference template towards a targeted object. To conserve the template mesh's topological properties, we train our model over a set of diffeomorphic transformations. This new implementation of a flow Ordinary Differential Equation (ODE) framework benefits from a small GPU memory footprint, allowing the generation of surfaces with several hundred thousand vertices. To reduce topological errors introduced by its discrete resolution, we derive numeric conditions which improve the manifoldness of the predicted triangle mesh. To exhibit the utility of CorticalFlow, we demonstrate its performance for the challenging task of brain cortical surface reconstruction. In contrast to current state-of-the-art, CorticalFlow produces superior surfaces while reducing the computation time from nine and a half minutes to one second. More significantly, CorticalFlow enforces the generation of anatomically plausible surfaces; the absence of which has been a major impediment restricting the clinical relevance of such surface reconstruction methods.