 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pragmatic Image Compression for Human-in-the-Loop Decision-Making
Jul 07, 2021


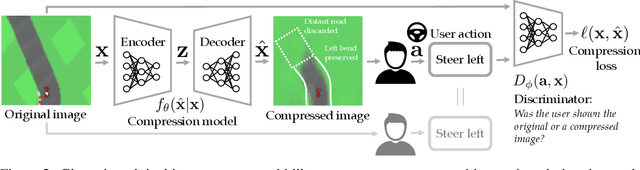
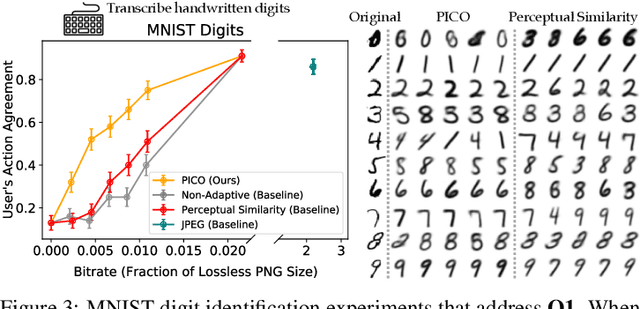
Standard lossy image compression algorithms aim to preserve an image's appearance, while minimizing the number of bits needed to transmit it. However, the amount of information actually needed by a user for downstream tasks -- e.g., deciding which product to click on in a shopping website -- is likely much lower. To achieve this lower bitrate, we would ideally only transmit the visual features that drive user behavior, while discarding details irrelevant to the user's decisions. We approach this problem by training a compression model through human-in-the-loop learning as the user performs tasks with the compressed images. The key insight is to train the model to produce a compressed image that induces the user to take the same action that they would have taken had they seen the original image. To approximate the loss function for this model, we train a discriminator that tries to distinguish whether a user's action was taken in response to the compressed image or the original. We evaluate our method through experiments with human participants on four tasks: reading handwritten digits, verifying photos of faces, browsing an online shopping catalogue, and playing a car racing video game. The results show that our method learns to match the user's actions with and without compression at lower bitrates than baseline methods, and adapts the compression model to the user's behavior: it preserves the digit number and randomizes handwriting style in the digit reading task, preserves hats and eyeglasses while randomizing faces in the photo verification task, preserves the perceived price of an item while randomizing its color and background in the online shopping task, and preserves upcoming bends in the road in the car racing game.
FIFO: Learning Fog-invariant Features for Foggy Scene Segmentation
Apr 04, 2022
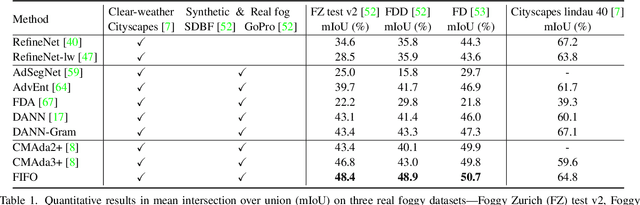
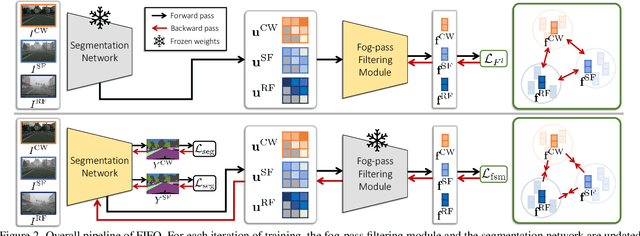
Robust visual recognition under adverse weather conditions is of great importance in real-world applications. In this context, we propose a new method for learning semantic segmentation models robust against fog. Its key idea is to consider the fog condition of an image as its style and close the gap between images with different fog conditions in neural style spaces of a segmentation model. In particular, since the neural style of an image is in general affected by other factors as well as fog, we introduce a fog-pass filter module that learns to extract a fog-relevant factor from the style. Optimizing the fog-pass filter and the segmentation model alternately gradually closes the style gap between different fog conditions and allows to learn fog-invariant features in consequence. Our method substantially outperforms previous work on three real foggy image datasets. Moreover, it improves performance on both foggy and clear weather images, while existing methods often degrade performance on clear scenes.
Optimization-Derived Learning with Essential Convergence Analysis of Training and Hyper-training
Jun 16, 2022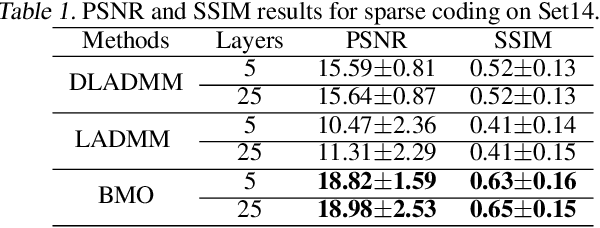

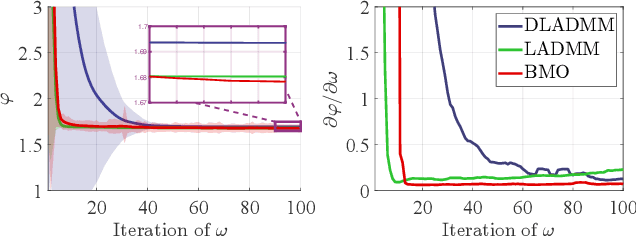
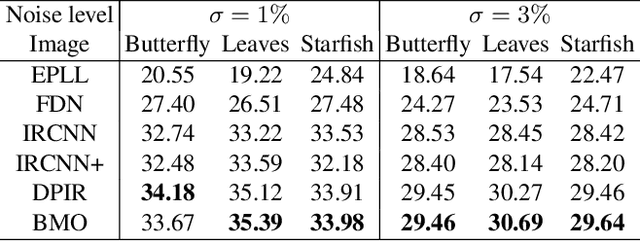
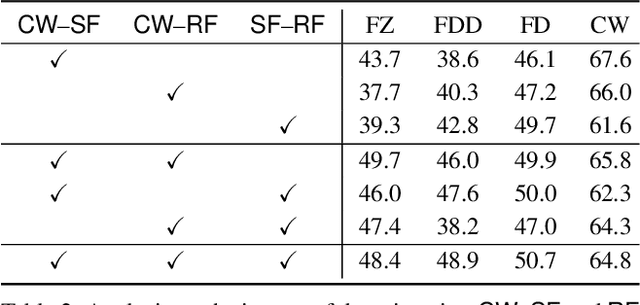
Recently, Optimization-Derived Learning (ODL) has attracted attention from learning and vision areas, which designs learning models from the perspective of optimization. However, previous ODL approaches regard the training and hyper-training procedures as two separated stages, meaning that the hyper-training variables have to be fixed during the training process, and thus it is also impossible to simultaneously obtain the convergence of training and hyper-training variables. In this work, we design a Generalized Krasnoselskii-Mann (GKM) scheme based on fixed-point iterations as our fundamental ODL module, which unifies existing ODL methods as special cases. Under the GKM scheme, a Bilevel Meta Optimization (BMO) algorithmic framework is constructed to solve the optimal training and hyper-training variables together. We rigorously prove the essential joint convergence of the fixed-point iteration for training and the process of optimizing hyper-parameters for hyper-training, both on the approximation quality, and on the stationary analysis. Experiments demonstrate the efficiency of BMO with competitive performance on sparse coding and real-world applications such as image deconvolution and rain streak removal.
T-Net: Deep Stacked Scale-Iteration Network for Image Dehazing
Jun 05, 2021
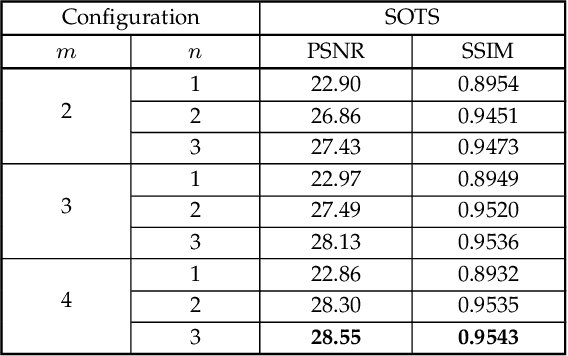
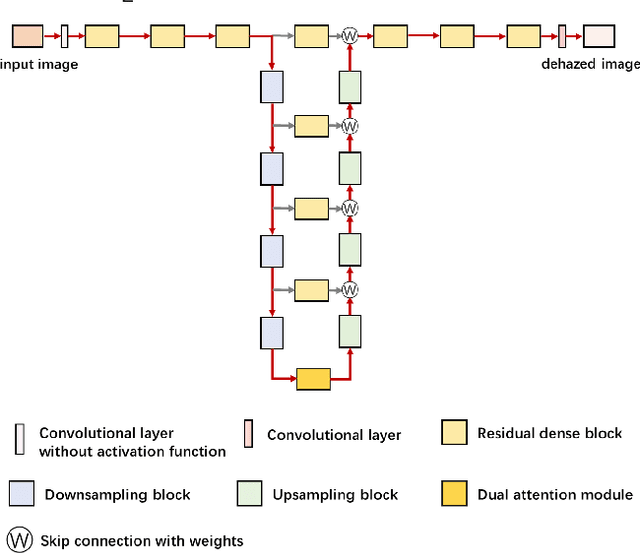
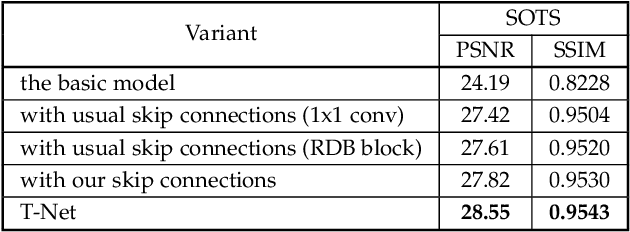
Hazy images reduce the visibility of the image content, and haze will lead to failure in handling subsequent computer vision tasks. In this paper, we address the problem of image dehazing by proposing a dehazing network named T-Net, which consists of a backbone network based on the U-Net architecture and a dual attention module. And it can achieve multi-scale feature fusion by using skip connections with a new fusion strategy. Furthermore, by repeatedly unfolding the plain T-Net, Stack T-Net is proposed to take advantage of the dependence of deep features across stages via a recursive strategy. In order to reduce network parameters, the intra-stage recursive computation of ResNet is adopted in our Stack T-Net. And we take both the stage-wise result and the original hazy image as input to each T-Net and finally output the prediction of clean image. Experimental results on both synthetic and real-world images demonstrate that our plain T-Net and the advanced Stack T-Net perform favorably against the state-of-the-art dehazing algorithms, and show that our Stack T-Net could further improve the dehazing effect, demonstrating the effectiveness of the recursive strategy.
Mean Field inference of CRFs based on GAT
May 29, 2022
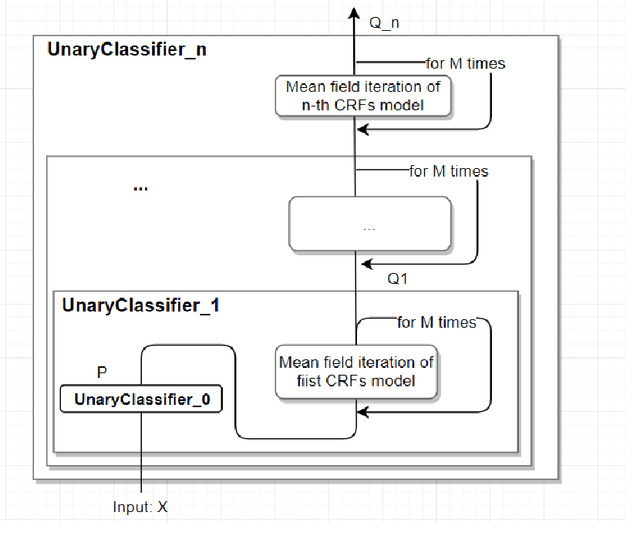

In this paper we propose an improved mean-field inference algorithm for the fully connected paired CRFs model. The improved method Message Passing operation is changed from the original linear convolution to the present graph attention operation, while the process of the inference algorithm is turned into the forward process of the GAT model. Combined with the mean-field inferred label distribution, it is equivalent to the output of a classifier with only unary potential. To this end, we propose a graph attention network model with residual structure, and the model approach is applicable to all sequence annotation tasks, such as pixel-level image semantic segmentation tasks as well as text annotation tasks.
A Generalized Framework for Edge-preserving and Structure-preserving Image Smoothing
Aug 04, 2021
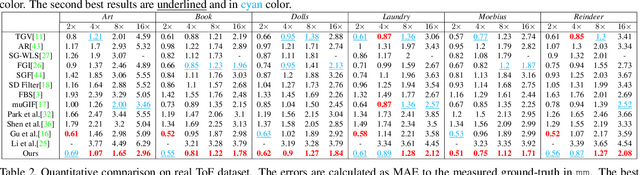
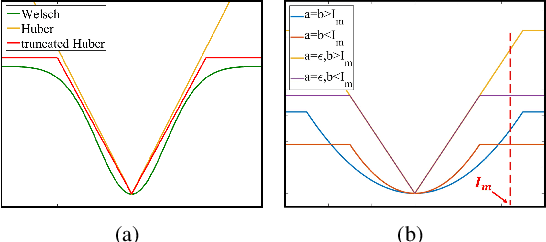

Image smoothing is a fundamental procedure in applications of both computer vision and graphics. The required smoothing properties can be different or even contradictive among different tasks. Nevertheless, the inherent smoothing nature of one smoothing operator is usually fixed and thus cannot meet the various requirements of different applications. In this paper, we first introduce the truncated Huber penalty function which shows strong flexibility under different parameter settings. A generalized framework is then proposed with the introduced truncated Huber penalty function. When combined with its strong flexibility, our framework is able to achieve diverse smoothing natures where contradictive smoothing behaviors can even be achieved. It can also yield the smoothing behavior that can seldom be achieved by previous methods, and superior performance is thus achieved in challenging cases. These together enable our framework capable of a range of applications and able to outperform the state-of-the-art approaches in several tasks, such as image detail enhancement, clip-art compression artifacts removal, guided depth map restoration, image texture removal, etc. In addition, an efficient numerical solution is provided and its convergence is theoretically guaranteed even the optimization framework is non-convex and non-smooth. A simple yet effective approach is further proposed to reduce the computational cost of our method while maintaining its performance. The effectiveness and superior performance of our approach are validated through comprehensive experiments in a range of applications. Our code is available at https://github.com/wliusjtu/Generalized-Smoothing-Framework.
Systematic Clinical Evaluation of A Deep Learning Method for Medical Image Segmentation: Radiosurgery Application
Aug 21, 2021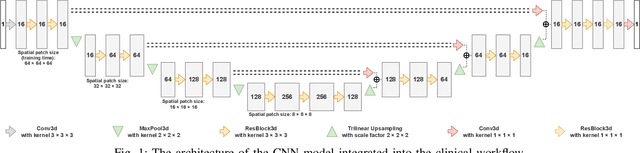
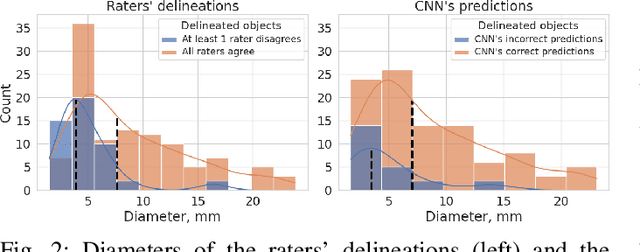
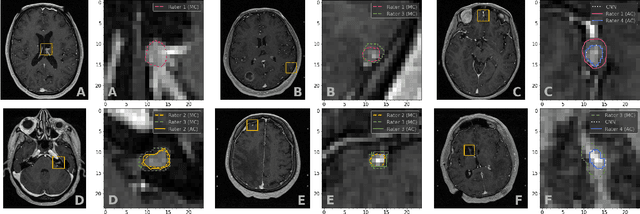
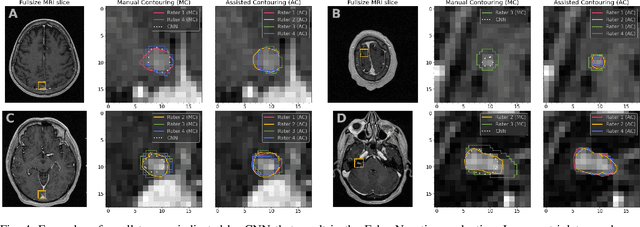
We systematically evaluate a Deep Learning (DL) method in a 3D medical image segmentation task. Our segmentation method is integrated into the radiosurgery treatment process and directly impacts the clinical workflow. With our method, we address the relative drawbacks of manual segmentation: high inter-rater contouring variability and high time consumption of the contouring process. The main extension over the existing evaluations is the careful and detailed analysis that could be further generalized on other medical image segmentation tasks. Firstly, we analyze the changes in the inter-rater detection agreement. We show that the segmentation model reduces the ratio of detection disagreements from 0.162 to 0.085 (p < 0.05). Secondly, we show that the model improves the inter-rater contouring agreement from 0.845 to 0.871 surface Dice Score (p < 0.05). Thirdly, we show that the model accelerates the delineation process in between 1.6 and 2.0 times (p < 0.05). Finally, we design the setup of the clinical experiment to either exclude or estimate the evaluation biases, thus preserve the significance of the results. Besides the clinical evaluation, we also summarize the intuitions and practical ideas for building an efficient DL-based model for 3D medical image segmentation.
Voxel-MAE: Masked Autoencoders for Pre-training Large-scale Point Clouds
Jun 27, 2022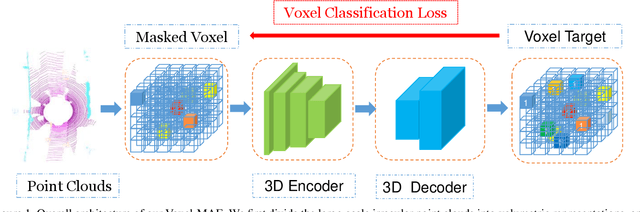
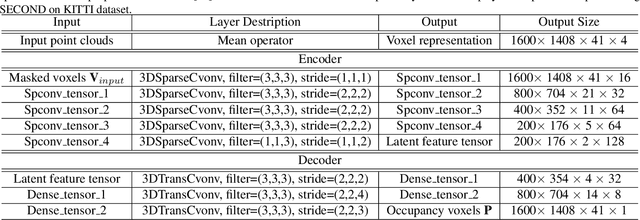
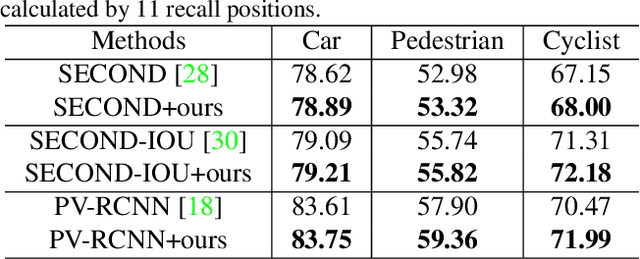
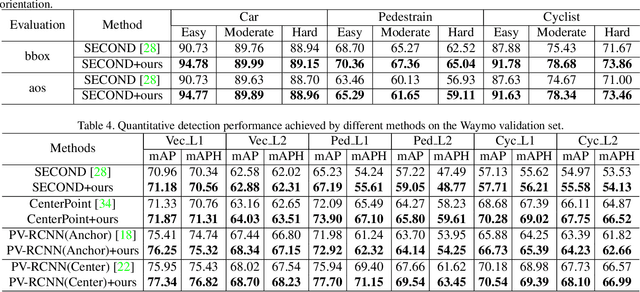
Mask-based pre-training has achieved great success for self-supervised learning in image, video, and language, without manually annotated supervision. However, it has not yet been studied about large-scale point clouds with redundant spatial information in autonomous driving. As the number of large-scale point clouds is huge, it is impossible to reconstruct the input point clouds. In this paper, we propose a mask voxel classification network for large-scale point clouds pre-training. Our key idea is to divide the point clouds into voxel representations and classify whether the voxel contains point clouds. This simple strategy makes the network to be voxel-aware of the object shape, thus improving the performance of the downstream tasks, such as 3D object detection. Our Voxel-MAE with even a 90% masking ratio can still learn representative features for the high spatial redundancy of large-scale point clouds. We also validate the effectiveness of Voxel-MAE in unsupervised domain adaptative tasks, which proves the generalization ability of Voxel-MAE. Our Voxel-MAE proves that it is feasible to pre-train large-scale point clouds without data annotations to enhance the perception ability of the autonomous vehicle. Extensive experiments show great effectiveness of our pre-trained model with 3D object detectors (SECOND, CenterPoint, and PV-RCNN) on two popular datasets (KITTI, Waymo). Codes are publicly available at https://github.com/chaytonmin/Voxel-MAE.
QuTI! Quantifying Text-Image Consistency in Multimodal Documents
Apr 28, 2021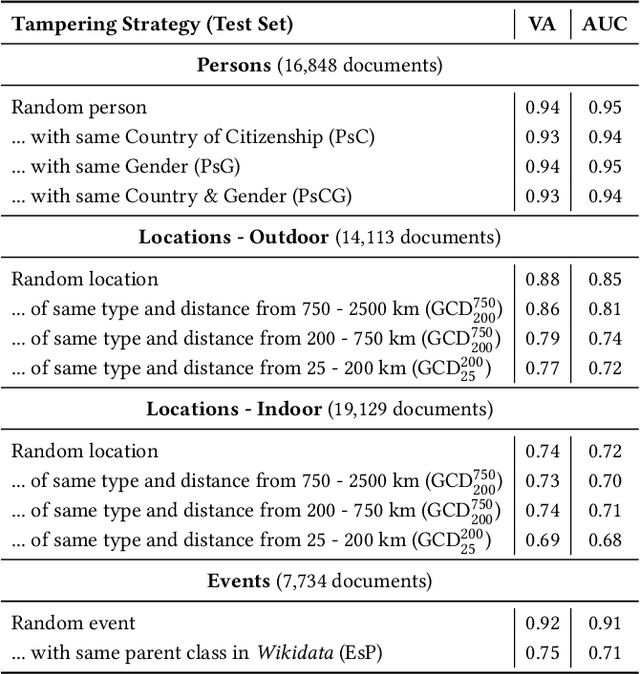
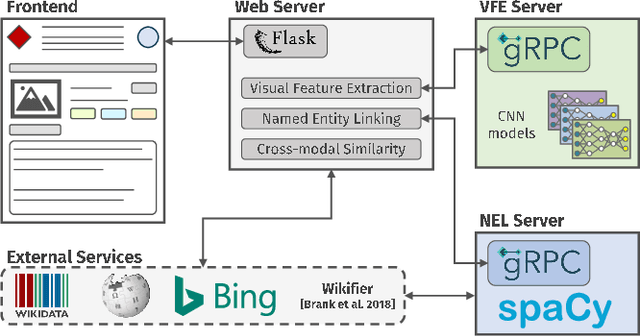
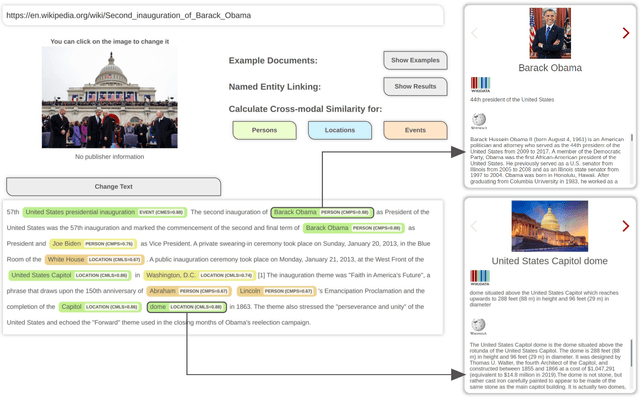
The World Wide Web and social media platforms have become popular sources for news and information. Typically, multimodal information, e.g., image and text is used to convey information more effectively and to attract attention. While in most cases image content is decorative or depicts additional information, it has also been leveraged to spread misinformation and rumors in recent years. In this paper, we present a Web-based demo application that automatically quantifies the cross-modal relations of entities (persons, locations, and events) in image and text. The applications are manifold. For example, the system can help users to explore multimodal articles more efficiently, or can assist human assessors and fact-checking efforts in the verification of the credibility of news stories, tweets, or other multimodal documents.
BadDet: Backdoor Attacks on Object Detection
May 28, 2022
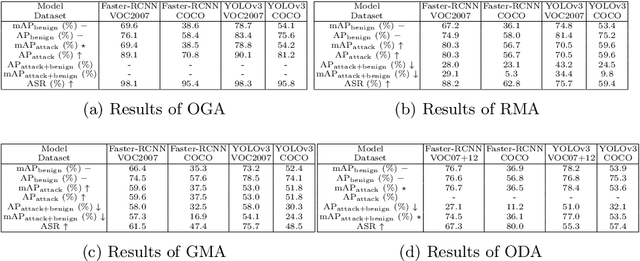


Deep learning models have been deployed in numerous real-world applications such as autonomous driving and surveillance. However, these models are vulnerable in adversarial environments. Backdoor attack is emerging as a severe security threat which injects a backdoor trigger into a small portion of training data such that the trained model behaves normally on benign inputs but gives incorrect predictions when the specific trigger appears. While most research in backdoor attacks focuses on image classification, backdoor attacks on object detection have not been explored but are of equal importance. Object detection has been adopted as an important module in various security-sensitive applications such as autonomous driving. Therefore, backdoor attacks on object detection could pose severe threats to human lives and properties. We propose four kinds of backdoor attacks for object detection task: 1) Object Generation Attack: a trigger can falsely generate an object of the target class; 2) Regional Misclassification Attack: a trigger can change the prediction of a surrounding object to the target class; 3) Global Misclassification Attack: a single trigger can change the predictions of all objects in an image to the target class; and 4) Object Disappearance Attack: a trigger can make the detector fail to detect the object of the target class. We develop appropriate metrics to evaluate the four backdoor attacks on object detection. We perform experiments using two typical object detection models -- Faster-RCNN and YOLOv3 on different datasets. More crucially, we demonstrate that even fine-tuning on another benign dataset cannot remove the backdoor hidden in the object detection model. To defend against these backdoor attacks, we propose Detector Cleanse, an entropy-based run-time detection framework to identify poisoned testing samples for any deployed object detector.