 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
S3Net: A Single Stream Structure for Depth Guided Image Relighting
May 03, 2021


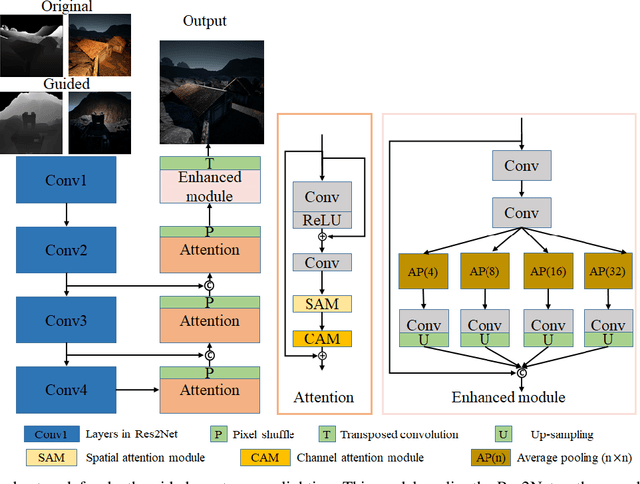
Depth guided any-to-any image relighting aims to generate a relit image from the original image and corresponding depth maps to match the illumination setting of the given guided image and its depth map. To the best of our knowledge, this task is a new challenge that has not been addressed in the previous literature. To address this issue, we propose a deep learning-based neural Single Stream Structure network called S3Net for depth guided image relighting. This network is an encoder-decoder model. We concatenate all images and corresponding depth maps as the input and feed them into the model. The decoder part contains the attention module and the enhanced module to focus on the relighting-related regions in the guided images. Experiments performed on challenging benchmark show that the proposed model achieves the 3 rd highest SSIM in the NTIRE 2021 Depth Guided Any-to-any Relighting Challenge.
A Simple Baseline for BEV Perception Without LiDAR
Jun 16, 2022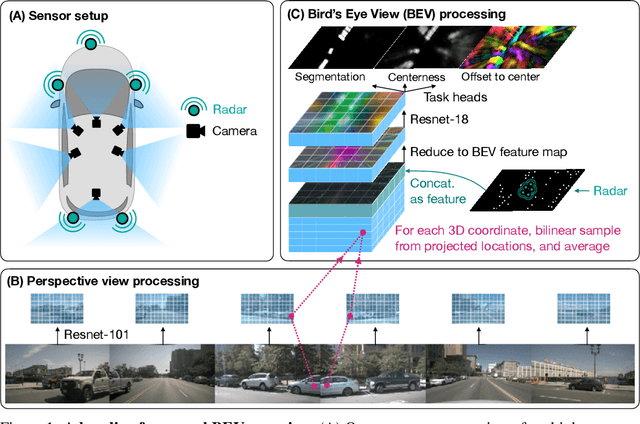



Building 3D perception systems for autonomous vehicles that do not rely on LiDAR is a critical research problem because of the high expense of LiDAR systems compared to cameras and other sensors. Current methods use multi-view RGB data collected from cameras around the vehicle and neurally "lift" features from the perspective images to the 2D ground plane, yielding a "bird's eye view" (BEV) feature representation of the 3D space around the vehicle. Recent research focuses on the way the features are lifted from images to the BEV plane. We instead propose a simple baseline model, where the "lifting" step simply averages features from all projected image locations, and find that it outperforms the current state-of-the-art in BEV vehicle segmentation. Our ablations show that batch size, data augmentation, and input resolution play a large part in performance. Additionally, we reconsider the utility of radar input, which has previously been either ignored or found non-helpful by recent works. With a simple RGB-radar fusion module, we obtain a sizable boost in performance, approaching the accuracy of a LiDAR-enabled system.
BiOcularGAN: Bimodal Synthesis and Annotation of Ocular Images
May 03, 2022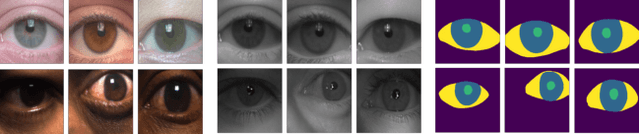
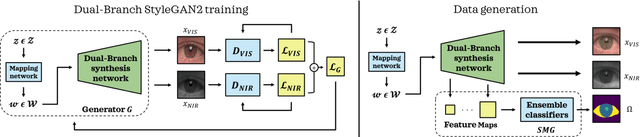
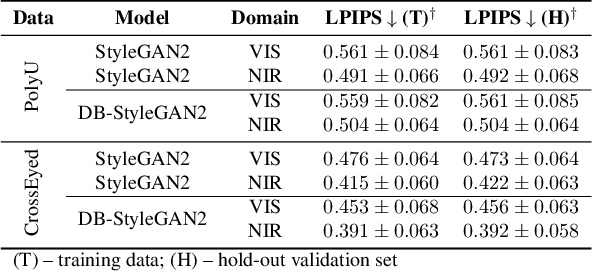
Current state-of-the-art segmentation techniques for ocular images are critically dependent on large-scale annotated datasets, which are labor-intensive to gather and often raise privacy concerns. In this paper, we present a novel framework, called BiOcularGAN, capable of generating synthetic large-scale datasets of photorealistic (visible light and near infrared) ocular images, together with corresponding segmentation labels to address these issues. At its core, the framework relies on a novel Dual-Branch StyleGAN2 (DB-StyleGAN2) model that facilitates bimodal image generation, and a Semantic Mask Generator (SMG) that produces semantic annotations by exploiting DB-StyleGAN2's feature space. We evaluate BiOcularGAN through extensive experiments across five diverse ocular datasets and analyze the effects of bimodal data generation on image quality and the produced annotations. Our experimental results show that BiOcularGAN is able to produce high-quality matching bimodal images and annotations (with minimal manual intervention) that can be used to train highly competitive (deep) segmentation models that perform well across multiple real-world datasets. The source code will be made publicly available.
RES: A Robust Framework for Guiding Visual Explanation
Jun 27, 2022
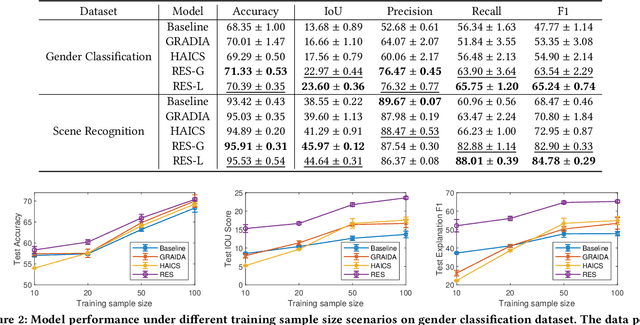
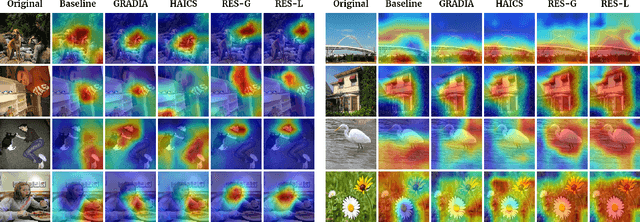
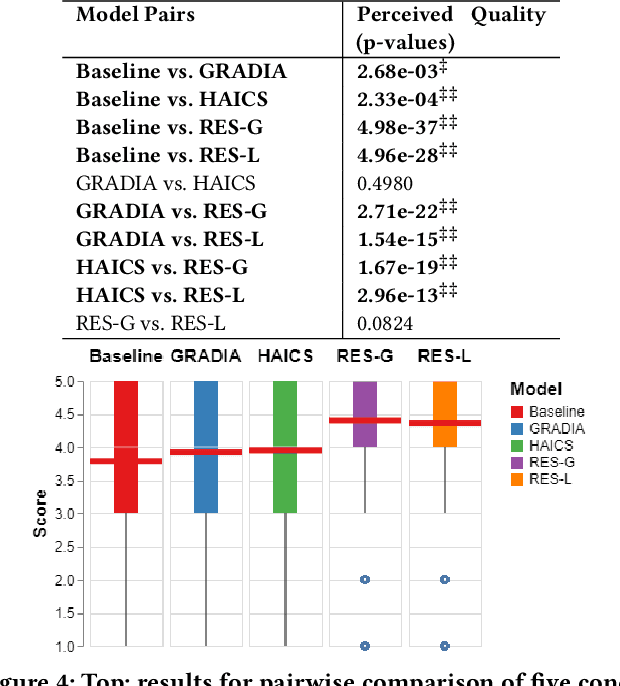
Despite the fast progress of explanation techniques in modern Deep Neural Networks (DNNs) where the main focus is handling "how to generate the explanations", advanced research questions that examine the quality of the explanation itself (e.g., "whether the explanations are accurate") and improve the explanation quality (e.g., "how to adjust the model to generate more accurate explanations when explanations are inaccurate") are still relatively under-explored. To guide the model toward better explanations, techniques in explanation supervision - which add supervision signals on the model explanation - have started to show promising effects on improving both the generalizability as and intrinsic interpretability of Deep Neural Networks. However, the research on supervising explanations, especially in vision-based applications represented through saliency maps, is in its early stage due to several inherent challenges: 1) inaccuracy of the human explanation annotation boundary, 2) incompleteness of the human explanation annotation region, and 3) inconsistency of the data distribution between human annotation and model explanation maps. To address the challenges, we propose a generic RES framework for guiding visual explanation by developing a novel objective that handles inaccurate boundary, incomplete region, and inconsistent distribution of human annotations, with a theoretical justification on model generalizability. Extensive experiments on two real-world image datasets demonstrate the effectiveness of the proposed framework on enhancing both the reasonability of the explanation and the performance of the backbone DNNs model.
* Published in KDD 2022
Posterior Sampling for Image Restoration using Explicit Patch Priors
Apr 20, 2021


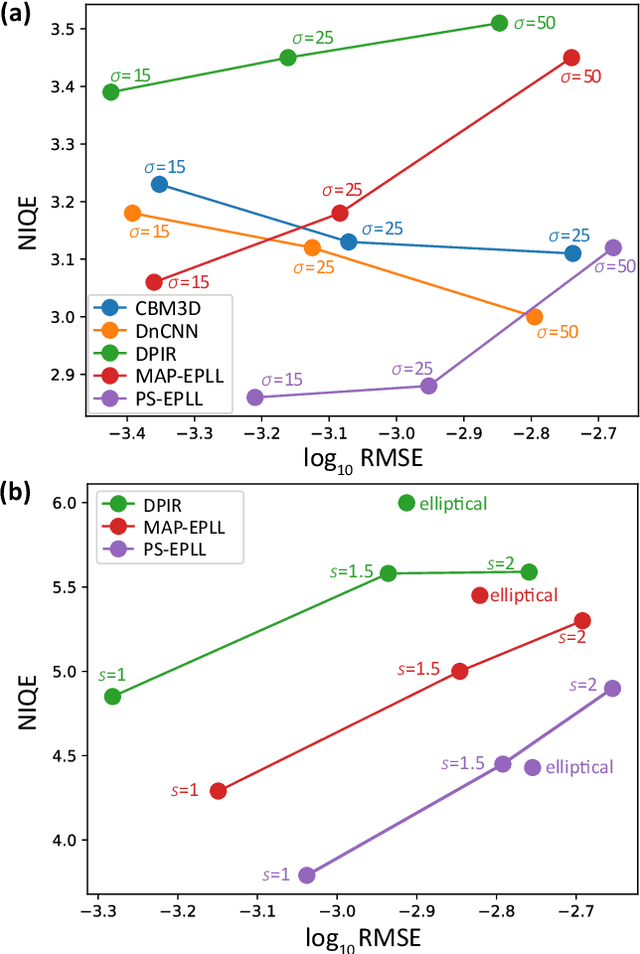
Almost all existing methods for image restoration are based on optimizing the mean squared error (MSE), even though it is known that the best estimate in terms of MSE may yield a highly atypical image due to the fact that there are many plausible restorations for a given noisy image. In this paper, we show how to combine explicit priors on patches of natural images in order to sample from the posterior probability of a full image given a degraded image. We prove that our algorithm generates correct samples from the distribution $p(x|y) \propto \exp(-E(x|y))$ where $E(x|y)$ is the cost function minimized in previous patch-based approaches that compute a single restoration. Unlike previous approaches that computed a single restoration using MAP or MMSE, our method makes explicit the uncertainty in the restored images and guarantees that all patches in the restored images will be typical given the patch prior. Unlike previous approaches that used implicit priors on fixed-size images, our approach can be used with images of any size. Our experimental results show that posterior sampling using patch priors yields images of high perceptual quality and high PSNR on a range of challenging image restoration problems.
Invisible Backdoor Attacks Using Data Poisoning in the Frequency Domain
Jul 09, 2022
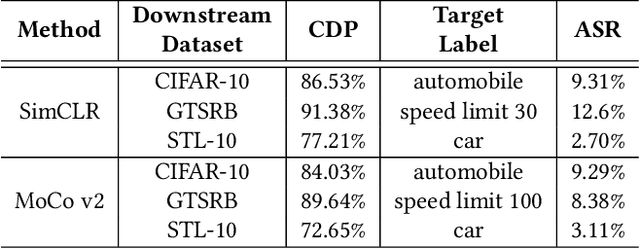

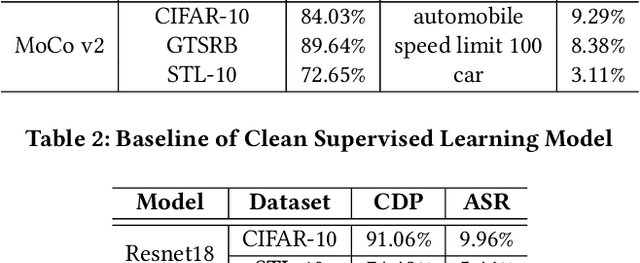
With the broad application of deep neural networks (DNNs), backdoor attacks have gradually attracted attention. Backdoor attacks are insidious, and poisoned models perform well on benign samples and are only triggered when given specific inputs, which cause the neural network to produce incorrect outputs. The state-of-the-art backdoor attack work is implemented by data poisoning, i.e., the attacker injects poisoned samples into the dataset, and the models trained with that dataset are infected with the backdoor. However, most of the triggers used in the current study are fixed patterns patched on a small fraction of an image and are often clearly mislabeled, which is easily detected by humans or defense methods such as Neural Cleanse and SentiNet. Also, it's difficult to be learned by DNNs without mislabeling, as they may ignore small patterns. In this paper, we propose a generalized backdoor attack method based on the frequency domain, which can implement backdoor implantation without mislabeling and accessing the training process. It is invisible to human beings and able to evade the commonly used defense methods. We evaluate our approach in the no-label and clean-label cases on three datasets (CIFAR-10, STL-10, and GTSRB) with two popular scenarios (self-supervised learning and supervised learning). The results show our approach can achieve a high attack success rate (above 90%) on all the tasks without significant performance degradation on main tasks. Also, we evaluate the bypass performance of our approach for different kinds of defenses, including the detection of training data (i.e., Activation Clustering), the preprocessing of inputs (i.e., Filtering), the detection of inputs (i.e., SentiNet), and the detection of models (i.e., Neural Cleanse). The experimental results demonstrate that our approach shows excellent robustness to such defenses.
Reconstruction and segmentation from sparse sequential X-ray measurements of wood logs
Jun 20, 2022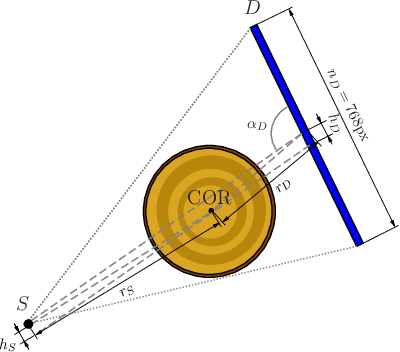



In industrial applications it is common to scan objects on a moving conveyor belt. If slice-wise 2D computed tomography (CT) measurements of the moving object are obtained we call it a sequential scanning geometry. In this case, each slice on its own does not carry sufficient information to reconstruct a useful tomographic image. Thus, here we propose the use of a Dimension reduced Kalman Filter to accumulate information between slices and allow for sufficiently accurate reconstructions for further assessment of the object. Additionally, we propose to use an unsupervised clustering approach known as Density Peak Advanced, to perform a segmentation and spot density anomalies in the internal structure of the reconstructed objects. We evaluate the method in a proof of concept study for the application of wood log scanning for the industrial sawing process, where the goal is to spot anomalies within the wood log to allow for optimal sawing patterns. Reconstruction and segmentation quality is evaluated from experimental measurement data for various scenarios of severely undersampled X-measurements. Results show clearly that an improvement of reconstruction quality can be obtained by employing the Dimension reduced Kalman Filter allowing to robustly obtain the segmented logs.
Improving Image co-segmentation via Deep Metric Learning
Mar 19, 2021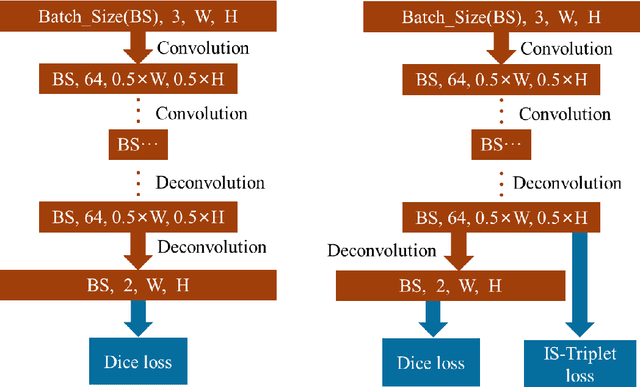
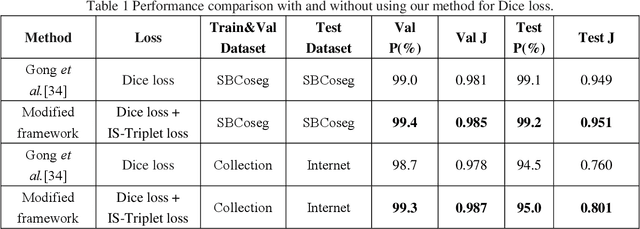
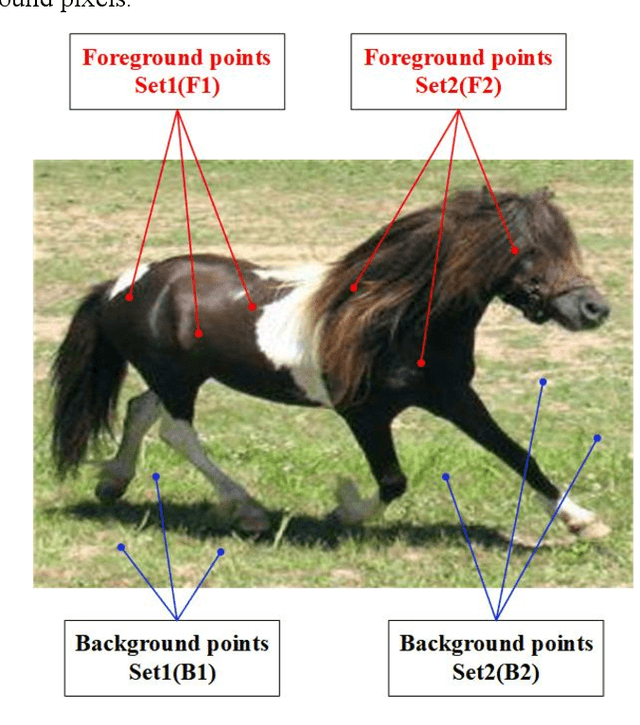
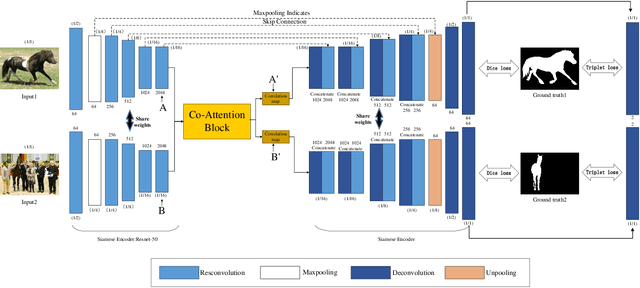
Deep Metric Learning (DML) is helpful in computer vision tasks. In this paper, we firstly introduce DML into image co-segmentation. We propose a novel Triplet loss for Image Segmentation, called IS-Triplet loss for short, and combine it with traditional image segmentation loss. Different from the general DML task which learns the metric between pictures, we treat each pixel as a sample, and use their embedded features in high-dimensional space to form triples, then we tend to force the distance between pixels of different categories greater than of the same category by optimizing IS-Triplet loss so that the pixels from different categories are easier to be distinguished in the high-dimensional feature space. We further present an efficient triple sampling strategy to make a feasible computation of IS-Triplet loss. Finally, the IS-Triplet loss is combined with 3 traditional image segmentation losses to perform image segmentation. We apply the proposed approach to image co-segmentation and test it on the SBCoseg dataset and the Internet dataset. The experimental result shows that our approach can effectively improve the discrimination of pixels' categories in high-dimensional space and thus help traditional loss achieve better performance of image segmentation with fewer training epochs.
WaveFill: A Wavelet-based Generation Network for Image Inpainting
Jul 23, 2021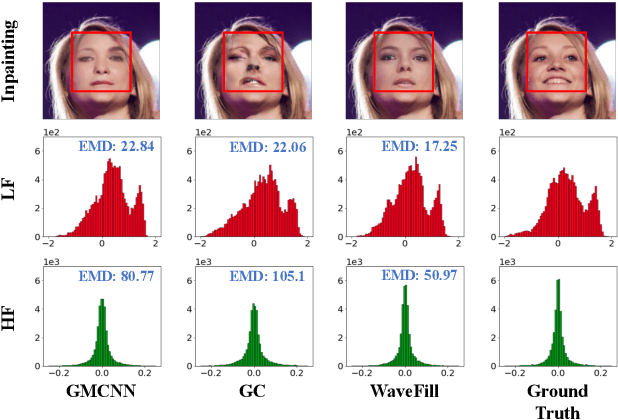
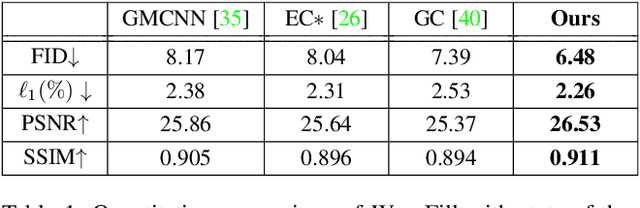
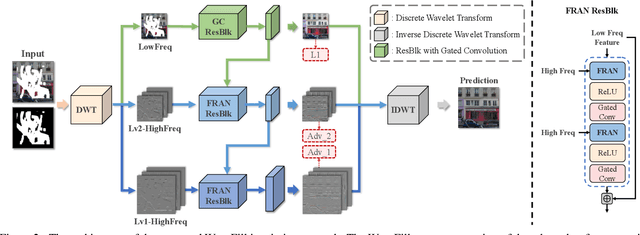
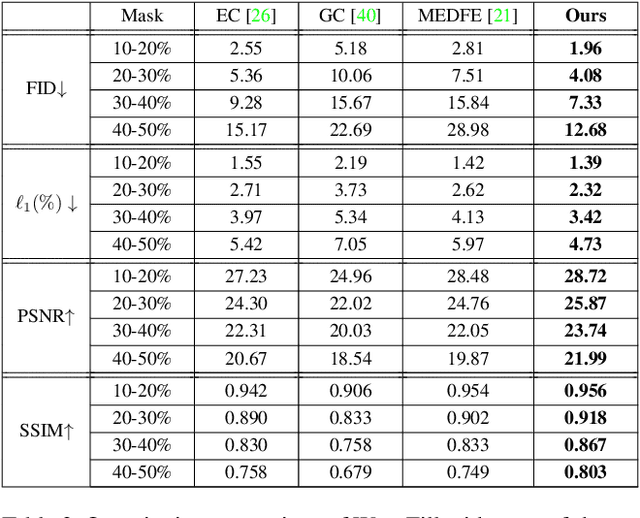
Image inpainting aims to complete the missing or corrupted regions of images with realistic contents. The prevalent approaches adopt a hybrid objective of reconstruction and perceptual quality by using generative adversarial networks. However, the reconstruction loss and adversarial loss focus on synthesizing contents of different frequencies and simply applying them together often leads to inter-frequency conflicts and compromised inpainting. This paper presents WaveFill, a wavelet-based inpainting network that decomposes images into multiple frequency bands and fills the missing regions in each frequency band separately and explicitly. WaveFill decomposes images by using discrete wavelet transform (DWT) that preserves spatial information naturally. It applies L1 reconstruction loss to the decomposed low-frequency bands and adversarial loss to high-frequency bands, hence effectively mitigate inter-frequency conflicts while completing images in spatial domain. To address the inpainting inconsistency in different frequency bands and fuse features with distinct statistics, we design a novel normalization scheme that aligns and fuses the multi-frequency features effectively. Extensive experiments over multiple datasets show that WaveFill achieves superior image inpainting qualitatively and quantitatively.
Optimization-Derived Learning with Essential Convergence Analysis of Training and Hyper-training
Jun 16, 2022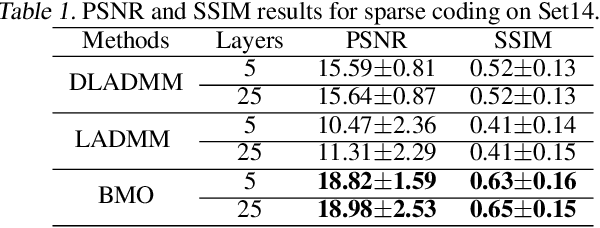

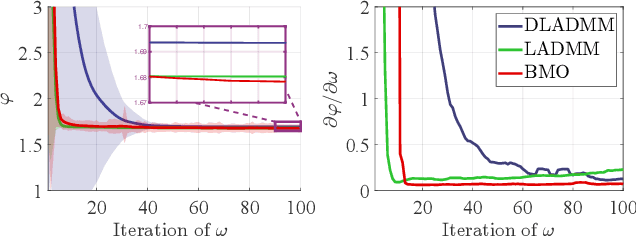
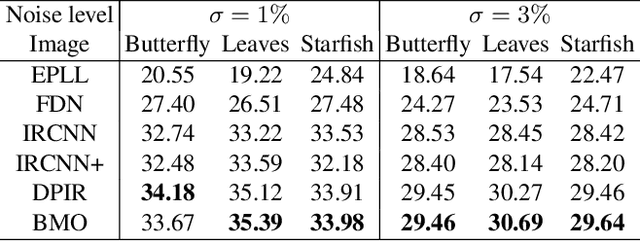
Recently, Optimization-Derived Learning (ODL) has attracted attention from learning and vision areas, which designs learning models from the perspective of optimization. However, previous ODL approaches regard the training and hyper-training procedures as two separated stages, meaning that the hyper-training variables have to be fixed during the training process, and thus it is also impossible to simultaneously obtain the convergence of training and hyper-training variables. In this work, we design a Generalized Krasnoselskii-Mann (GKM) scheme based on fixed-point iterations as our fundamental ODL module, which unifies existing ODL methods as special cases. Under the GKM scheme, a Bilevel Meta Optimization (BMO) algorithmic framework is constructed to solve the optimal training and hyper-training variables together. We rigorously prove the essential joint convergence of the fixed-point iteration for training and the process of optimizing hyper-parameters for hyper-training, both on the approximation quality, and on the stationary analysis. Experiments demonstrate the efficiency of BMO with competitive performance on sparse coding and real-world applications such as image deconvolution and rain streak removal.