 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
Feb 29, 2024
In this paper, we delve into the creation of one-shot hand avatars, attaining high-fidelity and drivable hand representations swiftly from a single image. With the burgeoning domains of the digital human, the need for quick and personalized hand avatar creation has become increasingly critical. Existing techniques typically require extensive input data and may prove cumbersome or even impractical in certain scenarios. To enhance accessibility, we present a novel method OHTA (One-shot Hand avaTAr) that enables the creation of detailed hand avatars from merely one image. OHTA tackles the inherent difficulties of this data-limited problem by learning and utilizing data-driven hand priors. Specifically, we design a hand prior model initially employed for 1) learning various hand priors with available data and subsequently for 2) the inversion and fitting of the target identity with prior knowledge. OHTA demonstrates the capability to create high-fidelity hand avatars with consistent animatable quality, solely relying on a single image. Furthermore, we illustrate the versatility of OHTA through diverse applications, encompassing text-to-avatar conversion, hand editing, and identity latent space manipulation.
NRDF: Neural Riemannian Distance Fields for Learning Articulated Pose Priors
Mar 05, 2024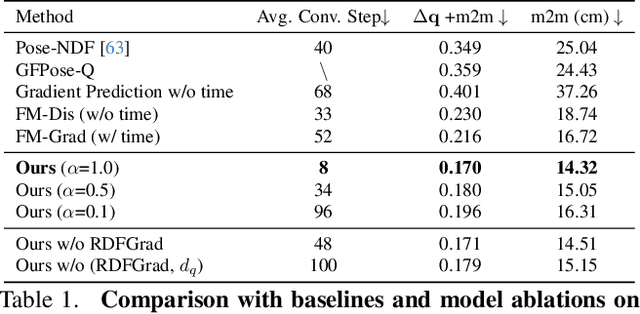
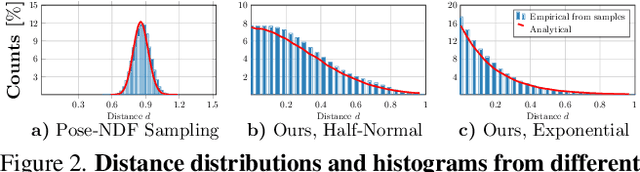
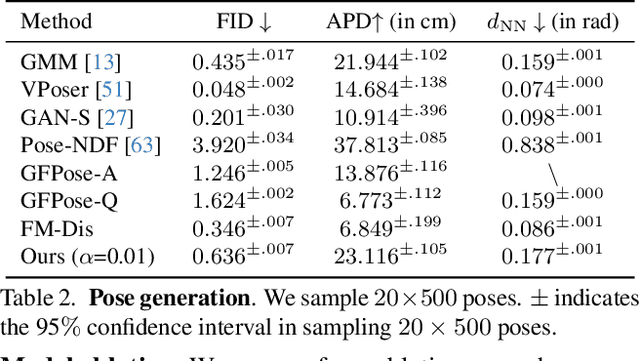
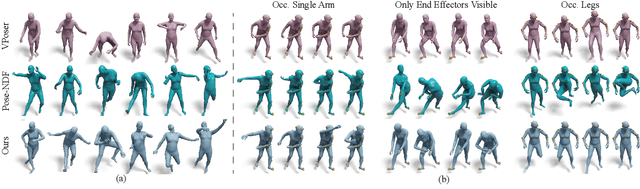
Faithfully modeling the space of articulations is a crucial task that allows recovery and generation of realistic poses, and remains a notorious challenge. To this end, we introduce Neural Riemannian Distance Fields (NRDFs), data-driven priors modeling the space of plausible articulations, represented as the zero-level-set of a neural field in a high-dimensional product-quaternion space. To train NRDFs only on positive examples, we introduce a new sampling algorithm, ensuring that the geodesic distances follow a desired distribution, yielding a principled distance field learning paradigm. We then devise a projection algorithm to map any random pose onto the level-set by an adaptive-step Riemannian optimizer, adhering to the product manifold of joint rotations at all times. NRDFs can compute the Riemannian gradient via backpropagation and by mathematical analogy, are related to Riemannian flow matching, a recent generative model. We conduct a comprehensive evaluation of NRDF against other pose priors in various downstream tasks, i.e., pose generation, image-based pose estimation, and solving inverse kinematics, highlighting NRDF's superior performance. Besides humans, NRDF's versatility extends to hand and animal poses, as it can effectively represent any articulation.
Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models
Mar 05, 2024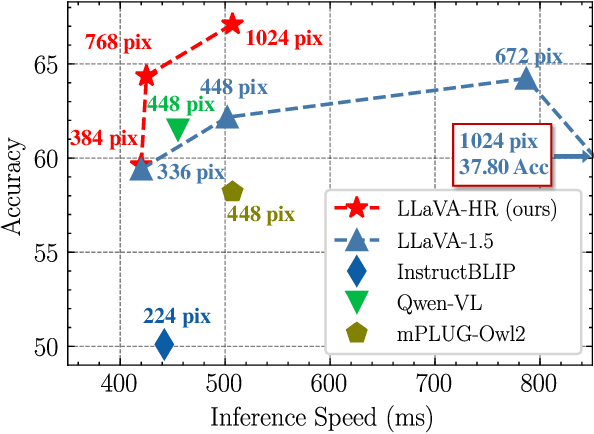
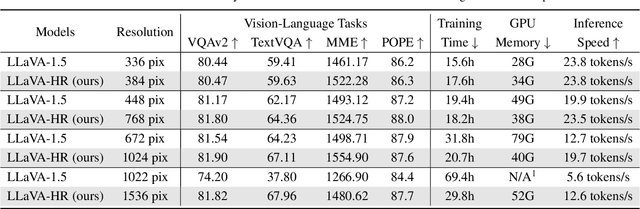
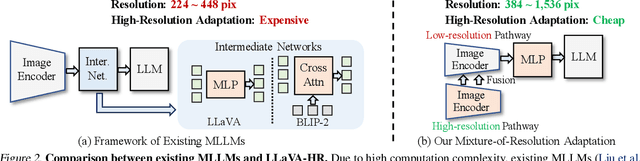
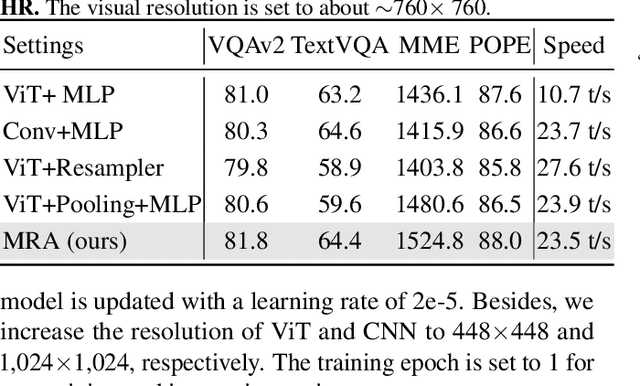
Despite remarkable progress, existing multimodal large language models (MLLMs) are still inferior in granular visual recognition. Contrary to previous works, we study this problem from the perspective of image resolution, and reveal that a combination of low- and high-resolution visual features can effectively mitigate this shortcoming. Based on this observation, we propose a novel and efficient method for MLLMs, termed Mixture-of-Resolution Adaptation (MRA). In particular, MRA adopts two visual pathways for images with different resolutions, where high-resolution visual information is embedded into the low-resolution pathway via the novel mixture-of-resolution adapters (MR-Adapters). This design also greatly reduces the input sequence length of MLLMs. To validate MRA, we apply it to a recent MLLM called LLaVA, and term the new model LLaVA-HR. We conduct extensive experiments on 11 vision-language (VL) tasks, which show that LLaVA-HR outperforms existing MLLMs on 8 VL tasks, e.g., +9.4% on TextVQA. More importantly, both training and inference of LLaVA-HR remain efficient with MRA, e.g., 20 training hours and 3$\times$ inference speed than LLaVA-1.5. Source codes are released at: https://github.com/luogen1996/LLaVA-HR.
Matrix Completion with Convex Optimization and Column Subset Selection
Mar 05, 2024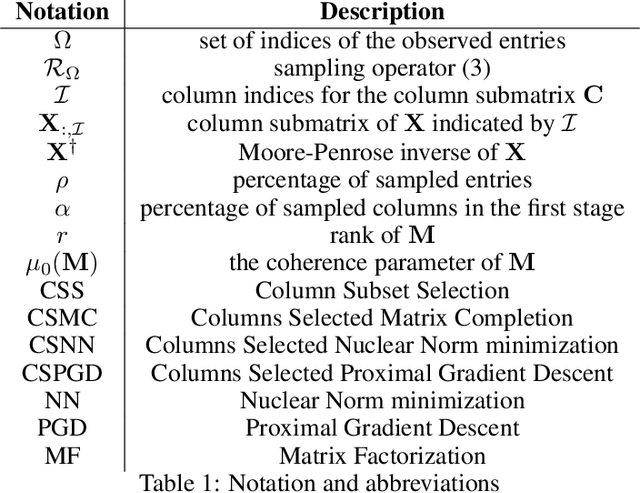
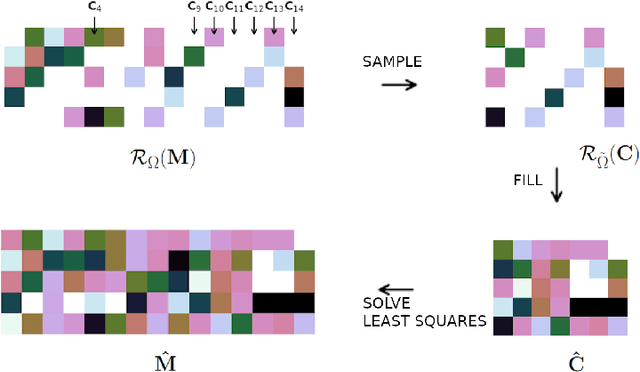
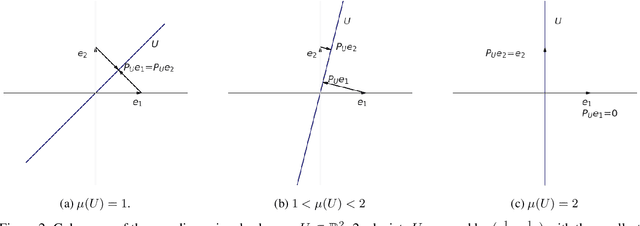
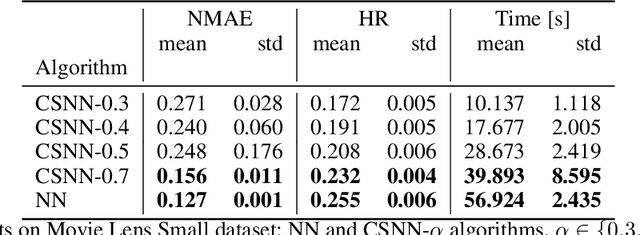
We introduce a two-step method for the matrix recovery problem. Our approach combines the theoretical foundations of the Column Subset Selection and Low-rank Matrix Completion problems. The proposed method, in each step, solves a convex optimization task. We present two algorithms that implement our Columns Selected Matrix Completion (CSMC) method, each dedicated to a different size problem. We performed a formal analysis of the presented method, in which we formulated the necessary assumptions and the probability of finding a correct solution. In the second part of the paper, we present the results of the experimental work. Numerical experiments verified the correctness and performance of the algorithms. To study the influence of the matrix size, rank, and the proportion of missing elements on the quality of the solution and the computation time, we performed experiments on synthetic data. The presented method was applied to two real-life problems problems: prediction of movie rates in a recommendation system and image inpainting. Our thorough analysis shows that CSMC provides solutions of comparable quality to matrix completion algorithms, which are based on convex optimization. However, CSMC offers notable savings in terms of runtime.
Behavior Generation with Latent Actions
Mar 05, 2024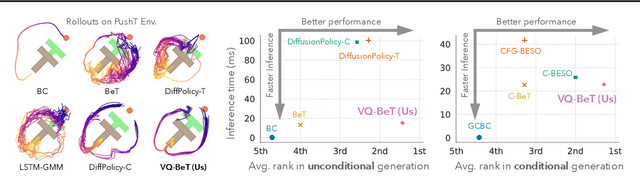
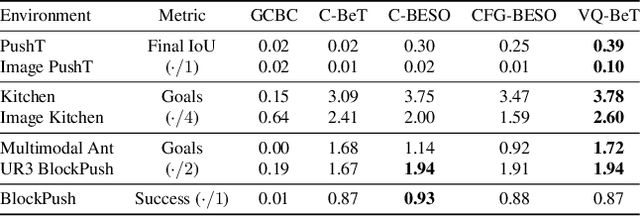
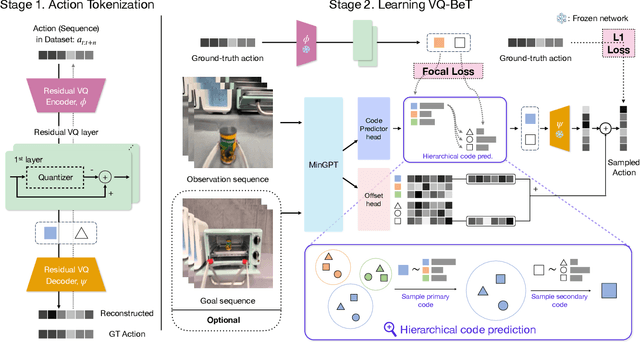
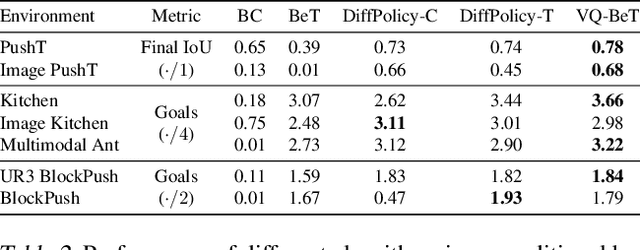
Generative modeling of complex behaviors from labeled datasets has been a longstanding problem in decision making. Unlike language or image generation, decision making requires modeling actions - continuous-valued vectors that are multimodal in their distribution, potentially drawn from uncurated sources, where generation errors can compound in sequential prediction. A recent class of models called Behavior Transformers (BeT) addresses this by discretizing actions using k-means clustering to capture different modes. However, k-means struggles to scale for high-dimensional action spaces or long sequences, and lacks gradient information, and thus BeT suffers in modeling long-range actions. In this work, we present Vector-Quantized Behavior Transformer (VQ-BeT), a versatile model for behavior generation that handles multimodal action prediction, conditional generation, and partial observations. VQ-BeT augments BeT by tokenizing continuous actions with a hierarchical vector quantization module. Across seven environments including simulated manipulation, autonomous driving, and robotics, VQ-BeT improves on state-of-the-art models such as BeT and Diffusion Policies. Importantly, we demonstrate VQ-BeT's improved ability to capture behavior modes while accelerating inference speed 5x over Diffusion Policies. Videos and code can be found https://sjlee.cc/vq-bet
Enhancing Generalization in Medical Visual Question Answering Tasks via Gradient-Guided Model Perturbation
Mar 05, 2024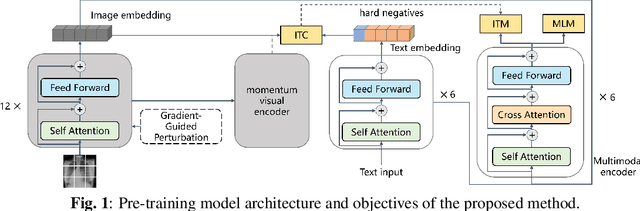
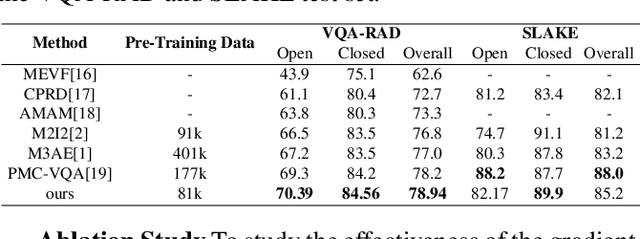
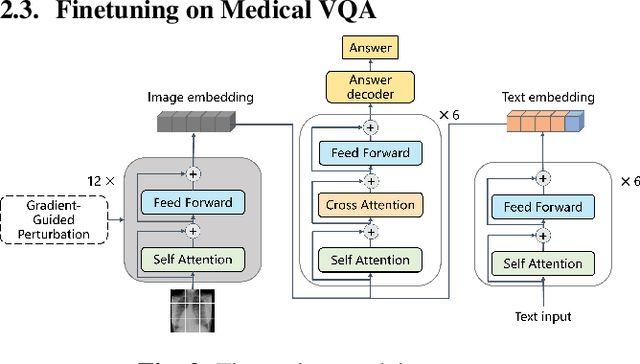
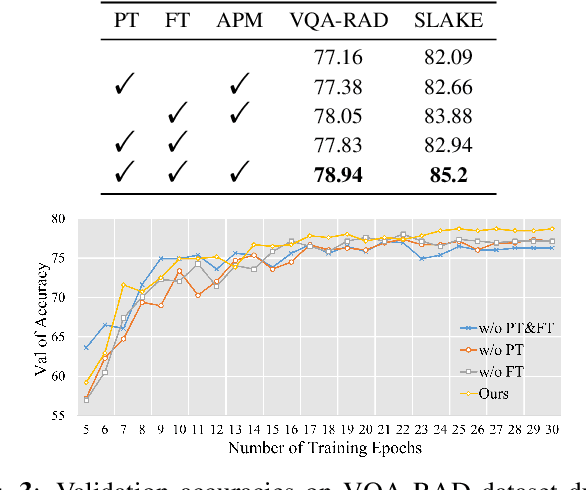
Leveraging pre-trained visual language models has become a widely adopted approach for improving performance in downstream visual question answering (VQA) applications. However, in the specialized field of medical VQA, the scarcity of available data poses a significant barrier to achieving reliable model generalization. Numerous methods have been proposed to enhance model generalization, addressing the issue from data-centric and model-centric perspectives. Data augmentation techniques are commonly employed to enrich the dataset, while various regularization approaches aim to prevent model overfitting, especially when training on limited data samples. In this paper, we introduce a method that incorporates gradient-guided parameter perturbations to the visual encoder of the multimodality model during both pre-training and fine-tuning phases, to improve model generalization for downstream medical VQA tasks. The small perturbation is adaptively generated by aligning with the direction of the moving average gradient in the optimization landscape, which is opposite to the directions of the optimizer's historical updates. It is subsequently injected into the model's visual encoder. The results show that, even with a significantly smaller pre-training image caption dataset, our approach achieves competitive outcomes on both VQA-RAD and SLAKE datasets.
Domain-Agnostic Mutual Prompting for Unsupervised Domain Adaptation
Mar 05, 2024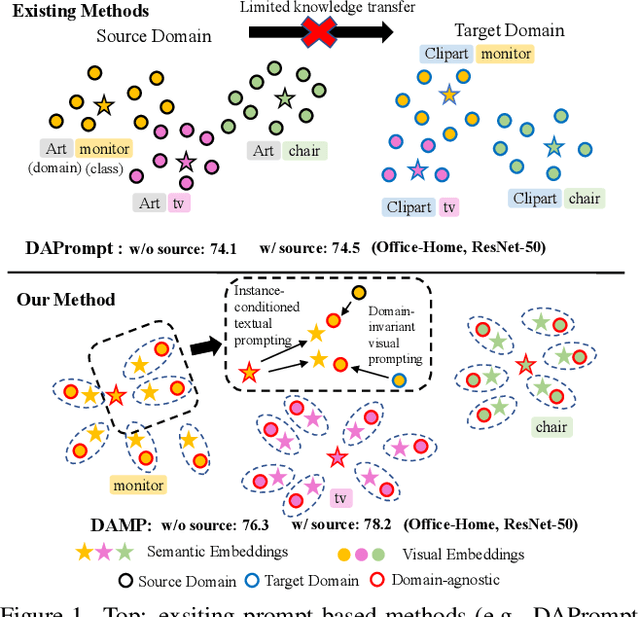
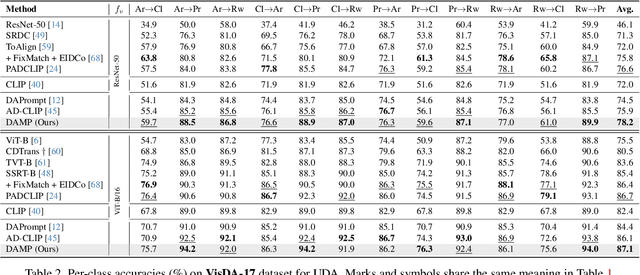
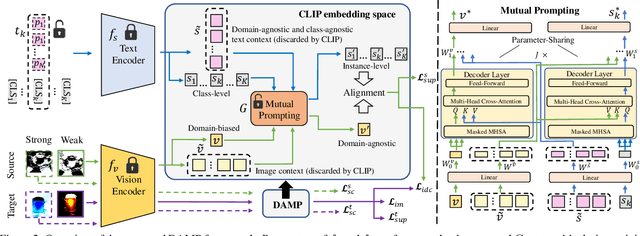
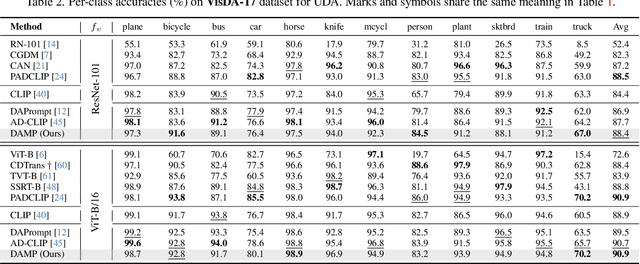
Conventional Unsupervised Domain Adaptation (UDA) strives to minimize distribution discrepancy between domains, which neglects to harness rich semantics from data and struggles to handle complex domain shifts. A promising technique is to leverage the knowledge of large-scale pre-trained vision-language models for more guided adaptation. Despite some endeavors, current methods often learn textual prompts to embed domain semantics for source and target domains separately and perform classification within each domain, limiting cross-domain knowledge transfer. Moreover, prompting only the language branch lacks flexibility to adapt both modalities dynamically. To bridge this gap, we propose Domain-Agnostic Mutual Prompting (DAMP) to exploit domain-invariant semantics by mutually aligning visual and textual embeddings. Specifically, the image contextual information is utilized to prompt the language branch in a domain-agnostic and instance-conditioned way. Meanwhile, visual prompts are imposed based on the domain-agnostic textual prompt to elicit domain-invariant visual embeddings. These two branches of prompts are learned mutually with a cross-attention module and regularized with a semantic-consistency loss and an instance-discrimination contrastive loss. Experiments on three UDA benchmarks demonstrate the superiority of DAMP over state-of-the-art approaches.
Learning semantic image quality for fetal ultrasound from noisy ranking annotation
Feb 13, 2024We introduce the notion of semantic image quality for applications where image quality relies on semantic requirements. Working in fetal ultrasound, where ranking is challenging and annotations are noisy, we design a robust coarse-to-fine model that ranks images based on their semantic image quality and endow our predicted rankings with an uncertainty estimate. To annotate rankings on training data, we design an efficient ranking annotation scheme based on the merge sort algorithm. Finally, we compare our ranking algorithm to a number of state-of-the-art ranking algorithms on a challenging fetal ultrasound quality assessment task, showing the superior performance of our method on the majority of rank correlation metrics.
VisionLLaMA: A Unified LLaMA Interface for Vision Tasks
Mar 01, 2024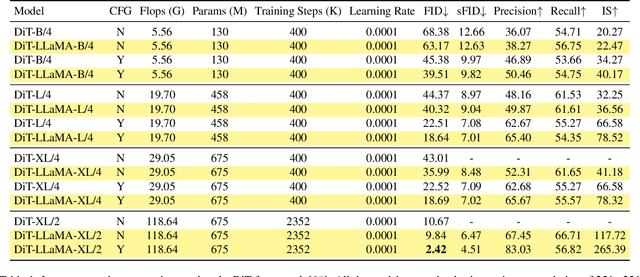
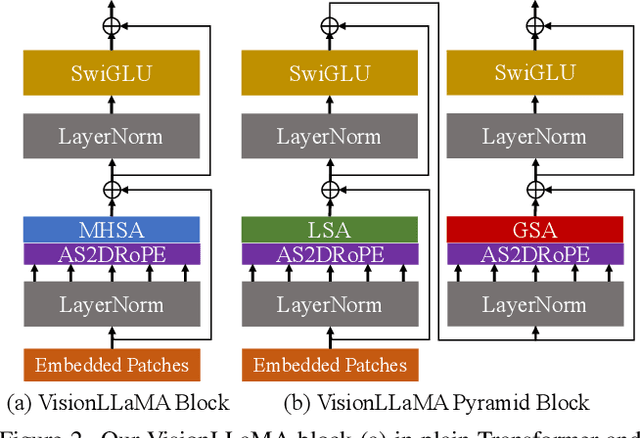
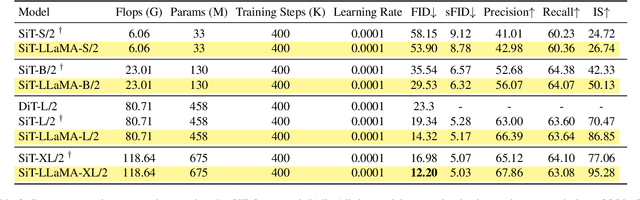
Large language models are built on top of a transformer-based architecture to process textual inputs. For example, the LLaMA stands out among many open-source implementations. Can the same transformer be used to process 2D images? In this paper, we answer this question by unveiling a LLaMA-like vision transformer in plain and pyramid forms, termed VisionLLaMA, which is tailored for this purpose. VisionLLaMA is a unified and generic modelling framework for solving most vision tasks. We extensively evaluate its effectiveness using typical pre-training paradigms in a good portion of downstream tasks of image perception and especially image generation. In many cases, VisionLLaMA have exhibited substantial gains over the previous state-of-the-art vision transformers. We believe that VisionLLaMA can serve as a strong new baseline model for vision generation and understanding. Our code will be released at https://github.com/Meituan-AutoML/VisionLLaMA.
TAMM: TriAdapter Multi-Modal Learning for 3D Shape Understanding
Feb 28, 2024The limited scale of current 3D shape datasets hinders the advancements in 3D shape understanding, and motivates multi-modal learning approaches which transfer learned knowledge from data-abundant 2D image and language modalities to 3D shapes. However, even though the image and language representations have been aligned by cross-modal models like CLIP, we find that the image modality fails to contribute as much as the language in existing multi-modal 3D representation learning methods. This is attributed to the domain shift in the 2D images and the distinct focus of each modality. To more effectively leverage both modalities in the pre-training, we introduce TriAdapter Multi-Modal Learning (TAMM) -- a novel two-stage learning approach based on three synergetic adapters. First, our CLIP Image Adapter mitigates the domain gap between 3D-rendered images and natural images, by adapting the visual representations of CLIP for synthetic image-text pairs. Subsequently, our Dual Adapters decouple the 3D shape representation space into two complementary sub-spaces: one focusing on visual attributes and the other for semantic understanding, which ensure a more comprehensive and effective multi-modal pre-training. Extensive experiments demonstrate that TAMM consistently enhances 3D representations for a wide range of 3D encoder architectures, pre-training datasets, and downstream tasks. Notably, we boost the zero-shot classification accuracy on Objaverse-LVIS from 46.8 to 50.7, and improve the 5-way 10-shot linear probing classification accuracy on ModelNet40 from 96.1 to 99.0. Project page: \url{https://alanzhangcs.github.io/tamm-page}.